一种与胃腺癌发生发展相关的生物标志物的制作方法
本发明属于生物医药领域,涉及一种与胃腺癌发生发展相关的生物标志物。
背景技术:
胃癌(gastriccancer,gc)是消化系统中常见的一种恶性肿瘤,有着很高的发病率和病死率,全球每年新发胃癌病例约100万例,严重威胁人体健康和生命质量。虽然现在我们在胃癌的临床治疗及基础研究方面取得了一些进步,但是多种因素参与胃癌的发生发展,其发病机制十分复杂,有许多问题仍有待阐明。找到有效调控胃癌发生发展的重要分子可以指导研发临床胃癌分子诊断及分子靶向药物,还需要深入研究探讨。
人类基因组测序结果分析表明,全基因组中70%-90%基因进行转录,但只有不到2%基因最终翻译为蛋白,剩下的绝大部分转录本被命名为非编码rna(non-codingrna,ncrna)(tayy,rinnj,pandolfipp.themultilayeredcomplexityofcernacrosstalkandcompetition.nature.2014;505(7483):344-52.)。其中含有小于200个核苷酸的微小rna(microrna,mirna)和大于200个核苷酸的长链非编码rna(longnon-codingrna,1ncrna)。目前,关于mirna功能研究已有大量结果,1ncrna也成为现今的研究热点。
1ncrna,多数由rna聚合酶ii(rnapolymeraseii,rnapii)转录生成,不能编码蛋白,但是生物学功能非常复杂,可以调节转录、翻译、表观遗传修饰等多个层面。目前发现1ncrna参与多种疾病的发生发展,其对肿瘤的调控作用是当今研究的热点。研究发现1ncrna可调控包括肺癌、胃癌、肝癌、乳腺癌、前列腺癌在内的多种肿瘤。虽然近年来涌现出许多关于1ncrna的研究以及相关数据库,但是大部分的1ncrna的功能机制仍然不被人类所了解。1ncrna是一个非常有前景的研究方向。研究胃癌与lncrna的关系,对于实现胃癌的精准化诊断以及个性化治疗具有重要的意义。
技术实现要素:
为了弥补现有技术的不足,本发明的目的之一,提供一种检测长链非编码rnarp11-320g24.1的产品,为实现胃癌的早期诊断提供基础。
本发明的目的之二,提供一种胃癌的诊断方法,通过检测lncrnarp11-320g24.1的表达水平来诊断患者是否患有胃癌。
为了实现上述目的,本发明采用如下技术方案:
本发明提供了检测长链非编码rnarp11-320g24.1的试剂在制备诊断胃癌的产品中的应用。
其中,rp11-320g24.1包括rp11-320g24.1基因及其同源物,突变,和同等型。该术语涵盖全长,未加工的rp11-320g24.1,以及源自细胞中加工的任何形式的rp11-320g24.1。该术语涵盖rp11-320g24.1的天然发生变体(例如剪接变体或等位变体)。该术语涵盖例如rp11-320g24.1基因,rp11-320g24.1的基因序列以及来自任何其它脊椎动物来源。目前公开的rp11-320g24.1存在两个转录本:enst00000452690.1和enst00000447570.1。在本发明的具体实施方式中,一种代表性的rp11-320g24.1序列如enst00000452690.1所示。
熟悉本领域的技术人员可以了解,对测序结果进行生物信息学分析时,通常会将测序结果和已知的基因组进行比对,只要测序片段可以比对到相关的基因上,就可以看做是该基因的表达,因此,rp11-320g24.1的不同的转录产物同样包含在本发明中。
进一步,rp11-320g24.1在胃癌患者中表达上调。
