用于预测和/或监测心血管疾病及其治疗的方法和组合物与流程
本公开文本总体上涉及与预测个体的心血管疾病(cvd)(例如,冠心病(chd))相关的方法和组合物。
背景技术:
1、心血管疾病(cvd)并且特别是冠心病(chd),是最常见的心脏病类型,并且2017年在美国造成超过360,000人死亡。为了降低死亡人数,已经开发了许多风险估计器,以更好地鉴定患有chd或有chd风险的人。从弗雷明汉(framingham)风险得分(frs)和最近的ascvd合并群组方程(pce)开始,这些工具捕获关键生理参数(如已知与cvd(包括chd)风险相关的血清脂质水平)的变化。
2、尽管有这些巨大的努力,但当前的风险估计器通常缺乏灵敏度和特异性。因此,需要用于cvd的替代分层方法。
技术实现思路
1、提供了用于预测心血管疾病(cvd)的发病率或风险的方法和组合物。例如,本文描述了用于预测冠心病(chd)的一年、三年或五年发病率的方法和组合物。一般原理适用于其他发病率窗口(例如,一个月、六个月、两年或十年)以及其他类型的cvd(包括而不限于chd、中风、心律失常、心脏停搏和充血性心力衰竭)的发病率或患病率。具体地,描述了用于确定至少一个cpg基因座的甲基化状态和至少一个单核苷酸多态性(snp)的方法和组合物。
2、在一方面,提供了用于确定至少一个cpg二核苷酸的甲基化状态和至少一个单核苷酸多态性(snp)的基因型的试剂盒。此类试剂盒通常包括:长度为至少8个核苷酸的至少一个第一核酸引物,其与包含第一cpg二核苷酸或第二cpg二核苷酸的亚硫酸氢盐转化核酸序列互补,所述第一cpg二核苷酸在选自cg00300879、cg09552548和cg14789911的gc基因座处,所述第二cpg二核苷酸与在选自cg00300879、cg09552548和cg14789911的gc基因座处的所述第一cpg二核苷酸连锁不平衡,其中所述连锁不平衡具有r>0.3的值,其中所述至少一个第一核酸引物检测甲基化或非甲基化cpg二核苷酸;和长度为至少8个核苷酸的至少一个第二核酸引物,其与选自rs11716050、rs6560711、rs3735222、rs6820447和rs9638144的第一snp或第二snp的dna序列或亚硫酸氢盐转化dna序列互补,所述第二snp与选自rs11716050、rs6560711、rs3735222、rs6820447和rs9638144的第一snp连锁不平衡,其中所述连锁不平衡具有r>0.3的值。
3、在一些实施方案中,所述至少一个第一核酸引物检测非甲基化cpg二核苷酸。在一些实施方案中,所述至少一个第一核酸引物检测甲基化cpg二核苷酸。
4、在一些实施方案中,本文所述的试剂盒进一步包括与cpg二核苷酸上游的核酸序列互补的长度为至少8个核苷酸的至少第三核酸引物。在一些实施方案中,所述试剂盒进一步包括与cpg二核苷酸下游的核酸序列互补的长度为至少8个核苷酸的至少第三核酸引物。
