成熟B细胞肿瘤的分型标志物及其应用的制作方法
成熟b细胞肿瘤的分型标志物及其应用
技术领域
1.本发明涉及生物医学技术领域,具体涉及一种成熟b细胞肿瘤的分型标志物及其应用。
背景技术:
2.成熟b细胞肿瘤是一类成熟b细胞克隆增殖性疾病,是淋巴瘤中最常见和发病率最高的亚类,约占所有淋巴瘤病例的80%以上。根据2016年世界卫生组织造血和淋巴组织肿瘤分类,成熟b细胞肿瘤包括40余种亚型,其诊断依据形态学(morphology)、免疫学(immunology)、遗传学(cytogenetics)及分子生物学(molecular biology)分型(micm分型)。形态学是临床上成熟b细胞肿瘤亚型诊断的金标准,免疫学、遗传学和分子生物学则在亚型分类、精准治疗和预后评估上有重要的作用。
3.然而,成熟b细胞肿瘤无论从临床表现还是从形态学上观察都是一类高度异质性的疾病,其临床表现复杂,形态特征和结果差异大,许多疑难病例的出现使成熟b细胞肿瘤的亚型鉴别诊断成为临床工作中的重点和难点。
4.例如,形态学作为临床上成熟b细胞肿瘤亚型诊断的金标准,其在临床诊断应用过程中存在亚型诊断模糊、亚型鉴别不清等问题,有一些病例可以通过免疫学、遗传学的方法来辅助形态学进行成熟b细胞肿瘤亚型鉴别诊断,但仍然有许多临床疑难病例无法通过以上方法进行明确的亚型诊断,从而影响后续的精准治疗,且利用ngs肿瘤亚型之间突变谱差异对诊断的辅助作用还尚待开发。
5.并且,形态学诊断和病理医生的水平一般有直接的关系,对病理医生的临床经验有较大的依赖性,某些淋巴瘤亚型依赖病理形态和免疫组化无法明确鉴别区分,诊断不清甚至误诊的情况时有发生。
6.近年来随着二代测序(ngs)的广泛应用和肿瘤基因组学研究的日益深入,许多成熟b细胞肿瘤亚型的重现性亚显微异常和血液肿瘤相关致病基因被不断发现和研究。然而,二代测序在成熟b细胞肿瘤的分型诊断应用上一直是临床工作中的重点和难点,血液肿瘤临床诊断共识指南中也只仅有少数单个基因对诊断的作用被写入,如何对ngs数据进行合适的清洗、筛选以及其临床意义的挖掘,利用肿瘤亚型之间突变谱的差异对诊断的辅助作用还有巨大的空间尚待开发。
7.ngs目前在临床上已得到广泛应用,在淋巴瘤中以预后评估和靶向治疗占应用主流,但随着临床检测ngs panel的不断扩大,患者医疗成本也不断增高,如何寻找分型的关键基因以减少无效医疗成本,利用突变谱对诊断的辅助作用尚待开发。
技术实现要素:
8.基于此,有必要针对上述问题,提供一种成熟b细胞肿瘤的分型标志物,采用该分型标志物,能够在兼顾控制成本和分型诊断准确性的基础上,解决临床上部分疑难病例亚型诊断困难的情况并在初诊时辅助预后评估,对成熟b细胞肿瘤的分型诊断和分层精准治
疗有十分重要的临床意义。
9.一种成熟b细胞肿瘤的分型标志物,包括以下基因中的至少16种基因的组合:abcb1,abl1,ankrd26,apc,arid1a,arid1b,arid2,asxl1,atg2b,atm,atrx,b2m,bcl10,bcl2,bcl6,bcor,bcorl1,birc3,blm,bpgm,braf,brca1,brca2,brip1,btg1,btk,calr,card11,cbl,cblb,cblc,ccnd1,ccnd3,cd28,cd58,cd79a,cd79b,cdkn1a,cdkn2a,cdkn2b,cebpa,chd8,ciita,crebbp,crlf2,csf1r,csf3r,ctcf,cux1,cxcr4,ddx41,