一种合成2`-岩藻糖基乳糖的重组大肠杆菌及其构建方法与流程
本发明涉及基因工程技术领域,具体涉及一种合成2′-岩藻糖基乳糖的重组大肠杆菌及其构建方法。
背景技术:
母乳是一种复杂的混合物,含有水、脂肪、蛋白质、矿物质、维生素、多糖、单糖、双糖(乳糖)、低聚糖。乳糖是母乳主要固体成分(总固形物的~6.8%),同时广泛存在于动物乳汁。但是,结构较复杂的母乳低聚糖(总固形物的~1%)却是人类所独有的。目前,结构确证的母乳低聚糖大约有200种,聚合度从3到32不等。母乳低聚糖的结构特征包括乳糖-n-乙酰葡萄糖胺骨架、直链β-(1,3/4)-糖苷键、支链β-(1,6)-糖苷键、乳糖在糖链还原末端而l-岩藻糖或唾液酸在非还原末端。
2’-岩藻糖基乳糖是大多数哺乳期母亲乳汁中含量最丰富的母乳低聚糖。在表达α-(1,2)-岩藻糖基转移酶基因fut2的分泌型母亲的乳汁中,2’-岩藻糖基乳糖占母乳低聚糖总量的比例可以高达30%。因此,2’-岩藻糖基乳糖的研究较为充分,并且发现2’-岩藻糖基乳糖具有多种有益功能。例如,2’-岩藻糖基乳糖特异性地抑制空肠弯曲菌、伤寒杆菌、致病性大肠杆菌、幽门螺杆菌、诺如病毒与对应宿主受体的结合从而避免感染。2’-岩藻糖基乳糖可以抑制绿脓杆菌与局部上皮细胞的相互作用,从而避免绿脓杆菌对胃肠道、尿道和呼吸系统的感染。此外,2’-岩藻糖基乳糖可以抑制细胞膜表面的脂多糖结合受体cd14,从而减弱致病性大肠杆菌1型菌毛脂多糖诱发的炎症。新近发现,2’-岩藻糖基乳糖还可以改善啮齿目动物的学习与记忆。
2’-岩藻糖基乳糖有益健康,因而被逐步用作婴儿配方食品和医学营养产品的功能食品原料。然而,2’-岩藻糖基乳糖的工业化生产并非易事,以至于现今2’-岩藻糖基乳糖在婴儿配方产品中的使用量仍然低于其在母乳中的天然含量。早期,2’-岩藻糖基乳糖是从捐赠的母乳中色谱分离获得的,由于材料来源有限,无法大规模生产。2’-岩藻糖基乳糖可以直接化学合成,然而,受限于保护基团的化学性质,无法扩大规模,并且化学合成需要使用有毒试剂,更不适于大规模食品生产。岩藻糖基转移酶可以体外催化合成2’-岩藻糖基乳糖,但是,供体底物鸟苷二磷酸岩藻糖十分昂贵。因此,对于年产数百吨的工业生产,2’-岩藻糖基乳糖的酶法合成并不适用。微生物发酵是目前唯一适合大规模生产的技术路线。代谢工程、发酵工程、纯化工艺等技术进展,使2’-岩藻糖基乳糖得以大规模生产销售。在发酵过程中,供体底物分子鸟苷二磷酸岩藻糖由微生物自身从头合成,而受体底物分子乳糖一般由外部加入。
因此,构建一种合成2′-岩藻糖基乳糖的重组大肠杆菌,有效促进2′-岩藻糖基乳糖的发酵合成,并为未来规模化生产奠定坚实基础是本领域技术人员亟待解决的问题。
技术实现要素:
有鉴于此,本发明所解决的技术问题在于提供一种合成2′-岩藻糖基乳糖的重组大肠杆菌及其构建方法,克服了同源重组技术的试验周期较长、成功率较低等难题,优化外源岩藻糖基转移酶基因的表达,有效地促进了2′-岩藻糖基乳糖的合成,从而实现2′-岩藻糖基乳糖的高效发酵合成。
为了解决上述技术问题,一方面,本发明的方案提供一种合成2′-岩藻糖基乳糖的重组大肠杆菌,所述重组大肠杆菌是在大肠杆菌原始菌株的基因组中敲除β-半乳糖苷酶基因、从鸟苷二磷酸岩藻糖出发合成可拉酸的关键酶基因,强化表达乳糖通透酶基因、鸟苷二磷酸岩藻糖从头合成途径的关键酶基因,并表达外源岩藻糖基转移酶基因得到的。
优选地,所述敲除β-半乳糖苷酶基因是指利用crispr基因编辑技术敲除β-半乳糖苷酶基因lacz,敲除从鸟苷二磷酸岩藻糖出发合成可拉酸的关键酶基因是指利用crispr基因编辑技术敲除十一碳二烯磷酸酯葡萄糖磷酸转移酶基因wcaj。
优选地,利用crispr基因编辑技术敲除十一碳二烯磷酸酯葡萄糖磷酸转移酶基因wcaj时,敲除基因wcaj的grna1的靶标序列的核苷酸序列如seqidno.1所示,敲除基因wcaj的grna2的靶标序列的核苷酸序列如seqidno.2所示,pcr鉴定的上游引物的核苷酸序列如seqidno.3所示,pcr鉴定的下游引物的核苷酸序列如seqidno.4所示。
优选地,利用crispr基因编辑技术敲除β-半乳糖苷酶基因lacz时,敲除基因lacz的grna1的靶标序列的核苷酸序列如seqidno.5所示,敲除基因lacz的grna2的靶标序列的核苷酸序列如seqidno.6所示,pcr鉴定的上游引物的核苷酸序列如seqidno.7所示,pcr鉴定的下游引物的核苷酸序列如seqidno.8所示。
