一种培育水稻普通核不育系的方法与流程
本发明涉及水稻生物技术育种领域,具体涉及一种培育水稻普通核不育系的方法。
背景技术:
普通核不育受一对隐性核基因控制,一般不受外部环境因子的影响,不管环境条件怎样变化,总是表现为不育。在生产应用中,普通核不育具有以下优点:1)育性正常的品种都是它的恢复系,恢复谱及其广泛,配组自由使得选育优良组合的几率大增;2)能紧跟常规稻的选育步伐,开辟籼粳亚种间杂种优势新领域,使水稻产量在现有杂交水稻基础上实现更高产目标。因此,袁隆平院士将普通核不育系应用于杂交水稻制种的技术称为第三代的杂交水稻。目前普通核不育系的繁殖难题已经攻克,湖南杂交水稻研究中心申请的ZL201210426678.7号和ZL201210426939.5号中国专利文献中记载了利用基因工程手段构建工程保持系来大规模繁殖普通核不育系的方法,为普通核不育系应用于实际生产奠定了基础。但利用普通核不育系配制高产、高抗和质优的超级稻组合还存在难题,主要的难题就是优良普通核不育系的选育方面还只能通过传统的物理化学方法诱变优良的保持系和恢复系等可育材料获得或者将这些优良的可育材料与不育系通过多代回交选育获得。物理化学诱变方法具有随机性,效率低下,劳动强度大;回交选育需要经过多代回交进行背景筛选,时间跨度大,即使经过多代回交也很难恢复原有的遗传背景,导致原有的一些优良性状丢失和利用工程保持系所繁育的普通核不育系株型不一致。所以,这两种传统方法都有很大的局限性,延缓了第三代杂交水稻技术在生产制种中的应用。要突破传统方法的局限,必须利用基因工程手段。近年来,基因组编辑技术取得了突破性进展,尤其是以TALEN(Transcription activator-like effector nucleases)和CRISPR/Cas9(Clustered regularly interspaced short palindromic repeats and CRISPR associated)这两种高效的基因编辑技术的成熟和完善,已广泛应用于各种生物的基因组的定点突变。比如CN201410496037.8号和CN201510009526.0号专利报道了利用CRISPR/Cas9基因编辑系统定点突变控制水稻光温敏不育性状的tms5基因和P-TMS12-1基因实现快速培育两系不育系目标的方法。目前尚没有采用CRISPR/Cas9基因工程手段快速培育普通核不育系的方法。
技术实现要素:
本发明要解决的技术问题是克服现有技术的不足,提供一种利用基因组编辑技术定点突变普通核不育基因获得普通核不育系的方法,通过彻底失活普通核不育基因,实现快速培育普通核不育系的目标,育种周期短、成本低且实用性强,将为推进第三代杂交水稻的广泛应用具有重要意义。
为此,本发明提供了一种培育水稻普通核不育系的方法,包括以下步骤:
S1、利用CRISPR/Cas9系统,根据水稻普通核不育基因设计靶位点序列;
S2、构建含所述靶位点序列片段的pCRISPR/Cas9重组载体;
S3、将所获得的pCRISPR/Cas9重组载体导入保持系的胚性愈伤组织中得到转基因苗;
S4、筛选所述转基因苗中的转基因阳性植株;
S5、筛选所述转基因阳性植株中的突变植株;
S6、将所述突变植株进行繁种,于后代植株中分离不含转基因成分的普通核不育系。
上述的方法,优选的,所述步骤S1中设计的靶位点序列的一条链具有以下结构中的一种:5’-(N)n-NGG-3’、5’-(N)n-NAG-3’、5’-(N)n-NGA-3’,所述N表示A,T,C和G中的任意一个,14≤n≤30。
上述的方法,优选的,所述普通核不育基因为msp1、pair1、pair2、zep1、mel1、pss1、tdr、udt1、gamyb4、ptc1、api5、wda1、cyp704B2、dpw、mads3、osc6、rip1、csa和aid1中的一种。
上述的方法,优选的,所述普通核不育基因为ptc1,所述靶位点序列包括PTC1-Target1和PTC1-Target2,所述PTC1-Target1的DNA序列为SEQ ID NO.1所示的序列,所述PTC1-Target1的DNA序列为SEQ ID NO.2所示的序列。
上述的方法,优选的,所述步骤S2具体包括以下步骤:
S2-1、根据靶位点序列以及酶切位点信息,设计带粘性末端的接头引物;
S2-2、酶切原始载体;
S2-3、将所述带粘性末端的接头引物退火后连接到酶切过的原始载体上,得到重组的gRNA表达盒;
S2-4、将所述重组gRNA表达盒进行PCR扩增得到扩增产物;
S2-5、酶切扩增产物,将酶切后的扩增产物连接到酶切过的pCRISPR/Cas9载体上得到重组载体。
