一种高亲和力的抗FGF‑2的二硫键稳定的人源双链抗体及应用的制作方法
本发明属于抗体领域,特别涉及一种高亲和力的抗fgf-2的二硫键稳定的人源双链抗体及应用。
背景技术:
fgf-2称为碱性成纤维细胞生长因子,是一种广泛的有丝分裂原,可通过自分泌或旁分泌的方式促进肿瘤细胞和血管内皮细胞的增殖、分化及抗凋亡。fgf-2在多种肿瘤组织中的高表达与肿瘤的发生发展有着密切的关系。目前,已有报道多株鼠源的抗fgf-2单克隆抗体能够显著地抑制肿瘤的生长。coppola等报道了抗fgf-2的单克隆抗体在体内外实验中都能抑制fgf-2诱导的肿瘤血管新生并且抑制大鼠中软骨肉瘤的生长。以fgf-2为作用靶点,通过抗体阻断fgf-2/fgfr信号通路,进而抑制肿瘤组织中的血管生成,可能会是癌症治疗的有效策略。目前,抑制肿瘤血管新生的抗体药物avastin(抗vegf抗体药物)在临床上广泛用于恶性结直肠癌、非小细胞肺癌、恶性肾细胞癌、乳腺癌和脑癌的治疗。但该抗体药物长期使用会代偿性的促进bfgf和血小板源性生长因子(pdgf)表达,进而促进肿瘤血管新生,促进肿瘤复发和生长,导致耐药。所以,抗bfgf抗体有可能解决以vegf为靶点的抗血管新生治疗所产生的代偿性耐药性等问题。
抗体分子包括轻链和重链,每条链与包含恒定区(简称c区)和可变区(简称v区)两部分。只有可变区可与抗原结合,在可变区中,与抗原特异性结合最紧密的区域被称为互补决定区(cdr区),又被称为高变区,所以,抗体的重链和轻链可变区内均各有3个cdr区。这些cdr区氨基酸序列决定了该抗体结合抗原抗原的特异性(沈倍奋等的《重组抗体》)。正是由于抗体的这种特性,科学家们都在孜孜以求得到亲和力更高的抗体。
技术实现要素:
本发明的首要目的在于提供一种型高亲和力的抗fgf-2的二硫键稳定的人源双链抗体。
本发明的另一目的在于提供所述高亲和力的抗fgf-2的二硫键稳定的人源双链抗体的应用。
本发明的目的通过下述技术方案实现:一种高亲和力的抗fgf-2的二硫键稳定的人源双链抗体,包括轻链可变区和重链可变区;
轻链可变区的氨基酸序列如下所示(seqidno.1):
qsvltqpasvsgspgqsitisctgtssdvggywyvswyqqhpgkapklmiyevsnrpsgvsnrfsgsksgntasltisglqaedeadyycesyteshtwvfgcgtkltvl;
重链可变区的氨基酸序列如下所示(seqidno.2):
qvqlqesggglvqpggslrlscaasgfdfsyyhmnwvrqapgkclewvsyfshwgfeiyyadsvkgrftisrdnaknslylqmnslraedtavyycarllygwwgafdiwgqgtmvtvss。
编码所述的轻链可变区的核苷酸序列如下所示(seqidno.3):
cagagcgtgctgacacagcccgccagcgtgagcgggagccccggccagagcatcaccattagctgcacaggcaccagctccgatgtgggcgggtactggtacgtgtcctggtaccagcagcacccaggcaaggcccccaagctgatgatctacgaggtgagcaacaggcctagcggggtgagcaaccggttcagcgggtccaagagcgggaacacagcctccctgacaattagcggcctgcaggccgaggatgaggccgactactactgcgagagctacacagagagccacacctgggtgttcggctgcggcacaaagctgaccgtgctg。
该轻链可变区的基因由330个碱基组成,编码110个氨基酸,可变区含有3个cdr区:cdrl1编码14个氨基酸,cdrl2编码8个氨基酸,cdrl3编码10个氨基酸;可变区的框架区与其余人源性抗体的同源性为98%,而3个cdr区则为特异性序列,与其余人源性抗体λ链有较大差异。
编码所述的重链可变区的核苷酸序列如下所示(seqidno.4):
caggtgcagctgcaggagagcggcggggggctggtgcagcctgggggcagcctgcggctgtcctgcgccgcctccggcttcgactttagctactaccacatgaactgggtgcggcaggcccccggcaagtgcctggagtgggtgtcctacttcagccactggggcttcgagatctactacgccgactccgtgaagggcaggttcacaatcagcagggataacgccaagaacagcctgtacctgcagatgaactccctgagagctgaggacacagccgtgtactactgcgctaggttgttgtacgggtggtggggggcctttgatatttggggacagggaacaatggtgacagtgagtagc。
该重链可变区的基因由360个碱基组成,编码120个氨基酸,可变区含有3个cdr区:cdrh1编码10个氨基酸,cdrh2编码8个氨基酸,cdrh3编码13个氨基酸;可变区的框架区与其余人源性抗体的同源性高达94%,而3个cdr区则是特异性序列。
所述的高亲和力的抗fgf-2的二硫键稳定的人源双链抗体(优化突变型抗fgf-2人源性ds_diabody)优选氨基酸如下所述的抗体(seqidno.5):
qsvltqpasvsgspgqsitisctgtssdvggywyvswyqqhpgkapklmiyevsnrpsgvsnrfsgsksgntasltisglqaedeadyycesyteshtwvfgcgtkltvlggggsqvqlqesggglvqpggslrlscaasgfdfsyyhmnwvrqapgkclewvsyfshwgfeiyyadsvkgrftisrdnaknslylqmnslraedtavyycarllygwwgafdiwgqgtmvtvss。
该高亲和力的抗fgf-2的二硫键稳定的人源双链抗体是将抗fgf-2人源性scfv抗体的轻链可变区第103位氨基酸gly和重链可变区第44位氨基酸gly定点突变为cys,引入共价键二硫键,同时用编码一个连接肽(linker:氨基酸序列为ggggs)的基因连接轻重链可变区,并对该基因片段的17个氨基酸同时突变,包括asn-37>trp、asp-56>glu、ser-105>glu、ser-109>glu、ser-114>his、val-116>trp、thr-229>asp、ser-236>tyr、glu-238>his、ile-256>phe、ser-258>his、ser-259>trp、ser-263>phe、thr-264>glu、glu-307>leu、thr-309>tyr、asp-311>phe,从而构建vl-ggggs-vh的双链抗体,该双链抗体分子之间会形成共价二硫键,最终形成高亲和力的抗fgf-2的二硫键稳定的人源性双链抗体。
