人类α半乳糖苷酶变体的制作方法
人类
α
半乳糖苷酶变体
1.本技术要求2018年12月20日提交的美国临时申请序列第62/782,553号的优先权,该美国临时申请为了所有目的在此通过引用以其整体并入。
发明领域
2.本发明提供了工程化人类α半乳糖苷酶多肽及其组合物。该工程化人类α半乳糖苷酶多肽已经被优化,以提供提高的热稳定性、血清稳定性、降低的免疫原性、提高的细胞摄取、和在酸性(ph<4)和碱性(ph>7)条件下的稳定性以及改进的球形三酰神经酰胺(globotriaosylceramide)从细胞中的清除。本发明还涉及包含该工程化人类α半乳糖苷酶多肽的组合物用于治疗目的的用途。
3.对序列表、表格或计算机程序的引用
4.序列表的正式副本作为ascii格式的文本文件经由efs
‑
web与说明书同时提交,文件名为“cx7
‑
184wo2_st25.txt”,创建日期为2019年12月19日,且大小为1.67兆字节。经由efs
‑
web提交的序列表是说明书的一部分并且通过引用以其整体并入本文。
5.发明背景
6.人类α半乳糖苷酶(“gla”;ec 3.2.1.22)是一种溶酶体糖蛋白,负责从糖脂和糖蛋白水解末端α半乳糖基部分。人类α半乳糖苷酶作用于一系列人体组织中存在的许多底物。法布里病(fabry disease)(也称为弥漫性体部血管角化瘤、安德森
‑
法布里病(anderson
‑
fabry disease)、遗传性异位性脂质沉积症、α半乳糖苷酶a缺乏症、gla缺乏症和球形三酰神经酰胺酶缺乏症)是一种由α半乳糖苷酶a缺乏或缺乏活性导致的鞘糖脂分解代谢的x连锁的先天性错误。罹患法布里病的患者的血管、组织和器官中的血浆和细胞溶酶体中积累球形三酰神经酰胺(本文中称为“gb
3”和“gb3”)和相关鞘糖脂(参见例如,nance等人,arch.neurol.,63:453
‑
457[2006])。随着患者年龄增长,由于这些脂质的积累,血管逐渐变窄,导致到达组织(特别是在皮肤、肾、心脏、脑和神经系统中)的血流和营养减少。因此,法布里病是一种全身性紊乱,表现为肾衰竭、心脏病、脑血管病、小纤维周围神经病变和皮肤病灶以及其他紊乱(参见例如,schiffmann,pharman.ther.,122:65
‑
77[2009])。受影响的患者表现出诸如手和脚疼痛、患者皮肤上的深红色小斑点簇、出汗能力下降、角膜混浊、胃肠问题、耳鸣和听力损失的症状。潜在的危及生命的并发症包括进行性肾损害、心脏病发作和中风。该疾病估计影响1/40,000
‑
1/60,000的男性,但也发生于女性中。实际上,患有法布里病的杂合子女性经历严重的危及生命的状况,包括神经系统异常、慢性疼痛、疲劳、高血压、心脏病、肾衰竭和中风,因此需要药物治疗(参见例如,want等人,genet.med.,13:457
‑
484[2011])。法布里病的病征可以从婴儿期的任何时间开始,病征通常在4岁和8岁之间开始出现,尽管一些患者表现出较轻的迟发性疾病。治疗通常是支持性的,并且法布里病是无法治愈的,因此仍然存在对安全且有效的治疗的需求。
[0007]
发明概述
[0008]
本发明提供了工程化人类α半乳糖苷酶多肽及其组合物。该工程化人类α半乳糖苷酶多肽已经被优化,以提供提高的热稳定性、血清稳定性、降低的免疫原性、提高的细胞摄
取、和在酸性(ph<4)和碱性(ph>7)条件下的稳定性以及改进的球形三酰神经酰胺(globotriaosylceramide)从细胞中的清除。本发明还涉及包含该工程化人类α半乳糖苷酶多肽的组合物用于治疗目的的用途。
[0009]
本发明提供了重组α半乳糖苷酶a和/或生物活性重组α半乳糖苷酶a片段,其包含含有与seq id no:8的至少约70%、至少约75%、至少约80%、至少约85%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%或至少约99%序列同一性的氨基酸序列。本发明提供了重组α半乳糖苷酶a和/或生物活性重组α半乳糖苷酶a片段,其包含含有与seq id no:8的至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%或至少99%序列同一性的氨基酸序列。
[0010]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:44、44/217、44/217/316、44/217/322、44/217/322/337、44/247、44/247/302、44/247/302/322、44/247/322、44/247/337、44/247/362、44/302、44/337、44/373、217/322、217/373、247/322、247/362、302/322/362/373、302/337、316、316/337、322、322/337、362/373和373,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:44l、44l/217f、44l/217f/316l、44l/217f/322m、44l/217f/322m/337a、44l/247n、44l/247n/302q、44l/247n/302q/322m、44l/247n/322m、44l/247n/337a、44l/247n/362k、44l/302q、44l/337a、44l/373r、217f/322m、217f/373r、247n/322m、247n/362k、302q/322m/362k/373r、302q/337a、316l、316l/337a、322m、322m/337a、362k/373r和373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:r44l、r44l/r217f、r44l/r217f/d316l、r44l/r217f/i322m、r44l/r217f/i322m/p337a、r44l/d247n、r44l/d247n/k302q、r44l/d247n/k302q/i322m、r44l/d247n/i322m、r44l/d247n/p337a、r44l/d247n/q362k、r44l/k302q、r44l/p337a、r44l/k373r、r217f/i322m、r217f/k373r、d247n/i322m、d247n/q362k、k302q/i322m/q362k/k373r、k302q/p337a、d316l、d316l/p337a、i322m、i322m/p337a、q362k/k373r和k373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。
[0011]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10/39/44/47/92/166/206/217/247/261/271/302/316/322/337/362/368/373/392、44/217/316、44/217/322/
337、166/362、217/373和362/373,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10t/39m/44l/47s/92y/166s/206k/217f/247n/261a/271h/302q/316l/322m/337a/362k/368w/373r/392m、44l/217f/316l、44l/217f/322m/337a、166a/362k、217f/373r和362k/373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:p10t/e39m/r44l/t47s/h92y/p166s/a206k/r217f/d247n/g261a/a271h/k302q/d316l/i322m/p337a/q362k/a368w/k373r/t392m、r44l/r217f/d316l、r44l/r217f/i322m/p337a、p166a/q362k、r217f/k373r和q362k/k373r,其中所述多肽序列的氨基酸位置参考seqid no:8来编号。
[0012]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:7、7/48/68、7/48/68/120/282/299、7/48/130/282、7/48/180、7/68/130/282/365、7/68/180、7/88/120/305/365、7/120、7/130、7/282、7/305、7/305/365、7/365、39、47、47/87/95/96/158/162、47/95、47/273、47/343、48、48/68、48/180/282、48/282、48/282/305、67/180、68、68/299/300、71、87/91/95/96/158/162、87/91/95/96/206/343、87/96/155/273/343、88、91/95、91/95/96、92、93、96、96/273、96/312/343、120、120/299/305、151、158、158/162/273、162、162/273、162/343、166、178、180、181、206、217、271、273、273/343、282、282/365、293/391、299/300、299/300/305/365、300、301、305、305/365、314、333、336、337、343、345、363、365、370、389、393、394、396/398、397和398,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:7l、7l/48d/68e、7l/48d/68e/120h/282n/299r、7l/48d/130e/282n、7l/48d/180g、7l/68e/130e/282n/365v、7l/68e/180g、7l/88a/120h/305g/365v、7l/120h、7l/130e、7l/282n、7l/305g、7l/305g/365v、7l/365v、39v、47d、47d/87k/95e/96l/158r/162h、47d/95e、47d/273p、47d/343g、47v、48d、48d/68e、48d/180g/282n、48d/282n、48d/282n/305g、67t/180g、68e、68e/299r/300i、71p、87k/91q/95e/96l/158a/162k、87k/91q/95e/96l/206s/343g、87k/96i/155n/273p/343g、88a、91q/95e、91q/95e/96l、92f、92t、93i、96l、96l/273p、96l/312q/343g、120h、120h/299r/305g、151l、158a、158a/162k/273g、158r、162h/343d、162k、162k/273p、162s、166k、178g、178s、180g、180l、180t、180v、181a、206k、206s、217k、271r、273p、273p/343g、282n、282n/365v、293p/391a、299r/300i、299r/300i/305g/365v、300i、301m、305g、305g/365v、314a、333f、333g、336v、
337r、343d、343g、345a、345q、363q、365a、365q、365v、370g、389k、393v、394k、396g/398t、397a、398a、398p、398s和398v,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:r7l、r7l/e48d/q68e、r7l/e48d/q68e/y120h/d282n/q299r、r7l/e48d/d130e/d282n、r7l/e48d/f180g、r7l/q68e/d130e/d282n/f365v、r7l/q68e/f180g、r7l/q88a/y120h/n305g/f365v、r7l/y120h、r7l/d130e、r7l/d282n、r7l/n305g、r7l/n305g/f365v、r7l/f365v、e39v、t47d、t47d/r87k/s95e/k96l/l158r/r162h、t47d/s95e、t47d/s273p、t47d/k343g、t47v、e48d、e48d/q68e、e48d/f180g/d282n、e48d/d282n、e48d/d282n/n305g、p67t/f180g、q68e、q68e/q299r/l300i、s71p、r87k/n91q/s95e/k96l/l158a/r162k、r87k/n91q/s95e/k96l/a206s/k343g、r87k/k96i/h155n/s273p/k343g、q88a、n91q/s95e、n91q/s95e/k96l、h92f、h92t、v93i、k96l、k96l/s273p、k96l/p312q/k343g、y120h、y120h/q299r/n305g、d151l、l158a、l158a/r162k/s273g、l158r、r162h/k343d、r162k、r162k/s273p、r162s、p166k、w178g、w178s、f180g、f180l、f180t、f180v、q181a、a206k、a206s、r217k、a271r、s273p、s273p/k343g、d282n、d282n/f365v、l293p/q391a、q299r/l300i、q299r/l300i/n305g/f365v、l300i、r301m、n305g、n305g/f365v、s314a、s333f、s333g、i336v、p337r、k343d、k343g、v345a、v345q、l363q、f365a、f365q、f365v、s370g、t389k、s393v、l394k、d396g/l398t、l397a、l398a、l398p、l398s和l398v,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。
[0013]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:24/202、39/47、39/47/217、39/151、39/282/337/398、39/337/343/398、39/393/398、47/130、47/151、47/343/345/393、48、48/68、48/68/217/333/391/393、48/68/333、48/217、48/333、48/345/393、48/393、59/143、68、68/345、130、130/158、130/158/393、130/345/393、143/271、143/333、143/387、151、151/158/217/343/345/393、151/206/282/337/343/345/398、151/282/393、151/345/393/398、151/393、158、158/393、202、206、206/217、217、217/333、217/337/345/398、271、282/393、333、333/345、337/343/345/398、343、343/345/393/398、393和393/398,其中所述多肽序列的氨基酸位置参考seqid no:158来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seqid no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:24s/202n、39v/47d、39v/47v/217k、39v/151l、39v/282n/337r/398a、39v/337r/343g/398a、39v/393v/398a、47v/130e、47v/151l、47v/343d/345q/393v、48d、48d/68e、48d/68e/217k/333f/391a/393v、48d/68e/333f、48d/217k、48d/333f、48d/333g、48d/345q/393v、48d/393v、59a/143s、68e、68e/345q、130e、130e/158r、130e/158r/393v、130e/345q/393v、143s/271n、143s/333n、143s/387n、151l、151l/158r/217k/343g/345q/393v、151l/206s/282n/
337r/343d/345q/398a、151l/282n/393v、151l/345q/393v/398a、151l/393v、158r、158r/393v、202n、206s、206s/217k、217k、217k/333f、217k/333g、217k/337r/345q/398a、271n、282n/393v、333f/345q、333g、333n、337r/343g/345q/398a、343d、343d/345q/393v/398a、393v和393v/398a,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:d24s/d202n、e39v/t47d、e39v/t47v/r217k、e39v/d151l、e39v/d282n/p337r/l398a、e39v/p337r/k343g/l398a、e39v/s393v/l398a、t47v/d130e、t47v/d151l、t47v/k343d/v345q/s393v、e48d、e48d/q68e、e48d/q68e/r217k/s333f/q391a/s393v、e48d/q68e/s333f、e48d/r217k、e48d/s333f、e48d/s333g、e48d/v345q/s393v、e48d/s393v、c59a/c143s、q68e、q68e/v345q、d130e、d130e/l158r、d130e/l158r/s393v、d130e/v345q/s393v、c143s/a271n、c143s/s333n、c143s/e387n、d151l、d151l/l158r/r217k/k343g/v345q/s393v、d151l/a206s/d282n/p337r/k343d/v345q/l398a、d151l/d282n/s393v、d151l/v345q/s393v/l398a、d151l/s393v、l158r、l158r/s393v、d202n、a206s、a206s/r217k、r217k、r217k/s333f、r217k/s333g、r217k/p337r/v345q/l398a、a271n、d282n/s393v、s333f/v345q、s333g、s333n、p337r/k343g/v345q/l398a、k343d、k343d/v345q/s393v/l398a、s393v和s393v/l398a,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。
[0014]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10、10/39/44/322、10/39/92/206/217/271、10/39/92/247、10/39/92/247/271/316、10/44、10/44/47/92/247、10/44/47/261/302/322/368、10/44/92/316/322、10/44/261/302/316、10/44/302/337/368、10/47/217/247/316/392、10/47/217/322、10/47/271、10/92、10/92/206/217/247、10/92/206/247/316/322/392、10/92/206/247/322/368、10/92/217/261/302/337、10/206/217/271、10/206/247、10/206/261/271/316、10/261、10/271/302、10/302、10/302/316、10/302/322/337、10/316/322、10/337/392、10/368、39/44/92/162/247/302/316/322、39/44/92/217/322、39/44/92/247/271/302、39/47/92/247/302/316/322、39/47/217/247/368、39/47/247、39/92/247/302/316/337/368、39/92/316/322、39/247/271、39/247/271/316、39/322、44/47/92/206/217/316/322、44/47/92/247/261/271/316/337/368、44/47/206/217/247/271/322、44/47/247/322/368、44/47/302/316/322、44/92/206/247/368、44/206/337、44/247/261/302/316、44/247/261/302/316/322、47/92/247/271、47/217/302、47/247、47/247/271、89/217/247/261/302/316、92/217/271、92/247、92/247/271/322、92/247/302/322/337、92/271/337、92/302、92/316、206/217/271/392、217/247/316/322/337/368、247、247/271、247/302、271、271/302/322、271/316/322、302/322/368和368,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重
组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10p、10p/39e/44r/322i、10p/39e/92h/206a/217r/271a、10p/39e/92h/247d、10p/39e/92h/247d/271a/316d、10p/44r、10p/44r/47t/92h/247d、10p/44r/47t/261g/302k/322i/368a、10p/44r/92h/316d/322i、10p/44r/261g/302k/316d、10p/44r/302k/337p/368a、10p/47t/217r/247d/316d/392t、10p/47t/217r/322i、10p/47t/271a、10p/92h、10p/92h/206a/217r/247d、10p/92h/206a/247d/316d/322i/392t、10p/92h/206a/247d/322i/368a、10p/92h/217r/261g/302k/337p、10p/206a/217r/271a、10p/206a/247d、10p/206a/261g/271a/316d、10p/261g、10p/271a/302k、10p/302k、10p/302k/316d、10p/302k/322i/337p、10p/316d/322i、10p/337p/392t、10p/368a、39e/44r/92h/162m/247d/302k/316d/322i、39e/44r/92h/217r/322i、39e/44r/92h/247d/271a/302k、39e/47t/92h/247d/302k/316d/322i、39e/47t/217r/247d/368a、39e/47t/247d、39e/92h/247d/302k/316d/337p/368a、39e/92h/316d/322i、39e/247d/271a、39e/247d/271a/316d、39e/322i、44r/47t/92h/206a/217r/316d/322i、44r/47t/92h/247d/261g/271a/316d/337p/368a、44r/47t/206a/217r/247d/271a/322i、44r/47t/247d/322i/368a、44r/47t/302k/316d/322i、44r/92h/206a/247d/368a、44r/206a/337p、44r/247d/261g/302k/316d、44r/247d/261g/302k/316d/322i、47t/92h/247d/271a、47t/217r/302k、47t/247d、47t/247d/271a、89i/217r/247d/261g/302k/316d、92h/217r/271a、92h/247d、92h/247d/271a/322i、92h/247d/302k/322i/337p、92h/271a/337p、92h/302k、92h/316d、206a/217r/271a/392t、217r/247d/316d/322i/337p/368a、247d、247d/271a、247d/302k、271a、271a/302k/322i、271a/316d/322i、302k/322i/368a和368a,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:t10p、t10p/m39e/l44r/m322i、t10p/m39e/y92h/k206a/f217r/h271a、t10p/m39e/y92h/n247d、t10p/m39e/y92h/n247d/h271a/l316d、t10p/l44r、t10p/l44r/s47t/y92h/n247d、t10p/l44r/s47t/a261g/q302k/m322i/w368a、t10p/l44r/y92h/l316d/m322i、t10p/l44r/a261g/q302k/l316d、t10p/l44r/q302k/a337p/w368a、t10p/s47t/f217r/n247d/l316d/m392t、t10p/s47t/f217r/m322i、t10p/s47t/h271a、t10p/y92h、t10p/y92h/k206a/f217r/n247d、t10p/y92h/k206a/n247d/l316d/m322i/m392t、t10p/y92h/k206a/n247d/m322i/w368a、t10p/y92h/f217r/a261g/q302k/a337p、t10p/k206a/f217r/h271a、t10p/k206a/n247d、t10p/k206a/a261g/h271a/l316d、t10p/a261g、t10p/h271a/q302k、t10p/q302k、t10p/q302k/l316d、t10p/q302k/m322i/a337p、t10p/l316d/m322i、t10p/a337p/m392t、t10p/w368a、m39e/l44r/y92h/r162m/n247d/q302k/l316d/m322i、m39e/l44r/y92h/f217r/m322i、m39e/l44r/y92h/n247d/h271a/q302k、m39e/s47t/y92h/n247d/q302k/l316d/m322i、m39e/s47t/f217r/n247d/w368a、m39e/s47t/n247d、m39e/y92h/n247d/q302k/l316d/a337p/w368a、m39e/y92h/l316d/m322i、m39e/n247d/h271a、m39e/n247d/h271a/l316d、m39e/m322i、l44r/s47t/y92h/k206a/f217r/l316d/m322i、l44r/s47t/y92h/n247d/a261g/h271a/l316d/a337p/w368a、l44r/s47t/k206a/f217r/n247d/h271a/m322i、l44r/s47t/n247d/m322i/w368a、l44r/s47t/q302k/l316d/m322i、l44r/y92h/k206a/n247d/
w368a、l44r/k206a/a337p、l44r/n247d/a261g/q302k/l316d、l44r/n247d/a261g/q302k/l316d/m322i、s47t/y92h/n247d/h271a、s47t/f217r/q302k、s47t/n247d、s47t/n247d/h271a、l89i/f217r/n247d/a261g/q302k/l316d、y92h/f217r/h271a、y92h/n247d、y92h/n247d/h271a/m322i、y92h/n247d/q302k/m322i/a337p、y92h/h271a/a337p、y92h/q302k、y92h/l316d、k206a/f217r/h271a/m392t、f217r/n247d/l316d/m322i/a337p/w368a、n247d、n247d/h271a、n247d/q302k、h271a、h271a/q302k/m322i、h271a/l316d/m322i、q302k/m322i/w368a和w368a,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。
