一种海带碳水化合物磺基转移酶基因及其应用的制作方法
本发明属于分子生物学
技术领域:
,具体的说是一种海带碳水化合物磺基转移酶基因及其应用。
背景技术:
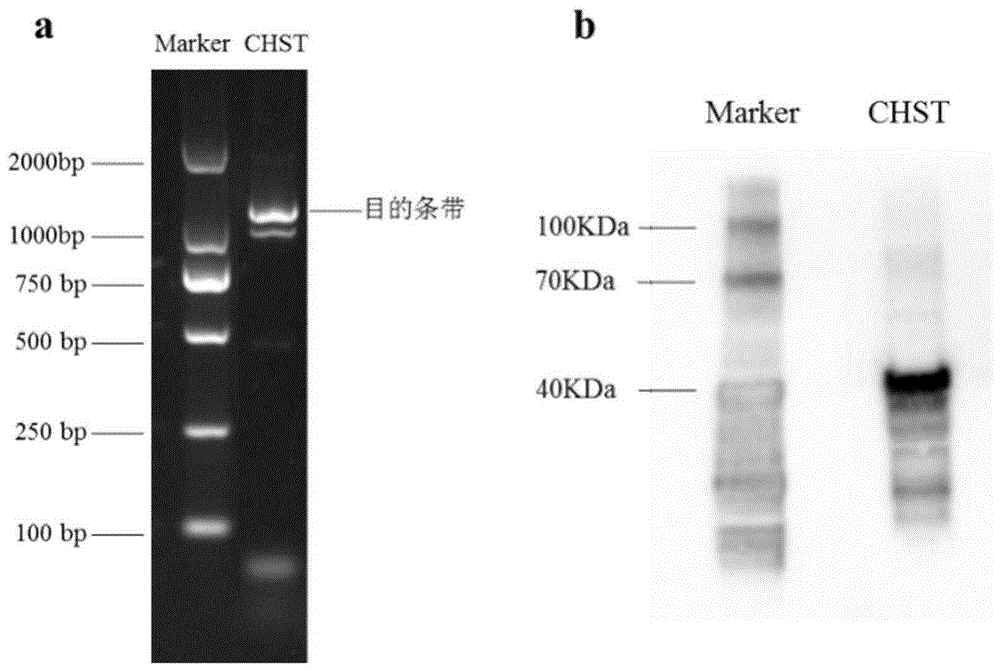
:褐藻多糖硫酸酯又称褐藻糖胶、岩藻聚糖、岩藻聚糖硫酸酯,是目前研究最多的非哺乳动物来源的具有生物活性的硫酸化多糖,主要组分是l-褐藻糖-4-硫酸酯,多存在于褐藻类海藻细胞壁中。褐藻多糖硫酸酯具有抗病毒,抗凝血,治疗糖尿病肾病等多种生物活性,在医药开发领域具有广阔的应用前景。研究表明,褐藻多糖硫酸酯的生物活性与其硫酸基团含量,分子量及磺酰基位置具有紧密的关联,但由于褐藻多糖硫酸酯的硫酸基团含量差别较大,磺酰基取代位置具有不确定性等因素,给其构效关系的研究带来了一定程度的困难,影响了海藻活性物质的开发利用。现阶段褐藻多糖硫酸酯的生物合成途径尚处于理论推测阶段,并未有完整的实验验证过程来说明合成途径中相关基因及功能。而且,尽管在已有的褐藻基因组数据中预测得到数十条磺基转移酶的序列,但是哪些序列能真正催化硫酸基团的转移,还需要进一步的验证分析。技术实现要素:本发明目的在于提供一种海带碳水化合物磺基转移酶基因及其应用。为实现上述目的,本发明采用技术方案为:一种海带碳水化合物磺基转移酶基因,磺基转移酶基因(chst基因)为序列表sediqno.1中的碱基所示。所述基因编码蛋白为序列表sediqno.2中氨基酸所示。一种海带碳水化合物磺基转移酶基因,所述基因编码蛋白为可溶性表达蛋白,可用于褐藻多糖硫酸酯的定点硫酸化修饰,利于褐藻多糖硫酸酯构效,在制备褐藻多糖硫酸酯中的应用;同时还可应用在医药领域。一种海带碳水化合物磺基转移酶基因的重组质粒,所述重组质粒含权利要求1所述的磺基转移酶基因(chst基因)所编码的蛋白。所述质粒在制备褐藻多糖硫酸酯中的应用。本发明的突出优点如下:本发明磺基转移酶基因从海带中克隆获得,并通过体外原核表达技术获得该基因开放阅读框(orf)全长序列,对其编码蛋白质的特征进行在线预测分析;通过低温诱导表达,得到chst蛋白,通过sds-page及westernblot检测目的蛋白的可溶性。本发明所得海带chst蛋白可在原核表达系统中得到可溶性表达;且序列中经检测发现含有磺基转移酶结构域,属于sulfotransfer_3家族成员,可为褐藻多糖硫酸酯的构效关系研究及海藻活性物质的开发与利用提供理论依据。附图说明图1为本发明是实例提供的chst基因克隆电泳图与westernblot结果图;其中,a.chst基因扩增;b.westernblot检测结果。具体实施方式以下结合实例对本发明的具体实施方式做进一步说明,应当指出的是,此处所描述的具体实施方式只是为了说明和解释本发明,并不局限于本发明。本发明基于海带转录组测序结果,从海带中克隆得到一种转录水平较高的碳水化合物磺基转移酶(chst)基因的cdna序列,其开放阅读框(orf)为1134bp,编码含377个氨基酸的蛋白质序列。利用体外原核表达体系,成功获得可溶性重组蛋白表达。实施例1本发明所述海带chst基因的克隆方法,主要包括以下步骤:1.海带幼孢子体总rna提取及cdna合成;2.chst基因特异性引物合成及pcr扩增产物测序;3.chst蛋白质结构预测分析。具体操作如下:1.海带幼孢子体总rna的提取:取适量海带样品(≤100mg),于液氮预冷的研钵内研磨,重复3~5次,取研磨好的粉末进行rna提取。按照qiagen公司的植物rna提取试剂盒(rneasyplantminikit)步骤提取海带总rna。利用roche公司的transcriptorfirststrandcdnasynthesiskit合成试剂盒反转录合成cdna,用于基因扩增。详细操作参见各试剂盒说明书。2.chst基因特异性引物合成及pcr扩增产物测序:在海带转录数据基础上,选取得到海带中1月-5月fpkm平均值大于5的高表达的chst基因,利用primerpremier5软件,设计扩增chst基因orf的特异性引物序列chst-f和chst-r(表1)。扩增体系为:3μlcdna,1μlchst-f,1μlchst-r,10μl诺唯赞2×phantamaxmastermix,5μlddh2o。反应程序为:95℃预变性5min;然后进入5个循环:95℃变性15s,65℃退火15s,72℃延伸1.5min;然后进入30个循环:95℃变性15s,60℃退火15s,72℃延伸1.5min;最后进行72℃延伸10min。pcr产物经dna电泳检测、胶回收、连接与转化后,测序验证。