进一步,所述产品包括:通过测序技术、核酸杂交技术、核酸扩增技术或免疫测定的方法检测rp11-320g24.1基因的表达水平。
进一步,所述核酸扩增技术选自聚合酶链式反应(pcr)、逆转录聚合酶链式反应(rt-pcr)、转录介导的扩增(tma)、连接酶链式反应(lcr)、链置换扩增(sda)和基于核酸序列的扩增(nasba)。
通常,pcr使用变性、引物对与相反链的退火以及引物延伸的多个循环,以指数方式增加靶核酸序列的拷贝数;rt-pcr则将逆转录酶(rt)用于从mrna制备互补的dna(cdna),然后将cdna通过pcr扩增以产生dna的多个拷贝;tma在基本上恒定的温度、离子强度和ph的条件下自身催化地合成靶核酸序列的多个拷贝,其中靶序列的多个rna拷贝自身催化地生成另外的拷贝,tma任选地包括使用阻断,部分、终止部分和其他修饰部分,以改善tma过程的灵敏度和准确度;lcr使用与靶核酸的相邻区域杂交的两组互补dna寡核苷酸。dna寡核苷酸在热变性、杂交和连接的重复多个循环中通过dna连接酶共价连接,以产生可检测的双链连接寡核苷酸产物;sda使用以下步骤的多个循环:引物序列对与靶序列的相反链进行退火,在存在dntpαs下进行引物延伸以产生双链半硫代磷酸化的(hemiphosphorothioated)引物延伸产物,半修饰的限制性内切酶识别位点进行的核酸内切酶介导的切刻,以及从切口3'端进行的聚合酶介导引的物延伸以置换现有链并产生供下一轮引物退火、切刻和链置换的链,从而引起产物的几何扩增。
本发明提供了一种体外检测样本中lncrnarp11-320g24.1表达水平的产品,所述产品包括芯片、试剂盒或核酸膜条。所述“样本”包括细胞、组织或体液。可用于本发明的体液包括血液、淋巴液、尿液、唾液或任何其它身体分泌液或其衍生物。血液可以包括全血、血浆、血清或任何血液衍生物。优选的,所述样本为组织、血液。在本发明的具体实施方式中,所选样本为组织。
进一步,所述芯片、试剂盒或核酸膜条包括针对rp11-320g24.1的特异性引物对或探针。
进一步,所述特异性引物对用于sybrgreen、taqman探针、分子信标、双杂交探针、复合探针的检测。
进一步,所述特异性引物对的序列如seqidno.1和seqidno.2所示。
本发明提供了一种上面所述的产品在制备诊断胃癌的工具中的应用。
本发明提供了rp11-320g24.1在构建预测胃癌的计算模型中的应用。
正如熟练技术人员可以领会的,可以使用两种或更多种标志物的测量来改进调查中的诊断问题。生化标志物可以个别测定,或者在本发明的一个实施方案中,它们可以同时测定,例如使用芯片或基于珠的阵列技术。然后独立解读生物标志物的浓度,例如使用每种标志物的个别截留,或者它们组合进行解读。
在本发明中,可以以不同方式实施和实现将标志物水平与某种可能性或风险关联起来的步骤。优选地,在数学上组合基因和一种或多种其它标志物的测定浓度,并将组合值与根本的诊断问题关联起来。可以通过任何适宜的现有技术数学方法将标志物值的测定组合。
优选地,在标志物组合中应用的数学算法是一种对数函数。优选地,应用此类数学算法或此类对数函数的结果是单一值。根据根本的诊断问题,能容易地将此类值与例如个体关于胃癌的风险或与有助于评估胃癌松患者的其它有意诊断用途关联起来。以一种优选的方式,此类对数函数是如下获得的:a)将个体分类入组,例如正常人、有胃癌风险的个体、具有胃癌的患者等等,b)通过单变量分析来鉴定在这些组之间差异显著的标志物,c)对数回归分析以评估标志物的可用于评估这些不同组的独立差别值,并d)构建对数函数来组合独立差别值。在这种类型的分析中,标志物不再是独立的,而是代表一个标志物组合。
