工程化的CAS9核酸酶的制作方法
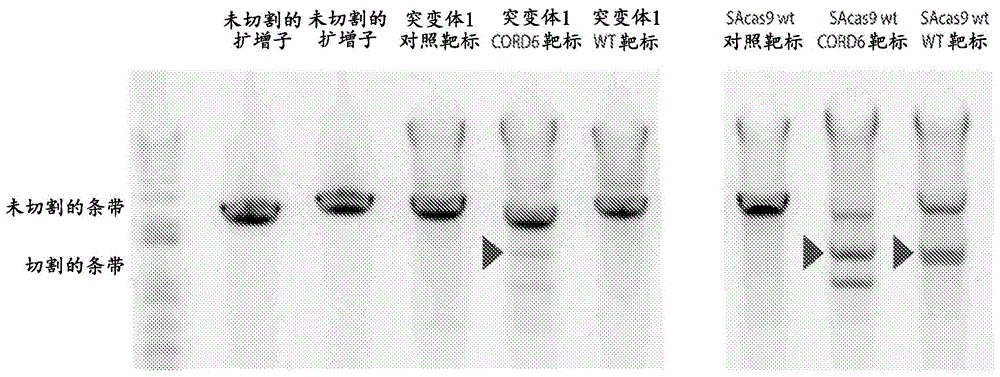
相关申请的交叉引用本申请要求2017年6月9日提交的美国临时申请号62/517,811和2018年5月1日提交的美国临时申请号62/665,388的优先权,两者通过援引以其全文并入本文。序列表本说明书参考了序列表(2018年6月8日以名称“2011271-0077_sl.txt”的.txt文件电子提交)。所述.txt文件生成于2018年6月4日并且大小为41,513个字节。将序列表的全部内容通过援引并入本文。本披露涉及用于编辑靶核酸序列或调节靶核酸序列的表达的crispr/cas相关方法和组分。更具体地,本披露涉及具有改变和改善的靶特异性的工程化cas9核酸酶。
背景技术:
:crispr(成簇规律间隔短回文重复序列)在细菌和古核生物中作为适应性免疫系统进化,以防御病毒攻击。在暴露于病毒后,病毒dna的短区段被整合进crispr基因座中。rna是从包括病毒序列的crispr基因座的一部分转录。该rna含有与病毒基因组互补的序列,介导将rna指导的核酸酶蛋白如cas9或cpf1靶向病毒基因组中的靶序列。rna指导的核酸酶反过来切割并因此使病毒靶标沉默。crispr系统已经过改造,用于在真核细胞中的基因组编辑。这些系统通常包括蛋白质组分(rna指导的核酸酶)和核酸组分(通常称为指导rna或“grna”)。这两种组分形成复合物,所述复合物与由系统的两种组分识别或互补的特定靶dna序列相互作用,并任选地编辑或改变靶序列,例如通过位点特异性dna切割进行。诸如此类的核酸酶作为用于治疗遗传性疾病的工具的价值已得到广泛认可。例如,美国食品药品监督管理局(fda)于2016年11月15日举行了科学委员会会议,讨论了此类系统的使用及其产生的潜在监管考虑。在这次会议上,fda指明,虽然可定制cas9/指导rna(grna)核糖核蛋白(rnp)复合物以在目的基因座处产生精确编辑,但这些复合物也可与其他“脱靶”基因座相互作用并在其他“脱靶”基因座处切割。脱靶切割(“脱靶”)的可能性就使用这些核酸酶的治疗方法的批准而言,又至少引起了潜在的监管考虑。技术实现要素:本披露通过部分地提供工程化的rna指导的核酸酶来解决潜在的监管考虑,所述工程化的rna指导的核酸酶例如相对于野生型核酸酶表现出就靶向dna序列而言改善的特异性。改善的特异性可以是,例如,相对于野生型rna指导的核酸酶和/或另一种变异核酸酶,(i)dna的增加的中靶结合、切割和/或编辑和/或(ii)dna的降低的脱靶结合、切割和/或编辑。一方面,本披露提供了分离的酿脓链球菌(staphylococcuspyogenes)cas9(spcas9)多肽,其相对于野生型spcas9在以下位置中的一个或多个处包含氨基酸取代:d23、d1251、y128、t67、n497、r661、q695、和/或q926。在一些实施例中,分离的spcas9多肽包含与seqidno:13的氨基酸序列具有至少80%、85%、90%、95%、96%、97%、98%或99%同一性的氨基酸序列,其中所述多肽在seqidno:13的以下位置中的一个或多个处包含氨基酸取代:d23、d1251、y128、t67、n497、r661、q695、和/或q926。在一些实施例中,分离的多肽包含以下氨基酸取代中的一个或多个:d23a、y128v、t67l、n497a、d1251g、r661a、q695a、和/或q926a。在一些实施例中,分离的多肽包含以下氨基酸取代:d23a/y128v/d1251g/t67l。在另一方面,本披露提供了融合蛋白,其包含与异源功能域以及任选的间插接头融合的本文所述的分离的多肽,其中所述接头不干扰融合蛋白的活性。在一些实施例中,异源功能域选自由以下组成的组:vp64、nf-κbp65、krueppel相关框(krab)域、erf阻遏域(erd)、msin3a相互作用域(sid)、异染色质蛋白1(hp1)、dna甲基转移酶(dnmt)、tet蛋白、组蛋白乙酰转移酶(hat)、组蛋白脱乙酰酶(hdac)、组蛋白甲基转移酶(hmt)、或组蛋白脱甲基酶(hdm)、ms2、csy4、λn蛋白和foki。在另一方面,本披露特征在于基因组编辑系统,其包含本文所述的分离的多肽。在另一方面,本披露特征在于编码本文所述的分离的多肽的核酸。在另一方面,本披露特征在于包含核酸的载体。在另一方面,本披露特征在于组合物,其包含本文所述的分离的多肽、本文所述的基因组编辑系统、本文所述的核酸和/或本文所述的载体、以及任选地药学上可接受的运载体。在另一方面,本披露特征在于改变细胞的方法,其包括使细胞与这种组合物接触。在另一方面,本披露特征在于治疗患者的方法,其包括向患者施用这种组合物。在另一方面,本披露特征在于多肽,其包含与seqidno:13至少约80%相同(例如,至少约85%、90%、92%、94%、95%、96%、97%、98%、或99%相同),并在seqidno:13的位置d23、t67、y128和d1251中的一个或多个处具有氨基酸取代的氨基酸序列。在一些实施例中,多肽在d23处包含氨基酸取代。在一些实施例中,多肽在d23处包含氨基酸取代,并且在t67、y128或d1251处包含至少一个氨基酸取代。在一些实施例中,多肽在d23处包含氨基酸取代,并且在t67、y128或d1251处包含至少两个取代。在一些实施例中,多肽在t67处包含氨基酸取代。在一些实施例中,多肽在t67处包含氨基酸取代,并且在d23、y128或d1251处包含至少一个氨基酸取代。在一些实施例中,多肽在t67处包含氨基酸取代,并且在d23、y128或d1251处包含至少两个取代。在一些实施例中,多肽在y128处包含氨基酸取代。在一些实施例中,多肽在y128处包含氨基酸取代,并且在d23、t67或d1251处包含至少一个氨基酸取代。在一些实施例中,多肽在y128处包含氨基酸取代,并且在d23、t67或d1251处包含至少两个取代。在一些实施例中,多肽在d1251处包含氨基酸取代。在一些实施例中,多肽在d1251处包含取代,并且在d23、t67或y128处包含至少一个氨基酸取代。在一些实施例中,多肽在d1251处包含氨基酸取代,并且在d23、t67或y128处包含至少两个取代。在一些实施例中,多肽在d23、t67、y128和d1251处包含氨基酸取代。在一些实施例中,多肽还包含至少一个另外的本文所述的氨基酸取代。在一些实施例中,当多肽与靶双链dna(dsdna)接触时,脱靶编辑率(rateofoff-targetediting)低于观察到的野生型spcas9对靶标的脱靶编辑率。在一些实施例中,多肽的脱靶编辑率比野生型spcas9的低约5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%或95%。在一些实施例中,脱靶编辑率是通过评估脱靶位点处的插入缺失(indel)的水平(例如,小数或百分比)来测量的。在另一方面,本披露特征在于融合蛋白,其包含多肽和核定位序列、细胞穿透肽序列和/或亲和标签中的一个或多个。在另一方面,本披露特征在于融合蛋白,其包含与异源功能域以及任选的间插接头融合的融合多肽,其中所述接头不干扰融合蛋白的活性。在一些实施例中,异源功能域是转录反式激活域。在一些实施例中,转录反式激活域来自vp64或nfk-bp65。在一些实施例中,异源功能域是转录沉默子或转录抑制域。在一些实施例中,转录抑制域是krueppel相关盒(krab)域、erf阻遏域(erd)或msin3a相互作用域(sid)。在一些实施例中,转录沉默子是异染色质蛋白1(hp1)。在一些实施例中,异源功能域是修饰dna的甲基化状态的酶(例如,dna甲基转移酶(dnmt)或tet蛋白)。在一些实施例中,tet蛋白是teti。在一些实施例中,异源功能域是修饰组蛋白亚基的酶(例如,组蛋白乙酰转移酶(hat)、组蛋白脱乙酰酶(hdac)、组蛋白甲基转移酶(hmt)或组蛋白脱甲基酶)。在一些实施例中,异源功能域是生物系链(例如,ms2、csy4或λn蛋白)。在一些实施例中,异源功能域是fokl。在另一方面,本披露特征在于编码本文所述多肽的分离的核酸。在另一方面,本披露特征在于包含此类分离的核酸的载体。在另一方面,本披露特征在于包含此类载体的宿主细胞。在另一方面,本披露特征在于多肽,其包含与seqidno:13至少约80%相同(例如,至少约85%、90%、92%、94%、95%、96%、97%、98%、或99%相同)的氨基酸序列,并包含以下氨基酸取代中的一个或多个:d23a、t67l、y128v和d1251g。在一些实施例中,多肽包含d23a;和/或多肽包含d23a和t67l、y128v和d1251g中的至少一个;和/或多肽包含d23a和t67l、y128v和d1251g中的至少两个;和/或多肽包含t67l;和/或多肽包含t67l和d23a、y128v和d1251g中的至少一个;和/或多肽包含t67l和d23a、y128v和d1251g中的至少两个;和/或多肽包含y128v;和/或多肽包含y128v和d23a、t67l和d1251g中的至少一个;和/或多肽包含y128v和d23a、t67l和d1251g中的至少两个;和/或多肽包含d1251g;和/或多肽包含d1251g和d23a、t67l和y128v中的至少一个;和/或多肽包含d1251g和d23a、t67l和y128v中的至少两个;和/或多肽包含d23a、t67l、y128v和d1251g。在一些实施例中,多肽与靶双链dna(dsdna)靶标接触时,脱靶编辑率低于观察到的野生型spcas9对靶标的脱靶编辑率。在一些实施例中,多肽的脱靶编辑率比野生型spcas9的低约5%、10%、15%、20%、30%、40%、50%、60%、70%、80%、90%或95%。在一些实施例中,脱靶编辑率是通过评估脱靶位点处的插入缺失的水平(例如,小数或百分比)来测量的。在另一方面,本披露特征在于融合蛋白,其包含多肽和核定位序列、细胞穿透肽序列和/或亲和标签中的一个或多个。在另一方面,本披露特征在于融合蛋白,其包含与异源功能域以及任选的间插接头融合的融合多肽,其中所述接头不干扰融合蛋白的活性。在一些实施例中,异源功能域是转录反式激活域(例如,来自vp64或nfk-bp65的反式激活域)。在一些实施例中,异源功能域是转录沉默子或转录抑制域(例如,krueppel相关盒(krab)域、erf阻遏域(erd)或msin3a相互作用域(sid))。在一些实施例中,转录沉默子是异染色质蛋白1(hp1)。在一些实施例中,异源功能域是修饰dna的甲基化状态的酶(例如,dna甲基转移酶(dnmt)或tet蛋白)。在一些实施例中,tet蛋白是teti。在一些实施例中,异源功能域是修饰组蛋白亚基的酶(例如,组蛋白乙酰转移酶(hat)、组蛋白脱乙酰酶(hdac)、组蛋白甲基转移酶(hmt)或组蛋白脱甲基酶)。在一些实施例中,异源功能域是生物系链(例如,ms2、csy4或λn蛋白)。在一些实施例中,异源功能域是fokl。在另一方面,本披露特征在于编码此类多肽的分离的核酸。在另一方面,本披露特征在于包含此类分离的核酸的载体。在另一方面,本披露特征在于包含此类载体的宿主细胞。在另一方面,本披露特征在于对细胞群进行基因工程的方法,所述方法包括在所述细胞中表达本披露的多肽(例如,本文所述的变体核酸酶)以及指导核酸或使所述细胞与所述多肽以及指导核酸接触,从而改变所述细胞中至少多个的基因组,所述指导核酸具有与所述细胞的基因组的靶核酸上的靶序列互补的区域。在一些实施例中,多肽的脱靶编辑率低于观察到的野生型spcas9对靶序列的脱靶编辑率。在一些实施例中,多肽的脱靶编辑率比野生型spcas9的低约5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%或95%。在一些实施例中,脱靶编辑率是通过评估脱靶位点处的插入缺失的水平(例如,小数或百分比)来测量的。在一些实施例中,多肽和指导核酸以核糖核酸蛋白(rnp)施用。在一些实施例中,rnp以1x10-4μm至1μmrnp的剂量施用。在另一方面,本披露特征在于编辑双链dna(dsdna)分子的群体的方法,所述方法包括使dsdna分子与本披露的多肽(例如,本文所述的变体核酸酶)以及指导核酸和指导核酸接触,从而对多个所述dsdna分子进行编辑,所述指导核酸具有与所述dsdna分子的靶序列互补的区域。在一些实施例中,多肽的脱靶编辑率低于观察到的野生型spcas9对靶序列的脱靶编辑率。在一些实施例中,多肽的脱靶编辑率比野生型spcas9的低约5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%或95%。在一些实施例中,脱靶编辑率是通过评估脱靶位点处的插入缺失的水平(例如,小数或百分比)来测量的。在一些实施例中,多肽和指导核酸以核糖核酸蛋白(rnp)施用。在一些实施例中,rnp以1x10-4μm至1μmrnp的剂量施用。附图说明图1描述了如实例1所述获得的高选择的cas9突变体的体外裂解物切割测定的结果。突变体表现出仅在cord6靶标上切割,而野生型酶有效地裂解两个靶标(即cord6靶标和野生型靶标)。对应于切割产物的条带由三角形表示。图2显示了一个示意图,概述了针对显示已知脱靶位点处活性的核酸酶进行选择的进化策略。在每个循环中,通过诱变方法生成文库,然后对中靶切割进行一轮阳性选择,之后针对包含不同脱靶位点的合并的噬菌体进行一轮阴性选择。图3描述了示例性cas9文库质粒和pselect靶噬菌粒。图4描述了使用靶向和非靶向cas9以及tse2作为阳性选择剂进行阳性选择的示例性结果。图5描述了使用野生型cas9和具有tse2作为阳性选择剂的突变体cas9的文库进行阳性选择的示例性结果。图6描述了用氯霉素(“cm”)作为阴性选择剂,使用野生型cas9和突变体cas9的文库的阴性选择的示例性结果。图7描绘了野生型cas的阳性和阴性选择的连续轮次以进化选择性cas9突变体的示例性结果。图8a和8b描述了使用中靶序列底物(图8a)和在四个位置与中靶底物不同的脱靶底物(图8b)的生化切割测定的结果。图9a和9b描述了体内切割测定的结果,其中在用增加剂量的cas9/指导rna核糖核蛋白复合物(rnp)浓度处理的t细胞中评估中靶基因组序列(图9a)和已知脱靶基因组序列(图9b)的切割。图10描述了在单一rnp浓度下在图9a和9b中描绘的t细胞实验中的中靶切割与脱靶切割的比率。图11描述了通过密码子位置并根据氨基酸取代,酿脓链球菌cas9多肽中突变的频率。图12描绘了体外编辑测定的结果,其中在用增加剂量的野生型酿脓链球菌cas9或变体cas9/指导rna核糖核蛋白复合物(rnp)处理的人t细胞中评估中靶基因组序列和已知的脱靶基因组序列的切割。图13描述了体外编辑测定的结果,其中在用包含野生型酿脓链球菌cas9(wtspcas9)或三种不同变体cas9蛋白之一的rnp处理的人t细胞中评估了中靶基因组序列的切割。图14a-14c描绘了体外编辑测定的结果,其中在用增加剂量的包含野生型或变体cas9蛋白的rnp处理的人t细胞中评估了三个中靶基因组序列的切割。图15a和15b描绘了体外编辑测定的结果,其中在用增加剂量的野生型酿脓链球菌cas9(“spcas9”)或三种不同变体cas9之一/指导rna核糖核蛋白复合物(rnp)处理的人t细胞中评估中靶基因组序列(图15a)和已知的脱靶基因组序列(图15b)的切割。图16显示了一个示意图,概述了针对显示已知脱靶位点处活性的核酸酶进行选择的进化策略。通过诱变生成cas9突变体的噬菌粒文库,然后对中靶切割进行一轮阳性选择,之后对脱靶切割进行一轮阴性选择。图17显示了酿脓链球菌和脑膜炎奈瑟氏球菌cas9序列的比对。图18a和18b描述了野生型cas9和两种cas9变体的脱靶切割。具体实施方式定义在整个说明书中,采用了以下段落中定义的几个术语。在本说明书的正文中还可以找到其他定义。如本文所用,在本文中关于数值使用的术语“约”和“大约”包括在任一方向上落在(大于或小于)所述数值的20%、10%、5%或1%范围内的数值,除非另有说明或从上下文中明显看出为其他情况(这种数值将超过可能值的100%的情况除外)。如本文所用,术语“切割(cleavage)”是指dna分子的共价主链的断裂。切割可通过多种方法引发,包括但不限于磷酸二酯键的酶促水解或化学水解。单链切割和双链切割都是可能的,并且由于两个独立的单链切割事件的结果,可能发生双链切割。dna切割可导致产生平末端或粘性末端。如本文所用,“保守取代”是指在以下组内的氨基酸之中进行的氨基酸的取代:i)蛋氨酸、异亮氨酸、亮氨酸、缬氨酸,ii)苯丙氨酸、酪氨酸、色氨酸,iii)赖氨酸、精氨酸、组氨酸,iv)丙氨酸、甘氨酸,v)丝氨酸、苏氨酸,vi)谷氨酰胺、天冬酰胺和vii)谷氨酸、天冬氨酸。在一些实施例中,保守氨基酸取代是指不改变在其中进行氨基酸取代的蛋白质的相对电荷或大小特征的氨基酸取代。如本文所用,“融合蛋白”是指通过两个或更多个最初分离的蛋白或其部分的连接而产生的蛋白。在一些实施例中,接头或间隔子将存在于每种蛋白质之间。.如本文所用,关于多肽域的术语“异源的”是指多肽域并非天然地一起存在(例如,在同一多肽中)的事实。例如,在人工产生的融合蛋白中,来自一个多肽的多肽域可以与来自不同多肽的多肽域融合。这两个多肽域相对于彼此而言被认为是“异源的”,因为它们并非天然地一起存在。如本文所用,术语“宿主细胞”是根据本发明操纵的细胞,例如,将核酸引入其中的细胞。“转化的宿主细胞”是已经经历转化以使其吸收了外源物质,例如外源遗传物质,例如外源核酸的细胞。如本文所用,术语“同一性”是指聚合物分子之间,例如核酸分子(例如dna分子和/或rna分子)之间和/或多肽分子之间的总体相关性。在一些实施例中,如果聚合物分子的序列为至少25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、95%或99%相同,则认为它们彼此“基本上相同”。例如,两个核酸或多肽序列的同一性百分比计算可通过出于最佳比较目的比对两个序列来进行(例如,对于最佳比对,可以在第一和第二序列中的一个或两个中引入缺口;而出于比较目的,可以忽略不相同的序列)。在某些实施例中,为了比较目的而比对的序列的长度是参考序列长度的至少30%、至少40%、至少50%、至少60%、至少70%、至少80%、至少90%、至少95%或基本上100%。然后比较在相应位置的核苷酸。序列的比较和两个序列之间同一性百分比的确定可以使用数学算法来完成。如本领域众所周知的,可以使用多种算法中的任何一种来比较氨基酸或核酸序列,包括可在商业计算机程序中获得的那些算法,例如用于核苷酸序列的blastn和用于氨基酸序列的blastp、有缺口的blast和psi-blast。示例性的此类程序描述于以下中:altschul等人,basiclocalalignmentsearchtool[基本局部比对搜索工具],j.mol.biol.[分子生物学杂志],215(3):403-410,1990;altschul等人,methodsinenzymology[酶学方法];altschul等人,nucleicacidsres.[核酸研究]25:3389-3402,1997;baxevanis等人,bioinformatics:apracticalguidetotheanalysisofgenesandproteins[生物信息学:基因和蛋白质分析实用指南],威利出版社(wiley),1998;和misener等人,(编辑),bioinformaticsmethodsandprotocols(methodsinmolecularbiology,vol.132),[生物信息学方法和方案(分子生物学方法第132卷)]瑚玛娜出版社(humanapress),1999。如本文在多核苷酸的上下文中所使用的,术语“文库”是指两个或更多个不同的多核苷酸的群体。在一些实施例中,文库包含至少两个包含编码核酸酶的不同序列的多核苷酸和/或至少两个包含编码指导rna的不同序列的多核苷酸。在一些实施例中,文库包括至少101、至少102、至少103、至少104、至少105、至少106、至少107、至少108、至少109、至少1010、至少1011、至少1012、至少1013、至少1014、或至少1015个不同的多核苷酸。在一些实施例中,文库的成员可以包含随机序列,例如完全或部分随机序列。在一些实施例中,文库包含彼此不相关的多核苷酸,例如包含完全随机序列的核酸。在其他实施例中,文库的至少一些成员可以是相关的,例如,它们可以是特定序列的变体或衍生物。如本文所用,术语“可操作地连接”是指并置,其中所描述的组分处于允许它们以其预期方式发挥功能的关系中。与功能元件“可操作地连接”的调节元件以这样的方式相关联:在与调节元件相容的条件下实现功能元件的表达和/或活性。在一些实施例中,“可操作地连接”的调节元件与目的编码元件是相连的(例如,共价连接的);在一些实施例中,调节元件反式作用于目的功能元件或以其他方式起作用。如本文所用,术语“核酸酶”是指能够切割核酸的核苷酸亚基之间的磷酸二酯键的多肽;术语“核酸内切酶”是指能够切割多核苷酸链内的磷酸二酯键的多肽。如本文所用,术语“核酸”、“核酸分子”或“多核苷酸”在本文可互换使用。它们是指单链或双链形式的脱氧核糖核苷酸或核糖核苷酸的聚合物,并且除非另有说明,否则包括能以与天然存在的核苷酸相似的方式起作用的天然核苷酸的已知类似物。所述术语涵盖具有合成骨架的核酸样结构,以及扩增产物。dna和rna两者都是多核苷酸。聚合物可包括天然核苷(即腺苷、胸苷、鸟苷、胞苷、尿苷、脱氧腺苷、脱氧胸苷、脱氧鸟苷和脱氧胞苷),核苷类似物(例如2-氨基腺苷、2-硫代胸苷、肌苷、吡咯并嘧啶、3-甲基腺苷、c5-丙炔基胞苷、c5-丙炔基尿苷、c5-溴尿苷、c5-氟尿苷、c5-碘尿苷、c5-甲基胞嘧啶、7-脱氮杂腺苷、7-脱氮鸟苷、8-氧代腺苷、8-氧代鸟苷、o(6)-甲基鸟嘌呤和2-硫代胞苷),化学修饰的碱基,生物修饰的碱基(例如甲基化的碱基),插层的碱基,修饰的糖(例如2’-氟核糖、核糖、2’-脱氧核糖、阿拉伯糖和己糖)或经修饰的磷酸基团(例如,硫代磷酸和5’-n-亚磷酰胺键)。如本文所用,术语“寡核苷酸”是指一串核苷酸或其类似物。寡核苷酸可以通过许多方法获得,包括例如化学合成、限制酶消化或pcr。如本领域技术人员将理解的,寡核苷酸的长度(即,核苷酸的数目)可以广泛地变化,这通常取决于寡核苷酸的预期功能或用途。在整个说明书中,每当寡核苷酸由字母序列表示(选自四个碱基字母:a、c、g和t,分别代表腺苷、胞苷、鸟苷和胸苷)时,核苷酸从左到右均以5’到3’的顺序显示。在某些实施例中,寡核苷酸的序列包括一个或多个本文所述的简并残基。如本文所用,术语“脱靶”是指rna指导的核酸酶对dna的非预料或非预期区域的结合、切割和/或编辑。在一些实施例中,当dna区域与打算或预期结合、切割和/或编辑的dna区域相差1、2、3、4、5、6、7或更多个核苷酸时,其是脱靶区域。如本文所用,术语“中靶”是指rna指导的核酸酶对dna的预料或预期区域的结合、切割和/或编辑。如本文所用,术语“多肽”通常具有其本领域公认的氨基酸聚合物的含义。此术语也用于指多肽的特定功能类别,例如像核酸酶、抗体等。如本文所用,术语“调节元件”是指控制或影响基因表达的一个或多个方面的dna序列。在一些实施例中,调节元件是或包括启动子、增强子、沉默子和/或终止信号。在一些实施例中,调节元件控制或影响诱导型表达。如本文所用,术语“靶位点”是指限定结合分子将结合的核酸的一部分的核酸序列,条件是存在足以结合的条件。在一些实施例中,靶位点是本文所述的核酸酶与之结合和/或被这种核酸酶切割的核酸序列。在一些实施例中,靶位点是本文所述的指导rna与之结合的核酸序列。靶位点可以是单链或双链的。在二聚化的核酸酶(例如,包含fokldna切割域的核酸酶)的背景下,靶位点通常包含左半位点(与核酸酶的一个单体结合)、右半位点(与核酸酶的第二个单体结合)和在其中进行切割的两个半位点之间的间隔序列。在一些实施例中,左半位点和/或右半位点长度在10-18个核苷酸之间。在一些实施例中,两个半位点中的一个或两个较短或较长。在一些实施例中,左半位点和右半位点包含不同的核酸序列。在锌指核酸酶的背景下,在一些实施例中,靶位点可包含两个半位点,每个半位点的长度为6-18bp,侧翼为4-8bp长的未指定的间隔区。在talen的情况下,在一些实施例中,靶位点可包括两个半位点位点,每个半位点位点的长度为10-23bp,侧翼为10-30bp长的未指定的间隔区。在rna指导的(例如,rna可编程的)核酸酶的背景下,靶位点通常包含与rna可编程的核酸酶的指导rna互补的核苷酸序列,以及邻近于指导rna互补序列的3’末端或5’末端处的原型间隔子邻近基序(pam)。对于rna指导的核酸酶cas9,在一些实施例中,靶位点可以是16-24个碱基对加上3-6个碱基对的pam(例如,nnn,其中n代表任何核苷酸)。rna指导的核酸酶、例如cas9的示例性靶位点是本领域技术人员已知的、并且包括但不限于nng、ngn、nag、nga、ngg、ngag和ngcg,其中n代表任何核苷酸。另外,来自不同物种(例如嗜热链球菌而不是酿脓链球菌)的cas9核酸酶识别包含序列nggng的pam。已知另外的pam序列,包括但不限于nnagaaw和naar(参见,例如,esvelt和wang,molecularsystemsbiology[分子系统生物学],9:641(2013),其全部内容通过援引并入本文)。