一种大麦钙调蛋白基因HvCAM1及其耐盐应用的制作方法
本发明属于生物基因工程技术领域,特别涉及一种大麦钙调蛋白基因hvcam1及其耐盐应用。
背景技术:
盐胁迫是全球限制作物生长与生产的最主要非生物胁迫之一。在长期适应盐胁迫的过程中,植物通过感应外界刺激,产生并转导相应的逆境信号,从而启动多种防御机制应对盐胁迫的为害。植物的耐盐性是一个复杂的数量性状,尽管人们在耐盐相关基因的解析上取得了很大进步,但其相关下游基因的信号转导与调控机理尚不明确(ligabaandkatsuhara,2010,jplantres.123:105-118)。
ca2+通常被认为是植物响应多种环境刺激下信号转导中的第二信使,它广泛参与植物的生长与发育过程,并能迅速对外界刺激产生反应。目前,可直接结合ca2+的受体蛋白有四类:钙调蛋白(calmodulin,cams),类钙调蛋白(calmodulin-likeproteins,cmls),钙调磷酸酶(calcinneurinb-likeproteins,cbps或cbls),钙依赖性蛋白激酶(calcium-dependentproteinkinase,cdpks)(zhuetal,2015,trendsplantsci.20(8):483-9)。
钙调蛋白(cam)是ca2+信号的主要转化器,能将ca2+信号转换到特定的下游反应,在植物对生物和非生物胁迫的响应及其正常的生长发育过程中起到重要的调控作用(reddyetal,2011,plantcell.23:2010-2032;galonetal,2010,molplant.3(4):653-669)。在结构上,植物中的cam都具有ef-hand,可直接与胞内快速增加的ca2+结合,改变构象,并通过磷酸化等作用于下游的蛋白激酶或转录因子,进而调控基因的行为(reddyetal,2011,plantcell.23:2010-2032)。现有研究指出,拟南芥中发现7个cam家族成员,水稻5个(zhuetal,2015,trendsplantsci.20(8):483-9)。现如今一些cam家族的基因功能已被证实,例如拟南芥atcam3被证实参与热激信号的转导过程,而同一家族的atcam1和atcam2则不响应热胁迫(zhangetal,2009,plantphysiol.149(4):1773-1784)。
大麦(hordeumvulgare)是全球普遍栽培的第四大禾谷类作物,其适应性广,抗逆性强,已成为理想的禾谷类作物遗传机理研究的模式材料。大麦在禾谷类作物中耐盐性最强,但是,当前尚无大麦cam的相关报道。因此从大麦中发掘优异的耐盐相关基因,如cam家族成员,对改良和提高作物的耐盐性具有重要意义。
技术实现要素:
本发明的目的在于提供一种大麦钙调蛋白基因hvcam1,该基因参与大麦的盐胁迫响应。
本发明解决其技术问题所采用的技术方案是:
一种大麦钙调蛋白基因hvcam1,该基因的核苷酸序列如seqidno:1所示,全长基因组序列2124bp。本发明首先克隆得到一个大麦的钙调蛋白编码基因,命名为hvcam1,其转录本cdna全长核苷酸序列为seqidno:2所示,全长cdna序列728bp。
一种所述的基因编码的大麦cam1蛋白,该蛋白的氨基酸序列如seqidno:3所示。
一种所述的hvcam1基因启动子,该启动子的核苷酸序列如seqidno:4所示。该启动子为3kb,用于引导该基因在植物细胞中大量表达,以满足快速合成钙调蛋白和响应各种刺激或胁迫所需。
一种pbract214:hvcam1过表达重组载体,该重组载体是由seqidno:2所示的编码基因hvcam1的cdna全长序列中编码区域的450bp基因片段连入pbract214载体attr1和attr2位点间构建得到。
一种panda:hvcam1干涉重组载体,该重组载体是由seqidno:2所示的编码基因hvcam1包含5’-utr和编码区域的388bp基因片段连入panda载体的attr1和attr2位点间构建得到。
一种大麦钙调蛋白基因hvcam1在提高大麦耐盐性中的应用。该基因参与大麦耐盐性的调控,抑制该基因的表达可提高大麦的耐盐性,过表达该基因则对耐盐性贡献不大。作为优选,所述大麦品种为大麦栽培品种goldenpromise。
本发明从大麦中克隆了该基因的基因组dna序列,如seqno:1所示,同时克隆了hvcam1基因的cdna全长序列如seqno:2所示,该基因编码的氨基酸序列如seqno:3所示。