优选地,所述强化表达乳糖通透酶基因、鸟苷二磷酸岩藻糖从头合成途径的关键酶基因是指利用crispr基因编辑技术在鸟苷二磷酸岩藻糖从头合成途径的磷酸甘露糖变位酶基因manb上游敲入t7lac启动子。
优选地,利用crispr基因编辑技术在鸟苷二磷酸岩藻糖从头合成途径的磷酸甘露糖变位酶基因manb上游敲入t7lac启动子时,敲入片段的核苷酸序列如seqidno.9所示,敲入位置上游基因的核苷酸序列如seqidno.10所示,敲入位置下游基因的核苷酸序列如seqidno.11所示,pcr鉴定的上游引物的核苷酸序列如seqidno.12所示,pcr鉴定的下游引物的核苷酸序列如seqidno.13所示。
优选地,所述重组大肠杆菌携带用于诱导高表达蛋白质的多个重组质粒,所述重组质粒分别包含基因manb、甘露糖-1-磷酸鸟苷转移酶基因manc、鸟苷二磷酸甘露糖-4,6-脱水酶基因gmd、鸟苷二磷酸-l-岩藻糖合成酶基因fcl、乳糖通透酶基因lacy、外源岩藻糖基转移酶基因。
优选地,所述外源岩藻糖基转移酶wcfb基因源自脆弱拟杆菌,密码子优化的wcfb基因序列如seqidno.14所示。
优选地,原始菌株为大肠杆菌,优选为大肠杆菌bl21(de3)。
具体实现过程中,本发明提供一种合成2′-岩藻糖基乳糖的重组大肠杆菌,采用crispr基因编辑技术,敲除原始菌株基因组十一碳二烯磷酸酯葡萄糖磷酸转移酶基因wcaj和β-半乳糖苷酶基因lacz。同时,在鸟苷二磷酸岩藻糖从头合成途径的磷酸甘露糖变位酶基因manb上游敲入t7lac启动子。并且,同时过表达磷酸甘露糖变位酶基因manb,甘露糖-1-磷酸鸟苷转移酶基因manc,鸟苷二磷酸甘露糖-4,6-脱水酶基因gmd,鸟苷二磷酸-l-岩藻糖合成酶基因fcl,乳糖通透酶基因lacy,密码子优化的α-1,2-岩藻糖转移酶基因wcfb。
所述基因wcaj,基因登录号gi:8182600;基因lacz,基因登录号gi:8181469;基因manb,基因登录号gi:946574;基因manc,基因登录号gi:946580;基因gmd,基因登录号gi:946562;基因fcl,基因登录号gi:946563;基因lacy,基因登录号gi:949083;基因wcfb,基因登录号gi:3287270。所述基因过表达,是指采用重组质粒表达载体实现各个基因对应的蛋白质酶分子的诱导高表达。
另一方面,本发明还提供了一种合成2′-岩藻糖基乳糖的重组大肠杆菌的构建方法,包括如下步骤:
1)分别制备含有基因manb,基因manc,基因gmd,基因fcl,乳糖通透酶基因lacy,密码子优化的基因wcfb的重组质粒,获得构建代谢途径的质粒;
2)检测显示大肠杆菌bl21(de3)原始菌株生长状态正常,目标基因wcaj和lacz以及t7lac启动子敲入位置及其上下游序列的检测显示,pcr扩增条带大小符合预期,测序结果与ncbi序列一致;
3)根据目标基因序列的插入位置及周围的序列特点,设计并制备grna,将grna以及donor序列克隆至基因编辑载体donor质粒,并通过测序验证确保构建的载体中grna以及donor序列均与目标序列一致;
4)制备大肠杆菌bl21(de3)电转感受态,cas9质粒转化至bl21(de3)感受态中,挑斑制备bl21(de3)-cas9电转感受态,donor质粒转化至bl21(de3)-cas9电转感受态,加入阿拉伯糖诱导后涂板,进行基因编辑菌株筛选实验;
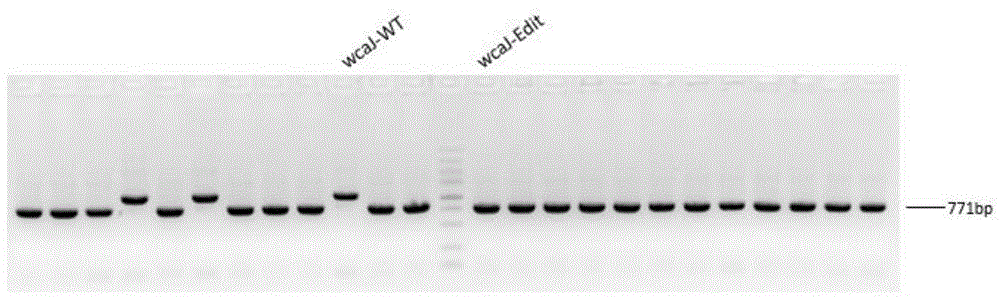
5)pcr扩增验证编辑后的bl21(de3)单克隆,wcaj基因敲除成功条带大小771bp,未敲除成功条带大小为1049bp;lacz基因敲除成功条带大小687bp,未敲除成功条带大小为983bp;t7lac启动子敲入成功的条带大小1076bp,未敲入成功无条带;电泳图显示,成功筛选到wcaj基因和lacz基因同时敲除并且t7lac启动子敲入的单克隆;
6)将步骤5)中crispr编辑的大肠杆菌进行溶源化处理,再将步骤1)所得的代谢途径构建质粒转化到溶源菌中,获得能够合成2′-岩藻糖基乳糖的重组大肠杆菌。
