检测DMDA827T、DMDA5741T和DMD6436insC位点突变的引物和方法与流程
本发明属生命科学和生物技术领域,特别涉及检测dmda827t、dmda5741t和dmd6436insc位点突变的引物,采用普通pcr结合sanger测序技术,可用于快速检测dmd/bmd患者体内dmda827t、dmda5741t和dmd6436insc位点的突变情况。
背景技术:
假性肥大型肌营养不良(duchenne/beckermilsculardystrophy,dmd/bmd)是常见的x-连锁隐性遗传性肌肉疾病,由dmd基因突变所致。dmd在活产男婴中的发病率为1/3500,多于5岁前发病,病程进展快,12岁前失去独立行走能力,20岁左右死于心力衰竭或呼吸衰竭。bmd起病年龄较dmd晚,病程进展缓慢,一般于16岁后失去独立行走能力。由于本病发病率与致残率高,给患者家庭带来沉重的精神和经济负担,目前临床上尚无有效的治疗方法,所以准确、快速的dmd致病基因检测,优质的遗传咨询及准确的产前诊断对防止患儿的出生显得尤为重要。
肌萎缩蛋白基因(dystrophingene,dmd)是人类最大的基因之一,位于xp21.2,长2.4mb,约占人类基因组的0.1%,含79个外显子,其mrna序列长14kb,编码3685个氨基酸,组成抗肌萎缩蛋白(dystrophin)。dmd基因突变导致肌细胞内缺乏dystrophin蛋白,造成肌细胞膜不稳定,无法在收缩时保持完整,出现钙内流,最终导致肌细胞坏死和功能缺失,肌肉组织纤维化,表现为假性肥大肌营养不良。sanger测序法是基因检测的主要手段之一,也是基因检测的金标准。通过测序法对dmd基因突变进行检测可发现dmd基因已知和未知的全部类型的异常,为dmd/bmd的诊断提供依据。本发明中发现dmda827t、dmda5741t和dmd6436insc三个位点的突变在中国人群中普遍存在。因此,临床在利用dmd基因突变辅助诊断dmd/bmd时需格外谨慎,加以区别。
技术实现要素:
本发明的目的是提供一种检测dmda827t、dmda5741t和dmd6436insc位点突变的引物,采用pcr技术,可用于快速检测dmd/bmd患者体内dmda827t、dmda5741t和dmd6436insc位点的突变情况。所述检测dmda827t、dmda5741t和dmd6436insc位点突变情况的引物,其特征在于,包括:
扩增dmda827t、dmda5741t和dmd6436insc位点的引物,其碱基序列为:
dmda827t-f:tgtaaaacgacggccagtatgttctgttttctaccatgttg
dmda827t-r:aacagctatgaccatgtcaataacaaagcagaatcacat
dmda5741t-f:tgtaaaacgacggccagtttagcttcctatacatgggtc
dmda5741t-r:aacagctatgaccatgtttaccagaaaacacatcaca
dmd6436insc-f:tgtaaaacgacggccagtttttgtatttctttctttgccag
dmd6436insc-r:aacagctatgaccatgttctttaatgttagtgcctttca。
进一步地,还包括测序引物,其碱基序列为:
m13f:tgtaaaacgacggccagt
m13r:aacagctatgaccatg
进一步地,引物序列dmda827t-f和dmda827t-r是扩增dmd基因第827位碱基的引物;引物序列dmda5741t-f和dmda5741t-r是扩增dmd基因第5741位碱基的引物;引物序列dmd6436insc-f和dmd6436insc-r是扩增dmd基因第6436位碱基的引物。
本发明还提供了检测dmda827t、dmda5741t和dmd6436insc位点突变情况的方法,包括以下步骤:
1.抽提外周血或肌肉组织中的基因组dna;
2.用pcr扩增步骤1中提取的dna;
3.对步骤2中的扩增产物进行测序;
4.对测序结果进行判断,确定dmda827t、dmda5741t和dmd6436insc位点是否发生突变;
其中pcr扩增引物为:
扩增dmda827t、dmda5741t和dmd6436insc位点的引物,其碱基序列为:
dmda827t-f:tgtaaaacgacggccagtatgttctgttttctaccatgttg
dmda827t-r:aacagctatgaccatgtcaataacaaagcagaatcacat
dmda5741t-f:tgtaaaacgacggccagtttagcttcctatacatgggtc
dmda5741t-r:aacagctatgaccatgtttaccagaaaacacatcaca
dmd6436insc-f:tgtaaaacgacggccagtttttgtatttctttctttgccag
dmd6436insc-r:aacagctatgaccatgttctttaatgttagtgcctttca。
进一步地,测序引物碱基序列为:
m13f:tgtaaaacgacggccagt
m13r:aacagctatgaccatg。
本发明还提供了一种检测dmda827t、dmda5741t和dmd6436insc位点突变的试剂盒,其特征在于,所述试剂盒包括:
(i)血液/组织dna抽提试剂;
(ii)检测体系pcr扩增反应液:包括扩增dmda827t、dmda5741t和dmd6436insc位点的引物,其碱基序列为:
dmda827t-f:tgtaaaacgacggccagtatgttctgttttctaccatgttg
dmda827t-r:aacagctatgaccatgtcaataacaaagcagaatcacat
dmda5741t-f:tgtaaaacgacggccagtttagcttcctatacatgggtc
dmda5741t-r:aacagctatgaccatgtttaccagaaaacacatcaca
dmd6436insc-f:tgtaaaacgacggccagtttttgtatttctttctttgccag
dmd6436insc-r:aacagctatgaccatgttctttaatgttagtgcctttca;
(iii)测序体系试剂:包括测序引物,其碱基序列为:
m13f:tgtaaaacgacggccagt
m13r:aacagctatgaccatg;
(iv)阳性对照品和阴性对照品。
有益效果:本发明设计了扩增dmda827t、dmda5741t和dmd6436insc的引物。采用pcr技术,构建了稳定的扩增体系。通过调整引物浓度、退火温度等反应条件,可使扩增效率达到最佳。本发明利用测序技术检测患者dmda827t、dmda5741t和dmd6436insc突变热点的方法,可以将dmd基因dmda827t、dmda5741t和dmd6436insc的突变检测出来,相比较荧光定量pcr法降低了检测的成本和难度。荧光定量pcr法要针对不同的突变类型设计3个探针,成本高,检测难度大。
附图说明
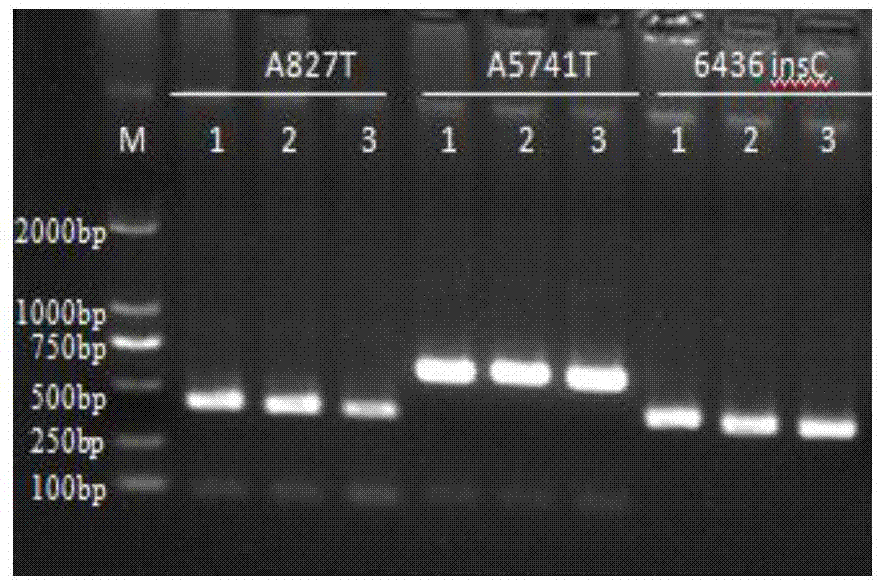
图1为3对扩增引物的琼脂糖凝胶电泳图,m为markerdl2000,1和2为血液样本1和样本2,经3对引物扩增后,引物扩增有效,且目的条带清晰,产物大小正确。
图2为样本2检测dmda827t位点的阳性测序截图结果。
图3为样本2检测dmda5741t位点的阳性测序截图结果。
图4为样本2检测dmd6436insc位点的阳性测序截图结果。
具体实施方式
实施例1
下面结合具体实施例和附图,进一步阐述本发明。应当注意的是,实施例中未说明的常规条件和方法,通常按照所属领域实验人员常规采用方法:譬如,奥斯柏和金斯顿主编的《精编分子生物学实验指南》第四版,或者按照制造厂商所建议的步骤和条件。