编码上述高亲和力的抗fgf-2的二硫键稳定的人源双链抗体(优化突变型抗fgf-2人源性ds_diabody)的核苷酸序列如下所示(seqidno.6):
cagagcgtgctgacacagcccgccagcgtgagcgggagccccggccagagcatcaccattagctgcacaggcaccagctccgatgtgggcgggtactggtacgtgtcctggtaccagcagcacccaggcaaggcccccaagctgatgatctacgaggtgagcaacaggcctagcggggtgagcaaccggttcagcgggtccaagagcgggaacacagcctccctgacaattagcggcctgcaggccgaggatgaggccgactactactgcgagagctacacagagagccacacctgggtgttcggctgcggcacaaagctgaccgtgctgggcgggggcgggagccaggtgcagctgcaggagagcggcggggggctggtgcagcctgggggcagcctgcggctgtcctgcgccgcctccggcttcgactttagctactaccacatgaactgggtgcggcaggcccccggcaagtgcctggagtgggtgtcctacttcagccactggggcttcgagatctactacgccgactccgtgaagggcaggttcacaatcagcagggataacgccaagaacagcctgtacctgcagatgaactccctgagagctgaggacacagccgtgtactactgcgctaggttgttgtacgggtggtggggggcctttgatatttggggacagggaacaatggtgacagtgagtagc。
上述的高亲和力的抗fgf-2人源性ds-diabody可在临床上进行如下应用:(1)用于肿瘤的诊断;(2)用于肿瘤的治疗,如抑制肿瘤血管新生和抑制肿瘤的生长和转移;(3)抑制内脏(如肾、肝或肺等)纤维化的进程。
本发明相对于现有技术具有如下的优点:
(1)fgf-2是重要的血管新生因子,与肿瘤关系密切,可促进肿瘤新生血管,促进肿瘤的生长和转移。抗fgf-2抗体可有效抑制肿瘤血管新生,抑制肿瘤的生长和转移。可用作肿瘤的治疗药物。
(2)抗fgf-2人源性ds-diabody的相对分子质量适中,具有良好的肿瘤靶向、瘤组织穿透力和较长的血液清除率,在临床诊断和治疗方面具有广阔的应用前景。
(3)抗fgf-2人源性ds-diabody是在抗fgf-2scfv抗体(实验室前期通过噬菌体抗体展示获得,专利号zl201110449568.8)的基础上,通过改变链接方式(linker改为ggggs),引入二硫键,并通过分子结构模拟改造优化其关键氨基酸的组成获得的高亲和力抗体。通过引入二硫键,可使得ds-diabody的两条肽链以共价键结合,大大增强了抗体的稳定性,延长体内的半衰期。
(4)本发明制备的抗fgf-2人源性ds-diabody是针对特定表位的高亲和力抗fgf-2人源性抗体,是利用分子结构模拟,模拟抗体ds-diabody与抗原的空间结构,并通过热力学分析其稳定性,对抗体结构进行改造优化,获得的亲和力提高的新型抗fgf-2人源性ds-diabody。
附图说明
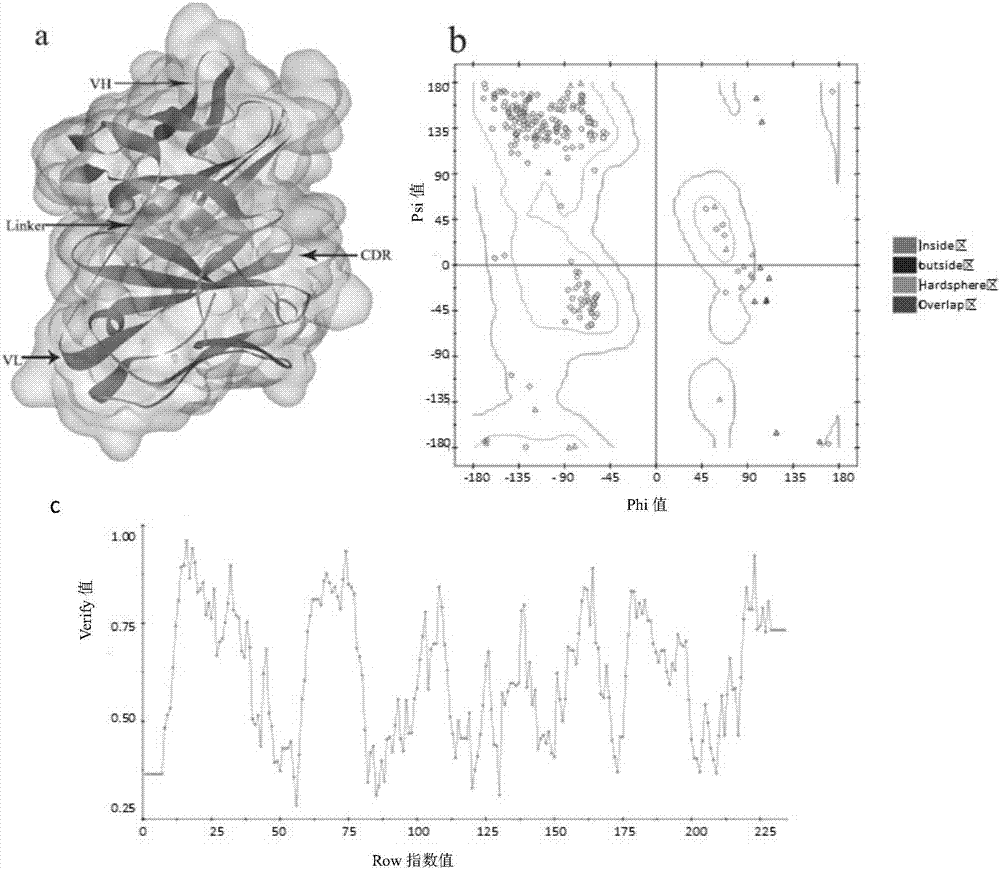
图1为fgf-2的模型示意图;其中,图a为fgf-2的三维结构模型示意图,图b为fgf-2模型的拉氏评价图,图c为fgf-2模型的profile-3d图。
图2为抗fgf-2人源性ds-diabody模型示意图;其中,图a为通过同源建模构建的抗fgf-2人源性ds-diabody三维结构模型图,图b为抗fgf-2人源性ds-diabody模型的拉氏图评价图,图c为抗fgf-2人源性ds-diabody模型的profile-3d图评价图。
图3为fgf-2模型与抗fgf-2人源性ds-diabody模型的分子对接示意图。
图4为fgf-2与优化突变型抗fgf-2人源性ds-diabody分子对接的模型示意图。
图5为抗fgf-2人源性ds-diabody和优化突变型抗fgf-2人源性ds-diabody的westernblot鉴定结果图。
图6为优化突变型抗fgf-2人源性ds-diabody的抗原结合活性的检测结果图。
具体实施方式
下面结合实施例及附图对本发明作进一步详细的描述,但本发明的实施方式不限于此。
实施例1
抗fgf-2人源性ds-diabody的基因片段的获取:
以编码抗fgf-2人源性scfv抗体(实验室前期通过噬菌体抗体展示获得,专利号zl201110449568.8)的vl基因和vh基因片段为基础,将抗fgf-2人源性scfv抗体的vl第103位氨基酸gly和vh第44位氨基酸gly定点突变为cys,引入共价键二硫键,同时对其编码的一个连接肽进行改造,改造为:氨基酸序列为ggggs的linker。通过改造的linker将抗体轻重链可变区连接,即vl-ggggs-vh,构建抗fgf-2人源性ds-diabody。
编码抗fgf-2人源性scfv抗体轻链可变区的核苷酸序列(seqidno.7)如下所示:
cagtctgtgttgacgcagcctgcctccgtgtctgggtctcctggacagtcgatcaccatctcctgcactggaaccagcagtgacgttggtggttataactatgtctcctggtaccaacaacacccaggcaaagcccccaaactcatgatttatgatgtcagtaatcggccctcaggggtttctaatcgcttctctggctccaagtctggcaacacggcctccctgaccatctctgggctccaggctgaggacgaggctgattattactgcagctcatatacaagcagcagcactgtggtattcggctgtgggaccaagctgaccgtccta。
编码抗fgf-2人源性scfv抗体重链可变区的核苷酸序列(seqidno.8)如下所示:
caggtgcagctgcaggagtctgggggaggcttggtacagcctggagggtccctgagactctcctgtgcagcctctggattcaccttcagtagttatgaaatgaactgggtccgccaggctccagggaagtgtctggagtgggtttcatacattagtagtagtggtagtaccatatactacgcagactctgtgaagggccggttcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtgcgagagagctaactggggattggggtgcttttgatatctggggccaggggacaatggtcactgtctcctca。
实施例2
fgf-2和抗fgf-2人源性ds-diabody分子空间结构模拟同源建模:
fgf-2的cdna序列(seqidno.9):
ctggtgggtgtggggggtggagatgtagaagatgtgacgccgcggcccggcgggtgccagattagcggacgcggtgcccgcggttgcaacgggatcccgggcgctgcagcttgggaggcggctctccccaggcggcgtccgcggagacacccatccgtgaaccccaggtcccgggccgccggctcgccgcgcaccaggggccggcggacagaagagcggccgagcggctcgaggctgggggaccgcgggcgcggccgcgcgctgccgggcgggaggctggggggccggggccggggccgtgccccggagcgggtcggaggccggggccggggccgggggacggcggctccccgcgcggctccagcggctcggggatcccggccgggccccgcagggaccatggcagccgggagcatcaccacgctgcccgccttgcccgaggatggcggcagcggcgccttcccgcccggccacttcaaggaccccaagcggctgtactgcaaaaacgggggcttcttcctgcgcatccaccccgacggccgagttgacggggtccgggagaagagcgaccctcacatcaagctacaacttcaagcagaagagagaggagttgtgtctatcaaaggagtgtgtgctaaccgttacctggctatgaaggaagatggaagattactggcttctaaatgtgttacggatgagtgtttcttttttgaacgattggaatctaataactacaatacttaccggtcaaggaaatacaccagttggtatgtggcactgaaacgaactgggcagtataaacttggatccaaaacaggacctgggcagaaagctatactttttcttccaatgtctgctaagagctga。
fgf-2的氨基酸序列(seqidno.10):
mvgvgggdvedvtprpggcqisgrgargcngipgaaaweaalprrrprrhpsvnprsraagsprtrgrrteerpsgsrlgdrgrgralpggrlggrgrgrapervggrgrgrgtaapraapaargsrpgpagtmaagsittlpalpedggsgafppghfkdpkrlycknggfflrihpdgrvdgvreksdphiklqlqaeergvvsikgvcanrylamkedgrllaskcvtdecffferlesnnyntyrsrkytswyvalkrtgqyklgsktgpgqkailflpmsaks。
(1)构建fgf-2同源模型:
在discoverystudio分子结构系统中,载入fgf-2的氨基酸序列。选取模板,依据blast搜索pdb数据库的结果,与fgf-2序列同源性最高的模板蛋白是fgf2-disaccharide(s3i2)complex蛋白质,pdb序列号为4oee_a,依据kabsch-sander和pdb对序列结构形式的分类方法,相应氨基酸序列的二级结构形式图将出现在模板序列的下方。通过目标蛋白与模板结构进行序列比对,可计算出目标蛋白与模板结构的一致性和相似性。4oee_a与fgf-2的序列一致性为94.5%,序列相似性为98.48%。依据pdftotalenergy与dopescore选择最优模型,两种函数分数越低,模型质量越可靠。当dopescore挑选的最优模型与pdftotalenergy挑选的最优模型不一致时,选取pdftotalenergy最低的模型作为最合理的初始模型,所以选用fgf-2.m0002作为最优模型(图1a),如下列表(表1)所示:
表1
模型评估:依据pdftotalenergy或dopescore选取最优模型,pdf值是模型排名的首要依据。选用ramachandranplot法和profile-3d法对模型进行评估。
根据fgf-2模型的拉氏图(图1b),可以计算出99.1%的氨基酸的
(2)构建抗fgf-2人源性ds-diabody的同源模型:
编码抗fgf-2人源性ds-diabody核苷酸序列(seqidno.11)如下所示:
cagtctgtgttgacgcagcctgcctccgtgtctgggtctcctggacaatcgatcaccatctcctgcactggaaccagcagtgacgttggtggttataactatgtctcctggtaccaacaacacccaggcaaagcccccaaactcatgatttatgatgtcagtaatcggccctcaggggtttctaatcgcttctctggctccaagtctggcaacacggcctccctgaccatctctgggctccaggctgaggacgaggctgattattactgcagctcatatacaagcagcagcactgtggtattcggctgtgggaccaagctgaccgtcctaggtggcggtggctcgcaggtgcagctgcaggagtctgggggaggcttggtacagcctggagggtccctgagactctcctgtgcagcctctggattcaccttcagtagttatgaaatgaactgggtccgccaggctccagggaagtgtctggagtgggtttcatacattagtagtagtggtagtaccatatactacgcagactctgtgaagggccggttcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtgcgagagagctaactggggattggggtgcttttgatatctggggccaggggacaatggtcactgtctcctca。