本发明重组大肠杆菌发酵合成2′-岩藻糖基乳糖,培养基和发酵方法如下:
lb培养基(1l):胰蛋白胨,10g;酵母提取物,5g;氯化钠,5g。配制固体培养基,则再加入15g琼脂粉。
本发明重组大肠杆菌在2ml的lb培养基(卡那霉素50μg/ml,链霉素50μg/ml)中37℃并且摇床转速220rpm过夜培养约15h。取1ml过夜培养的种子液转入50ml的lb培养基(卡那霉素50μg/ml,链霉素50μg/ml,加入终浓度为20g/l的葡萄糖),30℃并且摇床转速250rpm培养约8h(菌液od600约0.8)。加入终浓度为12g/l的乳糖和0.3mm的iptg,25℃并且摇床转速250rpm继续诱导发酵48h。
本发明公开的一种合成2′-岩藻糖基乳糖的重组大肠杆菌及其构建方法与现有技术相比所具有的积极效果在于:
(1)本发明重组大肠杆菌具备发酵合成2′-岩藻糖基乳糖的代谢途径,同时克服了同源重组技术的试验周期较长、成功率较低等难题,获得了一个高效的基因组编辑方案;除合成2′-岩藻糖基乳糖外,原始菌株其它特性没有改变,不影响发酵;采用的质粒为常用的大肠杆菌质粒,不影响细菌生长和代谢。
(2)通过提高细胞内乳糖和鸟苷二磷酸岩藻糖的浓度,同时优化外源岩藻糖基转移酶基因的表达,有效地促进了2′-岩藻糖基乳糖的合成;本发明重组大肠杆菌,构建思路清晰,实际效果显著,具有良好的应用前景。
(3)本发明重组大肠杆菌以葡萄糖为碳源发酵合成2′-岩藻糖基乳糖,成本更低,经济可行性更高,发酵48h,可以得到6~10g/l的2′-岩藻糖基乳糖。
(4)本发明重组大肠杆菌在放大过程中十分稳定,极具工业应用潜力。
附图说明
图1是wcaj基因敲除的pcr验证产物的电泳图;
(wcaj-wt是wcaj基因扩增产物;wcaj-edit是敲除之后wcaj基因的扩增产物)
图2是lacz基因敲除的pcr验证产物的电泳图;
(lacz-wt是lacz基因扩增产物;lacz-edit是敲除之后lacz基因的扩增产物)
图3是t7lac启动子敲入的pcr验证产物的电泳图;
(7lac-wt是未敲入t7lac的扩增产物;7lac-edit是成功敲入t7lac的扩增产物)
图4是质谱检测发酵液图谱,其中分子量487.16的质谱峰为2′-岩藻糖基乳糖。
具体实施方式
下面通过具体的实施方案叙述本发明。除非特别说明,本发明中所用的技术手段均为本领域技术人员所公知的方法。另外,实施方案应理解为说明性的,而非限制本发明的范围,本发明的实质和范围仅由权利要求书所限定。对于本领域技术人员而言,在不背离本发明实质和范围的前提下,对这些实施方案中的物料成分和用量进行的各种改变或改动也属于本发明的保护范围。本发明所用原料及试剂均有市售。以下实施例中所用的材料、试剂、仪器和方法均为本领域中的常规材料、试剂、仪器和方法,均可通过商业渠道获得。
实施例1
基因的获取:
本实施例中,获取来源于大肠杆菌mg1655的基因manb(基因登录号gi:946574),基因manc(基因登录号gi:946580),基因gmd(基因登录号gi:946562),基因fcl(基因登录号gi:946563),基因lacy(基因登录号gi:949083),获取来源于脆弱拟杆菌nctc9343的基因wcfb(基因登录号gi:3287270)。
本实施例中,通过抽提大肠杆菌mg1655的基因组dna,成功获取大肠杆菌基因manb、manc、gmd、fcl和lacy;通过人工合成密码子优化的基因并克隆到大肠杆菌质粒,成功获取来源于脆弱拟杆菌nctc9343的基因wcfb。基因的成功获取,为重组质粒构建奠定基础。
实施例2
重组质粒的制备
使用设计的引物(上游引物序列如seqidno.15所示,下游引物序列如seqidno.16所示)对实施例1中获得的来源于大肠杆菌mg1655的基因manc和基因manb进行pcr扩增,扩增后的片段进行切胶纯化,并用ncoi和hindiii限制性内切酶进行双酶切,酶切后的片段与同样经过ncoi和hindiii双酶切的质粒pcoladuet-1质粒进行连接,将载体:目的片段按摩尔比为1:3的比例混合,加入t4dna连接酶后在22℃下酶连5h,连接产物转化至大肠杆菌dh5α感受态细胞,并在卡那霉素板上进行筛选,获得重组质粒pcola-cb。使用设计的引物(上游引物序列如seqidno.17所示,下游引物序列如seqidno.18所示)对实施例1中获得的来源于大肠杆菌mg1655的基因gmd和基因fcl进行pcr扩增,扩增后的片段进行切胶纯化,并用ndei和xhoi进行双酶切,酶切后的片段与同样经过ndei和xhoi双酶切的质粒pcola-cb质粒进行连接,将载体:目的片段按摩尔比为1:3的比例混合,加入t4dna连接酶后在22℃下酶连5h,连接产物转化至大肠杆菌dh5α感受态细胞,并在卡那霉素板上进行筛选,获得重组质粒pcola-cbgf。