5、在一些实施方案中,所述至少一个第一核酸引物包含一个或多个核苷酸类似物。在一些实施方案中,所述至少一个第一核酸引物包含一个或多个合成或非天然核苷酸。
6、在一些实施方案中,本文所述的试剂盒进一步包括与所述至少一个第一核酸引物结合的固体基质。在一些实施方案中,所述基质是聚合物、玻璃、半导体、纸、金属、凝胶或水凝胶。在一些实施方案中,所述固体基质是微阵列或微流体卡。
7、在一些实施方案中,本文所述的试剂盒进一步包括可检测标记。
8、在另一方面,提供了确定来自患者的生物样品中与预测chd相关的生物标记物的存在的方法。此类方法通常包括(a)提供所述生物样品的第一部分和所述生物样品的第二部分,其中来自至少所述第一部分的核酸是亚硫酸氢盐转化的;(b)使所述生物样品的第一部分与长度为至少8个核苷酸的第一寡核苷酸引物接触,所述第一寡核苷酸引物与包含第一cpg二核苷酸或第二cpg二核苷酸的序列互补,所述第一cpg二核苷酸在选自cg00300879、cg09552548和cg14789911的gc基因座处,所述第二cpg二核苷酸与在选自cg00300879、cg09552548和cg14789911的gc基因座处的第一cpg二核苷酸连锁不平衡,其中所述连锁不平衡具有r>0.3的值,其中所述第一核酸引物检测甲基化或非甲基化cpg二核苷酸;并且(c)使所述生物样品的第二部分与长度为至少8个核苷酸的核酸引物接触,所述核酸引物与选自rs11716050、rs6560711、rs3735222、rs6820447和rs9638144的第一snp或第二snp的dna序列或亚硫酸氢盐转化dna序列互补,所述第二snp与选自rs11716050、rs6560711、rs3735222、rs6820447和rs9638144的第一snp连锁不平衡,其中所述连锁不平衡具有r>0.3的值。通常,在选自cg00300879、cg09552548和cg14789911的gc基因座处所述cpg二核苷酸的甲基化百分比和在选自rs1 1716050、rs6560711、rs3735222、rs6820447和rs9638144的第一snp或与所述第一snp连锁不平衡的第二snp处的核苷酸的身份是与chd的发病率相关的生物标记物。
9、在一些实施方案中,所述生物样品选自血液和唾液。
10、在一些实施方案中,所述至少一个第一核酸引物检测非甲基化cpg二核苷酸。在一些实施方案中,所述至少一个第一核酸引物检测甲基化cpg二核苷酸。
11、在一些实施方案中,所述至少一个第一核酸引物包含一个或多个核苷酸类似物。在一些实施方案中,所述至少一个第一核酸引物包含一个或多个合成或非天然核苷酸。
12、在一些实施方案中,发病窗口是三年。
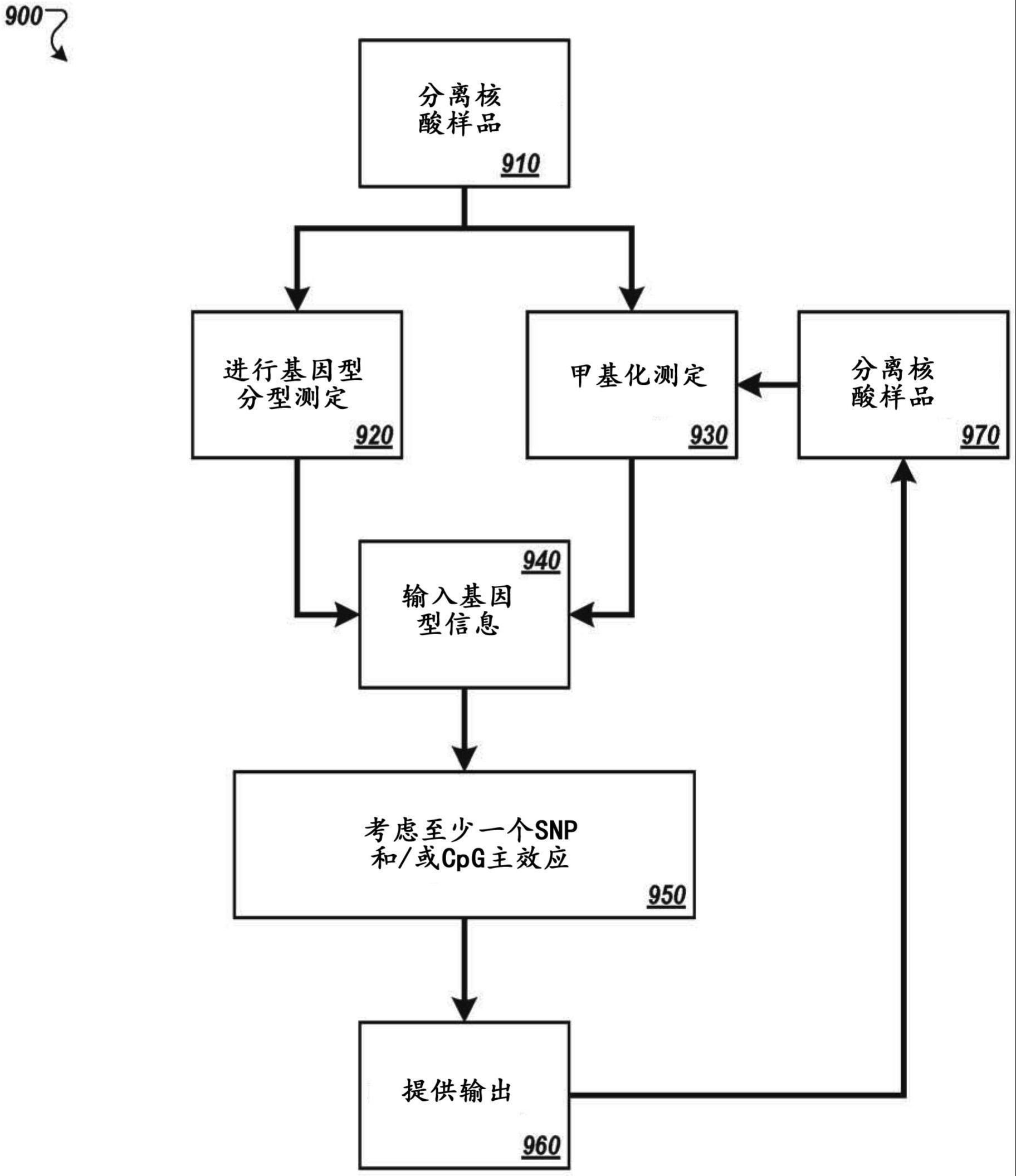