上述的方法,优选的,所述步骤S2-1中所述接头引物包括PTC1-Target1-F、PTC1-Target1-R、PTC1-Target2-F和PTC1-Target2-R;所述PTC1-Target1-F的DNA序列为SEQ ID NO.3所示的序列,所述PTC1-Target1-R的DNA序列为SEQ ID NO.4所示的序列,所述PTC1-Target2-F的DNA序列为SEQ ID NO.5所示的序列;所述PTC1-Target2-R的DNA序列为SEQ ID NO.6所示的序列。
上述的方法,优选的,所述原始载体为pU3-gRNA或pU6a-gRNA。
上述的方法,优选的,所述步骤S2-2中采用BsaI酶切所述原始载体;所述步骤S2-3中,所述带粘性末端的接头引物位于所述表达载体的两个Bsa I酶切位点之间,形成重组的gRNA表达盒;所述步骤S2-5中,采用BsaI酶切所述扩增产物。
上述的方法,优选的,所述步骤S5步骤具体为:提取所述转基因阳性植株的DNA,进行PCR扩增得到扩增产物;对所述扩增产物进行测序,选择任一靶位点发生功能缺失突变的T0代纯合突变体作为突变植株。
上述的方法,优选的,所述步骤S6具体为:将突变植株与保持系回交,于后代植株中分离不含转基因成分的普通核不育系。
与现有技术相比,本发明的优点在于:
(1)本发明提供了一种基于CRISPR/Cas9系统靶向突变普通核不育基因获得普通核不育系的方法,培育出的普通核不育系不含转基因成分,与物理化学诱变方法和回交选育方法获得的普通核不育系没有本质区别,规避了转基因带来的潜在风险。
(2)本发明提供了一种水稻普通核不育系的方法,实现了快速培育普通核不育系,比物理化学诱变方法效率高,基因组损伤小;比传统的回交选育方法节省时间(传统的回交选育方法一般需要4~6年,而本发明提供的水稻普通核不育系的方法仅需两年),并且能克服传统的回交选育导致原有的一些优良性状丢失和利用工程保持系所繁育的普通核不育系株型不一致的缺点。
附图说明
为使本发明实施例的目的、技术方案和优点更加清楚,下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。
图1为本发明培育普通核不育系的流程图。
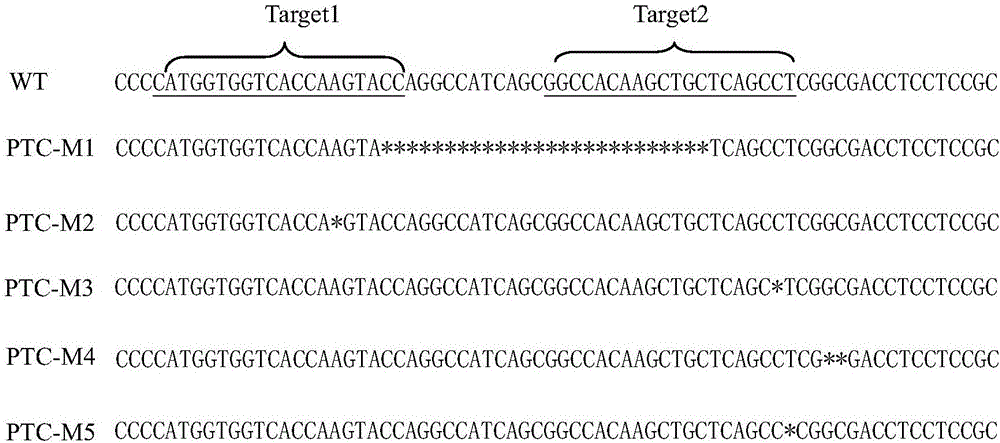
图2为五个阳性植株的突变类型,其中WT为野生型832B;PTC-M1至PTC-M5为5个阳性植株。
图3为PT6-F/PT6-R引物对BC1F2群体中的单株进行PTC1基因分型的部分结果。
图4为杂合单株与普通核不育系单株颖花形态对比。其中杂合单株花药为浅黄色,内含正常的花粉,表现出可育性状;普通核不育系花药呈白色,内无正常的花粉,表现出不育性状。
图5为PCR检测潮霉素基因结果,杂合株含有潮霉素基因,因此含有转基因成份;普通核不育系不含潮霉素基因,因此不含转基因成份。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述,但并不因此而限制本发明的保护范围。
实施例
以下实施例中所采用的材料和仪器均为市售。
实施例1:
一种本发明的快速培育普通核不育系的方法,其应用的具体对象即为本实施例所述的由CRISPR/Cas9系统定点突变保持系832B中的PTC1基因(SEQ ID NO.7为PTC1基因的cDNA序列、SEQ ID NO.8为PTC1基因的qDNA序列)获得普通核不育系,具体包括以下步骤(工艺流程可参见图1):
(1)根据PTC1基因的外显子序列设计双靶位点:
PTC1-Target1(SEQ ID NO.1):CATGGTGGTCACCAAGTACC;
PTC1-Target2(SEQ ID NO.2):GGCCACAAGCTGCTCAGCCT。
两个位点分别位于PTC1基因编码区的886bp-905bp和917bp-936bp。
PTC1-Target1具有5’-(N)n-NGG-3’的结构;PTC1-Target2具有5’-(N)n-NGA-3’结构。
(2)含有PTC1-Target1、PTC1-Target2双靶点的CRISPR/Cas9重组载体(pCRISPR/Cas9-PTC1)的构建:
2.1根据靶位点序列合成两个靶位点互补配对的核苷酸单链:
PTC1-Target1-F(SEQ ID NO.3):ggcaCATGGTGGTCACCAAGTACC;
PTC1-Target1-R(SEQ ID NO.4):aaacGGTACTTGGTGACCACCATG;