本发明还利用rnai干涉的方法在大麦goldenpromise中成功沉默了hvcam1基因,并利用该材料证实了盐胁迫下hvcam1基因的负调控作用可以有效地增强大麦的耐盐性;与此同时,在大麦goldenpromise中过表达hvcam1基因,并不能增强大麦的耐盐性。
本发明的有益效果是:
1.本发明首次克隆和分析了大麦中响应盐胁迫的钙调蛋白基因hvcam1,公布了该基因的核苷酸序列、氨基酸序列和启动子序列,对阐明大麦耐盐调控的分子机理和耐盐材料的培育具有重要意义。
2.本发明首次通过转基因手段,证实了hvcam1基因参与大麦耐盐性。其中干涉hvcam1基因后可显著增强大麦的耐盐性,有效缓减盐胁迫带来的不利影响,从而维持植株的正常生长。
3.本发明指出钙调蛋白家族在植物中还存在多种分型,如能得到充分发掘和有效利用,将有利于改良大麦品种的耐盐性,同时亦可提高其他作物的抗逆性。
附图说明
图1是hvcam1基因结构图,数字表示碱基位点,白框表示外显子,黑框表示非编码区域;
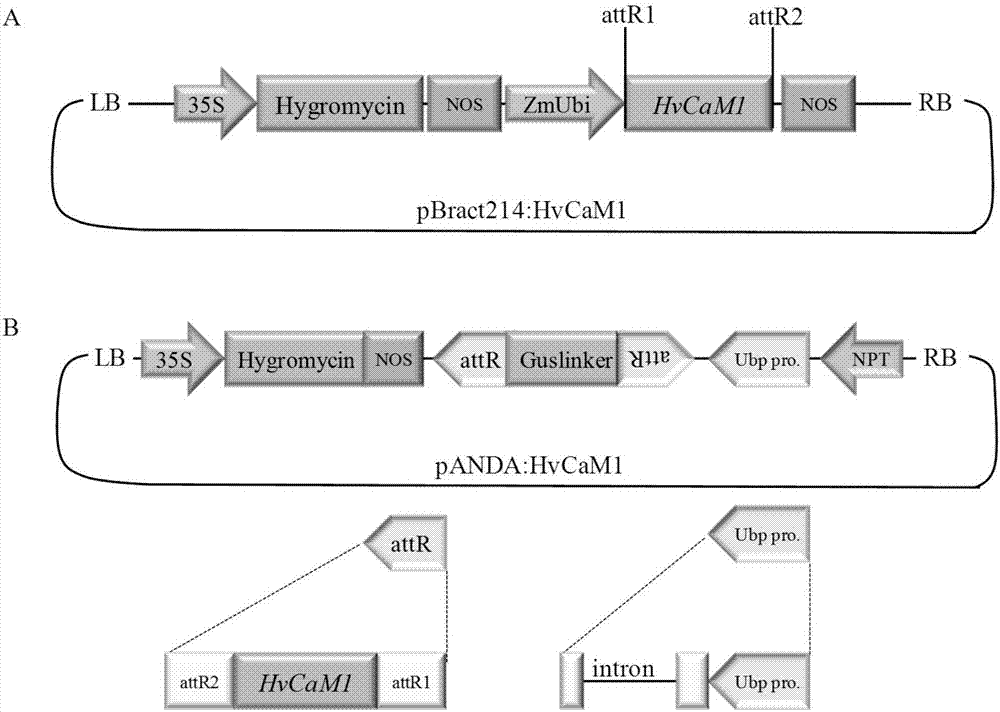
图2是载体构建示意图,其中:a表示过表达载体构建图,35s启动子驱动抗性基因潮霉素(hygromycin),玉米ubi启动子(zmubi)驱动hvcam1基因,attr1和attr2是gateway方法中lr反应交换位置,nos表示终止子;b表示干涉载体构建图,35s启动子驱动抗性基因潮霉素(hygromycin),玉米ubi启动子(ubipro.)驱动hvcam1基因部分序列和guslinker片段,其中attr(含attr1和attr2)是gateway方法中lr反应交换位置,nos表示终止子,npt表示卡那霉素抗性基因;
图3是转基因材料水培实验结果,其中(a)是pcr产物琼脂糖凝胶电泳图,m表示dnamarkerdl2000(takara,日本),pr是pbract214:hvcam1或panda:hvcam1载体扩增片段,r1/2/3是干涉转基因植株的3个株系,oe73/15/74是过表达转基因植株的3个株系,oe表示分别用过表达转基因3个株系用干涉引物扩增无片段,rnai表示分别用干涉转基因3个株系用过表达引物扩增无片段;(b)是qrt-pcr结果,其中干涉(rnai)植株中hvcam1的表达量下调40~50%,过表达(oe)植株中该基因表达量上调1~2倍;(c)在盐处理(200mmnacl)三周以后的干涉和过表达转基因植株表型差异图,wt:野生型,wtoe:转基因阴性植株;(d)地上部和(e)地下部的鲜重测量结果,单位:g;
图4是转基因材料土培实验结果对比图,处理6周,对照组(control)和盐处理组(salinity)中干涉材料和野生型的耐盐性差异。wt:野生型,r1:干涉转基因材料其中一个株系r1。
具体实施方式
下面通过具体实施例,对本发明的技术方案作进一步的具体说明。应当理解,本发明的实施并不局限于下面的实施例,对本发明所做的任何形式上的变通和/或改变都将落入本发明保护范围。
在本发明中,若非特指,所有的份、百分比均为重量单位,所采用的设备和原料等均可从市场购得或是本领域常用的。下述实施例中的方法,如无特别说明,均为本领域的常规方法。
全式金hifi高保真酶,购自北京全式金生物技术(transgenbiotech)有限公司;
t载体,购自北京全式金生物技术(transgenbiotech)有限公司;
农杆菌agl1,购自上海唯地生物(shanghaiweidibiotech)有限公司。
pbract214载体由英国格拉斯哥大学peterdominy博士提供,panda载体由日本奈良先端科学技术大学hiroyukitsuji博士提供。
实施例1大麦钙调蛋白hvcam1基因和启动子克隆
1、植物材料的处理
大麦goldenpromise种子用2%h2o2消毒20min后,用ddh2o冲洗5次后,种子腹面朝上在发芽盒中发芽。于培养室(14h/10h,22℃/18℃)暗培养3天,至地上部露白2cm后补光。取7日苗龄的大麦幼苗,液氮速冻后保存于-70℃,用于dna和总rna提取。
2、大麦基因组dna的提取
采用ctab法提取大麦基因组dna。
3、大麦总rna的提取
采用trizol法提取大麦总rna。并用dnasei酶(takara,日本)去除基因组dna。
4、cdna的合成
使用takara公司的
5、hvcam1基因、启动子等的克隆
以上述步骤2中的dna和4中的cdna为模板,根据目的基因的orf框分别设计引物,选用全式金hifi高保真酶分别进行pcr扩增:
pcr体系(25μl):
pcr程序:
获得特异性的目的条带,切胶回收后将片段连入t载体(全式金),转化大肠杆菌dh5α,pcr验证得到阳性克隆,然后送公司进行测序。引物合成和测序均由上海生工生物工程股份有限公司完成。
所涉及的引物和序列信息见核苷酸序列表,其中:
以dna为模板,dna-f/r扩增的全长基因组序列2124bp,为seqidno:1所示,引物信息为:
dna-f:5’-atcattccccaccaccgagc-3’,(seqidno:5)
dna-r:5’-atcattccccaccaccgagc-3’;(seqidno:6)
以cdna为模板,cdna-f/r为引物扩增全长cdna序列728bp,为seqidno:2所示,引物信息为:
cdna-f:5’-gatcattccccaccaccgag-3’,(seqidno:7)
cdna-r:5’-tccaatgttgctccacacga-3’;(seqidno:8)
以dna为模板,promoter-f/r扩增的启动子序列3050bp,为seqidno:4所示,引物信息为:
promoter-f:5’-cgtcgaactaggactgattg-3’,(seqidno:9)
promoter-r:5’-gagaaggtgcgcacgagac-3’;(seqidno:10)
通过bioxm2.6将hvcam1基因的cds核苷酸序列翻译成氨基酸序列149aa,为seqidno:3所示。
通过对基因结构进行分析,发现该基因存在两个外显子和一个内含子,基因结构图见附图1。
实施例2rnai和过表达转基因方法验证hvcam1基因功能
1、pbract214:hvcam1过表达载体的构建
采用gateway的方法(invitrogen,美国),首先以上述实施例1中的含cdna的阳性t载体为模板,设计oe-hvcam1-f/r引物扩增长度为覆盖hvcam1编码区域的450bp片段,引物信息为:
oe-hvcam1-f:5’-atggcggaccagctcacc-3’,(seqidno:11)
oe-hvcam1-r:5’-tcacttggccatcatgacc-3’。(seqidno:12)
经两轮pcr扩增,使用
2、panda:hvcam1干涉载体的构建
与过表达载体构建方法相同,采用gateway的方法(invitrogen,美国),以上述实施例1中的含cdna的阳性t载体为模板,设计引物rnai-hvcam1-f/r扩增长度为覆盖hvcam1cdna全长序列中含5’-utr和cds区域388bp的片段,引物信息为:
rnai-hvcam1-f:5’-caccttctcgaagcttcctc-3’,(seqidno:13)
rnai-hvcam1-r:5’-ctcctcgtccgtcagcttctc-3’。(seqidno:14)
经两轮pcr扩增,在gatewaybp和lr反应后,最终获得panda:hvcam1干涉载体(见附图2b)。
3、转基因大麦植株的获得
采用热激法将上述步骤1和步骤2中构建好的表达载体,分别导入农杆菌agl1中。将含过表达载体和干涉载体的农杆菌依次转化大麦goldenpromise幼胚,经潮霉素筛选后,获得数十株转基因候选植株。再依次提取转基因候选植株和大麦goldenpromise野生型的dna,通过pcr的验证方法获得转基因阳性植株,其中过表达验证引物为pbr214-f/oecam1-r,扩增片段长度478bp,引物信息为:
pbr214-f:5’-gctcaccctgttgtttggtg-3’,(seqidno:15)
oecam1-r:5’-tcgtagttgatctggccgtc-3’。(seqidno:16)
干涉验证引物为guslink-r/rnai-hvcam1-r,扩增片段长度为510bp,引物信息为:
guslink-r:5’-gtcgtcggtgaacaggtatgg-3’,(seqidno:17)
rnai-hvcam1-r:5’-ctcctcgtccgtcagcttctc-3’。(seqidno:18)
繁种后,收获足够用于实验的转基因种子。
4、大麦hvcam1过表达和干涉转基因植株耐盐性的比较
(1)水培实验:依次选取大麦hvcam1过表达和干涉转基因材料各3份、大麦goldenpromise野生型1份、大麦hvcam1转基因阴性植株1份为材料。以上述材料发芽14天以后的幼苗为实验材料,每个基因型移入相同数量的幼苗至15l培养盒,分别设置含nacl浓度为0和200mm的营养液培养盒各2盆,作为正常条件和盐处理条件,每隔3天换一次nacl浓度相同的营养液。培养室条件为:光照强度为250μmm-2s-1,日夜温度为22/18℃,日夜时长14/10h。经3周盐处理以后,用去离子水清洗三遍,将实验材料表面的盐分去除,控干多余水分后,再对实验材料通过整体拍照、qrt-pcr、测地上部和地下部鲜重等操作。