dis3,dkc1,dnm2,dnmt3a,eed,egfr,egln1,elane,ep300,epha7,epor,etv6,ezh2,fas,fat1,fbxo11,fbxw7,flt3,foxo1,gata1,gata2,gfi1,gna13,gnai2,gnas,gnb1,gskip,hax1,hras,id3,idh1,idh2,ikzf1,ikzf2,irf8,itpkb,jak1,jak2,jak3,kdm6a,kit,kmt2a,kmt2b,kmt2c,kmt2d,kras,krt20,lmo2,lyn,map2k1,mcl1,mef2b,mfhas1,mpl,mtor,myc,myd88,myom2,nf1,notch1,notch2,npm1,nras,nsd2,nt5c2,palb2,pax5,pdgfra,pdgfrb,phf6,piga,pik3ca,pik3cd,pim1,plcg2,ppm1d,prdm1,prf1,prkdc,prpf8,pten,ptpn11,rad21,reln,rhoa,runx1,sbds,setbp1,setd2,setdb1,sf3b1,sgk1,sh2b3,smc1a,smc3,socs1,srp72,srsf2,stag2,stat3,stat5b,stat6,suz12,syk,tal1,tcf3,tent5c,terc,tert,tet2,tnfaip3,tnfrsf14,tp53,tpmt,traf3,u2af1,vhl,wt1,xpo1,zap70,zrsr2。
10.本领域中,如何将ngs应用于成熟b细胞肿瘤分型诊断一直是临床工作中的重点和难点,本发明人在充分分析ngs在肿瘤基因组学研究中所取得的进展,并结合目前临床工作中存在的问题,利用机器学习的方法,经过对ngs数据进行处理后,通过对关键分型相关基因(或基因位点)的寻找和筛选,建立一种利用二代测序和机器学习对成熟b细胞肿瘤亚型诊断模型的方法,可在兼顾控制成本和分型诊断准确性的基础上,解决临床上部分疑难病例亚型诊断困难的情况并在初诊时辅助预后评估,对成熟b细胞肿瘤的分型诊断和分层精准治疗有十分重要的临床意义。
11.在其中一个实施例中,该分型标志物至少包括以下基因:b2m,braf,ccnd1,cd79b,cdkn2a,cxcr4,ezh2,id3,kmt2d,myc,myd88,notch1,notch2,sf3b1,socs1,tnfaip3。
12.在其中一个实施例中,该分型标志物包括以下基因:b2m,braf,ccnd1,cd79b,cdkn2a,cxcr4,ezh2,id3,kmt2d,myc,myd88,notch1,notch2,sf3b1,socs1,tnfaip3。
13.本发明还公开了上述的分型标志物在制备用于成熟b细胞肿瘤分型诊断的试剂或设备中的应用。
14.本发明还公开了一种用于成熟b细胞肿瘤分型诊断的试剂盒,包括用于检测上述分型标志物的试剂。
15.本发明还公开了一种成熟b细胞肿瘤分型诊断模型的建立方法,包括以下步骤:
16.数据清洗:取若干已知分型的成熟b细胞肿瘤样本数据集a,进行变异清洗和筛选,获得数据集b;
17.变异分级:按照肿瘤变异分类标准与指南,对上述数据集b进行变异分类分级,将有害变异和可能有害变异分为i-ii类,意义未明确变异分为iii类,良性变异或可能良性变异分为iv类,获得数据集c;