PTC1-Target2-F(SEQ ID NO.5):gccGGCCACAAGCTGCTCAGCCT;
PTC1-Target2-R(SEQ ID NO.6):aaacAGGCTGAGCAGCTTGTGGC。
2.2构建CRISPR/Cas9-PTC1重组载体:
2.2.1将步骤2.1中互补配对的两条核苷酸单链等量混合后,经过90℃变性3min和20℃退火5min后形成具有粘性末端的双链接头。
2.2.2酶切环状pU3-gRNA、pU6a-gRNA载体,获得线性化pU3-gRNA、pU6a-gRNA载体:在20μL反应体系中用10U BsaI酶切pU3-gRNA、pU6a-gRNA载体20min,在70℃下放置5min使酶失活,得到线性化的pU3-gRNA、pU6agRNA载体。
2.2.3将步骤2.2.1中得到的具有粘性末端的双链接头与线性化的pU3-gRNA、pU6a-gRNA载体连接。连接步骤为:取1μl 10x T4 DNA ligase buffer,0.5μl pU3-gRNA/pU6a-gRNA载体(12ng),1μl PTC1-Target1/PTC1-Target1,1μl T4 DNA ligase,最后加ddH2O至总体积10μl,在20℃~25℃下连接30min,得到重组的guide-RNA表达盒中间载体:pU3-PTC1-Target1-gRNA、pU6a-PTC1-Target2-gRNA。
2.2.4 PCR扩增表达盒:用引物U3-F和U3-R扩增步骤2.2.3中得到的pU3-PTC1-Target1-gRNA;用引物U6a-F和U6a-R扩增步骤2.2.3中得到的pU6a-PTC1-Target2-gRNA。其中引物的序列分别为:
U3-F:TTCAGAGGTCTCTCTCGCACTGGAATCGGCAGCAAAGG;
U3-R:AGCGTGGGTCTCGTCAGGGTCCATCCACTCCAAGCTC;
U6a-F:TTCAGAGGTCTCTCTGACACTGGAATCGGCAGCAAAGG;
U6a-R:AGCGTGGGTCTCGACCGGGTCCATCCACTCCAAGCTC;
反应体系为:1μl pU3-PTC1-Target1-gRNA/pU6a-PTC1-Target2-gRNA载体,引物各1.5μl,10μl dNTP,25μl 2xbuffer,1μlKOD酶,加ddH2O至总体积50μL。
反应程序为:95℃预变性3min,35个循环:95℃变性10s,60℃退火15s,68℃延伸20s。
扩增获得的PTC1-Target1-gRNA和PTC1-Target2-gRNA用PCR纯化试剂盒纯化。
2.2.5将PTC1-Target1-gRNA和PTC1-Target2-gRNA连接到pCRISPR/Cas9载体上构建成pCRISPR/Cas9-PTC1重组载体。具体构建方法:1μlPTC1-Target1-gRNA和1μl PTC1-Target2-gRNA,1μLpCRISPR/Cas9载体,1μL BsaI,1.5μL 10xSmart Buffer,1.5μL ATP(1mM),1μL T4 DNA ligase,最后加ddH2O至总体积15μL。
将上述反应体系在PCR上进行反应,反应程序为37℃5min、10℃5min、20℃5min。
(3)采用农杆菌介导的技术将pCRISPR/Cas9-PTC1重组载体整合到保持系832B的胚性愈伤组织并通过愈伤的分化获得16株T0代转基因植株。具体步骤如下:
3.1构建好的pCRISPR/Cas9-PTC1重组载体导入农杆菌种EHA105得到含有pCRISPR/Cas9-PTC1重组载体的EHA105;用832B的成熟种子在诱导培养基上诱导愈伤组织得到水稻愈伤组织。
3.2将含有pCRISPR/Cas9-PTC1重组载体的EHA105接种于YM琼脂培养基28℃培养2天得到培养液。
3.3将收集到的培养液加入到含有100mol/L的乙酰丁香酮的NB液体培养基中,得到OD600为0.5的菌液。
3.4将步骤3.1获得水稻愈伤组织浸泡在步骤3.3的菌液中30min,用无菌水冲洗3次,干燥后,将水稻愈伤组织转移到NB培养基上28℃暗培养3天。然后转移水稻愈伤组织至含有50mg/L潮霉素的培养基上,放置于28℃暗培养,每15天继代一次,继代2次。抗性筛选后,转入到再生培养基,共分化出16株转基因苗。经潮霉素PCR检测,获得5株转基因阳性植株。
(4)突变位点的鉴定:
4.1提取5株阳性植株的DNA。
4.2根据两个靶位点的位置设计检测引物:
PT6-F:CCTCCGACATGATGCCCCGGTAGTCCAT和