使用设计的引物(上游引物序列如seqidno.19所示,下游引物序列如seqidno.20所示)对实施例1中获得的来源于大肠杆菌mg1655的基因lacy进行pcr扩增,扩增后的片段进行切胶纯化,并用ndei和xhoi进行双酶切,酶切后的片段与同样经过ndei和xhoi双酶切的质粒pcdfduet-1进行连接,将载体:目的片段按摩尔比为1:3的比例混合,加入t4dna连接酶后在22℃下酶连5h,连接产物转化至大肠杆菌dh5α感受态细胞,并在链霉素板上进行筛选,获得重组质粒pcdf-lacy。使用设计的引物(上游引物序列如seqidno.21所示,下游引物序列如seqidno.22所示)对实施例1中获得的来源于脆弱拟杆菌的基因wcfb进行pcr扩增,扩增后的片段进行切胶纯化,并用ncoi和bamhi进行双酶切,酶切后的片段与同样经过ncoi和bamhi双酶切的质粒pcdf-lacy进行连接,将载体:目的片段按摩尔比为1:3的比例混合,加入t4dna连接酶后在22℃下酶连5h,连接产物转化至大肠杆菌dh5α感受态细胞,并在链霉素板上进行筛选,获得重组质粒pcdf-lacy-wcfb。
本实施例中,成功制备重组质粒pcola-cbgf和pcdf-lacy-wcfb,为大肠杆菌2’-岩藻糖基乳糖相关代谢途径的构建奠定基础。
实施例3
基因编辑
本实施例使用crispr基因编辑技术实现wcaj与lacz基因敲除以及t7lac启动子敲入。下面详细阐述基因编辑的步骤。
1)检测显示大肠杆菌bl21(de3)原始菌株生长状态正常,目标基因wcaj和lacz以及t7lac启动子敲入位置及其上下游序列的检测显示,pcr扩增条带大小符合预期,测序结果与ncbi序列一致;
2)根据目标基因序列的插入位置及周围的序列特点,设计并制备grna,将grna以及donor序列克隆至基因编辑载体donor质粒,并通过测序验证确保构建的载体中grna以及donor序列均与目标序列一致;
3)制备大肠杆菌bl21(de3)电转感受态,cas9质粒转化至bl21(de3)感受态中,挑斑制备bl21(de3)-cas9电转感受态,donor质粒转化至bl21(de3)-cas9电转感受态,加入阿拉伯糖诱导后涂板,进行基因编辑菌株筛选实验;
5)pcr扩增验证编辑后的bl21(de3)单克隆,wcaj基因敲除成功条带大小771bp,未敲除成功条带大小为1049bp;lacz基因敲除成功条带大小687bp,未敲除成功条带大小为983bp;t7lac启动子敲入成功的条带大小1076bp,未敲入成功无条带;电泳图显示,成功筛选到wcaj基因和lacz基因同时敲除并且t7lac启动子敲入的单克隆。
本实施例中,通过crispr基因编辑技术,实现大肠杆菌bl21(de3)基因wcaj的敲除(图1是wcaj基因敲除的pcr验证产物的电泳图),降低鸟苷二磷酸岩藻糖的消耗;实现大肠杆菌bl21(de3)基因lacz的敲除(图2是lacz基因敲除的pcr验证产物的电泳图),降低细胞内乳糖的水解;实现t7lac启动子在大肠杆菌基因组的基因manb上游的敲入(图3是t7lac启动子敲入的pcr验证产物的电泳图),促进基因manb、manc、gmd、fcl表达对应的糖酶,提高细胞内鸟苷二磷酸岩藻糖的含量。以上三个方面的成功实施,可以有效促进大肠杆菌合成2’-岩藻糖基乳糖。
实施例4
构建合成2’-岩藻糖基乳糖的重组大肠杆菌
将实施例3中crispr编辑的大肠杆菌进行溶源化处理,再将实施例2所得的代谢途径构建质粒转化到溶源菌中,获得能够合成2′-岩藻糖基乳糖的重组大肠杆菌。
本实施例中,成功获得合成2′-岩藻糖基乳糖的重组大肠杆菌,为进一步的发酵验证奠定基础。
实施例5