水培实验结果表明被试材料的耐盐性强弱依次为:hvcam1干涉材料耐盐性最强,其余hvcam1过表达材料、野生型和hvcam1转基因阴性植株耐盐性较弱且无明显区别。经pcr(过表达验证引物为3中所述pbr214-f/oecam1-r,干涉验证引物为3中所述guslink-r/rnai-hvcam1-r)和qrt-pcr(引物为qhvcam1-f/r)验证,试验所用大麦转基因材料均为阳性植株(见附图3a),干涉(rnai)植株中hvcam1的表达量下调40~50%,过表达(oe)植株中该基因表达量上调1~2倍(见附图3b)。引物信息为:
qhvcam1-f:5’-catgatcaacgaggttgacg-3’,(seqidno:19)
qhvcam1-r:5’-gagatgaagccgttctggtc-3’。(seqidno:20)
在盐处理(200mmnacl)三周以后,干涉和过表达的转基因植株出现明显的表型差异(见附图3c)。干涉植株的耐盐性优于过表达植株,生长表现为:干涉植株地上部仅有1~2片老叶黄化,新叶生长放缓,侧生1~2个分蘖;而过表达植株地上部3~4片老叶发黄,新叶萎蔫,侧生0~1个分蘖。此外,野生型(wt)和转基因阴性植株(wtoe)的耐盐情况与过表达植株相似,但明显差于干涉转基因材料。地上部和地下部的鲜重也表明,干涉植株的耐盐性最强(见附图3d和3e)。
(2)土培实验:依次选取大麦hvcam1干涉转基因材料各3份、大麦goldenpromise野生型1份为材料。将野生型1株和各hvcam1干涉转基因材料1株同时播种于同一个含5l土样(9蛭石:1营养土)的培养盆中,培养室条件为:光照强度为250μmm-2s-1,日夜温度为22/18℃,日夜时长14/10h。待幼苗长至两叶一心期后,设置对照组和盐处理组,其中对照组浇自然水,盐处理组浇盐水(将氯化钠固体溶于自然水至nacl终浓度为400mm),每三天浇1l自然水或盐水,相同基因型和处理组各种3盆为重复。处理6周以后,盐处理组的干涉材料和野生型出现明显的耐盐性差异(见附图4)。干涉植株的耐盐性优于野生型,表现为处理组的干涉植株抽穗,新叶依旧生长,侧生11~12个分蘖;野生型枯萎,侧生8~9个分蘖,分蘖均表现出枯叶横生。与此同时,对照组的干涉材料和野生材料并无明显表型差异,生长良好,部分分蘖开始抽穗(见附图4)。水培实验和土培实验均表明,hvcam1干涉转基因植株的耐盐性明显优于野生型等其他材料。因此,可以通过抑制hvcam1基因在大麦植株中的表达,从而提高大麦的耐盐性。
以上所述的实施例只是本发明的一种较佳的方案,并非对本发明作任何形式上的限制,在不超出权利要求所记载的技术方案的前提下还有其它的变体及改型。所有涉及hvcam1基因的转录本、基因组和启动子的核苷酸序列,编码蛋白的氨基酸序列,以及含任一上诉基因的生物材料,均属于本发明的保护范畴。
序列表
<110>浙江大学
<120>一种大麦钙调蛋白基因hvcam1及其耐盐应用
<130>zjdx-sqf001
<160>20
<170>siposequencelisting1.0
<210>1
<211>2124
<212>dna
<213>大麦钙调蛋白基因hvcam1(hordeumvulgare)
<400>1
atcattccccaccaccgagcccggtttattcccccccttcgcgcagccgcccccgtgtct60
cgtgcgcaccttctcgaagcttcctccccccatggcggaccagctcaccgacgagcagat120
cgccgagttcaaggaggccttcagcctcttcgacaaggatggcgacggtaccccccctct180
ccccctccccccgctctcccgcggccggccggatcgtgctcgggcggcccccgatccggc240
cgaattgggtttttgtcccggagcgctgtggctagggctgtagatccgggcggccatgcc300
tgggctgtgtggtcgttttaggactttcgcgttgttctggccctgcgcgggatggatgct360
tgcatccggtgggatcgttcgtttgctctggctagctgtttgttctgtgcccgactgcag420
