一种羧肽酶及其编码基因、重组载体、重组菌及应用的制作方法
本发明涉及一种羧肽酶及其编码基因、重组载体、重组菌及应用,属于酶工程技术领域。
背景技术:
羧肽酶是一类水解肽链c末端氨基酸残基的蛋白酶,可以专一性地从肽链的c端逐个降解和释放氨基酸残基,其广泛存在于真菌、高等植物和动物组织中。根据来源的不同,可分为:动物羧肽酶、植物羧肽酶和微生物羧肽酶。根据羧肽酶活性中心含有氨基酸残基、半胱氨酸残基和金属离子的不同,又可分为:丝氨酸羧肽酶、半胱氨酸羧肽酶和金属羧肽酶。
赭曲霉毒素是一类由曲霉属(aspergillus)和青霉(penicillium)中某些微生物产生的有毒的次级代谢产物,主要污染小麦、玉米和豆类等粮食作物,且能够通过食物链传播到人类。其中,以赭曲霉毒素a(ochratoxinsa,ota)的毒性最强,危害最大。流行病学研究表示:ota是一种肾脏毒素和免疫抑制剂,且在某些动物物种中,其具有很强的致癌、致畸和致突变性。ota作为一种真菌毒素污染,广泛存在于食品和饲料产品中,对人和动物的健康存在着巨大的威胁,所以减少或去除粮食、食品及其原料中的ota对国民食品安全至关重要。
利用物理脱毒法去除ota,如拣选未污染物、清洗污染物以及吸附处理、澄清处理毒素等,虽然对毒素的残留量起到了一定的控制作用,但并没有从根本上彻底的去除自然界中的ota,且极易造成二次污染,对人和动物的健康仍有危害;化学脱毒法虽然具有高效性,但对实施条件的要求较为苛刻,且化学脱毒在降低毒素量的同时损害了饲料和食品中营养物质的含量;而相比这些传统的物理和化学脱毒法,生物脱毒法则更为温和,且不添加有害的化学药品,不易造成营养物质的损失。所以对于污染物的控制来说,生物脱毒法以其高效、低毒、环境污染小和特异性强等优点受到了越来越多人的青睐,成为当前研究领域的热点之一。
技术实现要素:
为解决上述问题,本发明提供一种来源于溶杆菌属降解菌种,其可以在原核表达系统中实现了异源高效表达,易于后期的纯化和酶制剂的制备,该酶对底物ota的12小时降解效率可以达到36.8%,其商业化生产成本低。
本发明的第一个目的是提供一种羧肽酶,其氨基酸序列如seqidno.1所示。
进一步地,所述的羧肽酶来源于溶杆菌属降解菌种。
本发明的第二个目的是提供编码所述羧肽酶的基因。
进一步地,所述的基因具有如seqidno.2所示的核苷酸序列。
本申请发明人将本发明的能够降解赭曲霉毒素的氨基酸序列和核苷酸序列经蛋白质数据库和核苷酸数据库分别进行搜寻比较发现其属于羧肽酶的一种,命名为cp239(基因命名为cp239)。
本发明的第三个目的是提供一种携带所述基因的重组载体。
进一步地,所述的载体为细菌质粒、噬菌体、酵母质粒、植物细胞病毒或哺乳动物细胞病毒。
本发明的第四个目的是提供一种表达所述羧肽酶的重组菌。
进一步地,是以细菌、真菌、植物、昆虫或动物细胞为宿主细胞。
通过常规的重组dna技术,利用本发明的多核苷酸序列可用来表达或生产重组的羧肽酶。一般来说有以下步骤:
(1)用本发明的编码羧肽酶的多核苷酸(或变异体),或用含有该多核苷酸的重组表达载体转化或转染合适的宿主细胞;
(2)在合适的培养基中培养宿主细胞;
(3)从培养基或细胞中分离、纯化蛋白质,或者使用细胞破碎后的粗酶液。
在步骤(2)中,根据所用的宿主细胞,培养中所用的培养基可选自各种常规培养基。在适于宿主细胞的条件下进行培养。当宿主细胞生长在适当的细胞密度后,用合适的方法诱导选择的启动子,将细胞再培养一段时间。
在步骤(3)中,重组酶可包被于细胞内、或在细胞膜上表达、或分泌到细胞外。如果需要,可利用其物理的、化学的和其它特性通过各种分离方法分离和纯化重组的蛋白。这些方法是本领域技术人员所熟知的。这些方法包括但不限于:常规的复性处理、蛋白沉淀剂处理(盐析方法)、离心、渗透破菌、超声波处理、超离心、亲和层析、分子筛层析(凝胶过滤)、吸附层析、离子交换层析、高效液相层析(hplc)和其它各种液相层析技术及这些方法的结合。