重组大肠杆菌合成2’-岩藻糖基乳糖的验证
将菌种接种在2ml的lb培养基(卡那霉素50μg/ml,链霉素50μg/ml)中37℃并且摇床转速220rpm过夜培养约15h。取1ml过夜培养的种子液转入50ml的lb培养基(卡那霉素50μg/ml,链霉素50μg/ml,加入终浓度为20g/l的葡萄糖),30℃并且摇床转速250rpm培养约8h(菌液od600约0.8)。加入终浓度为12g/l的乳糖和0.3mm的iptg,25℃并且摇床转速250rpm继续诱导发酵48h。发酵液8000rpm离心10min,收集上清,上清100℃煮10min,再次离心,取0.5ml上清与0.5ml纯净水混匀,样品过0.22μm滤膜,通过电喷雾质谱检测(图4是质谱检测发酵液图谱,其中分子量487.16的质谱峰为2′-岩藻糖基乳糖)。
本实施例中,摇瓶发酵液的质谱检测显示,重组大肠杆菌成功合成2′-岩藻糖基乳糖,为进一步的中试放大乃至工业生产奠定基础。
以上实施例仅用以说明本发明的技术方案,而非对其进行限制,尽管参照上述实施例对本发明进行了详细的说明,对于本领域的普通技术人员来说,依然可以对前述实施例所记载的技术方案进行修改,或者对其中部分技术特征进行等同替换。而这些修改或替换,并不使相应技术方案的本质脱离本发明所要求保护的技术方案的范围和精神。
序列表
<110>量子高科(广东)生物有限公司
<120>一种合成2'-岩藻糖基乳糖的重组大肠杆菌及其构建方法
<160>22
<170>siposequencelisting1.0
<210>1
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>1
ttgccctgctgctacaaaactgg23
<210>2
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>2
gccgtggttagggtttgaagtgg23
<210>3
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>3
gtgcgcctgaatgtggaatc20
<210>4
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>4
gagctcagtttcaccgccag20
<210>5
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>5
atggcgaatggcgctttgcctgg23
<210>6
<211>23
<212>dna
<213>人工序列(artificialsequence)
<400>6
ttaactcggcgtttcatctgtgg23
<210>7
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>7
ccaatacgcaaaccgcctct20
<210>8
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>8
ttacccgtaggtagtcacgc20
<210>9
<211>120
<212>dna
<213>人工序列(artificialsequence)
<400>9
gaggatcgagatcgatctcgatcccgcgaaattaatacgactcactataggggaattgtg60
agcggataacaattcccctctagaaataattttgtttaactttaagaaggagatatacat120
<210>10
<211>575
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>10
atgcaggatttaagtggattctcggtgccgaaagggttccggggtggcaacgctattaaa60
gtgcaattgtggtgggcagtacaggcaacattatttgcctggtcgccacaagtattgtat120
cgctggcgggcatttttattacgtttattcggcgcaaaaatagggaaaaacgtagttatt180