gccgtttgtcttgttgaggcgattcggttcatggctgtaggatttggggctgctcctgtg480
cgaggagcagcgactggctgcatttaggagctagggtttagagctgtcgagtgtttcgga540
atttgcagtgatacagatgcgaatcaggttgttcttcgtgtactaccacaaacaacaaag600
gttaaatgctctagcagggtagcacgagtagctcttaggcattcccgttgctggtagttg660
ggccagttgagggttctgtgtggtttttaatgatagggtcgaatgcaccaacggttggac720
ctgatggacaatttgatgcgttgatctggttgtgatctacagtactagtggctgcttgat780
gtcaaggattagtaaggattcggggttgcgattagctctcctttgtataacctgacactg840
aagagactttgtggttacagtatgatctagcttctgacagcgtataactcggagatctag900
tgttaaccgtctagtctaagaccaacatttgatttgtcgattcctcttttctagtagtgt960
caaagctcatttctgcaatatttaatactactctagttatttccttgcttggtagtagta1020
tgcatgatgacttgttgaattgtatgttgacttctgatttcatcatttgttaatgagcag1080
caagaactacatcattatttacttgatgggatacaacctgattaatgctaaaacctaagc1140
attgccttcttaaggcttctgcctgtacgcggtccatcatttcttcagatgatccataaa1200
ttgatttctagaattcagtatgttggaatgaacatcagtgacacattaggaatgcgtctg1260
gcaagttggacctatctttttgttccctcatgttaccctgtctggactataatatttaaa1320
ctgtactgcttatactgcaagacagacacatagtacttgtttagatccatgtttgtttaa1380
gaaccccgcccgttgcaacttgcagctccttgtggttacattatgtaagtggccaacatg1440
ctgattagtggtactatcattatgccatatcctgtgttgttaggacattaacaaagatag1500
tcccacattgcctaaacagaccaattcttaaatccatggtagttaacttattcttgtttt1560
atttcgtagtgctgaacaaatgcttatcgatatttgattttgtacaggttgcatcaccac1620
caaggagctcggaaccgtgatgcgatcccttgggcagaaccccacggaggcggagctgca1680
ggacatgatcaacgaggttgacgcggacggcaacggcaccatcgacttcccagagttcct1740
gaacctgatggcgaggaagatgaaggacacggactcggaggaggagctcaaggaggcctt1800
ccgcgtgttcgacaaggaccagaacggcttcatctcggctgcagagctgcgccatgtgat1860
gaccaacctcggggagaagctgacggacgaggaggtggacgagatgatccgggaggcgga1920
cgtggacggcgacggccagatcaactacgaggagttcgtcaaggtcatgatggccaagtg1980
aggggggcggggcgggccctcccacggaaaataagctttagtttgctctcaagtggattg2040
gaaatttggaaatgccagacagactcgaaagttgtattttgtgctgtgtgatcgtttttt2100
aagcactgttgggtagctggtggg2124
<210>2
<211>728
<212>dna
<213>大麦钙调蛋白转录本cdna(hordeumvulgare)
<400>2
gatcattccccaccaccgagcccggtttattcccccccttcgcgcagccgcccccgtgtc60