编码抗fgf-2人源性ds-diabody氨基酸序列(seqidno.12)
qsvltqpasvsgspgqsitisctgtssdvggynyvswyqqhpgkapklmiydvsnrpsgvsnrfsgsksgntasltisglqaedeadyycssytssstvvfgcgtkltvlggggsqvqlqesggglvqpggslrlscaasgftfssyemnwvrqapgkclewvsyisssgstiyyadsvkgrftisrdnaknslylqmnslraedtavyycareltgdwgafdiwgqgtmvtvss。
在discoverystudio分子结构系统中,载入抗fgf-2人源性ds-diabody的氨基酸序列(seqidno.11)。利用嵌合方式对抗体framework区进行同源建模,嵌合方式建模能够比较全面地考虑轻链和重链模板结构的信息,而且依据轻链和重链之间的表面结构决定了轻链和重链的三维取向。选择与目标蛋白抗fgf-2人源性ds-diabody同源性最高的pdb序列号分别为1t2j-a,4nki-l和4nki-lh的蛋白质晶体结构作为抗fgf-2人源性ds-diabody重链可变区、轻链可变区和轻重链界面的模板蛋白。由模板蛋白与抗fgf-2人源性ds-diabody的序列比对结果可以看出,1t2j-a与抗fgf-2人源性ds-diabody重链可变区的序列同一性和相似性都为94.5%;4nki-l与抗fgf-2人源性ds-diabody轻链可变区的序列同一性为95.5%,相似性为96.6%;4nki-lh与抗fgf-2人源性ds-diabody轻重链界面的序列同一性为92.2%,相似性为96.1%。
cdr区的优化:基于氨基酸的序列识别出抗体中的互补决定区(cdr),并利用blast从cdr库和抗体结构域中为每一个cdr区搜索可能的loop模板蛋白,模板蛋白将和抗体相应的cdr区叠合,最后构建优化后的抗体的6个cdr结构。
模型评估:利用ramachandranplot法和profile-3d法评估抗fgf-2人源性ds-diabody的模型(图2a)。
ramanchandranplo法:从主菜单栏中选择chart|ramachandranplot,显示抗fgf-2人源性ds-diabody同源模型的拉氏图(图2b)。
profile-3d法:在toolsexplorer中,展开macromolecules|createhomologymodels,点击打开verifyprotein对话框。设置inputproteinmolecules为ds-diabodyagainstfgf-2:visible。点击run运行任务。点击verifyscore的表头以选取整列数据。在主菜单栏中选择chart|lineplot,显示抗fgf-2人源性ds-diabody同源模型的profile-3d图(图2c)。
拉氏图表示蛋白质或肽段中氨基酸二面角是否合理,由抗fgf-2人源性ds-diabody模型的拉氏图可以计算出96.4%的氨基酸的
实施例3
fgf-2与抗fgf-2人源性ds-diabody的分子空间结构对接:
(1)利用zdock对接fgf-2与抗fgf-2人源性ds-diabody分子结构
采样的欧拉角度为6°时,zdock运算所产生的的样本数量为54000个构象,使得预测的结果更加精准。zrank用于依据范德华力、静电势和去溶剂化效应能对zdock预测的构象重新进行排名。抗fgf-2人源性ds-diabody的连接肽不可能出现在抗原与抗体相互作用界面,选中构成连接肽的氨基酸。抗fgf-2人源性ds-diabody中的cdr区一定会出现在抗原与抗体的作用界面,选中构成cdr区的氨基酸。借助plots和dockandanalyzeproteincomplexes程序来分析对接的构象,并选zdock产生的一部分对接构象利用优化程序rdock进行优化。
(2)利用rdock优化对接构象
新产生的组里包括选取的zdockscore大于11.0的构象。其它参数设置为默认值进行构象优化。
(3)分析fgf-2与抗fgf-2人源性ds-diabody的相互作用
通过discoverystudio4.5预测抗原—抗体复合物相互作用界面处分别位于fgf-2和抗fgf-2人源性ds-diabody上的关键氨基酸,并对fgf-2与抗fgf-2人源性ds-diabody之间形成的相互作用力进行分析。
运用分子对接zdock运算将抗原模型和抗体模型进行刚性对接,筛选出所有可能的构象,由于在分子对接的运算过程中对抗体cdr区和连接肽进行了定义和限制,导致分子对接产生了48个结合构象。通过优化程序rdock对fgf-2与抗fgf-2人源性ds-diabody复合物进行基于charmm力场的能量优化和打分,得到43个复合物模型,表明蛋白对接构象的能量越低,对接结果越为可信,依据e_rdock,选取能量最低的pose1作为最终的结合构象(图3)。
实施例5
(1)虚拟氨基酸饱和突变提高抗fgf-2人源性ds-diabody的亲和力
将fgf-2与抗fgf-2人源性ds-diabody相互作用距离小于6埃,位于抗fgf-2人源性ds-diabody上的氨基酸定义名为抗fgf-2人源性ds-diabodymutation的组,作为后续突变的位点。将抗fgf-2人源性ds-diabodymutation组中的氨基酸突变为其余19种除asph、gluh、lysn、argn、hsc以外的所有标准氨基酸。其中38个氨基酸突变为各自对应的氨基酸后,推测将会提高抗fgf-2人源性ds-diabody亲和力。
(2)虚拟氨基酸突变提高抗fgf-2人源性ds-diabody的稳定性
将抗fgf-2人源性ds-diabodymutation组中的氨基酸进行虚拟氨基酸饱和突变后导致亲和力突变效应为稳定的氨基酸定义为ds-diabodybindingresidues的组,作为后续突变的位点。将定义的ds-diabodybindingresidues组中的氨基酸突变为亲和力突变能值最大的氨基酸。
(3)多点同时突变提高抗fgf-2人源性ds-diabody与fgf-2的亲和力和稳定性
将ds-diabodybindingmutation组中的氨基酸进行虚拟氨基酸饱和突变后亲和力和稳定性二者突变效应都为稳定的氨基酸定义为ds-diabodykeyresidues的组,作为后续突变的位点。结果将是多个氨基酸同时突变产生的协同效应的突变能,将ds-diabodykeyresidues组中的氨基酸突变为亲和力突变能值最大且稳定性也会提高的氨基酸,将ds-diabodykeyresidues组中的17个氨基酸同时突变为各自亲和力突变能效应最显著且稳定性也会提高的氨基酸,其协同效应的突变能值为-24.36kcal/mol,如下列表(表2)所示:
表2
实施例6
fgf-2与优化改造的抗fgf-2人源性ds-diabody的分子空间结构对接:
(1)利用zdock和rdock对接fgf-2和优化改造的抗fgf-2人源性ds-diabody分子
分析对接的构象,选取zdock产生的一部分对接构象,利用优化程序rdock进行优化。(方法同实施例4)。
(2)抗fgf-2人源性ds-diabody与优化突变型抗fgf-2人源性ds-diabody结合构象的比较
抗体氨基酸序列的比较:将抗fgf-2人源性ds-diabody与优化突变型抗fgf-2人源性ds-diabody进行序列比对。
结合构象打分及能量的比较:通过zdock中的zdockscore及rdock中的e-rdock比较fgf-2结合抗fgf-2人源性ds-diabody与优化突变型抗fgf-2人源性ds-diabody的最优结合构象(图4)。
实施例7
优化突变型抗fgf-2人源性ds-diabody的表达:
(1)优化突变型抗fgf-2人源性ds-diabody真核表达载体的构建
结构优化改造的抗fgf-2人源性ds-diabody的基因序列如seqidno.6所示,由生工(上海)生物工程有限公司合成并加入酶切位点hindiii和xbai,构建入pgem-t载体,为质粒a。按《分子克隆实验指南》,通过hindiii和xbai分别双酶切质粒a和表达真核表达载体pcdna3.1/v5(invitrogen),质粒a的酶切产物通过琼脂糖凝胶电泳分离,胶回收得到目的基因,将其插入到双酶切后的pcdna3.1/v5表达载体中,得到重组表达载体a(pcdna3.1/v5-mut-dsdiabody)。
同时,将结构改造前的抗fgf-2人源性ds-diabody(seqidno.10),由生工(上海)生物工程有限公司合成并加入酶切位点hindiii和xbai,构建入pgem-t载体,为质粒b,按照上述步骤,将结构改造前的抗fgf-2人源性ds-diabody的基因通过hindiii和xbai克隆入真核表达载体pcdna3.1/v5,得到重组表达载体b(pcdna3.1/v5-dsdiabody)。
(2)优化突变型抗fgf-2人源性ds-diabody的表达和鉴定
①待hek293t传代到第三代时,调整细胞密度至2×105个/ml。取100μlhek293t细胞至96孔细胞培养板中,在dmem完全培养基中于37℃,5%co2培养箱中培养。当细胞占板底面积约75%时,可以用于转染。
②按照fugene6(promega)说明书操作将表达载体质粒a转染hek293t细胞。每个样品3个复孔,于37℃、5%co2的恒温细胞培养箱中培养48h,同时,转染重组表达载体b作为对照。
③将细胞表达上清进行电泳,随后进行转膜。用pbs-t稀释的质量体积比为5%的脱脂奶粉于4℃过夜封闭。pbs-t缓冲液每5min洗涤1次pvdf膜,共5次。加入5%脱脂奶粉稀释1:1000鼠抗egfp单抗,于37℃孵育1h。pbs-t每5min洗涤1次,共5次。加入5%脱脂奶粉稀释1:8000hrp-34羊抗鼠二抗,于37℃孵育45min。pbs-t缓冲液每5min洗涤1次,共5次,在pvdf膜目的蛋白大小处滴加50μlecl超灵敏化学发光液,曝光,观察结果。图5为表达上清westernblot鉴定结果,结果显示在还原条件下,转染了重组表达载体a和重组表达载体b的hek293t细胞培养上清与抗组氨酸标签抗体反应在35kda有特异性条带,与预期的目的蛋白大小相符;在非还原条件下,转染了重组表达载体a和重组表达载体b的细胞培养上清与抗组氨酸标签抗体反应在55kda有特异性条带,与预期的目的蛋白大小相符(图5),表明重组质粒成功表达fgf-2和优化突变型fgf-2融合蛋白。
实施例8
间接elisa检测优化突变型抗fgf-2人源性ds-diabody的抗原结合活性:
(1)用0.05m的碳酸盐缓冲液稀释fgf-2抗原(北京启维益成科技有限公司)至500ng/ml,以每孔100μl的稀释液加入至可拆酶标板中,4℃,16h;
(2)弃包被液,用纸巾拍干酶标板后每孔加入300μl的pbs-t,静置5min,弃pbs-t后拍干酶标板。每5min用pbs-t洗涤1次,共3次;
(3)每孔加入200μl质量体积比为5%的脱脂奶粉,将酶标板置于37℃,2h;
(4)pbs-t洗板3次;
(5)用0.015mpbs(ph7.4)将转染了重组表达载体a的hek293t细胞上清倍比稀释2倍、4倍、8倍、16倍和32倍,吸取100μl原液,2倍、4倍、8倍、16倍和32倍稀释上清至酶标板中,于37℃孵育1h;
(6)pbs-t洗涤共5次;
(7)每孔加入1:5000的100μl抗组氨酸标签的单抗(广州佰路生物科技有限公司)稀释液,于37℃孵育1h;
(8)pbs-t洗涤3次;
(9)每孔中加入1:8000的100μl的hrp标记的羊抗鼠igg二抗,于37℃孵育45min;
(10)pbs-t洗涤3次;
(11)每孔中加入100μltmb,避光10min后每孔加入50μl2mh2so4终止反应,最后立即用酶标仪测定od450nm值。
本实验以转染了重组表达载体b的hke293t细胞上清作为对照。
间接elisa实验结果表明,与抗fgf-2人源性ds-diabody相比,优化突变型抗fgf-2人源性ds-diabody与抗原fgf-2的结合活性提高了3倍,具有更高的亲和力(图6)。
上述实施例为本发明较佳的实施方式,但本发明的实施方式并不受上述实施例的限制,其他的任何未背离本发明的精神实质与原理下所作的改变、修饰、替代、组合、简化,均应为等效的置换方式,都包含在本发明的保护范围之内。
序列表
<110>暨南大学
<120>一种高亲和力的抗fgf-2的二硫键稳定的人源双链抗体及应用
<160>12
<170>siposequencelisting1.0
<210>1
<211>110
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>轻链可变区的氨基酸序
<400>1
glnservalleuthrglnproalaservalserglyserproglygln
151015
serilethrilesercysthrglythrserseraspvalglyglytyr
202530