13、在再另外的方面,提供了确定患者样品中与chd相关的生物标记物的存在的方法。此类方法通常包括(a)从所述患者样品分离核酸样品,(b)对所述核酸样品的第一部分进行基因型分型测定,以检测至少一个snp的存在,其中所述至少一个snp是来自附录c的第一snp和/或是与来自附录c的第一snp连锁不平衡(r>0.3)的第二snp,以获得基因型数据;和/或(c)亚硫酸氢盐转化所述核酸的第二部分中的核酸,并对所述核酸样品的第二部分进行甲基化评估,以检测来自附录a的至少一个cpg位点和/或与来自附录a的cpg共线(r>0.3)的cpg位点的甲基化状态,以获得甲基化数据;以及(d)将来自步骤(b)的基因型数据和/或来自步骤(c)的甲基化数据输入到算法中,所述算法考虑至少一个snp主效应和/或至少一个cpg主效应和/或至少一个相互作用效应,其中所述算法是能够考虑线性效应和非线性效应的机器学习算法。
14、在一些实施方案中,所述至少一个相互作用效应选自基因-环境相互作用(snpxcpg)效应、基因-基因相互作用(snpxsnp)效应以及环境-环境相互作用(cpgxcpg)效应。
15、在一些实施方案中,所述至少一个相互作用效应是来自附录a的cpg位点或与来自附录a的cpg位点共线(r>0.3)的cpg位点与来自附录c的snp或与来自附录c的snp中等连锁不平衡(r>0.3)的snp之间的基因-环境相互作用效应(snpxcpg)。在一些实施方案中,所述至少一个相互作用效应是来自附录a的至少两个cpg位点之间的环境-环境相互作用效应(cpgxcpg)。
16、在一些实施方案中,所述至少两个cpg位点中的一个或两个与来自附录a的至少两个cpg位点中的一个或两个共线(r>0.3)。在一些实施方案中,所述至少一个相互作用效应是来自附录c的至少两个snp之间的基因-基因相互作用效应(snpxsnp)。在一些实施方案中,所述至少两个snp中的一个或两个与来自附录c的至少两个snp中的一个或两个共线(r>0.3)。
17、在一些实施方案中,所述生物样品是唾液样品。
18、在另一方面,提供了用于确定至少一个cpg二核苷酸的甲基化状态和至少一个单核苷酸多态性(snp)的基因型的系统。此类系统通常包括:核酸分离模块,其被配置为从受试样品分离核酸样品;基因型分型测定模块,其被配置为对所述核酸样品的第一部分进行基因型分型测定,以检测至少一个snp的存在,其中所述至少一个snp是来自附录c的第一snp和/或是与来自附录c的第一snp连锁不平衡(r>0.3)的第二snp,以获得基因型数据;甲基化测定模块,其被配置为亚硫酸氢盐转化所述核酸的第二部分中的核酸,并对所述核酸样品的第二部分进行甲基化评估,以检测来自附录a的至少一个cpg位点和/或与来自附录a的cpg共线(r>0.3)的cpg位点的甲基化状态,以获得甲基化数据;以及鉴定系统,其被配置为基于来自步骤(b)的基因型数据和/或来自步骤(c)的甲基化数据来考虑至少一个snp主效应和/或至少一个cpg主效应和/或至少一个相互作用效应。
