扩增经亚硫酸氢盐处理的DNA的方法
扩增经亚硫酸氢盐处理的dna的方法
1.相关申请的交叉引用
2.本申请要求2018年7月27日递交的美国临时专利申请第62/711184号的优先权权益,其内容通过引用整体并入本文。
3.政府支持声明
4.本发明是在由美国国立卫生研究院授予的批准号hg006827下利用政府支持完成的。政府拥有本发明的一定权利。
5.发明背景
i.技术领域
6.本发明的实施方案一般涉及细胞生物学。在某些方面,方法包括确定核酸分子中是否存在5
‑
甲基胞嘧啶和/或5
‑
羟甲基胞嘧啶。
ii.
背景技术:
[0007]5‑
甲基胞嘧啶(5mc)和5
‑
羟甲基胞嘧啶(5hmc)是哺乳动物细胞中重要的表观遗传标记。目前5mc和5hmc测序方法可总结如下:1)基于亚硫酸氢盐转化的方法;2)基于亲和捕获的方法,其包括基于抗体的下拉和基于选择性化学标记的下拉;和3)基于限制性内切酶的方法。所有这些现有的方法都需要微克的输入基因组dna。大量的输入限制了稀有样本和单细胞系统的研究应用,例如单细胞在分化过程中的行为。由于其在单碱基分辨率中定量区分5mc和普通的c的能力,基于亚硫酸氢盐转化的方法被认为是黄金标准。然而,dna降解是主要的缺点。基于亲和捕获的方法相对便宜,但分辨率低,并可能因cpg密度覆盖度低而丢失信息(基于抗体的方法)。限制性内切酶的方法的分辨率有限,并且覆盖度取决于序列特异性和甲基化或羟甲基化的敏感性。总的来说,目前的方法都不能对少量dna(纳克级或亚纳克级)中的5mc和5hmc进行测序,或在单细胞水平中获得这些修饰的信息。因此,本领域需要更多的方法用于检测少量dna中的胞嘧啶修饰,例如5mc和5hmc。
技术实现要素:
[0008]
本公开的方法、组合物和试剂盒提供了一种用于整个基因组的有效方法,即无偏dna分析方法,所述方法可以在有限量的dna上进行并且可以有效测定dna的修饰状态。本公开的方面涉及用于扩增经亚硫酸氢盐处理的脱氧核糖核酸(dna)分子的方法,所述方法包括:(a)将衔接子连接到dna分子上,其中衔接子包括rna聚合酶启动子,所述启动子包含亚硫酸氢盐保护的胞嘧啶;(b)用亚硫酸氢盐处理连接的dna分子;(c)使经亚硫酸氢盐处理的dna分子与引物杂交;(d)延伸杂交的引物以产生双链dna;和(e)体外转录所述双链dna以产生rna。
[0009]
本公开的方面涉及用于扩增经亚硫酸氢盐处理的脱氧核糖核酸(dna)分子的方法,所述方法包括:(a)在适于将衔接子连接到dna分子的条件下使核酸分子与连接酶和衔接子接触;其中衔接子包括rna聚合酶启动子,所述启动子包含亚硫酸氢盐保护的胞嘧啶;
(b)用亚硫酸氢盐处理连接的dna分子;(c)在允许引物与经亚硫酸氢盐处理的dna分子杂交的条件下,使dna分子与至少部分与衔接子互补的引物接触;(d)进行引物延伸以产生双链dna;和(e)在适于体外转录dna以产生rna的条件下,在ntp的存在下使双链dna与rna聚合酶接触。
[0010]
术语“亚硫酸氢盐保护的胞嘧啶”是指与亚硫酸氢盐接触后能抵抗脱氨作用的胞嘧啶。本文描述了示例性的亚硫酸氢盐保护的胞嘧啶,包括例如5
‑
甲基胞嘧啶和5
‑
羟甲基胞嘧啶。
[0011]
本公开的其他方面涉及用于鉴定dna分子中的5
‑
羟甲基胞嘧啶(5hmc)的方法,所述方法包括:(1)修饰dna分子中的5hmc以保护其不被氧化;(2)用甲基胞嘧啶双加氧酶氧化来自(1)的经修饰的dna分子,以将5
‑
甲基胞嘧啶(5mc)转化为5
‑
羧基基胞嘧啶(5cac);(3)进行包括以下步骤的方法:(a)将衔接子连接到dna分子上,其中衔接子包括rna聚合酶启动子,所述启动子包含亚硫酸氢盐保护的胞嘧啶;(b)用亚硫酸氢盐处理连接的dna分子;(c)使经亚硫酸氢盐处理的dna分子与引物杂交;(d)延伸杂交的引物以产生双链dna;和(e)体外转录所述双链dna以产生rna。在一些实施方案中,步骤(a)在步骤(1)之前进行。在一些实施方案中,步骤(a)在步骤(1)之后和步骤(2)之前进行。在一些实施方案中,(a)在步骤(2)之后和步骤(3)之前进行。在一些实施方案中,(a)在步骤(3)之后和步骤(b)之前进行。
[0012]
其他方面涉及用于鉴定dna分子中的5mc的方法,所述方法包括:(1)用氧化剂氧化dna分子以将5hmc氧化成5
‑
甲酰基胞嘧啶(5fc)或5cac;(2)进行包括以下步骤的方法:(a)将衔接子连接到dna分子上,其中衔接子包括rna聚合酶启动子,所述启动子包含亚硫酸氢盐保护的胞嘧啶;(b)用亚硫酸氢盐处理连接的dna分子;(c)使经亚硫酸氢盐处理的dna分子与引物杂交;(d)延伸杂交的引物以产生双链dna;和(e)体外转录所述双链dna以产生rna。在一些实施方案中,步骤(a)在步骤(1)之前进行。在一些实施方案中,步骤(a)在步骤(1)之后和步骤(2)之前进行。在一些实施方案中,(a)在(2)之后进行。
[0013]
本公开的其他方面涉及用于鉴定dna分子中的5mc的方法,所述方法包括:(a)将衔接子连接到dna分子上,其中衔接子包括rna聚合酶启动子,所述启动子包含亚硫酸氢盐保护的胞嘧啶;(b)用亚硫酸氢盐处理连接的dna分子;(c)使经亚硫酸氢盐处理的dna分子与引物杂交;(d)延伸杂交的引物以产生双链dna;和(e)体外转录所述双链dna以产生rna;(f)逆转录rna以产生dna;(g)对dna进行测序,并将经测序的dna中的5mc鉴定为序列中的“c”。
[0014]
本公开的其他方面涉及包括dna衔接子的试剂盒,所述衔接子包括rna启动子,其中rna启动子的胞嘧啶是亚硫酸氢盐保护的。
[0015]
在一些实施方案中,甲基胞嘧啶双加氧酶是tet1、tet2或tet3或其同系物。在一些实施方案中,用葡萄糖或经修饰的葡萄糖修饰5hmc。在一些实施方案中,通过包括将核酸分子与β
‑
葡糖基转移酶和葡萄糖或经修饰的葡萄糖分子一起孵育的方法来修饰5hmc。在一些实施方案中,葡萄糖分子是尿苷二磷酸葡萄糖分子。在一些实施方案中,经修饰的葡萄糖分子是经修饰的尿苷二磷酸葡萄糖分子。
[0016]
在一些实施方案中,所述氧化选择性地氧化5hmc残基。在一些实施方案中,氧化剂是化学氧化剂。在一些实施方案中,氧化剂是过钌酸盐氧化剂。在一些实施方案中,氧化剂包括kruo4。在一些实施方案中,氧化剂包括本文所述的氧化剂。
[0017]
在一些实施方案中,亚硫酸氢盐保护的胞嘧啶包括5mc或5hmc。在一些实施方案
中,亚硫酸氢盐保护的胞嘧啶包括肟或腙修饰的5fc。在一些实施方案中,用包含羟胺基团、肼基或酰肼基团的化合物修饰5fc。在一些实施方案中,所述化合物是羟胺;盐酸羟胺;硫酸羟铵;磷酸羟胺;o
‑
甲基羟胺;o
‑
己基羟胺;o
‑
戊基羟胺;o
‑
苄基羟胺;o
‑
乙基羟胺(etonh2)、o
‑
烷基化或o
‑
芳基化羟胺、其酸或盐。在一些实施方案中,亚硫酸氢盐保护的胞嘧啶包括亚硫酸氢盐保护的5cac。在一些实施方案中,5cac是经酰胺修饰的5cac。在一些实施方案中,通过与包含胺基的化合物连接而对5cac进行酰胺修饰。在一些实施方案中,通过将dna分子与碳二亚胺衍生物一起孵育而使5cac与胺基连接。在一些实施方案中,包含胺基的化合物是苄胺、经取代的苄胺、烷基胺、烷基二胺、二甲苯胺、经取代的二甲苯胺、环烷基胺、环烷基二胺、羟胺或经取代的羟胺。在一些实施方案中,亚硫酸氢盐保护的胞嘧啶包括5
’‑
烷基胞嘧啶。烷基可以被进一步取代或是未被取代的。在一些实施方案中,亚硫酸氢盐保护的胞嘧啶包含可以改变芳环的电子密度和/或增加空间阻碍以保护胞嘧啶免受脱氨作用的官能团。
[0018]
在一些实施方案中,启动子是dna依赖的rna聚合酶。启动子可以是原核或非真核rna聚合酶,如细菌或噬菌体。在某些实施方案中,通过由单亚基组成的rna聚合酶识别启动子。在进一步实施方案中,rna聚合酶启动子包括sp6、t7或t3启动子。在一些实施方案中,(a)包括dna的末端修饰和/或dna的末端修复。在一些实施方案中,末端修饰包括末端加a。在一些实施方案中,(a)包括在足以使衔接子与dna分子连接的条件下,使dna与连接酶接触。在一些实施方案中,衔接子进一步包括3’末端封闭分子。3’末端封闭分子是指缺少连接反应所必需的3’磷酸盐的核酸。在一些实施方案中,3’末端封闭分子包括作为末端基团的3’磷酸盐。在一些实施方案中,3’末端封闭分子缺少作为末端基团的3’羟基。
[0019]
在一些实施方案中,衔接子是部分双链的,例如至少或至多20%、25%、30%、35%、40%、45%、50%、55%、60%、65%、70%、75%、80%、85%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%(或其间可推导的任何范围)是双链的。在其他实施方案中,可以有、至少有或至多有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个或多于20个(或其间可推导的任何范围)单链核酸残基。在一些实施方案中,衔接子包含一个或多于一个引物结合位点。在一些实施方案中,衔接子包含一个或多于一个限制性位点。
[0020]
在一些实施方案中,(d)包括使dna分子与dna聚合酶接触。在一些实施方案中,(d)包括在使双链dna变性为单链dna的变性条件下孵育dna。在一些实施方案中,(d)包括在足以使引物退火至单链dna的条件下孵育dna。在一些实施方案中,(d)包括在足以使引物延伸以产生双链dna的条件下孵育dna。
[0021]
在一些实施方案中,(e)包括使dna分子与rna聚合酶和核苷三磷酸接触。
[0022]
在一些实施方案中,该方法还包括一个或多于一个纯化步骤。在一些实施方案中,所述纯化步骤包括固相可逆固定化(spri)珠。在一些实施方案中,该方法还包括(e)的rna分子的纯化。在一些实施方案中,该方法还包括通过使核酸分子与捕获剂接触来分离或纯化核酸分子,其中捕获剂与亲和标签结合;并以及将与亲和标记的核酸分子结合的捕获剂与周围组分分离。
[0023]
在一些实施方案中,该方法还包括(e)的rna分子的逆转录以产生相应的dna分子。在一些实施方案中,按顺序进行(a)至(e)。在一些实施方案中,该方法还包括相应dna分子
的文库构建。在一些实施方案中,该方法还包括对相应的dna分子进行测序。在一些实施方案中,测序包括通过桑格测序、maxam
‑
gilbert测序、solid测序、合成测序、焦磷酸测序、ion torrent半导体测序、大规模平行测序技术、聚合酶克隆测序、454焦磷酸测序、illumina染料测序、dna纳米球测序或单分子实时测序进行的测序。在一些实施方案中,该方法不包括核酸的亚硫酸氢盐处理。
[0024]
在一些实施方案中,dna分子是片段化的。在一些实施方案中,该片段长为100bp至400bp。在一些实施方案中,该片段长为150bp至300bp。在一些实施方案中,该片段长至少、至多或恰好为20bp、30bp、40bp、50bp、60bp、70bp、80bp、90bp、100bp、125bp、150bp、175bp、200bp、225bp、250bp、275bp、300bp、325bp、350bp、375bp、400bp、425bp、450bp、475bp、500bp、525bp、550bp、575bp、600bp、625bp、650bp、675bp、700bp、725bp、750bp、775bp、800bp、825bp、850bp、875bp、900bp、950bp、1000bp、1050bp、1100bp、1150bp、1200bp、1300bp、1400bp、1500bp、1600bp、1700bp、1800bp、1900bp、2000bp、2100bp、2200bp、2300bp、2400bp、2500bp、2600bp、2700bp、2800bp、2900bp、3000bp、3200bp、3400bp、3600bp、3800bp或4000bp(或其间可推导的任何范围)。在一些实施方案中,dna分子包括生物片段,例如分离时以片段状态自然存在的dna。在一些实施方案中,dna分子包括游离dna(cfdna)。在一些实施方案中,游离dna从血清、全血、血浆或其一部分分离。在一些实施方案中,游离dna从组织样本中分离。在一些实施方案中,片段包括基因组dna。在一些实施方案中,片段包括从细胞分离的基因组dna。在一些实施方案中,dna分子被片段化并进行尺寸分级。dna片段的尺寸分级可以通过本领域已知的方法例如凝胶分级、尺寸排除色谱法和通过使用可商购获得的试剂盒(例如epinext
tm
dna尺寸选择试剂盒(epigentek)和select
‑
a
‑
size dna clean&concentrator(zymo research))来进行。
[0025]
在一些实施方案中,该方法还包括使核酸分子片段化。在一些实施方案中,该方法还包括标记核酸分子。在一些实施方案中,核酸被转座子标记和/或片段化。在一些实施方案中,标记和/或片段化核酸包括使核酸分子与转座酶和转座子接触。在一些实施方案中,转座子包括含p7衔接子的转座子。在一些实施方案中,转座子包含亲和标签。亲和标签可以包括例如生物素、myc和his标签。
[0026]
