鉴定小麦产量相关性状的分子标记与方法与流程
本发明涉及生物技术领域中,鉴定小麦产量相关性状的分子标记与方法。
背景技术:
小麦是世界的主要粮食作物。随着全球气候变化,各种极端天气频发,严重影响了小麦生产。为确保粮食安全,迫切需要培育抗逆、稳产、广适的小麦新品种,挖掘和利用小麦自身优异遗传资源是解决这一问题的有效途径。nac(nam,ataf和cuc)转录因子是植物特有的一种转录因子,它不仅在植物生长发育过程中起重要作用,而且还参与对高盐、低温、低氧和干旱等多种非生物胁迫的响应。如何将nac用于抗逆高产农作物新品种培育,不仅是分子生物学家和遗传学家关注的焦点,也是育种家迫切要解决的问题。从农作物种质资源中发掘nac优异等位基因,然后通过传统杂交和分子标记辅助选择相结合加以利用,无疑是最直接、最有效,也是最易被接受的农作物品种改良方法。常规育种通常依赖表型选择,尽管取得很大成就,但耗时耗力,进展缓慢;相比较而言,分子标记辅助选择育种可以在早世代进行有针对性的选择,操作简单易行,且可以高效利用优异基因,能显著加快育种进程。
技术实现要素:
本发明所要解决的技术问题是如何检测小麦的产量相关性状—穗长和每穗小穗数。
为解决上述技术问题,本发明首先提供了一种鉴定或辅助鉴定小麦产量相关性状的方法,所述产量相关性状为穗长和每穗小穗数,所述方法包括:检测待测小麦h和j位点的核苷酸,根据h和j位点的核苷酸确定待测小麦性状:
h位点为t的小麦穗长长于或候选长于h位点为g的小麦穗长;j位点为c的小麦每穗小穗数多于或候选多于j位点为t的小麦每穗小穗数;
所述h位点为序列表序列1自5′末端的第31位;
所述j位点为序列表序列2自5′末端的第21位。
所述待测小麦可为大于等于两种小麦组成的小麦群体。
上述方法中,所述检测待测小麦h和j位点的核苷酸可包括1)和2):
1)利用名称为ph的引物对对待测小麦的基因组dna进行pcr扩增,检测pcr扩增产物对应于序列表中序列1的第31位的核苷酸,确定所述h位点的核苷酸;所述ph能扩增得到含有所述h位点的dna片段;
2)利用名称为pj的引物对对待测小麦的基因组dna进行pcr扩增,检测pcr扩增产物对应于序列表中序列2的第21位的核苷酸,确定所述j位点的核苷酸;所述pj能扩增得到含有所述j位点的dna片段。
利用名称为ph的引物对对待测小麦的基因组dna进行pcr扩增,可先利用名称为nac67ds的引物对对所述待测小麦的基因组dna进行pcr扩增,得到nac67dspcr扩增产物,然后再利用所述ph对所述nac67dspcr扩增产物进行pcr扩增;所述nac67dspcr扩增产物含有h和j位点。
利用名称为pj的引物对对待测小麦的基因组dna进行pcr扩增,可利用所述ph对所述nac67dspcr扩增产物进行pcr扩增。
所述nac67ds由nac67dsf和nac67dsr组成,所述nac67dsf和所述nac67dsr分别为序列表中序列7和8所示的单链dna。
上述方法中,所述ph由名称分别为pe1和pe2的单链dna组成,所述pe1的序列可为序列表中序列3,所述pe2的序列可为序列表中序列4;
所述pj由名称分别为pe3和pe4的单链dna组成,所述pe3的序列可为序列表中序列5,所述pe4的序列可为序列表中序列6。
