用于治疗1a型糖原贮积症的组合物和方法与流程
背景技术:
1、对于大多数已知的遗传疾病,要研究或解决该疾病的根本病因,需要校正靶基因座中的点突变,而不是随机破坏基因。当前的基因组编辑技术利用成簇规律间隔短回文重复序列(crispr)系统在靶基因座处引入双链dna断裂作为基因校正的第一步。为了响应双链dna断裂,细胞dna修复过程主要通过非同源末端接合在dna切割位点处产生随机插入或缺失(indel)。尽管大多数遗传疾病是由点突变引起的,但当前的点突变校正方法效率低下,并且典型地会因细胞对dsdna断裂的反应而在靶基因座处诱导大量随机插入和缺失(indel)。因此,需要一种改进的基因组编辑形式,这种形式更有效,并且具有更少的不需要产物,例如随机插入或缺失(indel)或易位。
2、1型糖原贮积症(又称为gsd1或冯吉尔克氏病(von gierke disease))是一种遗传性病症,会导致糖原分解和糖异生不足,以及组织中糖原和脂质积累,引起危及生命的低血糖和乳酸性酸中毒,并导致潜在的cns损伤和长期肝肾并发症,如脂肪变性、肝腺瘤和肝细胞癌。
3、gsd1有两种类型,1a型(gsd1a或gsd-ia)和1b型(gsd1b),它们是由不同的基因突变引起的。gsd1a是由葡萄糖-6-磷酸酶(g6pc)基因突变引起的,并影响约80%的gsd1患者。在美国,每100,000名新生儿中就有约一名患有gsd1a,其中约22%的患者携带隐性突变q347*,而37%的患者携带隐性突变r83c。
4、没有被批准用于gsd1a的药物疗法。虽然肝移植是能治病的,但没有经过批准的疗法,而且当前的治疗方案涉及几乎连续地食用玉米淀粉。如果长期不治疗,则患者会发展严重的乳酸性酸中毒,可进展为肾衰竭,并且在婴儿期或儿童期中死亡。gsd1a是一个亟待满足医疗需求的领域。因此,需要用于治疗gsd1a患者的新颖组合物和方法。
技术实现思路
1、本文表现特征、提供和描述的是使用可编程的核碱基编辑器精确校正致病性氨基酸的组合物和方法。具体点说,本文公开和描述的组合物和方法可用于治疗1a型糖原贮积症(gsd1a)。因此,提供了使用腺苷(a)碱基编辑器(abe)精确校正内源性g6pc基因中的单核苷酸多态性以校正有害突变(例如q347x、r83c)来治疗gsd1a的组合物和方法。
2、在一方面,提供了一种腺苷脱氨酶变体,该变体包括以下氨基酸序列中第82位氨基酸处的甘氨酸(g)、第147位氨基酸处的苏氨酸(t)或天冬氨酸(d)、第154位氨基酸处的丝氨酸(s)以及以下中的一者或多者:第36位氨基酸处的组氨酸(h)、第76位氨基酸处的酪氨酸、第149位氨基酸处的酪氨酸、第157位氨基酸处的赖氨酸(k)和第167位氨基酸处的天冬酰胺(n),其中腺苷脱氨酶与所述氨基酸序列具有至少约85%的同一性:
3、msevefsheywmrhaltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1),或另一腺苷脱氨酶的相应改变。
4、另一方面提供了一种腺苷脱氨酶变体,参照以下seq id no:1,该变体包括以下改变组合中的任一者:a)i76y+v82g+y147t+q154s;b)l36h+v82g+y147t+q154s+n157k;c)v82g+y147d+f149y+q154s+d167n;d)l36h+v82g+y147d+f149y+q154s+n157k+d167n;e)l36h+i76y+v82g+y147t+q154s+n157k;f)i76y+v82g+y147d+f149y+q154s+d167n;g)y147d+f149y+d167n;h)l36h;i76y;v82g;q154s;和n157k;i)i76y;v82g;q154s;或j)l36h+i76y+v82g+y147d+f149y+q154s+n157k+d167n,
5、msevefsheywmrhaltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1);或另一腺苷脱氨酶中的相应改变组合。
6、在上述腺苷脱氨酶变体的一个实施方案中,腺苷脱氨酶变体包括seq id no:1中的以下改变组合:i76y+v82g+y147d+f149y+q154s+d167n,或另一腺苷脱氨酶的相应改变。在另一个实施方案中,腺苷脱氨酶与seq id no:1具有至少约90%的同一性。在另一个实施方案中,腺苷脱氨酶与seq id no:1具有至少约95%的同一性。在另一个实施方案中,腺苷脱氨酶包含seq id no:1或基本上由seq id no:1组成。