3.chst蛋白质结构分析:对获得的目的chst基因序列,用orffinder工具预测其开放阅读框,并利用翻译工具myhits将核酸序列翻译为氨基酸序列。用protparam在线工具预测蛋白的分子量(mw)和等电点(pi),同时用signalp4.1预测蛋白的信号肽序列,用tmhmmserverv.2.0预测蛋白是否含有跨膜结构。经预测,chst基因orf全长1134bp,编码377个氨基酸序列,编码蛋白分子量mw为40.53kda,理论等电点为5.14,是一种分泌蛋白。表1引物及其核苷酸序列引物名称引物序列(5’-3’)chst-fgcgcatatgatggcggtgggaaggtcgggchst-rccggaattcctacggttcataacctagagcatccsediqno.1海带碳水化合物磺基转移酶(chst)基因碱基序列atggcggtgggaaggtcgggctcgacattggtcggacagcttttccaacaaaacaaggatgttctctacttttacgaaccgtgcaggaagctgagcggaacggatattgatggcttggagtgcctggcctttctgcaaaggctgacccagtgcaccttcagtgccgaagattccgcatggatcgcagacgatgccaattcggtcaagaatggatcgccggcgctcaaatcactgctggctgcttctggcagaaaagagttcgctgaggcacacgaacgtctcgtggacacgtgcatcaacagcaaggctgtcgtggtgaaatctattcggctgggcgtgggcctgggcggcagggattacgacctcggggggctgaaggtgttgcatcttgtgcgcgaccccagaggagtagtgagatctcagcgggagcatttcgggatatcgtggggggcttcaaatgatgcggacagcgcgacgattgcgcacgctggcggggccagtatttgtggtagttacaggaaccagctggattcttcgaagaagttgggcgatgacaggtaccttcgggttcggtacgaagacattgctacctctcccgagctagccgtggcgttcatctactactggtgcggtctcggcaccgtccccgccagcgtctcggaatgggttgaggtcaacacgaacatgccgacttgcgacggcggtgccgttcgaacgaggcacttgcgcgcggacgccgaggacacgcccttcggctacgtgtacgcagcggtaccagagcaacctttgtccggaagaggtgatgccgtcgtggaagctttcgtgcgagaggaccagagagcgctgcgcgccccgcaggcagggacgagcgaggcagctgcagcggtggtgccgaagacacaaatactcagtggcggcggcagcggcagcagcagcaacaaccaaagcggacaggaactcgaagagtgcgctgcgaacacaaacgaggccaggcataacccgtacgggacgaaaaggcagtccgcggctatggcttcgatgtggcgaactctcatgtctgggcaggacgcgcaggccgtttgggaggcgtgcgaggaatcgggggtaatggatgctctaggttatgaaccgtag(a)序列特征:·长度:1134·类型:碱基序列·链型:单链·拓扑结构:线性(b)分子类型:dna(c)假设:否(d)反义:否(e)最初来源:海带sediqno.2海带碳水化合物磺基转移酶(chst)基因编码蛋白氨碱基序列mavgrsgstlvgqlfqqnkdvlyfyepcrklsgtdidgleclaflqrltqctfsaedsawiaddansvkngspalksllaasgrkefaeaherlvdtcinskavvvksirlgvglggrdydlgglkvlhlvrdprgvvrsqrehfgiswgasndadsatiahaggasicgsyrnqldsskklgddrylrvryediatspelavafiyywcglgtvpasvsewvevntnmptcdggavrtrhlradaedtpfgyvyaavpeqplsgrgdavveafvredqralrapqagtseaaaavvpktqilsgggsgsssnnqsgqeleecaantnearhnpygtkrqsaamasmwrtlmsgqdaqavweaceesgvmdalgyep(a)序列特征:·长度:377·类型:氨基酸序列·链型:单链·拓扑结构:线性(b)分子类型:蛋白质(c)假设:否(d)反义:否(e)最初来源:海带结构特点:12bp—213bp处为sulfotransfer_3结构域,122bp—232bp处为sulfotransfer_1结构域。