[0015]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10/36/92/166/247/261/316/392、10/39、10/39/44/47/92/206/217、10/39/44/47/316、10/39/44/47/337、10/39/44/92/166/261/316/322、10/39/44/92/166/302/322、10/39/44/92/166/392、10/39/44/92/217/302/322、10/39/44/92/302/322、10/39/44/166/261/271/316/322、10/39/44/392、10/39/47/92/337、10/39/92/131/166/271/316/322、10/39/92/166/217/247/271、10/39/92/217/316、10/44/47/166/261/271、10/44/47/166/271/322/368、10/44/47/217/271/316/322、10/44/92、10/44/92/217/247/271/302/316/392、10/44/166/302、10/44/206/316/322、10/47/92/166/271/316/337、10/47/92/271/302、10/47/92/316/322/392、10/47/166/271、10/47/166/316、10/92/166、10/92/166/217/247/261/271、10/92/166/261/271/392、10/92/166/261/316/322/337、10/92/166/337/368、10/92/302/337、10/92/316/322、10/206、10/206/247/261、10/217/322、10/261、10/261/337/392、10/316/392、10/368、39/44/47/92/166/206/392、39/44/47/92/206/247/261、39/44/47/92/206/392、39/44/47/206/337/368/392、39/44/92/166/247/261/302/337、39/44/166/271、39/44/166/271/337/368/392、39/47/92/316/322、39/47/92/392、39/47/166/217/261/392、39/47/217/247/368、39/47/247、39/92/166/217/392、39/92/261/302、39/166/217/261/316/368、39/322、39/392、44/47、44/47/92/217/271、44/47/92/217/316/322/392、44/47/92/392、44/47/166、44/47/166/271、44/47/247/271/392、44/316/322/392、44/337、47/166/206/217/247/337、47/166/217/271/337、47/206、47/217/247/261、47/271、52/217/302/316、92/166/206/271/316、92/166/217/261/271/392、92/166/217/316/337/392、92/166/247、92/166/316、92/206/322、92/217、92/217/271/337、92/261/271、92/271、166/217/316/322/337、166/247/271/316、166/316/322/337、206/217、217/392、247/316、316/322/368和316/337/392,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10t/36m/92y/166s/247n/261a/316l/392m、10t/39m、10t/39m/44l/47s/92y/206k/217f、10t/39m/44l/47s/316l、10t/39m/44l/47s/337a、10t/39m/44l/92y/166s/261a/316l/322m、10t/39m/44l/92y/166s/302q/322m、10t/39m/44l/92y/166s/392m、10t/39m/44l/92y/217f/302q/322m、10t/39m/44l/92y/302q/322m、10t/39m/44l/166s/261a/
271h/316l/322m、10t/39m/44l/392m、10t/39m/47s/92y/337a、10t/39m/92y/131g/166s/271h/316l/322m、10t/39m/92y/166s/217f/247n/271h、10t/39m/92y/217f/316l、10t/44l/47s/166s/261a/271h、10t/44l/47s/166s/271h/322m/368w、10t/44l/47s/217f/271h/316l/322m、10t/44l/92y、10t/44l/92y/217f/247n/271h/302q/316l/392m、10t/44l/166s/302q、10t/44l/206k/316l/322m、10t/47s/92y/166s/271h/316l/337a、10t/47s/92y/271h/302q、10t/47s/92y/316l/322m/392m、10t/47s/166s/271h、10t/47s/166s/316l、10t/92y/166s、10t/92y/166s/217f/247n/261a/271h、10t/92y/166s/261a/271h/392m、10t/92y/166s/261a/316l/322m/337a、10t/92y/166s/337a/368w、10t/92y/302q/337a、10t/92y/316l/322m、10t/206k、10t/206k/247n/261a、10t/217f/322m、10t/261a、10t/261a/337a/392m、10t/316l/392m、10t/368w、39m/44l/47s/92y/166s/206k/392m、39m/44l/47s/92y/206k/247n/261a、39m/44l/47s/92y/206k/392m、39m/44l/47s/206k/337a/368w/392m、39m/44l/92y/166s/247n/261a/302q/337a、39m/44l/166s/271h、39m/44l/166s/271h/337a/368w/392m、39m/47s/92y/316l/322m、39m/47s/92y/392m、39m/47s/166s/217f/261a/392m、39m/47s/217f/247n/368w、39m/47s/247n、39m/92y/166s/217f/392m、39m/92y/261a/302q、39m/166s/217f/261a/316l/368w、39m/322m、39m/392m、44l/47s、44l/47s/92y/217f/271h、44l/47s/92y/217f/316l/322m/392m、44l/47s/92y/392m、44l/47s/166s、44l/47s/166s/271h、44l/47s/247n/271h/392m、44l/316l/322m/392m、44l/337a、47s/166s/206k/217f/247n/337a、47s/166s/217f/271h/337a、47s/206k、47s/217f/247n/261a、47s/271h、52n/217f/302q/316l、92y/166s/206k/271h/316l、92y/166s/217f/261a/271h/392m、92y/166s/217f/316l/337a/392m、92y/166s/247n、92y/166s/316l、92y/206k/322m、92y/217f、92y/217f/271h/337a、92y/261a/271h、92y/271h、166s/217f/316l/322m/337a、166s/247n/271h/316l、166s/316l/322m/337a、206k/217f、217f/392m、247n/316l、316l/322m/368w和316l/337a/392m,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:p10t/k36m/h92y/p166s/d247n/g261a/d316l/t392m、p10t/e39m、p10t/e39m/r44l/t47s/h92y/a206k/r217f、p10t/e39m/r44l/t47s/d316l、p10t/e39m/r44l/t47s/p337a、p10t/e39m/r44l/h92y/p166s/g261a/d316l/i322m、p10t/e39m/r44l/h92y/p166s/k302q/i322m、p10t/e39m/r44l/h92y/p166s/t392m、p10t/e39m/r44l/h92y/r217f/k302q/i322m、p10t/e39m/r44l/h92y/k302q/i322m、p10t/e39m/r44l/p166s/g261a/a271h/d316l/i322m、p10t/e39m/r44l/t392m、p10t/e39m/t47s/h92y/p337a、p10t/e39m/h92y/w131g/p166s/a271h/d316l/i322m、p10t/e39m/h92y/p166s/r217f/d247n/a271h、p10t/e39m/h92y/r217f/d316l、p10t/r44l/t47s/p166s/g261a/a271h、p10t/r44l/t47s/p166s/a271h/i322m/a368w、p10t/r44l/t47s/r217f/a271h/d316l/i322m、p10t/r44l/h92y、p10t/r44l/h92y/r217f/d247n/a271h/k302q/d316l/t392m、p10t/r44l/p166s/k302q、p10t/r44l/a206k/d316l/i322m、p10t/t47s/h92y/p166s/a271h/d316l/p337a、p10t/t47s/h92y/a271h/k302q、p10t/t47s/h92y/d316l/i322m/t392m、p10t/t47s/p166s/a271h、p10t/t47s/p166s/d316l、p10t/h92y/p166s、p10t/h92y/p166s/r217f/d247n/g261a/a271h、p10t/
h92y/p166s/g261a/a271h/t392m、p10t/h92y/p166s/g261a/d316l/i322m/p337a、p10t/h92y/p166s/p337a/a368w、p10t/h92y/k302q/p337a、p10t/h92y/d316l/i322m、p10t/a206k、p10t/a206k/d247n/g261a、p10t/r217f/i322m、p10t/g261a、p10t/g261a/p337a/t392m、p10t/d316l/t392m、p10t/a368w、e39m/r44l/t47s/h92y/p166s/a206k/t392m、e39m/r44l/t47s/h92y/a206k/d247n/g261a、e39m/r44l/t47s/h92y/a206k/t392m、e39m/r44l/t47s/a206k/p337a/a368w/t392m、e39m/r44l/h92y/p166s/d247n/g261a/k302q/p337a、e39m/r44l/p166s/a271h、e39m/r44l/p166s/a271h/p337a/a368w/t392m、e39m/t47s/h92y/d316l/i322m、e39m/t47s/h92y/t392m、e39m/t47s/p166s/r217f/g261a/t392m、e39m/t47s/r217f/d247n/a368w、e39m/t47s/d247n、e39m/h92y/p166s/r217f/t392m、e39m/h92y/g261a/k302q、e39m/p166s/r217f/g261a/d316l/a368w、e39m/i322m、e39m/t392m、r44l/t47s、r44l/t47s/h92y/r217f/a271h、r44l/t47s/h92y/r217f/d316l/i322m/t392m、r44l/t47s/h92y/t392m、r44l/t47s/p166s、r44l/t47s/p166s/a271h、r44l/t47s/d247n/a271h/t392m、r44l/d316l/i322m/t392m、r44l/p337a、t47s/p166s/a206k/r217f/d247n/p337a、t47s/p166s/r217f/a271h/p337a、t47s/a206k、t47s/r217f/d247n/g261a、t47s/a271h、d52n/r217f/k302q/d316l、h92y/p166s/a206k/a271h/d316l、h92y/p166s/r217f/g261a/a271h/t392m、h92y/p166s/r217f/d316l/p337a/t392m、h92y/p166s/d247n、h92y/p166s/d316l、h92y/a206k/i322m、h92y/r217f、h92y/r217f/a271h/p337a、h92y/g261a/a271h、h92y/a271h、p166s/r217f/d316l/i322m/p337a、p166s/d247n/a271h/d316l、p166s/d316l/i322m/p337a、a206k/r217f、r217f/t392m、d247n/d316l、d316l/i322m/a368w和d316l/p337a/t392m,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。
[0016]
在一些实施方案中,本发明的α半乳糖苷酶a在表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中提供的至少一个位置中包含至少一个突变,其中位置参考seq id no:2来编号。在一些另外的实施方案中,重组α半乳糖苷酶a源自人类α半乳糖苷酶a。在一些另外的实施方案中,重组α半乳糖苷酶a包含seq id no:8、58、158、372和/或374的多肽序列。
[0017]
在一些实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a更具热稳定性。在一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a在ph 7更稳定。在又一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a在ph 4更稳定。在还一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a在ph 7更稳定且在ph 4更稳定。在还另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a对暴露于血清更稳定。在一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a更具溶酶体稳定性。在又一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a更容易被细胞摄取。在一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a从细胞中消耗更多球形三酰神经酰胺。在又一些另外的实施方案中,重组α半乳糖苷酶a与seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a相比表现出提高的细胞摄取。在一些另外的实施方案中,重组α半乳糖苷酶a比seq id no:2、8、58、158、372和/或374的α半乳糖苷酶a免疫原性更少。在一些另外的实施方案中,重组α半乳糖苷酶a与参考序列相比表现出至少一种选自以下的改进
的特性:i)催化活性增强;ii)对ph 7的耐受性增加;iii)对ph 4的耐受性增加;iv)对血清的耐受性增加;v)细胞摄取提高;vi)免疫原性降低;或vii)从细胞中消耗球形三酰神经酰胺增加;或i)、ii)、iii)、iv)、v)、vi)或vii)的任何组合。在一些实施方案中,参考序列为seq id no:2、8、58、158、372和/或374。在一些另外的实施方案中,重组α半乳糖苷酶a是纯化的。
[0018]
本发明还提供了编码至少一种本文(例如,在表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中)提供的重组α半乳糖苷酶a的重组多核苷酸序列。在一些实施方案中,多核苷酸序列选自dna、rna和mrna。
[0019]
在一些实施方案中,重组多核苷酸序列是密码子优化的。
[0020]
本发明还提供了包含编码至少一种本文(例如,表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1)提供的重组α半乳糖苷酶a的重组多核苷酸序列的表达载体。在一些实施方案中,重组多核苷酸序列可操作地连接至控制序列。在一些另外的实施方案中,控制序列是启动子。在一些另外的实施方案中,启动子是异源启动子。在一些实施方案中,表达载体还包含如本文所提供的信号序列。
[0021]
本发明还提供了包含至少一种本文提供的表达载体的宿主细胞。在一些实施方案中,宿主细胞包含表达载体,该表达载体包含编码至少一种本文(例如,表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1)提供的重组α半乳糖苷酶a的重组多核苷酸序列。在一些实施方案中,宿主细胞选自真核细胞和原核细胞。在一些实施方案中,宿主细胞为真核细胞。在一些另外的实施方案中,宿主细胞为哺乳动物细胞。
[0022]
本发明还提供了产生α半乳糖苷酶a变体的方法,该方法包括在产生由重组多核苷酸编码的α半乳糖苷酶a的条件下培养本文提供的宿主细胞。在一些实施方案中,该方法还包括回收α半乳糖苷酶a的步骤。在一些另外的实施方案中,该方法还包括纯化α半乳糖苷酶a的步骤。本发明还提供了包含至少一种本文(例如,表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1)提供的重组α半乳糖苷酶a的组合物。在一些实施方案中,本发明提供了药物组合物。在一些实施方案中,本发明提供了包含至少一种本文提供的重组多核苷酸的药物组合物。在一些另外的实施方案中,本发明提供了用于治疗法布里病的药物组合物,该药物组合物包含本文提供的酶组合物。在一些实施方案中,药物组合物还包含药学上可接受的载体和/或赋形剂。在一些另外的实施方案中,药物组合物适于向人类胃肠外注射或输注。
[0023]
本发明还提供了用于治疗和/或预防受试者的法布里病症状的方法,该方法包括提供患有法布里病的受试者,并提供至少一种药物组合物,该药物组合物包含至少一种本文(例如,表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1)提供的重组α半乳糖苷酶a,并向受试者施用该药物组合物。在一些实施方案中,受试者的法布里病症状得到改善。在一些另外的实施方案中,施用了本发明的药物组合物的受试者能够食用脂肪含量比表现出法布里病症状的受试者所需的饮食限制更少的饮食。在一些实施方案中,受试者是婴儿或儿童,而在一些可选的实施方案中,受试者是成年人或年轻成人。
[0024]
本发明还提供了本文提供的组合物的用途。
[0025]
附图简述
[0026]
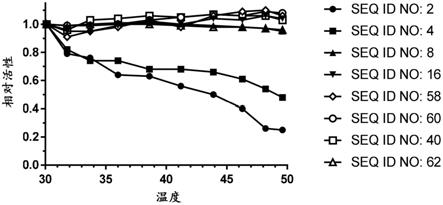
图1提供了示出在温度30
‑
50℃孵育1小时后gla变体的相对活性的图。
[0027]
图2提供了示出在37℃用人类血清挑战0
‑
24小时后gla变体的相对活性的图。
[0028]
图3提供了示出在37℃用人类溶酶体提取物挑战0
‑
24小时后gla变体的相对活性的图。
[0029]
图4提供了示出不同的纯化gla变体的细胞摄取的图,表示为在37℃与培养的法布里病患者成纤维细胞一起孵育4小时后与野生型相比的相对活性。
[0030]
图5提供了示出在施用后1周、2周和4周,与seq id no:2相比,gla变体在法布里病小鼠心脏中的活性的图。
[0031]
图6提供了示出用gla变体处理的法布里病小鼠在施用后1周和2周心脏中的残余gb3的图。
[0032]
发明描述
[0033]
本发明提供了工程化人类α半乳糖苷酶多肽及其组合物。该工程化人类α半乳糖苷酶多肽已经被优化,以提供提高的热稳定性、血清稳定性、提高的细胞摄取、以及在酸性(ph<4)和碱性(ph>7)条件下的稳定性、降低的免疫原性和改进的球形三酰神经酰胺从细胞中的去除。本发明还涉及包含该工程化人类α半乳糖苷酶多肽的组合物用于治疗目的的用途。
[0034]
在一些实施方案中,工程化人类α半乳糖苷酶多肽已经被优化以提供提高的细胞摄取,同时保持稳定性。本发明还涉及包含该工程化人类α半乳糖苷酶多肽的组合物用于治疗目的的用途。
[0035]
在一些情况下,用于治疗法布里病的酶替换疗法(例如,agalsidaseβ;genzyme)被考虑用于合格的个人。目前使用的酶替换疗法是重组表达形式的野生型人类gla。已知,静脉施用的gla循环,通过受体(主要是甘露糖6
‑
磷酸受体(m6pr))介导的内吞作用被摄取到细胞中,并运送至靶器官的内吞体/溶酶体,在内吞体/溶酶体中gla清除积累的gb3。这些药物不能完全缓解患者症状,因为神经性疼痛和短暂缺血发作以降低的比率继续发生。此外,与高度血管化且富含m6pr的肝相比,大多数靶器官对gla的摄取较差,并且该酶在血液和溶酶体的ph不稳定。因此,可用的治疗仍然存在问题。此外,患者可能会产生免疫应答(靶向所施用的药物的igg和ige抗体),并遭受严重的变态(过敏性)反应、严重的输注反应以及甚至死亡。本发明意图提供适用于治疗法布里病的更稳定且有效的酶,但与目前可用的治疗相比,具有减少的副作用和改善的结果。实际上,本发明意图提供在引入血流时酶遇到的血液(ph 7.4)中具有增加的稳定性的重组gla酶。此外,该酶在溶酶体的ph(ph 4.3)具有增加的稳定性,溶酶体是该酶在治疗过程中有活性的位置。因此,在人类hek293t细胞中重组表达的人类gla的定向演化(采用不同酶变体文库的高通量筛选)用于提供具有保持的稳定性特性、改进的球形三酰神经酰胺清除和细胞摄取的新型gla变体。在一些实施方案中,gla变体表现出降低的免疫原性。
[0036]
缩写和定义:
[0037]
除非另外定义,否则本文使用的所有技术术语和科学术语通常具有与本发明所属领域普通技术人员通常理解的相同的含义。通常,本文使用的命名法和下文描述的细胞培养、分子遗传学、微生物学、有机化学、分析化学和核酸化学中的实验程序是本领域熟知的并且普遍地采用的那些。这样的技术是熟知的,并且在本领域技术人员熟知的许多教科书和参考著作中进行了描述。对于化学合成和化学分析使用了标准技术或其修改形式。本文(上文和下文两者)提及的所有专利、专利申请、文章和出版物,在此通过引用明确并入本文。
[0038]
尽管本发明的实践中可使用与本文描述的方法和材料类似或等同的任何合适的方法和材料,但本文也描述了一些方法和材料。应理解本发明不限于所描述的特定方法、方案和试剂,因为这些可以根据本领域技术人员使用它们的情况而改变。因此,下文即将定义的术语通过参考本技术作为整体而被更充分地描述。本文(上文和下文两者)提及的所有专利、专利申请、文章和出版物,在此通过引用明确并入本文。
[0039]
此外,如本文使用的,单数“一(a)”、“一(an)”和“所述/该(the)”包括复数指示物,除非上下文另外清楚地指示。
[0040]
数值范围包括限定该范围的数字。因此,本文公开的每个数值范围意图包括落在这样的较宽数值范围内的每一较窄数值范围,如同这样的较窄数值范围在本文被全部清楚地写出。还意图本文公开的每个最大的(或最小的)数值限制包含每个较低(或较高)的数值限制,如同这样的较低(或较高)数值限制在本文被清楚地写出。
[0041]
术语“约”意指特定值的可接受误差。在一些实例中,“约”意指在给定值范围的0.05%、0.5%、1.0%或2.0%内。在一些实例中,“约”意指在给定值的1、2、3或4个标准偏差内。
[0042]
此外,本文所提供的标题不是可以通过参考本技术作为整体而获取的本发明的各个方面或实施方案的限制。因此,下文即将定义的术语通过参考本技术作为整体而被更充分地定义。尽管如此,为了便于理解本发明,许多术语定义如下。
[0043]
除非另外指示,否则,分别地,核酸以5'至3'方向从左到右书写;氨基酸序列以氨基至羧基方向从左至右书写。
[0044]
如本文使用的,术语“包括(comprising)”及其同源词以其包括性意义使用(即,等同于术语“包括(including)”及其相应的同源词)。
[0045]“ec”编号是指生物化学和分子生物学国际联合命名委员会(nomenclature committee of the international union of biochemistry and molecular biology)(nc
‑
iubmb)的酶命名法。该iubmb生化分类是基于酶催化的化学反应的酶数字分类系统。
[0046]“atcc”是指美国典型培养物保藏中心(american type culture collection),其生物保藏收集物包括基因和菌株。
[0047]“ncbi”是指美国国家生物技术信息中心(national center for biological information)和其中提供的序列数据库。
[0048]“蛋白质”、“多肽”和“肽”在本文中可互换地使用,来表示通过酰胺键共价连接的至少两个氨基酸的聚合物,而不论长度或翻译后修饰(例如糖基化或磷酸化)。
[0049]“氨基酸”通过其通常已知的三字母符号或通过iupac
‑
iub生物化学命名委员会推荐的单字母符号在本文被提及。同样地,核苷酸可以通过其通常可接受的单字母代码被提及。
[0050]
当提及细胞、多核苷酸或多肽使用时,术语“工程化”、“重组”、“非天然存在的”和“变体”是指如下材料或与该材料的天然或自然形式对应的材料:已经以自然界本来不存在的方式被修饰或与其相同但由合成材料产生或衍生和/或通过使用重组技术操作产生。
[0051]
如本文使用的,“utr”是指mrna多核苷酸的非翻译区。在一些实施方案中,“5'非翻译区”或“5'utr”被称为“前导序列”或“前导rna”。该mrna区域位于起始密码子的直接上游。在一些实施方案中,“3'非翻译区”或“3'utr”是位于终止密码子直接下游的mrna区域。在各
种生物体(例如,原核生物、真核生物和病毒)中,这两个区域对于翻译调控和细胞内转运都是重要的。
[0052]
如本文使用的,“野生型”和“天然存在的”是指在自然界中发现的形式。例如,天然存在的或野生型多肽或多核苷酸序列为生物体中存在的序列,其可以从天然来源分离且未通过人为操纵被有意地修饰。
[0053]“编码序列”是指核酸(例如基因)编码蛋白质的氨基酸序列的部分。
[0054]
术语“序列同一性百分比(%)”在本文中用于指多核苷酸和多肽之间的比较,并通过比较比较窗中两条最佳比对的序列确定,其中多核苷酸或多肽序列在比较窗中的部分与参考序列相比可以包括添加或缺失(即,空位),以用于两个序列的最佳比对。百分比可以通过如下计算:确定两个序列中出现相同核酸碱基或氨基酸残基的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并将结果乘以100以得到序列同一性百分比。可选择地,百分比可以通过如下计算:确定两个序列中出现相同的核酸碱基或氨基酸残基或者核酸碱基或氨基酸残基与空位对齐的位置的数目以产生匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并将结果乘以100以得到序列同一性的百分比。本领域技术人员理解,存在许多可用于比对两个序列的已建立的算法。用于比较的序列的最佳比对可以例如通过以下进行:通过smith和waterman的局部同源性算法(smith和waterman,adv.appl.math.,2:482[1981]),通过needleman和wunsch的同源性比对算法(needleman和wunsch,j.mol.biol.,48:443[1970]),通过pearson和lipman的相似性搜索方法(pearson和lipman,proc.natl.acad.sci.usa 85:2444[1988]),通过这些算法的计算机化实现(例如,gcg wisconsin软件包中的gap、bestfit、fasta和tfasta),或者通过目视检查,如本领域已知的。适合于确定序列同一性和序列相似性百分比的算法的实例包括但不限于blast和blast 2.0算法,由altschul等人描述(分别参见altschul等人,j.mol.biol.,215:403