用于将标志物组合与疾病关联起来的对数函数优选采用通过应用统计方法开发和获得的算法。例如,适宜的统计方法是判别分析(da)(即线性、二次、规则da)、kernel方法(即svm)、非参数方法(即k-最近邻居分类器)、pls(部分最小二乘)、基于树的方法(即逻辑回归、cart、随机森林方法、助推/装袋方法)、广义线性模型(即对数回归)、基于主分量的方法(即simca)、广义叠加模型、基于模糊逻辑的方法、基于神经网络和遗传算法的方法。熟练技术人员在选择适宜的统计方法来评估本发明的标志物组合并由此获得适宜的数学算法方面不会有问题。在一个实施方案中,用于获得评估胃癌中使用的数学算法的统计方法选自da(即线性、二次、规则判别分析)、kernel方法(即svm)、非参数方法(即k-最近邻居分类器)、pls(部分最小二乘)、基于树的方法(即逻辑回归、cart、随机森林方法、助推方法)、或广义线性模型(即对数回归)。
本发明提供了rp11-320g24.1在制备治疗胃癌的药物组合物中的应用。
进一步,所述药物包括下调rp11-320g24.1表达的试剂,和/或药学上可接受的载体。
本文所用术语“差异表达”表示与第二种样品中相同的一种或多种本发明生物标志物的表达水平比较,经测定rna的量或水平,在一个样品中本发明的一种或多种生物标志物的rna和/或所述生物标志物rna的一种或多种剪接变体表达水平的差异。“差异表达的”还可以包括与第二种样品或样品群中蛋白质表达量或水平比较,对样品或样品群中本发明生物标志物编码的蛋白质的测定。差异表达可以如本文所述和本领域技术人员理解的方法确定。术语“差异表达”或“表达水平的变化”表示与第二种样品中给定生物标志物的可测定表达水平比较,经测定rna的量和/或蛋白质的量,样品中给定生物标志物可测定表达水平的增加或降低。术语“差异表达”或“表达水平的变化”还可以表示与第二个样品群中生物标志物的可测定表达水平比较,样品群中给定生物标志物可测定表达水平的增加或降低。本文所用“差异表达”可以用给定生物标志物的表达水平相对于对照中给定生物标志物的平均表达水平的比率进行测定,其中比率不等于1.0。还可以用p值测定差异表达。当使用p值时,当p值小于0.1时生物标志物被鉴定为在第一和第二群体之间差异表达。更优选p值小于0.05。甚至更优选p值小于0.01。还更优选p值小于0.005。最优选p值小于0.001。当基于比率确定差异表达时,如果第一种和第二种样品中表达水平的比率大于或小于1.0,则rna或蛋白质是差异表达的。举例来说,大于1.2、1.5、1.7、2、3、4、10、20的比率,或小于1的比率,例如0.8、0.6、0.4、0.2、0.1、0.05。在本发明的另一个实施方案中,如果第一群体的平均表达水平与第二群体的平均表达水平的比率大于或小于1.0,则核酸转录本是差异表达的。举例来说,大于1.2、1.5、1.7、2、3、4、10、20的比率,或小于1的比率,例如0.8、0.6、0.4、0.2、0.1、0.05。在本发明的另一个实施方案中,如果第一个样品中表达水平与第二个群体中平均表达水平的比率大于或小于1.0,例如包括比率大于1.2、1.5、1.7、2、3、4、10、20,或比率小于1,例如0.8、0.6、0.4、0.2、0.1、0.05,则核酸转录本是差异表达的。
“表达差异增加”或“上调”表示基因相对于对照而言,基因表达(以rna表达或蛋白质表达测定)显示增加至少10%或更多,例如20%、30%、40%或50%、60%、70%、80%、90%或更多或1.1倍、1.2倍、1.4倍、1.6倍、1.8倍或更多。在本发明的具体实施方式中,基因表达指的是rna表达。