利用所述ph和所述pj进行pcr扩增时反应体系中两条单链dna的浓度均可为0.5μmol/l。利用所述ph和所述pj进行pcr扩增的反应体系具体可为:模板dna2μl(10pg-1μg)、2×utaqpcrmastermix10μl、正向引物(10μmol/l)和反向引物(10μmol/l)各1.0μl,补ddh2o至20.0μl。所述2×utaqpcrmastermix10μl具体可为北京庄盟国际生物基因科技有限公司产品。
利用所述ph进行pcr扩增时的退火温度可为61℃。利用所述ph进行pcr扩增的条件具体可为:95℃5min;95℃1min,61℃45s,72℃30s,33次循环;72℃10min,4℃保存。
利用所述pj进行pcr扩增时的退火温度可为64℃。利用所述pj进行pcr扩增的条件可为95℃5min;95℃1min,64℃45s,72℃30s,33次循环;72℃10min,4℃保存。
上述方法中,检测pcr扩增产物对应于序列表中序列1的第31位的核苷酸可通过包括如下a1)或a2)的方法完成:
a1)利用haeⅲ对所述ph的pcr扩增产物进行酶切,得到酶切产物,检测所述酶切产物的大小,根据所述酶切产物的大小确定pcr扩增产物对应于序列表中序列1的第31位的核苷酸:若所述酶切产物为308bp的dna片段,所述pcr扩增产物对应于序列表中序列1的第31位的核苷酸为t,即所述待测小麦在h位点的核苷酸为t;若所述酶切产物为276bp、32bp的两个dna片段,所述pcr扩增产物对应于序列表中序列1的第31位的核苷酸为g,即所述待测小麦在h位点的核苷酸为g;若所述酶切产物为308bp、276bp、32bp的三个dna片段,所述pcr扩增产物对应于序列表中序列1的第31位的核苷酸为t和g,即所述待测小麦在h位点的核苷酸为t和g;
a2)对所述ph的pcr扩增产物进行测序,若所述pcr扩增产物含有序列表中序列1所示的dna片段、且不含有序列9所示的dna片段,所述pcr扩增产物对应于序列表中序列1的第31位的核苷酸为g,即所述待测小麦在h位点的核苷酸为g;若所述pcr扩增产物含有序列表中序列9所示的dna片段、且不含有序列1所示的dna片段,所述pcr扩增产物对应于序列表中序列1的第31位的核苷酸为t,即所述待测小麦在h位点的核苷酸为t;若所述pcr扩增产物含有序列表中序列9和序列1所示的两条dna片段,所述pcr扩增产物对应于序列表中序列1的第31位的核苷酸为t和g,即所述待测小麦在h位点的核苷酸为t和g;
检测所述pj的pcr扩增产物对应于序列表中序列2的第21位的核苷酸通过包括如下b1)或b2)的方法完成:
b1)利用salⅰ对所述pj的pcr扩增产物进行酶切,得到酶切产物,检测所述酶切产物的大小,根据所述酶切产物的大小确定pcr扩增产物对应于序列表中序列2的第21位的核苷酸:若所述酶切产物为216bp的dna片段,所述pcr扩增产物对应于序列表中序列2的第21位的核苷酸为t,即所述待测小麦在j位点的核苷酸为t;若所述酶切产物为200bp、16bp的两条dna片段,所述pcr扩增产物对应于序列表中序列2的第21位的核苷酸为c,即所述待测小麦在j位点的核苷酸为c;若所述酶切产物为216bp、200bp、16bp的三条dna片段,所述pcr扩增产物对应于序列表中序列2的第21位的核苷酸为t和c,即所述待测小麦在j位点的核苷酸为t和c;