‑
410[1990];和altschul等人,1977,nucleic acids res.,3389
‑
3402[1977])。公众可通过美国国家生物技术信息中心网站获得用于进行blast分析的软件。该算法包括首先通过鉴定查询序列中长度w的短字来鉴定高评分序列对(hsp),所述短字在与数据库序列中相同长度的字比对时匹配或满足某一正值的阀值评分t。t被称为邻近字评分阈值(参见,altschul等人,上文)。这些最初的邻近字击中(word hit)充当启动搜索的种子以找到包含它们的更长hsp。然后字击中沿着每个序列的两个方向延伸直到累积比对评分不能增加的程度。对于核苷酸序列,累积评分使用参数m(用于匹配残基对的奖励评分;总是>0)和n(用于错配残基的惩罚评分;总是<0)计算。对于氨基酸序列,评分矩阵用于计算累积评分。在以下情况时,停止字击中在每一个方向的延伸:累积比对评分从其最大达到值下降了量x;由于累积了一个或更多个负评分残基比对,累积得分达到0或小于0;或到达任一序列末端。blast算法参数w、t和x决定比对的灵敏度和速度。blastn程序(对于核苷酸序列)使用以下作为默认值:字长(w)为11、期望值(e)为10、m=5、n=
‑
4、以及两条链的比较。对于氨基酸序列,blastp程序使用以下作为默认值:字长(w)为3,期望(e)为10和blosum62评分矩阵(参见,henikoff和henikoff,proc.natl.acad.sci.usa 89:10915[1989])。序列比对与%序列同一性的示例性确定可以使用gcg wisconsin软件包(accelrys、madison wi)中的bestfit或gap程序,使用提供的默认参数。
[0055]“参考序列”是指用作序列比较的基础的确定序列。参考序列可以是更大序列的子
集,例如,全长基因或多肽序列的区段(segment)。通常,参考序列为至少20个核苷酸或氨基酸残基的长度、至少25个残基的长度、至少50个残基的长度、至少100个残基的长度或者核酸或多肽的全长。因为两个多核苷酸或多肽可以各自(1)包含两个序列之间相似的序列(即,完整序列的一部分),和(2)还可以包含两个序列之间不同的(divergent)序列,所以两个(或更多个)多核苷酸或多肽之间的序列比较通常通过比较两个多核苷酸或多肽在“比较窗”中的序列以鉴定和比较局部区域的序列相似性来进行。在一些实施方案中,“参考序列”可以基于一级氨基酸序列(primary amino acid sequence),其中参考序列是可以在一级序列中具有一个或更多个变化的序列。“比较窗”是指至少约20个连续核苷酸位置或氨基酸残基的概念性区段,其中序列可以与至少20个连续核苷酸或氨基酸的参考序列进行比较,并且其中序列在比较窗中的部分与参考序列(其不包含添加或缺失)相比,可以包含20%或更少的添加或缺失(即,空位)以用于两个序列的最佳比对。比较窗可以比20个连续残基更长,并任选地包括30、40、50、100或更长的窗。
[0056]
当在对给定氨基酸或多核苷酸序列进行编号的情况中使用时,“对应于”、“参考”或“相对于”是指当给定氨基酸或多核苷酸序列与参考序列相比较时对指定参考序列的残基进行编号。换言之,给定聚合物的残基编号或残基位置关于参考序列被指定,而不是通过给定氨基酸或多核苷酸序列内残基的实际数字位置被指定。例如,给定氨基酸序列,诸如工程化gla的氨基酸序列可以通过引入空位以与参考序列对齐,来优化两个序列之间的残基匹配。在这些情况中,尽管存在空位,但对给定氨基酸或多核苷酸序列中的残基关于与其比对的参考序列进行编号。
[0057]“氨基酸差异”或“残基差异”指在多肽序列的一个位置处氨基酸残基相对于参考序列中对应位置处的氨基酸残基的差异。本文中氨基酸差异的位置通常被称为“xn”,其中n是指残基差异所基于的参考序列中的对应位置。例如,“与seq id no:8相比,在位置x44处的残基差异”是指在对应于seq id no:8的位置44的多肽位置处的氨基酸残基的差异。因此,如果参考多肽seq id no:8在位置44处具有精氨酸,则“与seq id no:8相比,在位置x44处的残基差异”是指在对应于seq id no:8的位置44的多肽位置处除精氨酸以外的任何残基的氨基酸取代。在本文的大多数情况下,在一个位置处的特定氨基酸残基差异指示为“xny”,其中“xn”指定如上文描述的对应位置,并且“y”是在工程化多肽中发现的氨基酸(即,与参考多肽中的不同的残基)的单字母标识符。在一些情况下(例如,如表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和表9
‑
1中示出的),本公开内容还提供由常规符号“anb”表示的特定氨基酸差异,其中a是参考序列中的残基的单字母标识符,“n”是在参考序列中的残基位置的编号,并且b是工程化多肽的序列中残基取代的单字母标识符。在一些情况下,本公开内容的多肽可以包含相对于参考序列的一个或更多个氨基酸残基差异,所述氨基酸残基差异由相对于参考序列存在残基差异的指定位置的列表指示。在一些实施方案中,当多于一个氨基酸可以在多肽的特定残基位置中使用时,可以使用的各种氨基酸残基由“/”分开(例如,x247d/x247n或x247d/n)。在一些实施方案中,酶变体包含多于一个取代。为了便于阅读,这些取代由斜线分开(例如,d24s/d202n)。本技术包括包含一个或更多个氨基酸差异的工程化多肽序列,所述一个或更多个氨基酸差异包括保守氨基酸取代和非保守氨基酸取代的任一种/或两者。
[0058]“保守氨基酸取代”是指用具有相似侧链的不同残基取代残基,并且因此通常包括
用相同或相似的氨基酸定义类别中的氨基酸取代多肽中的氨基酸。例如但不限于,具有脂肪族侧链的氨基酸可以被另一种脂肪族氨基酸(例如,丙氨酸、缬氨酸、亮氨酸和异亮氨酸)取代;具有羟基侧链的氨基酸被另一种具有羟基侧链的氨基酸(例如,丝氨酸和苏氨酸)取代;具有芳香族侧链的氨基酸被另一种具有芳香族侧链的氨基酸(例如,苯丙氨酸、酪氨酸、色氨酸和组氨酸)取代;具有碱性侧链的氨基酸被另一种具有碱性侧链的氨基酸(例如,赖氨酸和精氨酸)取代;具有酸性侧链的氨基酸被另一种具有酸性侧链的氨基酸(例如,天冬氨酸或谷氨酸)取代;和/或疏水氨基酸或亲水氨基酸分别被另一种疏水氨基酸或亲水氨基酸取代。
[0059]“非保守取代”是指用具有显著不同的侧链性质的氨基酸取代多肽中的氨基酸。非保守取代可以使用定义的组之间而不是之内的氨基酸,并且影响(a)取代区域中的肽骨架的结构(例如,脯氨酸取代甘氨酸),(b)电荷或疏水性,或(c)侧链体积。例如但不限于,示例性非保守取代可以是用碱性或脂肪族氨基酸取代酸性氨基酸;用小氨基酸取代芳香族氨基酸;和用疏水氨基酸取代亲水氨基酸。
[0060]“缺失”是指通过从参考多肽去除一个或更多个氨基酸对多肽进行的修饰。缺失可以包括去除1个或更多个氨基酸、2个或更多个氨基酸、5个或更多个氨基酸、10个或更多个氨基酸、15个或更多个氨基酸或者20个或更多个氨基酸、多达组成参考酶的氨基酸总数的10%或多达氨基酸总数的20%,同时保留酶活性和/或保留工程化酶的改进的性质。缺失可以涉及多肽的内部部分和/或末端部分。在多种实施方案中,缺失可以包括连续的区段或可以是不连续的。
[0061]“插入”是指通过将一个或更多个氨基酸添加到参考多肽对多肽进行的修饰。插入可以处于多肽的内部部分或者可以是插入到羧基或氨基末端。如本文使用的插入包括如本领域已知的融合蛋白。插入可以是氨基酸的连续区段或由天然存在的多肽中的一个或更多个氨基酸分开。
[0062]
在本文中可互换使用的“功能片段”或“生物活性片段”是指这样的多肽:所述多肽具有氨基末端缺失和/或羧基末端缺失和/或内部缺失,但其中剩余的氨基酸序列与和它进行比较的序列(例如,本发明的全长工程化gla)中的对应位置相同,并且保留全长多肽的基本上全部活性。
[0063]“分离的多肽”是指与天然伴随其的其他污染物(例如蛋白质、脂质和多核苷酸)基本上分开的多肽。该术语包括已经从它们天然存在的环境或表达系统(例如,宿主细胞或体外合成)中取出或纯化的多肽。重组gla多肽可以存在于细胞内、存在于细胞培养基中,或以各种形式(诸如裂解物或分离的制品)制备。因此,在一些实施方案中,重组gla多肽可以是分离的多肽。
[0064]“基本上纯的多肽”是指如下组合物,在所述组合物中多肽物质是存在的主要物质(即,在摩尔或重量基础上,它比该组合物中的任何其他单独的大分子物质更丰富),并且当目标物质构成存在的大分子物质的按摩尔或%重量计至少约50%时,通常是基本上纯化的组合物。通常,基本上纯的gla组合物构成该组合物中存在的所有大分子物质的按摩尔或%重量计约60%或更多、约70%或更多、约80%或更多、约90%或更多、约95%或更多以及约98%或更多。在一些实施方案中,将目标物质纯化至基本同质(即,通过常规检测方法不能在组合物中检测出污染物物质),其中该组合物基本上由单一大分子物质组成。溶剂物质、
小分子(<500道尔顿)和元素离子物质不被认为是大分子物质。在一些实施方案中,分离的重组gla多肽是基本上纯的多肽组合物。
[0065]“改进的酶特性”是指与参考gla多肽和/或野生型gla多肽或另一种工程化gla多肽相比,表现出任何酶特性的改进的工程化gla多肽。改进的特性包括但不限于这样的特性,如增加的基因表达、增加的蛋白产量、增加的热活性、增加的热稳定性、在各种ph水平增加的活性、增加的稳定性、增加的酶活性、增加的底物特异性或亲和力、增加的比活性、增加的对底物和/或产物抑制的抗性、增加的化学稳定性、改进的化学选择性、改进的溶剂稳定性、增加的对酸性、中性或碱性ph的耐受性、增加的对蛋白水解活性的耐受性(即,降低的对蛋白水解的敏感性)、减少的聚集、增加的溶解性、降低的免疫原性,改进的翻译后修饰(例如,糖基化)、改变的温度谱(temperature profile)、增加的细胞摄取、增加的溶酶体稳定性、增加的消耗细胞gb3的能力、增加的从gla产生细胞的分泌等。
[0066]“增加的酶促活性”或“增强的催化活性”是指工程化gla多肽的改进的特性,其可以被表示为与参考gla酶相比,比活性(例如,产生的产物/时间/重量蛋白)的增加或底物向产物的转化百分比(例如,使用指定量的gla,在指定的时间段内,起始量的底物向产物的转化百分比)的增加。确定酶活性的示例性方法在实施例中提供。与酶活性相关的任何特性都可以被影响,包括经典的酶特性k
m
、v
max
或k
cat
,其改变可以导致酶促活性的增加。酶活性的改进可以是从对应野生型酶的酶促活性的约1.1倍至比天然存在的gla或gla多肽所源自的另一种工程化gla的多达2倍、5倍、10倍、20倍、25倍、50倍、75倍、100倍、150倍、200倍或更多的酶促活性。
[0067]
在一些实施方案中,工程化gla多肽具有以下的k
cat
:至少0.1/sec、至少0.5/sec、至少1.0/sec、至少5.0/sec、至少10.0/sec,并且在一些优选的实施方案中大于10.0/sec。在一些实施方案中,k
m
在约1μm至约5mm的范围内、在约5μm至约2mm的范围内、在约10μm至约2mm的范围内或在约10μm至约1mm的范围内。在一些特定实施方案中,在暴露于某些条件之后,工程化gla酶与参考gla酶(例如,野生型gla或任何其它参考gla,诸如seq id no:8)的酶促活性相比表现出1.5倍至10倍、1.5倍至25倍、1.5倍至50倍、1.5倍至100倍或更大的范围内的改进的酶促活性。gla活性可以通过本领域已知的任何合适的方法来测量(例如,标准测定,例如监测反应物或产物的分光光度特性的变化)。在一些实施方案中,产生的产物的量可以通过高效液相色谱法(hplc)分离结合uv吸光度或荧光检测来直接测量或在o
‑
酞二醛(opa)衍生化后测量。在一些实施方案中,产生的产物的量可以通过水解4
‑
甲基伞形基
‑
α
‑
d
‑
吡喃半乳糖苷(4
‑
mugal)分子后监测荧光(ex.355nm,em.460nm)来测量。酶活性的比较使用限定的酶制品、设定条件下的限定的测定和一种或更多种限定的底物来进行,如本文进一步详细描述的。通常,当比较裂解物时,确定细胞的数目和测定的蛋白的量,并使用相同表达系统和相同宿主细胞以使由宿主细胞产生并存在于裂解物中的酶的量的变化最小化。
[0068]
术语“提高的对酸性ph的耐受性”意指与参考gla或另一种酶相比,根据本发明的重组gla将具有增加的稳定性(在暴露于酸性ph指定的时间段(1小时,最多24小时)后,在约ph 4.8保持更高的活性)。
[0069]
术语“提高的细胞摄取”意指与参考gla(包括野生型gla)或另一种酶相比,本文提供的重组gla表现出增加的进入细胞的内吞作用。在一些实施方案中,细胞是培养的法布里
病患者成纤维细胞(在与培养的细胞一起孵育指定的时间段后,与参考gla或另一种酶相比,保持更高的细胞内活性)。在一些另外的实施方案中,与参考gla(包括野生型gla)或另一种酶相比,本文提供的重组gla在与培养的细胞一起孵育指定的时间段后表现出更大的保持的细胞内活性。在一些另外的实施方案中,该时间段为约4小时,而在一些其他实施方案中,该时间段小于4小时(例如,1小时、2小时或3小时),并且在一些可选的实施方案中,该时间段大于4小时(例如,5小时、6小时、7小时、8小时或更多小时)。
[0070]
如本文使用的“生理ph”意指通常存在于受试者(例如,人类)的血液内的ph范围。
[0071]
术语“碱性ph”(例如,用于述及提高的对碱性ph条件的稳定性或增加的对碱性ph的耐受性)意指约7至11的ph范围。
[0072]
术语“酸性ph”(例如,用于述及提高的对酸性ph条件的稳定性或增加的对酸性ph的耐受性)意指约1.5至4.5的ph范围。
[0073]“转化”是指底物向对应产物的酶促转化(或生物转化)。“转化百分比”是指在指定条件下在一定时间段内转化为产物的底物的百分比。因此,gla多肽的“酶促活性”或“活性”可以表示为在指定的时间段内底物向产物的“转化百分比”。
[0074]“杂交严格性”是指核酸杂交中的杂交条件,诸如洗涤条件。通常,杂交反应在较低严格性的条件下进行,随后是不同的但较高严格性的洗涤。术语“中度严格杂交”是指允许靶dna结合以下互补核酸的条件,所述互补核酸与靶dna具有约60%同一性,优选地约75%同一性,约85%同一性,与靶多核苷酸具有大于约90%同一性。示例性中度严格条件是等同于在50%甲酰胺、5
×
denhart溶液、5
×
sspe、0.2%sds中在42℃杂交,随后在0.2
×
sspe、0.2%sds中在42℃洗涤的条件。“高严格性杂交”通常是指与如对限定的多核苷酸序列在溶液条件下确定的热解链温度t
m
相差约10℃或更小的条件。在一些实施方案中,高严格性条件是指仅允许在0.018m nacl中在65℃形成稳定杂交体的那些核酸序列的杂交(即,如果杂交体在0.018m nacl中在65℃是不稳定的,它在如本文预期的高严格性条件下是不稳定的)的条件。可以提供高严格性条件,例如,通过在等同于在50%甲酰胺、5
×
denhart溶液、5
×
sspe、0.2%sds在42℃的条件杂交,然后在0.1
×
sspe和0.1%sds中在65℃洗涤提供。另一种高严格性条件是在等同于在含有0.1%(w:v)sds的5x ssc中在65℃杂交的条件进行杂交和在含有0.1%sds的0.1
×
ssc中在65℃洗涤。其他高严格性杂交条件以及中度严格条件在上文引用的参考文献中描述。
[0075]“密码子优化”是指编码蛋白的多核苷酸的密码子的改变,使得编码的蛋白在感兴趣的生物体和/或细胞中更有效地表达。尽管遗传密码是简并的,即大多数氨基酸由被称为“同义”(“synonyms”)或“同义”(“synonymous”)密码子的若干密码子表示,但熟知的是,特定生物体的密码子使用是非随机的和对于特定的密码子三联体是有偏倚的。就给定基因、具有共同功能或祖先起源的基因、高表达的蛋白对比低拷贝数蛋白和生物体的基因组的聚集蛋白编码区而言,这种密码子使用偏倚可能更高。在一些实施方案中,可以考虑gc含量、隐蔽剪接位点、转录终止信号、可能影响rna稳定性的基序、和核酸二级结构以及任何其他感兴趣的因素,对编码gla酶的多核苷酸进行密码子优化,用于从选择用于表达的宿主生物体和/或细胞类型中最佳产生。
[0076]“控制序列”在本文中是指包括对本技术的多核苷酸和/或多肽的表达必要或有利的所有组分。每个控制序列对于编码多肽的核酸序列可以是天然的或外源的。这样的控制
序列包括但不限于前导序列、多腺苷酸化序列、前肽序列、启动子序列、信号肽序列、起始序列和转录终止子。在最小程度上,控制序列包括启动子和转录及翻译终止信号。控制序列可以与接头一起被提供,以用于引入促进控制序列与编码多肽的核酸序列的编码区的连接的特定限制性位点的目的。
[0077]“可操作地连接的”在本文被定义为如下配置:在所述配置中控制序列被适当地放置(即,以功能关系)在相对于感兴趣的多核苷酸的位置处,使得控制序列指导或调节感兴趣的多核苷酸和/或多肽的表达。
[0078]“启动子序列”是指被宿主细胞识别用于感兴趣的多核苷酸诸如编码序列的表达的核酸序列。启动子序列包含介导感兴趣的多核苷酸的表达的转录控制序列。启动子可以是在选择的宿主细胞中显示出转录活性的任何核酸序列,包括突变体、截短的和杂合的启动子,并且可以从编码与宿主细胞同源或异源的细胞外或细胞内多肽的基因获得。
[0079]“合适的反应条件”是指在酶促转化反应溶液中的那些条件(例如,酶载量、温度、ph、缓冲液、共溶剂等的范围),在该条件下本技术的gla多肽能够将底物转化为期望的产物化合物。示例性的“合适的反应条件”被提供于本技术中并且通过实施例来说明。“酶载量”是指在反应开始时反应混合物中的组分的浓度或量。在酶促转化反应过程的上下文中,“底物”是指受gla多肽作用的化合物或分子。在酶促转化过程的上下文中,“产物”是指由gla多肽对底物的作用产生的化合物或分子。
[0080]
如本文使用的术语“培养”是指微生物细胞、哺乳动物细胞或其他合适细胞的群体在任何合适的条件(例如,使用液体、凝胶或固体培养基)下的生长。
[0081]
重组多肽可以使用本领域已知的任何合适方法产生。编码感兴趣的野生型多肽的基因可以被克隆到载体诸如质粒中,并在期望的宿主诸如大肠杆菌(e.coli)、酿酒酵母(s.cerevisiae)或哺乳动物细胞系(例如,hek或cho细胞)等中表达。重组多肽的变体可以通过本领域已知的各种方法产生。事实上,存在本领域技术人员熟知的各种各样不同的诱变技术。此外,诱变试剂盒还可从许多商业分子生物学供应商获得。方法可用于做出确定的氨基酸(定点)处的特定取代、基因的局部区域中的特异性(区域特异性)或随机突变,或整个基因内的随机诱变(例如,饱和诱变)。本领域的技术人员已知产生酶变体的许多合适的方法,包括但不限于,使用pcr对单链dna或双链dna定点诱变、盒式诱变、基因合成、易错pcr、改组和化学饱和诱变,或本领域已知的任何其他合适的方法。用于dna和蛋白工程化的方法的非限制性实例在以下专利中提供:美国专利第6,117,679号;美国专利第6,420,175号;美国专利第6,376,246号;美国专利第6,586,182号;美国专利第7,747,391号;美国专利第7,747,393号;美国专利第7,783,428号和美国专利第8,383,346号。产生变体后,可以对它们筛选任何期望的特性(例如,高或增加的活性、或者低或减少的活性、增加的热活性、增加的热稳定性和/或酸性ph稳定性等)。在一些实施方案中,可使用“重组gla多肽”(在本文中也称为“工程化gla多肽”、“变体gla酶”和“gla变体”)。
[0082]
如本文使用的,“载体”是用于将dna序列引入到细胞中的dna构建体。在一些实施方案中,载体是被可操作地连接至能够实现dna序列中编码的多肽在合适宿主中的表达的合适的控制序列的表达载体。在一些实施方案中,“表达载体”具有可操作地连接至dna序列(例如,转基因)以驱动在宿主细胞中表达的启动子序列,并且在一些实施方案中,还包含转录终止子序列。
[0083]
如本文使用的,术语“基因治疗载体”是指适于向细胞递送多核苷酸序列的媒介物或载体。在一些实施方案中,载体封装用于递送至细胞或组织的基因(例如,治疗性基因)或多核苷酸序列,载体包括但不限于腺病毒(av)、腺相关病毒(aav)、慢病毒(lv)和非病毒载体,诸如脂质体。不意图本发明限于任何特定的基因治疗载体,因为任何适用于给定环境的媒介物都可使用。基因治疗载体可以被设计成将基因递送至特定物种或宿主,或者可具有更普遍的适用性。
[0084]
如本文使用的,术语“表达”包括涉及多肽产生的任何步骤,包括但不限于转录、转录后修饰、翻译和翻译后修饰。在一些实施方案中,该术语还包括多肽从细胞的分泌。
[0085]
如本文使用的,术语“产生”是指由细胞产生蛋白和/或其他化合物。意图该术语涵盖参与多肽产生的任何步骤,包括但不限于转录、转录后修饰、翻译和翻译后修饰。在一些实施方案中,该术语还包括多肽从细胞的分泌。
[0086]
如本文使用的,如果氨基酸或核苷酸序列(例如,启动子序列、信号肽、终止子序列等)与它被可操作地连接的另一种序列在自然界中不是缔合的,则这两种序列是“重组”或“异源”的。
[0087]
如本文使用的,术语“宿主细胞”和“宿主菌株”是指用于包含本文提供的dna(例如,编码gla变体的多核苷酸)的表达载体的合适的宿主。在一些实施方案中,宿主细胞是已经用使用如本领域已知的重组dna技术构建的载体转化或转染的原核细胞或真核细胞。
[0088]
术语“类似物”意指与参考多肽具有多于70%序列同一性,但少于100%序列同一性(例如,多于75%、78%、80%、83%、85%、88%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%序列同一性)的多肽。在一些实施方案中,“类似物”意指含有一个或更多个非天然存在的氨基酸残基(包括但不限于高精氨酸、鸟氨酸和正缬氨酸)以及天然存在的氨基酸的多肽。在一些实施方案中,类似物还包括一个或更多个d
‑
氨基酸残基和两个或更多个氨基酸残基之间的非肽键。
[0089]
术语“治疗剂”是指向显示出病理学迹象或症状的受试者施用的具有有益或期望的医学效应的化合物。
[0090]
术语“药物组合物”是指包含药学有效量的由本发明所包括的工程化gla多肽和可接受的载体的适用于哺乳动物受试者(例如,人类)的药物用途的组合物。
[0091]
术语“基因疗法”是指用基因治疗载体将基因、多脱氧核糖核苷酸或多核苷酸序列递送至细胞或组织,用于修饰这些细胞或组织来治疗或预防疾病。基因疗法可以包括用基因的健康拷贝替换引起疾病的突变基因,或者使功能不正常的突变基因失活或“敲除”功能不正常的突变基因。在一些实施方案中,基因疗法用于治疗患者的疾病。
[0092]
术语“mrna疗法”是指将mrna多核糖核苷酸序列递送至细胞或组织,用于修饰这些细胞或组织来治疗或预防疾病。在一些实施方案中,用于递送至细胞或组织的mrna多核苷酸序列被配制在例如但不限于脂质体中。在一些实施方案中,mrna疗法用于治疗患者的疾病。
[0093]
术语“细胞疗法”是指将外源修饰的活细胞递送至患者,以提供缺失的基因来治疗或预防疾病。然后,将修饰的细胞重新引入体内。
[0094]
术语“有效量”意指足以产生期望的结果的量。本领域普通技术人员可以通过使用常规实验确定有效量是多少。
[0095]
术语“分离的”和“纯化的”用于指从与其天然缔合的至少一种其他组分取出的分子(例如,分离的核酸、多肽等)或其他组分。术语“纯化的”不要求绝对纯度,而是意图作为相对定义。
[0096]
术语“受试者”包括哺乳动物,诸如人类、非人类灵长目动物、家畜、宠物和实验动物(例如,啮齿动物和兔形目动物)。意图的是该术语包括雌性以及雄性。
[0097]
如本文所用,术语“患者”意指正在被评估、治疗或正在经历疾病的任何受试者。
[0098]
术语“婴儿”是指在出生之后第一个月至约一(1)岁的时期内的儿童。如本文使用的,术语“新生儿”是指在从出生至生命的第28天的时期内的儿童。术语“早产婴儿”是指妊娠第二十个完整周之后但在妊娠期满之前出生的婴儿,通常在出生时称重~500至~2499克。“极低出生体重婴儿”是在出生时称重少于1500g的婴儿。
[0099]
如本文使用的,术语“儿童”是指对于同意治疗或研究程序未达到法定年龄的人。在一些实施方案中,该术语是指在出生和青春期的时期之间的人。
[0100]
如本文使用的,术语“成人”是指对于相关司法权已经达到法定年龄的人(例如,在美国为18岁)。在一些实施方案中,该术语是指任何完全发育成熟的生物体。在一些实施方案中,术语“青年”是指小于18岁但已经达到性成熟的人。
[0101]
如本文使用的,“组合物”和“制剂”包括意图用于任何适合的用途的包含本发明的至少一种工程化gla的产物(例如,药物组合物、膳食/营养补充物、饲料等)。
[0102]
术语“施用(administration)”和“施用(administering)”组合物意指向受试者(例如,遭受法布里病效果的人)提供本发明的组合物。
[0103]
当提及药物组合物使用时,术语“载体”意指标准药物载体,缓冲液和赋形剂诸如稳定剂、防腐剂和佐剂中的任一种。
[0104]
术语“药学上可接受的”意指可以向受试者施用而不引起任何不良生物效应或以有害的方式与在其中它被包含的组分的任何一种相互作用并且拥有期望的生物活性的材料。
[0105]
如本文使用的,术语“赋形剂”是指任何药学上可接受的添加剂、载体、稀释剂、佐剂或其他成分,而不是活性药物成分(api;例如,本发明的工程化gla多肽)。赋形剂通常被包括以用于制剂和/或施用目的。
[0106]
当提及疾病/状况的症状使用时,术语“治疗有效量”是指改善、减弱或消除疾病/状况的一种或更多种症状或者预防或延缓症状的发作的化合物(例如,工程化gla多肽)的量和/或浓度。
[0107]
当提及疾病/状况使用时,术语“治疗有效量”是指改善、减弱或消除该疾病/状况的组合物(例如,工程化gla多肽)的量和/或浓度。在一些实施方案中,该术语被用于指组合物的量,所述组合物的量引发研究者、医师、兽医师或其他临床医师寻求的组织、系统或动物受试者的生物学(例如,医学)响应。
[0108]
意图的是,术语“治疗(treating)”、“治疗(treat)”和“治疗(treatment)”包括预防性治疗(例如,预防剂)以及姑息治疗。
[0109]
工程化gla的表达和活性:
[0110]
使用合成的小鼠ig信号肽实现了酵母密码子优化的成熟人类gla的分泌表达。克隆从hek293t细胞中的pcdna3.1(+)载体表达。这种方法提供了对荧光底物4
‑
甲基伞形基α
‑
d
‑
吡喃半乳糖苷(4
‑
mugal)具有可测量活性的上清液。
[0111]
在一些实施方案中,为了鉴定与seq id no:8相比具有相似稳定性和提高的细胞摄取的突变多样性,构建了产生源自seq id no:8的gla变体的组合文库。在未挑战条件下(未孵育,ph 4.6)或在低ph(3.9
‑
4.2)、中性ph(7.0
‑
7.6)或人类血清(生理ph 7.1
‑
8.2)环境中孵育1小时后,筛选等体积的上清液。由于gla表达增加或gla比活性增加而具有活性的gla变体基于它们相对于亲本gla的倍数提高来鉴定。具有增加的稳定性的gla变体通过将在挑战条件下观察到的改进倍数除以在未挑战条件下观察到的改进倍数来鉴定。这种方法减少了基于表达增加但在极端ph比活性不变而选择变体的偏倚。综合活性评分(所有三种条件下倍数提高的乘积)和稳定性(稳定性评分的乘积)用于对改进的变体中的突变进行排序,用于纳入后续的gla文库。在另外的实施方案中,使用了实施例中描述的另外的方法和序列。
[0112]
工程化gla:
[0113]
在一些实施方案中,表现出改进特性的工程化gla与seq id no:2、8、58、158、372和/或374具有至少约85%、至少约88%、至少约90%、至少约91%、至少约92%、至少约93%、至少约94%、至少约95%、至少约96%、至少约97%、至少约98%、至少约99%或至少约100%的氨基酸序列同一性,并且与seq id no:2、8、58、158、372和/或374相比在一个或更多个氨基酸位置处具有氨基酸残基差异(诸如与seq id no:2、8、58、158、372和/或374相比在1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、14个、15个、20个或更多个氨基酸位置处,或与seq id no:2、8、58、158、372和/或374具有至少85%、至少88%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%或更高氨基酸序列同一性的序列)。在一些实施方案中,与seq id no:2、8、58、158、372和/或374相比在一个或更多个位置处的残基差异包括至少1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个保守氨基酸取代。在一些实施方案中,工程化gla多肽是表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中列出的多肽。在一些实施方案中,工程化gla多肽包含seq id no:2、8、58、158、372和/或374。