“表达差异降低”或“下调”表示基因相对于对照而言,基因表达(以rna表达或蛋白质表达测定)显示降低至少10%或更多,例如20%、30%、40%或50%、60%、70%、80%、90%或少于1.0倍、0.8倍、0.6倍、0.4倍、0.2倍、0.1倍或更少的基因。在本发明的具体实施方式中,基因表达指的是rna表达。
在本发明中,“探针”指能与另一分子的特定序列或亚序列或其它部分结合的分子。除非另有指出,术语“探针”通常指能通过互补碱基配对与另一多核苷酸(往往称为“靶多核苷酸”)结合的多核苷酸探针。根据杂交条件的严谨性,探针能和与该探针缺乏完全序列互补性的靶多核苷酸结合。探针可作直接或间接的标记,其范围包括引物。杂交方式,包括,但不限于:溶液相、固相、混合相或原位杂交测定法。
所述探针具有与靶点基因的特定的碱基序列互补的碱基序列。这里,所谓“互补”,只要是杂交即可,可以不是完全互补。这些多核苷酸通常相对于该特定的碱基序列具有80%以上、优选90%以上、更优选95%以上、特别优选100%的同源性。这些探针可以是dna,也可以是rna,另外,可以为在其一部分或全部中核苷酸通过pna(polyamidenucleicacid,肽核酸)、lna(注册商标,lockednucleicacid,bridgednucleicacid,交联化核酸)、ena(注册商标,2′-o,4′-c-ethylene-bridgednucleicacids)、gna(glycerolnucleicacid,甘油核酸)、tna(threosenucleicacid,苏糖核酸)等人工核酸置换得到的多核苷酸。
术语“同源性”是指互补性的程度。可以存在部分同源性或完全同源性(即,同一性)。部分互补的序列是至少部分地抑制完全互补的核酸分子与“基本上同源的”靶核酸杂交的核酸分子。完全互补序列与靶序列的杂交的抑制可通过在低严格性条件下使用杂交测定(southern或northern印迹、液相杂交等)进行检查。基本上同源的序列或探针将竞争并抑制完全同源的核酸分子在低严格性条件下与靶标的结合(即,杂交)。这并非是说,低严格性条件是使得允许非特异性结合的条件;低严格性条件要求两个序列彼此之间的结合为特异性(即,选择性)的相互作用。非特异性结合的不存在可通过使用基本上非互补(例如,低于约30%同一性)的第二靶标进行测试;在不存在非特异性结合的情况下,探针将不与第二非互补靶标杂交。
本发明中的术语“杂交”用于指代互补核酸的配对。杂交和杂交强度(即,核酸之间的缔合强度)受诸如以下的因素影响:核酸之间的互补程度、所涉及的条件的严格性、形成的杂交体的tm和核酸内的g:c比率。在其结构内含有互补核酸的配对的单个分子称为“自我杂交的”。
本发明中基因检测试剂盒或基因芯片可用于检测包括rp11-320g24.1基因在内的多个基因(例如,与胃癌相关的多个基因)的表达水平,将胃癌的多个标志物同时进行检测,可大大提高胃癌诊断的准确率。
本领域技术人员将认识到,本发明的实用性并不局限于对本发明的标志物基因的任何特定变体的基因表达进行定量。