19、在一些实施方案中,此类系统进一步包括输出模块,其被配置为基于所述鉴定系统的鉴定来提供输出,其中所述鉴定基于来自步骤(b)的基因型数据和/或来自步骤(c)的甲基化数据来考虑至少一个snp主效应和/或至少一个cpg主效应和/或至少一个相互作用效应。
20、在一些实施方案中,所述算法是能够考虑线性和非线性效应的机器学习算法。
21、在又另一方面,提供了非暂时性计算机可读介质,其存储可由执行操作的处理装置执行的指令。此类操作通常包括基于基因型数据和/或甲基化数据考虑至少一个snp主效应和/或至少一个cpg主效应和/或至少一个相互作用效应,其中:(i)所述基因型数据基于对从受试样品分离的核酸样品的第一部分的基因型分型测定,以检测至少一个snp的存在,其中所述至少一个snp是来自附录c的第一snp和/或是与来自附录c的第一snp连锁不平衡(r>0.3)的第二snp,以获得基因型数据;并且(ii)所述甲基化数据基于对所述核酸样品的第二部分中的亚硫酸氢盐转化核酸的甲基化测定,以检测来自附录a的至少一个cpg位点和/或与来自附录a的cpg共线(r>0.3)的cpg位点的甲基化状态,以获得甲基化数据。
22、在一些实施方案中,所述操作进一步包括基于所述考虑提供输出。代表性输出包括而不限于以下中的一个或多个:基于所述考虑将报告存储到另一非暂时性计算机可读介质,基于所述考虑修改显示,基于所述考虑触发可听警报,基于所述考虑触发触觉或振动警报,基于所述考虑触发报告的打印,或基于所述考虑触发治疗剂的递送。
23、本文描述的整合遗传-表观遗传模型提供了若干优点和益处。第一个是跨群组的总体灵敏度。平均而言,在intermountain healthcare(im)群组中,典型的风险计算器在10名个体中准确地鉴定出5名新发事件高风险个体,相比而言本文所述的整合遗传-表观遗传模型在10名个体中准确地鉴定出7名新发事件高风险个体。第二个是关于标准风险计算器按性别鉴定的性能。平均而言,在im群组中,典型的风险计算器在10名男性中准确地鉴定出5名并且在10名女性中准确地鉴定出4名处于新发事件风险中。平均而言,在im群组中,本文所述的整合遗传-表观遗传工具在10名男性中准确地鉴定出7名并且在10名女性中准确地鉴定出7名处于新发事件风险中。因此,本文所述的整合遗传-表观遗传模型在鉴定处于新发事件风险中的男性和女性的能力方面没有展现出性别差距。
24、除非另外定义,否则本文中使用的所有技术术语和科学术语具有与所述方法和物质组合物所属领域的普通技术人员通常所理解的含义相同的含义。尽管与本文所述的方法和材料类似或等同的方法和材料可以用于所述方法和物质组合物的实践或测试中,但下文描述了合适的方法和材料。此外,材料、方法以及例子仅是说明性的并且不旨在局限于预测新发chd。本文提及的所有出版物、专利申请、专利和其他参考文献都通过引用以其整体而并入。
- 还没有人留言评论。精彩留言会获得点赞!