例如,rna指导的核酸酶例如像cas9的靶位点可以包含[nz]-[pam]结构,其中每个n独立地是任何核苷酸,且z是1到50之间的整数。在一些实施例中,z是至少2、至少3、至少4、至少5、至少6、至少7、至少8、至少9、至少10、至少11、至少12、至少13、至少14、至少15、至少16、至少17、至少18、至少19、至少20、至少25、至少30、至少35、至少40、至少45、或至少50。在一些实施例中,z是5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、或50。在一些实施例中,z是20。如本文所用,术语“变体”是指这样的实体,其与参考实体(例如,野生型序列)显示出显著的结构同一性,但是在一个或多个化学部分的存在或水平下与参考实体相比在结构上不同。在许多实施例中,变体在功能上也与其参考实体不同。通常,特定实体是否被恰当地视为参考实体的“变体”是基于其与参考实体的结构同一性程度。如本领域技术人员将理解的,任何生物学或化学参考实体都具有某些特征性结构元件。根据定义,变体是共有一个或多个此类特征性结构元件的独特化学实体。仅举几个实例,多肽可具有特征性序列元件,所述特征性序列元件包含在线性或三维空间中相对于彼此具有指定位置和/或有助于特定生物学功能的多个氨基酸;核酸可具有特征性序列元件,所述特征性序列元件包含在线性或三维空间中相对于另一个具有指定位置的多个核苷酸残基。例如,由于氨基酸序列的一个或多个差异和/或共价附接于多肽主链的化学部分(例如,碳水化合物、脂质等)的一个或多个差异,变体多肽可以不同于参考多肽。在一些实施例中,变体多肽显示与参考多肽(例如,本文所述的核酸酶)至少60%、65%、70%、75%、80%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%的总体序列同一性。可替代地或另外地,在一些实施例中,变体多肽不与参考多肽共享至少一个特征序列元件。在一些实施例中,参考多肽具有一种或多种生物学活性。在一些实施例中,变体多肽共享参考多肽的一种或多种生物学活性,例如核酸酶活性。在一些实施例中,变体多肽缺乏参考多肽的生物学活性中的一种或多种。在一些实施例中,与参考多肽相比,变体多肽显示降低水平的一种或多种生物学活性(例如,核酸酶活性,例如脱靶核酸酶活性)。在一些实施例中,如果目的多肽除特定位置处具有少量序列改变之外具有与亲本相同的氨基酸序列,则认为所述目的多肽是亲本或参考多肽的“变体”。通常,与亲本相比,变体中少于20%、15%、10%、9%、8%、7%、6%、5%、4%、3%、2%的残基被取代。在一些实施例中,变体与亲本相比具有10、9、8、7、6、5、4、3、2或1个取代的残基。通常,变体具有很少数量(例如,少于5、4、3、2或1个)数量的取代的功能残基(即,参与特定生物活性的残基)。在一些实施例中,与亲本相比,变体具有不超过5、4、3、2或1个添加或缺失,并且通常不具有添加或缺失。此外,任何添加或缺失典型地小于约25、约20、约19、约18、约17、约16、约15、约14、约13、约10、约9、约8、约7、约6个残基,并且通常少于约5、约4、约3或约2个残基。在一些实施例中,亲本或参考多肽是天然存在的。概述本披露部分地涵盖发现rna指导的核酸酶相对于野生型核酸酶表现出对靶向dna序列的改进的特异性。本文提供了此类rna指导的核酸酶变体、包含此类核酸酶变体的组合物和系统、以及产生此类核酸酶变体的方法和使用此类核酸酶变体例如编辑一个或多个靶核酸的方法。rna指导的核酸酶根据本披露的rna指导的核酸酶包括但不限于天然存在的2类的crispr核酸酶,例如cas9和cpf1,以及由其衍生或获得的其他核酸酶。例如,从其衍生或获得的其他核酸酶包括变体核酸酶。在一些实施例中,变体核酸酶包含一种或多种改变的酶学性质,例如改变的核酸酶活性或改变的解旋酶活性(如与天然存在的或其他参考核酸酶分子(包括已经被工程化或改变的核酸酶分子相比))。在一些实施例中,变体核酸酶可以具有切口酶活性或没有切割活性(与双链核酸酶活性相反)。在另一个实施例中,变体核酸酶具有改变其大小的改变,例如减小其大小的氨基酸序列的缺失(例如,对一种或多种或对任何核酸酶活性具有或不具有显著影响)。在另一个实施例中,变体核酸酶可以识别不同的pam序列。在一些实施例中,不同的pam序列是除参考核酸酶的内源性野生型pi域识别的pam序列以外的pam序列,例如非典型序列。在功能方面,rna指导的核酸酶被定义为如下的那些核酸酶:(a)与grna相互作用(例如复合);和(b)与grna一起缔合或任选地切割或修饰dna的靶区域,所述靶区域包含(i)与grna的靶向域互补的序列,以及任选地,(ii)称为“原型间隔子邻近基序”或“pam”的另一序列,其更详细地描述于下文中。rna指导的核酸酶在广义上可以由其pam特异性和切割活性来定义,尽管在共享相同pam特异性或切割活性的各个rna指导的核酸酶之间可能存在变异。技术人员将了解,本披露的一些方面涉及可以使用具有某种pam特异性和/或切割活性的任何适宜rna指导的核酸酶实施的系统、方法和组合物。为此,除非另外指明,否则术语rna指导的核酸酶应理解为通用术语,并不限于rna指导的核酸酶的任何特定类型(例如,cas9与cpf1)、种类(例如,酿脓链球菌与金黄色葡萄球菌)或变体(例如,全长与截短或分裂;天然存在的pam特异性与工程化pam特异性等)。pam序列的名称来源于其与“原型间隔子”序列的顺序关系,所述原型间隔子序列与grna靶向域(或“间隔子”)互补。与原型间隔子一起,pam序列定义特定rna指导的核酸酶/grna组合的靶区域或序列。多种rna指导的核酸酶可能需要pam与原型间隔子之间的不同顺序关系。通常,如相对于指导rna靶向域可视化的,cas9识别原型间隔子3’的pam序列。另一方面,cpf1通常识别原型间隔子5’的pam序列。除了识别pam和原型间隔子的特定顺序定向以外,rna指导的核酸酶还可以识别特定pam序列。例如,金黄色葡萄球菌cas9识别nngrrt或nngrrv的pam序列,其中n个残基紧靠由grna靶向域所识别区域的3’。酿脓链球菌cas9识别nggpam序列。并且新凶手弗朗西斯菌(f.novicida)cpf1识别ttnpam序列。已鉴别多种rna指导的核酸酶的pam序列,并且鉴别新颖pam序列的策略已描述于shmakov等人,2015,molecularcell[分子细胞]60,385-397,2015年11月5日中。还应注意,工程化rna指导的核酸酶可具有与参考分子的pam特异性不同的pam特异性(例如,在工程化rna指导的核酸酶的情形中,参考分子可以是衍生出rna指导的核酸酶的天然存在的变体,或与工程化rna指导的核酸酶具有最大氨基酸序列同源的天然存在的变体)。除了其pam特异性以外,rna指导的核酸酶可通过其dna切割活性来表征:天然存在的rna指导的核酸酶典型地在靶核酸中形成dsb,但是已产生仅生成ssb的工程化变体(上文所讨论)(ran和hsu等人,cell[细胞]154(6),1380-1389,2013年9月12日(“ran”),通过援引并入本文),或完全不切割的工程化变体。cas9已确定酿脓链球菌cas9的晶体结构(jinek等人,science[科学]343(6176),1247997,2014(“jinek2014”),以及与单分子指导rna和靶dna复合的金黄色葡萄球菌cas9的晶体结构(nishimasu2014;anders等人,nature[自然].2014年9月25日;513(7519):569-73(“anders2014”);和nishimasu2015)。天然存在的cas9蛋白包含两个叶:识别(rec)叶和核酸酶(nuc)叶;每一叶包含特定的结构和/或功能域。rec叶包含富精氨酸桥螺旋(bh)域,以及至少一个rec域(例如rec1域和任选地rec2域)。rec叶与其他已知蛋白不共享结构相似性,指示其是独特的功能域。不希望受限于任何理论,突变分析提出bh和rec域的特殊功能作用:bh域似乎在grna:dna识别中起作用,而rec域被认为与grna的重复:抗重复双链体相互作用并且介导cas9/grna复合物的形成。nuc叶包含ruvc域、hnh域和pam相互作用(pi)域。ruvc域与逆转录病毒整合酶超家族成员共享结构相似性,并且切割靶核酸的非互补(即底部)链。其可从两个或更多个分裂ruvc基序(例如酿脓链球菌和金黄色葡萄球菌中的ruvci、ruvcii和ruvciii)形成。同时,hnh域在结构上与hnn内切核酸酶基序类似,并且切割靶核酸的互补(即顶部)链。顾名思义,pi域有助于pam特异性。虽然cas9的某些功能与上文所述的特定域相关(但不一定完全取决于所述域),但这些和其他功能可以由其他cas9域或任一叶上的多个域来介导或影响。例如,在酿脓链球菌cas9中,如在nishimasu2014中所述,grna的重复:抗重复双链体落在rec叶与nuc叶之间的沟中,并且双链体中的核苷酸与bh、pi和rec域中的氨基酸相互作用。第一茎环结构中的一些核苷酸也与多个域(pi、bh和rec1)中的氨基酸相互作用,第二和第三茎环(ruvc和pi域)中的一些核苷酸也是如此。变体cas9核酸酶本披露包括例如相对于野生型核酸酶对其靶标具有增加的特异性水平的变体rna指导的核酸酶。例如,相对于野生型核酸酶,本披露的变体rna指导的核酸酶表现出增加水平的中靶结合、编辑和/或切割活性。另外地或可替代地,相对于野生型核酸酶,本披露的变体rna指导的核酸酶表现出降低水平的脱靶结合、编辑和/或切割活性。本文所述的变体核酸酶包括酿脓链球菌cas9和脑膜炎奈瑟氏球菌(neisseriameningitidis或n.meningitidis)(seqidno:14)的变体。野生型酿脓链球菌cas9的氨基酸序列作为seqidno:13提供。相对于野生型核酸酶,变体核酸酶可以在单个位置或多个位置,例如在2、3、4、5、6、7、8、9、10或更多个位置处包含氨基酸取代。在一些实施例中,变体核酸酶包含与野生型核酸酶至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%相同的氨基酸序列。一种或多种野生型氨基酸可以被丙氨酸取代。另外地或可替代地,一种或多种野生型氨基酸可以被保守的变体氨基酸取代。另外地或可替代地,一种或多种野生型氨基酸可以被非保守的变体氨基酸取代。例如,相对于野生型核酸酶(例如,seqidno:13),本文所述的变体核酸酶可以包含在以下位置中的一、二、三、四、五、六、七或全部八个处的取代:d23、d1251、y128、t67、n497、r661、q695和/或q926(例如,这些位置中一个或所有位置处的丙氨酸保守和/或非保守取代)。相对于野生型核酸酶,示例性变体核酸酶可包含以下取代中的一、二、三、四、五、六、七或全部八个:d23a、d1251g、y128v、t67l、n497a、r661a、q695a和/或q926a。相对于野生型核酸酶,本披露的特定核酸酶变体包含以下取代:d23a、d1251g、y128v和t67l。在一些实施例中,变体核酸酶包含与seqidno:13至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%相同并包括以下取代中的一、二、三、四、五、六、七或全部八个的氨基酸序列:d23a、d1251g、y128v、t67l、n497a、r661a、q695a和/或q926a。例如,变体核酸酶可包含与seqidno:13至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%相同并包括以下取代的氨基酸序列:d23a、d1251g、y128v和t67l。除了在d23、d1251、y128、t67、n497、r661、q695和/或q926的一、二、三、四、五、六、七或全部八个处的取代(例如,d23a、d1251g、y128v、和t67l),酿脓链球菌cas9变体还可以在以下位置中的一个或多个处包括取代:l169;y450;m495;w659;m694;h698;a728;e1108;v1015;r71;y72;r78;r165;r403;t404;f405;k1107;s1109;r1114;s1116;k1118;d1135;s1136;k1200;s1216;e1219;r1333;r1335;t1337;y72;r75;k76;l101;s104;f105;r115;h116;i135;h160;k163;y325;h328;r340;f351;d364;q402;r403;i1110;k1113;r1122;y1131;r63;r66;r70;r71;r74;r78;r403;t404;n407;r447;i448;y450;k510;y515;r661;v1009;y1013;k30;k33;n46;r40;k44;e57;t62;r69;n77;l455;s460;r467;t472;i473;h721;k742;k1097;v1100;t1102;f1105;k1123;k1124;e1225;q1272;h1349;s1351;和/或y1356,例如美国专利9,512,446中所述的取代。在一些实施例中,酿脓链球菌变体可以在以下位置中的一个或多个处包括取代:n692、k810、k1003、r1060和g1218。在一些实施例中,酿脓链球菌变体包括以下取代中的一个或多个:n692a、k810a、k1003a、r1060a和g1218r。表1列出了根据本披露的某些实施例的示例性酿脓链球菌cas9突变体,其包含3至5个取代。为了清楚起见,本披露涵盖在本披露的上文和其他地方列出的位点中的1、2、3、4、5或更多个位点处具有突变的cas9变体蛋白。示例性的三、四、五突变体在表1中给出并且描述于以下中,例如chen等人,nature[自然]550:407-410(2017);slaymake等人,science[科学]351:84-88(2015);kleinstiver等人,nature[自然]529:490-495;kleinstiver等人,nature[自然]523:481-485(2015);kleinstiver等人,naturebiotechnology[自然生物技术]33:1293-1298(2015)。表1:位置d1135v/r1335q/t1337rd1135e/r1335q/t1337rd1135v/g1218r/r1335e/t1337rn497a/r661a/q695a/q926ad1135e/n497a/r661a/q695a/q926an497a/r661a/q695a/q926a/l169an497a/r661a/q695a/q926a/y450ak810a/k1003a/r1060ak848a/k1003a/r1060an692a/m694a/q695a/h698a酿脓链球菌cas9变体还可以包括会降低或破坏cas9的核酸酶活性的一个或多个氨基酸取代基:d10、e762、d839、h983或d986和h840或n863。例如,酿脓链球菌cas9可包括氨基酸取代d10a/d10n和h840a/h840n/h840y,以使蛋白质的核酸酶部分催化失活。这些位置处的取代基可以是丙氨酸或其他残基,例如谷氨酰胺、天冬酰胺、酪氨酸、丝氨酸或天冬氨酸,例如e762q、h983n、h983y、d986n、n863d、n863s或n863h(nishimasu等人,cell[细胞]156,935-949(2014);wo2014/152432)。在一些实施例中,变体在d10a或h840a处包含单个氨基酸取代,其产生单链切口酶。在一些实施例中,变体多肽在d10a和h840a处包括使核酸酶活性失活的氨基酸取代(例如,称为死亡cas9或dcas9)。本文所述的变体核酸酶还包括脑膜炎奈瑟氏球菌(n.meningitidis)的变体(hou等人,pnasearlyedition[pnas早期版]2013,1-6;通过援引并入本文)。野生型脑膜炎奈瑟氏球菌cas9的氨基酸序列作为seqidno:14提供)。脑膜炎奈瑟氏球菌和酿脓链球菌cas9序列的比较表明某些区域是保守的(参见wo2015/161276)。因此,本披露包括脑膜炎奈瑟氏球菌cas9变体,其在酿脓链球菌cas9的上下文中包括本文所述的一种或多种取代,例如在脑膜炎奈瑟球菌cas9的一个或多个对应氨基酸位置处的取代。例如,分别对应于酿脓链球菌氨基酸位置d23、d1251、y128、t67、r661、q695和/或q926的在脑膜炎奈瑟氏球菌氨基酸位置d29、d983、l101、s66、q421、e459、y671处的取代(图17)。相对于野生型核酸酶,变体脑膜炎奈瑟氏球菌核酸酶可以在单个位置或多个位置,例如在2、3、4、5、6、7、8、9、10或更多个位置处包含氨基酸取代。在一些实施例中,变体脑膜炎奈瑟氏球菌核酸酶包含与野生型核酸酶至少70%、75%、80%、85%、90%、95%、96%、97%、98%或99%相同的氨基酸序列。变体核酸酶保留了野生型核酸酶的一种或多种功能活性,例如,切割双链dna的能力、切割dna的单链的能力(例如,切口酶)、靶向dna而不切割dna的能力(例如,死亡核酸酶)、和/或与指导核酸相互作用的能力。在一些实施例中,变体核酸酶具有与野生型核酸酶相同或大约相同水平的中靶活性。在一些实施例中,变体核酸酶具有相对于野生型核酸酶而言改善的一种或多种功能活性。例如,本文所述的变体核酸酶可以表现出增加水平的中靶活性(例如相对于野生型,为10%、20%、30%、40%、50%、60%、70%、80%、90%、100%、125%、150%、175%、200%或更高)和/或降低水平的脱靶活性(例如为野生型活性的90%、80%、70%、60%、50%、40%、30%、20%、10%或5%)。在一些实施例中,当本文所述的变体核酸酶与双链dna(dsdna)(例如,靶dsdna)接触时,脱靶编辑(例如脱靶编辑率)低于野生型核酸酶对靶dsdna的观察到或测得的脱靶编辑率。例如,变体核酸酶的脱靶编辑率可以比野生型核酸酶低约5%、10%、15%、20%、25%、30%、40%、50%、60%、70%、80%、90%或95%。可以使用本领域中已知的任何方法来评估变体核酸酶的活性(例如,中靶和/或脱靶活性),例如guide-seq(指导-序列,参见例如,tsai等人(nat.biotechnol.[自然生物技术]33:187-197(2015));circle-seq(参见,例如,tsai等人,naturemethods[自然方法]14:607-614(2017));digenome-seq(参见,例如,kim等人,naturemethods[自然方法]12:237-243(2015));或chip-seq(参见,例如,o’geen等人,nucleicacidsres.[核酸研究]43:3389-3404(2015))。在一些实施例中,脱靶编辑率通过确定脱靶位点处的插入缺失的%来评估。如本领域普通技术人员众所周知的,存在用于将取代引入多肽的氨基酸序列中的多种方法。可以将编码变体核酸酶的核酸引入病毒或非病毒载体中以在宿主细胞(例如人细胞、动物细胞、细菌细胞、酵母细胞、昆虫细胞)中表达。在一些实施例中,将编码变体核酸酶的核酸可操作地连接至用于核酸酶表达的一个或多个调节域。如本领域普通技术人员将认识到的那样,合适的细菌和真核启动子是本领域众所周知的,并且描述于例如sambrook等人,molecularcloning,alaboratorymanual[分子克隆:实验室手册](2001年第3版);kriegler,genetransferandexpression:alaboratorymanual[基因转移和表达:实验室手册](1990);和currentprotocolsinmolecularbiology[分子生物学实验指南](ausubel等人编,2010)中。用于表达工程化的蛋白的细菌表达系统是在例如大肠杆菌、芽孢杆菌属物种和沙门氏菌属中可得的(paiva等人,1983,gene[基因]22:229-235)。cpf1与crrna复合的氨基酸球菌属物种(acidaminococcussp.)cpf1和包括tttnpam序列的双链(ds)dna靶标的晶体结构已经由yamano等人解析(cell[细胞].2016年5月5日;165(4):949-962(“yamano”),通过援引并入本文)。cpf1像cas9一样,具有两个叶:rec(识别)叶和nuc(核酸酶)叶。rec叶包括rec1和rec2域,其缺少与任何已知蛋白质结构的相似性。同时,nuc叶包括三个ruvc域(ruvc-i、-ii和-iii)和bh域。然而,与cas9相反,cpf1rec叶缺少hnh域,并且包括同样缺少与已知蛋白质结构的相似性的其他域:结构上独特的pi域、三个楔形(wed)域(wed-i、-ii和-iii)和核酸酶(nuc)域。虽然cas9和cpf1共享结构和功能的相似性,但应了解,某些cpf1活性是由与任何cas9域不同的结构域介导的。例如,靶dna的互补链的切割似乎是由nuc域介导,所述nuc域在顺序上和空间上与cas9的hnh域不同。另外,cpf1grna的非靶向部分(把手)采用假结(pseudoknot)结构,而不是cas9grna中由重复:抗重复双链体形成的茎环结构。编码rna指导的核酸酶的核酸本文提供编码rna指导的核酸酶(例如cas9、cpf1或其功能片段)的核酸。先前已经描述了编码rna指导的核酸酶的示例性核酸(参见,例如,cong等人,science[科学].2013年2月15日;339(6121):819-23(“cong2013”);wang等人,plosone[公共科学图书馆综合].2013年12月31日;8(12):e85650(“wang2013”);mali2013;jinek2012)。在一些情形中,编码rna指导的核酸酶的核酸可以是合成的核酸序列。例如,合成核酸分子可以经化学修饰。在某些实施例中,编码rna指导的核酸酶的mrna将具有一种或多种(例如,所有)以下特性:其可以被加帽;多聚腺苷酸化;以及经5-甲基胞苷和/或假尿苷取代。合成的核酸序列也可以经密码子优化,例如,至少一个非常见密码子或较不常见的密码子已经常见密码子替代。例如,合成核酸可以引导经优化信使mrna的合成,例如,针对在哺乳动物表达系统中的表达进行优化,例如,本文所述。密码子优化的cas9编码序列的实例呈现于wo2016/073990(“cotta-ramusino”)中。另外,或可替代地,编码rna指导的核酸酶的核酸可包含核定位序列(nls)。核定位序列是本领域中已知的。指导rna(grna)分子术语“指导rna”和“grna”是指促进rna指导的核酸酶例如cas9或cpf1与靶序列例如细胞中的基因组序列或游离序列特异性结合(或“靶向”)的任何核酸。grna可以是单分子的(包含单个rna分子,也可替代性地称为嵌合分子),或是模块化的(包含超过一个,且通常包含两个单独的rna分子,例如crrna和tracrrna,它们通常例如通过双链化相互关联)。grna及其组分在整个文献中都有描述,例如在briner等人(molecularcell[分子细胞]56(2),333-339,2014年10月23日(“briner”),将其通过援引并入本文)和在cotta-ramusino中。在细菌和古细菌中,ii型crispr系统通常包含rna指导的核酸酶蛋白(例如cas9)、包括与外来序列互补的5’区的crisprrna(crrna)和包括与crrna的3’区互补并形成双链体的5’区的反式激活crrna(tracrrna)。虽然并非旨在受限于任何理论,但认为此双链体有助于形成cas9/grna复合物,并且是所述复合物的活性所需的。在ii型crispr系统经改适用于基因编辑中时,发现crrna和tracrrna可以接合成单一单分子或嵌合指导rna,在一个非限制性实例中借助桥接crrna(在其3’末端)和tracrrna(在其5’末端)的互补区的四核苷酸(例如gaaa)“四环(tetraloop)”或“接头”序列来接合。(mali等人science.[科学]2013年2月15日;339(6121):823-826(“mali2013”);jiang等人natbiotechnol[自然生物技术].2013年3月;31(3):233-239(“jiang”);和jinek等人,2012science[科学]8月17日;337(6096):816-821(“jinek2012”),全部通过援引并入本文)。指导rna不论是单分子的或模块化的都包括“靶向域”,所述靶向域与靶序列内的靶标域完全或部分互补,所述靶序列是例如期望编辑的细胞基因组中的dna序列。靶向域在文献中通过多种名称来提及,包括但不限于“指导序列”(hsu等人,natbiotechnol.[自然生物技术]2013年9月;31(9):827-832,(“hsu”),通过援引并入本文),“互补性区”(cotta-ramusino),“间隔区”(briner),并统称为“crrna”(jiang)。不论给予其何种名称,靶向域典型地长度为10-30个核苷酸,并且在某些实施例中长度为16-24个核苷酸(例如,长度为16、17、18、19、20、21、22、23或24个核苷酸),并且在cas9grna情况下位于5’末端处或5’末端附近,并且在cpf1grna情况下位于3’末端处或3’末端附近。