本发明的第五个目的是提供所述的羧肽酶在降解赭曲霉毒素中的应用。
进一步地,所述的应用包括降解粮食或茶叶中的赭曲霉毒素。
本发明的第六个目的是提供一种包含所述羧肽酶的酶制剂。
本发明的有益效果是:
本发明提供了一种羧肽酶及其编码基因,还提供了该羧肽酶在水解赭曲霉毒素和粮食赭曲霉毒素生物脱毒中的应用。该羧肽酶在温和条件下处理10ppb的赭曲霉毒素18小时,ota的降解率达到36.8%,这个降解效率在本领域具有很好的应用前景。
附图说明
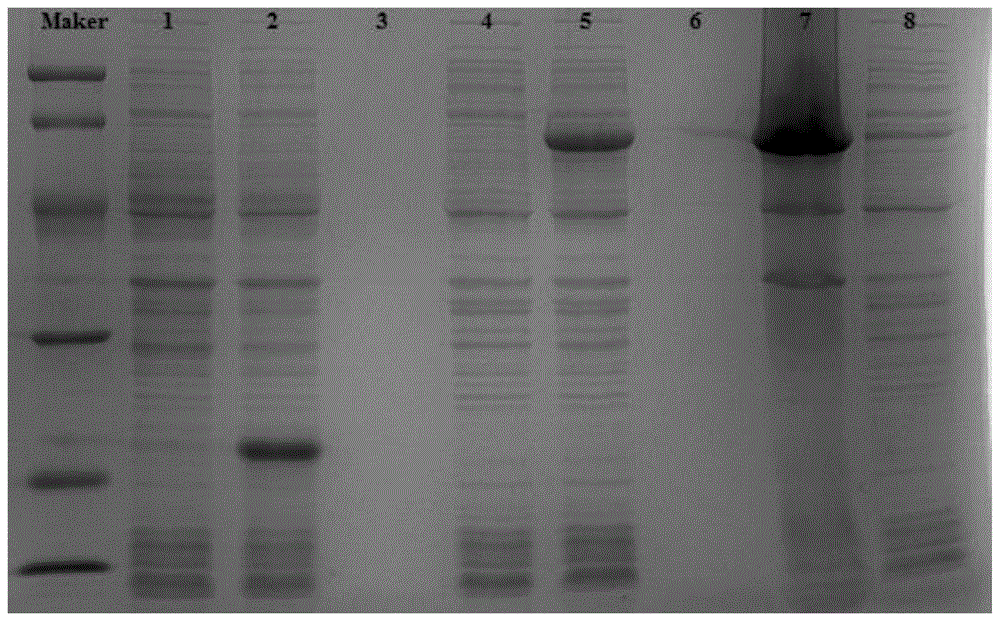
图1为原核表达的羧肽酶sds-page蛋白电泳;其中,marker:蛋白marker;1:空载体诱导前沉淀;2:空载体诱导后沉淀;3:空载体诱导后上清;4:重组子诱导前沉淀;5:重组子诱导后沉淀;6:重组子诱导后上清;7:重组子破碎后沉淀;8:重组子破碎后上清;
图2为原核表达的羧肽酶细菌破碎后的上清液对ota的降解效果;
图3为羧肽酶对小麦粉中赭曲霉毒素a的降解效果;
图4为羧肽酶对茯砖茶中赭曲霉毒素a的降解效果。
具体实施方式
下面结合附图和具体实施例对本发明作进一步说明,以使本领域的技术人员可以更好地理解本发明并能予以实施,但所举实施例不作为对本发明的限定。
羧肽酶的氧化活性鉴定方法和降解afb1活性测定方法如下:
羧肽酶活性测定方法如下:
含有pet-32a/cp239表达载体的转化株e.colibl21(de3)在最适条件下进行表达,取10μl表达菌液的破碎后上清液置于2ml离心管中,加入至490μl赭曲霉毒素a标准缓冲液(使用1*pbs配置ph7.3),赭曲霉毒素a的终浓度约为10ppb,反应18h,向反应体系中加入1.5ml的乙腈停止反应。使用高效液相色谱检测ota的残留量,实验结果表明,该重组酶粗酶液对ota的降解率达到36.8%。空白对照组为含有pet-32a空质粒的e.colibl21(de3)破碎后上清液,对照组破碎后粗酶液并无赭曲霉毒素a降解活性。
实施例1:羧肽酶基因的cdna合成与克隆
菌株来源于实验室前期得到的溶杆菌,通过基因序列测定,分析得到羧肽酶基因的开放式阅读框核苷酸序列,设计扩增出完整编码阅读框的引物上游引物(cp239-f)(seqidno.3):5'-cgcggatccatgaagtctcccgccgc-3';下游引物(cp239-r)(seqidno.4):5'-cccaagctttcaggccgactgccac-3',在上游和下游引物上分别引入限制性内切酶位点(可视选用的载体而定,本发明中添加了hindiii和xhoi酶切位点,已用下划线标出,斜体序列为保护碱基)。通过体外扩增技术获得编码seqidno.1所示氨基酸的羧肽酶基因,其序列如seqidno.2所示。在保证阅读框架正确的前提下构建好表达重组质粒pet-32a/cp239,再将其转入e.coilbl21(de3)中。序列分析得出,该cp239酶的理论等电点5.72,理论分子量为43.33kda。
实施例2:溶杆菌羧肽酶基因的异源表达
将实施例1中获得的e.coilbl21(de3)/pet-32a/cp239转化株在100ml含100μg/ml氨苄青霉素的lb液体培养基中摇床过夜培养。吸取1.0ml种子菌液接种于新鲜的100mllb液体培养基(含有100μg/ml氨苄青霉素)中,37℃温度下,180r/min震荡培养。当菌液od600达到0.6时,加入0.2mmol/ml的iptg在16℃条件下诱导表达4h。在7000r/min的转速下冷冻离心10min,弃尽上清。用10ml的1×磷酸盐缓冲液(pbs)悬浮菌体,在冰浴条件下超声波破碎菌体。离心,取上清。sds-page电泳结果显示菌体破碎后的上清液中含有该酶,其(包含gst标签22kda)表观分子量约为65kda(图1),与理论分子量相符。
实施例3:异源重组羧肽酶在赭曲霉毒素a生物脱毒中的应用
1、实验材料