PT6-R:GAGCTCCCCATGGTGGTCACCAAGTACCAG。
4.3使PT6-F在靶位点PTC1-Target1的上游,PT6-R在靶位点PTC1-Target2的下游。以5株阳性株DNA为模板,以PT6-F和PT6-R为引物进行PCR扩增得到PCR扩增产物。PCR扩增的反应体系为:5μl PCR Mix,PT6-F和PT6-R各0.2μl,1μl模板,ddH2O补足至10μl。反应程序为:95℃预变性3min,35个循环:94℃变性10s,60℃退火30s,72℃延伸30s。
4.4将PCR扩增产物送测序公司测序。测序结果参见图2,*表示碱基缺失。从图2中显示5个阳性植株中有两个为纯合突变株系,T0代表现出不育性状,分别命名为PTC-M1和PTC-M2。PTC-M1在两个靶位点之间缺失26碱基,PTC-M2在PTC1-Target1靶位点处缺失1个碱基A;其他三个为杂合可育突变植株,分别命名为PTC-M3、PTC-M4、PTC-M5;PTC-M3在PTC1-Target2靶位点附近缺失了一个碱基C;PTC-M4在PTC1-Target2靶位点附近缺失了两个碱基GC;PTC-M5在PTC1-Target2靶位点附近缺失了一个碱基T。
(5)在两个为纯合突变株系中选择PTC-M1株系与832B回交1代获得BC1F1后代;将BC1F1后代自交1代后获得378株BC1F2后代。由于PTC-M1株系的PTC1基因缺失了26个碱基,因此用PT6-F和PT6-R引物扩增832B和PTC-M1株系的DNA时,两者PCR产物条带大小会相差26个碱基,而杂合单株的PCR产物则会出现大小相差26个碱基的两条带。故可以根据PT6-F和PT6-R引物扩增条带的大小和数目对回交后代的PTC1基因进行基因分型,通过基因分型鉴定回交后代中的不育株、杂合株和可育株。
具体步骤为:
5.1以832B(PCR产物电泳条带较大)和不育突变株PTC-M1(PCR产物电泳条带较小)为对照,用PT6-F和PT6-R引物分别扩增378株BC1F2后代的DNA,扩增产物进行聚丙烯酰胺凝胶电泳,根据电泳条带的大小和数目,鉴定出不育单株、杂合可育单株、纯合可育单株。结果参见图3:M为50bp marker;P1为832B带型,为纯合可育的野生型;P2为PTC-M1带型,为纯合不育的突变带型,双带为可育杂合型。因此,1-24号单株中,1、2、6、7、15、16为可育单株,8、9、10、11、14、18、21、22、23、24为突变的不育单株,其他双带的为杂合可育株。
利用上述方法,从378株BC1F2后代中鉴定出不育单株89株,杂合可育株183株,纯合可育株106。
抽穗扬花期进行田间育性性状调查,图4中杂合单株与普通核不育系单株颖花形态,其中杂合单株花药为浅黄色,内含正常的花粉,表现出可育性状;普通核不育系花药呈白色,内无正常的花粉,表现出不育性状。育性调查结果与上述基因分型结果完全一致。
对89株不育单株进行潮霉素基因PCR检测,图5中PCR检测潮霉素基因,杂合株含有潮霉素基因,因此含有转基因成份;普通核不育系不含潮霉素基因,因此不含转基因成份。结果从89株不育单株中筛选出2株不含转基因成分的普通核不育系。
潮霉素基因PCR检测引物为HPT-F:GACGTCTGTCGAGAAGTTTC和HPT-R:GCTGTTATGCGGCCATTGTC,反应程序为:95℃预变性3min,35个循环:95℃变性10s,58℃退火15s,72℃延伸30s。
以上所述,仅是本发明的较佳实施例而已,并非对本发明作任何形式上的限制。虽然本发明已以较佳实施例揭示如上,然而并非用以限定本发明。任何熟悉本领域的技术人员,在不脱离本发明的精神实质和技术方案的情况下,都可利用上述揭示的方法和技术内容对本发明技术方案做出许多可能的变动和修饰,或修改为等同变化的等效实施例。因此,凡是未脱离本发明技术方案的内容,依据本发明的技术实质对以上实施例所做的任何简单修改、等同替换、等效变化及修饰,均仍属于本发明技术方案保护的范围内。
SEQUENCE LISTING
<110> 湖南杂交水稻研究中心
<120> 一种培育水稻普通核不育系的方法
<130> 无
<160> 8
<170> PatentIn version 3.5
<210> 1
<211> 20
<212> DNA
<213> 人工序列
<400> 1
catggtggtc accaagtacc 20
<210> 2
<211> 20
<212> DNA
<213> 人工序列
<400> 2
ggccacaagc tgctcagcct 20