trptyrvalsertrptyrglnglnhisproglylysalaprolysleu
354045
metiletyrgluvalserasnargproserglyvalserasnargphe
505560
serglyserlysserglyasnthralaserleuthrileserglyleu
65707580
glnalagluaspglualaasptyrtyrcysglusertyrthrgluser
859095
histhrtrpvalpheglycysglythrlysleuthrvalleu
100105110
<210>2
<211>120
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>重链可变区的氨基酸序列
<400>2
glnvalglnleuglngluserglyglyglyleuvalglnproglygly
151015
serleuargleusercysalaalaserglypheaspphesertyrtyr
202530
hismetasntrpvalargglnalaproglylyscysleuglutrpval
354045
sertyrpheserhistrpglyphegluiletyrtyralaaspserval
505560
lysglyargphethrileserargaspasnalalysasnserleutyr
65707580
leuglnmetasnserleuargalagluaspthralavaltyrtyrcys
859095
alaargleuleutyrglytrptrpglyalapheaspiletrpglygln
100105110
glythrmetvalthrvalserser
115120
<210>3
<211>330
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>编码轻链可变区的核苷酸序列
<400>3
cagagcgtgctgacacagcccgccagcgtgagcgggagccccggccagagcatcaccatt60
agctgcacaggcaccagctccgatgtgggcgggtactggtacgtgtcctggtaccagcag120
cacccaggcaaggcccccaagctgatgatctacgaggtgagcaacaggcctagcggggtg180
agcaaccggttcagcgggtccaagagcgggaacacagcctccctgacaattagcggcctg240
caggccgaggatgaggccgactactactgcgagagctacacagagagccacacctgggtg300
ttcggctgcggcacaaagctgaccgtgctg330
<210>4
<211>360
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>编码重链可变区的核苷酸序列
<400>4
caggtgcagctgcaggagagcggcggggggctggtgcagcctgggggcagcctgcggctg60
tcctgcgccgcctccggcttcgactttagctactaccacatgaactgggtgcggcaggcc120
cccggcaagtgcctggagtgggtgtcctacttcagccactggggcttcgagatctactac180
gccgactccgtgaagggcaggttcacaatcagcagggataacgccaagaacagcctgtac240
ctgcagatgaactccctgagagctgaggacacagccgtgtactactgcgctaggttgttg300
tacgggtggtggggggcctttgatatttggggacagggaacaatggtgacagtgagtagc360
<210>5
<211>235
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>优化突变型抗fgf-2人源性ds_diabody
<400>5
glnservalleuthrglnproalaservalserglyserproglygln
151015
serilethrilesercysthrglythrserseraspvalglyglytyr
202530
trptyrvalsertrptyrglnglnhisproglylysalaprolysleu
354045
metiletyrgluvalserasnargproserglyvalserasnargphe
505560
serglyserlysserglyasnthralaserleuthrileserglyleu
65707580
glnalagluaspglualaasptyrtyrcysglusertyrthrgluser
859095
histhrtrpvalpheglycysglythrlysleuthrvalleuglygly
100105110
glyglyserglnvalglnleuglngluserglyglyglyleuvalgln
115120125
proglyglyserleuargleusercysalaalaserglypheaspphe
130135140
sertyrtyrhismetasntrpvalargglnalaproglylyscysleu
145150155160
glutrpvalsertyrpheserhistrpglyphegluiletyrtyrala
165170175
aspservallysglyargphethrileserargaspasnalalysasn
180185190
serleutyrleuglnmetasnserleuargalagluaspthralaval
195200205
tyrtyrcysalaargleuleutyrglytrptrpglyalapheaspile
210215220
trpglyglnglythrmetvalthrvalserser
225230235
<210>6
<211>705
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>优化突变型抗fgf-2人源性ds_diabody的核苷酸序列
<400>6
cagagcgtgctgacacagcccgccagcgtgagcgggagccccggccagagcatcaccatt60