在一些实施方案中,用于试验的起始材料的dna分子的量为1pg至1000ng。在一些实施方案中,用于试验的起始材料的dna分子的量为1pg至100ng。在一些实施方案中,用于试验的起始材料的dna分子的量为1pg至10ng。在一些实施方案中,用于试验的起始材料的dna分子的量为1pg至1ng。在一些实施方案中,用于试验的起始材料的dna分子的量为10pg至1000ng。在一些实施方案中,用于试验的起始材料的dna分子的量为10pg至100ng。在一些实施方案中,用于试验的起始材料的dna分子的量为10pg至10ng。在一些实施方案中,用于试验的起始材料的dna分子的量为10pg至1ng。在一些实施方案中,用于试验的起始材料的dna分子的量为、至少为、至多为约1pg、10pg、50pg、100pg、200pg、300pg、400pg、500pg、600pg、700pg、800pg、900pg、或1000pg或1ng、5ng、10ng、20ng、30ng、40ng、50ng、60ng、70ng、80ng、90ng、100ng、110ng、120ng、130ng、140ng、150ng、160ng、170ng、180ng、190ng、200ng、210ng、220ng、230ng、240ng、250ng、260ng、270ng、280ng、290ng或300ng(或其间可推导的任何范围)。
[0027]
在一些实施方案中,dna分子从对象的样本中分离。在一些实施方案中,dna分子从
活检样本中分离。在一些实施方案中,样本是液体样本或液体活检样本。在特定的实施方案中,样本来自血液、尿液、脑脊液(csf)或房水cfdna。在特定的实施方案中,评估单细胞或评估至多1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、50个、100个、200个、300个、400个或500个细胞(或其间可推导的任何范围)。
[0028]
一些实施方案涉及用于鉴定样本中包括dna分子的生物标志物的方法,所述方法包括执行本公开的方法。一些实施方案涉及为患者提供诊断或预后的方法,所述方法包括执行本公开的方法,其中从患者的生物样本中提供dna分子。一些实施方案涉及评估单细胞的方法,所述方法包括执行本公开的方法,其中从单细胞的基因组dna中提供dna分子。
[0029]
在一些实施方案中,该方法还包括将细胞群分成分离的单细胞。可以通过本领域已知的方法如facs或通过细胞群的连续稀释对细胞分类。在一些实施方案中,该方法还包括标记具有独特核酸序列的每个单细胞的核酸。在一些实施方案中,该方法还包括将标记的核酸合并成单一组合物。
[0030]
在一些实施方案中,该方法还包括核酸的末端修复。末端修复试剂盒是本领域已知和可商购获得的,并且可以用于将含有受损的或不相容的5’和/或3’突出末端的dna转化为5’磷酸化的钝端dna。
[0031]
本公开的某些方法使用样本来进行。生物样本可以使用本领域已知的任意方法获得,所述方法可以提供适于本文描述的分析方法的样本。样本可以通过无创方法获得,所述方法包括但不限于:刮擦皮肤或子宫颈、擦拭脸颊、收集唾液、收集尿液、收集粪便、收集月经、眼泪或精液。
[0032]
样本可以通过本领域已知的方法获得。在某些实施方案中,样本通过活检获得。在其他实施方案中,样本通过擦拭、刮擦、静脉切开术或本领域已知的任何其他方法获得。在一些情况下,可以使用本方法的试剂盒的组件来获得、储存、冷冻或转运样本。在一些实施方案中,样本包括血液样本、血清样本、血浆样本或其部分。在一些实施方案中,样本包括尿液样本。
[0033]
在一些实施方案中,生物样本可以通过内科医生、护士或其他医学专家,例如医疗技术人员、内分泌学家、细胞学家、静脉切开术专家、放射学家或肺学家获得。医学专家可以指示对样本执行的适当的测试或试验。在某些方面,分子分析事务可以咨询哪种试验或测试被最适当地指示出来。在本发明的其他方面,患者或对象可以无需医疗专家协助而获得用于测试的生物样本,例如获得全血样本、尿液样本、粪便样本、口腔样本或唾液样本。
[0034]
除非另有说明,否则方法可以涉及本文描述的任何以下步骤并可以以任意特定顺序。特别预期本文所讨论的任何方法或试剂盒或组合物可与本文所讨论的任何其它实施方案组合。步骤和实施方案可以以任何可行的组合一起使用。
[0035]
本公开的方法可以包括1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、或15个或多于15个以下步骤,所述步骤可以以任何顺序进行并在全部的任意特定方法实施方案中重复:获得核酸分子;从生物样本中获得核酸分子;从对象中获得含有核酸的生物样本;分离核酸分子;纯化核酸分子;获得含有待修饰核酸的阵列或微阵列;使核酸分子变性;剪切或切割核酸;使核酸分子杂交;使核酸片段化;使核酸分子与酶一起孵育;使核酸分子与不修饰5mc的酶一起孵育;使核酸分子与限制性酶一起孵育;使一种或多于一种化学基团或化合物与核酸或5mc或经修饰的5mc连接;使一种或多于一种化学基团
或化合物与核酸或5mc或经修饰的5mc缀合;通过添加或去除一种或多于一种元素、化学基团或化合物,使核酸分子与修饰核酸分子或5mc或经修饰的5mc的酶一起孵育;将5mc修饰或转化为5
‑
羟甲基胞嘧啶(5hmc);用β
‑
葡糖基转移酶(βgt)修饰5hmc;在促进通过葡萄糖分子(其可以被修饰或不被修饰)糖基化核酸并产生在一种或多于一种5
‑
羟甲基胞嘧啶上糖基化的核酸的条件下,将β
‑
葡糖基转移酶与udp
‑
葡萄糖分子和核酸底物一起孵育;使衔接子与dna分子连接,其中所述衔接子包括rna聚合酶启动子,所述启动子包含亚硫酸氢盐保护的胞嘧啶;用亚硫酸氢盐处理连接的dna分子;使经亚硫酸氢盐处理的dna分子与引物杂交;延伸杂交的引物以产生双链dna;和在体外转录双链dna以产生rna。
[0036]
预期一些实施方案将涉及在体外进行的步骤,例如通过人、或控制或使用机械的人以执行一个或多于一个步骤。
[0037]
方法或组合物将涉及经纯化的核酸、修饰试剂或酶、标记、化学修饰部分、经修饰的udp
‑
glc和/或酶,例如β
‑
葡糖基转移酶。这样的方案对本领域技术人员是已知的。
[0038]
在某些实施方案中,纯化作用可以产生相对于任何污染组分(重量/重量或重量/体积)约或至少约70%、75%、80%、85%、90%、95%、96%、97%、98%、99%、99.1%、99.2%、99.3%、99.4%、99.5%、99.6%、99.7%、99.8%、99.9%或大于99.9%的纯度(或其间可推导的任何范围)的分子。
[0039]
在其他方法中,有步骤包括但不限于获得约核酸样本中一种或多于一种胞嘧啶修饰的信息(定性和/或定量);安排检测以确定、鉴定和/或映射核酸样本中的胞嘧啶修饰;报告关于核酸样本中一种或多于一种胞嘧啶修饰的信息(定性和/或定量);将该信息与对照或比较样本中不同胞嘧啶修饰的信息进行比较。除非另有说明,在样本的上下文中,术语“测定”、“分析”、“检测”和“评估”是指样本的化学或物理转化,以收集关于样本的定性和/或定量数据。而且,术语“映射”表示鉴定特定核苷酸的核酸序列内的位置。
[0040]
在一些实施方案中,核酸分子可以是dna、rna或两者的组合。核酸可以是重组的、基因组的或合成的。在另外的实施方案中,方法涉及分离的和/或纯化的核酸分子。在一些实施方案中,核酸分子是片段化的。在一些实施方案中,核酸分子是天然片段化的。天然片段化是指自然界中作为片段存在的核酸分子,例如游离dna和胎儿dna。在一些实施方案中,核酸可以从细胞或生物样本中分离。某些实施方案涉及从真核细胞、哺乳动物细胞或人细胞中分离核酸。在一些情况下,它们是从非核酸中分离的。在一些实施方案中,核酸分子是真核的;在一些情况下,核酸是哺乳动物的,所述哺乳动物可能是人。这意味着核酸分子是从人细胞中分离的,和/或具有鉴定其为人的序列。在特定的实施方案中,预期核酸分子不是原核核酸,例如细菌核酸分子。在另外的实施方案中,分离的核酸分子在阵列上。在特定的情况下,阵列是微阵列。在一些情况下,核酸是通过本领域技术人员已知的任意技术分离的,其包括但不限于使用凝胶、柱、基质或过滤器来分离核酸。在一些实施方案中,凝胶是聚丙烯酰胺或琼脂糖凝胶。
[0041]
方法和组合物还可以涉及一种或多于一种酶。在一些实施方案中,酶是聚合酶。在某些情况下,实施方案涉及限制性酶。限制性酶可以是甲基化不敏感的。预期利用酶实现结果的步骤涉及在反应条件下孵育酶以实现该结果。这样的条件包括但不限于温度、压力、ph、黏度、体积和用于反应的任何辅因子的存在,这为本领域技术人员所知。它可以包括一种或多于一种反应缓冲液。在一些实施方案中,可以通过热灭活、稀释、改变ph、或添加干扰
反应的化合物或通过改变停止反应的条件来停止反应。
[0042]
方法或组合物涉及检测、表征和/或区分胞嘧啶修饰。方法可以涉及通过将经修饰的核酸与未经修饰的核酸或与修饰状态已知的核酸进行比较来鉴定核酸中的5mc。修饰的检测可涉及多种重组核酸技术。在一些实施方案中,在允许经修饰的核酸进行聚合的条件下,将经修饰的核酸分子与聚合酶、至少一种引物和一种或多于一种核苷酸一起孵育。在另外的实施方案中,方法可以涉及对经修饰的核酸分子进行测序。在其他实施方案中,经修饰的核酸用于引物延伸检测。
[0043]
方法和组合物可以涉及对照核酸。对照可以用于评估是否发生了修饰或其他酶反应或化学反应。或者,对照可以用于比较修饰状态。对照可以是阴性对照或其可以使阳性对照。它可以是在修饰反应中不与一种或多于一种试剂一起孵育的对照。或者,对照核酸可以是参考核酸,这表示其修饰状态(基于与5mc处的修饰相关的定性和/或定量信息,或其缺失)用于与被评估的核酸进行比较。在一些实施方案中,不同来源的多重核酸为对照核酸提供了基础。而且,在一些情况下,对照核酸来自关于特定属性如疾病或状态或其他表型的常规样本。在一些实施方案中,对照包括非癌症的组织。在一些实施方案中,对照包括截止值。在一些实施方案中,对照样本来自不同的患者群体、不同的细胞类型或器官类型、不同的疾病状态、疾病状态的不同阶段或严重程度、不同的预后、不同的发展阶段等。
[0044]
实施方案还涉及试剂盒,其可以在合适的容器中,可用于实现所述方法。本公开的实施方案涉及包括dna衔接子的试剂盒,所述衔接子包括rna启动子,其中rna启动子的胞嘧啶是亚硫酸氢盐保护的。在一些实施方案中,试剂盒包括连接酶和/或连接酶缓冲液。在一些实施方案中,试剂盒包括亚硫酸氢盐。在一些实施方案中,试剂盒还包括与衔接子互补的引物。在一些实施方案中,试剂盒还包括dntp。在一些实施方案中,试剂盒进一步包括dna聚合酶。在一些实施方案中,试剂盒还包括无核酸酶水。在一些实施方案中,试剂盒进一步包括蛋白酶。在一些实施方案中,试剂盒还包括rna聚合酶。在一些实施方案中,试剂盒还包括ntp。在一些实施方案中,试剂盒还包括氧化剂。在一些实施方案中,试剂盒还包括加双氧酶。在一些实施方案中,试剂盒还包括包含羟胺基团、肼基或酰肼基团的化合物。在一些实施方案中,试剂盒还包括包含胺基的化合物。在一些实施方案中,试剂盒还包括3’末端封闭分子。在一些实施方案中,试剂盒还包括spri珠。在一些实施方案中,试剂盒还包括逆转录酶。在一些实施方案中,试剂盒还包括葡萄糖或经修饰的葡萄糖。在一些实施方案中,试剂盒还包括β
‑
葡糖基转移酶。
[0045]
在某些实施方案中,试剂盒的内容物可以包括甲基胞嘧啶双加氧酶或其同系物和5
‑
羟甲基胞嘧啶修饰剂。在另外的方面,甲基胞嘧啶双加氧酶是tet1、tet2或tet3。在其他实施方案中,试剂盒包括tet1、tet2或tet3催化结构域。在某些方面,5hmc修饰剂是β
‑
葡糖基转移酶,所述5hmc修饰剂是指能够修饰5hmc的试剂。
[0046]
在另外的实施方案中,试剂盒还含有5hmc修饰,例如尿苷二磷酸葡萄糖或经修饰的尿苷二磷酸葡萄糖分子。在特定的实施方案中,经修饰的尿苷二磷酸葡萄糖分子可以是尿苷二磷酸6
‑
n3‑
葡萄糖分子。在另外的实施方案中,试剂盒还含有生物素。
[0047]
某些实施方案涉及包括载体和5
‑
羟甲基胞嘧啶修饰剂的试剂盒,所述载体包括可操作地与编码双加氧酶或其一部分的核酸片段连接的启动子。在某些方面,核酸片段编码tet1、tet2或tet3或其催化结构域。在某些方面,5hmc修饰剂是β
‑
葡糖基转移酶。在另外的
方面,试剂盒还含有5hmc修饰,例如尿苷二磷酸葡萄糖或经修饰的尿苷二磷酸葡萄糖分子。在特定的实施方案中,经修饰的尿苷二磷酸葡萄糖分子可以是尿苷二磷酸6
‑
n3‑
葡萄糖分子。在另外的实施方案中,试剂盒还含有生物素。
[0048]
在一些实施方案中,存在包含一种或多于一种修饰剂(酶或化学的)和一种或多于一种修饰部分的试剂盒。分子可以具有或涉及不同类型的修饰剂。在进一步实施方案中,试剂盒可以包括一种或多于一种缓冲液,例如用于核酸或用于涉及核酸的反应的缓冲液。除了β
‑
葡萄糖基转移酶或替代β
‑
葡萄糖基转移酶,试剂盒中可以包括其他酶。在一些实施方案中,酶是聚合酶。试剂盒还可以包括与聚合酶一起使用的核苷酸。在一些情况下,除了聚合酶或代替聚合酶,还包括限制性酶。在一些实施方案中,试剂盒包括核酸探针。核酸探针可能已经或可能还没有被修饰。在一些实施方案中,试剂盒包括用于与核酸探针连接的修饰部分。
[0049]
其他实施方案还涉及含有核酸分子的阵列或微阵列,所述核酸分子已在5hmc和/或5mc的核苷酸上被修饰。在一些实施方案中,微阵列包括从样本中分离的片段化的核酸。
[0050]
以下专利申请描述了对本发明的方法有用的实施方案:wo2011127136、wo2012138973和wo2014165770,其通过引用并入本文。
[0051]
当在权利要求和/或说明书中与术语“包含”一起使用时,要素前面不使用数量词可以表示“一个”,但是其也符合“一个或更多个”、“至少一个”和“一个或多于一个”的意思。
[0052]