<210> 3
<211> 24
<212> DNA
<213> 人工序列
<400> 3
ggcacatggt ggtcaccaag tacc 24
<210> 4
<211> 24
<212> DNA
<213> 人工序列
<400> 4
aaacggtact tggtgaccac catg 24
<210> 5
<211> 23
<212> DNA
<213> 人工序列
<400> 5
gccggccaca agctgctcag cct 23
<210> 6
<211> 23
<212> DNA
<213> 人工序列
<400> 6
aaacaggctg agcagcttgt ggc 23
<210> 7
<211> 2232
<212> DNA
<213> 水稻
<400> 7
cgttgattgg cagcaactag ctagctcgcc gtccggccgg ccggccatgg cgcctaagat 60
ggtgatcagc ctggggagct cgcggcggcg gaagcgcggc gagatgctgt tccggttcga 120
ggccttctgc cagcccggct acccggcgaa cttcgccggc gccggcggct tcagggacaa 180
cgtgaggacg ctgctcggct tcgcgcacct ggaggccggc gtccacggcg agaccaagtg 240
ctggtcgttc cagctcgagc tgcaccgcca cccccccacc gtcgtgaggc tcttcgtcgt 300
cgaggaggag gtcgccgcct cgccgcaccg ccagtgccac ctctgccgcc atattgggtg 360
ggggaggcat ctgatatgca gcaagaggta tcacttcttg ctgccgagga gggaatcggc 420
ggcggaagcc gacggcctgt gcttcgcgat caaccacggc ggcggcggtg gcgcggagaa 480
agcgtcgtcg aaagggacga cgacgacggc ctccagcaga ggccacctgc tacacggcgt 540
cgtgcacctc aacggctacg gccacctcgt cgccctccac ggcctcgagg gcggctccga 600
cttcgtctcc ggccaccaga tcatggacct ctgggaccgc atttgctcag ccttgcacgt 660
aaggacggtg agcctggtgg acacggcgag gaagggccac atggagctga ggctgctgca 720
cggcgtcgcg tacggcgaga cgtggttcgg gcggtggggg tacaggtacg gccggccgag 780
ctacggcgtc gcgctgccgt cgtaccggca gtcgctgcac gtgctcggct ccatgccgct 840
ctgcgtgctg gtgccgcacc tgtcgtgctt cagccaggag ctccccatgg tggtcaccaa 900
gtaccaggcc atcagcggcc acaagctgct cagcctcggc gacctcctcc gcttcatgct 960
cgagctgcgc gcccgcctgc cggccacctc cgtcacggcc atggactacc ggggcatcat 1020
gtcggaggcc tcgtgccggt ggtcggcgaa gcgcgtcgac atggcggcgc gcgccgtcgt 1080
ggacgcgctc cgccgcgccg agccggcggc gcggtgggtc acgcggcagg aggtgcgcga 1140
cgcggcgcgc gcctacatcg gcgacacggg cctcctcgac ttcgtgctca agtccctcgg 1200
caaccacatc gtcggcaact acgtcgtgcg ccgcaccatg aacccggtga ccaaggtgct 1260
cgagtactgc ctcgaggacg tctccagcgt gctcccggcg gtcgccgccg gcggcggcgt 1320
gccggcgcag ggcaagatga gggtgaggtt ccagctcacg cgtgcgcagc tcatgaggga 1380