cgtccgtcagtaaaaattacctatccgtggaaattaaccttaggtgattacgcgtgggtc240
ggcgatgacgtcaatttatataccctcggtgaaataaccattggcgcacattcggtgata300
tcgcaaaaaagttatttatgcaccggtagccacgaccatgcaagtcaacatttcaccatt360
aatgctacgcctattgtgattggcgagaaatgctggctggcaaccgatgtttttgttgcc420
cctggcgtcacgattggcgacggcaccgtcgtgggtgcacgaagcagtgtttttaaaacg480
cttccggcaaatgtggtttgccgggggaatcccgcagtggtgatacgcgaacgcgttgaa540
actgaataaattcaaaaaatacagaggaataagac575
<210>11
<211>1120
<212>dna
<213>大肠杆菌(escherichiacoli)
<400>11
atgtcaaaagtcgctctcatcaccggtgtaaccggacaagacggttcttacctggcagag60
tttctgctggaaaaaggttacgaggtgcatggtattaagcgtcgtgcatcgtcattcaac120
accgagcgcgtggatcacatttatcaggatccgcacacctgcaacccgaaattccatctg180
cattatggcgacctgagtgatacctccaacctgacacgcattttgcgtgaagtgcagccg240
gatgaagtgtataacctgggcgcaatgagccacgttgcggtctcttttgagtcaccggaa300
tataccgcagacgttgatgcgatgggtacgctgcgcctgctcgaggcgatccgcttcctc360
ggtctggaaaagaaaacccgtttttatcaggcttccacctctgaactgtacggtctggtg420
caggaaattccgcagaaagaaactacgccgttctacccgcgatctccgtatgcggtcgcc480
aaactgtacgcctactggatcaccgttaactaccgcgaatcctacggcatgtacgcctgt540
aacggtattctcttcaaccatgaatccccgcgccgcggtgaaaccttcgttacccgcaaa600
atcacccgcgcaatcgccaatatcgcccaggggctggagtcgtgcctgtacctcggcaat660
atggattccctgcgtgactggggccatgccaaagactacgtaaaaatgcagtggatgatg720
ctgcaacaggaacagccggaagatttcgttattgctaccggcgttcagtactccgtacgt780
cagttcgtggaaatggcggcagcacagttgggcatcaaactgcgctttgaaggcacgggt840
gttgaagagaagggcattgtggtttccgtcaccgggcatgacgcgccgggcgttaaaccg900
ggtgatgtgattatcgccgttgacccgcgttacttccgtccggcagaagttgaaacgctg960
ctcggcgacccgaccaaagcgcacgaaaaactgggctggaaaccggaaatcaccctcaga1020
gagatggtgtctgaaatggtggctaatgacctcgaagcggcgaaaaaacactctctgctg1080
aaatctcacggctacgacggcgatcgcgctggagtcataa1120
<210>12
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>12
gaggatcgagatcgatctcg20
<210>13
<211>20
<212>dna
<213>人工序列(artificialsequence)
<400>13