[0114]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:44、44/217、44/217/316、44/217/322、44/217/322/337、44/247、44/247/302、44/247/302/322、44/247/322、44/247/337、44/247/362、44/302、44/337、44/373、217/322、217/373、247/322、247/362、302/322/362/373、302/337、316、316/337、322、322/337、362/373和373,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:44l、44l/217f、44l/217f/316l、44l/217f/322m、44l/217f/322m/337a、44l/247n、44l/247n/302q、44l/247n/302q/322m、44l/247n/322m、44l/247n/337a、44l/247n/362k、44l/302q、44l/337a、44l/373r、217f/322m、217f/373r、247n/322m、247n/362k、302q/322m/362k/373r、302q/337a、316l、
316l/337a、322m、322m/337a、362k/373r和373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:r44l、r44l/r217f、r44l/r217f/d316l、r44l/r217f/i322m、r44l/r217f/i322m/p337a、r44l/d247n、r44l/d247n/k302q、r44l/d247n/k302q/i322m、r44l/d247n/i322m、r44l/d247n/p337a、r44l/d247n/q362k、r44l/k302q、r44l/p337a、r44l/k373r、r217f/i322m、r217f/k373r、d247n/i322m、d247n/q362k、k302q/i322m/q362k/k373r、k302q/p337a、d316l、d316l/p337a、i322m、i322m/p337a、q362k/k373r和k373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。
[0115]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10/39/44/47/92/166/206/217/247/261/271/302/316/322/337/362/368/373/392、44/217/316、44/217/322/337、166/362、217/373和362/373,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10t/39m/44l/47s/92y/166s/206k/217f/247n/261a/271h/302q/316l/322m/337a/362k/368w/373r/392m、44l/217f/316l、44l/217f/322m/337a、166a/362k、217f/373r和362k/373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:p10t/e39m/r44l/t47s/h92y/p166s/a206k/r217f/d247n/g261a/a271h/k302q/d316l/i322m/p337a/q362k/a368w/k373r/t392m、r44l/r217f/d316l、r44l/r217f/i322m/p337a、p166a/q362k、r217f/k373r和q362k/k373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。
[0116]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:7、7/48/68、7/48/68/120/282/299、7/48/130/282、7/48/180、7/68/130/282/365、7/68/180、7/88/120/305/365、7/120、7/130、7/282、7/305、7/305/365、7/365、39、47、47/87/95/96/158/162、47/95、47/273、47/343、48、48/68、48/180/282、48/282、48/282/305、67/180、68、68/299/300、71、87/91/95/96/158/162、87/91/95/96/206/343、87/96/155/273/343、88、91/95、91/95/96、92、93、96、96/273、96/312/343、120、120/299/305、151、158、158/162/273、162、162/273、162/343、166、178、180、181、206、217、271、273、273/343、282、282/365、293/391、299/300、
299/300/305/365、300、301、305、305/365、314、333、336、337、343、345、363、365、370、389、393、394、396/398、397和398,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:7l、7l/48d/68e、7l/48d/68e/120h/282n/299r、7l/48d/130e/282n、7l/48d/180g、7l/68e/130e/282n/365v、7l/68e/180g、7l/88a/120h/305g/365v、7l/120h、7l/130e、7l/282n、7l/305g、7l/305g/365v、7l/365v、39v、47d、47d/87k/95e/96l/158r/162h、47d/95e、47d/273p、47d/343g、47v、48d、48d/68e、48d/180g/282n、48d/282n、48d/282n/305g、67t/180g、68e、68e/299r/300i、71p、87k/91q/95e/96l/158a/162k、87k/91q/95e/96l/206s/343g、87k/96i/155n/273p/343g、88a、91q/95e、91q/95e/96l、92f、92t、93i、96l、96l/273p、96l/312q/343g、120h、120h/299r/305g、151l、158a、158a/162k/273g、158r、162h/343d、162k、162k/273p、162s、166k、178g、178s、180g、180l、180t、180v、181a、206k、206s、217k、271r、273p、273p/343g、282n、282n/365v、293p/391a、299r/300i、299r/300i/305g/365v、300i、301m、305g、305g/365v、314a、333f、333g、336v、337r、343d、343g、345a、345q、363q、365a、365q、365v、370g、389k、393v、394k、396g/398t、397a、398a、398p、398s和398v,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。
[0117]
在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:r7l、r7l/e48d/q68e、r7l/e48d/q68e/y120h/d282n/q299r、r7l/e48d/d130e/d282n、r7l/e48d/f180g、r7l/q68e/d130e/d282n/f365v、r7l/q68e/f180g、r7l/q88a/y120h/n305g/f365v、r7l/y120h、r7l/d130e、r7l/d282n、r7l/n305g、r7l/n305g/f365v、r7l/f365v、e39v、t47d、t47d/r87k/s95e/k96l/l158r/r162h、t47d/s95e、t47d/s273p、t47d/k343g、t47v、e48d、e48d/q68e、e48d/f180g/d282n、e48d/d282n、e48d/d282n/n305g、p67t/f180g、q68e、q68e/q299r/l300i、s71p、r87k/n91q/s95e/k96l/l158a/r162k、r87k/n91q/s95e/k96l/a206s/k343g、r87k/k96i/h155n/s273p/k343g、q88a、n91q/s95e、n91q/s95e/k96l、h92f、h92t、v93i、k96l、k96l/s273p、k96l/p312q/k343g、y120h、y120h/q299r/n305g、d151l、l158a、l158a/r162k/s273g、l158r、r162h/k343d、r162k、r162k/s273p、r162s、p166k、w178g、w178s、f180g、f180l、f180t、f180v、q181a、a206k、a206s、r217k、a271r、s273p、s273p/k343g、d282n、d282n/f365v、l293p/q391a、q299r/l300i、q299r/l300i/n305g/f365v、l300i、r301m、n305g、n305g/f365v、s314a、s333f、s333g、i336v、p337r、k343d、k343g、v345a、v345q、l363q、f365a、f365q、f365v、s370g、t389k、s393v、l394k、d396g/l398t、l397a、l398a、l398p、l398s和l398v,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。
[0118]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:24/202、39/47、39/
47/217、39/151、39/282/337/398、39/337/343/398、39/393/398、47/130、47/151、47/343/345/393、48、48/68、48/68/217/333/391/393、48/68/333、48/217、48/333、48/345/393、48/393、59/143、68、68/345、130、130/158、130/158/393、130/345/393、143/271、143/333、143/387、151、151/158/217/343/345/393、151/206/282/337/343/345/398、151/282/393、151/345/393/398、151/393、158、158/393、202、206、206/217、217、217/333、217/337/345/398、271、282/393、333、333/345、337/343/345/398、343、343/345/393/398、393和393/398,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:24s/202n、39v/47d、39v/47v/217k、39v/151l、39v/282n/337r/398a、39v/337r/343g/398a、39v/393v/398a、47v/130e、47v/151l、47v/343d/345q/393v、48d、48d/68e、48d/68e/217k/333f/391a/393v、48d/68e/333f、48d/217k、48d/333f、48d/333g、48d/345q/393v、48d/393v、59a/143s、68e、68e/345q、130e、130e/158r、130e/158r/393v、130e/345q/393v、143s/271n、143s/333n、143s/387n、151l、151l/158r/217k/343g/345q/393v、151l/206s/282n/337r/343d/345q/398a、151l/282n/393v、151l/345q/393v/398a、151l/393v、158r、158r/393v、202n、206s、206s/217k、217k、217k/333f、217k/333g、217k/337r/345q/398a、271n、282n/393v、333f/345q、333g、333n、337r/343g/345q/398a、343d、343d/345q/393v/398a、393v和393v/398a,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:d24s/d202n、e39v/t47d、e39v/t47v/r217k、e39v/d151l、e39v/d282n/p337r/l398a、e39v/p337r/k343g/l398a、e39v/s393v/l398a、t47v/d130e、t47v/d151l、t47v/k343d/v345q/s393v、e48d、e48d/q68e、e48d/q68e/r217k/s333f/q391a/s393v、e48d/q68e/s333f、e48d/r217k、e48d/s333f、e48d/s333g、e48d/v345q/s393v、e48d/s393v、c59a/c143s、q68e、q68e/v345q、d130e、d130e/l158r、d130e/l158r/s393v、d130e/v345q/s393v、c143s/a271n、c143s/s333n、c143s/e387n、d151l、d151l/l158r/r217k/k343g/v345q/s393v、d151l/a206s/d282n/p337r/k343d/v345q/l398a、d151l/d282n/s393v、d151l/v345q/s393v/l398a、d151l/s393v、l158r、l158r/s393v、d202n、a206s、a206s/r217k、r217k、r217k/s333f、r217k/s333g、r217k/p337r/v345q/l398a、a271n、d282n/s393v、s333f/v345q、s333g、s333n、p337r/k343g/v345q/l398a、k343d、k343d/v345q/s393v/l398a、s393v和s393v/l398a,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。
[0119]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10、10/39/44/322、10/39/92/206/217/271、10/39/92/247、10/39/92/247/271/316、10/44、10/44/47/92/247、10/44/47/261/302/322/368、10/44/92/316/322、10/44/261/302/316、10/44/302/337/
368、10/47/217/247/316/392、10/47/217/322、10/47/271、10/92、10/92/206/217/247、10/92/206/247/316/322/392、10/92/206/247/322/368、10/92/217/261/302/337、10/206/217/271、10/206/247、10/206/261/271/316、10/261、10/271/302、10/302、10/302/316、10/302/322/337、10/316/322、10/337/392、10/368、39/44/92/162/247/302/316/322、39/44/92/217/322、39/44/92/247/271/302、39/47/92/247/302/316/322、39/47/217/247/368、39/47/247、39/92/247/302/316/337/368、39/92/316/322、39/247/271、39/247/271/316、39/322、44/47/92/206/217/316/322、44/47/92/247/261/271/316/337/368、44/47/206/217/247/271/322、44/47/247/322/368、44/47/302/316/322、44/92/206/247/368、44/206/337、44/247/261/302/316、44/247/261/302/316/322、47/92/247/271、47/217/302、47/247、47/247/271、89/217/247/261/302/316、92/217/271、92/247、92/247/271/322、92/247/302/322/337、92/271/337、92/302、92/316、206/217/271/392、217/247/316/322/337/368、247、247/271、247/302、271、271/302/322、271/316/322、302/322/368和368,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10p、10p/39e/44r/322i、10p/39e/92h/206a/217r/271a、10p/39e/92h/247d、10p/39e/92h/247d/271a/316d、10p/44r、10p/44r/47t/92h/247d、10p/44r/47t/261g/302k/322i/368a、10p/44r/92h/316d/322i、10p/44r/261g/302k/316d、10p/44r/302k/337p/368a、10p/47t/217r/247d/316d/392t、10p/47t/217r/322i、10p/47t/271a、10p/92h、10p/92h/206a/217r/247d、10p/92h/206a/247d/316d/322i/392t、10p/92h/206a/247d/322i/368a、10p/92h/217r/261g/302k/337p、10p/206a/217r/271a、10p/206a/247d、10p/206a/261g/271a/316d、10p/261g、10p/271a/302k、10p/302k、10p/302k/316d、10p/302k/322i/337p、10p/316d/322i、10p/337p/392t、10p/368a、39e/44r/92h/162m/247d/302k/316d/322i、39e/44r/92h/217r/322i、39e/44r/92h/247d/271a/302k、39e/47t/92h/247d/302k/316d/322i、39e/47t/217r/247d/368a、39e/47t/247d、39e/92h/247d/302k/316d/337p/368a、39e/92h/316d/322i、39e/247d/271a、39e/247d/271a/316d、39e/322i、44r/47t/92h/206a/217r/316d/322i、44r/47t/92h/247d/261g/271a/316d/337p/368a、44r/47t/206a/217r/247d/271a/322i、44r/47t/247d/322i/368a、44r/47t/302k/316d/322i、44r/92h/206a/247d/368a、44r/206a/337p、44r/247d/261g/302k/316d、44r/247d/261g/302k/316d/322i、47t/92h/247d/271a、47t/217r/302k、47t/247d、47t/247d/271a、89i/217r/247d/261g/302k/316d、92h/217r/271a、92h/247d、92h/247d/271a/322i、92h/247d/302k/322i/337p、92h/271a/337p、92h/302k、92h/316d、206a/217r/271a/392t、217r/247d/316d/322i/337p/368a、247d、247d/271a、247d/302k、271a、271a/302k/322i、271a/316d/322i、302k/322i/368a和368a,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:t10p、t10p/m39e/l44r/m322i、t10p/m39e/y92h/k206a/f217r/h271a、t10p/m39e/y92h/
n247d、t10p/m39e/y92h/n247d/h271a/l316d、t10p/l44r、t10p/l44r/s47t/y92h/n247d、t10p/l44r/s47t/a261g/q302k/m322i/w368a、t10p/l44r/y92h/l316d/m322i、t10p/l44r/a261g/q302k/l316d、t10p/l44r/q302k/a337p/w368a、t10p/s47t/f217r/n247d/l316d/m392t、t10p/s47t/f217r/m322i、t10p/s47t/h271a、t10p/y92h、t10p/y92h/k206a/f217r/n247d、t10p/y92h/k206a/n247d/l316d/m322i/m392t、t10p/y92h/k206a/n247d/m322i/w368a、t10p/y92h/f217r/a261g/q302k/a337p、t10p/k206a/f217r/h271a、t10p/k206a/n247d、t10p/k206a/a261g/h271a/l316d、t10p/a261g、t10p/h271a/q302k、t10p/q302k、t10p/q302k/l316d、t10p/q302k/m322i/a337p、t10p/l316d/m322i、t10p/a337p/m392t、t10p/w368a、m39e/l44r/y92h/r162m/n247d/q302k/l316d/m322i、m39e/l44r/y92h/f217r/m322i、m39e/l44r/y92h/n247d/h271a/q302k、m39e/s47t/y92h/n247d/q302k/l316d/m322i、m39e/s47t/f217r/n247d/w368a、m39e/s47t/n247d、m39e/y92h/n247d/q302k/l316d/a337p/w368a、m39e/y92h/l316d/m322i、m39e/n247d/h271a、m39e/n247d/h271a/l316d、m39e/m322i、l44r/s47t/y92h/k206a/f217r/l316d/m322i、l44r/s47t/y92h/n247d/a261g/h271a/l316d/a337p/w368a、l44r/s47t/k206a/f217r/n247d/h271a/m322i、l44r/s47t/n247d/m322i/w368a、l44r/s47t/q302k/l316d/m322i、l44r/y92h/k206a/n247d/w368a、l44r/k206a/a337p、l44r/n247d/a261g/q302k/l316d、l44r/n247d/a261g/q302k/l316d/m322i、s47t/y92h/n247d/h271a、s47t/f217r/q302k、s47t/n247d、s47t/n247d/h271a、l89i/f217r/n247d/a261g/q302k/l316d、y92h/f217r/h271a、y92h/n247d、y92h/n247d/h271a/m322i、y92h/n247d/q302k/m322i/a337p、y92h/h271a/a337p、y92h/q302k、y92h/l316d、k206a/f217r/h271a/m392t、f217r/n247d/l316d/m322i/a337p/w368a、n247d、n247d/h271a、n247d/q302k、h271a、h271a/q302k/m322i、h271a/l316d/m322i、q302k/m322i/w368a和w368a,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。
[0120]
本发明还提供了重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10/36/92/166/247/261/316/392、10/39、10/39/44/47/92/206/217、10/39/44/47/316、10/39/44/47/337、10/39/44/92/166/261/316/322、10/39/44/92/166/302/322、10/39/44/92/166/392、10/39/44/92/217/302/322、10/39/44/92/302/322、10/39/44/166/261/271/316/322、10/39/44/392、10/39/47/92/337、10/39/92/131/166/271/316/322、10/39/92/166/217/247/271、10/39/92/217/316、10/44/47/166/261/271、10/44/47/166/271/322/368、10/44/47/217/271/316/322、10/44/92、10/44/92/217/247/271/302/316/392、10/44/166/302、10/44/206/316/322、10/47/92/166/271/316/337、10/47/92/271/302、10/47/92/316/322/392、10/47/166/271、10/47/166/316、10/92/166、10/92/166/217/247/261/271、10/92/166/261/271/392、10/92/166/261/316/322/337、10/92/166/337/368、10/92/302/337、10/92/316/322、10/206、10/206/247/261、10/217/322、10/261、10/261/337/392、10/316/392、10/368、39/44/47/92/166/206/392、39/44/47/92/206/247/261、39/44/47/92/206/392、39/44/47/206/337/368/392、39/44/92/166/247/261/302/337、39/44/166/271、39/44/166/271/337/368/392、39/47/92/316/322、39/47/92/392、39/47/166/217/261/392、39/47/217/247/