除了靶向域以外,grna典型地(但不一定,如下文所讨论)包括多个可影响grna/cas9复合物的形成或活性的域。例如,如上文所提及,通过grna的第一和第二互补性域形成的双链化结构(也称为重复:抗重复双链体)与cas9的识别(rec)叶相互作用,并且可以介导cas9/grna复合物的形成。(nishimasu等人,cell[细胞]156,935-949,2014年2月27日(“nishimasu2014”)和nishimasu等人,cell[细胞]162,1113-1126,2015年8月27日(“nishimasu2015”),将这两篇文献通过援引并入本文)。应注意,第一和/或第二互补性域可含有一个或多个多聚腺苷酸段,其可以由rna聚合酶识别为终止信号。因此,第一和第二互补性域的序列任选地经修饰以消除这些段,并促进grna的体外转录的完成,例如通过使用如briner中所述的a-g交换、或通过使用a-u交换来修饰。对第一和第二互补性域的这些和其他类似修饰在本披露的范围内。与第一和第二互补性域一起,cas9grna典型地包括两个或更多个其他双链化区域,该两个或更多个其他双链化区域在体内但不一定在体外参与核酸酶活性。(nishimasu2015)。在第二互补性域的3’部分附近的第一茎环一被不同地称为“近端域”(cotta-ramusino)、“茎环1”(nishimasu2014和2015)以及“连结(nexus)”(briner)。一个或多个其他茎环结构通常存在于grna的3’末端附近,其数目依物种而变:酿脓链球菌grna典型地包括2个3’茎环(总计4个茎环结构,包括重复:抗重复双链体),而金黄色葡萄球菌和其他物种仅具有一个(总计3个茎环结构)。对根据物种组织化的保守茎环结构(更通常地,和grna结构)的描述于briner中提供。虽然前述说明集中于用于cas9的grna,但应了解,已经(或可能在未来)发现或发明其他rna指导的核酸酶,其利用在一些方面与针对这一点描述的那些grna不同的grna。例如,cpf1(“来自普雷沃菌属(prevotella)和弗朗西斯菌属(franciscella)1的crispr”)是新近发现的rna指导的核酸酶,其发挥功能不需要tracrrna。(zetsche等人,2015,cell[细胞]163,759-7712015年10月22日(“zetschei”),通过援引并入本文)。用于cpf1基因组编辑系统的grna通常包括靶向域和互补性域(替代性地称为“把手”)。还应注意,在与cpf1一起使用的grna中,靶向域通常存在于3’末端处或附近,而不是如上文结合cas9grna所述的5’末端(把手位于cpf1grna的5’末端处或附近)。但本领域技术人员将了解,虽然在来自不同原核物种的grna之间或在cpf1与cas9grna之间可能存在结构差异,但grna的操作原理通常是一致的。因为这种操作一致性,grna可在广义上通过其靶向域序列来定义,并且技术人员将了解,可将给定靶向域序列并入任何适宜grna中,包括单分子或嵌合grna,或包括一种或多种化学修饰和/或序列修饰(取代、额外核苷酸、截短等)的grna。因此,为了便于呈现本披露,grna可仅在其靶向域序列方面加以描述。更通常地,技术人员将了解,本披露的一些方面涉及可以使用多个rna指导的核酸酶实施的系统、方法和组合物。为此,除非另外指定,否则术语grna应理解为不仅涵盖那些与cas9或cpf1的特定种类相容的grna,还涵盖可以用于任何rna指导的核酸酶的任何适宜grna。通过说明,在某些实施例中,术语grna可以包括与存在于2类crispr系统(例如ii型或v型或crispr系统)中的任何rna指导的核酸酶或从其衍生或改适的rna指导的核酸酶一起使用的grna。选择方法本披露还提供了基于竞争的选择策略,其将在一组条件中选择具有最大适应性的变体(例如,在变体/突变体文库中)。本发明的选择方法可用于例如定向进化策略,例如涉及一轮或多轮诱变然后进行选择的策略。在某些实施例中,与当前多肽和/或多肽进化策略通常观察到的相比,当前披露的方法允许更高通量的定向进化策略。基于与噬菌粒中dna靶位点结合的选择一方面,本披露提供基于是否结合dna靶位点来选择目的多肽或多核苷酸的版本(version)的方法。这些方法通常包括以下步骤:(a)提供多核苷酸的文库,其中所述文库中的不同多核苷酸编码不同版本的目的多肽或用作不同版本的目的多核苷酸的模板;(b)将多核苷酸的文库引入宿主细胞,使得每个转化的宿主细胞包括编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板的多核苷酸;(c)提供多种噬菌体,所述噬菌体包含编码第一选择剂并包含dna靶位点的噬菌粒;(d)在培养条件下将步骤(b)的转化的宿主细胞与多种噬菌体一起孵育,使得所述多种噬菌体感染转化的宿主细胞,其中第一选择剂的表达赋予被感染的宿主细胞以存活优势或劣势;和(e)选择在(d)中表现出存活优势(例如本文所述的存活优势)的宿主细胞。例如,步骤(d)的存活基于以下概述的各种方案。在dna靶位点的结合降低了由噬菌粒编码或包含在其上的选择剂(如本文进一步讨论的)的表达。如本文进一步讨论的,选择剂可赋予存活劣势或存活优势。通过在dna靶位点处结合介导的选择剂的转录抑制,可以发生选择剂表达的降低。在一些实施例中,通过在dna靶位点处或附近切割噬菌粒而发生选择剂(selectionagent)表达的降低。例如,目的多肽或多核苷酸既可以结合也可以切割dna。某些类型的酶与特定的dna识别位点结合,并在结合位点处或附近切割dna。因此,dna切割的位点可以与dna结合位点相同或不同。在dna切割位点不同于dna结合位点的一些实施例中,两个位点彼此靠近(例如,在20、15、10或5个碱基对之内)。另外地或可替代地,两个位点不在彼此的20、15、10或5个碱基对内。当涉及切割时,它可以是噬菌粒的一条链(也称为“切口”)或两条链的切割,如下所述,噬菌粒在宿主细胞内部时以双链质粒的形式复制。在某些实施例中,在dna靶位点处的结合增加了由噬菌粒编码的或模板在噬菌粒上的选择剂的表达。例如,通过在dna靶位点处的结合介导的选择剂的转录激活,可以发生选择剂表达的增加。可以选择与dna靶位点结合的多肽或多核苷酸的版本,例如,由于用这种版本转化的宿主细胞表现出维持细胞生长动力学、增加细胞生长动力学(例如增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救);而用不与dna靶位点结合的版本转化的宿主细胞则不表现出细胞生长动力学的增加(例如,表现出细胞生长动力学和/或细胞分裂的减少)和/或被杀死。在某些实施例中,选择与dna靶位点结合的多肽或多核苷酸的版本,因为用这种版本转化的宿主细胞能存活,而用不结合dna靶位点的版本转化的宿主细胞不能存活。可以选择不与dna靶位点结合的多肽或多核苷酸的版本,例如,由于用这种版本转化的宿主细胞表现出维持细胞生长动力学、增加细胞生长动力学(例如增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救);而用与dna靶位点结合的版本转化的宿主细胞则不表现出细胞生长动力学的增加(例如,表现出细胞生长动力学和/或细胞分裂的减少)和/或被杀死。在某些实施例中,选择不结合dna靶位点的多肽或多核苷酸的版本,因为用这种版本转化的宿主细胞能存活,而用结合dna靶位点的版本转化的宿主细胞不能存活。在替代性实施例中,可以构建编码cas9蛋白的噬菌粒(例如,pevol_cas)和靶向靶序列的grna以及噬菌体起点f1元件(图16)。在一些实施例中,噬菌粒组成型表达β-内酰胺酶(其赋予对氨苄青霉素(ampr)或类似抗生素例如羧苄青霉素的抗性),以及控制cas9的表达的诱导型阿拉伯糖启动子(ara)。在一些实施例中,可以将pevol_cas包装到辅助噬菌体中以引入转化的宿主细胞中。也可以构建质粒,例如pselect_mut和pselect_wt,其各自包含潜在的靶位点。可替代地或另外地,这些质粒还可以包含组成型表达的氯霉素抗性基因(cmr)和在lac启动子控制下的细菌毒素,从而允许通过例如iptg(异丙基β-d-1-硫代吡喃半乳糖苷)诱导毒素表达。为了设计等位基因特异性,可以使用例如pevol_cas噬菌粒作为诱变的初始模板,以及针对每个密码子并允许调整突变率的全面且无偏的诱变方法来生成cas9突变体的噬菌粒文库。可替代地或另外地,在一些实施例中,每一轮进化包括在竞争性培养物中对pevol_cas突变体的噬菌粒文库进行对含有例如pselect_mut或pselect_wt的大肠杆菌的切割的阳性选择。例如,可以使用噬菌体包装pevol_cas突变体来感染含有pselect_mut或pselect_wt的细菌,并且可以在氨苄青霉素的液体培养物中培养该细菌。在一些实施例中,在初始孵育和感染后,可以通过添加例如iptg来诱导毒素表达以评估使用毒素进行的阳性选择的严格度。在一些实施例中,可以通过添加阿拉伯糖来诱导cas9和指导rna的表达。在阳性选择过程中,细菌可被液体培养物中存在的噬菌体连续感染,从而对切割靶标提出了持续的挑战。在一些实施例中,在初始孵育和感染后,使用抗生素例如氯霉素进行的阴性选择的严格度。在一些实施例中,可以通过添加阿拉伯糖诱导cas9和指导rna的表达。在阴性选择过程中,细菌可被液体培养物中存在的噬菌体连续感染,从而对切割靶标提出了持续的挑战。另一方面,这些方法通常包括以下步骤:(a)提供编码第一选择剂并包括dna靶位点的多核苷酸;(b)将多核苷酸引入宿主细胞,使得每个转化的宿主细胞包括编码第一选择剂和dna靶位点的多核苷酸;(c)提供包含编码多核苷酸文库的噬菌粒的多种噬菌体,其中所述文库中的不同多核苷酸编码不同版本的目的多肽或用作不同版本的目的多核苷酸的模板;(d)在培养条件下将步骤(b)的转化的宿主细胞与多种噬菌体一起孵育,使得所述多种噬菌体感染转化的宿主细胞,其中第一选择剂的表达赋予被感染的宿主细胞以存活优势或劣势;和(e)选择在(d)中表现出存活优势(例如本文所述的存活优势)的宿主细胞。例如,步骤(d)的存活基于以上概述的各种方案。当结合降低不利选择剂的表达时,基于dna靶位点处的结合进行选择在某些实施例中,选择剂在宿主细胞中赋予存活劣势(例如,细胞生长动力学的降低(例如,生长延迟)和/或细胞分裂的抑制)和/或杀死宿主细胞,而在dna靶位点处的结合降低选择剂的表达。于是,存活是基于dna靶位点处的结合:用与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出维持细胞生长动力学、增加细胞生长动力学(例如增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救)。同时,用不与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出存活劣势(例如,细胞生长动力学的降低(例如,生长延迟)和/或细胞分裂的抑制)、不能存活和/或被杀死)。在一些实施例中,通过在dna靶位点处或附近切割噬菌粒,例如通过切割噬菌粒的一条链(“切口”)或两条链来降低选择剂的表达。文库中的多核苷酸可包括例如抗生素抗性基因,并且选择剂(由噬菌粒编码或其模板在噬菌粒上)抑制抗生素抗性基因的产物。在这种选择过程中的培养条件可以包括例如暴露于抗生素抗性基因对其产生抗性的抗生素。在一个实例中,抗生素抗性基因编码β-内酰胺酶,抗生素是氨苄青霉素或青霉素或另一种β-内酰胺抗生素,而选择剂是β-内酰胺酶抑制蛋白(blip)。当结合会降低有利选择剂的表达时,基于dna靶位点处的结合的缺乏进行选择在某些实施例中,选择剂在宿主细胞中赋予存活优势(例如,维持细胞生长动力学、增加细胞生长动力学(例如,增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救),而在dna靶位点处的结合降低选择剂的表达。于是,存活是基于dna靶位点处的结合的缺乏:用不与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出维持细胞生长动力学、增加细胞生长动力学(例如增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救)。同时,用与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出存活劣势(例如,细胞生长动力学的降低(例如,生长延迟)、细胞分裂的抑制、不能存活和/或被杀死)。在一些实施例中,通过在dna靶位点处或附近切割噬菌粒,例如通过切割噬菌粒的一条链(“切口”)或两条链来降低选择剂的表达。当结合增加有利选择剂的表达时,基于dna靶位点处的结合进行选择在某些实施例中,选择剂在宿主细胞中赋予存活优势(例如,维持细胞生长动力学、增加细胞生长动力学(例如,增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救),而在dna靶位点处的结合增加选择剂的表达。于是,存活是基于dna靶位点处的结合:用与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出维持细胞生长动力学、增加细胞生长动力学(例如增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救)。同时,用不与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出存活劣势(例如,细胞生长动力学的降低(例如,生长延迟)、细胞分裂的抑制、不能存活和/或被杀死)。当结合会增加不利选择剂的表达时,基于dna靶位点处的结合的缺乏进行选择在某些实施例中,选择剂在宿主细胞中赋予存活劣势(例如,细胞生长动力学的降低(例如,生长延迟)和/或细胞分裂的抑制)和/或杀死宿主细胞,而在dna靶位点处的结合增加选择剂的表达。于是,存活是基于dna靶位点处的结合的缺乏:用不与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出维持细胞生长动力学、增加细胞生长动力学(例如增加细胞分裂)和/或逆转细胞生长动力学的降低(例如,从细胞生长动力学的降低至少部分拯救)。同时,用与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞表现出存活劣势(例如,细胞生长动力学的降低(例如,生长延迟)、细胞分裂的抑制、不能存活和/或被杀死)。基于在选择剂存在下与宿主细胞基因组中的dna靶位点的结合进行选择一方面,本披露提供基于选择剂存在下是否结合dna靶位点来选择目的多肽或多核苷酸的版本的方法。如本文进一步讨论的,这些方法通常包括以下步骤:(a)提供多核苷酸的文库,其中所述文库中的不同多核苷酸编码不同版本的目的多肽或多核苷酸;(b)将多核苷酸的文库引入宿主细胞,使得每个转化的宿主细胞包括编码目的多肽或多核苷酸版本的多核苷酸,其中宿主细胞基因组包括dna靶位点;(c)提供包含编码第一选择剂的噬菌粒的多种噬菌体,其中所述第一选择剂是第一选择多核苷酸;(d)在培养条件下将步骤(b)的转化的宿主细胞与多种噬菌体一起孵育,使得所述多种噬菌体感染转化的宿主细胞,其中在第一选择剂存在下dna靶位点的结合赋予被感染宿主细胞的存活优势或劣势;和(e)选择在步骤(d)中存活的宿主细胞。步骤(d)中的存活是基于以下概述的各种方案。dna靶位点可以例如在宿主细胞基因组中。另外地或可替代地,dna靶位点可以在宿主细胞的必需存活基因中。另外地或可替代地,dna靶位点可以在其产物阻止存活基因表达的基因中。在一些实施例中,选择多核苷酸是用于crispr相关(cas)核酸酶的指导rna。当结合将是不利的时,存活是基于dna靶位点处的结合的缺乏在某些实施例中,在选择剂(其为多核苷酸)存在下宿主细胞中dna靶位点处的结合是不利的(例如,因为在dna靶位点处的结合导致宿主细胞中必需的存活基因的破坏)。于是,存活是基于dna靶位点处的结合的缺乏:用不与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞存活。同时,用与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞不能存活。当结合将是有利的时,存活是基于dna靶位点处的结合在某些实施例中,在选择剂(其为多核苷酸)存在下宿主细胞中dna靶位点处的结合是有利的(例如,因为在dna靶位点处的结合导致宿主细胞中存活基因的表达)。于是,存活是基于dna靶位点处的结合:用与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞存活。同时,用不与dna靶位点结合的、来自文库的多核苷酸(编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板)转化的宿主细胞不能存活。基于多肽表达的诱导进行选择一方面,本披露提供基于调节或控制多肽表达来选择目的多肽或多核苷酸的版本的方法。如本文进一步讨论的,这些方法通常包括以下步骤:(a)提供多核苷酸的文库,其中所述文库中的不同多核苷酸编码不同版本的目的多肽或用作不同版本的目的多核苷酸的模板;(b)将多核苷酸的文库引入宿主细胞,使得每个转化的宿主细胞包括编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板的多核苷酸;(c)诱导多肽的表达以控制培养物中存在的多肽的量;(d)提供多种噬菌体,所述噬菌体包含编码第一选择剂并包含dna靶位点的噬菌粒;(e)在培养条件下将步骤(b)的转化的宿主细胞与多种噬菌体一起孵育,使得所述多种噬菌体感染转化的宿主细胞,其中第一选择剂的表达赋予被感染的宿主细胞以存活优势或劣势;和(f)选择在步骤(d)中存活的宿主细胞。步骤(d)中的存活是基于本文所述的各种方案。多核苷酸可以包括诱导型启动子(例如本文所述的诱导型启动子),并且通过使多核苷酸与本文所述的一种或多种诱导剂接触来诱导表达。例如,多核苷酸可以包括阿拉伯糖启动子,并且可以通过使多核苷酸与阿拉伯糖接触来诱导多核苷酸的表达。在另一个实例中,多核苷酸可以包括tac启动子,并且可以通过使多核苷酸与iptg接触来诱导多核苷酸的表达。在又另一个实例中,多核苷酸可以包括rhabad启动子,并且可以通过使多核苷酸与鼠李糖接触来诱导多核苷酸的表达。多核苷酸的文库本披露的方法可以例如从提供多核苷酸的文库(例如质粒文库)的步骤开始,其中文库中的不同多核苷酸编码不同版本的目的多肽(或,在目的多核苷酸的情况下,文库包括不同版本的目的多核苷酸和/或用作不同版本的目的多核苷酸的模板的不同版本的目的多核苷酸)。本文所述的文库可包括例如可操作地连接至诱导型启动子的多核苷酸。例如,启动子的诱导可以诱导多核苷酸编码的多肽的表达。在一些实施例中,启动子的诱导(以诱导由多核苷酸编码的多肽的表达)影响选择方法的效率。例如,相对于不使用诱导型启动子的选择方法的效率,可以提高和/或增加选择方法的效率。可以例如通过使用或购买现有的文库来获得这样的文库,诸如商业上可得的和/或可通过公众收藏获得的文库。可替代地或另外地,文库可以从诱变方法获得。例如,可以通过随机诱变方法或综合诱变方法,例如在整个用于诱变的预定的靶区域中随机靶向多核苷酸的方法来获得文库。文库也可以通过靶向诱变方法获得。例如,目的多核苷酸或目的多肽的子区域可被靶向诱变。另外地或可替代地,可以将全部目的多核苷酸或全部目的多肽靶向诱变。尽管目的多肽或多核苷酸通常具有dna结合能力,但可以预期并非文库中不同多核苷酸编码的目的多肽或多核苷酸的所有版本都必然能够结合dna。此外,在由文库中的不同多核苷酸编码的目的多肽或多核苷酸的那些形式中,预期它们结合dna的能力可能不同。实际上,本披露的选择方法涉及区分能够和不能结合dna靶位点的目的多肽或多核苷酸的版本。在某些实施例中,目的多肽或多核苷酸的许多或甚至大多数版本不结合dna。类似地,在目的多肽或多核苷酸可以切割dna的实施例中,并非目的多肽或多核苷酸的所有版本都必然可以切割dna。宿主细胞本披露的方法可以包括,在提供多核苷酸的文库的步骤之后,使得每个转化的宿主细胞包括编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板的多核苷酸。宿主细胞通常是指可以吸收外源物质例如核酸(例如dna和rna)、多肽或核糖核蛋白的细胞。宿主细胞可以是例如单细胞生物,例如像微生物;或真核细胞,例如酵母细胞、哺乳动物细胞(例如在培养物中)等。在一些实施例中,宿主细胞是原核细胞,例如细菌细胞,例如细菌大肠杆菌。细菌细胞可以是革兰氏阴性或革兰氏阳性,并且可以属于细菌(以前称为真细菌)域或古核生物(以前称为古细菌)域。这些细菌类型中的任何一种都适合作为宿主细胞,只要它们可以在实验室中生长并吸收外源材料即可。宿主细胞可以是有能力的或使得有能力的细菌细胞,例如,因为它们能够或被制成能够吸收外源材料,例如遗传材料。存在多种机制,可以通过所述多种机制将外源材料(例如遗传材料)引入宿主细胞。例如,在细菌中,存在三种通用机制,分类为转化(摄取和掺入胞外核酸(例如dna))、转导(例如,通过质粒或感染细胞的病毒如噬菌体将遗传物质从一种细胞转移到另一种细胞)、和接合(核酸在两个临时连接的细胞之间的直接转移)。已经通过转化将遗传物质引入其中的宿主细胞通常被称为“转化的宿主细胞”。在一些实施例中,通过转化将多核苷酸的文库引入宿主细胞。用于转化宿主细胞的方案是本领域已知的。例如,对于细菌细胞,有基于电穿孔的方法、基于脂质转染的方法、基于热休克的方法、基于玻璃珠搅拌的方法、基于化学转化的方法、基于用外源材料(例如dna或rna包覆的颗粒进行轰击的方法等。本领域普通技术人员将能够基于宿主细胞制造商提供的技术和/或方案来选择方法。例如,转化的宿主细胞各自可包括编码目的多肽的一个版本或用作目的多核苷酸的一个版本的模板的多核苷酸。可将多核苷酸的文库引入宿主细胞群中,使得转化的宿主细胞群共同包括文库的所有成员。也就是说,对于文库中的每个版本的多核苷酸,群体中的至少一个宿主细胞包括该版本的多核苷酸,使得文库中的多核苷酸的所有版本都在转化的宿主细胞群中表示。噬菌体在将多核苷酸的文库引入宿主细胞的步骤之后,本披露的方法可包括提供多种噬菌体,所述噬菌体包含编码第一选择剂并包含dna靶位点的噬菌粒。噬菌体是感染细菌并将其基因组(和/或包装在噬菌体中的任何噬菌粒)注入细菌细胞质中的病毒。通常,尽管存在复制缺陷型噬菌体,噬菌体在细菌内复制。在一些实施例中,在允许噬菌体感染转化的宿主细胞的条件下,将包含本文所述的噬菌粒的多种噬菌体与转化的宿主细胞一起孵育。噬菌体可以具有复制能力,例如,噬菌体在转化的宿主细胞内复制,并且复制的病毒颗粒以病毒体的形式释放于培养基中,从而允许其他宿主细胞被噬菌体再感染。病毒体可以从宿主细胞中释放出来而无需裂解宿主细胞。在一些实施例中,多个噬菌体连续感染(感染和再感染)转化的宿主细胞,从而对宿主细胞发起连续的挑战。噬菌体可以是“辅助噬菌体”,因为相比噬菌体dna它们优先包装噬菌粒。例如,噬菌体可以优先以超过噬菌体dna至少3:1、至少4:1、至少5:1、至少6:1、至少7:1、至少8:1、至少9:1或至少10:1倍包装噬菌粒。在一些实施例中,噬菌体通常不裂解其宿主细胞,例如,在将转化的宿主细胞与多个噬菌体一起孵育的条件下,噬菌体不裂解其宿主细胞。噬菌体可以是丝状噬菌体。丝状噬菌体通常感染革兰氏阴性细菌(其尤其包括大肠杆菌、铜绿假单胞菌、淋病奈瑟氏球菌和鼠疫耶尔森氏菌)并且具有单链dna基因组。例如,丝状噬菌体可以是ff噬菌体,其感染携带f附加体的大肠杆菌。这种噬菌体的实例包括但不限于m13噬菌体、f1噬菌体、fd噬菌体及其衍生物和变体。另外地或可替代地,噬菌体可以是m13噬菌体或其衍生物或变体,例如,噬菌体可以是m13ko7,其是m13的具有卡那霉素抗性标记和p15a复制起点的衍生物。m13ko7已经被表征为具有大约10:1的高噬菌粒与噬菌体包装比,从而用作有用的辅助噬菌体。另外地或可替代地,噬菌体可以是vcsm13,其是m13ko7的衍生物。噬菌体也可以是f1噬菌体或其衍生物或变体。例如,噬菌体可以是r408,它是f1的衍生物,没有任何抗生素选择标记。另外地或可替代地,噬菌体可以是cm13,其是m13ko7的一种衍生物,据报道比m13ko7更可靠地产生病毒体。包含不同噬菌粒的噬菌体的池也可以用于本披露的方法中。例如,如本文进一步讨论的,当期望例如选择在一个以上的脱靶位点处抗结合和/或切割时,可以将不同的脱位靶标呈现在同一噬菌体池中所包含的不同噬菌粒上。噬菌粒噬菌粒是具有从f1噬菌体复制的f1起点的环状质粒,因此可以作为质粒复制并通过噬菌体包装成单链dna。噬菌粒还包含用于双链复制的复制起点(例如,在宿主细胞内部时)。适用于本发明的噬菌粒通常编码选择剂或用作选择剂的模板,并包含dna靶位点。因此,用于本发明的噬菌粒通常包含与编码选择剂或用作选择剂模板的基因元件可操作地连接并驱动其表达的调节元件。如上所述,dna靶位点可包含在噬菌粒内的任何地方。例如,dna靶位点可以位于调节元件内、位于基因元件内、位于调节元件和基因元件两者的外部和远侧、或位于两个元件的外部但靠近至少一个元件。dna靶位点的位置可以取决于实施例。例如,dna靶位点可以位于调节元件内。例如,在其中目的多肽是转录因子(例如转录激活物或阻遏物)并且选择是基于转录因子是否结合dna靶位点的实施例中,这种定位可能是合适的。