酶制剂为pet-32a/cp239转化株表达后的破碎后上清液粗酶液,其他试剂均为分析纯化学试剂。
2、实验方法
取10μlpet-32a/cp239转化株表达后的破碎上清液置于2ml离心管中,加入至490μl赭曲霉毒素a标准缓冲液(使用1*pbs配置ph7.3),赭曲霉毒素a的终浓度约为10ppb,在35℃条件下,反应24h。以空质粒pet-32a作为对照,每组设3个平行组。向反应体系中加入1.5ml的乙腈停止反应。使用高效液相色谱检测ota的残留量,实验结果表明,反应24h后,该破碎后的上清液将ota降解率达到36.8%(图2)。
实施例4:异源重组羧肽酶在赭曲霉毒素污染粮食生物脱毒中的应用
1、实验材料
酶制剂为pet-32a/cp239转化株表达后的破碎上清液粗酶液,实验材料为小麦粉。其他试剂均为分析纯化学试剂。
2、实验方法
向50ml磷酸盐缓冲液中加入适量ota标准储备液,混匀后立即倾注于500g已粉碎好的小麦粉样品中,搅拌均匀,使ota的终浓度达到50.0μg/kg,于阴凉通风处晾干待用。取200ml酶制剂与200g预制备好的毒素污染小麦粉混合均匀,将配制好的样品在37℃条件下培养,于0h、6h、12h、24h取样,每个降解实验设置3个重复。同时,以200ml新鲜缓冲液与200g预制备好的毒素污染小麦粉混合均匀混合作为阴性对照处理。处理组和空白对照组每次取样20g,立即依据赭曲霉毒素标准检测方法进行提取、净化和分析。
毒素的提取与纯化。准确称取10g培养后的样品于150ml具塞三角瓶内,加入1gnacl和20ml甲醇-水混合液(体积比4:1),常温震荡提取30min,取下瓶塞经曹纹滤纸过滤于干净的杯子中(或在3000r/min下常温离心5min),准确移取5.0ml上清液并加入20ml纯水稀释混匀,经玻璃纤维滤纸过滤1-2次至滤液澄清,进行免疫亲和柱纯化操作。
准确移取10.0ml(代表1.0g样品)上述澄清滤液,注入玻璃注射器中,调节压力使溶液以1-2滴/秒的流速缓慢通过免疫亲和柱,直至有部分空气通过柱体,以10ml纯水淋洗柱子(重复一次),弃去全部流出液并使部分空气通过柱体。准确加入1.5ml甲醇洗脱,流速为1滴/秒,收集洗脱液于玻璃进样瓶中,进行hplc-fld检测。
羧肽酶对赭曲霉毒素的动态降解曲线如图3所示,实验结果表明,羧肽酶处理毒素污染的小麦粉(终浓度25μg/kg),24h对ota降解率接近46.7%。说明该羧肽酶对小麦粉中赭曲霉毒素a有较好的降解效果。
实施例5:异源重组羧肽酶在赭曲霉毒素污染黑茶中脱毒的应用
1、实验材料
酶制剂为pet-32a/cp239转化株表达后的破碎后上清液粗酶液,实验材料为茯砖茶。其他试剂均为分析纯化学试剂。
2、实验方法
向50ml磷酸盐缓冲液中加入适量ota标准储备液,混匀后立即倾注于500g已粉碎好的茶粉样品中,搅拌均匀,使ota的终浓度达到50.0μg/kg,于阴凉通风处晾干待用。取200ml酶制剂与200g预制备好的毒素污染茶粉混合均匀,将配制好的样品在37℃条件下培养,于0h、24h、48h、72h取样,每个降解实验设置3个重复。同时,以200ml新鲜缓冲液与200g预制备好的毒素污染茶粉混合均匀混合作为阴性对照处理。处理组和空白对照组每次取样20g,立即依据赭曲霉毒素标准检测方法进行提取、净化和分析。
毒素的提取与纯化。准确称取10g培养后的样品于150ml具塞三角瓶内,加入1gnacl和20ml甲醇-水混合液(体积比4:1),常温震荡提取30min,取下瓶塞经曹纹滤纸过滤于干净的杯子中(或在3000r/min下常温离心5min),准确移取5.0ml上清液并加入20ml纯水稀释混匀,经玻璃纤维滤纸过滤1-2次至滤液澄清,进行免疫亲和柱纯化操作。
准确移取10.0ml(代表1.0g样品)上述澄清滤液,注入玻璃注射器中,调节压力使溶液以1-2滴/秒的流速缓慢通过免疫亲和柱,直至有部分空气通过柱体,以10ml纯水淋洗柱子(重复一次),弃去全部流出液并使部分空气通过柱体。准确加入1.5ml甲醇洗脱,流速为1滴/秒,收集洗脱液于玻璃进样瓶中,进行hplc-fld检测。