预期本文所讨论的任何实施方案可以针对本发明的任何方法或组合物实施,反之亦然。此外,本发明的组合物和试剂盒可以用于实现本发明的方法。另外,在一种方法的上下文中列举的任何步骤可以在本文公开的任何其他方法的上下文中使用(作为替代步骤或作为添加的步骤)。任何方法都可以省略本文列举的一个或多于一个步骤。
[0053]
在本申请中,术语“约”用于表明值包括针对用于确定该值而使用的装置或方法的误差的标准差。
[0054]
在权利要求中使用术语“或”表示“和/或”,除非明确地说明是仅指选择或选择是相互排斥的,尽管公开支持仅指选择和“和/或”的定义。还预期使用术语“或”所列出的任何事物也可以特别地排除在外。
[0055]
如本说明书和权利要求所使用的,单词“包含”、“具有”、“包括”或“含有”是包括性的或开放式的,并且不排除另外的、未列举的元素或方法步骤。预期本文所讨论的具有术语“包含”的任意实施方案可以用短语“由
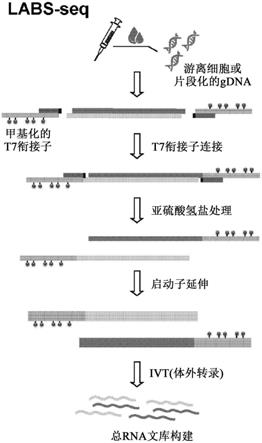
……
组成”或“基本上由
……
组成”代替,因为这些术语在专利法的背景下被理解。
[0056]
从以下详细描述中,本发明的其他目的、特征和优点将变得显而易见。然而,应该理解的是,详细描述和具体实施例虽然表明了本发明的具体实施方案,但仅以说明的方式给出,因为本详细描述在本发明的精神和范围内的各种变化和修改对于本领域技术人员将变得显而易见。
附图说明
[0057]
以下附图构成本说明书的一部分,并且包括在内以进一步说明本发明的某些方面。通过参照一个或多于一个这些附图结合本文所提供的具体实施方案的详细说明可以更好地理解本发明。
[0058]
图1a至图1e:(a)labs
‑
seq的工作流程:使游离dna或片段化的基因组dna与完全甲基化的t7衔接子连接;进行亚硫酸氢盐处理和t7启动子延伸;ivt扩增,然后制备总rna文库并进行测序。(b)针对由10pg、20pg、50pg、100pg、1ng、10ng和100ng构建的labs
‑
seq文库的映射效率、总体cpg甲基化水平和重复水平(含技术复制)。每个点都是文库。(c)labs
‑
seq、methylc
‑
seq和epignome之间的染色体覆盖度比较。(d)dna甲基化谱的基因组浏览器视图。(e)显示labs
‑
seq与批量参考和labs
‑
seq重复之间相关性的散点图,并显示皮尔逊相关性(r)。
[0059]
图2a至图2c:(a)labs
‑
seq、epignome和methylc
‑
seq的饱和度图,说明了cpg覆盖度与测序深度之间的关系。图显示了所覆盖的唯一cpg数量(y轴)与对齐读取(x轴)的函数关系。(b)三种方法的gc含量偏倚。(c)通过读值累积分数与基因组累积分数的洛伦兹曲线得到的扩增均匀度。完全均匀的覆盖对应对角线,偏离对角线代表扩增偏倚。
[0060]
图3a至图3d:(a)在注释的基因组位点,标准化的甲基化cpg超过总cpg残基。(b)甲基化水平随激活组蛋白标记h3k4me3和抑制的标记h3k27me3而变化。(c)cpg计数跨越不同的基因组背景。每个基因组背景上方的每组棒从左到右代表甲基
‑
seq
–
1ng、epignome
–
1ng和labs
‑
seq
–
50pg。(d)三种wgbs方法之间标准化颜色注释的比较。chromhmm状态右侧上方的每组棒从上到下代表甲基
‑
seq
–
1ng、epignome
–
1ng和labs
‑
seq
–
50pg。
[0061]
图4a至图4b:(a)在crc患者和pan患者中显示低甲基化(md<
‑
3sd)、高甲基化(md>3sd)和差异甲基化(|md|>3sd)的箱百分比。(c)一个健康对照、一个crc患者和一个胰腺癌患者的甲基化分析。三个样本的甲基化z评分位于从外环到内环。
[0062]
图5a至图5d:用于对crc患者和健康人进行分组的cfdna dmr。(a)crc患者和健康对照者中109种dmr的热图。通过欧氏距离对dmr和样本进行聚类。(b)dmr的全基因组分布。(c)crc组与健康组的分层聚类分析。(d)所有crc患者和健康人的pca图。
[0063]
图6a至图6c:(a)6个健康人和6个crc患者的不同组织对血浆cfdna的贡献百分比。每个棒都意味着每个人的比例。(b)结肠在crc患者和健康人血浆中的贡献。(c)嗜中性粒细胞在crc患者和健康人的血浆中的贡献。
[0064]
图7a至图7b:(a)labs
‑
seq(第1至6棒)、methylc
‑
seq(第10至12棒)和epignome(第7至9棒)之间的基因组覆盖度比较。(b)labs
‑
seq(第1至6棒)、methylc
‑
seq(第10至12棒)和epignome(第7至9棒)cpg之间的数量比较。
[0065]
图8:沿增长的截止读值1x、3x和5x的覆盖的cpg数量。
[0066]
图9:cpgs log2富集评分跨越不同基因组背景:3’utr、line、sine、外显子、内含子、基因间、启动子、5'utr、cpg岛、ltr、简单重复和随体。
[0067]
图10:cfdna labs
‑
seq文库比较lab
‑
seq、methylc
‑
seq和epignome之间的(a)基因组覆盖度;(b)cpg数量;(c)重复水平比较。所有这些cfdna文库均由100pg和1ng无癌cfdna采用技术重复来构建。每个点都是文库。
具体实施方式
[0068]
由于策略困难、亚硫酸氢盐降解和文库复杂性低,以单碱基分辨率对来自dna材料有限的样本,例如液体活检样本(低至亚纳克)的5
‑
甲基胞嘧啶(5mc)进行全基因组测序仍然具有挑战性。本公开涉及被称为基于线性扩增的全基因组亚硫酸氢盐测序方法(labs
‑
seq)的方法,其中微量游离dna材料可以通过体外转录来进行均匀且线性地扩增而不造成甲基化组信息的丢失或偏倚。所述方法展示了沿着重复水平和高映射比的高基因组覆盖度。labs
‑
seq提供高质量数据,尤其是亚纳克水平的数据,使得能够探索游离dna液体活检的dna修饰动态变化和差异甲基化信号,其用于肿瘤标志物的鉴定和组织来源的预测。
[0069]
i.分子生物学方法
[0070]
本公开的方法包括在本领域中已知且详细描述的某些分子生物学应用。例如,本公开的方法包括使衔接子与dna分子连接。典型的连接酶反应可以包括dna连接酶(例如t4 dna连接酶)、连接酶缓冲液、待通过连接反应进行连接的dna碎片和稀释剂,例如水或无核酸酶水。连接酶包括来自大肠杆菌(e.coli)的连接酶、来自噬菌体t4的t4 dna连接酶、哺乳动物连接酶和耐热连接酶(例如ampligase dna连接酶)和变体及其经修饰的形式。制备和混合了连接反应的组分后,通常通过在适于连接酶活性的条件下孵育该组分来进行所述反应。在一些实施方案中,这些条件可以包括约16℃的温度和约2个或多于2个小时的时间。在一些实施方案中,所述时间可以通过使用高浓度t4 dna来减少。在一些实施方案中,然后对反应进行加热(例如65℃)以使酶失活。
[0071]
在一些实施方案中,该方法包括核酸分子的文库构建。术语“文库”是指包含核酸分子的载体的集合(例如,多个载体)。载体可以是介体、构建体、阵列或其他物理载体。“载体”或“构建体”(有时称为基因递送或基因转移“载体”)是指大分子、分子复合物或病毒颗粒,包括将在体外或体内递送至宿主细胞的多核苷酸。多核苷酸可以是线性或环状分子。本领域技术人员应当有能力通过标准重组技术构建载体(参考,例如maniatis等人,1988;ausubel等人,1994,两者都通过引用并入本文)。阵列包含固体支持物,其中核酸探针附着于支持物。阵列通常包含多个不同的核酸探针,其在不同的已知位置结合于基质表面。这些阵列,也称为“微阵列”或俗称“芯片”,已在本领域中进行了普遍描述,例如,美国专利第5143854号、第5445934号、第5744305号、第5677195号、第6040193号、第5424186号和fodor等人(1991),其全部内容结合于此用于所有目的。使用机械合成方法合成这些阵列的技术在例如美国专利第5384261号中进行了描述,其全部内容结合于此用于所有目的。尽管在某些方面使用了平面阵列表面,但是可以在几乎任何形状的表面或甚至多个表面上制造阵列。阵列可以是珠子、凝胶、聚合物表面、纤维如光纤、玻璃或任何其他合适的基质上的核酸,参见美国专利第5770358号、第5789162号、第5708153、第6040193号和第5800992号,其全部内容结合于此用于所有目的。载体可以包含限制性核酸内切酶位点,其可用于进一步克隆或其他分子生物学过程。载体还可以包含引物结合位点,其可用于对pcr扩增进行测序和/或用于定量的pcr研究。
[0072]
在一些实施方案中,核酸是经纯化的。核酸的纯化可以在本文描述的任意步骤之间进行。在一些实施方案中,核酸的纯化不包括柱过滤。在一些实施方案中,纯化包括苯酚氯仿、磁珠、基于二氧化硅的方法(例如在离液盐存在下的二氧化硅膜)和阴离子交换。在一些实施方案中,所述纯化包含spri(固相可逆固定化)珠。spri珠是顺磁性的(仅在磁场中有磁性),并且这防止它们结块并脱离溶液。每个珠都由聚苯乙烯制成,周围有磁铁矿层,上面覆盖着羧基分子。正是这些在“拥挤剂”聚乙二醇(peg)和盐(20%peg、2.5m nacl是神奇的混合物(magic mix))的存在下可逆地结合dna。peg使带负电荷的dna与珠子表面的羧基结合。由于固定化取决于反应中peg和盐的浓度,因此珠子与dna的体积比很重要。spri特别适
合用于低浓度dna的清除。
[0073]
本公开的一些实施方案涉及引物延伸。引物延伸是指使引物退火至dna(被称为模板,因为它用作产生新链的模板)并添加聚合酶和dntp,并且在允许产生从引物开始沿5
’‑3’
方向延伸的dna分子的条件下培养反应。引物的退火一般通过在适于使引物与单链dna结合的条件下,使单链dna与引物一起孵育来实现。引物应该至少部分互补以允许结合。在一些实施方案中,引物可以具有允许添加模板dna中不存在的序列的非互补区域。引物可以具有100%、99%、98%、97%、96%、95%、94%、93%、92%、91%、90%、89%、88%、87%、86%或85%(或其间任何可推导的范围)与模板dna互补的区域。该区域能够退火至模板dna。退火步骤可以在允许使模板dna与引物结合的温度下进行。该温度一般低于引物的tm约3℃至5℃。一旦使引物退火,可以在适于通过引物延伸来产生核酸的条件下,使退火的引物和模板dna与dntp(如果反应是为了制造rna,则为ntp)和聚合酶一起孵育。使用的典型的聚合酶为taq(水生嗜热菌)聚合酶。延伸反应的温度取决于聚合酶表现出活性的温度。对于taq,一般延伸温度为约70℃至80℃。
[0074]
在一些实施方案中,可以对本公开方法的dna分子进行pcr扩增。基本的pcr设置需要几种组分和试剂,其包括:含有dna靶区域以扩增的dna模板、dna聚合酶、聚合新dna链的酶;耐热taq聚合酶特别常见,因为它可能在高温dna变性过程中保持完整;与dna靶的每条有义链和无义链的3’(三种引物)末端互补的一种或多于一种dna引物;脱氧核苷三磷酸或dntp(有时称为“脱氧核苷酸三磷酸”;含有三磷酸基团的核苷酸),dna聚合酶从中合成新的dna链的合成砌块;为dna聚合酶的活性和稳定性提供合适的化学环境的缓冲溶液;二价阳离子,通常为镁(mg)或锰(mn)离子;mg
2+
是最常规的,但mn
2+
可以用于pcr介导的dna诱变,因为更高的mn
2+
浓度增加了dna合成期间的差错率;单价阳离子,通常为钾(k)离子。
[0075]
本公开的实施方案涉及用亚硫酸氢盐处理dna分子。用亚硫酸氢盐处理dna会将胞嘧啶残基转化为尿嘧啶。方法涉及保护胞嘧啶残基免受亚硫酸氢盐影响。本文进一步描述了这种方法。亚硫酸氢盐处理可以是提供hso3‑
离子的任意处理,例如利用含有hso3‑
离子的盐,如亚硫酸氢纳。在一些实施方案中,经亚硫酸氢纳处理的dna是单链的。
[0076]
在一些实施方案中,dna分子是体外转录的。体外转录包括含有rna聚合酶启动子如双链rna启动子的dna模板、以及核糖核苷酸三磷酸(ntp)。在一些实施方案中,dna模板是经纯化的。在一些实施方案中,dna模板是直链的。体外转录还可以包括在适于进行体外转录的条件下孵育dna模板、rna聚合酶和ntp。在一些实施方案中,体外转录包括用缓冲液孵育反应。在一些实施方案中,缓冲液包括氧化还原试剂和阳离子。在一些实施方案中,氧化还原试剂包括二硫苏糖醇(dtt)。在一些实施方案中,阳离子包括二价阳离子。在一些实施方案中,阳离子包括镁阳离子。在一些实施方案中,进行体外转录的dna分子是直链的并且含有相对于待转录的靶序列的正确方向的rna聚合酶启动子。例如,最小t7启动子包含:taatacgactcactata(seq id no:1),其可以插入靶dna的5’末端。失控转录物将具有启动子之后3’区域的序列。在一些实施方案中,体外转录包括在适于进行dna分子的体外转录以产生相应rna分子的条件下,使dna分子与含有rna聚合酶和ntp的反应混合物接触。在一些实施方案中,所述条件包括在聚合酶有活性的温度下孵育反应混合物。例如,t7聚合酶可以需要温度为30℃至45℃或35℃至40℃保持至少1小时、2小时、4小时、12小时或24小时(或其间可推导的任何范围)、或长于24小时。体外转录系统是可商购获得的。例如,新英格兰生物学
实验室售卖hiscribe
tm
,即可用于本公开的方法的体外转录试剂盒。预期任意rna聚合酶可与其相应的启动子一起用于此系统。在一些实施方案中,rna启动子包括sp6启动子,并且rna聚合酶包括sp6聚合酶。在一些实施方案中,rna启动子包括t3启动子并且聚合酶包括t3聚合酶。在一些实施方案中,rna启动子包括t7启动子并且聚合酶包括t7聚合酶。