gtttcaacttctgccggacg20
<210>14
<211>864
<212>dna
<213>脆弱拟杆菌(bacteroidesfragilis)
<400>14
atgctgtacgttattctgcgggggcgtctggggaataatttatttcagattgcaaccgcc60
gcctcactgacccagaactttattttttgtaccgttaataaggatcaagagcggcaggtt120
ttactgtataaagatagctttttcaagaacatcaaggttatgaaaggagttccggatggt180
attccatactataaagaaccgtttcatgaatttagcagaattccttatgaggaaggtaaa240
gatctgatcattgatggttattttcagagcgaaaaatacttcaaacgtagcgtggtttta300
gacctgtaccgcataaccgatgaactgcgcaaaaagatatggaacatatgtggtaatatc360
cttgaaaagggagaaaccgttagcattcatgtgcggcgtggcgactatttaaagctgccg420
catgccttaccgttttgtggtaaaagctattataagaacgcaatccagtatatcggcgaa480
gataaaatttttatcatctgtagcgacgatatcgattggtgtaaaaagaatttcatcggt540
aaacgttactactttatcgaaaataccaccccgctgctggacttatatattcaaagcctg600
tgcacccataatattatttcaaatagcagcttcagctggtggggagcatggctgaatgaa660
aattctaataagattgtgatcgccccacaaatgtggtttggtattagtgttaaacttggt720
gtttctgatctgttacctgtgagctgggttagactgccgaataattataccctgggtcgc780
tattgttttgccttatataaagttgttgaagactacctgctgaatattctgcgtctgatt840
tggaaacgtaaaaagaatatgtaa864
<210>15
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>15
cataccatggcgcagtcgaaactctatccag31
<210>16
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>16
cccaagctttggggtaagggaagatccgac30
<210>17
<211>30
<212>dna
<213>人工序列(artificialsequence)
<400>17
cgccatatgtcaaaagtcgctctcatcacc30
<210>18
<211>31
<212>dna
<213>人工序列(artificialsequence)
<400>18
ccgctcgagttcctgacgtaaaaacatcatt31
<210>19
<211>34
<212>dna
<213>人工序列(artificialsequence)
<400>19
gaaagatcttatgtactatttaaaaaacacaaac34
<210>20
<211>27
<212>dna
<213>人工序列(artificialsequence)
<400>20
attggtaccttaagcgacttcattcac27
<210>21
<211>47
<212>dna
<213>人工序列(artificialsequence)
<400>21
ctttaataaggagatataccatgggcatgctgtacgttattctgcgg47
<210>22
<211>46
<212>dna
<213>人工序列(artificialsequence)
<400>22
cgcgccgagctcgaattcggatccttacatattctttttacgtttc46
- 还没有人留言评论。精彩留言会获得点赞!