实施实例2本发明所述海带chst重组蛋白表达及纯化方法,主要包括以下步骤:1.chst重组质粒构建与转化;2.chst重组蛋白表达;3.chst重组蛋白可溶性检测具体操作如下:1.chst重组质粒构建与转化:为了实现目的蛋白的可溶性表达,选择冷休克蛋白表达载体pcoldⅱ进行目的蛋白的表达,利用该载体表达的蛋白n端带有his标签,可用于后续的融合蛋白纯化。根据目的基因序列信息,选择ndei和ecori作为双酶切位点,设计带酶切位点和保护碱基的扩增引物,即chst-f和chst-r(表1),对基因的表达扩增序列不包含信号肽序列。pcr扩增条件同orf条件一致,扩增得到目的条带,电泳图如图1a。表达载体的构建按照iionestepcloningkit说明书进行,重组质粒转化trans1-t1感受态细胞。对经过测序为阳性的菌株扩大培养,提取质粒,转化pg-tf2/bl21感受态细胞,测序验证。2.chst重组蛋白表达:取阳性菌液适量,于37℃条件下过夜摇菌;分至4llb培养基(含氨苄青霉素)中,od600约为0.6时,将培养瓶于15℃冰浴中预冷30min,加入0.1mmiptg,于15℃条件下,120rpm,摇菌24h。3.重组蛋白可溶性检测:将菌液于8000rpm,4℃条件下离心15min,收集菌体沉淀,重悬于磷酸钠缓冲液(20mm磷酸钠,ph7.4,500mmnacl,30mm咪唑)中,在冰浴条件下超声破碎,破碎5s,间隔10s,将菌液破碎至澄清;破碎液于4℃,13000rpm,离心40min,离心所得上清液用0.45μm滤膜过滤。将16μl蛋白上清液与4μl蛋白上样缓冲液在离心管中混合,pcr仪控温95℃变性10min,sds-page于120v电压下反应55min。根据antihis-tagmousemonoclonalantibody和goatanti-mouseigg,hrpconjugated说明书分别以1:500和1:2000(v/v)的比例稀释一抗和二抗。用iblot转印仪和ibind蛋白印迹处理仪完成蛋白转膜和孵育。显色后用bio-rad凝胶成像系统观察膜片,在预测位置出现明显的条带,说明得到的重组蛋白为可溶性蛋白。结果如图1b所示。由上述可见本发明所得海带chst蛋白可在原核表达系统中得到可溶性表达;且序列中经检测发现含有磺基转移酶结构域,属于sulfotransfer_3家族成员,可为褐藻多糖硫酸酯的构效关系研究及海藻活性物质的开发与利用提供理论依据。序列表<110>中国科学院海洋研究所<120>一种海带碳水化合物磺基转移酶基因及其应用<160>2<170>siposequencelisting1.0<210>1<211>1134<212>dna<213>人工序列(artificialsequence)<400>1atggcggtgggaaggtcgggctcgacattggtcggacagcttttccaacaaaacaaggat60gttctctacttttacgaaccgtgcaggaagctgagcggaacggatattgatggcttggag120tgcctggcctttctgcaaaggctgacccagtgcaccttcagtgccgaagattccgcatgg180atcgcagacgatgccaattcggtcaagaatggatcgccggcgctcaaatcactgctggct240gcttctggcagaaaagagttcgctgaggcacacgaacgtctcgtggacacgtgcatcaac300agcaaggctgtcgtggtgaaatctattcggctgggcgtgggcctgggcggcagggattac360gacctcggggggctgaaggtgttgcatcttgtgcgcgaccccagaggagtagtgagatct420cagcgggagcatttcgggatatcgtggggggcttcaaatgatgcggacagcgcgacgatt480gcgcacgctggcggggccagtatttgtggtagttacaggaaccagctggattcttcgaag540aagttgggcgatgacaggtaccttcgggttcggtacgaagacattgctacctctcccgag600ctagccgtggcgttcatctactactggtgcggtctcggcaccgtccccgccagcgtctcg660gaatgggttgaggtcaacacgaacatgccgacttgcgacggcggtgccgttcgaacgagg720cacttgcgcgcggacgccgaggacacgcccttcggctacgtgtacgcagcggtaccagag780caacctttgtccggaagaggtgatgccgtcgtggaagctttcgtgcgagaggaccagaga840gcgctgcgcgccccgcaggcagggacgagcgaggcagctgcagcggtggtgccgaagaca900caaatactcagtggcggcggcagcggcagcagcagcaacaaccaaagcggacaggaactc960gaagagtgcgctgcgaacacaaacgaggccaggcataacccgtacgggacgaaaaggcag1020tccgcggctatggcttcgatgtggcgaactctcatgtctgggcaggacgcgcaggccgtt1080tgggaggcgtgcgaggaatcgggggtaatggatgctctaggttatgaaccgtag1134<210>2<211>377<212>prt<213>人工序列(artificialsequence)<400>2metalavalglyargserglyserthrleuvalglyglnleuphegln151015glnasnlysaspvalleutyrphetyrgluprocysarglysleuser202530glythraspileaspglyleuglucysleualapheleuglnargleu354045thrglncysthrpheseralagluaspseralatrpilealaaspasp505560alaasnservallysasnglyserproalaleulysserleuleuala65707580alaserglyarglysgluphealaglualahisgluargleuvalasp859095thrcysileasnserlysalavalvalvallysserileargleugly100105110valglyleuglyglyargasptyraspleuglyglyleulysvalleu115120125hisleuvalargaspproargglyvalvalargserglnarggluhis130135140pheglyilesertrpglyalaserasnaspalaaspseralathrile145150155160alahisalaglyglyalaserilecysglysertyrargasnglnleu165170175aspserserlyslysleuglyaspaspargtyrleuargvalargtyr180185190gluaspilealathrserprogluleualavalalapheiletyrtyr195200205trpcysglyleuglythrvalproalaservalserglutrpvalglu210215220valasnthrasnmetprothrcysaspglyglyalavalargthrarg225230235240hisleuargalaaspalagluaspthrpropheglytyrvaltyrala245250255alavalprogluglnproleuserglyargglyaspalavalvalglu260265270alaphevalarggluaspglnargalaleuargalaproglnalagly275280285thrserglualaalaalaalavalvalprolysthrglnileleuser290295300glyglyglyserglyserserserasnasnglnserglyglngluleu305310315320gluglucysalaalaasnthrasnglualaarghisasnprotyrgly325330335thrlysargglnseralaalametalasermettrpargthrleumet340345350serglyglnaspalaglnalavaltrpglualacysgluglusergly355360365valmetaspalaleuglytyrglupro370375当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1