[0077]
本公开的方法涉及利用可与dna连接的衔接子的实施方案。在一些实施方案中,衔接子包含一个或多于一个引物结合位点,其可用于测序、用于pcr或用于实时定量pcr。所述衔接子可以包含允许进行其他复制生物学技术的一个或多于一个克隆位点。所述衔接子可以包含报告基因,例如抗生素抗性基因或标记基因如提供荧光的基因(绿色荧光蛋白及其衍生物)。
[0078]
ii.核酸修饰
[0079]
在某些实施方案中,方法涉及保护特定胞嘧啶或胞嘧啶变体免受亚硫酸氢盐处理,尤其是亚硫酸氢盐介导的脱氨作用。所述保护可以包括这些变体的化学修饰,使经修饰序列的亚硫酸氢盐测序中的读值可以不同于未经修饰的对照核酸。
[0080]
用亚硫酸氢盐处理核酸可以使胞嘧啶残基转化为尿嘧啶,而5
‑
甲基胞嘧啶或5
‑
羟甲基胞嘧啶残基不受影响。因此,亚硫酸氢盐处理可以诱导dna测序中的特定变化,从而产生关于dna片段的甲基化状态的单核苷酸分辨率信息,所述dna测序取决于单独胞嘧啶残基的甲基化状态。可以对改变的序列进行各种分析来检索该信息。该分析的一个目的可以归结为区分亚硫酸氢盐转化导致的单核苷酸多态性(胞嘧啶和胸苷或尿嘧啶)。
[0081]
某些实施方案涉及5fc和/或5cac修饰以保护胞嘧啶免受亚硫酸氢盐处理。其他实施方案涉及5fc和/或5cac修饰以使它们易于进行亚硫酸氢盐脱氨作用。以下描述了可用于所公开方法的示例性修饰,其用于各种目的,例如,用于保护胞嘧啶免受亚硫酸氢盐脱氨作用或用于各种胞嘧啶修饰的差异检测。
[0082]
a.5fc的修饰
[0083]
某些实施方案针对用于修饰含有5fc的核酸或修饰、检测和/或评估核酸中的5fc的方法和组合物。在某些方面,修饰核酸以保护5fc免受亚硫酸氢盐介导的脱氨作用。例如,可以通过包括羟胺基团(如r
‑
nh
‑
oh)、肼基团(如r
‑
nh
‑
nh2)或酰肼基团(如r
‑
c(=o)
‑
nh
‑
nh2)的化合物将核酸修饰为肟。
[0084]
可以使用本文所述的方法将官能团(例如羟胺)结合或连接到核酸上。官能团的这种结合或连接允许用生物素或标签进一步标记或标注胞嘧啶残基。5fc的标记或标注可以使用例如点击化学或本领域技术人员已知的其他官能团/连接基团。含有5fc的经标记或标注的核酸片段可以被富集、分离、检测和/或评估。
[0085]
可用于某些方面的羟胺基团包括具有以下通式或具有包括以下通式的官能团的那些:
[0086]
[0087]
其中r1、r2是氢,r3选自氢、低级烷基和芳香基;和这些羟胺的水溶性盐。低级烷基通常可以具有1个至8个碳原子并且芳香基可以为例如苯基、苄基和甲苯基。
[0088]
合适的含有羟胺的化合物的非限制性实例包括羟胺;盐酸羟胺;硫酸羟铵;磷酸羟胺;o
‑
甲基羟胺;o
‑
己基羟胺;o
‑
戊基羟胺;o
‑
苄基羟胺;特别地,o
‑
乙基羟胺(etonh2),或可以使用任何o
‑
烷基化或o
‑
芳香基化羟胺。
[0089]
在某些方面也适用的是化合物,其在加入到含水体系中时产生羟胺。
[0090]
含有羟胺基团的化合物还可以包括经取代的羟胺衍生物。如果羟基氢被取代,这称为o
‑
羟胺。与普通胺类似,可以区分伯、仲和叔羟胺,后两种分别指两个或三个氢被取代的化合物。
[0091]“肼基”可以指二价基团
–
nr1r2‑
nh2,其中r1和r2可以是烷基、芳香基或苄基。如本文使用的,“肼基”包括但不限于肼、酰肼、氨基脲、卡巴肼、氨基硫脲、硫代卡巴肼、肼基羧酸酯和碳酸肼。本文使用的肼的实例包括n
‑
烷基肼、n
‑
芳基肼、n
‑
苄基肼、n,n
‑
二烷基肼、n,n
‑
二芳基肼、n,n
‑
二苄基肼、n,n
‑
烷基苄基肼、n,n
‑
芳基苄基肼和n,n
‑
烷基芳基肼。
[0092]“肼基”可以指常见官能团,其特征在于具有四个取代基的氮
‑
氮共价键,其中至少一个取代基是酰基。肼基的一般结构可以为r
‑
c(=o)
‑
nr3‑
nh2或r
‑
(so2)r3‑
nh2,其中r可以为烷基或芳香基,r3可以为氢、烷基、芳香基或苄基。这一类的重要成员是磺酰肼,例如p
‑
甲苯磺酰肼,它们是有机化学中如在shapiro反应中的有用试剂。这种试剂可以通过甲苯磺酰氯与肼的反应来制备。本文使用的酰肼的实例包括
‑
对甲苯磺酰肼、n
‑
酰基酰肼、n,n
‑
烷基酰基酰肼、n,n
‑
苄基酰基酰肼、n,n
‑
芳基酰基酰肼、n
‑
磺酰酰肼、n,n
‑
烷基磺酰酰肼、n,n
‑
苄基磺酰酰肼和n,n
‑
芳基磺酰酰肼。
[0093]
b.5cac的修饰
[0094]
某些实施方案针对用于修饰含有5cac的核酸的方法和组合物。在某些方面,修饰靶核酸以保护5cac免受亚硫酸氢盐介导的脱氨作用。例如,核酸可以通过与含胺化合物或包含胺基的化合物反应转化为酰胺。
[0095]
含胺化合物可以具有通式nh2‑
r,其中r=烷基如
–
ch2ch3或
–
ch
‑
(ch3)2;环烷基、芳香基或苄基。例如,胺基可以是烷基胺、环烷基胺、苄胺、二甲苯胺或羟胺。含胺化合物可以是烷基胺、环烷基胺或苄胺。可以将胺基连接到经检测的标签或化合物如生物素。
[0096]
胺基是含有带孤对电子的碱性氮的官能团。胺是氨的衍生物,其中以一个或多于一个氢原子被取代基例如烷基或芳香基所取代。包含胺基的化合物可以是脂肪族胺或芳香族胺、伯胺、仲胺、叔胺或环胺。
[0097]
脂肪族胺没有与氮原子直接相连的芳族环。芳香胺的氮原子与芳族环连接,如在不同苯胺中一样。芳族环降低了胺的碱性,这取决于它的取代基。胺基的存在由于其给电子效应大大提高了芳族环的反应性。
[0098]
还可以将胺分为四个子类:
[0099]
伯胺
‑
当氨中的三个氢原子之一被烷基或芳香族取代时,就会产生伯胺。重要的伯烷基胺包括甲胺、乙醇胺(2
‑
氨基乙醇)和缓冲剂三羟甲基氨基甲烷,而伯芳香族胺包括苯胺。
[0100]
仲胺
‑
仲胺有两个取代基(烷基、芳香基或两者)与n和一个氢原子结合。重要的代表包括二甲胺和甲基乙醇胺,而芳族胺的一个实例是二苯胺。
[0101]
叔胺
‑
在叔胺中,所有三个氢原子都被有机取代基取代。实例包括三甲胺或三苯基胺,三甲胺具有明显的鱼腥味。
[0102]
环胺
‑
环胺是仲胺或叔胺。环胺的实例包括3元环氮丙啶和六元环哌啶。n
‑
甲基哌啶和n
‑
苯基哌啶是环叔胺的实例。
[0103]
在某些实施方案中,可以使用偶联剂用胺或硫醇基修饰或标记5cac,所述偶联剂例如碳二亚胺衍生物,即具有由式r1n=c=nr2组成的官能团的化合物。在特定实施方案中,r1和r2是相同的或不同的并且可以是烷基或芳香基。例如,碳二亚胺衍生物可以是1
‑
乙基
‑3‑
(3
‑
二甲基胺基丙基)碳二亚胺(edc)或n,n'
‑
二环己基碳二亚胺(dcc)。
[0104]
c.5mc和/或5hmc的修饰
[0105]
在某些实施方案中,核酸中的5mc和/或5hmc可以进行修饰,例如氧化为5cac。在进一步实施方案中,将5mc和/或5hmc氧化为5cac可以通过使核酸与甲基胞嘧啶双加氧酶(例如tet1、tet2和tet3)或具有与甲基胞嘧啶双加氧酶相似的活性或催化区域的酶接触来完成。核酸可以是分离的核酸、样本中的核酸、通过以上所述方法修饰的核酸(5fc和/或5cac的修饰)、或未经修饰的核酸。
[0106]
dna中的5
‑
甲基胞嘧啶(5mc)在基因表达、基因组印记和转座子的抑制方面具有重要功能。已知5mc可以通过tet(十
‑
十一易位)蛋白转化为5
‑
羟甲基胞嘧啶(5hmc)。因此,本公开的实施方案包括其中5mc氧化为5hmc和/或5hmc氧化为5fc和/或5fc氧化为5cac的方法。tet蛋白可以以依赖酶活性的方式将5mc转化为5
‑
甲酰胞嘧啶(5fc)和5
‑
羧基胞嘧啶(5cac)(ito等人,2011,通过引用并入)。
[0107]
5mc的修饰可以使用酶或化学试剂进行催化或导致修饰部分转化为5mc,从而产生经修饰的5mc(m5mc)来进行。这种策略有益于合并对5mc的修饰,以标记或标记真核核酸中的5mc。
[0108]
化学标签可以用于以高通量的方式确定5mc的精确位置。发明人表明5mc修饰使标记的dna对某些限制酶消化和/或聚合具有抗性。在某些方面,经修饰的和未经修饰的基因组dna可以用限制性酶进行处理,之后采用各种测序方法以显示阻碍消化的每个胞嘧啶修饰的精确位置。
[0109]
发明人表示,修饰部分,例如官能团(如叠氮基),可以使用本文所述的方法并入dna。官能团的这种合并允许用生物素或其他标签进一步标记或标注胞嘧啶残基。5mc的标记或标注可以使用例如点击化学或本领域技术人员已知的其他官能团/连接基团。含有m5mc的标记或标注的dna片段可以使用目前用于评估含有核酸的5mc的经修饰的方法来进行分离和/或评估。
[0110]
此外,本公开的方法和组合物可以用于向5mc引入空间上大的基团。dna模板链上的大基团的存在将干扰通过dna聚合酶或rna聚合酶合成核酸链,或干扰通过限制性核酸内切酶对dna的有效切割或抑制含有5mc的核酸的其他酶修饰。结果,可以进行引物延伸或其他试验,例如以评估特定长度的部分延伸的引物并且修饰位点可以通过对部分延伸的引物进行测序显示。也考虑了利用这种化学标记方法的其他方法。
[0111]
某些实施方案针对用于在核酸中修饰5hmc、检测5hmc和/或评估5hmc的方法和组合物。在某些方面,5hm是糖基化的。在进一步方面,5hmc与标记或经稀释的葡萄糖部分连接。在某些方面,靶核酸与β
‑
葡糖基转移酶和包含经修饰或可修饰葡萄糖部分的udp基质接
触。使用本文所述的方法,可以通过葡萄糖修饰将各种各样的可检测的基团(生物素、荧光标签放射性基团等)与5hmc连接。2011年4月6日提交的pct申请pct/us2011/031370中描述了方法和组合物,其再次通过引用整体并入。
[0112]
5hmc的修饰可以使用酶β
‑
葡糖基转移酶(βgt)或类似的酶来进行,所述酶催化了葡萄糖部分从尿苷二磷酸葡萄糖转移到5hmc的羟基,从而产生β
‑
糖基
‑5‑
羟甲基胞嘧啶(ghmc)。发明人已经发现这种酶糖化提供了用于合并经修饰的葡萄糖分子,以标记或标注真核核酸中的5hmc的策略。例如,经化学修饰以含有叠氮(n3)基的葡萄糖分子可以通过这种酶催化的糖基化共价连接到5hmc。然后,膦活化试剂包括但不限于生物素
‑
膦、荧光团
‑
膦和nhs
‑
膦或其它亲和标签可以通过与叠氮化物的反应特异性地安装在糖基化的5hmc上。
[0113]
5mc和/或5hmc可以直接或间接用若干官能团或标记的分子进行修饰。一个实例是5mc的氧化,并且随后用官能化或标记的葡萄糖分子进行标记。在某些实施方案中,可以在通过葡糖基部分的连接进行进一步修饰之前,首先用修饰部分或官能团进行修饰5mc。
[0114]
在另外的实施方案中,官能化或标记的葡萄糖分子可与βgt结合使用,以修饰例如dna或rna的核酸聚合物中的5hmc。在某些方面,βgt udp基质包含官能化或标记的葡萄糖部分。
[0115]
在另外方面,修饰部分可以使用点击化学或本领域已知的其他偶联化学进行修饰或官能化。点击化学是由k.barry sharpless在2001年引入的一种化学哲学(kolb等人,2001;evans,2007),描述了通过连接小单元快速且可靠地生成物质的化学。
[0116]
发明人表示,官能团(如叠氮基),可以使用本文所述的方法并入dna。官能团的这种合并允许用生物素或其他标签进一步标记或标注胞嘧啶残基。5hmc的标记或标注可以使用例如点击化学或本领域技术人员已知的其他官能团/连接基团。标记或标注的含有5hmc的dna片段可以使用目前用于评估含有5mc的核酸的经修饰的方法来进行分离和/或评估。
[0117]
在某些方面,可以评估两种或多于两种样本之间的核酸的差异修饰。包括心脏、肝、肺、肾、肌肉、睾丸、脾和大脑的研究表明,在正常条件下,5hmc主要在正常脑细胞中。评估和比较5hmc水平可用于评估各种疾病状态和比较各种核酸样本。
[0118]
d.tet蛋白
[0119]
十
‑
十一易位(tet)蛋白是dna羟化酶家族,已经发现其对胞嘧啶(5
‑
甲基胞嘧啶[5mc])5位上的甲基具有酶活性。tet蛋白家族包括三个成员:tet1、tet2和tet3。tet蛋白被认为能够通过三个连续的氧化反应使5mc转化为5
‑
羟甲基胞嘧啶(5hmc)、5
‑
甲酰基胞嘧啶(5fc)和5
‑
羧基胞嘧啶(5cac)。
[0120]
et家族蛋白的第一成员,即tet1基因,在急性髓细胞白血病(aml)中首次检测到,其作为组蛋白h3 lys 4(h3k4)甲基转移酶mll(混合谱系白血病)的融合伴侣(ono等人,2002年;lorsbach等人,2003年)。首次发现人的tet1蛋白具有酶活性,其能够使5mc羟基化生成5hmc(tahirani等人,2009年)。随后,已证明小鼠tet蛋白家族的所有成员(tet 1
‑
3)具有5mc羟化酶活性(ito等人,2010年)。
[0121]
tet蛋白通常具有几个保守结构域,包括对聚集的未甲基化cpg二核苷酸具有高亲和力的cxxc锌指结构域、铁(ii)
‑
和2
‑
氧代戊二酸(2og)依赖的双加氧酶典型的催化结构域、以及富含半胱氨酸的区域(wu和zhang,2011年,tahiliani等人,2009年)。
[0122]
在一些实施方案中,预期tet1、tet2或tet3是人或小鼠蛋白。人的tet1的编号为
nm_030625.2;人的tet2的编号为nm_001127208.2,或者nm_017628.4;人的tet3的编号为nm_144993.1。小鼠tet1的编号为nm_027384.1;小鼠tet2的编号为nm_001040400.2;小鼠tet3的编号为nm_183138.2。