cctggtgcac ctgtaccggc acgtgctcaa ggagcccagc caggcgctca ccggcggcgc 1440
gttcggcgcg atcccggtgg cggtgcggat ggtcctggac atcaagcact tcgtcaaaga 1500
ttaccacgaa ggacaagccg cggcgagcag caatggcggt ggcggattcg ggcatcccca 1560
catcaacctg tgctgcacgc tgctcgtgag caacgggagc ccggagctag ctccaccgta 1620
cgagacggtg accctgccgg cgcacgcgac ggtgggcgag ctgaagtggg aggcgcagag 1680
ggtgttcagc gagatgtacc tcggcctgag gagcttcgcg gcggactccg tcgtcggggt 1740
cggcgccgac caggagggcc tcccggtgct cgggctggtc gacgtcggaa gcgccgtcgt 1800
ggtgcaaggg agcgtgggcg agcagataaa cggggaggac cacgagagga aggaggaggc 1860
ggcggcggcg gccgtgtgcg aggggagcgg cggcggcgag cgcgtcgtgg actgcgcgtg 1920
cggcgcggtg gacgacgacg gcgagcgcat ggcgtgctgc gacatctgcg aggcgtggca 1980
gcacacgcgg tgcgccggga tcgcggacac cgaggacgcg ccgcacgtct tcctctgcag 2040
ccggtgcgac aacgacgtcg tgtcgttccc gtccttcaac tgttagatgt gatgctgctg 2100
ctgctactgc tactactact gcctctgctg ctatatatga tgctacctag tacaagtgat 2160
cgagaattca atttgttttc tcggcaaaac caaaatgaaa acgaaggtaa aaccaagtga 2220
acttcagatc aa 2232
<210> 8
<211> 2407
<212> DNA
<213> 水稻
<400> 8
cgttgattgg cagcaactag ctagctcgcc gtccggccgg ccggccatgg cgcctaagat 60
ggtgatcagc ctggggagct cgcggcggcg gaagcgcggc gagatgctgt tccggttcga 120
ggccttctgc cagcccggct acccggcgaa cttcgccggc gccggcggct tcagggacaa 180
cgtgaggacg ctgctcggct tcgcgcacct ggaggccggc gtccacggcg agaccaagtg 240
ctggtcgttc cagctcgagc tgcaccgcca cccccccacc gtcgtgaggc tcttcgtcgt 300
cgaggaggag gtcgccgcct cgccgcaccg ccagtgccac ctctgccgcc atattggtcc 360
gtcgaacaaa ctacaattaa tcaatcaacc tttacatagg attgatccga tcgatgccat 420
ggtgttgtag ggtgggggag gcatctgata tgcagcaaga ggtatcactt cttgctgccg 480
aggagggaat cggcggcgga agccgacggc ctgtgcttcg cgatcaacca cggcggcggc 540
ggtggcgcgg agaaagcgtc gtcgaaaggg acgacgacga cggcctccag cagaggccac 600
ctgctacacg gcgtcgtgca cctcaacggc tacggccacc tcgtcgccct ccacggcctc 660
gagggcggct ccgacttcgt ctccggccac cagatcatgg acctctggga ccgcatttgc 720
tcagccttgc acgtaaggta gtagtagtat acatgtgcgt gtgcatgcat gcaagcaatg 780