agctgcacaggcaccagctccgatgtgggcgggtactggtacgtgtcctggtaccagcag120
cacccaggcaaggcccccaagctgatgatctacgaggtgagcaacaggcctagcggggtg180
agcaaccggttcagcgggtccaagagcgggaacacagcctccctgacaattagcggcctg240
caggccgaggatgaggccgactactactgcgagagctacacagagagccacacctgggtg300
ttcggctgcggcacaaagctgaccgtgctgggcgggggcgggagccaggtgcagctgcag360
gagagcggcggggggctggtgcagcctgggggcagcctgcggctgtcctgcgccgcctcc420
ggcttcgactttagctactaccacatgaactgggtgcggcaggcccccggcaagtgcctg480
gagtgggtgtcctacttcagccactggggcttcgagatctactacgccgactccgtgaag540
ggcaggttcacaatcagcagggataacgccaagaacagcctgtacctgcagatgaactcc600
ctgagagctgaggacacagccgtgtactactgcgctaggttgttgtacgggtggtggggg660
gcctttgatatttggggacagggaacaatggtgacagtgagtagc705
<210>7
<211>330
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>编码抗fgf-2人源性scfv抗体轻链可变区的核苷酸序列
<400>7
cagtctgtgttgacgcagcctgcctccgtgtctgggtctcctggacagtcgatcaccatc60
tcctgcactggaaccagcagtgacgttggtggttataactatgtctcctggtaccaacaa120
cacccaggcaaagcccccaaactcatgatttatgatgtcagtaatcggccctcaggggtt180
tctaatcgcttctctggctccaagtctggcaacacggcctccctgaccatctctgggctc240
caggctgaggacgaggctgattattactgcagctcatatacaagcagcagcactgtggta300
ttcggctgtgggaccaagctgaccgtccta330
<210>8
<211>360
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>编码抗fgf-2人源性scfv抗体重链可变区的核苷酸序列
<400>8
caggtgcagctgcaggagtctgggggaggcttggtacagcctggagggtccctgagactc60
tcctgtgcagcctctggattcaccttcagtagttatgaaatgaactgggtccgccaggct120
ccagggaagtgtctggagtgggtttcatacattagtagtagtggtagtaccatatactac180
gcagactctgtgaagggccggttcaccatctccagagacaacgccaagaactcactgtat240
ctgcaaatgaacagcctgagagccgaggacacggctgtgtattactgtgcgagagagcta300
actggggattggggtgcttttgatatctggggccaggggacaatggtcactgtctcctca360
<210>9
<211>867
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>fgf-2的cdna序列
<400>9
ctggtgggtgtggggggtggagatgtagaagatgtgacgccgcggcccggcgggtgccag60
attagcggacgcggtgcccgcggttgcaacgggatcccgggcgctgcagcttgggaggcg120
gctctccccaggcggcgtccgcggagacacccatccgtgaaccccaggtcccgggccgcc180
ggctcgccgcgcaccaggggccggcggacagaagagcggccgagcggctcgaggctgggg240
gaccgcgggcgcggccgcgcgctgccgggcgggaggctggggggccggggccggggccgt300
gccccggagcgggtcggaggccggggccggggccgggggacggcggctccccgcgcggct360
ccagcggctcggggatcccggccgggccccgcagggaccatggcagccgggagcatcacc420
acgctgcccgccttgcccgaggatggcggcagcggcgccttcccgcccggccacttcaag480
gaccccaagcggctgtactgcaaaaacgggggcttcttcctgcgcatccaccccgacggc540
cgagttgacggggtccgggagaagagcgaccctcacatcaagctacaacttcaagcagaa600
gagagaggagttgtgtctatcaaaggagtgtgtgctaaccgttacctggctatgaaggaa660
gatggaagattactggcttctaaatgtgttacggatgagtgtttcttttttgaacgattg720
gaatctaataactacaatacttaccggtcaaggaaatacaccagttggtatgtggcactg780
aaacgaactgggcagtataaacttggatccaaaacaggacctgggcagaaagctatactt840
tttcttccaatgtctgctaagagctga867
<210>10
<211>288
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>fgf-2的氨基酸序列
<400>10
metvalglyvalglyglyglyaspvalgluaspvalthrproargpro
151015