[0123]
e.β
‑
糖基转移酶(β
‑
gt)
[0124]
葡糖基
‑
dna
‑
β
‑
葡糖基转移酶(ec 2.4.1.28,β
‑
糖基转移酶(β
‑
gt))是催化化学反应的酶,其中β
‑
d
‑
葡糖基残基从udp
‑
葡萄糖转移至核酸中的葡糖基羟甲基胞嘧啶残基。这种酶在这方面类似dnaβ
‑
葡糖基转移酶。这种酶属于糖基转移酶家族,特别是己糖基转移酶。这种酶类的系统名称为udp
‑
葡萄糖:d
‑
葡糖基
‑
dna
‑
β
‑
d
‑
葡糖基转移酶。常用的其他名称包括t6
‑
葡糖基
‑
hmc
‑
β
‑
葡糖基转移酶、t6
‑
β
‑
葡糖基转移酶、尿苷二磷酸葡萄糖
‑
葡糖基脱氧核糖核酸和β
‑
葡糖基转移酶。
[0125]
在某些方面,β
‑
葡糖基转移酶是his标签融合蛋白,其具有氨基酸序列(β
‑
gt始于第25位氨基酸(met)):
[0126][0127]
f.官能团
[0128]
核酸,尤其是胞嘧啶和/或经修饰的胞嘧啶可以直接或间接用若干官能团或标记的分子进行修饰。一个实例是5mc的氧化,并且随后用官能化的、保护剂或标记的葡萄糖分子进行标记。在某些实施方案中,可以在通过葡糖基部分的连接进行进一步修饰之前,首先用修饰部分或官能团进行修饰5mc。
[0129]
在另外的实施方案中,官能化或标记的葡萄糖分子可与βgt结合使用,以修饰例如dna或rna的核酸聚合物中的5hmc。在某些方面,βgt udp基质包含官能化或标记的葡萄糖部分。
[0130]
在另外方面,修饰部分可以使用点击化学或本领域已知的其他偶联化学进行修饰或官能化。点击化学是由k.barry sharpless在2001年引入的一种化学哲学(kolb等人,2001;evans,2007),描述了通过连接小单元快速且可靠地生成物质的化学。
[0131]
引起共价连接的化学反应包括例如环加成反应(例如diels
‑
alder反应、1,3
‑
偶极环加成huisgen反应和类似的“点击反应”)、缩合、亲核和亲电加成反应、亲核和亲电取代、加成和消除反应、烷基化反应、重排反应和任何其它涉及官能团的已知的有机反应。
[0132]
官能团的代表性的实例包括但不限于酰卤、醛、烷氧基、炔烃、酰胺、胺、芳氧基、叠氮化物、氮丙啶、偶氮、氨基甲酸酯、羰基、羧基、羧酸酯、氰基、二烯、亲二烯体、环氧基、胍、鸟嘌呤基、卤化物、酰肼、肼、羟基、羟胺、亚氨基、异氰酸酯、硝基、磷酸盐、膦酸酯、亚磺酰基、磺酰胺、磺酸盐、硫代烷氧基、硫代芳氧基、硫代氨基甲酸酯、硫代羰基、硫代羟基、硫脲和脲,因为这些术语在下文中定义。
[0133]
与本文所述的另一种官能团化学互补的示例性第一和第二官能团包括但不限于形成酯键的羟基和羧酸;形成硫酯键的硫醇和羧酸;形成酰胺键的胺和羧酸;形成席夫碱(亚胺键)的醛和胺、肼、酰肼、羟胺、苯肼、氨基脲或氨基硫脲;烯烃和二烯,它们通过环加成反应在它们之间反应;和可以参与点击反应的官能团。
[0134]
能够与另一种官能团反应的官能团对的进一步实例包括叠氮化物和炔烃、不饱和碳
‑
碳键(例如丙烯酸酯、甲基丙烯酸酯、马来酰亚胺)和硫醇、不饱和碳
‑
碳键和胺、羧酸和胺、羟基和异氰酸酯、羧酸和异氰酸酯、胺和异氰酸酯、硫醇和异氰酸酯。另外的实例包括胺、羟基、硫醇或羧酸以及亲核离去基团(例如羟基丁二酰亚胺、卤素)。
[0135]
在一些实施方案中,官能团可以是潜在基团,其在化学反应过程中暴露,使得一旦潜在基团暴露,就产生反应(例如,共价键的形成)。示例性的这种基团包括但不限于如上文描述的官能团,其用在选定反应条件下不稳定的保护基团来保护。
[0136]
不稳定保护基团的实例包括例如羧酸酯,其可以通过暴露于酸性或碱性条件而水解形成醇和羧酸;甲硅烷基醚,例如三烷基甲硅烷基醚,其可通过酸或氟离子水解为醇;p
‑
甲氧基苄基醚,其可以例如通过氧化条件或酸性条件水解为醇;叔丁氧羰基和9
‑
芴甲氧羰基,它们可以通过暴露于碱性条件下水解为胺;磺酰胺,其可通过暴露于合适的试剂如碘化钐或三丁氢化基锡而水解为磺酸盐和胺;缩醛和缩酮,它们可以通过暴露于酸性条件下分别水解形成醛或酮,以及醇或二醇;酰基(即其中碳原子连接到两个羧酸酯基团上),其可以例如通过暴露于路易斯酸而水解为酮的醛;原酸酯(即其中碳原子与三个烷氧基或芳氧基连接),其可以通过暴露于弱酸性条件下水解为羧酸酯(其可以如上所述进一步水解);2
‑
氰乙基磷酸酯,其通过暴露于温和的碱性条件下可转化为磷酸酯;甲基磷酸酯,其可通过暴露于强亲核试剂而水解成磷酸酯;磷酸酯,其可以例如通过暴露于磷酸酶而水解为醇;以及醛,其可以例如通过暴露于氧化剂而转化为羧酸。
[0137]
根据本发明的一些实施方案,两种官能团(第一和第二官能团)之间的键形成反应的结果是形成了连接基团。
[0138]
根据本发明的一些实施方案,如本文所述的第一和第二官能团之间形成的示例性连接部分包括但不限于酰胺、内酯、内酰胺、羧酸酯(酯)、环烯烃(例如环己烯)、杂双环、杂芳基、三嗪、三唑、二硫化物、亚胺、醛亚胺、酮亚胺、腙、缩氨基脲等。下文定义了其他连接部分。
[0139]
例如,二烯官能团和亲二烯官能团之间的反应,例如diels
‑
alde反应,将形成环烯连接部分,并且在大多数情况下是环己烯连接部分。在另一个实例中,在与羧基官能团反应时,胺官能团将形成酰胺连接部分。在另一个实例中,在与羧基官能团反应时,羟基官能团将形成酯连接部分。在另一个实例中,当在氧化条件下与另一种巯基官能团反应时,巯基官能团将形成二硫化物(
‑‑
s
‑‑
s
‑‑
)连接部分,或当与卤素官能团或另一个离去官能团反应时,形成硫醚(硫代烷氧基)连接部分。反应时,形成硫醚(硫烷氧基)连接部分。在另一个实例中,当通过“点击化学”与叠氮官能团反应时,炔基官能团将形成三唑连接部分。
[0140]
所述“点击反应”,也称“点击化学”,是经常用于描述叠氮化物和炔烃的huisgen 1,3
‑
偶极环加成生成1,2,3
‑
三唑的逐步变体的名称。该反应在环境条件下或在温和的微波辐射下进行,通常在cu(i)催化剂存在下进行,并且当由催化量的cu(i)盐介导时,对1,4
‑
二取代三唑产物具有排他性的区域选择性(v.rostovtsev,l.g.green,v.v.fokin,
k.b.sharpless,angew.chem.int.ed.2002,41,2596;h.c.kolb,m.finn,k.b.sharpless,angew chem.int.2001,40,2004)。
[0141]“点击反应”特别适用于本发明的实施方案的上下文中,因为它可以在不破坏dna分子的条件下进行,并且它可以在含水介质中,使用温和条件以高化学产率将标记剂附着到dna分子中的5hmc上。该反应的选择性允许在最大程度减少或取消使用保护基团的情况下进行反应,该使用经常导致多步繁琐的合成过程。
[0142]
g.dna的转座子标记
[0143]
在某些情况下,核酸用转座子进行标记。例如,核酸分子可以与转座子和转座酶接触以使转座子非特异整合到核酸分子中。
[0144]
如全文使用的,术语转座子是指含有通过转座酶或整合酶形成复合物所必需的核苷酸序列的双链dna,所述转座酶或整合酶在体外转座反应中起作用。转座子形成复合物或突触复合物或转座体复合物。转座子还可以与转座酶或整合酶形成转座体组合物,所述转座酶或整合酶识别并结合到转座子序列,并且其复合物能够插入或转座到靶dna中,在体外转座反应中与靶dna一起孵育。
[0145]
用转座子标记核酸分子还可以包括使标记的dna片段化。在一些实施方案中,转座酶可以用于催化寡核苷酸以高密度(例如,以约每300个碱基对)整合到靶核酸中。例如,转座酶例如nextera's transposome
tm
技术,可以用于生成随机的dsdna破坏。transposome
tm
复合物包含自由转座子末端和转座酶。当该复合物与dsdna一起孵育时,dna被片段化并且转座子末端寡核苷酸的转移链与dna片段的末端共价连接。在一些实施方案中,它连接到3’末端。在一些实施方案中,它连接到5’末端。在一些应用中,转座子末端可以附加引物位点。通过改变缓冲液和反应条件(例如,transposome
tm
复合物的浓度),可以控制片段化和标记的dna文库的尺寸分布。
[0146]
在一些实施方案中,转座子还包含标记或亲和标签,例如生物素。其他亲和标签包括电子标签、flag标签、ha标签、his标签、myc标签等。在一些实施方案中,亲和标签连接到p7衔接子的末端。在一些实施方案中,亲和标签连接到衔接子的5’末端。
[0147]
iii.测序方法
[0148]
a.大规模平行信号测序(mpss)。
[0149]
下一代测序技术中的第一个,大规模平行信号测序(或mpss),于20世纪90年代在lynx therapeutics开发。mpss是基于珠的方法,其使用了衔接子连接,然后进行衔接子解码,以四个核苷酸的增量读取序列的复杂方法。这种方法使其易受序列特异性偏倚或特异性序列丢失的影响。因为技术如此复杂,mpss只能通过lynx therapeutics“内部”进行,并且没有dna测序机器出售给独立实验室。在2004年,lynx therapeutic与solexa(后来被illumina收购)合并,导致了合成测序的发展,即从manteia predictive medicine获得的简单方法,这使mpss被淘汰。然而,mpss输出的基本特性是后来的“下一代”数据类型的典型特征,包括成千上万个短dna序列。在mpss的情况下,这些通常用于cdna测序,以测量基因表达水平。事实上,强大的illumina hiseq2000、hiseq2500和miseq系统都基于mpss。
[0150]
b.聚合酶克隆测序。
[0151]
在哈佛的george m.church的实验室开发的聚合酶克隆测序方法,是第一个下一代测序系统之一,并且在2005年用于全基因组测序。它将体外配对标签文库与乳液pcr、自
动显微镜和基于连接的测序化学组合,以>99.9999%的准确度对大肠杆菌基因组进行测序,成本约为sanger测序的1/9。该技术被授权给agencourt biosciences,随后被分拆为agencourt个人基因组学,并最终被整合到applied biosystems solid平台中,该平台现在由life technologies所有。
[0152]
c.454焦磷酸测序。
[0153]
454life sciences开发了焦磷酸测序的并行版本,之后该公司被roche diagnostics收购。该方法在油溶液中扩增水滴内的dna(乳液pcr),其中每个水滴含有连接到单个引物覆盖的珠的dna模板,然后形成克隆菌落。测序机器含有许多许多微微升体积的孔,每个孔含有单个珠和测序酶。焦磷酸测序使用荧光素酶以生成用于检测添加到新生dna中的单个分子的光,并且使用组合数据以生成序列读值。与一端为sange测序、另一端为solexa和solid测序相比,该技术提供了中间读取长度和每碱基价格。
[0154]
d.illumina(solexa)测序。
[0155]
solexa,现在是llumina的一部分,开发了一种基于可逆染料终止子技术和工程聚合酶的测序方法,其在内部开发。终止化学是在solexa内部开发的,solexa系统的概念是由剑桥大学化学系的balasubramanian和klennerman发明的。在2004年,solexa收购了公司manteia predictive medicine以获得基于“dna簇”的大规模并行测序技术,该技术涉及dna在表面的克隆扩增。簇技术是与加利福尼亚的lynx therapeutics共同收购的。solexa ltd.后来与lynx合并,成立了solexa inc.。
[0156]
用这方式,dna分子和引物首先附着在载玻片上,并用聚合酶扩增,从而形成局部克隆dna集落,其后来被称为“dna簇”。为了测定序列,加入了四种可逆终止子碱基(rt
‑
碱基)并且洗去了未合并的核苷酸。摄影机拍下了荧光标记的核苷酸的图像,然后将燃料与末端3’阻断剂从dna中化学去除,从而允许下一个周期开始。与焦磷酸测序不同,dna链一次延伸一个核苷酸,并且可以在延迟的时刻进行图像采集,从而允许用单个摄影机拍摄的连续图像来捕获非常大的dna集落阵列。
[0157]
将酶促反应与图像捕获分离可实现最佳处理量和理论上无限制的测序能力。利用最佳配置,最终可达到的仪器处理量仅由摄影机的模拟数字转换速率决定,乘以摄影机数量,并除以最佳地可视化它们(约10个像素/集落)所需的每个dna集落的像素数。在2012年,随着摄影机以超过10mhz a/d的转换速率运行和可用的光学、流体学和酶学,处理量可以是每秒100万个核苷酸的倍数,大致相当于每小时每台仪器覆盖1倍的一个人类基因组,以及重新测序的一个人基因组每台仪器(配有单个摄影机)每天(大约30倍)。
[0158]
e.solid测序
[0159]
applied biosystems(现在是life technologies brand)的solid技术通过连接进行测序。在这里,根据经测序的位置来标记所有可能的固定长度寡核苷酸的池。使寡核苷酸退火并连接;通过用于匹配序列的dna连接酶的优先连接造成了在该位置的核苷酸的信号信息。在测序前,通过乳液pcr扩增dna。将每个都含有相同dna分子的单一复制的所得到的珠沉积在载玻片上。结果是与illumina测序相当的数量和长度序列。据报道,这种通过连接法进行的测序在对回文序列进行测序时存在一些问题。
[0160]
f.ion torrent半导体测序。
[0161]