本发明中的核酸杂交技术包括但不限于原位杂交(ish)、微阵列和southern或northern印迹。原位杂交(ish)是一种使用标记的互补dna或rna链作为探针以定位组织一部分或切片(原位)或者如果组织足够小则为整个组织(全组织包埋ish)中的特异性dna或rna序列的杂交。dnaish可用于确定染色体的结构。rnaish用于测量和定位组织切片或全组织包埋内的mrna和其他转录本(例如,ncrna)。通常对样本细胞和组织进行处理以原位固定靶转录本,并增加探针的进入。探针在高温下与靶序列杂交,然后将多余的探针洗掉。分别使用放射自显影、荧光显微术或免疫组织化学,对组织中用放射、荧光或抗原标记的碱基标记的探针进行定位和定量。ish也可使用两种或更多种通过放射性或其他非放射性标记物标记的探针,以同时检测两种或更多种转录本。
术语“微阵列”,包括但不限于:dna微阵列(例如,cdna微阵列和寡核苷酸微阵列)、蛋白质微阵列、组织微阵列、转染或细胞微阵列、化学化合物微阵列和抗体微阵列。通常称为基因芯片、dna芯片或生物芯片的dna微阵列是微观dna点的集合,这些点连接到固体表面(例如,玻璃、塑料或硅芯片)上,形成用于对数千种基因同时进行表达谱分析或表达水平监测的阵列。固定的dna片段称为探针,其数千个可用于单个dna微阵列中。微阵列可用于通过比较疾病和正常细胞中的基因表达而识别疾病基因或转录本(例如,ncrna)。微阵列可使用多种技术加以制造,包括但不限于:用细尖针印刷到载玻片上、使用预制的掩模进行光刻、使用动态微镜器件进行光刻、喷墨印刷或微电极阵列上的电化学方法。
将southern和northern印迹分别用于检测特异性dna或rna序列。使从样本中提取的dna或rna断裂,在基质凝胶上通过电泳分离,然后转移到膜滤器上。使滤器结合的dna或rna与和所关注的序列互补的标记探针杂交。检测结合到滤器的杂交探针。该程序的一种变化形式是反向northern印迹,其中固定到膜的底物核酸为分离的dna片段的集合,而探针是从组织提取并进行了标记的rna。
本发明中的术语“诊断”是指通过疾病的体征和症状或遗传分析、病理分析、组织学分析等识别疾病。
本发明的优点和有益效果:
本发明发现了一种诊断胃癌的分子标志物,通过检测标志物rp11-320g24.1的表达水平即可对早期胃癌进行判断,从而进行早期干预,提高患者的生存率。
本发明提供了一种与胃癌的发生发展密切相关的基因,为胃癌的科学研究提供了理论依据。
附图说明
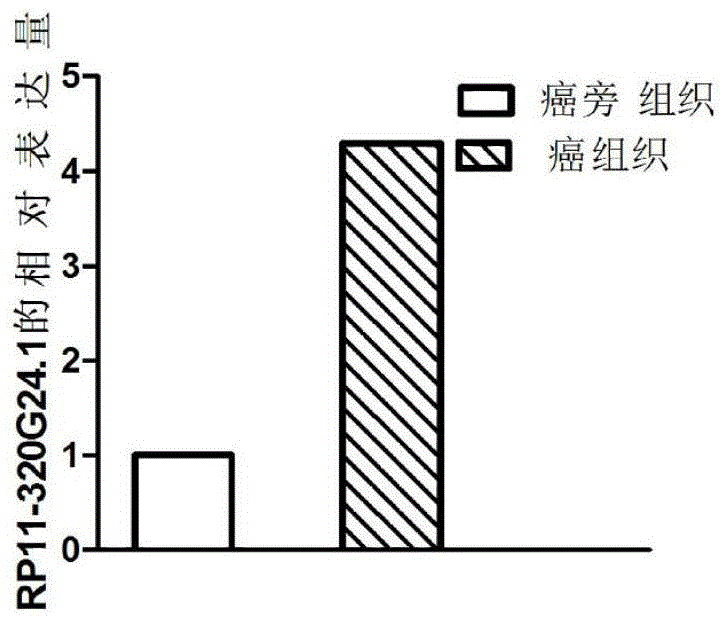
图1是利用qpcr检测rp11-320g24.1基因在胃癌组织中的表达情况图。
具体的实施方式
下面结合附图和实施例对本发明作进一步详细的说明。以下实施例仅用于说明本发明而不用于限制本发明的范围。实施例中未注明具体条件的实验方法,通常按照常规条件,或按照制造厂商所建议的条件。
实施例1筛选与胃癌相关的基因标志物
1、样品收集
收集4例胃腺癌的癌组织及相对应的癌旁组织样本,进行高通量测序,所有患者术前未进行化疗、放疗以及内分泌治疗。
2、rna样品的制备及质量分析
使用天根的动物组织总rna提取试剂盒(目录号为dp431)进行总rna的提取,步骤详见说明书。
1)匀浆处理
每10-20mg组织加300μl裂解液rl,用研磨杵将组织彻底研磨;随后向匀浆液中加入590μlrnase-freeddh2o和10μlproteinasek,混匀后56℃处理10-20min。
2)12,000rpm离心2-5min,取上清进行以下操作。
3)缓慢加入0.5倍上清体积无水乙醇,混匀,得到的溶液和沉淀一起转入吸附柱cr3中(吸附柱放在收集管中),12,000rpm离心30s,弃掉收集管中的废液,将吸附柱放回收集管中。
4)向吸附柱cr3中加入350μl去蛋白液rw1,12,000rpm离心30s,弃废液,将吸附柱放回收集管中。
5)向吸附柱cr3中央加入80μl的dnasei工作液,室温放置15min。