b2)对所述ph的pcr扩增产物进行测序,若所述pcr扩增产物含有序列表中序列10所示的dna片段、且不含有序列11所示的dna片段,所述pcr扩增产物对应于序列表中序列2的第21位的核苷酸为t,即所述待测小麦在j位点的核苷酸为t;若所述pcr扩增产物含有序列表中序列11所示的dna片段、且不含有序列10所示的dna片段,所述pcr扩增产物对应于序列表中序列2的第21位的核苷酸为c,即所述待测小麦在j位点的核苷酸为c;若所述pcr扩增产物含有序列表中序列11和序列10所示的两条dna片段,所述pcr扩增产物对应于序列表中序列2的第21位的核苷酸为t和c,即所述待测小麦在j位点的核苷酸为t和c。
检测酶切产物的大小可通过电泳进行。
本发明还提供了一种检测待测小麦基因组dna中h和j位点的核苷酸的方法,所述方法包括按照所述检测待测小麦h和j位点的核苷酸的方法检测待测小麦基因组dna中h和j位点的核苷酸。
本发明还提供了一种鉴定或辅助鉴定待测小麦产量相关性状的产品,所述产品为检测待测小麦基因组的h和j位点核苷酸的物质。
所述物质可包括所述ph和所述pj。
所述物质还可包括限制性内切酶,所述限制性内切酶为haeⅲ和/或salⅰ。
所述产品还可包括所述nac67ds。
所述产品可由所述ph和所述pj组成,也可由所述ph和所述pj与所述限制性内切酶组成,还可由所述ph和所述pj、所述限制性内切酶与所述nac67ds组成。
所述产品可为试剂盒。
本发明还提供了下述任一应用:
x1)所述产品在鉴定或辅助鉴定小麦产量相关性状中的应用;
x2)所述产品在制备鉴定或辅助鉴定待测小麦产量相关性状产品中的应用;
x3)所述产品在培育穗长长和/或每穗小穗数高的小麦中的应用;
x4)所述检测待测小麦h和j位点的核苷酸的方法在培育穗长长和/或每穗小穗数高的小麦中的应用。
本发明还提供了小麦育种方法,所述方法包括:按照所述检测待测小麦h和j位点的核苷酸的方法检测小麦h和j位点的核苷酸,选择h位点为t和j位点为c的小麦作为亲本进行育种。
本发明中,每穗小穗数为每个主穗上小穗的个数。
本发明中,h位点为t的小麦穗长长于或候选长于h位点为g的小麦穗长。j位点为c的小麦每穗小穗数高于或候选高于j位点为t的小麦每穗小穗数。
本发明发现2处单核苷酸多态性位点(命名为h和j位点)分别与小麦的穗长和每穗小穗数相关:h位点为t的小麦穗长长于h位点为g的小麦穗长。j位点为c的小麦每穗小穗数高于j位点为t的小麦每穗小穗数。通过检测h和j位点的核苷酸,即可找到穗长和每穗小穗数相对较高的小麦。本发明为小麦分子标记辅助选择育种提供了一个新方法,在培育高产小麦品种或研究中具有重要意义。
附图说明
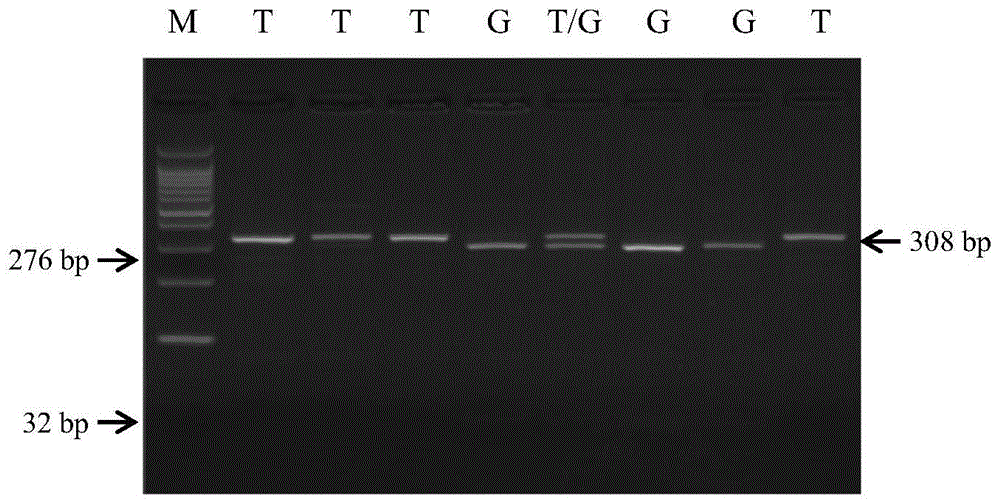
图1和图2为根据本发明的pcr扩增产物的酶切产物电泳检测结果。
其中,泳道m为100bpdnaladder。图1中所示为用haeⅲ对不同小麦的ph引物对的pcr扩增产物进行酶切的带型。泳道t含有一条308bp的条带;泳道g含有两条从上至下依次为276bp和32bp的条带,由于电泳时间较长,32bp的小片段条带较为模糊。图2中所示为用salⅰ对不同小麦的pj引物对的pcr扩增产物进行酶切的带型。泳道t含有一条216bp的条带;泳道c含有两条从上至下依次为200bp和16bp的条带,由于电泳时间较长,16bp的小片段条较为模糊。