glyglycysglnileserglyargglyalaargglycysasnglyile
202530
proglyalaalaalatrpglualaalaleuproargargargproarg
354045
arghisproservalasnproargserargalaalaglyserproarg
505560
thrargglyargargthrglugluargproserglyserargleugly
65707580
aspargglyargglyargalaleuproglyglyargleuglyglyarg
859095
glyargglyargalaprogluargvalglyglyargglyargglyarg
100105110
glythralaalaproargalaalaproalaalaargglyserargpro
115120125
glyproalaglythrmetalaalaglyserilethrthrleuproala
130135140
leuprogluaspglyglyserglyalapheproproglyhisphelys
145150155160
aspprolysargleutyrcyslysasnglyglyphepheleuargile
165170175
hisproaspglyargvalaspglyvalargglulysseraspprohis
180185190
ilelysleuglnleuglnalaglugluargglyvalvalserilelys
195200205
glyvalcysalaasnargtyrleualametlysgluaspglyargleu
210215220
leualaserlyscysvalthraspglucysphephephegluargleu
225230235240
gluserasnasntyrasnthrtyrargserarglystyrthrsertrp
245250255
tyrvalalaleulysargthrglyglntyrlysleuglyserlysthr
260265270
glyproglyglnlysalaileleupheleuprometseralalysser
275280285
<210>11
<211>705
<212>dna
<213>人工序列(artificialsequence)
<220>
<223>编码抗fgf-2人源性ds-diabody核苷酸序列
<400>11
cagtctgtgttgacgcagcctgcctccgtgtctgggtctcctggacaatcgatcaccatc60
tcctgcactggaaccagcagtgacgttggtggttataactatgtctcctggtaccaacaa120
cacccaggcaaagcccccaaactcatgatttatgatgtcagtaatcggccctcaggggtt180
tctaatcgcttctctggctccaagtctggcaacacggcctccctgaccatctctgggctc240
caggctgaggacgaggctgattattactgcagctcatatacaagcagcagcactgtggta300
ttcggctgtgggaccaagctgaccgtcctaggtggcggtggctcgcaggtgcagctgcag360
gagtctgggggaggcttggtacagcctggagggtccctgagactctcctgtgcagcctct420
ggattcaccttcagtagttatgaaatgaactgggtccgccaggctccagggaagtgtctg480
gagtgggtttcatacattagtagtagtggtagtaccatatactacgcagactctgtgaag540
ggccggttcaccatctccagagacaacgccaagaactcactgtatctgcaaatgaacagc600
ctgagagccgaggacacggctgtgtattactgtgcgagagagctaactggggattggggt660
gcttttgatatctggggccaggggacaatggtcactgtctcctca705
<210>12
<211>235
<212>prt
<213>人工序列(artificialsequence)
<220>
<223>编码抗fgf-2人源性ds-diabody氨基酸序列
<400>12
glnservalleuthrglnproalaservalserglyserproglygln
151015
serilethrilesercysthrglythrserseraspvalglyglytyr
202530
asntyrvalsertrptyrglnglnhisproglylysalaprolysleu
354045
metiletyraspvalserasnargproserglyvalserasnargphe
505560
serglyserlysserglyasnthralaserleuthrileserglyleu
65707580
glnalagluaspglualaasptyrtyrcyssersertyrthrserser
859095
serthrvalvalpheglycysglythrlysleuthrvalleuglygly
100105110
glyglyserglnvalglnleuglngluserglyglyglyleuvalgln
115120125
proglyglyserleuargleusercysalaalaserglyphethrphe
130135140
sersertyrglumetasntrpvalargglnalaproglylyscysleu
145150155160
glutrpvalsertyrileserserserglyserthriletyrtyrala
165170175
aspservallysglyargphethrileserargaspasnalalysasn
180185190
serleutyrleuglnmetasnserleuargalagluaspthralaval
195200205
tyrtyrcysalaarggluleuthrglyasptrpglyalapheaspile
210215220
trpglyglnglythrmetvalthrvalserser
225230235
- 还没有人留言评论。精彩留言会获得点赞!