tcgtgcgcaccttctcgaagcttcctccccccatggcggaccagctcaccgacgagcaga120
tcgccgagttcaaggaggccttcagcctcttcgacaaggatggcgacggttgcatcacca180
ccaaggagctcggaaccgtgatgcgatcccttgggcagaaccccacggaggcggagctgc240
aggacatgatcaacgaggttgacgcggacggcaacggcaccatcgacttcccagagttcc300
tgaacctgatggcgaggaagatgaaggacacggactcggaggaggagctcaaggaggcct360
tccgcgtgttcgacaaggaccagaacggcttcatctcggctgcagagctgcgccatgtga420
tgaccaacctcggggagaagctgacggacgaggaggtggacgagatgatccgggaggcgg480
acgtggacggcgacggccagatcaactacgaggagttcgtcaaggtcatgatggccaagt540
gaggggggcggggcgggccctcccacggaaaataagctttagtttgctctcaagtggatt600
ggaaatttggaaatgccagacagactcgaaagttgtattttgtgctgtgtgatcgttttt660
taagcactgttgggtagctggtggggttatctctgtgtagcggtgtagtcgtgtggagca720
acattgga728
<210>3
<211>149
<212>prt
<213>大麦cam1蛋白(hordeumvulgare)
<400>3
metalaaspglnleuthraspgluglnilealagluphelysgluala
151015
pheserleupheasplysaspglyaspglycysilethrthrlysglu
202530
leuglythrvalmetargserleuglyglnasnprothrglualaglu
354045
leuglnaspmetileasngluvalaspalaaspglyasnglythrile
505560
asppheproglupheleuasnleumetalaarglysmetlysaspthr
65707580
aspsergluglugluleulysglualapheargvalpheasplysasp
859095
glnasnglypheileseralaalagluleuarghisvalmetthrasn
100105110
leuglyglulysleuthraspglugluvalaspglumetileargglu
115120125
alaaspvalaspglyaspglyglnileasntyrglugluphevallys
130135140
valmetmetalalys
145
<210>4
<211>3050
<212>dna
<213>hvcam1基因启动子(hordeumvulgare)
<400>4
cgtcgaactaggactgattgggggtgaataagagagtgtagcttgacaatgtacataagg60
ggagatcaggaaccatctgtttctctctctttctttctttctttctttcttgagtgaact120
cttcttgtggcatgaggtccgaacggtctgaactgaactccggtgaaatgaaacaagagg180
cagtgttgtgaaaatgtctggtcttgttttgtgatctgttgtgtcagacataaatctaat240
tgtgttgcatgtgctggaatatgttgctggtaggtgtgagccgttcagtaggatggacaa300
agttgagacgccaaggtgggggagacgtaggtaaaccaagacaccgaaaggaaggaattc360
catacaaatacgtatacatgtgatgtggatgctcgtacaaaaagagaccgacagacaggg420
aaggcgatagcgtctcgcgatcaccgggttggcagcgtttgtcaaaaggctcaacagcga480
cggggacggtggagctttaattccctggatgatcttatatgaaacctagacagagaggta540