羧肽酶对茶粉中的赭曲霉毒素动态降解曲线如图4所示,实验结果表明,该酶处理毒素污染的茶粉(终浓度25μg/kg)72h的降解率接近为54.5%。说明该羧肽酶对茶粉中赭曲霉毒素a有高效的降解能力。
以上所述实施例仅是为充分说明本发明而所举的较佳的实施例,本发明的保护范围不限于此。本技术领域的技术人员在本发明基础上所作的等同替代或变换,均在本发明的保护范围之内。本发明的保护范围以权利要求书为准。
序列表
<110>安徽农业大学
<120>一种羧肽酶及其编码基因、重组载体、重组菌及应用
<160>4
<170>siposequencelisting1.0
<210>1
<211>405
<212>prt
<213>(人工序列)
<400>1
metlysserproalaalapheargvalileglyleualaalaleuthr
151015
thrleualavalglyphealaphealaglnthrproalaleuprolys
202530
prothrgluglnalaproalaserglualaleuprovalpropropro
354045
progluvalvalglythralatrpvalvalmetaspalaalasergly
505560
aspvalleualaglygluasnileaspthrproleugluproalaser
65707580
ilethrlysvalmetthrsertyrvalilealaalaglumetalagly
859095
glylysilelysproaspaspglnvalmetmetsergluasnalatrp
100105110
arglysglyglyalaglythraspglysertyrserglypheglnval
115120125
asnglnthralaproleuleuglumetglulysglymetvalvalgln
130135140
serglyasnaspalaalailealaleualagluhisvalalaglyser
145150155160
gluglualaphealaalaleumetasnglntyralaalaargilegly
165170175
metlysasnthrhisphealaasnalathrglyleuproaspglngly
180185190
hisleuserseralaargaspleualaleuleuglyargalaleuala
195200205
leuhispheprogluthrtyralatyrasnlysilelysgluphethr
210215220
valglyproilethrglnproasnargasnvalleuleutrpargasp
225230235240
serservalaspglyilelysthrglyhisthrserglyalaglytyr
245250255
cysleumetalaseralaglnargglygluglnargleuvalserval
260265270
valleuglyserthrserglulysglnargalaseraspserglnala
275280285
leuleuasntrpglypheargphetyrgluthrhislysleutyrasp
290295300
alaaspvalserilealaaspglnlysvaltrplysglyvalalaasn
305310315320
gluileglnleuglyleualagluproleuleuvalthrvalproarg
325330335
glyargtyraspglnleulysprothrmetaspvalproargthrleu
340345350
valalaproileserglnglyglnalaileglythrvallysvalmet