对dna靶位点位于何处没有限制,因为目的多肽在噬菌粒内任何地方的结合都会增加或减少选择剂的表达。例如,目的多肽在dna靶位点处的结合可导致在dna靶位点处或附近的噬菌粒的切割。噬菌粒内任何地方的噬菌粒的切割将引起噬菌粒的线性化,这将导致噬菌粒不在宿主细胞内复制,因此废除了选择剂的表达。噬菌粒可以使用本领域已知的方法包装到噬菌体中,包括噬菌体制造商提供的方案。例如,常用的方案是制备所需噬菌粒构建体的双链质粒版本,将双链质粒转化入宿主细胞如细菌中,然后用可将双链质粒包装为单链噬菌粒的辅助噬菌体接种这种转化的宿主细胞的培养物。培养条件在提供包含编码第一选择剂并包括dna靶位点的噬菌粒的多个噬菌体的步骤之后,本披露的方法可以包括在培养条件下将转化的宿主细胞(将多核苷酸的文库引入其中)连同多种噬菌体一起孵育使用,使得多种噬菌体感染转化的宿主细胞的步骤。通常,取决于实施例,这些条件是其中第一选择剂的表达赋予存活劣势或存活优势的条件。在某些实施例中,培养条件是竞争性培养条件。“竞争性培养条件”是指一群生物体(例如宿主细胞)一起生长并且必须竞争相同的有限资源(例如营养物、氧等)的条件。宿主细胞可以在没有或几乎没有新营养物输入的环境中孵育。例如,可以在没有或几乎没有新氧输入的环境中,例如在诸如烧瓶的密封容器中孵育宿主细胞。另外地或可替代地,可以将宿主细胞在整个孵育过程中充分混合的培养基中孵育,例如摇动液体培养。通常,在这种充分混合的条件下,宿主细胞具有相似的营养需求,并且随着营养物和/或氧被不断增长的群体消耗,它们将竞争营养物和/或氧(对于有氧生物而言)。另外地或可替代地,可以在近似恒定的温度下,例如在最适合宿主细胞类型的温度下孵育宿主细胞。例如,对于某些细菌物种(包括大肠杆菌),通常将宿主细胞在37℃左右的温度下孵育。在一些实施例中,将宿主细胞在37℃上下5℃、4℃、3℃、2℃或1℃内,例如在约37℃下孵育。可以在摇动的液体培养物中孵育宿主细胞。这种摇动通常足够剧烈以防止营养物的不均匀分布和/或某些宿主细胞在培养物底部沉降。例如,可以将宿主细胞以至少100rpm(每分钟转数)、至少125rpm、至少150rpm、至少175rpm、至少200rpm、至少225rpm、至少250rpm、至少275rpm、或至少300rpm摇动。在一些实施例中,宿主细胞在100rpm和400pm之间,例如在200和350rpm之间,例如在大约300rpm下摇动。在将多种噬菌体引入培养物中之前,可以将宿主细胞孵育一段时间。这段时间可以例如允许宿主细胞群体在引入多种噬菌体之前从储存中恢复和/或达到特定的理想密度。在引入多种噬菌体之前的这段时间中,可以使用选择压力,也可以不使用选择压力。培养条件可包括,例如,经一段时间,例如至少4小时、至少8小时、至少12小时或至少16小时,将宿主细胞与噬菌体一起连续孵育。另外地或可替代地,培养条件可以包括将宿主细胞与噬菌体一起连续孵育直至宿主细胞的生长饱和。培养条件可允许噬菌体连续感染宿主细胞。即,在孵育期间,宿主细胞被感染并连续地被再感染(如果它们存活)。另外地或可替代地,选择压力被引入培养物中。例如,特别是对于用外源dna(例如质粒)转化的宿主细胞,可以引入选择压力以有利于那些保持外源dna的宿主细胞。常用的方案包括使用一种或多种抗生素作为选择压力,以及在有待维持的外源dna中的相应抗生素抗性基因。所述选择压力可以与涉及本文所讨论的选择剂的相同或不同,并且在一些实施例中,两者例如依次和/或同时使用。在一些实施例中,在转化的宿主细胞与噬菌体一起孵育的至少一段时间内,培养条件包括暴露于一种或多种抗生素,一些宿主细胞由于存在于噬菌粒上的抗生素抗性基因、文库中的多核苷酸或两者而可能对所述一种或多种抗生素具有抗性。例如,文库中的噬菌粒和多核苷酸都可以具有抗生素抗性基因,例如,抗生素抗性基因可以相同或不同。如果噬菌粒包含一个抗生素抗性基因(赋予对“第一抗生素”的抗性的“第一抗生素抗性基因”)并且多核苷酸包含另一个抗生素抗性基因(赋予对“第二抗生素”的抗性的“第二抗生素抗性基因”),培养条件可以包括多种方案中的任何一种。作为非限制性实例,这些条件可以包括:1)同时暴露于第一抗生素和第二抗生素;2)相继暴露于第二抗生素持续一段时间(例如,在将噬菌体引入培养物之前先孵育宿主细胞的时间段内),然后暴露于i)第一抗生素或ii)第一抗生素和第二抗生素两者(例如,在宿主细胞与噬菌体一起孵育的时间段内);或3)在孵育过程中暴露于相关抗生素中的仅一种(例如第一抗生素)。选择剂本文所述的方法可包括提供多个噬菌体的步骤,所述噬菌体包含编码或用作选择剂模板的噬菌粒。取决于实施例,在宿主细胞与噬菌体一起孵育的条件下,选择剂可以赋予宿主细胞存活优势或存活劣势。在宿主细胞与噬菌体孵育的条件下,选择剂可以将细胞生长动力学的增加或细胞生长动力学的降低赋予宿主细胞。选择剂可以是例如多肽和/或多核苷酸。在一些实施例中,选择剂赋予宿主细胞存活优势。在一些实施例中,选择剂由宿主细胞存活必需的基因编码。这样的必需存活基因的实例包括但不限于参与脂肪酸生物合成的基因;参与氨基酸生物合成的基因;参与细胞分裂的基因;参与总体调节功能的基因;参与蛋白质翻译和/或修饰的基因;参与转录的基因;参与蛋白质降解的基因;编码热休克蛋白的基因;参与atp运输的基因;参与肽聚糖合成的基因;参与dna复制、修复和/或修饰的基因;参与trna修饰和/或合成的基因;和编码核糖体组分和/或参与核糖体合成的基因)。例如,在大肠杆菌中,许多必需存活基因是本领域已知的,包括但不限于accd(乙酰辅酶a羧化酶,羧基转移酶组分,β亚基)、acps(辅酶a:载脂蛋白-[酰基-载体-蛋白]泛酰巯基乙胺磷酸转移酶)、asd(天冬氨酸-半醛脱氢酶)、dape(n-琥珀酰-二氨基庚二酸脱酰基酶)、dnaj(带dnak的分子伴侣;热休克蛋白)、dnak(分子伴侣hsp70)、era(gtp结合蛋白)、frr(核糖体释放因子)、ftsi(隔膜形成;青霉素结合蛋白3;肽聚糖合成酶)、ftsl细胞分裂蛋白;隔膜壁向内生长);ftsn(必需细胞分裂蛋白);ftsz(细胞分裂;形成圆周环;微管蛋白样gtp结合蛋白和gtp酶)、gcpe、grpe(噬菌体λ复制;宿主dna合成;热休克蛋白;蛋白质修复)、hflb(降解sigma32,整合膜肽酶,细胞分裂蛋白)、infa(蛋白链起始因子if-1)、lgt(磷脂酰甘油原脂蛋白二酰基甘油基转移酶;主要膜磷脂)、lpxc(udp-3-o-酰基n-乙酰基葡糖胺脱乙酰基酶;脂质a生物合成)、map(蛋氨酸氨基肽酶)、mopa(groel,分子伴侣hsp60,肽依赖性atp酶,热休克蛋白)、mopb(groes,10kd分子伴侣结合pres.mg-atp中的hsp60,抑制其atp酶活性)、msbaatp结合转运蛋白;htrb的多拷贝抑制剂)、mura(胞壁质生物合成的第一步;udp-n-葡糖胺1-羧基乙烯基转移酶)、muri(谷氨酸消旋酶、d-谷氨酸和肽聚糖的生物合成所必需)、nade(nad合成酶,相比谷氨酰胺偏好nh3)、nusg(转录抗终止中的组分)、parc(dna拓扑异构酶iv亚基a)、ppa(无机焦磷酸酶)、pros(脯氨酸trna合成酶)、pyrb(天冬氨酸氨基甲酰基转移酶,催化亚基)、rpsb(30s核糖体亚基蛋白s2)、trma(trna(尿嘧啶5-)-甲基转移酶)、ycah、ycfb、yfil、ygjd(假定的o-唾液酸糖蛋白内肽酶)、yhbz(假定的gtp结合因子)、yiha和yjeq。大肠杆菌中的其他必需基因包括gerdes2003的“大肠杆菌mg1655中的必需基因的实验确定和系统级分析”中列出的那些基因,例如在增补表1、2和6中的那些。在一些实施例中,选择剂由抗生素抗性基因编码,如下文进一步讨论的。例如,培养条件可以包括暴露于抗生素抗性基因对其提供抗性的抗生素。在一些实施例中,选择剂抑制赋予存活劣势的基因产物。在某些实施例中,选择剂赋予宿主细胞存活劣势。选择剂可能对宿主细胞有毒。例如,选择剂可以是毒素,许多毒素是本领域已知的,并且许多毒素已经在各种细菌物种中鉴定出来。此类毒素的实例包括但不限于ccdb、flma、fst、hica、hok、ibs、kid、ldrd、mazf、pare、syme、tisb、txpa/brnt、xcv2162、yafo、zeta和tse2。例如,选择剂可以是在大肠杆菌中发现的ccdb。在其他实例中,选择剂是tse2。选择剂可能有毒,因为它会产生有毒物质。例如,有毒物质的产生只能在另一种试剂的存在下发生,该试剂的存在可以外部控制或可以不受外部控制。另外地或可替代地,选择剂可以抑制赋予存活优势的基因产物。作为非限制性实例,选择剂可以是β-内酰胺酶抑制蛋白(blip),其尤其抑制β-内酰胺酶,例如氨苄青霉素和青霉素。诱导剂本文所述的方法可包括提供多核苷酸的文库的步骤,其中该文库中的不同多核苷酸编码不同版本的目的多肽(或在目的多核苷酸的情况下,用作不同版本的目的多核苷酸的模板)。多核苷酸可以包括例如调节元件,例如可以控制多肽表达的启动子。调节元件可以是诱导型启动子,并且表达可以由诱导剂诱导。这样的诱导剂和/或诱导的表达可以增加或改善选择效率。诱导剂可以是多肽和/或多核苷酸。诱导剂也可以是小分子、光、温度或胞内代谢物。在一些实施例中,诱导剂是阿拉伯糖、脱水四环素、乳糖、iptg、丙酸酯、蓝光(470nm)红光(650nm)、绿光(532nm)或l-鼠李糖。例如,诱导剂可以是阿拉伯糖。编码不同版本cas9分子的多核苷酸的文库在一些实施例中,本发明的方法和组合物可以与编码不同版本的cas9分子或cas9多肽的多核苷酸的文库(例如,横跨cas9分子或cas9多肽的全部或部分的cas9突变体的全面且无偏见的文库)一起使用。在某些实施例中,本发明的方法和组合物可以用于基于特定性质选择文库的一个或多个成员。在典型的实施例中,cas9分子或cas9多肽具有与grna分子相互作用,并且与所述grna分子一起定位至核酸中的位点的能力。其他活性(例如,pam特异性、切割活性、或解旋酶活性)在cas9分子和cas9多肽中可以更广泛地变化。在一些实施例中,本发明的方法和组合物可以用于选择cas9分子或cas9多肽的一种或多种版本,所述版本包括改变的酶学性质,例如改变的核酸酶活性或改变的解旋酶活性(与天然存在的或其他参考cas9分子(包括已经过工程化或更改的cas9分子)相比))。如本文所述,参考cas9分子或cas9多肽的突变版本可以具有切口酶活性或没有切割活性(与双链核酸酶活性相反)。在实施例中,本发明的方法和组合物可以用于选择cas9分子或cas9多肽的一种或多种版本,所述版本具有改变其大小的改变,例如减小其大小的氨基酸序列的缺失(例如,对一种或多种或对任何cas9活性具有或不具有显著影响)。在实施例中,本发明的方法和组合物可以用于选择识别不同pam序列的cas9分子或cas9多肽的一种或多种版本(例如,可以选择识别不同于参考cas9分子的内源性野生型pi域所识别的pam序列的cas9分子版本)。可以使用任何方法来制备具有不同版本的cas9分子或cas9多肽的文库,例如通过改变亲本(例如天然存在的)cas9分子或cas9多肽,以提供经改变的cas9分子或cas9多肽的文库。例如,可以相对于亲本cas9分子(例如,天然存在的或工程化的cas9分子)引入一个或多个突变或差异。此类突变和差异包括:取代(例如保守取代或非必需氨基酸取代);插入;或缺失。在实施例中,本发明文库中的cas9分子或cas9多肽相对于参考(例如,亲本)cas9分子可以包含一个或多个突变或差异,例如,至少1、2、3、4、5、10、15、20、30、40或50个突变但少于200、100或80个突变。指导rna分子的文库在一些实施例中,本披露的方法和组合物可以与指导rna分子和/或编码指导rna分子的多核苷酸的文库一起使用。例如,可以提供和/或产生包括各自编码指导rna的dna分子的文库,所述指导rna具有(i)本文所述的不同靶向域;(ii)本文所述的不同的第一和/或第二互补域;和/或(iii)本文所述的不同茎环。如本文所述,可将文库引入宿主细胞。在一些实施例中,还将编码rna指导的核酸酶,例如cas9分子或cas9多肽的核酸引入到宿主细胞中。在某些实施例中,本披露的方法和组合物可用于基于特定性质,例如定位于核酸中的位点和/或与cas9分子或cas9多肽相互作用和/或将cas9分子或cas9多肽定位到核酸中的位点的能力,来选择指导rna文库的一个或多个成员。可以使用任何方法来制备具有不同版本的指导rna的文库,例如,通过改变亲本(例如,天然存在的)指导rna,以提供改变的指导rna的文库。例如,可以相对于亲本指导rna(例如,天然存在的或工程化的指导rna)引入一个或多个突变或差异。此类突变和差异包括:取代;插入;或缺失。在一些实施例中,本披露的文库中指导rna相对于参考,例如亲本指导rna可以包含一个或多个突变或差异,例如,至少1、2、3、4、5、10、15、20、30、40或50个突变但少于200、100或80个突变。dna靶位点通常,用于特定发明方法的dna靶位点可以取决于dna靶位点的物理位置(例如,在某些方面,dna靶位点可以位于噬菌粒上,而在其他方面,dna靶位点可以位于宿主细胞基因组中)、目的多肽或多核苷酸的性质、选择过程的性质和/或选择过程的所需结果。dna靶位点可以位于多种类型的核苷酸序列内。例如,在一些实施例中,dna靶位点可位于未转录的元件内、位于编码多肽或用作多核苷酸的模板(例如,非编码rna)的元件内、位于控制多肽的表达的调节元件内等。如本文所述,在一些实施例中,dna靶位点可以位于噬菌粒上。在一些实施例中,dna靶位点可以位于质粒上。在选择过程依赖于噬菌粒或质粒的切割(或不切割)的情况下,dna靶位点可以位于噬菌粒或质粒上的任何位置,因为选择取决于噬菌粒或质粒的线性化(以及随后的破坏),所述线性化可能是由于噬菌粒或质粒上任何位置的切割所致。在选择过程依赖于选择剂表达的抑制(或激活)的情况下,dna靶位点可以位于驱动选择剂表达的调节元件内。在一些实施例中,调节元件可以是诱导型调节元件。如本文所述,在一些实施例中,dna靶位点可以位于宿主细胞基因组内。在选择过程依赖于宿主细胞存活必需的内源基因(“必需基因”)的切割的情况下,dna靶位点可以例如位于必需基因的编码或调节元件内。在选择过程依赖于必需基因的抑制的情况下,dna靶位点可以位于宿主细胞基因组中与目的多肽结合时导致必需基因被抑制的任何位置(例如,必需基因的在调节元件内,在必需基因的启动子和编码区之间等)。dna靶位点的特定核苷酸序列(即与位于噬菌粒上或是宿主细胞基因组内的位点分离并分开)通常取决于目的多肽的性质、选择过程的性质和选择过程的期望结果。举例来说,当目的多肽是识别第一核苷酸序列的参考核酸酶(例如,大范围核酸酶、talen或锌指核酸酶)且本发明方法用于选择参考核酸酶的一个或多个经修饰版本(其选择性结合不同于第一核苷酸序列(例如在1、2、3个等碱基处)的第二核苷酸序列)时,本发明的方法可涉及在阳性选择步骤使用与第二核苷酸序列相对应的dna靶位点和在阴性选择步骤中使用与第一核苷酸序列相对应的dna靶位点(即,选择结合第二核苷酸序列但不结合第一核苷酸序列的参考核酸酶的版本)。对于cas分子(例如,cas9分子),将部分基于cas分子上的pam和用于将cas分子定位在dna靶位点处的grna的靶向域的序列确定dna靶位点。举例来说,当目的多肽是识别第一pam序列的cas9分子且本发明方法用于选择参考cas9分子的一个或多个经修饰版本(其选择性识别不同于第一pam序列(例如在1、2、3个等碱基处)的第二pam序列)时,本发明的方法可涉及在阳性选择步骤使用与第二pam序列相对应的dna靶位点和在阴性选择步骤中使用与第一pam序列相对应的dna靶位点(即,选择识别第二pam序列但不识别第一pam序列的参考cas9分子的版本)。在两种情况下,dna靶位点还将包括与用于将cas9分子定位在dna靶位点处的grna的靶向域的序列互补的序列。在一些实施例中,本文提供的方法可用于评估pam变体通过rna指导的核酸酶例如酿脓链球菌cas9直接切割靶位点的能力。在一些实施例中,文库包含多个核酸模板,所述模板进一步包括含有与靶位点相邻的pam变体的核苷酸序列。在一些实施例中,pam序列包含序列nga、ngag、ngcg、nngrrt、nngrra或nccrrc。本文提供的一些方法允许针对任何给定靶位点同时评估多个pam变体,并且在一些实施例中,与变体酿脓链球菌cas9组合进行。因此,从此类方法获得的数据可用于汇编介导特定靶位点的切割的pam变体(与野生型酿脓链球菌cas9或变体酿脓链球菌cas9组合)的列表。在一些实施例中,测序方法用于产生定量测序数据,并且可以确定由特定pam变体介导的特定靶位点的切割的相对丰度。抗生素抗性基因在某些实施例中,文库和/或噬菌粒中的质粒包含抗生素抗性基因。在一些实施例中,抗生素抗性基因赋予对杀死或抑制细菌例如大肠杆菌生长的抗生素的抗性。此类抗生素的非限制性实例包括氨苄青霉素、博来霉素、羧苄青霉素、氯霉素、红霉素、卡那霉素、青霉素、多粘菌素b、壮观霉素、链霉素和四环素。多种抗生素抗性基因盒是本领域已知的和/或可商购的,例如作为质粒中的元件。例如,存在许多具有ampr(氨苄青霉素抗性)、bler(博来霉素抗性)、carr(羧苄青霉素抗性)、cmr(氯霉素抗性)、kanr(卡那霉素抗性)和/或tetr(四环素抗性)的质粒或基因元件。抗生素抗性基因的另一个实例是β-内酰胺酶。在一些实施例中,噬菌粒包含第一抗生素抗性基因,并且文库中的质粒包含第二抗生素抗性基因。在一些实施例中,第一抗生素抗性基因不同于第二抗生素抗性基因。例如,在一些实施例中,第一抗生素抗性基因是cmr(氯霉素抗性)基因,且第二抗生素抗性基因是ampr(氨苄青霉素抗性)基因。调节元件在某些实施例中,基因元件(例如像,编码选择剂的那些、抗生素抗性基因、多肽、多核苷酸等)可操作地连接至调节元件,以允许表达一种或多种其他元件,例如选择剂、抗生素抗性基因、多肽、多核苷酸等。在一些实施例中,噬菌粒包括驱动所述噬菌粒上的一种或多种基因元件例如选择剂的表达的调节元件。在一些实施例中,文库中的多核苷酸包括调节元件,所述调节元件驱动多核苷酸上的一个或多个基因元件(例如,目的多肽或多核苷酸,以及如果存在的话,编码选择剂如抗生素抗性基因的基因元件)的表达。存在各种各样的基因调节元件。所使用的调节元件的类型可以取决于例如宿主细胞、要表达的基因的类型、其他因素(例如使用的转录因子)等。基因调节元件包括但不限于增强子、启动子、操纵子、终止子等,以及它们的组合。作为非限制性实例,调节元件可包含启动子和操纵子两者。在一些实施例中,调节元件是组成型的,因为它在细胞中的所有情况下都是有活性的。例如,诸如组成型启动子的组成型元件可以用于表达基因产物而无需额外的调节。在一些实施例中,调节元件是诱导型的,即,其仅响应于特定刺激才是有活性的。例如,可以通过在iptg(异丙基β-d-1-硫代吡喃半乳糖苷)的作用下使其具有活性来诱导lac操纵子。另一个实例是在阿拉伯糖存在下使其具有活性的阿拉伯糖启动子。在一些实施例中,调节元件是双向型的,它可以驱动序列中位于其另一侧的基因的表达。因此,在一些实施例中,至少两个基因元件的表达可以由相同的基因元件驱动。用作调节元件的基因片段在本领域中是容易获得的,并且许多可以从供应商处购得。例如,已经包含用以表达目的基因片段的一种或多种调节元件的表达质粒或其他载体是容易获得的。分析多肽和/或多核苷酸的选定版本一轮或多轮选择后,可以从在选择中存活下来的宿主细胞中回收多肽和/或多核苷酸的选定版本并进行分析。在使用一个以上进化循环(诱变后进行一个或多个选择轮次)的示意图中,此分析可以在每次循环结束时或仅在某些循环中进行。分析类型的实例包括但不限于测序、结合和/或切割测定(包括体外测定)、宿主细胞类型以外的细胞类型中选定版本的活性的验证。作为非限制性实例,可以进行下一代(也称为高通量测序)以对所有或大多数所选变体进行测序。在一些实施例中,进行深度测序,这意味着每个核苷酸在测序过程中被读取几次,例如以大于至少7、至少10、至少15、至少20或更大的深度读取,其中如下计算深度(d):d=n×l/g(等式1),其中n是读段的数目,l是原始基因组的长度,且g是进行测序的多核苷酸的长度。在一些实施例中,使用桑格(sanger)测序分析至少一些选定版本。序列分析可用于例如检查指示选定版本的富集的氨基酸残基或核苷酸。可替代地或另外地,可以从例如单个宿主细胞集落(例如细菌集落)中对所选版本的样品进行测序。结合和/或切割测定是本领域已知的。这些测定中的一些是在体外进行的,例如使用细胞组分或分离的分子(例如多肽、多核苷酸或核糖核蛋白)而不是整个细胞。在一些实施例中,进行用于dna底物的结合和/或切割的体外测定。在一些实施例中,测定测试从一轮或多轮选择存活的宿主细胞中提取的裂解物的活性。在一些实施例中,测定测试从一轮或多轮选择存活的宿主细胞中提取的多肽、多核苷酸和/或核糖核蛋白、或其复合物的活性。在一些实施例中,分析包括进行一种或多种测定以测试文库中所选版本的多核苷酸的产物(例如,由所选版本编码的多肽或其模板为所选版本的多核苷酸)的一种或多种功能。用途在一些实施例中,本发明的选择方法与产生质粒文库的诱变方法一起使用。任何诱变方法可以与本发明的选择方法一起使用。在一些实施例中,使用一轮诱变,然后进行一轮或多轮选择。该循环可以进行一次,或者可以例如作为定向进化策略的一部分重复一次或多次,其中将在一个循环中选择的目的多肽和/或多核苷酸的版本在下一个循环的轮次中诱变。循环可以根据需要重复多次,例如直到获得的目的多肽和/或多核苷酸的选定版本满足特定标准和/或直到获得满足特定标准的所需数目的选定多肽和/或多核苷酸。在一些实施例中,在一个循环中,一轮诱变之后是一轮阳性选择(例如,针对裂解和/或结合dna靶位点的目的多肽和/或多核苷酸的版本)。在一些实施例中,在一个循环中,一轮诱变之后是一轮阳性选择,其后是一轮阴性选择(例如,针对不切割和/或不结合dna靶位点的目的多肽和/或多核苷酸的版本)。在一些实施例中,在一个循环中,一轮诱变之后是一轮阴性选择,其后是一轮阳性选择。在其中执行超过一轮的实施例中,就诱变和选择轮次而言,循环不必具有相同的示意图。另外,其他细节在两次循环之间不必相同,例如,诱变的方法在一次循环至下次循环之间不必相同,选择轮次的确切条件或示意图也不必相同。因此,本披露的选择方法可以用于选择具有期望的结合和/或切割位点特异性的目的多肽和/或多核苷酸。例如,选择方法可用于选择结合一个等位基因但不结合另一等位基因的目的多肽和/或多核苷酸。例如,区分疾病等位基因和野生型等位基因的能力可用于例如基于基因编辑、基因抑制和/或基因激活技术来开发疗法。在一些实施例中,例如,进行阳性选择以选择识别一个等位基因(例如,疾病等位基因)的目的多肽或多核苷酸,然后进行阴性选择以选择识别另一个等位基因(例如,野生型等位基因)的目的多肽或多核苷酸。在一些实施例中,进行阴性选择以选择识别一个等位基因(例如,野生型等位基因)的目的多肽和/或多核苷酸,然后进行阳性选择以选择识别其他等位基因(例如,疾病等位基因)的目的多肽或多核苷酸。如实例中所示,本发明的选择方法已用于进化方案中,以进化出具有区分仅一个碱基改变的等位基因的能力的多肽。作为另一个实例,例如,与天然存在的目的多肽和/或多核苷酸相比,选择方法可以用于选择具有改变的结合偏好的目的多肽和/或多核苷酸。例如,某些dna结合蛋白(包括酶)具有非常有限的结合特异性,因此限制了它们的用途。选择和/或进化具有改变的结合特异性(例如,与天然存在的目的多肽和/或多核苷酸的结合特异性相比)的位点特异性dna结合域或蛋白质可以增加其使用范围。在一些实施例中,进行阳性选择以选择识别一个dna靶位点(例如,期望的新靶位点)的目的多肽和/或多核苷酸,然后进行阴性选择以选择识别另一个dna靶位点(例如天然靶位点)的目的多肽和/或多核苷酸。在一些实施例中,进行阳性选择以选择识别一个dna靶位点(例如,期望的新靶位点)的目的多肽和/或多核苷酸,并且不进行阴性选择。在一些实施例中,进行阴性选择以选择识别一个dna靶位点(例如天然靶位点)的目的多肽和/或多核苷酸,然后进行阳性选择以选择识别另一个dna靶位点(例如,所需的新靶位点)的目的多肽和/或多核苷酸。作为另一个实例,选择方法可以用于选择具有降低的脱靶活性的目的多肽或多核苷酸。尽管某些dna结合蛋白被分类为对特定识别序列具有特异性,但有些可能表现出混杂性,因为它们在某种程度上与一个或多个脱靶位点结合。在一些实施例中,例如,进行阴性选择以选择不识别一个或多个脱靶位点的目的多肽或多核苷酸。当期望针对超过一个的脱靶位点进行选择时,在一些实施例中,使用包含不同噬菌粒的噬菌体池,其中每个不同的噬菌粒均包含对应于脱靶位点之一的dna靶位点。由于在孵育步骤中宿主细胞可能会被各种噬菌体一次又一次地感染,因此能够在单轮阴性选择中针对多个脱靶处的结合或切割进行选择。在一些实施例中,例如,进行阳性选择以选择识别特定识别序列的目的多肽或多核苷酸,然后进行阴性选择以选择识别一个或多个脱靶位点的目的多肽和/或多核苷酸。在一些实施例中,进行阴性选择以选择识别一个或多个脱靶位点的目的多肽或多核苷酸,然后进行阳性选择以选择识别特定识别序列的目的多肽或多核苷酸。在其中在一个循环中使用超过一轮选择(例如,阳性选择轮然后是阴性选择轮)的一些实施例中,方法包括在选择轮之间使宿主细胞粒化(例如,通过离心)的步骤。这样的粒化步骤可以例如去除在先前的选择轮次中使用的试剂(例如抗生素、基因表达的诱导物如iptg等)。