caacgatgtc gggctgcgtg tgagaacatt tgcttgggca tggtgtggtg tatgcaagga 840
cggtgagcct ggtggacacg gcgaggaagg gccacatgga gctgaggctg ctgcacggcg 900
tcgcgtacgg cgagacgtgg ttcgggcggt gggggtacag gtacggccgg ccgagctacg 960
gcgtcgcgct gccgtcgtac cggcagtcgc tgcacgtgct cggctccatg ccgctctgcg 1020
tgctggtgcc gcacctgtcg tgcttcagcc aggagctccc catggtggtc accaagtacc 1080
aggccatcag cggccacaag ctgctcagcc tcggcgacct cctccgcttc atgctcgagc 1140
tgcgcgcccg cctgccggcc acctccgtca cggccatgga ctaccggggc atcatgtcgg 1200
aggcctcgtg ccggtggtcg gcgaagcgcg tcgacatggc ggcgcgcgcc gtcgtggacg 1260
cgctccgccg cgccgagccg gcggcgcggt gggtcacgcg gcaggaggtg cgcgacgcgg 1320
cgcgcgccta catcggcgac acgggcctcc tcgacttcgt gctcaagtcc ctcggcaacc 1380
acatcgtcgg caactacgtc gtgcgccgca ccatgaaccc ggtgaccaag gtgctcgagt 1440
actgcctcga ggacgtctcc agcgtgctcc cggcggtcgc cgccggcggc ggcgtgccgg 1500
cgcagggcaa gatgagggtg aggttccagc tcacgcgtgc gcagctcatg agggacctgg 1560
tgcacctgta ccggcacgtg ctcaaggagc ccagccaggc gctcaccggc ggcgcgttcg 1620
gcgcgatccc ggtggcggtg cggatggtcc tggacatcaa gcacttcgtc aaagattacc 1680
acgaaggaca agccgcggcg agcagcaatg gcggtggcgg attcgggcat ccccacatca 1740
acctgtgctg cacgctgctc gtgagcaacg ggagcccgga gctagctcca ccgtacgaga 1800
cggtgaccct gccggcgcac gcgacggtgg gcgagctgaa gtgggaggcg cagagggtgt 1860
tcagcgagat gtacctcggc ctgaggagct tcgcggcgga ctccgtcgtc ggggtcggcg 1920
ccgaccagga gggcctcccg gtgctcgggc tggtcgacgt cggaagcgcc gtcgtggtgc 1980
aagggagcgt gggcgagcag ataaacgggg aggaccacga gaggaaggag gaggcggcgg 2040
cggcggccgt gtgcgagggg agcggcggcg gcgagcgcgt cgtggactgc gcgtgcggcg 2100
cggtggacga cgacggcgag cgcatggcgt gctgcgacat ctgcgaggcg tggcagcaca 2160
cgcggtgcgc cgggatcgcg gacaccgagg acgcgccgca cgtcttcctc tgcagccggt 2220
gcgacaacga cgtcgtgtcg ttcccgtcct tcaactgtta gatgtgatgc tgctgctgct 2280
actgctacta ctactgcctc tgctgctata tatgatgcta cctagtacaa gtgatcgaga 2340
attcaatttg ttttctcggc aaaaccaaaa tgaaaacgaa ggtaaaacca agtgaacttc 2400
agatcaa 2407
- 还没有人留言评论。精彩留言会获得点赞!