368、39/47/247、39/92/166/217/392、39/92/261/302、39/166/217/261/316/368、39/322、39/392、44/47、44/47/92/217/271、44/47/92/217/316/322/392、44/47/92/392、44/47/166、44/47/166/271、44/47/247/271/392、44/316/322/392、44/337、47/166/206/217/247/337、47/166/217/271/337、47/206、47/217/247/261、47/271、52/217/302/316、92/166/206/271/316、92/166/217/261/271/392、92/166/217/316/337/392、92/166/247、92/166/316、92/206/322、92/217、92/217/271/337、92/261/271、92/271、166/217/316/322/337、166/247/271/316、166/316/322/337、206/217、217/392、247/316、316/322/368和316/337/392,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10t/36m/92y/166s/247n/261a/316l/392m、10t/39m、10t/39m/44l/47s/92y/206k/217f、10t/39m/44l/47s/316l、10t/39m/44l/47s/337a、10t/39m/44l/92y/166s/261a/316l/322m、10t/39m/44l/92y/166s/302q/322m、10t/39m/44l/92y/166s/392m、10t/39m/44l/92y/217f/302q/322m、10t/39m/44l/92y/302q/322m、10t/39m/44l/166s/261a/271h/316l/322m、10t/39m/44l/392m、10t/39m/47s/92y/337a、10t/39m/92y/131g/166s/271h/316l/322m、10t/39m/92y/166s/217f/247n/271h、10t/39m/92y/217f/316l、10t/44l/47s/166s/261a/271h、10t/44l/47s/166s/271h/322m/368w、10t/44l/47s/217f/271h/316l/322m、10t/44l/92y、10t/44l/92y/217f/247n/271h/302q/316l/392m、10t/44l/166s/302q、10t/44l/206k/316l/322m、10t/47s/92y/166s/271h/316l/337a、10t/47s/92y/271h/302q、10t/47s/92y/316l/322m/392m、10t/47s/166s/271h、10t/47s/166s/316l、10t/92y/166s、10t/92y/166s/217f/247n/261a/271h、10t/92y/166s/261a/271h/392m、10t/92y/166s/261a/316l/322m/337a、10t/92y/166s/337a/368w、10t/92y/302q/337a、10t/92y/316l/322m、10t/206k、10t/206k/247n/261a、10t/217f/322m、10t/261a、10t/261a/337a/392m、10t/316l/392m、10t/368w、39m/44l/47s/92y/166s/206k/392m、39m/44l/47s/92y/206k/247n/261a、39m/44l/47s/92y/206k/392m、39m/44l/47s/206k/337a/368w/392m、39m/44l/92y/166s/247n/261a/302q/337a、39m/44l/166s/271h、39m/44l/166s/271h/337a/368w/392m、39m/47s/92y/316l/322m、39m/47s/92y/392m、39m/47s/166s/217f/261a/392m、39m/47s/217f/247n/368w、39m/47s/247n、39m/92y/166s/217f/392m、39m/92y/261a/302q、39m/166s/217f/261a/316l/368w、39m/322m、39m/392m、44l/47s、44l/47s/92y/217f/271h、44l/47s/92y/217f/316l/322m/392m、44l/47s/92y/392m、44l/47s/166s、44l/47s/166s/271h、44l/47s/247n/271h/392m、44l/316l/322m/392m、44l/337a、47s/166s/206k/217f/247n/337a、47s/166s/217f/271h/337a、47s/206k、47s/217f/247n/261a、47s/271h、52n/217f/302q/316l、92y/166s/206k/271h/316l、92y/166s/217f/261a/271h/392m、92y/166s/217f/316l/337a/392m、92y/166s/247n、92y/166s/316l、92y/206k/322m、92y/217f、92y/217f/271h/337a、92y/261a/271h、92y/271h、166s/217f/316l/322m/337a、166s/247n/271h/316l、166s/316l/322m/337a、206k/217f、217f/392m、247n/316l、316l/322m/368w和316l/337a/392m,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、
90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:p10t/k36m/h92y/p166s/d247n/g261a/d316l/t392m、p10t/e39m、p10t/e39m/r44l/t47s/h92y/a206k/r217f、p10t/e39m/r44l/t47s/d316l、p10t/e39m/r44l/t47s/p337a、p10t/e39m/r44l/h92y/p166s/g261a/d316l/i322m、p10t/e39m/r44l/h92y/p166s/k302q/i322m、p10t/e39m/r44l/h92y/p166s/t392m、p10t/e39m/r44l/h92y/r217f/k302q/i322m、p10t/e39m/r44l/h92y/k302q/i322m、p10t/e39m/r44l/p166s/g261a/a271h/d316l/i322m、p10t/e39m/r44l/t392m、p10t/e39m/t47s/h92y/p337a、p10t/e39m/h92y/w131g/p166s/a271h/d316l/i322m、p10t/e39m/h92y/p166s/r217f/d247n/a271h、p10t/e39m/h92y/r217f/d316l、p10t/r44l/t47s/p166s/g261a/a271h、p10t/r44l/t47s/p166s/a271h/i322m/a368w、p10t/r44l/t47s/r217f/a271h/d316l/i322m、p10t/r44l/h92y、p10t/r44l/h92y/r217f/d247n/a271h/k302q/d316l/t392m、p10t/r44l/p166s/k302q、p10t/r44l/a206k/d316l/i322m、p10t/t47s/h92y/p166s/a271h/d316l/p337a、p10t/t47s/h92y/a271h/k302q、p10t/t47s/h92y/d316l/i322m/t392m、p10t/t47s/p166s/a271h、p10t/t47s/p166s/d316l、p10t/h92y/p166s、p10t/h92y/p166s/r217f/d247n/g261a/a271h、p10t/h92y/p166s/g261a/a271h/t392m、p10t/h92y/p166s/g261a/d316l/i322m/p337a、p10t/h92y/p166s/p337a/a368w、p10t/h92y/k302q/p337a、p10t/h92y/d316l/i322m、p10t/a206k、p10t/a206k/d247n/g261a、p10t/r217f/i322m、p10t/g261a、p10t/g261a/p337a/t392m、p10t/d316l/t392m、p10t/a368w、e39m/r44l/t47s/h92y/p166s/a206k/t392m、e39m/r44l/t47s/h92y/a206k/d247n/g261a、e39m/r44l/t47s/h92y/a206k/t392m、e39m/r44l/t47s/a206k/p337a/a368w/t392m、e39m/r44l/h92y/p166s/d247n/g261a/k302q/p337a、e39m/r44l/p166s/a271h、e39m/r44l/p166s/a271h/p337a/a368w/t392m、e39m/t47s/h92y/d316l/i322m、e39m/t47s/h92y/t392m、e39m/t47s/p166s/r217f/g261a/t392m、e39m/t47s/r217f/d247n/a368w、e39m/t47s/d247n、e39m/h92y/p166s/r217f/t392m、e39m/h92y/g261a/k302q、e39m/p166s/r217f/g261a/d316l/a368w、e39m/i322m、e39m/t392m、r44l/t47s、r44l/t47s/h92y/r217f/a271h、r44l/t47s/h92y/r217f/d316l/i322m/t392m、r44l/t47s/h92y/t392m、r44l/t47s/p166s、r44l/t47s/p166s/a271h、r44l/t47s/d247n/a271h/t392m、r44l/d316l/i322m/t392m、r44l/p337a、t47s/p166s/a206k/r217f/d247n/p337a、t47s/p166s/r217f/a271h/p337a、t47s/a206k、t47s/r217f/d247n/g261a、t47s/a271h、d52n/r217f/k302q/d316l、h92y/p166s/a206k/a271h/d316l、h92y/p166s/r217f/g261a/a271h/t392m、h92y/p166s/r217f/d316l/p337a/t392m、h92y/p166s/d247n、h92y/p166s/d316l、h92y/a206k/i322m、h92y/r217f、h92y/r217f/a271h/p337a、h92y/g261a/a271h、h92y/a271h、p166s/r217f/d316l/i322m/p337a、p166s/d247n/a271h/d316l、p166s/d316l/i322m/p337a、a206k/r217f、r217f/t392m、d247n/d316l、d316l/i322m/a368w和d316l/p337a/t392m,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。
[0121]
在一些实施方案中,重组α半乳糖苷酶a多肽序列与seq id no:4
‑
702中的偶数编号序列具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性。
[0122]
在一些实施方案中,工程化gla多肽包含本发明涵盖的工程化gla多肽的功能片
段。功能片段具有其所源自的工程化gla多肽(即,亲本工程化gla)的活性的至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%或99%。功能片段包含工程化gla的亲本序列的至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%以及甚至99%。在一些实施方案中,功能片段被截短少于5个、少于10个、少于15个、少于20个、少于25个、少于30个、少于35个、少于40个、少于45个和少于50个氨基酸。
[0123]
编码工程化多肽的多核苷酸、表达载体和宿主细胞:
[0124]
本发明提供了编码本文描述的工程化gla多肽的多核苷酸。在一些实施方案中,多核苷酸被可操作地连接至控制基因表达的一个或更多个异源或同源调控序列,以创建能够表达多肽的重组多核苷酸。包含编码工程化gla多肽的异源多核苷酸的表达构建体可以被引入到适当的宿主细胞中以表达对应的gla多肽。
[0125]
如对技术人员将是明显的,蛋白序列的可获得性和对应于各种氨基酸的密码子的知识提供了能够编码主题多肽的所有多核苷酸的说明。遗传密码的简并性,其中相同的氨基酸由可替代的密码子或同义密码子编码,允许制备极大数目的核酸,所有这些核酸都编码工程化gla多肽。因此,知道了特定的氨基酸序列后,本领域技术人员可以通过以不改变蛋白的氨基酸序列的方式简单修改序列的一个或更多个密码子来制备任何数目的不同核酸。在这方面,本发明特别设想了可以通过基于可能的密码子选择来选择组合以制备编码本文描述的多肽的多核苷酸的每种和每一种可能的改变,并且对于本文描述的任何多肽,所有此类改变,包括表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1、和/或表9
‑
1中提供的变体,应被认为被特别地公开。
[0126]
在多种实施方案中,优选地选择密码子来适应在其中产生蛋白的宿主细胞。例如,细菌中使用的优选的密码子被用于在细菌中的表达。因此,编码工程化gla多肽的密码子优化的多核苷酸在全长编码区的约40%、50%、60%、70%、80%或大于90%的密码子位置处包含优选的密码子。在一些实施方案中,本发明提供了重组多核苷酸序列,其中密码子被优化用于在人类细胞或组织中表达。
[0127]
在一些实施方案中,本发明提供了与seq id no:7具有至少约85%、约86%、约87%、约88%、约89%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,本发明提供了与seq id no:7具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,重组多核苷酸序列与seq id no:3
‑
701中的奇数编码序列具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多的序列同一性。
[0128]
在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,该重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:44、44/217、44/217/316、44/217/322、44/217/322/337、44/247、44/247/302、44/247/302/322、44/247/322、44/247/337、44/247/362、44/302、44/337、44/373、217/322、217/373、247/322、247/362、302/322/362/373、302/337、316、316/337、322、322/337、362/373和373,其中所述多肽
序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,该重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:44l、44l/217f、44l/217f/316l、44l/217f/322m、44l/217f/322m/337a、44l/247n、44l/247n/302q、44l/247n/302q/322m、44l/247n/322m、44l/247n/337a、44l/247n/362k、44l/302q、44l/337a、44l/373r、217f/322m、217f/373r、247n/322m、247n/362k、302q/322m/362k/373r、302q/337a、316l、316l/337a、322m、322m/337a、362k/373r和373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,该重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:r44l、r44l/r217f、r44l/r217f/d316l、r44l/r217f/i322m、r44l/r217f/i322m/p337a、r44l/d247n、r44l/d247n/k302q、r44l/d247n/k302q/i322m、r44l/d247n/i322m、r44l/d247n/p337a、r44l/d247n/q362k、r44l/k302q、r44l/p337a、r44l/k373r、r217f/i322m、r217f/k373r、d247n/i322m、d247n/q362k、k302q/i322m/q362k/k373r、k302q/p337a、d316l、d316l/p337a、i322m、i322m/p337a、q362k/k373r和k373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。
[0129]
在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,该重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10/39/44/47/92/166/206/217/247/261/271/302/316/322/337/362/368/373/392、44/217/316、44/217/322/337、166/362、217/373和362/373,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,该重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10t/39m/44l/47s/92y/166s/206k/217f/247n/261a/271h/302q/316l/322m/337a/362k/368w/373r/392m、44l/217f/316l、44l/217f/322m/337a、166a/362k、217f/373r和362k/373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,该重组α半乳糖苷酶a包含与seq id no:8具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:p10t/e39m/r44l/t47s/h92y/p166s/a206k/r217f/d247n/g261a/a271h/k302q/d316l/i322m/p337a/q362k/a368w/k373r/t392m、r44l/r217f/d316l、r44l/r217f/i322m/p337a、p166a/q362k、r217f/k373r和q362k/k373r,其中所述多肽序列的氨基酸位置参考seq id no:8来编号。
[0130]
在一些实施方案中,本发明提供了与seq id no:57具有至少约85%、约86%、约
87%、约88%、约89%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,本发明提供了与seq id no:57具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:7、7/48/68、7/48/68/120/282/299、7/48/130/282、7/48/180、7/68/130/282/365、7/68/180、7/88/120/305/365、7/120、7/130、7/282、7/305、7/305/365、7/365、39、47、47/87/95/96/158/162、47/95、47/273、47/343、48、48/68、48/180/282、48/282、48/282/305、67/180、68、68/299/300、71、87/91/95/96/158/162、87/91/95/96/206/343、87/96/155/273/343、88、91/95、91/95/96、92、93、96、96/273、96/312/343、120、120/299/305、151、158、158/162/273、162、162/273、162/343、166、178、180、181、206、217、271、273、273/343、282、282/365、293/391、299/300、299/300/305/365、300、301、305、305/365、314、333、336、337、343、345、363、365、370、389、393、394、396/398、397和398,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:7l、7l/48d/68e、7l/48d/68e/120h/282n/299r、7l/48d/130e/282n、7l/48d/180g、7l/68e/130e/282n/365v、7l/68e/180g、7l/88a/120h/305g/365v、7l/120h、7l/130e、7l/282n、7l/305g、7l/305g/365v、7l/365v、39v、47d、47d/87k/95e/96l/158r/162h、47d/95e、47d/273p、47d/343g、47v、48d、48d/68e、48d/180g/282n、48d/282n、48d/282n/305g、67t/180g、68e、68e/299r/300i、71p、87k/91q/95e/96l/158a/162k、87k/91q/95e/96l/206s/343g、87k/96i/155n/273p/343g、88a、91q/95e、91q/95e/96l、92f、92t、93i、96l、96l/273p、96l/312q/343g、120h、120h/299r/305g、151l、158a、158a/162k/273g、158r、162h/343d、162k、162k/273p、162s、166k、178g、178s、180g、180l、180t、180v、181a、206k、206s、217k、271r、273p、273p/343g、282n、282n/365v、293p/391a、299r/300i、299r/300i/305g/365v、300i、301m、305g、305g/365v、314a、333f、333g、336v、337r、343d、343g、345a、345q、363q、365a、365q、365v、370g、389k、393v、394k、396g/398t、397a、398a、398p、398s和398v,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:58具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:r7l、r7l/e48d/q68e、r7l/e48d/q68e/y120h/d282n/q299r、r7l/e48d/d130e/d282n、r7l/e48d/f180g、r7l/q68e/d130e/d282n/f365v、r7l/q68e/f180g、r7l/q88a/y120h/n305g/f365v、r7l/y120h、r7l/d130e、r7l/d282n、r7l/n305g、r7l/n305g/f365v、r7l/f365v、e39v、t47d、t47d/r87k/s95e/k96l/l158r/r162h、t47d/s95e、t47d/s273p、t47d/k343g、t47v、e48d、e48d/q68e、e48d/f180g/d282n、e48d/d282n、e48d/d282n/n305g、p67t/
f180g、q68e、q68e/q299r/l300i、s71p、r87k/n91q/s95e/k96l/l158a/r162k、r87k/n91q/s95e/k96l/a206s/k343g、r87k/k96i/h155n/s273p/k343g、q88a、n91q/s95e、n91q/s95e/k96l、h92f、h92t、v93i、k96l、k96l/s273p、k96l/p312q/k343g、y120h、y120h/q299r/n305g、d151l、l158a、l158a/r162k/s273g、l158r、r162h/k343d、r162k、r162k/s273p、r162s、p166k、w178g、w178s、f180g、f180l、f180t、f180v、q181a、a206k、a206s、r217k、a271r、s273p、s273p/k343g、d282n、d282n/f365v、l293p/q391a、q299r/l300i、q299r/l300i/n305g/f365v、l300i、r301m、n305g、n305g/f365v、s314a、s333f、s333g、i336v、p337r、k343d、k343g、v345a、v345q、l363q、f365a、f365q、f365v、s370g、t389k、s393v、l394k、d396g/l398t、l397a、l398a、l398p、l398s和l398v,其中所述多肽序列的氨基酸位置参考seq id no:58来编号。
[0131]
在一些实施方案中,本发明提供了与seq id no:157具有至少约85%、约86%、约87%、约88%、约89%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,本发明提供了与seq id no:157具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:24/202、39/47、39/47/217、39/151、39/282/337/398、39/337/343/398、39/393/398、47/130、47/151、47/343/345/393、48、48/68、48/68/217/333/391/393、48/68/333、48/217、48/333、48/345/393、48/393、59/143、68、68/345、130、130/158、130/158/393、130/345/393、143/271、143/333、143/387、151、151/158/217/343/345/393、151/206/282/337/343/345/398、151/282/393、151/345/393/398、151/393、158、158/393、202、206、206/217、217、217/333、217/337/345/398、271、282/393、333、333/345、337/343/345/398、343、343/345/393/398、393和393/398,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:24s/202n、39v/47d、39v/47v/217k、39v/151l、39v/282n/337r/398a、39v/337r/343g/398a、39v/393v/398a、47v/130e、47v/151l、47v/343d/345q/393v、48d、48d/68e、48d/68e/217k/333f/391a/393v、48d/68e/333f、48d/217k、48d/333f、48d/333g、48d/345q/393v、48d/393v、59a/143s、68e、68e/345q、130e、130e/158r、130e/158r/393v、130e/345q/393v、143s/271n、143s/333n、143s/387n、151l、151l/158r/217k/343g/345q/393v、151l/206s/282n/337r/343d/345q/398a、151l/282n/393v、151l/345q/393v/398a、151l/393v、158r、158r/393v、202n、206s、206s/217k、217k、217k/333f、217k/333g、217k/337r/345q/398a、271n、282n/393v、333f/345q、333g、333n、337r/343g/345q/398a、343d、343d/345q/393v/398a、393v和393v/398a,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:158具有至少85%、86%、87%、88%、89%、90%、91%、92%、