使用本文所述方法鉴定的变体核酸酶可用于遗传工程化细胞群。为了改变或设计细胞群,可将细胞与本文所述的变体核酸酶或能够表达变体核酸酶的载体和指导核酸接触。如本领域中已知的,指导核酸将具有与细胞基因组的靶核酸上的靶序列互补的区域。在一些实施例中,变体核酸酶和指导核酸以核糖核酸蛋白(rnp)施用。在一些实施例中,rnp以1x10-4μm至1μmrnp的剂量施用。在一些实施例中,少于1%、少于5%、少于10%、少于15%或少于20%的改变包括细胞群中脱靶序列的改变。在一些实施例中,大于70%、大于75%、大于80%、大于85%、大于90%、大于95%、大于98%、大于99%的交替包括细胞群中的中靶序列的变化。使用本文所述方法鉴定的变体核酸酶可用于编辑双链dna(dsdna)分子的群体。为了编辑dsdna分子的群体,可使分子与本文所述的变体核酸酶和指导核酸接触。如本领域已知的,指导核酸将具有与dsdna的靶序列互补的区域。在一些实施例中,变体核酸酶和指导核酸以核糖核酸蛋白(rnp)施用。在一些实施例中,rnp以1x10-4μm至1μmrnp的剂量施用。在一些实施例中,少于1%、少于5%、少于10%、少于15%或少于20%的编辑包括dsdna分子群体中脱靶序列的编辑。在一些实施例中,大于70%、大于75%、大于80%、大于85%、大于90%、大于95%、大于98%、大于99%的编辑包括dsdna分子的群体中的中靶序列的编辑。基因组编辑系统的实施方式:递送、配制和施用途径如上文所讨论的,本披露的基因组编辑系统可以用任何适宜方式来实施,意味着此类系统的组分(包括但不限于rna指导的核酸酶(例如本文所述的rna指导的核酸酶变体)、grna和任选供体模板核酸)可以用任何适宜形式或形式的组合来递送、配制或施用,从而在细胞、组织或受试者中(例如,离体或体内)导致基因组编辑系统的转导、表达或引入和/或引起所需的修复结果。表2和3展示基因组编辑系统实施方式的若干非限制性实例。但本领域技术人员将了解,这些列表不是全面性的,并且其他实施方式是可能的。在一些实施例中,本文所述的一种或多种组分在体内递送/施用。在一些实施例中,本文所述的一种或多种组分离体递送/施用。例如,在一些实施例中,将本文所述的编码rna指导的核酸酶变体的rna(例如,mrna)体内或离体递送/施用至细胞。在一些实施例中,本文所述的rna指导的核酸酶变体以与grna或不与grna一起的核糖核蛋白(rnp)复合物体内或离体递送/施用至细胞。尤其参照表2,该表列示包含单一grna和任选供体模板的基因组编辑系统的若干示例性实施方式。然而,根据本披露的基因组编辑系统可以并入多个grna、多个rna指导的核酸酶(例如,本文所述的多个rna指导的核酸酶变体)和其他组分例如蛋白质,并且基于表2中所示的原理多种实施方式对于技术人员将是显而易见的。在表2中,“[n/a]”指示基因组编辑系统不包括所指示的组分。表2表3总结了用于如本文所述的基因组编辑系统的组分的各种递送方法。同样,该列表旨在是示例性而不是限制性的。表3基因组编辑系统的基于核酸的递送可以通过本领域已知的方法或如本文所述将编码根据本披露的基因组编辑系统的各种元件的核酸施用于受试者或递送至细胞。例如,编码rna指导的核酸酶(例如,本文所述的rna指导的核酸酶变体)和/或编码grna的dna,以及供体模板核酸可以由例如载体(例如,病毒或非病毒载体)、基于非载体的方法(例如,使用裸dna或dna复合物)或其组合递送。编码基因组编辑系统或其组分的核酸可以作为裸dna或rna(例如mrna)直接递送至细胞,例如借助转染或电穿孔来递送,或者可以缀合至促进靶细胞(例如,红细胞、hsc)摄取的分子(例如,n-乙酰半乳糖胺)。也可以使用核酸载体,例如表3中总结的载体。核酸载体可以包含编码基因组编辑系统组分(例如rna指导的核酸酶(例如本文所述的rna指导的核酸酶变体)、grna和/或供体模板)的一个或多个序列。载体还可以包含编码信号肽(例如,用于核定位、核仁定位或线粒体定位)的序列,其与编码蛋白质的序列缔合(例如插入其中或与其融合)。作为一个实例,核酸载体可以包括cas9编码序列,其包括一个或多个核定位序列(例如,来自sv40)。核酸载体还可以包括任何适宜数目的调节/控制元件,例如,启动子、增强子、内含子、多聚腺苷酸化信号、科扎克(kozak)共有序列或内部核糖体进入位点(ires)。这些元件为本领域中所熟知,并且描述于cotta-ramusino中。根据本披露的核酸载体包括重组病毒载体。示例性病毒载体展示于表3中,并且其他适宜病毒载体以及其使用和产生描述于cotta-ramusino中。还可以使用本领域已知的其他病毒载体。另外,可以使用病毒颗粒来递送呈核酸和/或肽形式的基因组编辑系统组分。例如,可以组装“空”病毒颗粒以含有任何适宜负荷。病毒载体和病毒颗粒也可以经工程化以并入靶向配体,从而改变靶组织特异性。除了病毒载体以外,可以使用非病毒载体来递送编码根据本披露的基因组编辑系统的核酸。非病毒核酸载体的一个重要分类是纳米颗粒,其可以是有机的或无机的。纳米颗粒为本领域所熟知,并且概述于cotta-ramusino中。可以使用任何适宜的纳米颗粒设计来递送基因组编辑系统组分或编码此类组分的核酸。例如,在本披露的某些实施例中,有机(例如脂质和/或聚合物)纳米颗粒可以适合用作递送媒介物。用于纳米颗粒配制物和/或基因转移的示例性脂质显示于表4中,并且表5列示用于基因转移和/或纳米颗粒配制物的示例性聚合物。表4:用于基因转移的脂质表5:用于基因转移的聚合物聚合物缩写聚乙二醇peg聚乙烯亚胺pei二硫代双(琥珀酰亚胺基丙酸酯)dsp二甲基-3,3’-二硫代双丙亚氨酸酯dtbp聚(乙烯亚胺)双氨基甲酸酯peic聚(l-赖氨酸)pll组氨酸修饰的pll聚(n-乙烯基吡咯烷酮)pvp聚(丙烯亚胺)ppi聚(酰胺基胺)pamam聚(酰胺基乙烯亚胺)ss-paei三亚乙基四胺teta聚(β-氨基酯)聚(4-羟基-l-脯氨酸酯)php聚(烯丙基胺)聚(α-[4-氨基丁基]-l-乙醇酸)paga聚(d,l-乳酸-共-乙醇酸)plga聚(n-乙基-4-乙烯基溴化吡啶鎓)聚(磷腈)ppz聚(磷酸酯)ppe聚(氨基磷酸酯)ppa聚(n-2-羟基丙基甲基丙烯酰胺)phpma聚(2-(二甲基氨基)甲基丙烯酸乙酯)pdmaema聚(2-氨乙基丙烯磷酸酯)ppe-ea壳聚糖半乳糖基化壳聚糖n-十二烷基化的壳聚糖组蛋白胶原葡聚糖-精胺d-spm非病毒载体任选地包括靶向修饰以改进摄取和/或选择性靶向某些细胞类型。这些靶向修饰可以包括例如细胞特异性抗原、单克隆抗体、单链抗体、适体、聚合物、糖(例如,n-乙酰半乳糖胺(galnac))和细胞穿透肽。此类载体还任选地使用致融性和核内体去稳定肽/聚合物,经历酸触发的构象变化(例如,加速负荷的核内体逃逸),和/或并入刺激可裂解的聚合物,例如用于在细胞区室中释放。例如,可以使用在还原性细胞环境中裂解的基于二硫化物的阳离子型聚合物。在某些实施例中,除了基因组编辑系统的组分(例如,本文所述的rna指导的核酸酶组分和/或grna组分)以外,递送一种或多种核酸分子(例如,dna分子)。在实施例中,核酸分子是在递送基因组编辑系统一个或多个组分的同时进行递送的。在实施例中,核酸分子是在递送基因组编辑系统的一个或多个组分之前或之后(例如,小于约30分钟、1小时、2小时、3小时、6小时、9小时、12小时、1天、2天、3天、1周、2周或4周)递送。在实施例中,核酸分子是通过与递送基因组编辑系统的一个或多个组分(例如,rna指导的核酸酶组分和/或grna组分)不同的方式来递送。该核酸分子可以通过本文所述的任何递送方法来递送。例如,核酸分子可以通过病毒载体(例如,整合缺陷型慢病毒)来递送,并且rna指导的核酸酶分子组分和/或grna组分可以通过电穿孔来递送,例如,使得可以降低由核酸(例如,dna)引起的毒性。在实施例中,核酸分子编码治疗性蛋白质(例如,本文所述的蛋白质)。在实施例中,核酸分子编码rna分子(例如,本文所述的rna分子)。rnp和/或编码基因组编辑系统组分的rna的递送可以通过本领域已知的方法将rnp(grna和rna指导的核酸酶(例如,本文所述的rna指导的核酸酶变体)的复合物)和/或编码rna指导的核酸酶(例如,本文所述的rna指导的核酸酶变体)和/或grna的rna(例如,mrna)递送至细胞中或施用于受试者,其中一些方法描述于cotta-ramusino中。在体外,可以例如通过显微注射、电穿孔、瞬时细胞压缩或挤压来递送编码rna指导的核酸酶(例如本文所述的rna指导的核酸酶变体)和/或grna的rna(例如mrna)(参见,例如,lee2012)。还可以使用脂质介导的转染、肽介导的递送、galnac或其他缀合物介导的递送和其组合进行体外和体内递送。在体外,通过电穿孔递送包含将细胞与编码rna指导的核酸酶和/或grna的rna(例如mrna)(具有或不具有供体模板核酸分子)在盒、室或比色皿中混合,并且施加一个或多个限定持续时间和幅度的电脉冲。用于电穿孔的系统和方案为本领域中已知,并且任何适宜的电穿孔工具和/或方案可以结合本披露的各个实施例使用。施用途径可以通过任何适宜模式或途径(局部或全身)将基因组编辑系统或使用此类系统改变或操作的细胞施用于受试者。全身施用模式包括口服和肠胃外途径。肠胃外途径包括例如静脉内、骨髓内、动脉内、肌内、真皮内、皮下、鼻内和腹膜内途径。可以修饰或配制全身施用的组分以靶向例如,hsc、造血干细胞/祖细胞或红系祖细胞或前体细胞。局部施用模式包括例如骨髓内注射至骨小梁中或股骨内注射到髓隙中,以及输注至门静脉中。在一个实施例中,与当全身施用(例如,静脉内)相比时,显著较少量的组分(与全身途径相比)可以在局部施用(例如,直接进入骨髓)时发挥作用。局部施用模式可以降低或消除在全身性施用治疗有效量的组分时可能发生的潜在毒副作用的发生率。可以以周期性推注(例如静脉内)的形式,或者从内部储库或外部储库(例如从静脉注射袋或可植入泵)持续输注提供施用。组分可以局部施用,例如,通过从持续释放药物递送装置中持续释放。此外,可以将组分配制成允许经延长的时段释放。释放系统可以包括生物可降解材料或通过扩散释放所并入组分的材料的基质。所述组分可以在释放系统中均匀或者非均匀分配。多种释放系统可以是有用的,然而,选择适当的系统将取决于具体应用所需要的释放速率。不可降解和可降解的释放系统均可以被使用。适宜释放系统包括聚合物和聚合基质、非聚合基质或无机和有机赋形剂和稀释剂,例如但不限于碳酸钙和糖(例如,海藻糖)。释放系统可以是天然的或合成的。然而,合成释放系统是优选的,因为其通常更可靠、更具可重现性并且产生更明确的释放曲线。可以选择释放系统材料,使得具有不同分子量的组分是通过穿过材料扩散或通过材料降解而释放。代表性的合成生物可降解聚合物包括例如:聚酰胺,例如聚(氨基酸)和聚(肽);聚酯,例如聚(乳酸)、聚(乙醇酸)、聚(乳酸-共-乙醇酸)和聚(己内酯);聚(酸酐);聚原酸酯;聚碳酸酯;和其化学衍生物(取代、添加化学基团,例如,烷基、亚烷基、羟化、氧化和本领域技术人员常规进行的其他修饰)、共聚物和其混合物。代表性的合成非生物可降解聚合物包括例如:聚醚,例如聚(氧化乙烯)、聚(乙二醇)和聚(环氧丁烷);乙烯基聚合物-聚丙烯酸酯和聚甲基丙烯酸酯,例如甲基、乙基、其他烷基、甲基丙烯酸羟乙酯、丙烯酸和甲基丙烯酸和其他,例如聚(乙烯醇)、聚(乙烯基吡咯烷酮)和聚(乙酸乙烯酯);聚(氨酯);纤维素和其衍生物,例如烷基、羟烷基、醚、酯、硝化纤维素和各种醋酸纤维素;聚硅氧烷;和其任何化学衍生物(取代、添加化学基团,例如,烷基、亚烷基、羟化、氧化和本领域技术人员常规进行的其他修饰)、共聚物和其混合物。也可以使用聚(丙交酯共乙交酯)微球。典型地,微球是由乳酸和乙醇酸的聚合物构成,其经结构化以形成空心球体。球体的直径可以是约15-30微米,并且可以加载本文所述的组分。组分的多模或差别递送技术人员将理解,基因组编辑系统的不同组分可以一起递送或分开递送,同时或不同时递送。可能尤其期望基因组编辑系统组分的分开和/或异步递送以提供对基因组编辑系统功能的时间或空间控制并限制由其活性引起的某些效应。如本文所用,不同或差别模式是指递送模式,这些递送模式赋予受试组分分子(例如,rna指导的核酸酶分子、grna、模板核酸或有效负载)不同的药效学或药物代谢动力学特性。例如,递送模式可以导致不同的组织分布,不同的半衰期或不同的时间分布,例如,在所选区室、组织或器官中。一些递送的模式(例如,通过例如通过自主复制或插入细胞核酸中而在细胞或细胞子代中持续存在的核酸载体来递送)导致组分更持久的表达和存在。实例包括病毒(例如,aav或慢病毒)递送。举例来说,基因组编辑系统的组分(例如,rna指导的核酸酶和grna)可以通过在所递送组分在体内或在特定区室、组织或器官中的所得半衰期或持久性方面不同的模式进行递送。在实施例中,grna可以通过此类模式进行递送。rna指导的核酸酶分子组分可以通过导致在身体或特定区室或组织或器官中更低持久性或更少暴露的模式进行递送。更一般地说,在实施例中,第一递送模式被用于递送第一组分并且第二递送模式被用于递送第二组分。第一递送模式赋予第一药效学或药物代谢动力学特性。第一药效学特性可以是例如组分或编码该组分的核酸在体内、区室、组织或器官中的分布、持久性或暴露。第二递送模式赋予第二药效学或药物代谢动力学特性。第二药效学特性可以是例如组分或编码该组分的核酸在体内、区室、组织或器官中的分布、持久性或暴露。在某些实施例中,第一药效学或药物代谢动力学特性(例如,分布、持久性或暴露)比第二药效学或药物代谢动力学特性更受限。在某些实施例中,第一递送模式经选择以优化(例如,最小化)药效学或药物代谢动力学特性(例如,分布、持久性或暴露)。在某些实施例中,第二递送模式经选择以优化(例如,最大化)药效学或药物代谢动力学特性(例如,分布、持久性或暴露)。在某些实施例中,第一递送模式包含使用相对持久的元件,例如,核酸,例如,质粒或病毒载体,例如,aav或慢病毒。由于此类载体相对持久,从其转录的产物将相对持久。在某些实施例中,第二递送模式包含相对瞬时元件,例如,rna或蛋白质。在某些实施例中,第一组分包含grna,并且递送模式相对持久,例如,grna是从质粒或病毒载体(例如,aav或慢病毒)转录。这些基因的转录将具有极小生理学意义,因为这些基因不编码蛋白质产物,并且这些grna不能够单独起作用。第二组分(rna指导的核酸酶分子)是以瞬时方式递送,例如,作为编码蛋白质的mrna或作为蛋白质递送,从而确保完整的rna指导的核酸酶分子/grna复合物仅在短时间段内存在并有活性。此外,这些组分可以不同的分子形式或用不同的互为补充以增强安全性和组织特异性的递送载体进行递送。差别递送模式的使用可以增强性能、安全性和/或功效,例如,可以减少最终脱靶修饰的可能性。通过较不持久的模式递送免疫原性组分(例如,cas9分子)可以降低免疫原性,因为来自细菌源cas酶的肽通过mhc分子展示于细胞表面上。两部分式递送系统可以改善这些缺点。差别递送模式可以用于将组分递送至不同但重叠的靶区域。在靶区域的重叠以外,活性复合物的形成被最小化。因此,在实施例中,第一组分(例如,grna)是通过第一递送模式进行递送,其导致第一空间(例如,组织)分布。第二组分(例如,rna指导的核酸酶分子)是通过第二递送模式进行递送,其导致第二空间(例如,组织)分布。在一个实施例中,第一模式包括选自脂质体、纳米颗粒(例如,聚合物纳米颗粒)、以及核酸(例如,病毒载体)的第一元件。第二模式包含选自该组的第二元件。在实施例中,第一递送模式包括第一靶向元件(例如,细胞特异性受体或抗体),并且第二递送模式不包括该元件。在某些实施例中,第二递送模式包括第二靶向元件(例如,第二细胞特异性受体或第二抗体)。当在病毒递送载体、脂质体或聚合纳米颗粒中递送rna指导的核酸酶分子时,存在递送至多个组织并且在多个组织中具有治疗活性的可能性,但此时可能希望仅靶向单一组织。两部分式递送系统可以解决这一挑战并且增强组织特异性。如果将grna分子和rna指导的核酸酶分子包装于具有不同但重叠的组织向性的分开的递送运载体中,那么完全功能复合物仅在两种载体所靶向的组织中形成。本文提及的所有出版物、专利申请、专利和其他参考文献以其整体通过援引并入本文。另外,所述材料、方法和实例仅是说明性的并不旨在是限制性的。除非另外定义,本文所使用的所有技术术语和科学术语具有与本发明所属领域的普通技术人员通常所理解的相同的含义。尽管可以在本发明的实践或测试中使用类似于或等同于本文描述的那些的方法和材料,但是下文描述了适合的方法和材料。通过以下实例进一步说明本披露。提供这些实例仅出于说明目的。它们不应以任何方式解释为限制本披露的范围或内容。实例实例1:等位基因特异性cas9向单个碱基对突变的进化赋予锥体杆体营养不良6(cord6)本实例表明,本发明的选择方法可用于进化策略中,以进化出位点特异性核酸酶,其对与野生型非疾病等位基因相比差异仅在于点突变(单碱基变化)的疾病等位基因具有特异性。cas9或其他靶向核酸酶在杂合序列的等位基因特异性切割中的使用受到混杂活性的阻碍,尤其是等位基因之间存在一个碱基差异的情况。我们旨在设计cas9突变体,该突变体可以选择性地仅切割一个等位基因,此处选择性地切割视网膜鸟苷酸环化酶(gucy2d)蛋白中具有r838s突变的等位基因,从而赋予cord6疾病表型。我们构建了质粒pevol_cord6,其编码cas9蛋白和靶向cord6序列taacctggaggatctgatcc(seqidno:1)的grna。pevol_cord6还组成型表达赋予对氨苄青霉素的抗性的β-内酰胺酶。还构建了两个噬菌粒(含有噬菌体起点f1元件的质粒)pselect_cord6和pselect_gucy2dwt,分别包含潜在的靶位点(seqidno:2)和(seqidno:3)。粗体表示r838s突变的位点。选择突变的位点为靶向野生型cas9pam的第六个位置()。在此实例中,我们选择了邻近在第六位置上带有a的经修饰pam(即)切割的cas9突变体(“阳性选择”),同时还选择了邻近在第六位置上带有c的经修饰pam(即)切割的cas9突变体(“阴性选择”)。pselect_cord6和pselect_gucy2dwt各自还包含组成型表达的氯霉素抗性基因和位于lac启动子的控制下的ccdb(细菌毒素),从而可以通过iptg(异丙基β-d-1-硫代吡喃半乳糖苷)诱导ccdb表达。将pselect_cord6和pselect_gucy2dwt分别包装到辅助噬菌体中。为了设计等位基因特异性,使用针对每个密码子并允许调整突变率的全面且无偏的诱变方法,使用pevol_cord6质粒作为诱变的初始模板,生成了cas9突变体的两个大肠杆菌细菌文库。对一个文库进行调整,使其具有每个cas9多肽3个氨基酸突变的中位数(“低”突变率),另一个具有每个cas9多肽5个氨基酸突变的中位数(“高”突变率)。在进化的每一轮中,我们在不断被噬菌体挑战的竞争性培养物中将pevol_cord6突变体的每个细菌文库首先对切割含有pselect_cord6的噬菌体进行阳性选择,然后针对切割pselect_gucy2dwt进行阴性选择,如下:为了感染细菌,将包装有适当pselect质粒的噬菌体添加到含有pevol_cord6突变体的文库的饱和细菌中,并将细菌文库在氨苄青霉素液体培养物中进行培养。对于每个文库,整个文库都在相同的液体培养物中进行培养。在此初始孵育和感染后,通过添加1mmiptg(其诱导ccdb)进行阳性选择。然后将培养物生长过夜,例如至少12小时。然后沉淀细胞,去除一定iptg。然后,通过在第二次过夜培养过程中在50μg/ml氯霉素(其由两种pselect质粒组成型表达)存在下且在iptg不存在下使细菌生长进行阴性选择。在阳性和阴性选择过程中,细菌都被液体培养物中存在的噬菌体连续感染,因此对切割(阳性选择情况下)或不切割(阴性选择情况下)提出了连续的挑战。阴性选择后,来自所有选定文库成员的合并的质粒dna被用作下一诱变反应的模板。我们以这种方式重复了三轮诱变(生成文库)、阳性选择和阴性选择。通过对每个文库施加双重选择压力,对包含对cord6等位基因具有特异性的pam的cas9突变体进行了严格选择。每次进化循环中在阴性选择轮后,对从合并的选定文库成员中分离的质粒dna进行pacbio下一代测序。在仅第一次进化循环后,我们发现一个特定的突变体约占群体的20%,表明具有高选择强度。我们着手使用含有突变蛋白的大肠杆菌细胞裂解物在含有野生型或突变体的gucy2d序列的扩增子上测试该突变体的切割活性。我们仅在cord6扩增子上观察到了切割(图1)。对该突变体的pam偏好的进一步分析还表明,对第六位a而不是c的特异性高两倍。这种高选择的突变体的活性证实了设计的选择性压力,并展示了通过无偏诱变方法和竞争性选择策略实现了等位基因特异性cas9突变体的成功工程化。实例2:使用已知的脱靶,具有降低的脱靶活性的cas9的进化本实例描述了如何能够在进化策略中使用本发明的选择方法以降低位点特异性dna结合酶的脱靶活性。脱靶切割是cas9靶向dna切割的常见副产物。为了减轻这种影响,可以在我们的系统中将对中靶切割的选择(“阳性选择”)与针对已知或潜在脱靶序列的选择(“阴性选择”)结合。脱靶,例如通过guide-seq或其他方法发现的脱靶,可以以知情的方式进行反选择。可替代地,可以选择潜在的脱靶(例如单碱基对错配)的文库。用这种方法,可以将特定指导物通过与已经进化为减少脱靶切割的cas9组合修整(tailored)为优先在适当的位置进行切割。在这种情况下,进化是通过如下进行:首先选择阳性选择中的中靶切割,然后针对指定脱靶的混合噬菌体群体进行阴性选择,之后进行任选的深度测序验证(图2)。该进化算法可以经数轮重复。实例3:等位基因特异性cas9的进化本实例表明,本发明的选择方法可用于进化策略中,以进化出位点特异性核酸酶,其对与野生型非疾病等位基因相比差异仅在于点突变(单碱基变化)的疾病等位基因具有特异性。然而,本发明的选择方法还可用于进化位点特异性核酸酶,其相比于等位基因(例如,野生型或非疾病等位基因)对差异超过单个碱基改变的另一等位基因(例如,突变体或疾病等位基因)具有特异性。cas9或其他靶向核酸酶在杂合序列的等位基因特异性切割中的使用受到混杂活性的阻碍,尤其是等位基因之间存在一个碱基差异的情况。我们旨在设计cas9突变体,该突变体将选择性地仅切割一种等位基因(例如等位基因1,突变体等位基因),而不切割差异为单个碱基的等位基因(例如等位基因2,野生型等位基因)。我们还旨在提高选择cas9突变体的方法的效率,以实现对一个等位基因的切割的最大区分。最大程度区分cas9突变体的选择可以通过控制例如选择过程中存在的cas9的量和/或提高阳性和阴性选择的效率来实现。选择系统中cas9的量可通过例如使用表达cas9的质粒的较低拷贝数来控制。在一些实施例中,通过将cas9的表达置于诱导型启动子的控制下来控制cas9的量。在一些实施例中,诱导型启动子是阿拉伯糖启动子(图3)。阳性和阴性选择过程可能依赖于毒素分子的诱导型表达和/或对诸如抗生素的药物的抗性的表达。例如,当从质粒诱导毒素表达时,只有包含识别并切割质粒中合适靶标(例如等位基因1,突变体等位基因)的cas9突变体的细胞才能存活。包含不能识别并切割适当靶标的cas9的细胞会被毒素杀死。该阳性选择步骤针对所有能够识别并切割适当靶标(例如等位基因1,突变体等位基因)的cas9分子进行选择。在另一个实施例中,当用抗生素处理细胞时,仅杀死包含cas9的细胞,cas9切割了质粒中赋予抗生素抗性的不适当靶标。包含不能识别不适当靶标(例如等位基因2,野生型等位基因)的cas9的细胞保持对抗生素的抗性并存活。该阴性选择步骤针对能够识别并切割不适当靶标(例如等位基因2,野生型等位基因)的cas9分子进行选择。阳性和阴性选择步骤用于鉴定高选择性cas9分子的效用至少部分取决于细胞杀伤的高度区分。选择过程中细胞生长动力学的比较可以表征最佳cas9分子的选择效率。使用tse2进行选择的效率构建了质粒pevol_cas,其编码cas9蛋白和靶向靶序列的grna。还构建了质粒pevol_nontargeting(pevol_非靶向),其编码cas9蛋白和非靶向grna。两种质粒都组成型表达β-内酰胺酶(其赋予对氨苄青霉素的抗性(ampr))和诱导型阿拉伯糖启动子(ara)抗性,以及控制cas9的表达的诱导型阿拉伯糖启动子(ara)。还构建了噬菌粒(含有噬菌体起点f1元件的质粒)pselect_mut和pselect_wt,其各自包含潜在的靶位点。所述噬菌粒还包含在lac启动子控制下的组成型表达的氯霉素抗性基因(cmr)和tse2(细菌毒素),其允许通过iptg(异丙基β-d-1-硫代吡喃半乳糖苷)诱导tse2表达。将pselect_mut和pselect_wt各自分别包装到辅助噬菌体中。为了设计等位基因特异性,使用针对每个密码子并允许调整突变率的全面且无偏的诱变方法,使用pevol_cas质粒作为诱变的初始模板,生成了cas9突变体的两个大肠杆菌细菌文库。对一个文库进行调整,使其具有每个cas9多肽3个氨基酸突变的中位数(“低”突变率),另一个具有每个cas9多肽5个氨基酸突变的中位数(“高”突变率)。在进化的每一轮中,我们在不断被噬菌体挑战的竞争性培养物中将pevol_cas突变体的每个细菌文库针对切割含有pselect_mut的噬菌体进行阳性选择,如下:为了感染细菌,将包装pselect_mut质粒的噬菌体添加到含有pevol_cas突变体或pevol_nontargeting的文库的细菌中,并将细菌文库在氨苄青霉素液体培养物中进行培养。