18.机器学习:将上述数据集c中i类和ii类变异作为机器学习的结果数据,并以上述的分型标志物作为模型预测因子,以随机森林模型建立机器学习模型,即得成熟b细胞肿瘤分型诊断模型。
19.在其中一个实施例中,所述数据清洗步骤中,按照以下步骤进行变异清洗和筛选:
20.1)去除所有变异中的低质量变异;
21.2)去除所有变异中的内含子区或非翻译区变异;
22.3)去除所有变异中的同义突变变异;
23.4)去除所有变异中同批次出现频率大于50%或出现次数大于10次的变异;
24.在其中一个实施例中,所述变异分级数据中,按照以下标准进行变异分类分级:
25.1)按照肿瘤变异分类标准与指南记载标准,有a级、b级、c级和d级证据中至少一项证据的变异分类为i-ii类变异;
26.2)群体遗传学数据库中人群等位基因频率小于2
‰
且无a级、b级、c级和d级证据中至少一项证据的变异分类为iii类变异;
27.3)体细胞突变数据库中人群等位基因频率小于2
‰
且无a级、b级、c级和d级证据中至少一项证据的变异分类为iii类变异;
28.4)胚系突变数据库中人群等位基因频率小于2
‰
且无a级、b级、c级和d级证据中至少一项证据的变异分类为iii类变异;
29.5)群体遗传学数据库中人群等位基因频率大于2
‰
的变异分类为iv类变异;
30.6)体细胞突变数据库中人群等位基因频率大于2
‰
的变异分类为iv类变异;
31.7)在胚系突变数据库中人群等位基因频率大于2
‰
的变异分类为iv类变异。
32.在其中一个实施例中,所述群体遗传学数据库包括:esp、dbsnp、1000genome、exac数据库,所述体细胞突变数据库包括:cosmic、my cancer genome、tcga数据库,所述胚系突变数据库包括:hgmd、clinvar数据库,可以理解的,根据不同的需求和各数据库特点,本领域技术人员可对所参考数据库进行筛选和调整。
33.本发明还公开了一种上述的建立方法得到的成熟b细胞肿瘤分型诊断模型。
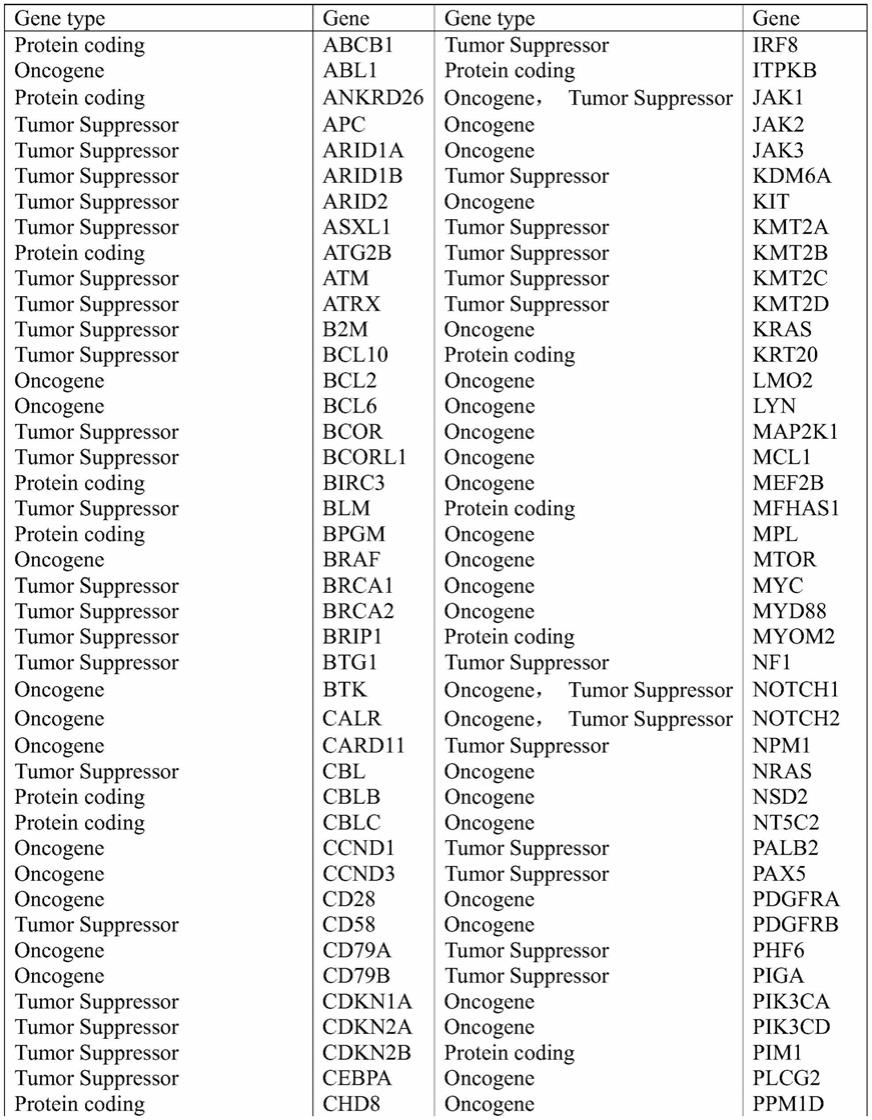
34.本发明还公开了一种成熟b细胞肿瘤分型诊断系统,包括:
35.检测模块,用于检测待测样品中上述基因序列;
36.分析模块,获取上述检测模块得到的基因序列数据,按照上述的模型进行数据分析,获得待测样本分型结果;
37.输出模块,用于将上述分型结果输出。
38.与现有技术相比,本发明具有以下有益效果:
39.本发明的一种成熟b细胞肿瘤的分型标志物,是针对形态学及其他辅助诊断方法在成熟b细胞肿瘤亚型诊断中存在的一些问题,利用二代测序和机器学习对成熟b细胞肿瘤亚型诊断模型的建立后得到。
40.本发明通过大量文献学习和整理之后,结合临床工作经验,选取了175个血液肿瘤相关基因作为模型建立预测因子,通过对成熟b细胞肿瘤不同亚型患者的ngs结果进行收集汇总、清洗筛选以及后续的因子筛选和随机验证,得到accuracy最佳模型(175个基因作为预测因子,模型a)和效率最佳模型(16个基因作为预测因子,模型b),为不同诊疗水平地区和不同收入患者群体利用ngs辅助成熟b细胞肿瘤分型诊断提供了不同的方法思路,利用机器学习建立亚型诊断模型,对形态学亚型鉴别不清或亚型诊断模糊的疑难病例进行辅助诊断。
41.并且,本发明采用机器学习的方法辅助形态学诊断使成熟b细胞肿瘤亚型的鉴别
诊断更具有客观性,克服了对病理医生临床经验的依赖。
42.同时,对临床上一些无法通过形态学、免疫学及遗传学方法进行明确亚型诊断的疑难病例,本方法提供了一种新的辅助诊断思路。