93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:d24s/d202n、e39v/t47d、e39v/t47v/r217k、e39v/d151l、e39v/d282n/p337r/l398a、e39v/p337r/k343g/l398a、e39v/s393v/l398a、t47v/d130e、t47v/d151l、t47v/k343d/v345q/s393v、e48d、e48d/q68e、e48d/q68e/r217k/s333f/q391a/s393v、e48d/q68e/s333f、e48d/r217k、e48d/s333f、e48d/s333g、e48d/v345q/s393v、e48d/s393v、c59a/c143s、q68e、q68e/v345q、d130e、d130e/l158r、d130e/l158r/s393v、d130e/v345q/s393v、c143s/a271n、c143s/s333n、c143s/e387n、d151l、d151l/l158r/r217k/k343g/v345q/s393v、d151l/a206s/d282n/p337r/k343d/v345q/l398a、d151l/d282n/s393v、d151l/v345q/s393v/l398a、d151l/s393v、l158r、l158r/s393v、d202n、a206s、a206s/r217k、r217k、r217k/s333f、r217k/s333g、r217k/p337r/v345q/l398a、a271n、d282n/s393v、s333f/v345q、s333g、s333n、p337r/k343g/v345q/l398a、k343d、k343d/v345q/s393v/l398a、s393v和s393v/l398a,其中所述多肽序列的氨基酸位置参考seq id no:158来编号。
[0132]
在一些实施方案中,本发明提供了与seq id no:371具有至少约85%、约86%、约87%、约88%、约89%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,本发明提供了与seq id no:371具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10、10/39/44/322、10/39/92/206/217/271、10/39/92/247、10/39/92/247/271/316、10/44、10/44/47/92/247、10/44/47/261/302/322/368、10/44/92/316/322、10/44/261/302/316、10/44/302/337/368、10/47/217/247/316/392、10/47/217/322、10/47/271、10/92、10/92/206/217/247、10/92/206/247/316/322/392、10/92/206/247/322/368、10/92/217/261/302/337、10/206/217/271、10/206/247、10/206/261/271/316、10/261、10/271/302、10/302、10/302/316、10/302/322/337、10/316/322、10/337/392、10/368、39/44/92/162/247/302/316/322、39/44/92/217/322、39/44/92/247/271/302、39/47/92/247/302/316/322、39/47/217/247/368、39/47/247、39/92/247/302/316/337/368、39/92/316/322、39/247/271、39/247/271/316、39/322、44/47/92/206/217/316/322、44/47/92/247/261/271/316/337/368、44/47/206/217/247/271/322、44/47/247/322/368、44/47/302/316/322、44/92/206/247/368、44/206/337、44/247/261/302/316、44/247/261/302/316/322、47/92/247/271、47/217/302、47/247、47/247/271、89/217/247/261/302/316、92/217/271、92/247、92/247/271/322、92/247/302/322/337、92/271/337、92/302、92/316、206/217/271/392、217/247/316/322/337/368、247、247/271、247/302、271、271/302/322、271/316/322、302/322/368和368,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a
在选自以下的一个或更多个位置处包含至少一个取代或取代集:10p、10p/39e/44r/322i、10p/39e/92h/206a/217r/271a、10p/39e/92h/247d、10p/39e/92h/247d/271a/316d、10p/44r、10p/44r/47t/92h/247d、10p/44r/47t/261g/302k/322i/368a、10p/44r/92h/316d/322i、10p/44r/261g/302k/316d、10p/44r/302k/337p/368a、10p/47t/217r/247d/316d/392t、10p/47t/217r/322i、10p/47t/271a、10p/92h、10p/92h/206a/217r/247d、10p/92h/206a/247d/316d/322i/392t、10p/92h/206a/247d/322i/368a、10p/92h/217r/261g/302k/337p、10p/206a/217r/271a、10p/206a/247d、10p/206a/261g/271a/316d、10p/261g、10p/271a/302k、10p/302k、10p/302k/316d、10p/302k/322i/337p、10p/316d/322i、10p/337p/392t、10p/368a、39e/44r/92h/162m/247d/302k/316d/322i、39e/44r/92h/217r/322i、39e/44r/92h/247d/271a/302k、39e/47t/92h/247d/302k/316d/322i、39e/47t/217r/247d/368a、39e/47t/247d、39e/92h/247d/302k/316d/337p/368a、39e/92h/316d/322i、39e/247d/271a、39e/247d/271a/316d、39e/322i、44r/47t/92h/206a/217r/316d/322i、44r/47t/92h/247d/261g/271a/316d/337p/368a、44r/47t/206a/217r/247d/271a/322i、44r/47t/247d/322i/368a、44r/47t/302k/316d/322i、44r/92h/206a/247d/368a、44r/206a/337p、44r/247d/261g/302k/316d、44r/247d/261g/302k/316d/322i、47t/92h/247d/271a、47t/217r/302k、47t/247d、47t/247d/271a、89i/217r/247d/261g/302k/316d、92h/217r/271a、92h/247d、92h/247d/271a/322i、92h/247d/302k/322i/337p、92h/271a/337p、92h/302k、92h/316d、206a/217r/271a/392t、217r/247d/316d/322i/337p/368a、247d、247d/271a、247d/302k、271a、271a/302k/322i、271a/316d/322i、302k/322i/368a和368a,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:372具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:t10p、t10p/m39e/l44r/m322i、t10p/m39e/y92h/k206a/f217r/h271a、t10p/m39e/y92h/n247d、t10p/m39e/y92h/n247d/h271a/l316d、t10p/l44r、t10p/l44r/s47t/y92h/n247d、t10p/l44r/s47t/a261g/q302k/m322i/w368a、t10p/l44r/y92h/l316d/m322i、t10p/l44r/a261g/q302k/l316d、t10p/l44r/q302k/a337p/w368a、t10p/s47t/f217r/n247d/l316d/m392t、t10p/s47t/f217r/m322i、t10p/s47t/h271a、t10p/y92h、t10p/y92h/k206a/f217r/n247d、t10p/y92h/k206a/n247d/l316d/m322i/m392t、t10p/y92h/k206a/n247d/m322i/w368a、t10p/y92h/f217r/a261g/q302k/a337p、t10p/k206a/f217r/h271a、t10p/k206a/n247d、t10p/k206a/a261g/h271a/l316d、t10p/a261g、t10p/h271a/q302k、t10p/q302k、t10p/q302k/l316d、t10p/q302k/m322i/a337p、t10p/l316d/m322i、t10p/a337p/m392t、t10p/w368a、m39e/l44r/y92h/r162m/n247d/q302k/l316d/m322i、m39e/l44r/y92h/f217r/m322i、m39e/l44r/y92h/n247d/h271a/q302k、m39e/s47t/y92h/n247d/q302k/l316d/m322i、m39e/s47t/f217r/n247d/w368a、m39e/s47t/n247d、m39e/y92h/n247d/q302k/l316d/a337p/w368a、m39e/y92h/l316d/m322i、m39e/n247d/h271a、m39e/n247d/h271a/l316d、m39e/m322i、l44r/s47t/y92h/k206a/f217r/l316d/m322i、l44r/s47t/y92h/n247d/a261g/h271a/l316d/a337p/w368a、l44r/s47t/k206a/f217r/n247d/h271a/m322i、l44r/s47t/n247d/m322i/w368a、l44r/s47t/q302k/l316d/m322i、l44r/y92h/k206a/n247d/
w368a、l44r/k206a/a337p、l44r/n247d/a261g/q302k/l316d、l44r/n247d/a261g/q302k/l316d/m322i、s47t/y92h/n247d/h271a、s47t/f217r/q302k、s47t/n247d、s47t/n247d/h271a、l89i/f217r/n247d/a261g/q302k/l316d、y92h/f217r/h271a、y92h/n247d、y92h/n247d/h271a/m322i、y92h/n247d/q302k/m322i/a337p、y92h/h271a/a337p、y92h/q302k、y92h/l316d、k206a/f217r/h271a/m392t、f217r/n247d/l316d/m322i/a337p/w368a、n247d、n247d/h271a、n247d/q302k、h271a、h271a/q302k/m322i、h271a/l316d/m322i、q302k/m322i/w368a和w368a,其中所述多肽序列的氨基酸位置参考seq id no:372来编号。
[0133]
在一些实施方案中,本发明提供了与seq id no:373具有至少约85%、约86%、约87%、约88%、约89%、约90%、约91%、约92%、约93%、约94%、约95%、约96%、约97%、约98%、约99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,本发明提供了与seq id no:373具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的重组多核苷酸序列。在一些实施方案中,多核苷酸编码重组α半乳糖苷酶a,其中所述重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10/36/92/166/247/261/316/392、10/39、10/39/44/47/92/206/217、10/39/44/47/316、10/39/44/47/337、10/39/44/92/166/261/316/322、10/39/44/92/166/302/322、10/39/44/92/166/392、10/39/44/92/217/302/322、10/39/44/92/302/322、10/39/44/166/261/271/316/322、10/39/44/392、10/39/47/92/337、10/39/92/131/166/271/316/322、10/39/92/166/217/247/271、10/39/92/217/316、10/44/47/166/261/271、10/44/47/166/271/322/368、10/44/47/217/271/316/322、10/44/92、10/44/92/217/247/271/302/316/392、10/44/166/302、10/44/206/316/322、10/47/92/166/271/316/337、10/47/92/271/302、10/47/92/316/322/392、10/47/166/271、10/47/166/316、10/92/166、10/92/166/217/247/261/271、10/92/166/261/271/392、10/92/166/261/316/322/337、10/92/166/337/368、10/92/302/337、10/92/316/322、10/206、10/206/247/261、10/217/322、10/261、10/261/337/392、10/316/392、10/368、39/44/47/92/166/206/392、39/44/47/92/206/247/261、39/44/47/92/206/392、39/44/47/206/337/368/392、39/44/92/166/247/261/302/337、39/44/166/271、39/44/166/271/337/368/392、39/47/92/316/322、39/47/92/392、39/47/166/217/261/392、39/47/217/247/368、39/47/247、39/92/166/217/392、39/92/261/302、39/166/217/261/316/368、39/322、39/392、44/47、44/47/92/217/271、44/47/92/217/316/322/392、44/47/92/392、44/47/166、44/47/166/271、44/47/247/271/392、44/316/322/392、44/337、47/166/206/217/247/337、47/166/217/271/337、47/206、47/217/247/261、47/271、52/217/302/316、92/166/206/271/316、92/166/217/261/271/392、92/166/217/316/337/392、92/166/247、92/166/316、92/206/322、92/217、92/217/271/337、92/261/271、92/271、166/217/316/322/337、166/247/271/316、166/316/322/337、206/217、217/392、247/316、316/322/368和316/337/392,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重
组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:10t/36m/92y/166s/247n/261a/316l/392m、10t/39m、10t/39m/44l/47s/92y/206k/217f、10t/39m/44l/47s/316l、10t/39m/44l/47s/337a、10t/39m/44l/92y/166s/261a/316l/322m、10t/39m/44l/92y/166s/302q/322m、10t/39m/44l/92y/166s/392m、10t/39m/44l/92y/217f/302q/322m、10t/39m/44l/92y/302q/322m、10t/39m/44l/166s/261a/271h/316l/322m、10t/39m/44l/392m、10t/39m/47s/92y/337a、10t/39m/92y/131g/166s/271h/316l/322m、10t/39m/92y/166s/217f/247n/271h、10t/39m/92y/217f/316l、10t/44l/47s/166s/261a/271h、10t/44l/47s/166s/271h/322m/368w、10t/44l/47s/217f/271h/316l/322m、10t/44l/92y、10t/44l/92y/217f/247n/271h/302q/316l/392m、10t/44l/166s/302q、10t/44l/206k/316l/322m、10t/47s/92y/166s/271h/316l/337a、10t/47s/92y/271h/302q、10t/47s/92y/316l/322m/392m、10t/47s/166s/271h、10t/47s/166s/316l、10t/92y/166s、10t/92y/166s/217f/247n/261a/271h、10t/92y/166s/261a/271h/392m、10t/92y/166s/261a/316l/322m/337a、10t/92y/166s/337a/368w、10t/92y/302q/337a、10t/92y/316l/322m、10t/206k、10t/206k/247n/261a、10t/217f/322m、10t/261a、10t/261a/337a/392m、10t/316l/392m、10t/368w、39m/44l/47s/92y/166s/206k/392m、39m/44l/47s/92y/206k/247n/261a、39m/44l/47s/92y/206k/392m、39m/44l/47s/206k/337a/368w/392m、39m/44l/92y/166s/247n/261a/302q/337a、39m/44l/166s/271h、39m/44l/166s/271h/337a/368w/392m、39m/47s/92y/316l/322m、39m/47s/92y/392m、39m/47s/166s/217f/261a/392m、39m/47s/217f/247n/368w、39m/47s/247n、39m/92y/166s/217f/392m、39m/92y/261a/302q、39m/166s/217f/261a/316l/368w、39m/322m、39m/392m、44l/47s、44l/47s/92y/217f/271h、44l/47s/92y/217f/316l/322m/392m、44l/47s/92y/392m、44l/47s/166s、44l/47s/166s/271h、44l/47s/247n/271h/392m、44l/316l/322m/392m、44l/337a、47s/166s/206k/217f/247n/337a、47s/166s/217f/271h/337a、47s/206k、47s/217f/247n/261a、47s/271h、52n/217f/302q/316l、92y/166s/206k/271h/316l、92y/166s/217f/261a/271h/392m、92y/166s/217f/316l/337a/392m、92y/166s/247n、92y/166s/316l、92y/206k/322m、92y/217f、92y/217f/271h/337a、92y/261a/271h、92y/271h、166s/217f/316l/322m/337a、166s/247n/271h/316l、166s/316l/322m/337a、206k/217f、217f/392m、247n/316l、316l/322m/368w和316l/337a/392m,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。在一些实施方案中,重组α半乳糖苷酶a包含与seq id no:374具有至少85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的多肽序列或其功能片段,并且其中所述重组α半乳糖苷酶a在选自以下的一个或更多个位置处包含至少一个取代或取代集:p10t/k36m/h92y/p166s/d247n/g261a/d316l/t392m、p10t/e39m、p10t/e39m/r44l/t47s/h92y/a206k/r217f、p10t/e39m/r44l/t47s/d316l、p10t/e39m/r44l/t47s/p337a、p10t/e39m/r44l/h92y/p166s/g261a/d316l/i322m、p10t/e39m/r44l/h92y/p166s/k302q/i322m、p10t/e39m/r44l/h92y/p166s/t392m、p10t/e39m/r44l/h92y/r217f/k302q/i322m、p10t/e39m/r44l/h92y/k302q/i322m、p10t/e39m/r44l/p166s/g261a/a271h/d316l/i322m、p10t/e39m/r44l/t392m、p10t/e39m/t47s/h92y/p337a、p10t/e39m/h92y/w131g/p166s/a271h/d316l/i322m、p10t/e39m/h92y/p166s/r217f/d247n/a271h、p10t/e39m/h92y/r217f/d316l、p10t/r44l/t47s/p166s/g261a/a271h、p10t/r44l/t47s/p166s/a271h/
i322m/a368w、p10t/r44l/t47s/r217f/a271h/d316l/i322m、p10t/r44l/h92y、p10t/r44l/h92y/r217f/d247n/a271h/k302q/d316l/t392m、p10t/r44l/p166s/k302q、p10t/r44l/a206k/d316l/i322m、p10t/t47s/h92y/p166s/a271h/d316l/p337a、p10t/t47s/h92y/a271h/k302q、p10t/t47s/h92y/d316l/i322m/t392m、p10t/t47s/p166s/a271h、p10t/t47s/p166s/d316l、p10t/h92y/p166s、p10t/h92y/p166s/r217f/d247n/g261a/a271h、p10t/h92y/p166s/g261a/a271h/t392m、p10t/h92y/p166s/g261a/d316l/i322m/p337a、p10t/h92y/p166s/p337a/a368w、p10t/h92y/k302q/p337a、p10t/h92y/d316l/i322m、p10t/a206k、p10t/a206k/d247n/g261a、p10t/r217f/i322m、p10t/g261a、p10t/g261a/p337a/t392m、p10t/d316l/t392m、p10t/a368w、e39m/r44l/t47s/h92y/p166s/a206k/t392m、e39m/r44l/t47s/h92y/a206k/d247n/g261a、e39m/r44l/t47s/h92y/a206k/t392m、e39m/r44l/t47s/a206k/p337a/a368w/t392m、e39m/r44l/h92y/p166s/d247n/g261a/k302q/p337a、e39m/r44l/p166s/a271h、e39m/r44l/p166s/a271h/p337a/a368w/t392m、e39m/t47s/h92y/d316l/i322m、e39m/t47s/h92y/t392m、e39m/t47s/p166s/r217f/g261a/t392m、e39m/t47s/r217f/d247n/a368w、e39m/t47s/d247n、e39m/h92y/p166s/r217f/t392m、e39m/h92y/g261a/k302q、e39m/p166s/r217f/g261a/d316l/a368w、e39m/i322m、e39m/t392m、r44l/t47s、r44l/t47s/h92y/r217f/a271h、r44l/t47s/h92y/r217f/d316l/i322m/t392m、r44l/t47s/h92y/t392m、r44l/t47s/p166s、r44l/t47s/p166s/a271h、r44l/t47s/d247n/a271h/t392m、r44l/d316l/i322m/t392m、r44l/p337a、t47s/p166s/a206k/r217f/d247n/p337a、t47s/p166s/r217f/a271h/p337a、t47s/a206k、t47s/r217f/d247n/g261a、t47s/a271h、d52n/r217f/k302q/d316l、h92y/p166s/a206k/a271h/d316l、h92y/p166s/r217f/g261a/a271h/t392m、h92y/p166s/r217f/d316l/p337a/t392m、h92y/p166s/d247n、h92y/p166s/d316l、h92y/a206k/i322m、h92y/r217f、h92y/r217f/a271h/p337a、h92y/g261a/a271h、h92y/a271h、p166s/r217f/d316l/i322m/p337a、p166s/d247n/a271h/d316l、p166s/d316l/i322m/p337a、a206k/r217f、r217f/t392m、d247n/d316l、d316l/i322m/a368w和d316l/p337a/t392m,其中所述多肽序列的氨基酸位置参考seq id no:374来编号。
[0134]
在一些实施方案中,如上文描述的,多核苷酸编码具有本文公开的特性的具有gla活性的工程化多肽,其中该多肽包含与参考序列(例如,seqid no:2、8、58、158、372和/或374)具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多同一性的氨基酸序列,或包含表2
‑
1和/或表5
‑
1中公开的任何变体的氨基酸序列以及与参考多肽seq id no:8或表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中公开的任何变体的氨基酸序列相比的一个或更多个残基差异(例如1个、2个、3个、4个、5个、6个、7个、8个、9个、10个或更多个氨基酸残基位置)。在一些实施方案中,多核苷酸编码具有本文公开的特性的具有gla活性的工程化多肽,其中该多肽在与seq id no:8、58、158、372和/或374的多肽最佳比对时,包含与参考序列seq id no:2、8、58、158、372和/或374具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、91%、92%、93%、94%、95%、96%、97%、98%、99%或更多序列同一性的氨基酸序列,以及与seq id no:2、8、58、158、372和/或374相比的一个或更多个残基差异,所述一个或更多个残基差异位于选自表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中提供的那些残基位置处。
[0135]
在一些实施方案中,编码工程化gla多肽的多核苷酸包含seq id no:7、57、157、371和/或373的多核苷酸序列。在一些实施方案中,多核苷酸能够在高度严格的条件下与参考多核苷酸序列杂交。在一些实施方案中,参考序列选自seq id no:1、7、57、157、371和/或373或其互补序列或编码本文提供的任何变体gla多肽的多核苷酸序列。在一些实施方案中,能够在高度严格条件下杂交的多核苷酸编码包含这样的氨基酸序列的gla多肽,所述氨基酸序列与seq id no:2、8、58、158、372和/或374相比,在选自表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中列出的任何位置的残基位置处具有一个或更多个残基差异。
[0136]