ion torrent systems inc.(现在为life technologies所有)开发了基于使用标
准测序化学的系统,但采用了基于半导体的新型检测系统。与其他测序系统中使用的光学方法相反,这种测序方法基于对dna聚合过程中释放的氢离子的检测。含有待测序的模板dna链的微孔充满了单个种类的核苷酸。如果引入的核苷酸与主导模板核苷酸互补,则其被并入生长互补链。这导致了氢离子的释放,其触发超敏感离子传感器,这表明已发生反应。如果如果模板序列中存在均聚物重复序列,则将在单个周期中引入多个核苷酸。这导致相应数量释放的氢和按比例更高的电子信号。
[0162]
g.dna纳米球测序。
[0163]
dna纳米球测序是一种高通量测序技术,用于测定生物体的全基因组序列。complete genomics公司使用这种技术来对独立研究人员提交的样本进行测序。该方法使用滚环式复制以使基因组dna的小片段扩增为dna纳米球。然后,使用通过连接进行的未束缚的测序来确定核苷酸序列。相比于其他下一代测序平台,这种dna测序方法使每次运行中以低试剂成本对大量dna纳米球进行测序。然而,只能从dna纳米球中测定dna短序列,所述纳米球使短读取映射到参考基因组变得困难。该技术已用于多个基因组测序项目,并计划用于更多项目。
[0164]
h.heliscope单分子测序。
[0165]
heliscope测序是由helicos biosciences开发的单分子测序方法。它使用带有添加了聚a尾衔接子的dna片段,这些衔接子连接到流动细胞表面。下面的步骤涉及基于延伸的测序,利用荧光标记的核苷酸对流动细胞进行循环洗涤(一次一种核苷酸类型,与sanger方法相同)。由heliscope测序仪进行读取。该读取是短的,最高为每次运行55个碱基,但是最近的改进允许更精确地读取一种类型的核苷酸的延伸。这种测序方法和设备用于对m13噬菌体的基因组进行测序。
[0166]
i.单分子实时(smrt)测序。
[0167]
(smrt)测序基于基于合成测序的方法。dna在零模式波导(zmw)——类似于孔的捕获工具位于孔底的小容器中合成。使用经修饰的聚合酶(连接到zmw底部)和在溶液中自由流动的荧光标记的核苷酸来进行测序。用只能检测孔底出现的荧光的方法来构建孔。荧光标记在并掺入dna链时与核苷酸分离,留下未经修饰的dna链。根据pacific biosciences,smrt技术开发人,该技术允许检测核苷酸修饰(例如胞嘧啶甲基化)。这通过观察聚合酶动力学而发生。这种方法允许读取20000个核苷酸或多于20000个核苷酸,其中平均读取长度为5千碱基。
[0168]
iv.使用方法
[0169]
a.dna甲基化变体的鉴定
[0170]
随着多种胞嘧啶变体的鉴定,dna甲基化分析领域最近有所扩展。传统的dna甲基化涉及将甲基转移到胞嘧啶的碳5位置以产生5
‑
甲基胞嘧啶(5mc)。然而,研究表明,胞嘧啶氧化酶的tet家族涉及将5
‑
甲基胞嘧啶氧化为5
‑
羟甲基胞嘧啶(5hmc)、5
‑
甲酰胞嘧啶(5fc)和5
‑
羧基胞嘧啶(5cac)。
[0171]5‑
甲酰胞嘧啶(5fc)是当tet酶作用于5
‑
羟甲基胞嘧啶时产生的dna变体的其中之一。进一步通过tet酶氧化5
‑
甲酰胞嘧啶将造成5
‑
羧基胞嘧啶的转换。据信通过不同的dna甲基化变体氧化5
‑
甲基胞嘧啶代表了dna去甲基化机制,并且据信该去甲基化途径在发展和生殖细胞编程过程中有用。5
‑
甲酰胞嘧啶存在于小鼠胚胎干(es)细胞和主要的小鼠器官
中。该dna修饰还出现在受精后的亲代原核中,伴随5
‑
甲基胞嘧啶的消失,表明了其参与了dna去甲基化过程。
[0172]5‑
羧基胞嘧啶(5cac)鉴定为在tet酶氧化5
‑
羟甲基胞嘧啶和之后的5
‑
甲酰胞嘧啶时产生的dna甲基化变体的其中之一。据信5
‑
甲基胞嘧啶氧化为5
‑
羧基胞嘧啶代表了dna去甲基化机制,并且据信该去甲基化途径在发展和生殖细胞编程过程中有用。建议通过胸腺嘧啶dna糖基化酶(tdg)将5cac从基因组dna中分离,这使胞嘧啶残基回到其未经修饰的状态。已在小鼠胚胎干(es)细胞中鉴定了5
‑
羧基胞嘧啶。该dna修饰出现在受精后的亲代原核中,伴随5
‑
甲基胞嘧啶的消失,进一步支持了该变体是dna去甲基化途径的一部分。
[0173]5‑
甲基胞嘧啶(5mc)是来自s
‑
腺苷甲硫胺酸(也称为adomet或sam)的甲基转移到胞嘧啶残基的碳5位置上产生的dna修饰。该转移由dna甲基转移酶催化(dnmt)。5
‑
甲基胞嘧啶是最常见和广泛研究的dna甲基化形式。它通常发生在cpg二核苷酸基序内,尽管已经在胚胎干细胞中鉴定了非cpg甲基化。
[0174]5‑
羟甲基胞嘧啶(5hmc)是通过铁依赖性脱氧酶3tet家族由于5
‑
甲基胞嘧啶(5mc)的酶促氧化而发生的dna甲基化修饰。在某些哺乳动物组织中,例如小鼠浦肯野细胞和颗粒神经元中,可以发现5
‑
羟甲基胞嘧啶的含量升高。或者,可以通过dnmt蛋白向dna胞嘧啶中加入甲醛来产生5hmc。
[0175]
已经提供了区分表观遗传修饰的其他方法。预期可以应用当前方法,并与本领域公开的其他方法结合。本领域公开的方法的实例包括美国临时专利申请第61/656924号、美国专利申请第13/095505号、美国临时专利申请61/321198号、pct申请第pct/us2011/031370号、pct申请第pct/us2012/032489号、美国临时专利申请第61/472435号、临时专利申请第61/512334号、pct申请第pct/us2014/032997号和pct申请第pct/us2018/021591号、美国出版物第20140178881号,其中每一篇通过引用整体结合于此。在一些实施方案中,当前的方法可以包括或不包括在上面引用的专利申请中所述的步骤。
[0176]
b.临床和诊断应用
[0177]
本公开的方法有利于评估用于临床和/或诊断目的的dna。某些实施方案涉及用于评估包括dna分子的样本的方法。该评估可以是特定胞嘧啶修饰的检测或测定或特定修改的差分检测或测定。
[0178]
样本可以来自活检,例如来自针吸活检、空芯针活检、真空辅助活检、切取活检、切除活检、钻取活检、刮取活检和皮肤活检。在某些实施方案中,可以通过前述任何活检方法从来自癌组织的活检获得样本。在其他实施方案中,可以从本文提供的任何组织中获得样本,所述组织包括但不限于胆囊、皮肤、心脏、肺、乳房、胰腺、肝、肌肉、肾、平滑肌、膀胱、结肠、肠、脑、前列腺、食道或甲状腺组织。或者,样本可以从任何其他来源获得,所述来源包括但不限于血液、汗液、毛囊、口腔组织、眼泪、月经、粪便或唾液。在某些方面,样本从囊液或来自肿瘤或赘生物的液体中获得。在其他实施方案中,囊肿、肿瘤或赘生物是结肠直肠的。在当前方法的某些方面中,任何医学专家例如医生、护士或医学技术人员可以获得生物样本用于测试。进一步地,生物样本无需医学专家地协助即可获得。
[0179]
样本可以包括但不限于组织、细胞或来自细胞或衍生自对象的细胞的生物材料。在一些实施方案中,样本包括游离dna。在一些实施方案中,样本包括受精卵、合子、胚泡或卵裂球。生物样本可以是细胞或组织的异质或同质群体。生物样本可以使用本领域已知的
任意方法获得,所述方法可以提供适于本文描述的分析方法的样本。样本可以通过无创方法获得,所述方法包括但不限于:刮擦皮肤或子宫颈、擦拭脸颊、收集唾液、收集尿液、收集粪便、收集月经、眼泪或精液。
[0180]
在一些实施方案中,本公开的方法可以用于发现用于疾病或状况的新型生物标志物。在一些实施方案中,本公开的方法可以在来自患者的样本上进行,以便为患者的某些疾病或状况提供预后。在一些实施方案中,本公开的方法可以在来自患者的样本上进行,以预测患者对特定治疗方法的反应。在一些实施方案中,疾病包括癌症。例如,癌症可以是胰腺癌、结肠癌、急性髓细胞白血病、肾上腺皮质癌、aids相关癌症、aids相关淋巴瘤、肛门癌、阑尾癌、星形细胞瘤、儿童期小脑或脑基底细胞癌、胆管癌、肝外膀胱癌、骨癌、骨肉瘤/恶性纤维组织细胞瘤、脑干胶质瘤、脑瘤、小脑星形细胞瘤脑肿瘤、脑星形细胞瘤/恶性胶质瘤脑肿瘤、室管膜瘤脑肿瘤、髓母细胞瘤脑肿瘤、幕上原始神经外胚层肿瘤脑肿瘤、视觉通路和下丘脑胶质瘤、乳腺癌、淋巴癌、支气管腺瘤/类癌、气管癌、伯基特淋巴瘤、类癌瘤、儿童类癌瘤、不明原发性胃肠道癌、中枢神经系统淋巴瘤、原发性小脑星形细胞瘤、儿童脑星形细胞瘤/恶性胶质瘤、儿童宫颈癌、儿童癌症、慢性淋巴细胞白血病、慢性粒细胞白血病、慢性骨髓增生性疾病、皮肤t细胞淋巴瘤、促结缔组织增生性小圆细胞瘤、子宫内膜癌、室管膜瘤、食道癌、尤因氏病、儿童性腺外生殖细胞瘤、肝外胆管癌、眼癌、眼内黑色素瘤眼癌、视网膜母细胞瘤、胆囊癌、胃部(胃)癌、胃肠道类癌、胃肠道间质瘤(gist)、生殖细胞肿瘤:颅外、性腺外或卵巢、妊娠滋养层肿瘤、脑干神经胶质瘤、神经胶质瘤、儿童脑星形细胞瘤、儿童视觉通路和下丘脑神经胶质瘤、胃类癌、毛细胞白血病、头颈癌、贲门癌、肝细胞(肝)癌、霍奇金淋巴瘤、下咽癌、下丘脑和视觉通路神经胶质瘤、儿童眼内黑色素瘤、胰岛细胞癌(内分泌胰腺)、卡波西肉瘤、肾癌(肾细胞癌)、喉癌、白血病、急性成淋巴细胞白血病(也称为淋巴细胞白血病)白血病、急性髓性(也称急性髓性白血病)白血病、慢性淋巴细胞(也称慢性淋巴细胞白血病)白血病、慢性髓性(也称慢性髓性白血病)白血病、毛细胞唇癌、口腔癌、脂肪肉瘤、肝癌原发性、、非小细胞肺癌、小细胞肺癌、淋巴瘤、艾滋病相关淋巴瘤、伯基特淋巴瘤、皮肤t细胞淋巴瘤、霍奇金淋巴瘤、非霍奇金淋巴瘤(除霍奇金淋巴瘤之外的所有淋巴瘤的旧分类)、原发性中枢神经系统淋巴瘤、waldenstrom巨球蛋白血症、骨/骨肉瘤的恶性纤维组织细胞瘤、儿童髓母细胞瘤、黑素瘤、眼内(眼)黑素瘤、默克尔细胞癌、成人恶性间皮瘤、儿童间皮瘤、转移性鳞状颈癌、口腔癌、多发性内分泌瘤形成综合征、多发性骨髓瘤/浆细胞瘤、蕈样肉芽肿病、骨髓增生异常综合征、骨髓增生异常/骨髓增生性疾病、慢性骨髓性白血病、成人急性髓性白血病、儿童急性髓性白血病、多发性骨髓瘤、慢性骨髓增生性疾病、鼻腔和副鼻窦癌、鼻咽癌、成神经细胞瘤、口癌、口咽癌、骨肉瘤/恶性、骨纤维组织细胞瘤、卵巢癌、卵巢上皮癌(表面上皮
‑
基质瘤)、卵巢生殖细胞瘤、卵巢低恶性潜能瘤、胰腺癌、胰岛细胞副鼻窦和鼻腔癌、甲状旁腺癌、阴茎癌、咽癌、嗜铬细胞瘤、松果体星形细胞瘤、松果体生殖细胞瘤、松果体母细胞瘤和幕上原始神经外胚层肿瘤、儿童垂体腺瘤、浆细胞瘤/多发性骨髓瘤、胸膜肺母细胞瘤、原发性中枢神经系统淋巴瘤、前列腺癌、直肠癌、肾细胞癌(肾癌)、肾盂输尿管移行细胞癌、视网膜母细胞瘤、横纹肌肉瘤、儿童唾液腺癌肉瘤、尤文氏肿瘤家族、卡波西肉瘤、软组织肉瘤、子宫塞扎里综合征肉瘤、皮肤癌(非黑色素瘤)、皮肤癌(黑色素瘤)、皮肤癌鳞状颈癌伴隐匿性原发性、转移性胃癌、幕上原始神经外胚层肿瘤、儿童t细胞淋巴瘤、睾丸癌、喉癌、胸腺瘤、儿童胸腺瘤、胸腺癌、甲状腺癌、尿道癌、子宫癌、子
宫内膜肉瘤、阴道癌、视觉通路和下丘脑神经胶质瘤、儿童外阴癌和肾母细胞瘤(肾癌)。
[0181]
在一些实施方案中,癌症包括卵巢癌、前列腺癌、结肠癌或肺癌。在一些实施方案中,方法用于使用本公开的方法通过评估游离dna来测定卵巢癌、前列腺癌、结肠癌或肺癌的新型生物标志物。在一些实施方案中,本公开的方法可用于分离自怀孕女性的胎儿dna。在一些实施方案中,本公开的方法可使用分离自怀孕女性的胎儿dna以用于产前诊断。在一些实施方案中,本公开的方法可用于评估受精胚胎如合子或胚泡,用于确定胚胎质量或特定疾病标志物的存在或不存在。
[0182]
v.试剂盒
[0183]
本发明任选地提供用于执行本发明的方法的试剂盒。试剂盒的内容可以包括整个本公开所述的一种或多于一种试剂和/或本领域已知的一种或多于一种试剂,用于执行整个本公开所述的一个或多于一个步骤。例如,试剂盒可以包括一个或多于一个以下物质:连接酶缓冲液、连接酶、t4连接酶、扩增酶、无核酸酶水、一种或多于一种引物、spri珠、交联剂、聚乙二醇、磁珠、dna聚合酶、taq聚合酶、dntp、dna聚合酶缓冲液、二价阳离子、单价阳离子、亚硫酸氢盐、亚硫酸氢钠、rna聚合酶、dtt、氧化还原试剂、mg2+、k+、衔接子、dna衔接子、包括rna启动子的dna、与本文所述的dna模板互补和/或能够退火(至少部分退火)的引物、蛋白酶、ntp、氧化剂、加双氧酶、包含羟胺基团、肼基团或酰肼基团的化合物、包含胺基、3’末端封闭分子、逆转录酶、葡萄糖或经修饰的葡萄糖和/或β
‑
葡糖基转移酶的化合物。
[0184]
试剂盒可以包括5mc或5hmc修饰剂或试剂例如tet、gt、修饰基序等。
[0185]
一种或多于一种试剂优选以适于库存储存的固体形式或液体缓冲剂提供,并且随后在进行使用试剂的方法时添加到反应介质中。提供合适的包装。试剂盒可以任选地提供在过程中有用的另外的组分。这些任选的组分包括缓冲液、捕获试剂、显影剂、标签、反应表面、检测手段、对照样本、说明和解释信息。
[0186]
每个试剂盒还可以包括另外的组分,其可用于扩增核酸、或对核酸进行测序或本文所述的本公开的其他应用。试剂盒可以任选地提供在过程中有用的另外的组分。这些任选的组分包括缓冲液、捕获试剂、显影剂、标签、反应表面、检测手段、对照样本、说明和解释信息。
[0187]
vi.实施例
[0188]
以下实施例是为了说明本发明的各种实施方案的目的提供的,不打算以任何方式限制本发明。本领域技术人员将容易地理解本发明很适合于实现目的并获得所提及的终点和优势,以及其中固有的那些目的、终点和优势。本实施例与本文描述的方法目前是某些实施方案的代表,作为实施例提供,且不旨在作为本发明的范围的限制。本领域技术人员会想到被包含在如权利要求书的范围所限定的本发明的精神内的其中的变化和其他用途。