43.ngs除了可以对成熟b细胞肿瘤进行亚型鉴别诊断外,其对疾病预后方面的指导意义也十分重要,如其中部分标志物(如tp53基因)突变往往预示患者预后较差,利用ngs检测做分型诊断的同时,可以提示临床医生注意患者的用药及预后评估。结合ngs辅助形态学不仅对疾病进行了亚型鉴别诊断,也为患者的治疗及预后提供了评估价值,利于后续的精准治疗。
附图说明
44.图1为实施例1中模型变量筛选示意图。
具体实施方式
45.为了便于理解本发明,下面将参照相关附图对本发明进行更全面的描述。附图中给出了本发明的较佳实施例。但是,本发明可以以许多不同的形式来实现,并不限于本文所描述的实施例。相反地,提供这些实施例的目的是使对本发明的公开内容的理解更加透彻全面。
46.除非另有定义,本文所使用的所有的技术和科学术语与属于本发明的技术领域的技术人员通常理解的含义相同。本文中在本发明的说明书中所使用的术语只是为了描述具体的实施例的目的,不是旨在于限制本发明。本文所使用的术语“和/或”包括一个或多个相关的所列项目的任意的和所有的组合。
47.以下实施例所用试剂,如非特别说明,均为市售可得,以下实施例所用方法,如非特别说明,均为常规方法可实现。
48.实施例1
49.成熟b细胞肿瘤的分型标志物的筛选。
50.1、调研选取候选标志物。
51.在pubmed数据库中进行全面搜索与筛选,结合发明人在临床实践中的经验,选取下表所示175个与血液肿瘤相关基因作为ngs检测panel并预设为模型预测因子。
52.表1.血液肿瘤相关基因
53.[0054][0055]
2、数据收集及清洗。
[0056]
1)在cosmic(the catalogue of somatic mutations in cancer)数据库中进行全面搜索与筛选,收集comsic数据库中诊断为成熟b细胞肿瘤病例的亚型诊断数据(comsic数据库数据收集截止日期:2020.5.20),结果见下表。
[0057]
表2.cosmic数据库病例收集情况及变异分级后病例保留情况
[0058][0059]
2)收集上述cosmic数据库中诊断为成熟b细胞肿瘤病例的原始ngs结果数据并建立数据集(数据集ta);
[0060]
3)对上述获得的数据集ta进行变异清洗和筛选,获得数据集tb,步骤如下:
[0061]
①
去除所有变异中的低质量变异,具体如下:
[0062]
对于组织、骨髓及外周血样本,要求去除低质量变异重复后,靶标区域序列50x≥99%,平均测序深度》200x,q30≥0.85,目标区域捕获≥99%;
[0063]
对于血液样本检测血浆游离dna,要求去重复除低质量变异后,靶标区域序列500x≥99%,平均测序深度》2000x,q30≥0.85,目标区域捕获≥99%;
[0064]
对符合上述标准的变异进行igv变异确认;
[0065]
②
去除所有变异中的内含子区/非翻译区(intron/utr)变异;
[0066]
③
去除所有变异中的同义突变(synonymous)变异;
[0067]
④
去除所有变异中同批次ngs检测出现频率大于50%或出现次数大于10次的变异(即要求this batch<50%或n<10samples);
[0068]
4)按照肿瘤变异分类标准与指南(standards and guidelines for the interpretation and reporting of sequence variants in cance,2017),对上述获得的数据集tb进行变异分类分级,获得数据集tc,步骤如下:
[0069]
①
按照《肿瘤变异分类标准与指南》标准,有a级、b级、c级和d级证据中至少一项证据的变异分类为i-ii类变异(有害变异或可能有害变异);
[0070]
②
群体遗传学数据库(esp、dbsnp、1000genome、exac数据库)中人群等位基因频率小于2
‰
且无a级、b级、c级和d级证据中至少一项证据的变异分类为ⅲ类变异(意义未明变异);
[0071]
③
体细胞突变数据库(cosmic、my cancer genome、tcga数据库)中人群等位基因频率小于2
‰
且无a级、b级、c级和d级证据中至少一项证据的变异分类为ⅲ类变异(意义未明变异);
[0072]
④
胚系突变数据库(hgmd、clinvar数据库)中人群等位基因频率小于2
‰
且无a级、b级、c级和d级证据中至少一项证据的变异分类为ⅲ类变异(意义未明变异);
[0073]
⑤
群体遗传学数据库(esp、dbsnp、1000genome、exac数据库)中人群等位基因频率
大于2
‰
的变异分类为iv类变异(良性变异或可能良性变异);
[0074]
⑥
体细胞突变数据库(cosmic、my cancer genome、tcga数据库)中人群等位基因频率大于2
‰
的变异分类为iv类变异(良性变异或可能良性变异);
[0075]
⑦
在胚系突变数据库(hgmd、clinvar数据库)中人群等位基因频率大于2
‰
的变异分类为iv类变异(良性变异或可能良性变异)。
[0076]
5)保留上述获得的数据集tc中分类为i/ii类的变异作为用于机器学习模型评估的ngs结果数据,得到数据集t,备用。
[0077]
3、模型建立及模型因子优化。
[0078]
1)对数据集t进行数据0、1转换(i-ii类变异标记为1,其他标记为0);并对数据集t以随机森林(random forest)模型采用5次10折交叉验证网格搜索进行机器学习模型建立。
[0079]
2)对数据集t采用递归式特征消除法(recursive feature elimination)进行模型变量筛选,结果如图1所示。
[0080]
从图中可以看到,随着检测基因数的增加,模型accuracy值不断提高。当选择全部变量(即175个基因,a点)时,模型accuracy值最高(accuracy=0.73);当选择16个变量时(即16个基因,b点)时,模型效率最高(accuracy=0.69)。
[0081]
即上述结果表明,当选取所有175个基因进行分型评估时,accuracy值最高,但选择16个基因进行分型评估时,模型效率最高,且效率最高时accuracy值与选取所有基因时,相比较于基因数量的差异,accuracy值差异不大,因而,可根据不同诊疗水平地区和不同收入患者群体利用ngs辅助成熟b细胞肿瘤分型诊断选择适用,即选择至少16个基因的组合作为分型标志物。
[0082]
4、模型因子优化。
[0083]
发明人根据文献报道及临床实践经验,进一步选取了15组不同的基因组合对上述模型筛选结果进行验证。
[0084]
表3. 15组不同基因组合及accuracy值
[0085]
[0086][0087]
验证结果如上表所示,与模型变量筛选结果一致。根据accuracy值,选取第9种组合,包含的基因为:b2m,braf,ccnd1,cd79b,cdkn2a,cxcr4,ezh2,id3,kmt2d,myc,myd88,notch1,notch2,sf3b1,socs1,tnfaip3,在此组合情况下,具有效率最佳的优势,且其accuracy值可达到0.69,甚至高于变量选择更多的10-15组。