在一些实施方案中,编码本文提供的任一种工程化gla多肽的分离的多核苷酸以各种方式被操作,以提供该多肽的表达。在一些实施方案中,编码多肽的多核苷酸以表达载体提供,表达载体中存在一个或更多个控制序列,以调控多核苷酸和/或多肽的表达。取决于表达载体,在将分离的多核苷酸插入载体前对分离的多核苷酸的操作可以是期望的或必要的。用于利用重组dna方法修饰多核苷酸和核酸序列的技术是本领域熟知的。
[0137]
在一些实施方案中,控制序列包括,除其它序列之外,启动子、kozak序列、前导序列、多腺苷酸化序列、前肽序列、信号肽序列、用于基因治疗保留(gene therapy retention)的基于dna的调控元件和转录终止子。如本领域已知的,合适的启动子可以基于使用的宿主细胞来选择。用于丝状真菌宿主细胞的示例性启动子包括从以下的基因获得的启动子:米曲霉(aspergillus oryzae)taka淀粉酶、米黑根毛霉(rhizomucor miehei)天冬氨酸蛋白酶、黑曲霉(aspergillus niger)中性α
‑
淀粉酶、黑曲霉酸稳定型α
‑
淀粉酶、黑曲霉或泡盛曲霉(aspergillus awamori)葡糖淀粉酶(glaa)、米黑根毛霉脂肪酶、米曲霉碱性蛋白酶、米曲霉磷酸丙糖异构酶、构巢曲霉(aspergillus nidulans)乙酰胺酶和尖孢镰刀菌(fusarium oxysporum)胰蛋白酶样蛋白酶(参见,例如wo 96/00787),以及na2
‑
tpi启动子(来自黑曲霉中性α
‑
淀粉酶基因和米曲霉磷酸丙糖异构酶基因的启动子的杂合体),和其突变体、截短的和杂合的启动子。示例性酵母细胞启动子可以来自以下的基因:酿酒酵母(saccharomyces cerevisiae)烯醇酶(eno
‑
1)、酿酒酵母半乳糖激酶(gal1)、酿酒酵母醇脱氢酶/甘油醛
‑3‑
磷酸脱氢酶(adh2/gap)和酿酒酵母3
‑
磷酸甘油酸激酶。用于酵母宿主细胞的其他有用的启动子是本领域已知的(参见例如,romanos等人,yeast 8:423
‑
488[1992])。用于在哺乳动物细胞中使用的示例性启动子包括但不限于,来自巨细胞病毒(cmv)的启动子、与cmv增强子融合的鸡β
‑
肌动蛋白启动子、猿猴空泡病毒40(sv40)的启动子、来自智人(homo sapiens)的磷酸甘油酸激酶、来自β
‑
肌动蛋白、延伸因子
‑
1a或甘油醛
‑3‑
磷酸脱氢酶的启动子或来自原鸡(gallusgallus)β
‑
肌动蛋白的启动子。
[0138]
在一些实施方案中,控制序列为合适的转录终止子序列,转录终止子序列是由宿主细胞识别以终止转录的序列。终止子序列被可操作地连接至编码多肽的核酸序列的3'末端。在选择的宿主细胞中有功能的任何终止子可用于本发明中。例如,用于丝状真菌宿主细胞的示例性转录终止子可以从以下的基因获得:米曲霉taka淀粉酶、黑曲霉葡糖淀粉酶、构巢曲霉邻氨基苯甲酸合酶、黑曲霉α
‑
葡萄糖苷酶和尖孢镰刀菌胰蛋白酶样蛋白酶。用于酵母宿主细胞的示例性终止子可以从以下的基因获得:酿酒酵母烯醇酶、酿酒酵母细胞色素c(cyc1)和酿酒酵母甘油醛
‑3‑
磷酸脱氢酶。用于酵母宿主细胞的其他有用的终止子是本领域已知的(参见例如,romanos等,上文)。用于哺乳动物细胞的示例性终止子包括但不限于来自巨细胞病毒(cmv)、猿猴空泡病毒40(sv40)、来自智人生长激素hgh、来自牛生长激素
bgh和来自人或兔β球蛋白的终止子。
[0139]
在一些实施方案中,控制序列是合适的前导序列、5'
‑
帽修饰、5'utr等。在一些实施方案中,这些调控序列元件介导与涉及mrna转运和翻译的分子的结合,抑制5'
‑
外切核酸酶降解并赋予对脱帽的耐受性。前导序列被可操作地连接至编码多肽的核酸序列的5'末端。可以使用在所选择的宿主细胞中有功能的任何前导序列。用于丝状真菌宿主细胞的示例性前导序列从以下的基因获得:米曲霉taka淀粉酶和构巢曲霉磷酸丙糖异构酶。用于酵母宿主细胞的合适的前导序列包括但不限于从以下的基因获得的那些:酿酒酵母烯醇化酶(eno
‑
1)、酿酒酵母3
‑
磷酸甘油酸激酶、酿酒酵母α
‑
因子和酿酒酵母醇脱氢酶/甘油醛
‑3‑
磷酸脱氢酶(adh2/gap)。用于哺乳动物宿主细胞的合适的先导序列包括但不限于正痘病毒属(orthopoxvirus)mrna中存在的5'
‑
utr元件。
[0140]
在一些实施方案中,控制序列包括3'非翻译核酸区和多腺苷酸化尾核酸序列,这些序列可操作地连接至蛋白编码核酸序列的3'末端,介导与涉及mrna转运和翻译以及mrna半衰期的蛋白的结合。在所选择的宿主细胞中有功能的任何多腺苷酸化序列和3'
‑
utr可用于本发明。用于丝状真菌宿主细胞的示例性多腺苷酸化序列包括但不限于来自以下的基因的那些:米曲霉taka淀粉酶、黑曲霉葡糖淀粉酶、构巢曲霉邻氨基苯甲酸合酶、尖孢镰刀菌胰蛋白酶样蛋白酶和黑曲霉α
‑
葡糖苷酶。用于酵母宿主细胞的有用的多腺苷酸化序列也是本领域已知的(参见例如,guo和sherman,mol.cell.biol.,15:5983
‑
5990[1995])。用于哺乳动物宿主细胞的有用的多腺苷酸化序列和3'utr序列包括但不限于α球蛋白和β球蛋白mrna的3'
‑
utr,所述3'
‑
utr含有若干个增加mrna的稳定性和翻译的序列元件。
[0141]
在一些实施方案中,控制序列为信号肽编码区,所述信号肽编码区编码连接至多肽的氨基末端的氨基酸序列并将编码的多肽引导到细胞的分泌途径中。核酸序列的编码序列的5'末端可以固有地包含信号肽编码区,所述信号肽编码区符合翻译阅读框地(in translation reading frame)与编码分泌多肽的编码区的区段天然地连接。可选地,编码序列的5'末端可以包含对编码序列是外源的信号肽编码区。将表达的多肽引导到选择的宿主细胞的分泌途径中的任何信号肽编码区可用于本文提供的工程化gla多肽的表达。用于丝状真菌宿主细胞的有效的信号肽编码区包括但不限于从以下的基因获得的信号肽编码区:米曲霉taka淀粉酶、黑曲霉中性淀粉酶、黑曲霉葡糖淀粉酶、米黑根毛霉天冬氨酸蛋白酶、特异腐质霉(humicola insolens)纤维素酶和绵毛状腐质霉(humicola lanuginosa)脂肪酶。用于酵母宿主细胞的有用的信号肽包括但不限于来自以下的基因的信号肽:酿酒酵母α因子和酿酒酵母转化酶。用于哺乳动物宿主细胞的有用的信号肽包括但不限于来自免疫球蛋白γ(igg)基因的信号肽。
[0142]
在一些实施方案中,控制序列为前肽编码区,所述前肽编码区编码定位在多肽的氨基末端处的氨基酸序列。产生的多肽被称为“前酶(proenzyme)”、“前多肽(propolypeptide)”或在某些情况下称为“酶原(zymogen)”。前多肽可以通过催化或自体催化前肽从前多肽的裂解被转化为成熟活性多肽。
[0143]
在另一方面,本发明还提供了重组表达载体,所述重组表达载体包含编码工程化gla多肽的多核苷酸和取决于多核苷酸被引入的宿主细胞的类型的一个或更多个表达调控区域,诸如启动子和终止子、复制起点等。在一些实施方案中,将以上描述的各种核酸和控制序列连接在一起以产生重组表达载体,所述重组表达载体包含一个或更多个方便的限制
位点以允许编码变体gla多肽的核酸序列在此类位点处插入或取代。可选地,本发明的多核苷酸序列通过将多核苷酸序列或包含该多核苷酸的核酸构建体插入适当的表达载体来表达。在产生表达载体时,编码序列位于载体中,使得编码序列与用于表达的适当的控制序列可操作地连接。
[0144]
重组表达载体可以是任何载体(例如,质粒或病毒,包括但不限于腺病毒(av)、腺相关病毒(aav)、慢病毒(lv)和非病毒载体,诸如脂质体),该载体可以方便地进行重组dna程序,并可以导致变体gla多核苷酸序列的表达。载体的选择通常将取决于载体与待引入载体的宿主细胞的相容性。载体可以是线性质粒或闭合的环状质粒。
[0145]
在一些实施方案中,表达载体是自主复制载体(即,作为染色体外实体存在的载体,其复制独立于染色体复制,诸如质粒、染色体外元件、微型染色体或人工染色体)。载体可以包含用于确保自我复制的任何工具(means)。在一些可选的实施方案中,载体可以是当被引入到宿主细胞中时,被整合到基因组中并与其被整合进的染色体一起复制的载体。此外,可以使用单一载体或质粒或者一起包含待引入到宿主细胞基因组中的总dna的两种或更多种载体或质粒,或者转座子。
[0146]
在一些实施方案中,表达载体优选地包含一个或更多个选择标志物,其允许容易选择经转化的细胞。“选择标志物”是一种基因,其产物提供杀生物剂或病毒耐受性、对重金属的耐受性、对营养缺陷型提供原养型等。用于酵母宿主细胞的合适的标志物包括但不限于ade2、his3、leu2、lys2、met3、trp1和ura3。用于在丝状真菌宿主细胞中使用的选择标志物包括但不限于amds(乙酰胺酶)、argb(鸟氨酸氨甲酰基转移酶)、bar(膦丝菌素乙酰基转移酶)、hph(潮霉素磷酸转移酶)、niad(硝酸盐还原酶)、pyrg(乳清酸核苷
‑
5'
‑
磷酸脱羧酶)、sc(硫酸腺苷酰转移酶(sulfate adenyltransferase))和trpc(邻氨基苯甲酸合酶)以及其等效物。在另一方面,本发明提供了包含编码本技术的至少一种工程化gla多肽的多核苷酸的宿主细胞,所述多核苷酸被可操作地连接至一个或更多个控制序列,用于在宿主细胞中表达工程化gla酶。用于表达由本发明的表达载体编码的多肽的宿主细胞是本领域熟知的,并且包括但不限于真菌细胞,诸如酵母细胞(例如,酿酒酵母和巴斯德毕赤酵母(pichia pastoris)[例如,atcc登录号201178]);昆虫细胞(例如,果蝇属(drosophila)s2和夜蛾属(spodoptera)sf9细胞)、植物细胞、动物细胞(例如,cho、cho
‑
k1、cos和bhk)和人类细胞(例如,hek293t、人类成纤维细胞、thp
‑
1、jurkat和bowes黑素瘤细胞系)。
[0147]
因此,在另一方面,本发明提供了用于产生工程化gla多肽的方法,其中该方法包括将能够表达编码工程化gla多肽的多核苷酸的宿主细胞在适于表达该多肽的条件下培养。在一些实施方案中,该方法还包括分离和/或纯化如本文描述的gla多肽的步骤。
[0148]
用于上文描述的宿主细胞的适当的培养基和生长条件是本领域熟知的。用于表达gla多肽的多核苷酸可以通过本领域已知的各种方法引入到细胞中。技术包括尤其是电穿孔、生物弹射粒子轰击(biolistic particle bombardment)、脂质体介导的转染、氯化钙转染和原生质体融合。
[0149]
具有本文公开的特性的工程化gla可以通过使编码天然存在或工程化的gla多肽的多核苷酸经受本领域已知和/或如本文描述的诱变和/或定向演化方法来获得。示例性定向演化技术为诱变和/或dna改组(参见例如,stemmer,proc.natl.acad.sci.usa 91:10747
‑
10751[1994];wo 95/22625;wo 97/0078;wo 97/35966;wo 98/27230;wo 00/42651;
wo 01/75767和美国专利6,537,746)。可以使用的其他定向演化程序包括交错延伸过程(step)、体外重组(参见例如,zhao等人,nat.biotechnol.,16:258
‑
261[1998])、诱变pcr(参见例如,caldwell等人,pcr methods appl.,3:s136
‑
s140[1994])和盒式诱变(参见例如,black等人,proc.natl.acad.sci.usa 93:3525
‑
3529[1996])以及其他。
[0150]
例如,诱变和定向演化方法可以容易地应用于多核苷酸,以生成可以被表达、筛选和测定的变体文库。诱变和定向演化方法是本领域熟知的(参见例如,美国专利号5,605,793、5,811,238、5,830,721、5,834,252、5,837,458、5,928,905、6,096,548、6,117,679、6,132,970、6,165,793、6,180,406、6,251,674、6,277,638、6,287,861、6,287,862、6,291,242、6,297,053、6,303,344、6,309,883、6,319,713、6,319,714、6,323,030、6,326,204、6,335,160、6,335,198、6,344,356、6,352,859、6,355,484、6,358,740、6,358,742、6,365,377、6,365,408、6,368,861、6,372,497、6,376,246、6,379,964、6,387,702、6,391,552、6,391,640、6,395,547、6,406,855、6,406,910、6,413,745、6,413,774、6,420,175、6,423,542、6,426,224、6,436,675、6,444,468、6,455,253、6,479,652、6,482,647、6,489,146、6,506,602、6,506,603、6,519,065、6,521,453、6,528,311、6,537,746、6,573,098、6,576,467、6,579,678、6,586,182、6,602,986、6,613,514、6,653,072、6,716,631、6,946,296、6,961,664、6,995,017、7,024,312、7,058,515、7,105,297、7,148,054、7,288,375、7,421,347、7,430,477、7,534,564、7,620,500、7,620,502、7,629,170、7,702,464、7,747,391、7,747,393、7,751,986、7,776,598、7,783,428、7,795,030、7,853,410、7,868,138、7,873,499、7,904,249、7,957,912、8,383,346、8,504,498、8,849,575、8,876,066、8,768,871、9,593,326以及所有相关的非美国的对应申请;ling等人,anal.biochem.,254(2):157
‑
78[1997];dale等人,meth.mol.biol.,57:369
‑
74[1996];smith,ann.rev.genet.,19:423
‑
462[1985];botstein等人,science,229:1193
‑
1201[1985];carter,biochem.j.,237:1
‑
7[1986];kramer等人,cell,38:879
‑
887[1984];wells等人,gene,34:315
‑
323[1985];minshull等人,curr.op.chem.biol.,3:284
‑
290[1999];christians等人,nat.biotechnol.,17:259
‑
264[1999];crameri等人,nature,391:288
‑
291[1998];crameri等人,nat.biotechnol.,15:436
‑
438[1997];zhang等人,proc.nat.acad.sci.u.s.a.,94:4504
‑
4509[1997];crameri等人,nat.biotechnol.,14:315
‑
319[1996];stemmer,nature,370:389
‑
391[1994];stemmer,proc.nat.acad.sci.usa,91:10747
‑
10751[1994];美国专利申请公布号2008/0220990、us 2009/0312196、us2014/0005057、us2014/0214391、us2014/0221216、us2015/0050658、us2015/0133307、us2015/0134315和所有相关的非美国的对应专利申请;wo 95/22625、wo 97/0078、wo 97/35966、wo 98/27230、wo 00/42651、wo 01/75767和wo 2009/152336;所有这些通过引用并入本文)。
[0151]
在一些实施方案中,诱变处理后获得的酶变体通过使酶变体经受指定的温度(或其他测定条件)并测量热处理或其他测定条件之后剩余的酶活性的量来筛选。然后从宿主细胞中分离包含编码gla多肽的多核苷酸的dna,测序以鉴定核苷酸序列改变(如果有的话),并用于在不同或相同的宿主细胞中表达该酶。测量来自表达文库的酶活性可以使用本领域已知的任何合适的方法(例如,标准生物化学技术,诸如hplc分析)来进行。
[0152]
对于已知序列的工程化多肽,编码酶的多核苷酸可以根据已知的合成方法通过标准的固相方法制备。在一些实施方案中,多达约100个碱基的片段可以被单独合成、然后被
连接(例如,通过酶促或化学连接方法或聚合酶介导的方法)以形成任何期望的连续序列。例如,本文公开的多核苷酸和寡核苷酸可以使用经典的亚磷酰胺方法(参见例如,beaucage等人,tetra.lett.,22:1859
‑
69[1981]和matthes等人,embo j.,3:801
‑
05[1984]),如通常在自动化合成方法中所实践的,通过化学合成制备。根据亚磷酰胺方法,寡核苷酸被合成(例如,在自动dna合成仪中)、纯化、退火、连接并克隆入适当的载体。
[0153]
因此,在一些实施方案中,用于制备工程化gla多肽的方法可以包括:(a)合成编码多肽的多核苷酸,所述多肽包含选自表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1和/或表9
‑
1中提供的任何变体氨基酸序列的氨基酸序列,以及seq id no:8、58、158、372和/或374,和(b)表达由该多核苷酸编码的gla多肽。在该方法的一些实施方案中,由多核苷酸编码的氨基酸序列可以任选地具有一个或若干个(例如,最多3个、4个、5个或最多10个)氨基酸残基缺失、插入和/或取代。在一些实施方案中,氨基酸序列任选地具有1
‑
2个、1
‑
3个、1
‑
4个、1
‑
5个、1
‑
6个、1
‑
7个、1
‑
8个、1
‑
9个、1
‑
10个、1
‑
15个、1
‑
20个、1
‑
21个、1
‑
22个、1
‑
23个、1
‑
24个、1
‑
25个、1
‑
30个、1
‑
35个、1
‑
40个、1
‑
45个或1
‑
50个氨基酸残基缺失、插入和/或取代。在一些实施方案中,氨基酸序列任选地具有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、17个、18个、19个、20个、21个、22个、23个、24个、25个、30个、30个、35个、40个、45个或50个氨基酸残基缺失、插入和/或取代。在一些实施方案中,氨基酸序列任选地具有1个、2个、3个、4个、5个、6个、7个、8个、9个、10个、11个、12个、13个、14个、15个、16个、18个、20个、21个、22个、23个、24个或25个氨基酸残基缺失、插入和/或取代。在一些实施方案中,取代可以是保守取代或非保守取代。
[0154]
可以使用本领域已知的任何合适的测定,包括但并不限于本文描述的测定和条件,评估所表达的工程化gla多肽的任何期望的改进特性(例如,活性、选择性、稳定性、酸耐受性、蛋白酶敏感性等)。
[0155]
在一些实施方案中,使用用于蛋白纯化的熟知技术中的任何一种或更多种,将在宿主细胞中表达的工程化gla多肽的任一种从细胞和/或培养基中回收,用于蛋白纯化的熟知技术除了其他以外包括,溶菌酶处理、超声处理、过滤、盐析、超离心和色谱法。
[0156]
用于分离gla多肽的色谱技术,除了其他以外,包括,反相色谱法、高效液相色谱法、离子交换色谱法、疏水相互作用色谱法、凝胶电泳和亲和色谱法。用于纯化特定酶的条件部分地取决于因素诸如净电荷、疏水性、亲水性、分子量、分子形状等,并且对本领域技术人员将是明显的。在一些实施方案中,亲和技术可以用于分离改进的变体gla酶。在利用亲和色谱法纯化的一些实施方案中,可使用特异性结合变体gla多肽的任何抗体。在一些利用亲和色谱法纯化的实施方案中,可使用与共价附接至gla的聚糖结合的蛋白。在利用亲和色谱法纯化的还其他实施方案中,可使用任何与gla活性位点结合的小分子。为了产生抗体,通过注射gla多肽(例如,gla变体)或其片段来免疫各种宿主动物,包括但不限于兔、小鼠、大鼠等。在一些实施方案中,gla多肽或片段通过侧链官能团或附接至侧链官能团的接头的方式附接至合适的载体,诸如bsa。
[0157]
在一些实施方案中,工程化gla多肽通过包括以下的方法在宿主细胞中产生:将包含编码如本文描述的工程化gla多肽的多核苷酸序列的宿主细胞(例如,酿酒酵母、胡萝卜(daucus carota)、烟草(nicotiana tabacum)、智人(例如,hek293t)或灰仓鼠(cricetulus griseus)(例如,cho))在有利于工程化gla多肽产生的条件下培养,并从细胞和/或培养基
回收工程化gla多肽。
[0158]
在一些实施方案中,本发明包括产生工程化gla多肽的方法,该方法包括在合适的培养条件下培养重组真核细胞,以允许产生工程化gla多肽,并任选地从培养基和/或培养的细胞回收工程化gla多肽,所述重组真核细胞包含编码工程化gla多肽的多核苷酸序列,当与seq id no:8、58、158、372和/或374的氨基酸序列最佳比对时,所述工程化gla多肽与参考序列(例如,seq id no:8、58、158、372和/或374)具有至少80%、81%、82%、83%、84%、85%、86%、87%、88%、89%、90%、95%、96%、97%、98%、99%或100%的序列同一性,以及与seq id no:8相比的一个或更多个氨基酸残基差异,所述一个或更多个氨基酸残基差异选自表2
‑
1、表5
‑
1、表6
‑
1、表7
‑
1、表8
‑
1、表9
‑
1中提供的那些氨基酸残基差异和/或其组合。
[0159]
在一些实施方案中,将工程化gla多肽从重组宿主细胞或细胞培养基回收后,将它们通过本领域已知的任何合适的方法进一步纯化。在一些另外的实施方案中,将纯化的gla多肽与其他成分和化合物组合,来提供适用于不同应用和用途的包含工程化gla多肽的组合物和制剂(例如,药物组合物)。在一些另外的实施方案中,纯化的工程化gla多肽或配制的工程化gla多肽被冻干。在一些实施方案中,工程化gla多肽直接在体内(即,在诸如人类或另一种动物的体内的细胞中)产生并且不被纯化。然而,在一些可选的实施方案中,工程化gla多肽在体内(即,在诸如人类或另一种动物的体内的细胞中)产生,并使用本领域已知的方法从体内收集。在一些另外的实施方案中,这些收集的工程化gla多肽被纯化。在又一些另外的实施方案中,将这些收集的和/或纯化的工程化多肽引入另一种动物(例如,人类或另一种动物)中或重新引入最初产生收集的和/或纯化的工程化gla多肽的体内。
[0160]
组合物:
[0161]
本发明提供了各种组合物和形式,包括但不限于下文描述的那些。在一些实施方案中,本发明提供了工程化gla多肽,所述工程化gla多肽适于在药物组合物和其他组合物诸如膳食/营养补充物中使用。
[0162]
取决于施用方式,包含治疗有效量的根据本发明的工程化gla的这些组合物呈固体、半固体或液体的形式。在一些实施方案中,组合物包括其他药学上可接受的组分,诸如稀释剂、缓冲液、赋形剂、盐、乳化剂、防腐剂、稳定剂、填料和其他成分。用于配制和施用的技术的细节是本领域熟知的,并在文献中被描述。在一些实施方案中,这些组合物在作为基因治疗引入后直接在人体内产生。
[0163]
在一些实施方案中,配制了工程化gla多肽用于在口服药物组合物中使用。用于在递送工程化gla多肽中使用的任何合适的形式可用于本发明,所述形式包括但不限于丸剂、片剂、凝胶片(gel tab)、胶囊、锭剂、糖衣丸、粉末、软凝胶、溶胶凝胶、凝胶、乳剂、植入物、贴剂、喷雾剂、软膏剂、搽剂、霜剂、糊剂、凝胶剂、涂剂、气雾剂、口香糖、缓和剂(demulcent)、条状物、溶液、悬浮液(包括但不限于油基悬浮液、水包油乳剂等)、浆液、糖浆剂、控释制剂、栓剂等。在一些实施方案中,工程化gla多肽以适于注射或输注的形式提供(即,以可注射制剂的形式)。在一些实施方案中,工程化gla多肽的多核苷酸序列以适于注射的形式提供。在一些实施方案中,工程化gla多肽以生物相容性基质诸如溶胶凝胶(包括基于二氧化硅(例如,氧基硅烷(oxysilane))的溶胶凝胶)提供。在一些实施方案中,将工程化gla多肽封装。在一些可选择的实施方案中,将工程化gla多肽封装在纳米结构(例如,纳
米管、纳米小管、纳米胶囊或微米胶囊、微球体、脂质体等)中。实际上,不意图本发明受限于任何特定递送制剂和/或递送方式。意图工程化gla多肽通过本领域已知的任何合适的方式来施用,包括但不限于:肠胃外、口服、局部、经皮、鼻内、眼内、鞘内、经由植入物等。
[0164]
在一些实施方案中,工程化gla多肽通过糖基化、化学交联试剂、聚乙二醇化(即,用聚乙二醇[peg]或活化的peg等修饰)或其他化合物被化学修饰(参见例如,ikeda,amino acids 29:283
‑
287[2005];美国专利号7,531,341、7,534,595、7,560,263和7,53,653;美国专利申请公布号2013/0039898、2012/0177722等)。实际上,不意图本发明受限于任何特定递送方法和/或机制。
[0165]
在一些另外的实施方案中,工程化gla多肽被提供,用于通过基因治疗(包括病毒递送载体,包括但不限于腺病毒(av)、腺相关病毒(aav)、慢病毒(lv)或非病毒载体(例如,脂质体))递送至细胞或组织。在一些实施方案中,工程化gla多肽被提供,用于以封装递送(诸如脂质体)配制多核糖核苷酸序列之后,通过mrna治疗递送至细胞或组织。在一些另外的实施方案中,工程化gla多肽被提供,用于通过细胞疗法递送至细胞或组织,其中编码工程化gla多肽的多核苷酸序列被引入外源性细胞,并且该细胞(或多于一个细胞)被引入受者(例如,表现出法布里病或处于发展法布里病风险的患者)中。
[0166]
在一些另外的实施方案中,工程化gla多肽在包含基质稳定的酶晶体的制剂中来提供。在一些实施方案中,该制剂包含交联的结晶工程化gla酶和具有附接至酶晶体的反应部分的聚合物。本发明还以聚合物提供了工程化gla多肽。
[0167]
在一些实施方案中,包含本发明的工程化gla多肽的组合物包括一种或更多种常用的载体化合物,包括但不限于糖(例如,乳糖、蔗糖、甘露糖醇和/或山梨糖醇)、淀粉(例如,玉米淀粉、小麦淀粉、大米淀粉、马铃薯淀粉或其他植物淀粉)、纤维素(例如,甲基纤维素、羟丙基甲基纤维素、羧甲基纤维素钠)、树胶(例如,阿拉伯胶、黄芪胶、瓜尔胶等)和/或蛋白(例如,明胶、胶原等)。
[0168]
在一些实施方案中,本发明提供了适用于降低流体(诸如血液、脑脊液等)中糖脂浓度的工程化gla多肽。施用的工程化gla多肽的剂量取决于状况或疾病、受试者的一般状况以及本领域技术人员已知的其他因素。在一些实施方案中,意图将组合物单次或多于一次施用。在一些实施方案中,设想施用至患有法布里病的人类的组合物中工程化gla多肽的浓度足以有效治疗和/或改善疾病(例如,法布里病)。在一些实施方案中,工程化gla多肽与其他药物和/或膳食组合物组合施用。
[0169]
实验
[0170]
提供了以下实施例,包括实验和获得的结果,仅用于说明性目的,而不应当被解释为限制本发明。
[0171]
在以下实验公开内容中,以下缩写适用:ppm(百万分率(parts per million));m(摩尔/升)、mm(毫摩尔/升)、um和μm(微摩尔/升)、nm(纳摩尔/升)、mol(摩尔)、gm和g(克)、mg(毫克)、ug和μg(微克)、l和l(升)、ml和ml(毫升)、cm(厘米)、mm(毫米)、um和μm(微米)、sec.(秒)、min(s)(分钟)、h(s)和hr(s)(小时)、u(单位)、mw(分子量)、rpm(转/分钟)、℃(摄氏度)、cds(编码序列)、dna(脱氧核糖核酸)、rna(核糖核酸)、大肠杆菌w3110(常用的实验室大肠杆菌菌株,从大肠杆菌遗传资源中心(coli genetic stock center)[cgsc],new haven,ct可获得)、hplc(高效液相色谱法)、mwco(分子量截止值)、sds
‑
page(十二烷基硫酸
钠聚丙烯酰胺凝胶电泳)、pbs(磷酸盐缓冲盐水)、dpbs(杜氏磷酸盐缓冲盐水)、pes(聚醚砜)、cfse(羧基荧光素琥珀酰亚胺酯)、iptg(异丙基β
‑
d
‑1‑
硫代吡喃半乳糖苷)、pmbs(硫酸多粘菌素b)、nadph(烟酰胺腺嘌呤二核苷酸磷酸)、gidh(谷氨酸脱氢酶)、fiopc(相对于阳性对照的改进倍数)、pbmc(外周血单个核细胞)、lb(luria肉汤)、meoh(甲醇)、athens research(athens research technology,athens,ga);prospec(prospec tany technogene,east brunswick,nj);sigma
‑
aldrich(sigma
‑