一种检测dmda827t、dmda5741t和dmd6436insc位点突变的引物,该引物的设计是针对dmda827t、dmda5741t和dmd6436insc突变位点所设计的特异性扩增引物,包括:
扩增dmd基因第827位、5741位和6436位碱基的引物,其碱基序列为:
dmda827t-f:tgtaaaacgacggccagtatgttctgttttctaccatgttg
dmda827t-r:aacagctatgaccatgtcaataacaaagcagaatcacat
dmda5741t-f:tgtaaaacgacggccagtttagcttcctatacatgggtc
dmda5741t-r:aacagctatgaccatgtttaccagaaaacacatcaca
dmd6436insc-f:tgtaaaacgacggccagtttttgtatttctttctttgccag
dmd6436insc-r:aacagctatgaccatgttctttaatgttagtgcctttca
一种检测dmda827t、dmda5741t和dmd6436insc位点突变的试剂盒,包括
(i)血液/组织dna抽提试剂;
(ii)检测体系pcr反应液;
(iii)测序体系试剂;
(iv)阳性对照品和阴性对照品。
其中,血液/组织dna抽提试剂可购自天根dna抽提试剂盒等商品化试剂。
检测体系pcr扩增反应液包括:2×pcrbuffer;2mmdntps;kodfxdnapolymerase(1u/μl);dmda827t、dmda5741t和dmd6436insc位点上、下游引物(10μm)。
测序体系试剂包括:测序纯化液(exoi:0.6u,cip:1.2u)、edta(125mmol)、无水乙醇、75%乙醇、hidi(高度去离子甲酰胺)、测序引物:检测dmda827t、dmda5741t和dmd6436insc的上、下游引物(3.2μm)。
实施例2
血液/细胞/组织基因组dna抽提试剂盒(天根生物)的操作流程:
(1)抽提血液中的组织dna:1)抽取300μl血液加入900μl红细胞裂解液,颠倒混匀,室温放置5分钟,期间再颠倒混匀几次。12,000rpm离心1min,吸去上清,留下白细胞沉淀,加200μl缓冲液ga,振荡至彻底混匀。2)加入20μl蛋白酶k溶液,混匀。3)加入200μl缓冲液gb,充分颠倒混匀,70℃放置10分钟,溶液应变清亮,简短离心以去除管盖内壁的水珠。4)加入200μl无水乙醇,充分振荡混匀15秒,此时可能会出现絮状沉淀,简短离心以去除管盖内壁的水珠。5)将上一步所得溶液和絮状沉淀都加入一个吸附柱cb3中(吸附柱放入收集管中),12,000rpm离心30秒,倒掉废液,将吸附柱cb3放回收集管中。6)向吸附柱cb3中加入500μl缓冲液gd(使用前请先检查是否已加入无水乙醇),12,000rpm离心30秒,倒掉废液,将吸附柱cb3放入收集管中。7)向吸附柱cb3中加入700μl漂洗液pw(使用前请先检查是否已加入无水乙醇),12,000rpm离心30秒,倒掉废液,将吸附柱cb3放入收集管中。8)向吸附柱cb3中加入500μl漂洗液pw,12,000rpm离心30秒,倒掉废液。9)将吸附柱cb3放回收集管中,12,000rpm离心2分钟,倒掉废液。将吸附柱cb3置于室温放置数分钟,以彻底晾干吸附材料中残余的漂洗液。10)将吸附柱cb3转入一个干净的离心管中,向吸附膜的中间部位悬空滴加100μl洗脱缓冲液te,室温放置2-5分钟,12,000rpm离心2分钟,将溶液收集到离心管中。
(2)试剂配置:按检测人份数配置检测体系pcr反应液各xμl,每人份18μl分装:
x=18μl反应液×(n份标本+1份阳性对照+1份阴性对照+1份空白对照)
n为检测标本数。