[0088]
实施例2
[0089]
模型评估。
[0090]
1、外部数据收集。
[0091]
1)采集受试者样本(外周血、骨髓、组织/淋巴结等)及受试者临床亚型诊断数据,结果见下表。
[0092]
表4.病例收集情况及变异分级后病例保留情况
[0093][0094]
2)数据获取。
[0095]
采用qiasymphony dsp dna mini kit试剂盒对受试者的样本进行dna提取,采用qiagen qiaseq fx dna library kit试剂盒构建文库及纯化,基于实施例1中所述175基因,按照常规实验室方法,建立ngs检测panel,采用探针杂交的方法进行捕获,选用illumina novaseq6000测序仪作为ngs测序平台,获得各样本的原始ngs检测结果数据并建立数据集(即数据集pa);
[0096]
将数据集pa按照实施例1中的方法进行变异清洗和筛选,获得数据集pb,并按照实施例1的方法对上述获得的数据集pb进行变异分类分级,获得数据集pc,再按照实施例1的方法,将数据集pc中分类为i/ii类的变异作为用于机器学习模型评估的ngs结果数据,得到数据集p(外部数据集p),备用。
[0097]
2、模型间对比验证评估。
[0098]
1)方法:对实施例1中数据集t采用分层随机采样进行数据分割,取80%作为训练集,20%作为测试集;选择a点和b点分别建立分型诊断模型,进行模型间对比验证评估。
[0099]
2)结果:
[0100]
选取a点作为模型预测因子,对数据集t以随机森林(random forest)模型采用5次10折交叉验证网格搜索进行机器学习模型建立,以accuracy值为评估指标,得到模型a内部验证评估,结果如下表。
[0101]
表5.模型a内部验证结果
[0102][0103][0104]
选取b点作为模型预测因子,对数据集t以随机森林(random forest)模型采用5次10折交叉验证网格搜索进行机器学习模型建立,以accuracy值为评估指标,得到模型b内部
验证评估,结果如下表。
[0105]
表6.模型b内部验证结果
[0106][0107]
3、模型间对比验证评估。
[0108]
1)用上述外部数据集p对成熟b细胞肿瘤亚型诊断模型a进行外部模型评估,结果见下表。
[0109]
表7.模型a外部验证结果
[0110][0111]
2)用上述外部数据集p对成熟b细胞肿瘤亚型诊断模型b进行外部模型评估,结果见下表。
[0112]
表8.模型a外部验证结果
[0113][0114]
上述结果表明,无论是模型内部验证,或是外部验证,本发明的基因组合形成的分型标志物,均可达到较好的成熟b细胞肿瘤分型效果。
[0115]
以上所述实施例的各技术特征可以进行任意的组合,为使描述简洁,未对上述实施例中的各个技术特征所有可能的组合都进行描述,然而,只要这些技术特征的组合不存在矛盾,都应当认为是本说明书记载的范围。
[0116]
以上所述实施例仅表达了本发明的几种实施方式,其描述较为具体和详细,但并不能因此而理解为对发明专利范围的限制。应当指出的是,对于本领域的普通技术人员来说,在不脱离本发明构思的前提下,还可以做出若干变形和改进,这些都属于本发明的保护范围。因此,本发明专利的保护范围应以所附权利要求为准。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1