aldrich,st.louis,mo);ram scientific(ram scientific,inc.,yonkers,ny);pall corp.(pall,corp.,pt.washington,ny);millipore(millipore,corp.,billerica ma);difco(difco laboratories,bd diagnostic systems,detroit,mi);molecular devices(molecular devices,llc,sunnyvale,ca);kuhner(adolf kuhner,ag,basel,switzerland);axygen(axygen,inc.,union city,ca);toronto research chemicals(toronto research chemicals inc.,toronto,ontario,canada);cambridge isotope laboratories,(cambridge isotope laboratories,inc.,tewksbury,ma);applied biosystems(applied biosystems,life technologies,corp.的一部分,grand island,ny),agilent(agilent technologies,inc.,santa clara,ca);thermo scientific(thermofisher scientific的一部分,waltham,ma);gibco(thermofisher scientific);pierce(pierce biotechnology(现为thermo fisher scientific的一部分),rockford,il);thermofisher scientific(thermo fisher scientific,waltham,ma);corning(corning,inc.,palo alto,ca);xenotech(sekisui xenotech,llc,kansas city,ks);coriell institute for medical research(coriell institute for medical research,camden,nj);vwr(vwr international,radnor,pa);jackson(the jackson laboratory,bar harbor,me);megazyme(megazyme international,wicklow,ireland);enzo(enzo life sciences,inc.,farmingdale,ny);ge healthcare(ge healthcare bio
‑
sciences,piscataway,nj);li
‑
cor(li
‑
corbiotechnology,lincoln,ne);amicus(amicus therapeutics,cranbury,nj);phenomenex(phenomenex,inc.,torrance,ca);optimal(optimal biotech group,belmont,ca)以及bio
‑
rad(bio
‑
rad laboratories,hercules,ca)。
[0172]
以下多核苷酸序列和多肽序列可用于本发明。在一些情况下(如下文示出的),多核苷酸序列后面是所编码的多肽。
[0173]
全长人类gla cdna的多核苷酸序列(seq id no.1):
[0174][0175]
全长人类gla的多肽序列:
[0176][0177]
成熟的酵母密码子优化(ycds)的人类gla的多核苷酸序列:
[0178][0179]
[0180]
成熟的人类gla(天然hcds)的多核苷酸序列:
[0181][0182]
成熟的人类gla的多肽序列:
[0183][0184]
pck110900i大肠杆菌表达载体的多核苷酸序列:
[0185]
[0186]
[0187][0188]
pyt
‑
72bgl分泌型酵母表达载体的多核苷酸序列:
[0189]
[0190]
[0191]
[0192]
[0193]
[0194][0195]
变体no.73 ycds的多核苷酸序列:
[0196][0197]
变体no.73的多核苷酸序列:
[0198][0199]
[0200]
变体no.73的多肽序列:
[0201][0202]
变体no.218 ycds的多核苷酸序列:
[0203][0204]
变体no.218 hcds的多核苷酸序列:
[0205][0206][0207]
变体no.218的多肽序列:
[0208][0209]
变体no.326 ycds的多核苷酸序列:
[0210][0211]
变体no.326的多肽序列:
[0212][0213][0214]
变体no.206 ycds的多核苷酸序列:
[0215][0216]
变体no.206 hcds的多核苷酸序列:
[0217][0218]
变体no.206的多肽序列:
[0219][0220]
变体no.205 ycds的多核苷酸序列:
[0221][0222]
变体no.205 hcds的多核苷酸序列:
[0223][0224][0225]
变体no.205的多肽序列:
[0226][0227]
变体no.76 ycds的多核苷酸序列:
[0228][0229]
变体no.76 hcds的多核苷酸序列:
[0230][0231][0232]
变体no.76的多肽序列:
[0233][0234]
mfα信号肽的多核苷酸序列:
[0235]
[0236]
mfα信号肽的多肽序列:
[0237][0238]
mmo435的多核苷酸序列:
[0239][0240]
mmo439的多核苷酸序列:
[0241][0242]
mmo514的多核苷酸序列:
[0243][0244]
mmo481的多核苷酸序列:
[0245][0246]
合成哺乳动物信号肽的多核苷酸序列:
[0247]
lake fw的多核苷酸序列:
[0248][0249]
br反向的多核苷酸序列:
[0250][0251]
brfw的多核苷酸序列:
[0252][0253]
hgla rv的多核苷酸序列:
[0254][0255]
sp
‑
gla(ycds)的多核苷酸序列:
[0256][0257]
mf前导
‑
gla(ycds)的多核苷酸序列:
[0258][0259][0260]
mf前导的多肽序列:
[0261][0262]
变体no.395 ycds的多核苷酸序列:
[0263][0264]
变体no.395的多肽序列:
[0265][0266]
变体no.402 ycds的多核苷酸序列:
[0267][0268]
变体no.402的多肽序列:
[0269][0270]
变体no.625 ycds的多核苷酸序列:
[0271][0272][0273]
变体no.625的多肽序列:
[0274][0275]
变体no.648 ycds的多核苷酸序列:
[0276][0277]
变体no.648的多肽序列:
[0278][0279]
实施例1
[0280]
gla基因获得及表达载体的构建
[0281]
编码wt人类gla序列(seq id no:2)的合成基因(seq id no:1)和衍生变体(seq id no:4、seq id no:6)如前所述构建(参见例如美国专利申请公布第2017/0360900a1号)。为了在哺乳动物细胞中分泌表达和瞬时转染,如下产生嵌合gla表达构建体,该嵌合gla表达构建体包含与编码不同gla变体的合成基因融合的编码合成小鼠ig信号肽的多核苷酸。使用寡核苷酸bamhi
‑
pcdna
‑
gla
‑
f(seq id no:63)和xhoi
‑
pcdna
‑
gla
‑
r(seq id no:64)来扩增编码信号肽的片段和成熟形式的gla变体的编码序列。将pcr产物连接到bamhi/xhoi线性化的哺乳动物表达载体pcdna3.1(+)(invitrogen)中。使用本领域技术人员通常已知的定向演化技术产生源自该质粒构建体中的seq id no:8的基因变体(参见例如,美国专利第8,383,346号和wo2010/144103)。
[0282]
实施例2
[0283]
高通量生长和测定
[0284]
gla和gla变体的高通量(htp)生长
[0285]
用3000试剂(thermofisher scientific)使用脂质体转染方法,用编码与野生型gla或gla变体融合的合成小鼠ig信号肽的pcdna 3.1(+)载体转染
hek 293t细胞。hek 293t细胞在生长培养基(含有10%胎牛血清的dmem[两者均来自corning])中进行培养。转染前24小时,将细胞以105个细胞/孔/250μl生长培养基中的密度接种到edge 2.096孔板(thermofisher scientific),并在培养箱中在37℃、5%co2培养。将细胞在37℃和5%co2培养24
‑
72小时,以允许gla变体的表达和分泌。将来自hek293t转染的条件培养基(50
‑
100μl)转移到corning 96孔实心黑色板(corning)中,用于活性分析和/或稳定性分析。
[0286]
上清液的htp分析
[0287]
gla变体活性通过测量4
‑
甲基伞形基α
‑
d
‑
吡喃半乳糖苷(4
‑
methylumbelliferylα
‑
d
‑
galactopyranoside,mugal)的水解来确定。对于未挑战测定,在96孔黑色不透明底部微量滴定板中,将50μl如上文描述产生的hek 293t条件培养基与50μl mcilvaine缓冲液(mcilvaine,j.biol.chem.,49:183
‑
186[1921])ph 4.8中的1mm mugal混合。将反应物短暂混合,并在37℃孵育30
‑
180分钟,然后用100μl 0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。来自该测定的结果呈现于表2
‑
1中。
[0288]
用酸预处理的上清液的htp分析
[0289]
用酸性缓冲液对gla变体进行挑战,以模拟变体在溶酶体内可能遇到的极端ph。首先,将50μl hek 293t条件培养基和50ul mcilvaine缓冲液(ph 3.3
‑
4.3)添加到96孔圆底微量滴定板的孔中。将板用热微量板密封器(agilent)密封,并在37℃孵育1
‑
2h。对于ph 4挑战测定,将50μl酸ph挑战的样品与50ul mcilvaine缓冲液ph 4.4中的1mm mugal混合。将反应物短暂混合,并在37℃孵育30
‑
180分钟,然后用100μl 0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。来自该测定的结果呈现于表2
‑
1中。
[0290]
用碱预处理的上清液的htp分析
[0291]
用碱性(中性)缓冲液对gla变体进行挑战,以模拟变体在施用至患者后在血液中遇到的ph。首先,将50μl gla变体hek 293t条件培养基和50μl mcilvaine缓冲液(ph 7.0
‑
8.2)添加到96孔圆底微量滴定板的孔中。将板密封,并在37℃孵育1
‑
18h。对于ph 7挑战测定,将50μl碱性ph挑战的样品与50μl mcilvaine缓冲液ph 4.4中的1mm mugal混合。将反应物短暂混合,并在37℃孵育30
‑
180分钟,然后用100μl 0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。来自该测定的结果呈现于表2
‑
1中。
[0292]
[0293][0294]
实施例3
[0295]
gla变体的产生
[0296]
在hek293t细胞中产生gla
[0297]
在哺乳动物细胞中gla变体的分泌表达通过瞬时转染hek293或hek293t细胞来进行。用与n末端合成哺乳动物信号肽融合的gla变体(seq id no:3、4、9、12、17、20、23和41)(并亚克隆到哺乳动物表达载体plev113中)转染细胞,如实施例1中描述的。使用本领域技术人员已知的标准技术,用质粒dna转染hek293细胞并在悬浮液中生长4天。收集上清液并储存于4℃直至分析。
[0298]
实施例4
[0299]
gla变体的纯化
[0300]
从哺乳动物细胞上清液纯化gla变体
[0301]
wt gla(seq id no:2)从哺乳动物培养物上清液纯化,如文献(yasuda等人,prot.exp.pur,.37:499
‑
506[2004])中描述的。所有其他gla变体如下进行纯化。gla变体从哺乳动物培养物上清液纯化,基本上如本领域已知的(参见,yasuda等人,prot.exp.pur,.37:499
‑
506[2004])。将伴刀豆球蛋白a树脂(sigma aldrich)用0.1m乙酸钠,0.1m nacl,1mmmgcl2、cacl2和mncl2,ph 6.0(伴刀豆球蛋白a结合缓冲液)平衡。将上清液用0.2μm的瓶顶过滤器进行无菌过滤,然后将上清液加载到柱上。加载后,将柱用10倍柱体积的伴刀豆球蛋白a结合缓冲液洗涤,并用补充有0.9m甲基
‑
α
‑
d
‑
吡喃甘露糖苷和0.9m甲基
‑
α
‑
d
‑
吡喃葡萄糖苷的伴刀豆球蛋白a结合缓冲液洗脱结合的蛋白。浓缩洗脱的蛋白,并使用带有30kda分子量截止膜的ultra 15ml过滤单元(millipore)将缓冲液交换为储存缓冲液(20mm磷酸钠、150mm氯化钠、185μm非离子去污剂,ph 6.0)。将储存缓冲液中的gla通过0.2μm注射过滤器(whatman)进行无菌过滤,并储存于
‑
80℃。基于bca定量,纯化提供了2.4
‑
50μg纯化的蛋白/ml培养物上清液。
[0302]
通过bca蛋白测定进行蛋白定量
[0303]
二喹啉甲酸(bca)蛋白测定(sigma aldrich)用于定量纯化的gla。在微量滴定板中,将适当稀释的25ul蛋白标准品和纯化的gla与200ul含有50份bca试剂a和1份bca试剂b的工作试剂混合。将板在板振荡器上充分混合30秒并在37℃孵育30分钟。板冷却至室温后,使用板读取器在562nm处测量样品的吸光度。
[0304]
实施例5
[0305]
gla变体的体外表征
[0306]
hek 293t细胞中表达的gla变体的热稳定性
[0307]
将gla变体暴露于各种温度挑战,以评估酶的总体稳定性。首先,将50μl 1
×
pbs ph 6.2中的纯化的hek 293t表达的gla和gla变体添加到96孔pcr板(biorad,hsp
‑
9601)的孔中。将板密封,并使用热循环仪的梯度程序,在30
‑
50℃孵育1h。对于该测定,将25μl挑战的上清液与25μl mcilvaine缓冲液ph 4.4中的1mm mugal混合。将反应物短暂混合,并在37℃孵育60分钟,然后用100μl 0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。对于每种变体,通过将挑战的样品的活性除以未挑战的样品的活性,计算在30℃至50℃的温度范围内孵育1h的残余活性百分比,其中“未挑战”是在时间0测量的水解,而“挑战”是在指定的温度1小时测量的水解。来自该测定的结果在表5
‑
1中示出。图1提供了示出gla变体在各种温度孵育1hr后的残余活性的图。
[0308]
hek 293t细胞中表达的gla变体的血清稳定性
[0309]
为了评估变体在存在血液时的相对稳定性,将样品暴露于血清。首先,将100μl在1
×
pbs ph 6.2中的7.5ug/ml纯化的gla变体和90μl人类血清添加到96孔圆形底板(corning)的孔中。将板密封,并在37℃孵育0
‑
24h。对于该测定,将50μl挑战的上清液与50μl mcilvaine缓冲液ph 4.4中的1mm mugal混合。将反应物短暂混合,并在37℃孵育90分钟,然后用100μl 0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。对于每种变体,通过将挑战的样品的活性除以未挑战的样品的活性,计算在血清中24h后的残余活性百分比,其中“未挑战”是在时间0测量
的水解,而“挑战”是在指定的时间点测量的水解。结果在表5
‑
1中示出。图2提供了示出用人类血清挑战0
‑
24hr后gla变体的残余活性的图。
[0310]
hek 293t细胞中表达的gla变体的溶酶体稳定性
[0311]
为了评估变体在存在溶酶体蛋白酶和其他溶酶体组分时的相对稳定性,按照制造商的说明及一些修改,将gla变体暴露于人类溶酶体裂解物(xenotech,#h0610.l),如本文中描述的。简言之,将gla变体稀释至适当的浓度范围(0.0625
‑
0.0078125mm),并将10μl稀释液与10μl 2
×
分解代谢缓冲液(xenotech,#k5200)中的1:20稀释的人类溶酶体裂解物在96孔圆底板(#3798,corning)中混合。将板密封,并在37℃孵育0
‑
24h。对于该测定,将50μl挑战的上清液与50μl mcilvaine缓冲液ph 4.4中的1mm mugal混合。将反应物短暂混合,并在37℃孵育90分钟,然后用100μl 0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。对于每种变体,通过将挑战的样品的活性除以未挑战的样品的活性,计算在溶酶体提取物中24h后的残余活性百分比,其中“未挑战”是在时间0测量的水解,而“挑战”是在4小时和24小时测量的水解。结果在表5
‑
1中提供。图3提供了示出用人类溶酶体提取物挑战0hr至24hr后gla变体的残余活性的图。
[0312]
法布里病成纤维细胞(fabry fibroblast)对纯化的hek293t细胞中表达的gla变体的细胞摄取
[0313]
确定与参考酶(wt gla[seq id no:2])相比的gla变体的细胞摄取,以评估变体被内吞入培养细胞中的整体能力。将法布里病成纤维细胞(gmo2775,coriell institute for medical research)接种到含有最小必需培养基(mem;gibco#11095
‑
080,补充有1%非必需氨基酸(neaa;gibco#11140
‑
050)和15%胎牛血清(corning#35
‑
016
‑
cv))的12孔培养皿中并允许生长至汇合(在37℃、5%co22
‑
3天)。达到汇合后,通过无菌真空去除补充的mem,并用1ml/孔的无血清mem+1%neaa替换。将如实施例4中描述纯化的酶以10ug gla/ml添加至细胞,并允许在37℃、5%co2培养4小时。通过无菌真空吸出无血清培养基,将细胞用1ml 1
×
pbs/孔短暂洗涤,并通过无菌真空吸出pbs。然后将细胞用200μl/孔0.25%胰蛋白酶
‑
edta(vwr#02
‑
0154
‑
0100)进行胰蛋白酶消化(trypsinize),并在室温孵育~5分钟,以使贴壁细胞从板脱离并降解剩余的细胞外gla。然后,向每个孔中添加500μl无血清mem,并将样品转移到1.5ml微量离心管中。将样品以8000rpm离心5min以沉淀细胞。用1000μl移液器温和吸出培养基。将细胞沉淀物重悬于500μl 1
×
pbs中,以8000rpm再离心5min,并温和去除pbs。然后,向每个样品中添加100μl裂解缓冲液(稀释于1
×
pbs中的0.2%triton x
‑
100
tm
非离子表面活性剂(sigma#93443)),然后声处理1
‑
2分钟,并在4℃以12,000
‑
14,000rpm离心10分钟。将上清液转移到无菌pcr管中用于蛋白测定和活性测定。对于活性测定,将10μl细胞裂解样品与50μl mcilvaine缓冲液ph 4.6中的2.5mm mugal混合。将反应板密封,并在37℃孵育60分钟,然后用每孔140μl 0.5m碳酸钠ph 10.2猝灭反应。mugal水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来确定。对于蛋白定量,bca测定按照制造商的说明(pierce,#23225)及以下修改来进行:将10μl细胞裂解样品与190μl bca工作试剂混合,并将板密封,并在37℃孵育60分钟。使用m2微量板读取器监测吸光度(562nm)来分析样品。根据bsa标准曲线计算蛋白浓度。每种gla变
体的细胞摄取通过首先从酶处理的样品中减去未处理细胞的背景非酶促荧光,并且然后针对每个孔中的蛋白浓度归一化来计算。细胞摄取fiopc通过将归一化的gla变体细胞内活性除以对应的对照(wt)活性来计算。图4提供了培养的法布里病患者成纤维细胞在37℃孵育4小时后对纯化的gla变体的细胞摄取的图,表示为与野生型(seq id no:2)相比的相对活性。
[0314][0315][0316]
法布里病成纤维细胞的裂解物中gla活性的htp分析
[0317]
挑战以htp产生的gla变体进入细胞并保持活性超过24小时至96小时的能力。将法布里病成纤维细胞(gmo2775,coriell institute for medical research)铺板,并允许在24
‑
72小时内生长至汇合。达到汇合后,使用自动化biomek i5液体处理机器人去除培养基。将来自如上文描述瞬时转染的hek293t细胞的条件培养基添加至法布里病成纤维细胞,并允许细胞与gla变体在37℃、5%co2一起孵育2
‑
4小时。用自动化biomek i5液体处理机器人
去除含gla的条件培养基。然后,用150μl 1
×
dpbs/孔短暂洗涤细胞,并用自动化biomek i5液体处理机器人去除dpbs。然后,向每个孔中添加200μl完全生长培养基,并将板返回至培养箱中24
‑
72小时。孵育结束时,用自动化biomek i5液体处理机器人去除完全生长培养基。用150μl 1
×
dpbs/孔洗涤细胞,并用自动化biomek i5液体处理机器人去除dpbs。通过添加50μl补充有0.2%triton x
‑
100
tm
非离子表面活性剂(sigma#93443)的mcilvain缓冲液ph 4.4并在室温搅拌30分钟来裂解细胞。通过添加50μl mcilvain缓冲液ph 4.4中的1.5mm mugal来评估活性。将板密封,并在37℃以400rpm搅拌孵育360分钟,然后用100μl0.5m碳酸钠ph 10.2猝灭。水解使用m2微量板读取器监测荧光(ex.355nm,em.460nm)来分析。细胞摄取fiopc通过将归一化的gla变体细胞内活性除以对应的参考序列活性来计算。
[0318]
gla诱导的法布里病成纤维细胞中球形三酰神经酰胺的消耗的htp分析
[0319]
挑战以htp产生的gla变体被摄取到细胞中并减少细胞的球形三酰神经酰胺负荷的能力。将法布里病成纤维细胞(gmo2775,coriell institute for medical research)铺板,并允许在24
‑
72小时内生长至汇合。达到汇合后,通过自动化biomek i5液体处理机器人去除培养基。将如上文描述瞬时转染的hek293t细胞产生的条件培养基添加至成纤维细胞,并允许在37℃、5%co2孵育2
‑
4小时。用自动化biomek i5液体处理机器人去除含gla的条件培养基。然后,用150μl 1
×
dpbs/孔短暂洗涤细胞,并用自动化biomek i5液体处理机器人去除dpbs。然后,向每个孔中添加200μl完全生长培养基,并将板返回至培养箱中24
‑
72小时。孵育结束时,用自动化biomek i5液体处理机器人去除完全生长培养基。然后,用150μl 1
×
dpbs/孔洗涤细胞,并用自动化biomek i5液体处理机器人去除dpbs。在室温温和搅拌30分钟,将球形三酰神经酰胺萃取到200ul补充有10ng/ml正十七烷酰基
‑
神经酰胺三己糖苷的甲醇中。将甲醇萃取物通过millipore疏水过滤器堆栈(millipore hydrophobic filter stack)过滤到圆底96孔板中。细胞球形三酰神经酰胺基本上如本领域已知的通过lc
‑
ms/ms来定量(参见,provencal等人,bioanal.,8:1793
‑
1807[2016])。确定每个细胞样品的峰积分之和,并通过将归一化的gla变体球形三酰神经酰胺水平的变化除以参考序列来计算球形三酰神经酰胺fiopc。
[0320]
实施例6
[0321]
源自seq id no:58的gla变体
[0322]
在本实施例中,描述了为评估法布里病成纤维细胞中gla变体的活性和gb3清除所进行的实验。在本实施例中,seq id no:58用作参考序列(即,变体中的氨基酸差异是相对于seq id no:58指示的,并且测定结果是相对于seq id no:58获得的结果报告)。在这些实验中,在没有预孵育的情况下,测试gla变体的mu
‑
gal活性,如实施例5中描述的。还测试了法布里病成纤维细胞中变体的gb3消耗,如实施例5中描述的。
[0323]
[0324]
[0325][0326]
实施例7
[0327]
源自seq id no:158的gla变体
[0328]
在本实施例中,描述了为评估gla变体的活性、在ph 7.4的稳定性和在法布里病成纤维细胞中的细胞内活性所进行的实验。在本实施例中,参考序列为seq id no:158(即,变体中的氨基酸差异是相对于seq id no:158指示的,并且测定结果是相对于seq id no:158
的结果报告的)。在没有预孵育(未挑战)和ph 7.4预孵育后,测试变体的gla mu
‑
gal活性,如实施例5中描述的。在裂解与gla变体一起孵育的法布里病成纤维细胞后,还测试了变体的mu
‑
gal活性,如实施例5中描述的。
[0329]
[0330]
[0331][0332]
实施例8
[0333]
源自seq id no:372的gla变体
[0334]
在本实施例中,描述了为评估gla变体的活性、在ph 7.4的稳定性、gb3清除和在法布里病成纤维细胞中的细胞内活性所进行的实验。在本实施例中,参考序列为seq id no:372(即,变体中的氨基酸差异是相对于seq id no:372指示的,并且测定结果是相对于seq id no:372的结果报告的)。在没有预孵育(未挑战)和ph 7.4预孵育后,测试这些变体的mu
‑
gal活性,如实施例5中描述的。在与gla变体一起孵育的法布里病成纤维细胞中,还测试了变体的mu
‑
gal活性(“裂解物fiopc”),如实施例5中描述的。在与gla变体一起孵育后,还测试了法布里病成纤维细胞中变体的gb3消耗(“gb3 fiopc”),如实施例5中描述的。
[0335]
[0336]
[0337]
[0338][0339]
实施例9
[0340]
源自seq id no:374的gla变体
[0341]
在本实施例中,描述了为通过在一系列或独立的挑战后测定酶活性来确定gla变体活性进行的实验。在没有预孵育和ph 7.4预孵育后,测试这些变体的gla mu
‑
gal活性,如实施例5中描述的。在裂解与变体一起孵育的法布里病成纤维细胞后,还测试了变体的mu
‑
gal活性,如实施例5中描述的。还测试了孵育后法布里病成纤维细胞中变体的gb3消耗,如实施例5中描述的。
[0342]
[0343]
[0344]
[0345]
[0346][0347]
实施例10
[0348]
gla变体的体内表征
[0349]
在体内表征了gla变体对积累的gb3的活性。使用了具有相同的遗传背景的法布里病小鼠(5月龄雌性;jackson,stock#3535)和年龄/性别匹配的野生型小鼠。小鼠通过尾静脉单次iv注射施用codexis酶变体(1.0mg/kg)。在预定的时间点(注射后1周和2周)使用co2麻醉处死动物,并将疾病相关组织(例如,心脏和肾)解剖成两部分(一部分用于酶活性测定,另一部分用于gb3定量),在干冰上冷冻,并储存于
‑
80℃直至分析。对于酶测定,在玻璃匀浆器中使用马达驱动的涂层杵,将小鼠组织在20
×
体积(w/v)的裂解缓冲液(稀释于1
×
pbs中的0.2%triton x
‑
100
tm
非离子表面活性剂(sigma#93443))中匀浆。将裂解物进行声处理,在4℃以14,000rpm离心15min,并将上清液用于酶测定。在存在0.1m n
‑
乙酰半乳糖胺(即,α半乳糖苷酶b的特异性抑制剂)的条件下,在ph 4.4,使用5mm 4
‑
甲基伞形基
‑
α
‑
d
‑
吡喃半乳糖苷通过标准荧光测定来测量α
‑
gal a活性。蛋白浓度使用bca蛋白测定试剂盒(pierce,#23225)来测量。将活性针对蛋白浓度归一化,并表示为nmol/mg蛋白/小时。如先前描述的,gb3浓度通过质谱法测量(参见,durant等人,j.lipid res.,52:1742
‑
6[2011])。简言之,在玻璃匀浆器中,将小鼠组织在冰冷的20
×
体积的超纯水中匀浆,并将对应于200μg总蛋白的裂解物进行鞘糖脂提取、皂化,并随后通过质谱法分析gb3。gb3浓度表示为ng/mg蛋白。图5提供了示出处理后1周、2周和4周法布里病小鼠模型的心脏中体内酶活性的图。图6提供了与未处理的动物相比,处理后1周和2周法布里病小鼠模型的心脏组织中gb3降解的图。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1