6)向吸附柱cr3中加入350μl去蛋白液rw1,12,000rpm离心30s,弃废液,将吸附柱放回收集管中。
7)向吸附柱cr3中加入500μl漂洗液rw,室温静置2min,12,000rpm离心30s,弃废液,将吸附柱cr3放回收集管中。
8)重复步骤7)。
9)12,000rpm离心2min,倒掉废液。将吸附柱cr3置于室温放置数分钟,以彻底晾干吸附材料中残余的漂洗液。
10)将吸附柱cr3转入一个新的rnase-free离心管中,向吸附膜的中间部位悬空滴加30-100μlrnase-freeddh2o,室温放置2min,12,000rpm离心2min,得到rna溶液。
11)rna的质量检测
用琼脂糖凝胶电泳检测rna的完整性(电泳条件:胶浓度1.2%;0.5×tbe电泳缓冲液;150v,15min)检测完整性。28srrna是18srrna的两倍时,说明rna的完整性较好。
用分光光度计检测rna的浓度及纯度,od260/od280读数在1.8-2.1之间,rna的质量较高。
3、cdna文库的构建及测序
cdna文库的构建及测序由华大基因完成,步骤如下:
1)总rnadnasei消化:利用dnasei消化totalrna样品中存在的dna片段,磁珠纯化回收反应产物,最后溶解于depc水;
2)去除rrna:取消化好的totalrna样品,使用epicentre的ribo-zero试剂盒去除rrna,去除之后进行agilent2100检测,验证rrna去除效果;
3)rna打断:取上一步样品,加入打断buffer,置于pcr仪中进行热打断,打断到140-160nt;
4)反转录一链的合成:向打断后的样品中加入适量引物,充分混匀后在thermomixer适温反应一定时间,使之打开二级结构并与引物结合,再加入提前配制的一链合成反应体系mix,在pcr仪上按相应程序合成一链cdna;
5)反转录二链的合成:配制二链合成反应体系,在thermomixer上适温反应一定时间,合成带有dutp的二链cdna,反应产物用磁珠进行纯化回收;
6)末端修复:配制末端修复反应体系,在thermomixer中适温反应一定时间,在酶的作用下,对反转录得到的cdna双链的粘性末端进行修复,末端修复产物用磁珠进行纯化回收,最后将样品溶于ebsolution;
7)cdna3’末端加“a”:配制加“a”反应体系,在thermomixer中适温反应一定时间,在酶的作用下,使末端修复的产物cdna的3’末端加上a碱基;
8)cdna5’adapter的连接:配制接头连接反应体系,在thermomixer中适温反应一定时间,在酶的作用下,使接头与a碱基连接,产物用磁珠进行纯化回收;
9)ung消化cdna二链:配制ung消化反应体系,通过ung酶消化掉双链dna中的二链,并用磁珠对产物进行纯化回收;
10)pcr反应及产物回收:配制pcr反应体系,选择适当的pcr反应程序,对上步骤得到的产物进行扩增,对pcr产物进行磁珠纯化回收,回收产物溶于eb溶液中,贴上标签。
11)文库质量检测:使用agilent2100bioanalyzer和abisteponeplusreal-timepcrsystem对文库质量进行检测;
12)上机测序:检测合格的文库,加入naoh变性成单链,按照预期上机数据量,稀释至一定的上机浓度。变性稀释后的文库加入到flowcell内,与flowcell上的接头杂交,在cbot上完成桥式pcr扩增,最后使用illuminahiseqx-ten平台进行测序。
4、生物信息学分析