[0189]
实施例1:用于游离dna癌症检测的线性扩增亚硫酸氢盐测序
[0190]
已知外周血中的游离dna(cfdna)来自细胞的凋亡与坏死。1在癌症患者中,除了造血谱系细胞外,它还贡献于肿瘤细胞和特定组织细胞。流入血流的这些肿瘤细胞片段能够追踪细胞来源并为其成为实体肿瘤的微创液体活检标志物提供了可能性。2此外,可重复对cfdna进行采样和监测,且不受组织活检中肿瘤内异质性的影响。这些优势,加上更高的患者依从性和临床便利性,使cfdna有可能在癌症的筛查、诊断和预后方面取得重大进展。
3,4
[0191]
除了检测点突变或拷贝数量变化(cnv),
2,5,6
表观遗传标记如dna甲基化可以以互
补和有价值的方式作用。dna甲基化5mc是化学稳定的、丰度较高的表观遗传修饰,长期以来被认为可调节基因表达。在肿瘤发生中,启动子的高甲基化会导致肿瘤抑制基因的沉默;同样地,癌基因的低甲基化可以促进疾病的发展。7‑9异常甲基化特征可能是早期甚至癌前病变最敏感和最早的指标。
[0192]
最近的研究使用wgbs、rrbs、mcta和mip
‑
seq结合随机森林、逻辑回归和构建概率模型等算法来探索cfdna中潜在的甲基化标记。
5,10
‑
14
然而,当处理珍贵的超低输入临床样本时,敏感性障碍和广泛的dna降解可能导致有用地读取急剧受限、数据质量差以及测序成本高。全基因组扩增(wga)可以使微量的cfdna扩增到大规模。mda(多重置换扩增),广泛使用的超支化链置换指数扩增wga技术,可以提供几乎完全的基因组覆盖度,但是它以指数的方式显示不可避免的偏倚和误差累积。另外,扩增片段化的dna时的低效率使其无法作用于cfdna。
17,18
相反,发明人在体外转录中标记了t7,因为线性扩增不仅具有全基因组的均匀覆盖,而且还展示比mda更少的扩增偏倚。更重要的是,它可以理想地将cfdna片段有效地整合以克服液体活检研究中的障碍。
19
[0193]
为了从本文的稀有临床样本中可靠地获得稳健且准确的碱基分辨率信息,发明人开发了用于亚纳克液体活组织检查材料的基于bs
‑
seq(labs
‑
seq)的t7线性扩增。labs
‑
seq可从cfdna片段的5
’‑
至3
’‑
末端或至bs损伤的切刻碱基(bs damaged nicking base)线性地产生rna转录物的多个复制,提供甲基化组信息更大程度的保存、5mc状态的准确呈现和更均匀的全基因组扩增。展现了更好的cpg和基因组覆盖的方法应用至结肠癌cfdna标记鉴定和组织来源分析。
[0194]
a.结果
[0195]
1.labs
‑
seq策略的设计
[0196]
为了在亚硫酸氢盐转换后使t7扩增,发明人首先将完全甲基化的t7衔接子(用5mc替换了所有c)连接至dna片段的两端,然后使连接产物进行亚硫酸氢盐(bs)转换(图1a)。衔接子结合了t7 rna聚合酶的启动子序列和3
’‑
末端封闭的短辅助序列,以形成辅助连接的部分双链dna结构。在亚硫酸氢盐(bs)处理过程中,c转化为u,而保留了5mc并以这种方法t7启动子序列保持完整。然后使用互补的t7引物并使启动子区域退火以启动体外转录。由于体外转录的无偏线性扩增,微量的dna片段可以均匀地扩增成多个rna复制。最后,这些有效量的rna产物进行逆转录,然后进行用于测序的文库构建。
[0197]
2.labs
‑
seq表现的评估
[0198]
本发明评估了e14tg2a小鼠胚胎干细胞(esc)基因组dna(gdna)上的labs
‑
seq。分别起始于100ng、10ng、1ng、100pg gdna的mesc文库通过illumina nextseq 500se75进行测序,并且对labs
‑
seq与其他两种可商购获得的wgbs
‑
seq方法,即methylc
‑
seq(pre
‑
bs)和epignome(post
‑
bs)进行系统比较。发明人进一步以相同的方法进行了50pg、20pg、10pg mesc文库的生物复制,以研究labs
‑
seq的技术局限性。
[0199]
每个文库可获得约2千万至4千万个单末端读取。发明人获得了所有cpg二核苷酸的甲基化cpg%,平均相当于所有cpg的42.7%。labs
‑
seq文库的映射效率为60.3
±
2.4%(图1b),并且随着输入材料的减少,该比例没有下降,甚至降低到10pg也没有下降。更重要的是,1ng和100pg labs
‑
seq文库的复制水平分别为7.7
±
0.5%和11.3
±
2.8%,而epignome和methylc
‑
seq文库的相应水平极高(82.8%至98.5%)。为了避免不同测序深度
的比较偏倚,发明人对每个样本的1500万个读值进行了下采样,用于进一步分析。比较基因组覆盖度、cpg覆盖度和染色体覆盖度,与其他方法(图1c和图7)相比,对于labs
‑
seq,随着减少的输入而导致覆盖的减少显著变慢。另外,随着多个rna转录物(称为多重读)覆盖的cpg位点数量的增加,ivt扩增获得了每个cpg特别是低输入材料的更精确的甲基化状态。在100pg文库的分析中,labs
‑
seq获得了至少300倍以上的5x读值覆盖的cpg(图8)。而且,更深的测序可以获得更多的cpg,因为饱和图甚至在100pg lab
‑
seq文库中也没有达到稳定水平(图2a)。
[0200]
接下来,发明人检测了labs
‑
seq的准确性。chg和chh(0.6%至0.9%)的总体甲基化水平表明在所有labs
‑
seq中的转化率高于99%。发明人按照进一步合并来自methyc
‑
seq和epigenome的100ng和10ng的文库作为大量参考,并与labs
‑
seq产生的文库进行比较。观察到高关联系数(皮尔逊r=0.88),表明该方法高度准确(图1e)。虽然在输入材料从100ng减少到100pg的情况下,methylc
‑
seq和epigenome文库的覆盖度明显下降,但即使输入50pg,labs
‑
seq文库也显示出类似的情况(图1d)。使用有限输入的10pg的库,发明人仍然可以识别出比100pg常规库中更多的cpg。所有这些结果表明labs
‑
seq可以提供低至亚纳克的敏感甲基化组信息。发明人进一步测试了单个cpg的再现性。观察到复制之间的高再现性,皮尔逊r为0.92至0.84。系数轻微下降是由于输入dna材料从10ng降低至50pg。
[0201]
3.测序偏好的分析和均匀扩增
[0202]
wgbs中的测序偏倚可以来自不完全的bs转换、pcr扩增和文库策略。该偏倚可能影响甲基化水平的准确估计,并导致相对差异失真。
20
为了评估可能的测序偏倚,发明人绘制了所有三种文库中不同gc含量的基因组箱中的标准化覆盖度。使用两种商业方案观察到各种偏倚的gc谱:methylc
‑
seq和epigenome文库分别在at富集和gc富集区域显示了显著增长的覆盖度,但在相反的gc富集和at富集的区域缺乏展示。相反,labs
‑
seq文库在极端区域(gc<20%并且>70%)展示出较少的gc偏倚和中等覆盖度(图2b),这可能受益于带有很少碱基偏好的全基因组的均匀线性扩增。发明人还研究了映射读值的链成分,以检查ivt是否涉及链偏倚:labs
‑
seq具有与其他两种方法类似的负链和正链百分比,不显示链偏倚(图1b)。
[0203]
进一步地,发明人应用lorenz曲线评估labs
‑
seq的均匀性。黑色对角线表示完美的覆盖均匀性,而理想对角线的偏离表示偏倚的读取分布(图2c)。发明人分别比较了0.1ng至1ng、由labs
‑
seq构建的wgbs文库和其他两种pre
‑
bs和post
‑
bs方法的曲线。证明了labs
‑
seq在整个基因组中表现出最好的均匀性。
[0204]
4.labs
‑
seq文库中mesc的甲基化特征
[0205]
在三种方案下的文库的甲基化组特征在不同方面几乎相同。发明人首先绘制了三种方法展现的各种基因组特征上的甲基化密度(图3a)。发明人观察到从上游到转录起始位点(tss)的3kb显著减少,然后在5’utr区域甲基化的局部消耗,并且在外显子、内含子、3’utr和下游区域的密度恢复到上游3kb(~40%)的类似水平。另外,一致地,本发明人通过在不同的组蛋白修饰特征上检查甲基化率,发现激活组蛋白标记h3k4me3处的甲基化显著下降和抑制标记h3k9me3处的甲基化增加(图3b)。然后,发明人研究了跨不同基因组背景的cpg计数(图3c),这也显示了三种方法之间的优越的一致性。然而,值得注意的是,50pg labs
‑
seq文库显示出与使用20倍gdna材料的其他文库相似或甚至更好的各种背景的覆盖度。log2富集评分进一步说明了上文的标准化读取(图9),其中三个方案在3'utr、外显子、
启动子、5'utr和cpg岛区域显示了一致的偏好。发明人还使用了跨基因组的chromhmm染色质状态以定量三种方法的不同覆盖度偏倚。epigenome方法优先注释状态1、2和4(分别为活性启动子、强增强子和转录/转换),而labs
‑
seq优先注释状态2和4。当输入材料降至100pg时,labs
‑
seq文库在不同状态间保持相当的趋势,并且提供的注释性信息多于epigenome和methylc
‑
seq。
[0206]
5.使用labs
‑
seq对cfdna中的5mc进行全基因组映射。
[0207]
由于labs
‑
seq在有限输入的构建文库中表现优异,发明人在混合的无癌血浆cfdna上测试了labs
‑
seq。如上比较epignome和methylc
‑
seq方案(图10)。labs
‑
seq在基因组覆盖、cpg覆盖和复制水平方面显示出压倒性的优势。然后发明人将该方法应用至患者cfdna样本。涉及了15名患者,包括6名健康患者、6名结肠癌患者和3名胰腺癌患者。
[0208]
6.癌症cfdna的全基因组低/高甲基化
[0209]
因为在许多癌症类型中发现总体甲基化变化,所以研究了全基因组低/高甲基化。发明人检查了全基因组5的每个1
‑
mb箱(总共2734个箱,不包括性染色体)中的甲基化密度(md)。所有健康人在每个箱中显示出相对稳定的水平,而crc和pan在相应的箱之间显示出高度变化。在crc和pan cfdna中,md>3sd与健康cfdna的平均数不同的箱数分别为177
±
83.6和108
±
19.2。发明人测定了患者的cfdna高度变异化特征的百分比(图4a)。这些高度变异特征的注释显示出它们大部分位于基因间和内含子区域,同时它还显示出启动子的高度富集。功能富集分析发现,近轴间充质细胞在crc衍生的低/高甲基化箱(fdr=5.36e
‑
6)中高度富集,这与间充质细胞在结肠癌中的重要作用一致。如果采集更多的样本,发明人可以通过利用相对较低的测序深度,基于全基因组低/高甲基化来有效区分癌症患者。
[0210]
7.dmr作为分类生物标志物
[0211]
为了检查labs
‑
seq数据是否可以导致差异性甲基化区域(dmr)的发现,发明人使用1
‑
kb的箱比较不同患者组,并发现109个在crc和健康人之间显著差异甲基化(图5a)。这些dmr分布在全基因组(图5b,不包括性染色体和线粒体)。在它们之间,crc组中47个dmr是低甲基化的,62个dmr为高甲基化的。发明人还观察到crc特异性低甲基化dmr在重复区域例如line和sine中特别富集,而crc特异的高dmr在与基因表达调节相关的启动子和外显子区域富集,表明健康的和crc患者之间的5mc谱差异很大,其可以揭示癌症相关的生物功能。所有这些结果表明该方法可以给出稳健的5mc基因组分析并揭示患者组之间合理的5mc差异。
[0212]
为了进一步评估这些dmr的分类效果,发明人使用层次聚类聚集了不同组的特征(图5c)。通过无监督聚类,可以以敏感(6/6crc)和特异(6/6健康)两种方式直接且完全分离两个患者组。发明人还在dmr特征上进行了pca分析,并注意到不同患者可以容易地基于疾病分类进行分组(图5d)。在crc和健康组之间的dmr中,发明人获得了一些潜在的crc标记基因,例如ccr9(趋化因子受体9,与crc侵袭和转移相关)、brd4(含结构域的蛋白4,其经常在结肠癌中异常甲基化)、lgal9(在crc患者中高度甲基化的肿瘤抑制基因)和irf1(在多种癌中已知的肿瘤抑制物并且可以诱导肿瘤细胞凋亡)。
[0213]
cea(癌胚抗原)21是在临床上有用的crc血液标志物(参考范围0ng/ml至3.4ng/ml)。患者crc5、crc4和crc6的cea血清测试结果分别为1.7ng/ml、4.5ng/ml和88.2ng/ml。在dmr聚类和pca中,三类患者全部自然地分类为癌症。表明了labs
‑
seq方法发现的dmr标志物可以是一种比cea或其他蛋白血清标志物更敏感的指标。crc1是ssa/息肉患者,为高风险癌
前期病变,并且crc1被分进crc组。它显示了在高风险癌前期病变的早期筛查中应用5mc cfdna的可能性。如果过程患者中有更多的癌前/癌症,发明人可以分别获得癌前疾病和癌症的5mc标志物。
[0214]
8.组织来源去卷积
[0215]
cfdna可以被认为是衍生自不同组织和大量造血细胞的dna的混合物。虽然不同组织类型实际上具有相同dna序列,但5mc甲基化谱高度特异。
14
使用展现出在其它组织中可忽略或较小比例的组织特异的5mc特征,发明人可以通过去卷积算法获得不同组织的混合比例,追踪组织来源,并且具有预测特定癌症的潜力。
10,13,22
[0216]
以这种方法,发明人重新分析了由roadmap项目(在genboree.org/epigenomeatlas/index.rhtml的万维网上找到)和另外两项研究生成的14个组织的公共wgbs数据。