aacctaccaatcatcttcccacgttatcgcacaaaacctcatctccttataattgtgata600
caattgtgagttgtgacgacggggaaagttgttttcttatctatgaacttgggggagagg660
gggaatttgaagctccaccccaacattgtatatacaaaaaaaaagagaggagatttctca720
gacagagacaaaaagggaaaagggtgggaacggatgatactttgctgttttttggtaata780
tagtagcagatgcttcgccgttctaacaagaaataaactgctttgcacaaagctctgatt840
ctcccaggcaatggtacaagacaaagccagatcatttatagaggcccgacaatattccct900
ctcttcattctctcagctctctgcaacggtttcgtgataagcccacgggccttttcgtcg960
cgagacgggaaaaaaaaatgcccatttccacatgcttgctgggctaacagggccggcccc1020
agcaaaacgcatcgctttcggctcgaaacagcgcgttgatagccacgtcgtcaggaagaa1080
aaagataacgacgacgacagcgtgttgaggtcagtcttgacctgagcttcttgcgtgtct1140
cctgtcctgtgtgcgatggaccgatgtctgatctgacggtgacggagcagtgacctggtc1200
catcgccttgactcgtccgcctctccttcctcccaacgcttgagataaacgactttgagg1260
aggaaaaacaacggaccgcaaggaattgatttatatcggacatcaagtctccctgcaaga1320
ggaaaaggaagatgtagaaacggagcagaaattgtttgaagaactgaaaacaaaaaataa1380
ctctggaccggagcaagctcgtatcgaattttcgagccgaacctcattgaatggacaaat1440
tatgtagtactggatattacctaatgcaagtagggttctgaatccactatcggcgacgaa1500
tccgtataatttttctttttgaattcatcttcaaatccgaattttattcatgttgtgcat1560
atattatatccatgatgatgaattttccacgacatttaaaggtagcaaccgcggtcagat1620
gcacggcaagccgtagcgcatcagacactttccctattaatgaaacatgtaaccttacta1680
gttgttcggttaacagtgctttataacatgcaacatggcactcaaagtcaagtaagcata1740
attgcaacttaatttgagtaatggaaaccggaaggataatcaatttttttcattttattt1800
cttttataatcattgacacacatgtcaactactcccaccgtttccaaatataactatctt1860
tagagattttaatactgattacatacggatgtatatatacatgtttcagagtatagattc1920
aatcgttttgctttgtatgtagtcaatattaaaatctccaaaaggttttatatttagaaa1980
tgtaccctgttcaaaaattcgttcgattaaccaattaatttgccgattaacccctactca2040
taagatcaccgagtaatcgattaagtggtaaatcgcccgattaattgattacatgggcga2100
ttaacttaccgattagactattaatcccgtactcgtcgaccaaccgagcagctaccagtt2160
aacgatttcctcaacaatgaaaatgaggggagtatactagttccaaactattcatatgtc2220
tgccctttgtccgccttttccctttgcaacccaggaagaatggaaggaaatccttcgata2280
acaattcttccttagttgaagaaatggtattcgatgcccgtggaaactctttcatttaaa2340