1)用cutadapt对reads的5’和3’段进行trim,trim掉质量<20的碱基,并且删掉n大于10%的reads;
2)tophat比对到参考基因组上,参考基因组版本为grch37.p13;
3)cuffquant定量lncrna的表达量并标准化输出;
4)cuffdiff包比较对照组跟疾病组lncrna的表达差异。
5、结果
测序结果显示,rp11-320g24.1在胃腺癌患者中表达显著上调,提示rp11-320g24.1可能作为检测靶标应用于胃腺癌的早期诊断。
实施例2qpcr测序验证rp11-320g24.1基因的差异表达
1、按照实施例1的收集方式收集的31例胃腺癌患者癌组织样本和癌旁组织样本对rp11-320g24.1基因差异表达进行大样本qpcr验证。
2、rna提取
使用天根的动物组织总rna提取试剂盒(目录号为dp431)进行总rna的提取,具体步骤参见实施例1。
3、qpcr
根据rp11-320g24.1和gadph的基因序列设计引物,引物序列如下:
rp11-320g24.1:
正向引物:5′-gtataatctgccacttct-3′(seqidno.1)
反向引物:5′-gtcttccacatcattcta-3′(seqidno.2)
gapdh:
正向引物:5′-aatcccatcaccatcttccag-3′(seqidno.3)
反向引物:5′-gagccccagccttctccat-3′(seqidno.4)
使用天根公司的quant一步法反转录-荧光定量试剂盒(sybrgreen)试剂盒(目录号:ng105)进行pcr反应,反应体系和反应条件如表1所示。在thermalcycler
表1qpcr反应体系和反应条件
4、结果
qpcr结果如图1所示,与对照相比,rp11-320g24.1在胃腺癌组织中表达上调,差异具有统计学意义(p<0.05),同高通量测序结果一致,提示可通过检测rp11-320g24.1的水平判断受试者是否患有胃腺癌,当rp11-320g24.1的水平显著增加时,受试者患有胃腺癌或者存在患有胃腺癌的风险,通过rp11-320g24.1与胃腺癌之间的关系可以设计降低rp11-320g24.1水平的干扰rna从而治疗胃腺癌,同时可以基于rp11-320g24.1与胃腺癌的关系,构建预测胃腺癌的计算模型。
上述实施例的说明只是用于理解本发明的方法及其核心思想。应当指出,对于本领域的普通技术人员来说,在不脱离本发明原理的前提下,还可以对本发明进行若干改进和修饰,这些改进和修饰也将落入本发明权利要求的保护范围内。
序列表
<110>徐州医科大学
<120>一种与胃腺癌发生发展相关的生物标志物
<160>4
<170>siposequencelisting1.0
<210>1
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>1
gtataatctgccacttct18
<210>2
<211>18
<212>dna
<213>人工序列(artificialsequence)
<400>2
gtcttccacatcattcta18
<210>3
<211>21
<212>dna
<213>人工序列(artificialsequence)
<400>3
aatcccatcaccatcttccag21
<210>4
<211>19
<212>dna
<213>人工序列(artificialsequence)
<400>4
gagccccagccttctccat19
- 还没有人留言评论。精彩留言会获得点赞!