23,24
通过将其中一个组织与其余组织进行比较,总共发现了5823个显著的dmr。然后将这些dmr用作去卷积的标志物。作为概念证明,发明人发现嗜中性粒细胞占据了几乎所有cfdna样本中最重要的部分(图6a,健康中的45%至68%;crc中的20%至62%),这与以前的研究一致。
22
发明人注意到,crc组中的嗜中性粒细胞百分比显示出显著下降,同时结肠的贡献增加(图6c)。四种crc患者(4/6)在cfdna种的结肠组织比例为3.1%至25%,但在健康组中的贡献无法检测。该结果支持了使用dna甲基化特征用于癌症类型预测的概念。通过将全基因组高/低甲基化检测与组织来源去卷积结合,发明人不仅可以检测癌症,还可以预测实体肿瘤的位置。
[0217]
b.讨论
[0218]
labs
‑
seq是第一个基于全基因组扩增的液体活检wgbs
‑
seq方法。使用labs
‑
seq技术,发明人对结肠癌患者的5mc信号进行了全面的研究。与健康人相比,该患者显示了在血浆cfdna中显著的dna甲基化异常。尽管只有6/6的crc/健康人参与dmr的无监督聚类和标志物鉴定,但发明人获得了更精细的标志物,如ccr9和brd4,以及完全有把握的聚类。在crc中,发明人发现癌前期的样本被分进crc组。这表明cfdna dna甲基化在早期筛查中可能是有用的,特别是在癌前病变中,其不够大以至于无法检测到或在成像中不确定。由于cfdna是来自不同来源的dna片段的平衡,因此它能够提供人体的全dna甲基化图片。最重要的是,不同类型的癌症显示出差异很大的甲基化特征,因此可以实现组织来源预测,并基于甲基化特征的检测增强实体肿瘤检测。在未来的工作中,为了充分利用labs
‑
seq,可以利用纵向监测以辅助肿瘤治疗,针对原发性实体肿瘤和转移性病变的独特cfdna特征。
[0219]
除血液外,该技术还可作用于包括但不限于尿液、脑脊液(csf)和房水cfdna,据报告其dna片段具有比血液中的dna片段更小的尺寸或更低的浓度。lab
‑
seq还可用于单细胞研究。使用转座酶或核酸酶等使单细胞gdna片段化之后,该技术可以用于将几微微克的材料扩增至纳克。它为研究人员提供了有力且准确的工具以利用对癌症和胚胎发育的深入了解,观察循环肿瘤细胞、细胞异质性和胚胎中整个基因组的表观遗传学变化。
[0220]
c.方法
[0221]
1.患者招募和血浆样本
[0222]
研究共招募了6位结肠癌患者、3位胰腺癌患者、6位健康人。
[0223]
在切除恶性肿瘤前,收集结肠癌患者的血液。切除病变后,外科病理学证实了诊断。胰腺癌患者的血液。健康人是指接受常规健康检查,无恶性或恶性前期疾病的患者。在
repair&a
‑
tailling buffer)和0.6μl末端修复&a
‑
尾酶混合物(end repair&a
‑
tailling enzyme mix)进行混合,在20℃下孵育30分钟,在65℃下孵育30分钟。接下来,加入1μl国产t7衔接子、1μl h2o、6μl连接缓冲液和2μl dna连接酶并在20℃下孵育4小时或在4℃下过夜。在使用1.4x ampure xp珠进行连接后的清理后,对其进行亚硫酸氢盐处理。将10μl h2o中的亚硫酸氢盐转化的dna与3μl 5x epimark buffer、0.3ul10μm t7引物(agccccgcgaaattaatacgactcactataggg(seq id no:3),idt用hplc纯化)、0.3μl 10mm dntp(neb,n0447s)、0.3μl epimark hot start taq dna聚合酶(neb,m0490s)和1.1μl无核酸酶h2o进行混合。t7引物退火和延伸在95℃下进行60秒,在59℃进行60秒,在68℃进行5分钟,在4℃下保持。然后,加入1μl 0.85mg/ml qiagen蛋白酶并在50℃下孵育2小时,然后再75℃下热灭活30分钟。用22μl h2o稀释t7标记的dsdna片段,并与60μl t7反应预混合物(neb hiscribe
tm
t7高产rna合成试剂盒e2040s、1x t7反应缓冲液、10μl rna聚合酶混合物、10mm atp/gtp/utp/ctp)和0.4u/μl superase in rnase抑制剂(life technologies,am2694)混合。该反应在37℃下进行12小时至16小时。
[0237]
在t7体外转录过夜后,在室温下将dnase i和消化缓冲液加入摘要dna模板20分钟,然后通过rnaclean&concentrator kit(zymo research,r1013)纯化rna转录物并在15μl h2o中洗脱。通过qubit 2.0rna hs assay kit(life technologies,q32855)对dna产量进行定量。大部分100ng rna用于文库构建(kapa biosystems,kapa rna hyperprep kit,kk8540)。按照制造商的方案,将10μl h2o中的rna与10μl 2x片段、引物和洗脱缓冲液混合。在65℃下将反应加热1分钟并在冰上终止反应。通过加入10μl反应混合物(缓冲液和kapa转录酶)启动第一链合成,并在25℃下进行10分钟,在42℃下进行15分钟,在70℃下进行15分钟,在4℃下保持。向反应中加入30μl第二链合成和a尾,并在16℃下孵育30分钟,在62℃下孵育10分钟,在4℃下保持。然后,将illumina衔接子在20℃下连接15分钟。在使用kapa pure bead进行两轮连接后的清理后,洗脱经pcr扩增(在98℃下30秒;针对以下进行10个至12个循环,在98℃下15秒,在60℃下30秒,在72℃下45秒;在72℃下1分钟),并提供1x ampure xp bead进行纯化。最后,使用nextseq 500sr80对文库进行测序。
[0238]
8.数据处理和分析
[0239]
通过trim galore首先对原始测序读值进行修整,以去除测序衔接子和低质量的核苷酸。然后将bismark用于将修整过的读值分别映射到mm9和hg19参照基因组。通过bismark包中的包装脚本进行进一步的重复删除和mc调用。cpg背景中的胞嘧啶残基进一步用于下游分析。samtool和bedtool用于区间相关的计算。通过picard package定量cg偏倚。通过deeptool计算元基因谱。
[0240]
9.cfdna的全基因组低/高甲基化
[0241]
为了定量患者的cfdna样本中的总体dna低甲基化和高甲基化,发明人将全基因组分为连续的1
‑
mb箱并计算每个箱的甲基化密度。将甲基化密度定义为甲基化的胞嘧啶数除以每个箱中cpg背景的胞嘧啶总数。计算健康样本中甲基化密度的平均数和变化并用z评分法确定某些样本是否正常。任何z评分大于3或小于
‑
3的箱被认为使高甲基化或低甲基化的,并用作癌症的潜在特征。rcircos包用于进一步的全基因组可视化。
[0242]
10.dmr分析
[0243]
通过分析methylki包下游无监督聚类的差异甲基化区域(dmr)的特征选择。基于
spring harbor perspectives in biology 8,a019372(2016).
[0259]
10.guo,s.et al.identification of methylation haplotype blocks aids in deconvolution of heterogeneous tissue samples and tumor tissue
‑
of
‑
origin mapping from plasma dna.nature genetics 49,635(2017).
[0260]
11.wen,l.et al.genome
‑
scale detection of hypermethylated cpg islands in circulating cell
‑
free dna of hepatocellular carcinoma patients.cell research 25,1250(2015).
[0261]
12.xu,r.
‑
h.et al.circulating tumour dna methylation markers for diagnosis and prognosis of hepatocellular carcinoma.nature materials 16,1155(2017).
[0262]
13.kang,s.et al.cancerlocator:non
‑
invasive cancer diagnosis and tissue
‑
of
‑
origin prediction using methylation profiles of cell
‑
free dna.genome biology 18,53(2017).
[0263]
14.feng,h.,jin,p.&wu,h.disease prediction by cell
‑
free dna methylation.briefings in bioinformatics.
[0264]
15.dean,f.b.et al.comprehensive human genome amplification using multiple displacement amplification.proceedings of the national academy of sciences 99,5261
‑
5266(2002).
[0265]
16.spits,c.et al.whole
‑
genome multiple displacement amplification from single cells.nature protocols 1,1965(2006).
[0266]
17.lage,j.m.et al.whole genome analysis of genetic alterations in small dna samples using hyperbranched strand displacement amplification and array
‑
cgh.genome research 13,294
‑
307(2003).
[0267]
18.gawad.c.,koh,w.&quake,s.r.single
‑
cell genome sequencing:current state of the science.nature reviews genetics 17,175(2016).
[0268]
19.chen,c.et al.single
‑
cell whole
‑
genome analyses by linear amplification via transposon insertion(lianti).science 356,189
‑
194(2017).
[0269]
20.olova,n.et al.comparison of whole
‑
genome bisulfite sequencing library preparation strategies identifies sources of biases affecting dna methylation data.genome biology 19,33(2018).
[0270]
21.fakih,m.g.&padmanabhan,a.cea monitoring in colorectal cancer.oncology
‑
williston park then huntington the melville new york
‑
20,579(2006).
[0271]
22.sun,k.et al.plasma dna tissue mapping by genome
‑
wide methylation sequencing for noninvasive prenatal,cancer,and transplantation assessments.proceedings of the national academy of sciences 112,e5503
‑
e5512(2015).
[0272]
23.lun.f.m.et al.noninvasive prenatal methylomic analysis by genomewide bisulfite sequencing of maternal plasma dna.clinical chemistry 59,
1583
‑
1594(2013).
[0273]
24.hodges,e.et al.directional dna methylation changes and complex intermediate states accompany lineage specificity in the adult hematopoietic compartment.molecular cell 44,17
‑
28(2011).
[0274]
25.smallwood,s.a.et al.single
‑
cell genome
‑
wide bisulfite sequencing for assessing epigenetic heterogeneity.nature methods 11,817
‑
820(2014).
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1