图3为自然群体中存在的4种单倍型。hap-6d-1、hap-6d-2、hap-6d-3和hap-6d-4分别为单倍型ⅰ、ⅱ、ⅲ和ⅳ。
具体实施方式
下面结合具体实施方式对本发明进行进一步的详细描述,给出的实施例仅为了阐明本发明,而不是为了限制本发明的范围。下述实施例中的实验方法,如无特殊说明,均为常规方法。下述实施例中所用的材料、试剂、仪器等,如无特殊说明,均可从商业途径得到。以下实施例中的定量试验,均设置三次重复实验,结果取平均值。下述实施例中,如无特殊说明,序列表中各核苷酸序列的第1位均为相应dna/rna的5′末端核苷酸,末位均为相应dna/rna的3′末端核苷酸。
下述实施例中的2×utaqpcrmastermix为北京庄盟国际生物基因科技有限公司产品,货号zt201a。
实施例1、与小麦穗长和每穗小穗数相关的snp及其标记多态性检测
1、扩增含小麦snp位点的基因组dna片段的特异引物
发明人从表1中36份普通六倍体小麦品种(来自于国家种质资源库)发现了2个变异位点,选择这2个snp开发为分子标记,这两个snp分别为:对应于序列表序列1自5′末端的第31位的核苷酸(命名为h位点,存在t和g的多态性),对应于序列2自5′末端的第21位的核苷酸(命名为j位点,存在t和c的多态性)。针对h和j位点小麦自然变异群体中存在4种单倍型:
单倍型ⅰ:g/t,即h位点为g、j位点为t的小麦;
单倍型ⅱ:g/c,即h位点为g、j位点为c的小麦;
单倍型ⅲ:t/c,即h位点为t、j位点为c的小麦;
单倍型ⅳ:t/t,即h位点为t、j位点为t的小麦。
序列1和序列2分别为小麦基因组中含有h位点和j位点的dna序列。
表1、36份普通六倍体小麦品种
根据小麦不同基因组的序列差异,设计基因组特异性引物对ph扩增包含h位点在内的dna片段,引物对ph由名称为pe1(正向引物)和pe2(反向引物)的单链dna组成,pe1为序列3(5′-agacgatgtgaagacgaccaaga-3′)所示的单链dna,pe2为序列4(5′-actgtggttcgtgcaaccctag-3′)所示的单链dna;设计基因组特异性引物对pj扩增包含j位点在内的dna片段,引物对pj由名称为pe3(正向引物)和pe4(反向引物)的单链dna组成,pe3为序列5(5′-cccatcatcgccgaggtcga-3′)所示的单链dna,pe4为序列6(5′-cttcttgatcccgacggtcctg-3′)所示的单链dna,其中pe3中引入错配碱基g,错配碱基为序列5的第16位。
2、序列多态性检测及基因分型方法的建立
1)提取待测小麦的基因组dna,用基因组特异引物(nac67dsf和nac67dsr)进行pcr扩增,得到pcr扩增产物;
nac67dsf:5′-gttaaagagaaagggaggaaggga-3′(序列7);
nac67dsr:5′-cgtgagagtattgagagctcagaag-3′(序列8)。
2)以步骤1)的pcr扩增产物稀释100倍为模板,采用步骤1中的引物对ph和pj分别进行pcr扩增,得到pcr扩增产物。
pcr扩增的体系为:模板dna2μl(10pg-1μg)、2×utaqpcrmastermix10μl、正向引物(10μmol/l)和反向引物(10μmol/l)各1.0μl,补ddh2o至20.0μl。
pcr扩增条件如下:
①ph引物对:95℃5min;95℃1min,61℃45s,72℃30s,33次循环;72℃10min,4℃保存。
②pj引物对:95℃5min;95℃1min,64℃45s,72℃30s,33次循环;72℃10min,4℃保存。
3)将步骤2)ph和pj位点的pcr扩增产物分别用haeⅲ和salⅰ酶切,获得酶切产物;酶切产物均进行4%琼脂糖凝胶电泳检测,识别记录酶切产物中各片段大小,并根据如下方法判断并记录待测小麦在h和j位点的情况:
若酶切产物为308bp的dna片段,待测小麦在h位点的核苷酸为t(图1中的泳道t);酶切产物为276bp、32bp的dna片段,则待测小麦在h位点的核苷酸为g(图1中的泳道g);酶切产物为308bp、276bp、32bp的dna片段,则待测小麦在h位点的核苷酸为t和g(图1中的泳道t/g)。
若酶切产物为216bp的dna片段,则待测小麦在j位点的核苷酸为t(图2中的泳道t);若酶切产物为200bp、16bp的dna片段,则待测小麦在j位点的核苷酸为c(图2中的泳道c);若酶切产物为216bp、200bp、16bp的dna片段,则待测小麦在j位点的核苷酸为t和c。
4)根据步骤3)的结果,根据h和j位点的情况将小麦分为如下四种单倍型:
ⅰ:g/t(即单倍型ⅰ);
ⅱ:g/c(即单倍型ⅱ);
ⅲ:t/c(即单倍型ⅲ);
ⅳ:t/t(即单倍型ⅳ)。
上述“/”前为h位点的情况,上述“/”后为j位点的情况。
3、利用该分子标记对自然群体进行分型并与穗长和每穗小穗数性状进行关联分析
以282份普通六倍体小麦(来自于国家种质资源库)组成的自然群体中各小麦分别作为待测小麦按照步骤2的方法进行分型,结果如表2所示。随机对部分小麦的扩增产物大小进行测序验证,结果显示,h位点为g的ph引物对的pcr扩增产物的序列均为序列1,h位点为t的ph引物对的pcr扩增产物的序列均为序列9,h位点为g和t的ph引物对的pcr扩增产物的序列均为序列1和序列9;j位点为t的pj引物对的pcr扩增产物的序列均为序列10,j位点为c的pj引物对的pcr扩增产物的序列均为序列11,j位点为t和c的pj引物对的pcr扩增产物的序列均为序列10和序列11。
表2、小麦自然群体中单倍型情况统计
表2中,“a/b”表示h和j位点中有1个位点为杂合的杂合体;“a/b/c/d”表示h和j位点中2个位点均为杂合的杂合体。
用tassel5.2.51软件中的generallinearmodel(glm)模型对h和j两个位点与小麦种子成熟后穗长、每穗小穗数的产量相关性状的相关性进行分析。单倍型ⅳ在群体所占的比例为2%,小于5%,为稀有变异。
结果(表3)发现,h位点为t的小麦穗长显著(或极显著)高于该位点为g的小麦;j位点为c的小麦每穗小穗数显著(或极显著)高于该位点为t的小麦。对自然群体的研究表明,单倍型ⅲ是具有小麦优异穗长和每穗小穗数性状的优异单倍型,可通过鉴定该单倍型小麦检测小麦的产量相关性状,也可进行分子标记辅助育种培育高产小麦。
表3、小麦自然群体中3种单倍型相关性状统计结果
表3中,每穗小穗数是指每个主穗上小穗数。
序列表
<110>中国农业科学院作物科学研究所
<120>鉴定小麦产量相关性状的分子标记与方法
<160>11
<170>siposequencelisting1.0
<210>1
<211>308
<212>dna
<213>小麦(triticumaestivuml.)