对于每个文库,整个文库都在相同的液体培养物中进行培养。在此初始孵育和感染后,通过向pevol_cas培养物的子部分和pevol_nontargeting培养物的子部分中添加1mmiptg(诱导tse2表达)来评估使用tse2进行阳性选择的严格性。通过添加阿拉伯糖诱导cas9和指导rna的表达。在用iptg处理过的pevol_cas培养物中,未诱导cas9和指导rna的表达。然后将培养物生长过夜,例如至少12小时。在阳性选择过程中,细菌被液体培养物中存在的噬菌体连续感染,从而对切割靶标提出了持续的挑战。如图4所示,由于tse2的诱导,表达tse2但不表达cas9(-cas+tse2)或表达非靶向指导rna(+非靶向cas+tse2)的培养物表现出明显的生长滞后。相比之下,培养物诱导表达tse2、也表达cas9和靶向指导rna(+cas+tse2)(预期将切割靶标并抑制tse2的表达),显示在大约7小时内迅速生长。表达cas9和靶向或非靶向指导rna、但不诱导表达tse2的培养物在最初的6小时内显示出快速的细胞生长。这些数据表明,当不存在cas9或指导rna不识别靶标时,tse2具有显著的细胞杀伤作用。这些数据还表明适当靶向的cas9和指导rna抵消了tse2表达诱导的影响。通过调节cas9表达进行选择的效率使用pevol_wtcas质粒作为诱变的初始模板,以及针对每个密码子并允许调整突变率的全面且无偏见的诱变方法,生成了质粒文库pevol_caslibrary(pevol_cas文库)。质粒编码cas9蛋白和靶向靶序列的grna。还构建了编码野生型cas9蛋白和靶向grna的质粒pevol_wtcas。两种质粒都组成型表达β-内酰胺酶(其赋予对氨苄青霉素的抗性(ampr))和诱导型阿拉伯糖启动子(ara)抗性,以及控制cas9的表达的诱导型阿拉伯糖启动子(ara)。如上所述,还构建了噬菌粒(含有噬菌体起点f1元件的质粒)pselect_mut和pselect_wt,它们含有潜在的靶位点。为了感染细菌,将包装pselect_mut质粒的噬菌体添加到含有pevol_caslibrary突变体或pevol_wtcas的文库的饱和细菌中,并将细菌文库在氨苄青霉素液体培养物中进行培养。对于每个文库,整个文库都在相同的液体培养物中进行培养。在此初始孵育和感染后,通过向pevol_caslibrary培养物的子部分和pevol_wtcas培养物的子部分中添加1mmiptg(诱导tse2表达)来评估使用tse2和野生型cas或cas文库进行阳性选择的严格性。通过添加阿拉伯糖诱导cas9和grna的表达。在用iptg处理过的pevol_caslibrary和pevol_wtcas培养物中,未诱导cas9和grna表达。然后将培养物生长过夜,例如至少12小时。在阳性选择过程中,细菌被液体培养物中存在的噬菌体连续感染,从而对切割靶标提出了持续的挑战。如图5所示,表达tse2但不表达野生型cas9(-wtcas+tse2)或突变体cas9文库(-cas文库+tse2)的培养物由于tse2的诱导而显示出显著的生长滞后。然而,野生型cas9培养物比突变体cas9文库培养物显示出更大的生长滞后,表明即使在没有阿拉伯糖的情况下,cas9突变体的泄露表达(leakyexpression)。相比之下,诱导培养物以表达tse2,但也表达cas9和靶向指导rna(+wtcas+tse2或+cas文库+tse2),预期所述培养物将切割靶标并抑制tse2的表达,显示在大约7小时内迅速生长。表达野生型cas9或cas9文库突变体但未诱导表达tse2的培养物在最初的6小时内显示出快速的细胞生长。表达带有或不带有tse2的野生型cas9的培养物之间的细胞生长差异小于表达带有或不带有tse2的cas9文库突变体的培养物之间的细胞生长差异。这些数据表明cas9文库突变体比野生型cas9具有更高的切割活性。这些数据还证实当不存在cas9时,tse2具有明显的细胞杀伤作用。在过夜培养过程中,在50μg/ml氯霉素存在下使细菌生长也可以进行阴性选择(pselect_mut和pselect_wt噬菌粒组成型表达对氯霉素的抗性)。对照培养物未用氯霉素处理。在阴性选择过程中,细菌不断地被液体培养物中存在的噬菌体感染,从而对切割适当的靶标(等位基因1,突变体等位基因)而不切割不适当的靶标(等位基因2,野生型等位基因)提出了连续的挑战。由于通过脱靶切割消除了对氯霉素的抗性,野生型cas9(wtcas+cm)和突变体cas9文库(文库+cm)均显示出显著的生长滞后(图6)。但是,由于选择了未表现出脱靶作用并保持了氯霉素抗性的cas9突变体,突变体cas9文库突变体显示出生长的恢复。文库进化文库进化的连续轮次产生了对切割靶标具有高选择性水平的cas9突变体。当培养物诱导表达tse2时,生长滞后的连续减少证明了这一点。图7显示了与表达不诱导tse2的野生型cas9的培养物(wtcas-tse2)的生长相比时,当诱导tse2时野生型cas9培养物(wtcas+tse2)的显著生长滞后和显著的阴性δ(delta)。经过一轮诱变后,细胞生长的δ降低(例如,第1轮+tse2对比第1轮-tse2)。经过三轮诱变,对于诱导表达tse2的培养物和尚未诱导表达tse2的培养物,细胞生长曲线几乎相同。这些数据表明,tse2的使用和诱变的选择轮次可以生成对中靶切割具有高选择性的突变体cas9。实例4:酿脓链球菌cas9的进化,以减少脱靶切割如下面的实例将进一步说明的,本披露的系统和方法可用于选择多种核酸酶特征。使用本文披露的选择方法已经从诱变的文库中鉴定了酿脓链球菌cas9变体,所述变体保持了中靶切割效率,但是在脱靶基因座处的切割减少,从而提供了一种潜在地拯救用于治疗用途的混杂的指导物的手段。突变体酿脓链球菌cas9文库是使用随机靶标扫描诱变(smart)生成的。然后将文库转化到大肠杆菌中,并用噬菌体进行挑战(三轮阳性和阴性选择)。阳性选择步骤利用阳性选择质粒,所述质粒包含切割盒,所述切割盒包括针对人类基因组基因座的指导rna的中靶序列(seqidno:4),所述人类基因组基因座具有由guide-seq确定的多个脱靶,如表6中所示:表6:用于阳性和阴性选择的靶位点阳性/阴性可选靶标序列阳性(靶上)gtctgggcggtgctacaactngg(seqidno4)阴性(脱靶1)aactgggtggtgctccaactcgg(seqidno5)阴性(脱靶2)aacggggcggtactacaacttgg(seqidno6)阴性(脱靶3)gtctggtggtgctacaacttgg(seqidno7)阴性(脱靶4)acctggacggtgatacaacccgg(seqidno8)单个阴性选择步骤利用四个合并的构建体,每个构建体包含独特的脱靶,所述脱靶与中靶序列的区别在于四个残基(seqidno:5-7)。在阳性和阴性选择步骤之后,选择克隆并通过下一代测序(ngs)进行测序,并比对读段以鉴定相对于未突变的酿脓链球菌cas9(seqidno:13)最常见的突变的氨基酸残基。利用中靶和脱靶底物进行的体外切割试验表明,克隆表现出与wtcas9相当的中靶切割效率(图8a),但是同时少数克隆相对于wt表现出减少的脱靶切割,其他克隆在体外表现出基本上相同的脱靶切割效率(图8b)。如图9a和9b所示,还对人t细胞中的基因组靶上和脱靶基因座进行了靶上和脱靶分析。wt和突变体cas9/指导rna核糖核蛋白复合物(rnp)以跨>2log范围的不同浓度递送,收获基因组dna并扩增靶上和脱靶位点,并通过下一代测序进行测序。如图10中所示,相对于wtcas9,几个突变体克隆表现出略微降低的中靶切割活性,同时还表现出比wt明显更低的脱靶切割。这些数据一起确定了本文所述的噬菌体选择方法可以通过选择补偿性cas9突变体蛋白而成功地用于减少脱靶切割(用特定grna观察到的)。表2列出了在此筛选中鉴定出的克隆中突变的选定氨基酸残基,以及可以在每个位置取代以产生具有降低的脱靶活性的突变体的残基:表7:表现出较低的脱靶切割活性的酿脓链球菌cas9突变体中突变的位置位置取代d23ad1251gy128vt67ln497ar661aq695aq926a表8列出了根据本披露的某些实施例的示例性的单、双和三酿脓链球菌cas9突变体。为了清楚起见,本披露涵盖在表8中列出的位点中的1、2、3、4、5或更多位点处具有突变的cas9变体蛋白,尽管为便于展示在表中仅列出了单、双和三突变体。表8:酿脓链球菌cas9氨基酸突变体的选定位置在不限制前述内容的情况下,本披露涵盖以下突变体:d23a(突变体1)y128vd1251g(突变体2)t67l(突变体3)d23a、y128v(突变体4)d23a、d1251g(突变体5)d23a、y128v、d1251g、t67l(突变体6)n497a/r661a/q695a/q926a(突变体7)本披露还涵盖包含本文所述的突变体酿脓链球菌cas9的基因组编辑系统。在本披露的某些实施例中,本文所述的分离的spcas9变体蛋白与异源功能域以及任选的间插接头融合,其中所述接头不干扰融合蛋白的活性。在一些实施例中,异源功能域是转录激活域。在一些实施例中,转录激活域来自vp64或nf-κbp65。在一些实施例中,异源功能域是转录沉默子或转录抑制域。在一些实施例中,转录抑制域是krueppel相关盒(krab)域、erf阻遏域(erd)或msin3a相互作用域(sid)。在一些实施例中,转录沉默子是异染色质蛋白1(hp1),例如,hp1α或hp1β。在一些实施例中,异源功能域是修饰dna的甲基化状态的酶。在一些实施例中,修饰dna的甲基化状态的酶是dna甲基转移酶(dnmt)或tet蛋白。在一些实施例中,tet蛋白是tet1。在一些实施例中,异源功能域是修饰组蛋白亚基的酶。在一些实施例中,修饰组蛋白亚基的酶是组蛋白乙酰转移酶(hat)、组蛋白脱乙酰酶(hdac)、组蛋白甲基转移酶(hmt)或组蛋白脱甲基酶。在一些实施例中,异源功能域是生物系链。在一些实施例中,生物系链是ms2、csy4或λn蛋白。在一些实施例中,异源功能域是foki。除了涵盖编码本文所述变体spcas9蛋白的分离的核酸之外,本披露还涵盖包含此类分离的核酸的病毒和非病毒载体,所述载体任选地可操作地连接至用于表达本文所述的变体spcas9蛋白的一个或多个调节域。本披露还包括宿主细胞,例如哺乳动物宿主细胞,其包含本文所述的核酸,并任选表达本文所述的变体spcas9蛋白中的一种或多种。本文所述的变体spcas9蛋白可以用于改变细胞的基因组(例如通过在细胞中表达本文所述的分离的变体sacas9或spcas9蛋白)以及具有与该细胞的基因组的选定部分互补的区域的指导rna。可替代地或另外地,本披露进一步涵盖通过使细胞与本文所述的蛋白质变体和具有与该细胞的基因组的选定部分互补的区域的指导rna接触来改变(例如,选择性地改变)细胞基因组的方法。在一些实施例中,细胞是干细胞,例如胚胎干细胞、间充质干细胞或诱导的多能干细胞;在存在于生命的动物内;或存在于胚(例如哺乳动物、昆虫或鱼(例如斑马鱼)的胚)或胚细胞中。在一些实施例中,分离的蛋白质或融合蛋白包含核定位序列、细胞穿透肽序列和/或亲和标签中的一个或多个。此外,本披露涵盖用于改变细胞中的双链dna(dsdna)分子的方法,例如体外方法、离体和体内方法。所述方法包括使dsdna分子与本文所述的变体蛋白中的一种或多种以及具有与dsdna分子的选定部分互补的区域的指导rna接触。实例5:酿脓链球菌cas9的进化,以减少脱靶切割如下面的实例将进一步说明的,本披露的系统和方法可用于选择多种核酸酶特征。使用本文披露的选择方法已经从诱变的文库中鉴定了酿脓链球菌cas9变体,所述变体保持了中靶切割效率,但是在脱靶基因座处的切割减少,从而提供了一种潜在地拯救用于治疗用途的混杂的指导物的手段。突变体酿脓链球菌cas9文库是使用随机靶标扫描诱变(smart)生成的。然后将文库转化到大肠杆菌中,并用噬菌体进行挑战(三轮阳性和阴性选择)(图1和2)。在阳性和阴性选择步骤之后,选择克隆并通过下一代测序(ngs)进行测序,并比对读段以鉴定相对于未突变的酿脓链球菌cas9(seqidno:13)最常见的突变的氨基酸残基。确定了通过密码子位置和根据氨基酸取代鉴定的突变的频率(图11)。在ruvc域(例如d23a)、rec域(例如t67l、y128v)和pam相互作用域(pi)(例如d1251g)中鉴定出突变。制备包含4种不同突变(d23a、t67l、y128v和d1251g)的组合的表达构建体,并在体外测试人t细胞中的中靶和脱靶编辑效率。在这个实例中,包含突变d23a、y128v、d1251g和t67l的构建体被命名为“mut6”或“spartacas”。使用mut6和野生型酿脓链球菌cas9对t细胞中的基因组靶上和脱靶基因座进行了体外剂量反应研究,如图12中所示。野生型或突变体cas9/指导rna核糖核蛋白复合物(rnp)以跨>2log范围的不同浓度递送。如图12中所示,mut6构建体表现出与野生型酿脓链球菌cas9相当的中靶切割活性,同时还表现出比野生型大幅降低的脱靶切割。在6个不同基因座(位点a、位点b、位点c、位点d、位点e和位点f)处的靶上编辑使用野生型酿脓链球菌cas9(wtspcas9)、“spartacas”(突变体6)和两个已知的突变体酿脓链球菌cas9蛋白ecas(slaymaker等人science[科学](2015)351:84-88)和hf1cas9(kleinstiver等人nature[自然](2016)529:490-495)来评估。将1μm(基因座1和2)或5μm(基因座3-6)野生型或突变体cas9/指导rnarnp递送至人t细胞中。编辑效率是基因座依赖性的。在所有基因座上,spartacas的编辑效率均高于hf1cas9,而在6个基因座中的4个上,其编辑效率也高于ecas(图13)。使用野生型酿脓链球菌cas9(“spy”)、野生型金黄色葡萄球菌cas9(“sau”)、野生型氨基酸球菌属cpf1(“ascpf1”)、spartacas(“mut6”或“s6”)和包括人t细胞中的hf1cas9、ecas9和cas9(“altrcas9”)(www.idtdna.com)的可替代的突变体酿脓链球菌cas9蛋白进行进一步的中靶编辑剂量反应研究。中靶编辑是靶标依赖性的而spartacas表现出高效率的中靶编辑(图14a-14c)。以范围在从0.03125μm至4μm的rnp剂量,进一步评估spartacas(mut6)的中靶和脱靶切割效率。中靶切割与野生型酿脓链球菌cas9相当,而脱靶切割显著降低(图15)。实例6:使用guide-seq评估酿脓链球菌cas9变体的脱靶切割使用以下方法,使用guide-seq评估野生型cas9、ecas和spartacas的脱靶切割。rnp的复合将rnp与由集成dna技术(integrateddnatechnologies)合成的两部分式grna复合。以1:1的crrna与tracrrna比,将所有指导物退火至200um的终浓度。使rnp复合以达到1:2的酶与指导物比。使用1:1体积比的100um酶和200umgrna以达到50um的最终rnp浓度。使rnp在室温下复合30分钟。然后将rnp跨8个浓度连续稀释2倍。将rnp在-80℃下冷冻直至核转染。t细胞的培养用lonzax-vivo15培养基培养t细胞。解冻细胞并用dynabeads人t激活剂cd3/cd28培养以进行t细胞扩增和激活。解冻后第二天,将细胞从珠子上除去。将细胞继续培养至第4天,然后离心分离细胞进行核转染。核转染后第2天,将细胞体积分成两半,放入新的板中,使得它们有继续扩增的空间。t细胞核转染使用bioradt-20细胞计数器对细胞进行计数。将细胞与锥虫蓝1:1混合并计数。将所需的细胞总数(每孔足以容纳500k细胞)等分到独立的管中,然后以1500rpm离心5分钟。然后将细胞重悬于lonzap2核转染溶液中。然后将细胞以每孔20ul接种在lonza96孔核转染板中。然后将细胞和rnp板移到biomekfx机器人上。使用96孔头将每个rnp的2ul转移并混合到核转染板中。然后将核转染板立即移至lonza穿梭系统,在其中用ds-130脉冲编码进行核转染。然后将细胞立即移到biomekfx,在其中将所述细胞转移到预热的96孔未处理培养基板中并混合。然后将细胞板置于37℃下孵育。gdna提取在第4天,将细胞以2000rpm在其板中离心5分钟。然后将培养基倒出。然后将细胞沉淀重悬于agencourtdnadvance裂解液中。在biomekfx上使用dnadvance方案提取gdna。guide-seqguide-seq是基于tsai等人(nat.biotechnol.[自然生物技术]33:187-197(2015))的方案进行的并如下改适为适用于t细胞。将10ul的4.4um的rnp与4ul的100umdsodn和6ul的1xh150缓冲液合并,总体积为20ul。将rnp放置在冰上直至核转染。使用bioradt-20细胞计数器对t细胞进行计数。将细胞与锥虫蓝1:1混合并计数。将所需的细胞总数(每小池(cuvette)足以容纳200万个细胞)等分到独立的管中,然后以1500rpm离心5分钟。然后将细胞重悬于80ul的lonzap2溶液中。然后将细胞吸移到它们各自的小池中,并将20ul的rnp/dsodn添加到每个小池中,并将整个溶液轻轻混合。然后使用ca-137脉冲编码对细胞进行核转染。然后立即将细胞吸移到预温热的未涂布培养基板中。然后将细胞板置于37℃下孵育。仅使用双向读取,使用tsai等人(nat.biotechnol.[自然生物技术]33:187-197(2015))的方案进行gdna提取和分析。结果图18a和18b分别描绘了“位点g”和“位点h”的脱靶切割。如图18a和18b中所示,相对于野生型cas9,spartacas和ecas均减少了脱靶的总数。此外,剩余的大多数脱靶的读段计数均下降(以青色显示)。等同物应理解,虽然已经结合其详细描述,对本发明进行了描述,但前面的描述旨在说明而非限制本发明的范围,本发明的范围由所附的权利要求书的范围限定。其他方面、优点以及修改都在以下权利要求书的范围之内。序列表编码酿脓链球菌的cas9分子的示例性密码子优化的核酸序列(seqidno:9)。编码金黄色葡萄球菌的cas9分子的示例性密码子优化的核酸序列(seqidno:10)。编码金黄色葡萄球菌的cas9分子的示例性密码子优化的核酸序列(seqidno:11)。编码金黄色葡萄球菌的cas9分子的示例性密码子优化的核酸序列(seqidno:12)。示例性酿脓链球菌cas9氨基酸序列(seqidno:13)。示例性脑膜炎奈瑟氏球菌cas9氨基酸序列(seqidno:14)。序列表<110>爱迪塔斯医药公司(editasmedicine,inc.)<120>工程化的cas9核酸酶<130>2011271-0077<150>62/517811<151>2017-06-09<150>62/665388<151>2018-05-01<160>14<170>patentin3.5版<210>1<211>20<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>1taacctggaggatctgatcc20<210>2<211>26<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>2taacctggaggatctgatccgggaga26<210>3<211>26<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>3taacctggaggatctgatccgggagc26<210>4<211>23<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<220><221>尚未归类的特征<222>(21)..(21)<223>n是a、c、g、或t<400>4gtctgggcggtgctacaactngg23<210>5<211>23<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>5aactgggtggtgctccaactcgg23<210>6<211>23<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>6aacggggcggtactacaacttgg23<210>7<211>22<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>7gtctggtggtgctacaacttgg22<210>8<211>23<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>8acctggacggtgatacaacccgg23<210>9<211>4107<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>9atggataaaaagtacagcatcgggctggacatcggtacaaactcagtggggtgggccgtg60attacggacgagtacaaggtaccctccaaaaaatttaaagtgctgggtaacacggacaga120cactctataaagaaaaatcttattggagccttgctgttcgactcaggcgagacagccgaa180gccacaaggttgaagcggaccgccaggaggcggtataccaggagaaagaaccgcatatgc240tacctgcaagaaatcttcagtaacgagatggcaaaggttgacgatagctttttccatcgc300ctggaagaatcctttcttgttgaggaagacaagaagcacgaacggcaccccatctttggc360aatattgtcgacgaagtggcatatcacgaaaagtacccgactatctaccacctcaggaag420aagctggtggactctaccgataaggcggacctcagacttatttatttggcactcgcccac480atgattaaatttagaggacatttcttgatcgagggcgacctgaacccggacaacagtgac540gtcgataagctgttcatccaacttgtgcagacctacaatcaactgttcgaagaaaaccct600ataaatgcttcaggagtcgacgctaaagcaatcctgtccgcgcgcctctcaaaatctaga660agacttgagaatctgattgctcagttgcccggggaaaagaaaaatggattgtttggcaac720ctgatcgccctcagtctcggactgaccccaaatttcaaaagtaacttcgacctggccgaa780gacgctaagctccagctgtccaaggacacatacgatgacgacctcgacaatctgctggcc840cagattggggatcagtacgccgatctctttttggcagcaaagaacctgtccgacgccatc900ctgttgagcgatatcttgagagtgaacaccgaaattactaaagcaccccttagcgcatct960atgatcaagcggtacgacgagcatcatcaggatctgaccctgctgaaggctcttgtgagg1020caacagctccccgaaaaatacaaggaaatcttctttgaccagagcaaaaacggctacgct1080ggctatatagatggtggggccagtcaggaggaattctataaattcatcaagcccattctc1140gagaaaatggacggcacagaggagttgctggtcaaacttaacagggaggacctgctgcgg1200aagcagcggacctttgacaacgggtctatcccccaccagattcatctgggcgaactgcac1260gcaatcctgaggaggcaggaggatttttatccttttcttaaagataaccgcgagaaaata1320gaaaagattcttacattcaggatcccgtactacgtgggacctctcgcccggggcaattca1380cggtttgcctggatgacaaggaagtcagaggagactattacaccttggaacttcgaagaa1440gtggtggacaagggtgcatctgcccagtctttcatcgagcggatgacaaattttgacaag1500aacctccctaatgagaaggtgctgcccaaacattctctgctctacgagtactttaccgtc1560tacaatgaactgactaaagtcaagtacgtcaccgagggaatgaggaagccggcattcctt1620agtggagaacagaagaaggcgattgtagacctgttgttcaagaccaacaggaaggtgact1680gtgaagcaacttaaagaagactactttaagaagatcgaatgttttgacagtgtggaaatt1740tcaggggttgaagaccgcttcaatgcgtcattggggacttaccatgatcttctcaagatc1800ataaaggacaaagacttcctggacaacgaagaaaatgaggatattctcgaagacatcgtc1860ctcaccctgaccctgttcgaagacagggaaatgatagaagagcgcttgaaaacctatgcc1920cacctcttcgacgataaagttatgaagcagctgaagcgcaggagatacacaggatgggga1980agattgtcaaggaagctgatcaatggaattagggataaacagagtggcaagaccatactg2040gatttcctcaaatctgatggcttcgccaataggaacttcatgcaactgattcacgatgac2100tctcttaccttcaaggaggacattcaaaaggctcaggtgagcgggcagggagactccctt2160catgaacacatcgcgaatttggcaggttcccccgctattaaaaagggcatccttcaaact2220gtcaaggtggtggatgaattggtcaaggtaatgggcagacataagccagaaaatattgtg2280atcgagatggcccgcgaaaaccagaccacacagaagggccagaaaaatagtagagagcgg2340atgaagaggatcgaggagggcatcaaagagctgggatctcagattctcaaagaacacccc2400gtagaaaacacacagctgcagaacgaaaaattgtacttgtactatctgcagaacggcaga2460gacatgtacgtcgaccaagaacttgatattaatagactgtccgactatgacgtagaccat2520atcgtgccccagtccttcctgaaggacgactccattgataacaaagtcttgacaagaagc2580gacaagaacaggggtaaaagtgataatgtgcctagcgaggaggtggtgaaaaaaatgaag2640aactactggcgacagctgcttaatgcaaagctcattacacaacggaagttcgataatctg2700acgaaagcagagagaggtggcttgtctgagttggacaaggcagggtttattaagcggcag2760ctggtggaaactaggcagatcacaaagcacgtggcgcagattttggacagccggatgaac2820acaaaatacgacgaaaatgataaactgatacgagaggtcaaagttatcacgctgaaaagc2880aagctggtgtccgattttcggaaagacttccagttctacaaagttcgcgagattaataac2940taccatcatgctcacgatgcgtacctgaacgctgttgtcgggaccgccttgataaagaag3000tacccaaagctggaatccgagttcgtatacggggattacaaagtgtacgatgtgaggaaa3060atgatagccaagtccgagcaggagattggaaaggccacagctaagtacttcttttattct3120aacatcatgaatttttttaagacggaaattaccctggccaacggagagatcagaaagcgg3180ccccttatagagacaaatggtgaaacaggtgaaatcgtctgggataagggcagggatttc3240gctactgtgaggaaggtgctgagtatgccacaggtaaatatcgtgaaaaaaaccgaagta3300cagaccggaggattttccaaggaaagcattttgcctaaaagaaactcagacaagctcatc3360gcccgcaagaaagattgggaccctaagaaatacgggggatttgactcacccaccgtagcc3420tattctgtgctggtggtagctaaggtggaaaaaggaaagtctaagaagctgaagtccgtg3480aaggaactcttgggaatcactatcatggaaagatcatcctttgaaaagaaccctatcgat3540ttcctggaggctaagggttacaaggaggtcaagaaagacctcatcattaaactgccaaaa3600tactctctcttcgagctggaaaatggcaggaagagaatgttggccagcgccggagagctg3660caaaagggaaacgagcttgctctgccctccaaatatgttaattttctctatctcgcttcc3720cactatgaaaagctgaaagggtctcccgaagataacgagcagaagcagctgttcgtcgaa3780cagcacaagcactatctggatgaaataatcgaacaaataagcgagttcagcaaaagggtt3840atcctggcggatgctaatttggacaaagtactgtctgcttataacaagcaccgggataag3900cctattagggaacaagccgagaatataattcacctctttacactcacgaatctcggagcc3960cccgccgccttcaaatactttgatacgactatcgaccggaaacggtataccagtaccaaa4020gaggtcctcgatgccaccctcatccaccagtcaattactggcctgtacgaaacacggatc4080gacctctctcaactgggcggcgactag4107<210>10<211>3159<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>10atgaaaaggaactacattctggggctggacatcgggattacaagcgtggggtatgggatt60attgactatgaaacaagggacgtgatcgacgcaggcgtcagactgttcaaggaggccaac120gtggaaaacaatgagggacggagaagcaagaggggagccaggcgcctgaaacgacggaga180aggcacagaatccagagggtgaagaaactgctgttcgattacaacctgctgaccgaccat240tctgagctgagtggaattaatccttatgaagccagggtgaaaggcctgagtcagaagctg300tcagaggaagagttttccgcagctctgctgcacctggctaagcgccgaggagtgcataac360gtcaatgaggtggaagaggacaccggcaacgagctgtctacaaaggaacagatctcacgc420aatagcaaagctctggaagagaagtatgtcgcagagctgcagctggaacggctgaagaaa480gatggcgaggtgagagggtcaattaataggttcaagacaagcgactacgtcaaagaagcc540aagcagctgctgaaagtgcagaaggcttaccaccagctggatcagagcttcatcgatact600tatatcgacctgctggagactcggagaacctactatgagggaccaggagaagggagcccc660ttcggatggaaagacatcaaggaatggtacgagatgctgatgggacattgcacctatttt720ccagaagagctgagaagcgtcaagtacgcttataacgcagatctgtacaacgccctgaat780gacctgaacaacctggtcatcaccagggatgaaaacgagaaactggaatactatgagaag840ttccagatcatcgaaaacgtgtttaagcagaagaaaaagcctacactgaaacagattgct900aaggagatcctggtcaacgaagaggacatcaagggctaccgggtgacaagcactggaaaa960ccagagttcaccaatctgaaagtgtatcacgatattaaggacatcacagcacggaaagaa1020atcattgagaacgccgaactgctggatcagattgctaagatcctgactatctaccagagc1080tccgaggacatccaggaagagctgactaacctgaacagcgagctgacccaggaagagatc1140gaacagattagtaatctgaaggggtacaccggaacacacaacctgtccctgaaagctatc1200aatctgattctggatgagctgtggcatacaaacgacaatcagattgcaatctttaaccgg1260ctgaagctggtcccaaaaaaggtggacctgagtcagcagaaagagatcccaaccacactg1320gtggacgatttcattctgtcacccgtggtcaagcggagcttcatccagagcatcaaagtg1380atcaacgccatcatcaagaagtacggcctgcccaatgatatcattatcgagctggctagg1440gagaagaacagcaaggacgcacagaagatgatcaatgagatgcagaaacgaaaccggcag1500accaatgaacgcattgaagagattatccgaactaccgggaaagagaacgcaaagtacctg1560attgaaaaaatcaagctgcacgatatgcaggagggaaagtgtctgtattctctggaggcc1620atccccctggaggacctgctgaacaatccattcaactacgaggtcgatcatattatcccc1680agaagcgtgtccttcgacaattcctttaacaacaaggtgctggtcaagcaggaagagaac1740tctaaaaagggcaataggactcctttccagtacctgtctagttcagattccaagatctct1800tacgaaacctttaaaaagcacattctgaatctggccaaaggaaagggccgcatcagcaag1860accaaaaaggagtacctgctggaagagcgggacatcaacagattctccgtccagaaggat1920tttattaaccggaatctggtggacacaagatacgctactcgcggcctgatgaatctgctg1980cgatcctatttccgggtgaacaatctggatgtgaaagtcaagtccatcaacggcgggttc2040acatcttttctgaggcgcaaatggaagtttaaaaaggagcgcaacaaagggtacaagcac2100catgccgaagatgctctgattatcgcaaatgccgacttcatctttaaggagtggaaaaag2160ctggacaaagccaagaaagtgatggagaaccagatgttcgaagagaagcaggccgaatct2220atgcccgaaatcgagacagaacaggagtacaaggagattttcatcactcctcaccagatc2280aagcatatcaaggatttcaaggactacaagtactctcaccgggtggataaaaagcccaac2340agagagctgatcaatgacaccctgtatagtacaagaaaagacgataaggggaataccctg2400attgtgaacaatctgaacggactgtacgacaaagataatgacaagctgaaaaagctgatc2460aacaaaagtcccgagaagctgctgatgtaccaccatgatcctcagacatatcagaaactg2520aagctgattatggagcagtacggcgacgagaagaacccactgtataagtactatgaagag2580actgggaactacctgaccaagtatagcaaaaaggataatggccccgtgatcaagaagatc2640aagtactatgggaacaagctgaatgcccatctggacatcacagacgattaccctaacagt2700cgcaacaaggtggtcaagctgtcactgaagccatacagattcgatgtctatctggacaac2760ggcgtgtataaatttgtgactgtcaagaatctggatgtcatcaaaaaggagaactactat2820gaagtgaatagcaagtgctacgaagaggctaaaaagctgaaaaagattagcaaccaggca2880gagttcatcgcctccttttacaacaacgacctgattaagatcaatggcgaactgtatagg2940gtcatcggggtgaacaatgatctgctgaaccgcattgaagtgaatatgattgacatcact3000taccgagagtatctggaaaacatgaatgataagcgcccccctcgaattatcaaaacaatt3060gcctctaagactcagagtatcaaaaagtactcaaccgacattctgggaaacctgtatgag3120gtgaagagcaaaaagcaccctcagattatcaaaaagggc3159<210>11<211>3159<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>11atgaagcggaactacatcctgggcctggacatcggcatcaccagcgtgggctacggcatc60atcgactacgagacacgggacgtgatcgatgccggcgtgcggctgttcaaagaggccaac120gtggaaaacaacgagggcaggcggagcaagagaggcgccagaaggctgaagcggcggagg180cggcatagaatccagagagtgaagaagctgctgttcgactacaacctgctgaccgaccac240agcgagctgagcggcatcaacccctacgaggccagagtgaagggcctgagccagaagctg300agcgaggaagagttctctgccgccctgctgcacctggccaagagaagaggcgtgcacaac360gtgaacgaggtggaagaggacaccggcaacgagctgtccaccaaagagcagatcagccgg420aacagcaaggccctggaagagaaatacgtggccgaactgcagctggaacggctgaagaaa480gacggcgaagtgcggggcagcatcaacagattcaagaccagcgactacgtgaaagaagcc540aaacagctgctgaaggtgcagaaggcctaccaccagctggaccagagcttcatcgacacc600tacatcgacctgctggaaacccggcggacctactatgagggacctggcgagggcagcccc660ttcggctggaaggacatcaaagaatggtacgagatgctgatgggccactgcacctacttc720cccgaggaactgcggagcgtgaagtacgcctacaacgccgacctgtacaacgccctgaac780gacctgaacaatctcgtgatcaccagggacgagaacgagaagctggaatattacgagaag840ttccagatcatcgagaacgtgttcaagcagaagaagaagcccaccctgaagcagatcgcc900aaagaaatcctcgtgaacgaagaggatattaagggctacagagtgaccagcaccggcaag960cccgagttcaccaacctgaaggtgtaccacgacatcaaggacattaccgcccggaaagag1020attattgagaacgccgagctgctggatcagattgccaagatcctgaccatctaccagagc1080agcgaggacatccaggaagaactgaccaatctgaactccgagctgacccaggaagagatc1140gagcagatctctaatctgaagggctataccggcacccacaacctgagcctgaaggccatc1200aacctgatcctggacgagctgtggcacaccaacgacaaccagatcgctatcttcaaccgg1260ctgaagctggtgcccaagaaggtggacctgtcccagcagaaagagatccccaccaccctg1320gtggacgacttcatcctgagccccgtcgtgaagagaagcttcatccagagcatcaaagtg1380atcaacgccatcatcaagaagtacggcctgcccaacgacatcattatcgagctggcccgc1440gagaagaactccaaggacgcccagaaaatgatcaacgagatgcagaagcggaaccggcag1500accaacgagcggatcgaggaaatcatccggaccaccggcaaagagaacgccaagtacctg1560atcgagaagatcaagctgcacgacatgcaggaaggcaagtgcctgtacagcctggaagcc1620atccctctggaagatctgctgaacaaccccttcaactatgaggtggaccacatcatcccc1680agaagcgtgtccttcgacaacagcttcaacaacaaggtgctcgtgaagcaggaagaaaac1740agcaagaagggcaaccggaccccattccagtacctgagcagcagcgacagcaagatcagc1800tacgaaaccttcaagaagcacatcctgaatctggccaagggcaagggcagaatcagcaag1860accaagaaagagtatctgctggaagaacgggacatcaacaggttctccgtgcagaaagac1920ttcatcaaccggaacctggtggataccagatacgccaccagaggcctgatgaacctgctg1980cggagctacttcagagtgaacaacctggacgtgaaagtgaagtccatcaatggcggcttc2040accagctttctgcggcggaagtggaagtttaagaaagagcggaacaaggggtacaagcac2100cacgccgaggacgccctgatcattgccaacgccgatttcatcttcaaagagtggaagaaa2160ctggacaaggccaaaaaagtgatggaaaaccagatgttcgaggaaaagcaggccgagagc2220atgcccgagatcgaaaccgagcaggagtacaaagagatcttcatcaccccccaccagatc2280aagcacattaaggacttcaaggactacaagtacagccaccgggtggacaagaagcctaat2340agagagctgattaacgacaccctgtactccacccggaaggacgacaagggcaacaccctg2400atcgtgaacaatctgaacggcctgtacgacaaggacaatgacaagctgaaaaagctgatc2460aacaagagccccgaaaagctgctgatgtaccaccacgacccccagacctaccagaaactg2520aagctgattatggaacagtacggcgacgagaagaatcccctgtacaagtactacgaggaa2580accgggaactacctgaccaagtactccaaaaaggacaacggccccgtgatcaagaagatt2640aagtattacggcaacaaactgaacgcccatctggacatcaccgacgactaccccaacagc2700agaaacaaggtcgtgaagctgtccctgaagccctacagattcgacgtgtacctggacaat2760ggcgtgtacaagttcgtgaccgtgaagaatctggatgtgatcaaaaaagaaaactactac2820gaagtgaatagcaagtgctatgaggaagctaagaagctgaagaagatcagcaaccaggcc2880gagtttatcgcctccttctacaacaacgatctgatcaagatcaacggcgagctgtataga2940gtgatcggcgtgaacaacgacctgctgaaccggatcgaagtgaacatgatcgacatcacc3000taccgcgagtacctggaaaacatgaacgacaagaggccccccaggatcattaagacaatc3060gcctccaagacccagagcattaagaagtacagcacagacattctgggcaacctgtatgaa3120gtgaaatctaagaagcaccctcagatcatcaaaaagggc3159<210>12<211>3159<212>dna<213>人工序列<220><223>化学合成的寡核苷酸<400>12atgaagcgcaactacatcctcggactggacatcggcattacctccgtgggatacggcatc60atcgattacgaaactagggatgtgatcgacgctggagtcaggctgttcaaagaggcgaac120gtggagaacaacgaggggcggcgctcaaagaggggggcccgccggctgaagcgccgccgc180agacatagaatccagcgcgtgaagaagctgctgttcgactacaaccttctgaccgaccac240tccgaactttccggcatcaacccatatgaggctagagtgaagggattgtcccaaaagctg300tccgaggaagagttctccgccgcgttgctccacctcgccaagcgcaggggagtgcacaat360gtgaacgaagtggaagaagataccggaaacgagctgtccaccaaggagcagatcagccgg420aactccaaggccctggaagagaaatacgtggcggaactgcaactggagcggctgaagaaa480gacggagaagtgcgcggctcgatcaaccgcttcaagacctcggactacgtgaaggaggcc540aagcagctcctgaaagtgcaaaaggcctatcaccaacttgaccagtcctttatcgatacc600tacatcgatctgctcgagactcggcggacttactacgagggtccaggggagggctcccca660tttggttggaaggatattaaggagtggtacgaaatgctgatgggacactgcacatacttc720cctgaggagctgcggagcgtgaaatacgcatacaacgcagacctgtacaacgcgctgaac780gacctgaacaatctcgtgatcacccgggacgagaacgaaaagctcgagtattacgaaaag840ttccagattattgagaacgtgttcaaacagaagaagaagccgacactgaagcagattgcc900aaggaaatcctcgtgaacgaagaggacatcaagggctatcgagtgacctcaacgggaaag960ccggagttcaccaatctgaaggtctaccacgacatcaaagacattaccgcccggaaggag1020atcattgagaacgcggagctgttggaccagattgcgaagattctgaccatctaccaatcc1080tccgaggatattcaggaagaactcaccaacctcaacagcgaactgacccaggaggagata1140gagcaaatctccaacctgaagggctacaccggaactcataacctgagcctgaaggccatc1200aacttgatcctggacgagctgtggcacaccaacgataaccagatcgctattttcaatcgg1260ctgaagctggtccccaagaaagtggacctctcacaacaaaaggagatccctactaccctt1320gtggacgatttcattctgtcccccgtggtcaagagaagcttcatacagtcaatcaaagtg1380atcaatgccattatcaagaaatacggtctgcccaacgacattatcattgagctcgcccgc1440gagaagaactcgaaggacgcccagaagatgattaacgaaatgcagaagaggaaccgacag1500actaacgaacggatcgaagaaatcatccggaccaccgggaaggaaaacgcgaagtacctg1560atcgaaaagatcaagctccatgacatgcaggaaggaaagtgtctgtactcgctggaggcc1620attccgctggaggacttgctgaacaacccttttaactacgaagtggatcatatcattccg1680aggagcgtgtcattcgacaattccttcaacaacaaggtcctcgtgaagcaggaggaaaac1740tcgaagaagggaaaccgcacgccgttccagtacctgagcagcagcgactccaagatttcc1800tacgaaaccttcaagaagcacatcctcaacctggcaaaggggaagggtcgcatctccaag1860accaagaaggaatatctgctggaagaaagagacatcaacagattctccgtgcaaaaggac1920ttcatcaaccgcaacctcgtggatactagatacgctactcggggtctgatgaacctcctg1980agaagctactttagagtgaacaatctggacgtgaaggtcaagtcgattaacggaggtttc2040acctccttcctgcggcgcaagtggaagttcaagaaggaacggaacaagggctacaagcac2100cacgccgaggacgccctgatcattgccaacgccgacttcatcttcaaagaatggaagaaa2160cttgacaaggctaagaaggtcatggaaaaccagatgttcgaagaaaagcaggccgagtct2220atgcctgaaatcgagactgaacaggagtacaaggaaatctttattacgccacaccagatc2280aaacacatcaaggatttcaaggattacaagtactcacatcgcgtggacaaaaagccgaac2340agggaactgatcaacgacaccctctactccacccggaaggatgacaaagggaataccctc2400atcgtcaacaaccttaacggcctgtacgacaaggacaacgataagctgaagaagctcatt2460aacaagtcgcccgaaaagttgctgatgtaccaccacgaccctcagacttaccagaagctc2520aagctgatcatggagcagtatggggacgagaaaaacccgttgtacaagtactacgaagaa2580actgggaattatctgactaagtactccaagaaagataacggccccgtgattaagaagatt2640aagtactacggcaacaagctgaacgcccatctggacatcaccgatgactaccctaattcc2700cgcaacaaggtcgtcaagctgagcctcaagccctaccggtttgatgtgtaccttgacaat2760ggagtgtacaagttcgtgactgtgaagaaccttgacgtgatcaagaaggagaactactac2820gaagtcaactccaagtgctacgaggaagcaaagaagttgaagaagatctcgaaccaggcc2880gagttcattgcctccttctataacaacgacctgattaagatcaacggcgaactgtaccgc2940gtcattggcgtgaacaacgatctcctgaaccgcatcgaagtgaacatgatcgacatcact3000taccgggaatacctggagaatatgaacgacaagcgcccgccccggatcattaagactatc3060gcctcaaagacccagtcgatcaagaagtacagcaccgacatcctgggcaacctgtacgag3120gtcaaatcgaagaagcacccccagatcatcaagaaggga3159<210>13<211>1368<212>prt<213>酿脓链球菌<400>13metasplyslystyrserileglyleuaspileglythrasnserval151015glytrpalavalilethraspglutyrlysvalproserlyslysphe202530lysvalleuglyasnthrasparghisserilelyslysasnleuile354045glyalaleuleupheaspserglygluthralaglualathrargleu505560lysargthralaargargargtyrthrargarglysasnargilecys65707580tyrleuglngluilepheserasnglumetalalysvalaspaspser859095phephehisargleuglugluserpheleuvalglugluasplyslys100105110hisgluarghisproilepheglyasnilevalaspgluvalalatyr115120125hisglulystyrprothriletyrhisleuarglyslysleuvalasp130135140serthrasplysalaaspleuargleuiletyrleualaleualahis145150155160metilelyspheargglyhispheleuilegluglyaspleuasnpro165170175aspasnseraspvalasplysleupheileglnleuvalglnthrtyr180185190asnglnleupheglugluasnproileasnalaserglyvalaspala195200205lysalaileleuseralaargleuserlysserargargleugluasn210215220leuilealaglnleuproglyglulyslysasnglyleupheglyasn225230235240leuilealaleuserleuglyleuthrproasnphelysserasnphe245250255aspleualagluaspalalysleuglnleuserlysaspthrtyrasp260265270aspaspleuaspasnleuleualaglnileglyaspglntyralaasp275280285leupheleualaalalysasnleuseraspalaileleuleuserasp290295300ileleuargvalasnthrgluilethrlysalaproleuseralaser305310315320metilelysargtyraspgluhishisglnaspleuthrleuleulys325330335alaleuvalargglnglnleuproglulystyrlysgluilephephe340345350aspglnserlysasnglytyralaglytyrileaspglyglyalaser355360365glnglugluphetyrlyspheilelysproileleuglulysmetasp370375380glythrglugluleuleuvallysleuasnarggluaspleuleuarg385390395400lysglnargthrpheaspasnglyserileprohisglnilehisleu405410415glygluleuhisalaileleuargargglngluaspphetyrprophe420425430leulysaspasnargglulysileglulysileleuthrpheargile435440445protyrtyrvalglyproleualaargglyasnserargphealatrp450455460metthrarglysserglugluthrilethrprotrpasnphegluglu465470475480valvalasplysglyalaseralaglnserpheilegluargmetthr485490495asnpheasplysasnleuproasnglulysvalleuprolyshisser500505510leuleutyrglutyrphethrvaltyrasngluleuthrlysvallys515520525tyrvalthrgluglymetarglysproalapheleuserglyglugln530535540lyslysalailevalaspleuleuphelysthrasnarglysvalthr545550555560vallysglnleulysgluasptyrphelyslysileglucyspheasp565570575servalgluileserglyvalgluaspargpheasnalaserleugly580585590thrtyrhisaspleuleulysileilelysasplysasppheleuasp595600605asnglugluasngluaspileleugluaspilevalleuthrleuthr610615620leuphegluaspargglumetileglugluargleulysthrtyrala625630635640hisleupheaspasplysvalmetlysglnleulysargargargtyr645650655thrglytrpglyargleuserarglysleuileasnglyileargasp660665670lysglnserglylysthrileleuasppheleulysseraspglyphe675680685alaasnargasnphemetglnleuilehisaspaspserleuthrphe690695700lysgluaspileglnlysalaglnvalserglyglnglyaspserleu705710715720hisgluhisilealaasnleualaglyserproalailelyslysgly725730735ileleuglnthrvallysvalvalaspgluleuvallysvalmetgly740745750arghislysprogluasnilevalileglumetalaarggluasngln755760765thrthrglnlysglyglnlysasnserarggluargmetlysargile770775780glugluglyilelysgluleuglyserglnileleulysgluhispro785790795800valgluasnthrglnleuglnasnglulysleutyrleutyrtyrleu805810815glnasnglyargaspmettyrvalaspglngluleuaspileasnarg820825830leuserasptyraspvalasphisilevalproglnserpheleulys835840845aspaspserileaspasnlysvalleuthrargserasplysasnarg850855860glylysseraspasnvalproserglugluvalvallyslysmetlys865870875880asntyrtrpargglnleuleuasnalalysleuilethrglnarglys885890895pheaspasnleuthrlysalagluargglyglyleusergluleuasp900905910lysalaglypheilelysargglnleuvalgluthrargglnilethr915920925lyshisvalalaglnileleuaspserargmetasnthrlystyrasp930935940gluasnasplysleuilearggluvallysvalilethrleulysser945950955960lysleuvalseraspphearglysasppheglnphetyrlysvalarg965970975gluileasnasntyrhishisalahisaspalatyrleuasnalaval980985990valglythralaleuilelyslystyrprolysleuglusergluphe99510001005valtyrglyasptyrlysvaltyraspvalarglysmetileala101010151020lyssergluglngluileglylysalathralalystyrphephe102510301035tyrserasnilemetasnphephelysthrgluilethrleuala104010451050asnglygluilearglysargproleuilegluthrasnglyglu105510601065thrglygluilevaltrpasplysglyargaspphealathrval107010751080arglysvalleusermetproglnvalasnilevallyslysthr108510901095gluvalglnthrglyglypheserlysgluserileleuprolys110011051110argasnserasplysleuilealaarglyslysasptrpasppro111511201125lyslystyrglyglypheaspserprothrvalalatyrserval113011351140leuvalvalalalysvalglulysglylysserlyslysleulys114511501155servallysgluleuleuglyilethrilemetgluargserser116011651170pheglulysasnproileasppheleuglualalysglytyrlys117511801185gluvallyslysaspleuileilelysleuprolystyrserleu119011951200phegluleugluasnglyarglysargmetleualaseralagly120512101215gluleuglnlysglyasngluleualaleuproserlystyrval122012251230asnpheleutyrleualaserhistyrglulysleulysglyser123512401245progluaspasngluglnlysglnleuphevalgluglnhislys125012551260histyrleuaspgluileilegluglnileserglupheserlys126512701275argvalileleualaaspalaasnleuasplysvalleuserala128012851290tyrasnlyshisargasplysproilearggluglnalagluasn129513001305ileilehisleuphethrleuthrasnleuglyalaproalaala131013151320phelystyrpheaspthrthrileasparglysargtyrthrser132513301335thrlysgluvalleuaspalathrleuilehisglnserilethr134013451350glyleutyrgluthrargileaspleuserglnleuglyglyasp135513601365<210>14<211>1081<212>prt<213>脑膜炎奈瑟氏球菌<400>14alaalaphelysproasnserileasntyrileleuglyleuaspile151015glyilealaservalglytrpalametvalgluileaspglugluglu202530asnproileargleuileaspleuglyvalargvalphegluargala354045gluvalprolysthrglyaspserleualametalaargargleuala505560argservalargargleuthrargargargalahisargleuleuarg65707580thrargargleuleulysarggluglyvalleuglnalaalaasnphe859095aspgluasnglyleuilelysserleuproasnthrprotrpglnleu100105110argalaalaalaleuasparglysleuthrproleuglutrpserala115120125valleuleuhisleuilelyshisargglytyrleuserglnarglys130135140asngluglygluthralaasplysgluleuglyalaleuleulysgly145150155160valalaglyasnalahisalaleuglnthrglyasppheargthrpro165170175alagluleualaleuasnlyspheglulysgluserglyhisilearg180185190asnglnargserasptyrserhisthrpheserarglysaspleugln195200205alagluleuileleuleupheglulysglnlysglupheglyasnpro210215220hisvalserglyglyleulysgluglyilegluthrleuleumetthr225230235240glnargproalaleuserglyaspalavalglnlysmetleuglyhis245250255cysthrphegluproalagluprolysalaalalysasnthrtyrthr260265270alagluargpheiletrpleuthrlysleuasnasnleuargileleu275280285gluglnglysergluargproleuthraspthrgluargalathrleu290295300metaspgluprotyrarglysserlysleuthrtyralaglnalaarg305310315320lysleuleuglyleugluaspthralaphephelysglyleuargtyr325330335glylysaspasnalaglualaserthrleumetglumetlysalatyr340345350hisalaileserargalaleuglulysgluglyleulysasplyslys355360365serproleuasnleuserprogluleuglnaspgluileglythrala370375380pheserleuphelysthraspgluaspilethrglyargleulysasp385390395400argileglnprogluileleuglualaleuleulyshisileserphe405410415asplysphevalglnileserleulysalaleuargargilevalpro420425430leumetgluglnglylysargtyraspglualacysalagluiletyr435440445glyasphistyrglylyslysasnthrgluglulysiletyrleupro450455460proileproalaaspgluileargasnprovalvalleuargalaleu465470475480serglnalaarglysvalileasnglyvalvalargargtyrglyser485490495proalaargilehisilegluthralaarggluvalglylysserphe500505510lysasparglysgluileglulysargglnglugluasnarglysasp515520525argglulysalaalaalalyspheargglutyrpheproasnpheval530535540glygluprolysserlysaspileleulysleuargleutyrglugln545550555560glnhisglylyscysleutyrserglylysgluileasnleuglyarg565570575leuasnglulysglytyrvalgluileasphisalaleupropheser580585590argthrtrpaspaspserpheasnasnlysvalleuvalleuglyser595600605gluasnglnasnlysglyasnglnthrprotyrglutyrpheasngly610615620lysaspasnserargglutrpglngluphelysalaargvalgluthr625630635640serargpheproargserlyslysglnargileleuleuglnlysphe645650655aspgluaspglyphelysgluargasnleuasnaspthrargtyrval660665670asnargpheleucysglnphevalalaaspargmetargleuthrgly675680685lysglylyslysargvalphealaserasnglyglnilethrasnleu690695700leuargglyphetrpglyleuarglysvalargalagluasnasparg705710715720hishisalaleuaspalavalvalvalalacysserthrvalalamet725730735glnglnlysilethrargphevalargtyrlysglumetasnalaphe740745750aspglylysthrileasplysgluthrglygluvalleuhisglnlys755760765thrhispheproglnprotrpgluphephealaglngluvalmetile770775780argvalpheglylysproaspglylysprogluphegluglualaasp785790795800thrleuglulysleuargthrleuleualaglulysleuserserarg805810815proglualavalhisglutyrvalthrproleuphevalserargala820825830proasnarglysmetserglyglnglyhismetgluthrvallysser835840845alalysargleuaspgluglyvalservalleuargvalproleuthr850855860glnleulysleulysaspleuglulysmetvalasnarggluargglu865870875880prolysleutyrglualaleulysalaargleuglualahislysasp885890895aspproalalysalaphealagluprophetyrlystyrasplysala900905910glyasnargthrglnglnvallysalavalargvalgluglnvalgln915920925lysthrglyvaltrpvalargasnhisasnglyilealaaspasnala930935940thrmetvalargvalaspvalpheglulysglyasplystyrtyrleu945950955960valproiletyrsertrpglnvalalalysglyileleuproasparg965970975alavalvalglnglylysaspglugluasptrpglnleuileaspasp980985990serpheasnphelyspheserleuhisproasnaspleuvalgluval99510001005ilethrlyslysalaargmetpheglytyrphealasercyshis101010151020argglythrglyasnileasnileargilehisaspleuasphis102510301035lysileglylysasnglyileleugluglyileglyvallysthr104010451050alaleuserpheglnlystyrglnileaspgluleuglylysglu105510601065ileargprocysargleulyslysargproprovalarg107010751080当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1