(3)加样:加入检测体系pcr反应液中2μldna;阳性对照和阴性对照直接加2μl阳性对照品和阴性对照品;空白对照加2μl生理盐水或不加任何物质。
(4)扩增:检测在常规pcr仪上进行,可用仪器包括abiveriti(美国appliedbiosystems公司)等。反应条件如下:
pcr扩增体系试剂配制方法如下:
其中,引物序列为:
注:f为上游引物,r为下游引物
(5)电泳:1.5%琼脂糖凝胶电泳,110v,35min,凝胶成像系统观察。
如图1所示,即为2例血液样本以相应的引物扩增后所得产物的电泳图谱。通过电泳图的分析表明本发明所述扩增有效,且条带清晰。
(6)sanger测序:
取9pcr产物与2μl纯化体系。按照以下程序进行纯化:
将1μl纯化产物分别与上、下测序引物按照如下体系进行混合:
测序反应程序:
沉淀环节:
向完成测序反应的产物中加入2μl125mmol的edta,静置5min;加入15μl无水乙醇,漩涡混匀;3700rpm离心30min;倒置离心15sec,加入50ml70%乙醇,漩涡混匀;3700rpm离心15min;倒置离心15sec,置于95℃金属浴上;加入10μlcbl后进行变性5min,最后-20℃2min上测序仪(abi3730)测序。
(7)结果判断:分别将测序结果与dmd(dmddp427m:004006.2)阴性参考序列进行比对,根据实际突变情况对结果进行报告。
实施例3
取30例临床外周血样品,按实施例2所述方法提取基因组、配制试剂并检测。每份样品加入检测体系pcr反应液中2μl。同时做阳性,阴性,空白对照各一份。测序后发现dmda827位点基因突变情况为样本1无突变,其余样本全部突变;dmda5741位点样本全部突变;dmda6436位点样本全部突变。样本1和样本2的琼脂糖凝胶电泳结果如图1所示,阳性测序图如图2-图4所示。
序列表
<110>杭州艾迪康医学检验中心有限公司
<120>检测dmda827t、dmda5741t和dmd6436insc位点突变的引物
<160>8
<170>siposequencelisting1.0
<210>1
<211>41
<212>dna
<213>人工序列(artificialsequence)
<400>1
tgtaaaacgacggccagtatgttctgttttctaccatgttg41
<210>2
<211>39
<212>dna
<213>人工序列(artificialsequence)
<400>2
aacagctatgaccatgtcaataacaaagcagaatcacat39
<210>3
<211>39
<212>dna
<213>人工序列(artificialsequence)
<400>3
tgtaaaacgacggccagtttagcttcctatacatgggtc39
<210>4
<211>37
<212>dna
<213>人工序列(artificialsequence)
<400>4
aacagctatgaccatgtttaccagaaaacacatcaca37
<210>5
<211>41
<212>dna
<213>人工序列(artificialsequence)
<400>5
tgtaaaacgacggccagtttttgtatttctttctttgccag41
<210>6
<211>39
<212>dna
<213>人工序列(artificialsequence)
<400>6
aacagctatgaccatgttctttaatgttagtgcctttca39
<210>7
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>7
tgtaaaacgacggccagt18
<210>8
<211>16
<212>dna
<213>人工序列(artificialsequence)
<400>8
aacagctatgaccatg16
- 还没有人留言评论。精彩留言会获得点赞!