355360365
leuaspglylysvalvalalagluargproleuvalalaleualaala
370375380
valglugluglyglyphephelysargleutrphisgluleuleumet
385390395400
trptrpglnserala
405
<210>2
<211>1218
<212>dna
<213>(人工序列)
<400>2
atgaagtctcccgccgctttccgcgtgatcggccttgccgcattgaccacccttgccgtc60
ggcttcgccttcgcgcagacgcccgcgctgccgaagccgaccgaacaggccccggccagc120
gaagcgctgcccgtcccgccgccacccgaagtggtcggcacggcgtgggtggtgatggat180
gcggccagcggcgacgtgctggcaggcgagaacatcgacaccccgctggagccggccagt240
atcaccaaggtcatgaccagctacgtgatcgccgccgagatggccggcggcaagatcaag300
cccgacgaccaggtgatgatgagcgagaacgcctggcgcaagggcggcgccggcaccgac360
ggcagctactcgggtttccaggtcaaccagaccgcgccgctgctggagatggagaagggc420
atggtggtgcagtccggcaacgacgccgcgatcgccctggccgagcacgtcgccggcagc480
gaggaggcgttcgccgcgctgatgaaccagtacgcggcgcgtatcggcatgaagaacacc540
cacttcgccaacgcgaccggcctgccggaccagggccacctgtccagcgcgcgcgacctg600
gcgttgctgggccgcgccctggcgctgcacttccccgaaacctacgcctacaacaagatc660
aaggagttcaccgtcgggccgatcacccagcccaaccgcaacgtgctgctgtggcgcgac720
agcagcgtggacggcatcaagaccggccacacctccggcgccggctactgcctgatggcc780
tcggcccagcgcggcgagcagcgcctggtatcggtggtgctcggctcgacctcggaaaag840
cagcgtgccagcgacagccaggcgctgctgaactggggtttccgcttctacgagacccac900
aagctgtatgacgcggacgtctcgatcgccgaccagaaagtgtggaagggtgtcgccaac960
gaaatccagctcgggctggccgagccgctgctggtgacggtcccgcgcggcaggtacgac1020
cagctcaagccgaccatggacgtgcccaggaccctggtggcaccgatcagccaaggccag1080
gcgatcggcacggtgaaggtcatgctcgacggcaaggtcgttgccgagcggccgctggtg1140
gcgctggccgcggtcgaggagggcggcttcttcaagcgcctgtggcacgagctgctgatg1200
tggtggcagtcggcctga1218
<210>3
<211>26
<212>dna
<213>(人工序列)
<400>3
cgcggatccatgaagtctcccgccgc26
<210>4
<211>25
<212>dna
<213>(人工序列)
<400>4
cccaagctttcaggccgactgccac25
- 还没有人留言评论。精彩留言会获得点赞!