<400>1
agacgatgtgaagacgaccaagaatccggcggccgttgctctcctgtacacatgcatgcg60
cggctggatttcattgtcgtgcatgaatcgtccgtcttgtgtcgtctgtatagcaatgct120
ggtaattcttagtggcaaagctgagcagccgaatacaactaggcacatggtaaatgataa180
aaactcattctaaaggcgtcatctttagtctagaaaaccaagccgggcagccacctacaa240
ctgcagagcacaacgagtgaattgaagaaaacatcgacattgaaggctagggttgcacga300
accacagt308
<210>2
<211>216
<212>dna
<213>小麦(triticumaestivuml.)
<400>2
cccatcatcgccgagctcgacctctaccggttcgacccgtgggagctcccggagcgggcg60
ctcttcggggcgcgggagtggtacttcttcacgccgcgggaccgcaagtaccccaacggc120
tcccgccccaaccgggccgccgggggcggctactggaaggccaccggcgccgacaggccc180
gtggcgcgcgcgggcaggaccgtcgggatcaagaag216
<210>3
<211>23
<212>dna
<213>人工序列()
<400>3
agacgatgtgaagacgaccaaga23
<210>4
<211>22
<212>dna
<213>人工序列()
<400>4
actgtggttcgtgcaaccctag22
<210>5
<211>20
<212>dna
<213>人工序列()
<400>5
cccatcatcgccgaggtcga20
<210>6
<211>22
<212>dna
<213>人工序列()
<400>6
cttcttgatcccgacggtcctg22
<210>7
<211>24
<212>dna
<213>人工序列()
<400>7
gttaaagagaaagggaggaaggga24
<210>8
<211>25
<212>dna
<213>人工序列()
<400>8
cgtgagagtattgagagctcagaag25
<210>9
<211>308
<212>dna
<213>人工序列()
<400>9
agacgatgtgaagacgaccaagaatccggctgccgttgctctcctgtacacatgcatgcg60
cggctggatttcattgtcgtgcatgaatcgtccgtcttgtgtcgtctgtatagcaatgct120
ggtaattcttagtggcaaagctgagcagccgaatacaactaggcacatggtaaatgataa180
aaactcattctaaaggcgtcatctttagtctagaaaaccaagccgggcagccacctacaa240
ctgcagagcacaacgagtgaattgaagaaaacatcgacattgaaggctagggttgcacga300
accacagt308
<210>10
<211>216
<212>dna
<213>人工序列()
<400>10
cccatcatcgccgaggtcgatctctaccggttcgacccgtgggagctcccggagcgggcg60
ctcttcggggcgcgggagtggtacttcttcacgccgcgggaccgcaagtaccccaacggc120
tcccgccccaaccgggccgccgggggcggctactggaaggccaccggcgccgacaggccc180
gtggcgcgcgcgggcaggaccgtcgggatcaagaag216
<210>11
<211>216
<212>dna
<213>人工序列()
<400>11
cccatcatcgccgaggtcgacctctaccggttcgacccgtgggagctcccggagcgggcg60
ctcttcggggcgcgggagtggtacttcttcacgccgcgggaccgcaagtaccccaacggc120
tcccgccccaaccgggccgccgggggcggctactggaaggccaccggcgccgacaggccc180
gtggcgcgcgcgggcaggaccgtcgggatcaagaag216
- 还没有人留言评论。精彩留言会获得点赞!