caaatgttcttcttaggaagcaaatcacattttctattgaattgtccactagcccagacc2400
tatgtagatttaatattatgcatcaccacatgttcccaaggactagcaaaatcgaaatag2460
tattttttttatcattctcttttcttgcttagccctttatcccctttgggatgcttcaca2520
caccgttatagtttttcatcgtcgacatggtaaagaatggacatacaatcactcacaacc2580
atcatctaccagctcttcaccgtaggggtccttccaaactctcgctaccaagtctttgtt2640
aatctacaaccgatgttattctaacgaaaacaacttgaaactcaacggagcctaaaagtg2700
attcctaaaccactaaaccatatacaaagaataaacatggaaaccatggttgcgcaatcg2760
gagtatggatggaaccatagattgccaaggatccaagcaaggaaaaagggccaagaggag2820
ggaataaaaaaaaggaaagggaaagaaaaagaaaaagaaaaagaaaaaagcaaagggaaa2880
ctggatacacggcccgcggctccaggaaacgaaccttccccctcgccagccgccaccggt2940
ctataaaacccagcccacgggggcacgcacaggccatcattccccaccaccgagcccggt3000
ttattcccccccttcgcgcagccgcccccgtgtctcgtgcgcaccttctc3050
<210>5
<211>20
<212>dna
<213>dna-f
<400>5
atcattccccaccaccgagc20
<210>6
<211>20
<212>dna
<213>dna-r
<400>6
atcattccccaccaccgagc20
<210>7
<211>20
<212>dna
<213>cdna-f
<400>7
gatcattccccaccaccgag20
<210>8
<211>20
<212>dna
<213>cdna-r
<400>8
tccaatgttgctccacacga20
<210>9
<211>20
<212>dna
<213>promoter-f
<400>9
cgtcgaactaggactgattg20
<210>10
<211>19
<212>dna
<213>promoter-r
<400>10
gagaaggtgcgcacgagac19
<210>11
<211>18
<212>dna
<213>oe-hvcam1-f
<400>11
atggcggaccagctcacc18
<210>12
<211>19
<212>dna
<213>oe-hvcam1-r
<400>12
tcacttggccatcatgacc19
<210>13
<211>20
<212>dna
<213>rnai-hvcam1-f
<400>13
caccttctcgaagcttcctc20
<210>14
<211>21
<212>dna
<213>rnai-hvcam1-r
<400>14
ctcctcgtccgtcagcttctc21
<210>15
<211>20
<212>dna
<213>pbr214-f
<400>15
gctcaccctgttgtttggtg20
<210>16
<211>20
<212>dna
<213>oecam1-r
<400>16
tcgtagttgatctggccgtc20
<210>17
<211>21
<212>dna
<213>guslink-r
<400>17
gtcgtcggtgaacaggtatgg21
<210>18
<211>21
<212>dna
<213>rnai-hvcam1-r
<400>18
ctcctcgtccgtcagcttctc21
<210>19
<211>20
<212>dna
<213>qhvcam1-f
<400>19
catgatcaacgaggttgacg20
<210>20
<211>20
<212>dna
<213>qhvcam1-r
<400>20
gagatgaagccgttctggtc20
- 还没有人留言评论。精彩留言会获得点赞!