7、另一方面,提供了一种融合蛋白或复合物,该融合蛋白或复合物包括多核苷酸可编程dna结合结构域和至少一个腺苷脱氨酶变体结构域,其中腺苷脱氨酶变体结构域包含以下氨基酸序列中第82位氨基酸处的甘氨酸(g)、第147位氨基酸处的苏氨酸(t)或天冬氨酸(d)、第154位氨基酸处的丝氨酸(s)以及以下中的一者或多者:第36位氨基酸处的组氨酸(h)、第76位氨基酸处的酪氨酸、第149位氨基酸处的酪氨酸、第157位氨基酸处的赖氨酸(k)和第167位氨基酸处的天冬酰胺(n),其中腺苷脱氨酶与所述氨基酸具有至少约85%的同一性:msevefsheywmrhaltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1);或另一腺苷脱氨酶的相应改变。在融合蛋白或复合物的一个实施方案中,腺苷脱氨酶变体结构域与seq id no:1具有至少约90%的同一性。在融合蛋白或复合物的另一个实施方案中,腺苷脱氨酶变体结构域与seq id no:1具有至少约95%的同一性。在融合蛋白或复合物的另一个实施方案中,腺苷脱氨酶变体结构域包含seqid no:1或基本上由seq id no:1组成。
8、又另一方面提供了一种融合蛋白或复合物,该融合蛋白或复合物包括多核苷酸可编程dna结合结构域和至少一个腺苷脱氨酶变体结构域,其中参照以下seq id no:1,该腺苷脱氨酶变体结构域包含以下改变组合中的任一者:a)i76y+v82g+y147t+q154s;b)l36h+v82g+y147t+q154s+n157k;c)v82g+y147d+f149y+q154s+d167n;d)l36h+v82g+y147d+f149y+q154s+n157k+d167n;e)l36h+i76y+v82g+y147t+q154s+n157k;f)i76y+v82g+y147d+f149y+q154s+d167n;g)y147d+f149y+d167n;h)l36h、i76y、v82g、q154s和n157k;i)i76y、v82g、q154s;或j)l36h+i76y+v82g+y147d+f149y+q154s+n157k+d167n,
9、msevefsheywmrhaltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1);或另一腺苷脱氨酶中的相应改变组合。
10、在上述融合蛋白或复合物的一些实施方案中,腺苷脱氨酶变体包括seq id no:1中的以下变化组合:i76y+v82g+y147d+f149y+q154s+d167n,或另一腺苷脱氨酶中的相应改变组合。在一些实施方案中,融合蛋白或复合物包括一个腺苷脱氨酶变体结构域。在一些实施方案中,融合蛋白或复合物包括野生型腺苷脱氨酶结构域和腺苷脱氨酶变体结构域。在一些实施方案中,融合蛋白或复合物包括tada*7.10腺苷脱氨酶结构域和腺苷脱氨酶变体结构域。在一些实施方案中,多核苷酸可编程dna结合结构域是cas9结构域。在一些实施方案中,cas9结构域包含核酸酶失活型cas9(dcas9)、cas9切口酶(ncas9)或核酸酶活性型cas9。在一些实施方案中,多核苷酸可编程dna结合结构域是金黄色葡萄球菌(staphylococcus aureus)cas9(sacas9)、嗜热链球菌1(streptococcus thermophilus 1)cas9(st1cas9)、化脓性链球菌(streptococcus pyogenes)cas9(spcas9)或其变体。在一些实施方案中,多核苷酸可编程dna结合结构域包含具有改变的原间隔序列相邻基序(pam)特异性的修饰过的sacas9。在一些实施方案中,sacas9对核酸序列5'-nngrrt-3'具有原间隔序列相邻基序(pam)特异性。在一些实施方案中,sacas9对核酸序列5'-gagaat-3'具有特异性。在一些实施方案中,sacas9是核酸酶活性型sacas9、无核酸酶活性型sacas9(sacas9d)或sacas9切口酶(sacas9n)。在一些实施方案中,sacas9是包含氨基酸取代n579a或其相应氨基酸取代的切口酶。在一些实施方案中,sacas9是化脓性链球菌cas9(spcas9)或其变体。
11、在上述融合蛋白或复合物的一些实施方案中,腺苷脱氨酶变体能够使脱氧核糖核酸(dna)中的腺嘌呤脱氨基。在一些实施方案中,融合蛋白或复合物还包括多核苷酸可编程dna结合结构域与腺苷脱氨酶变体结构域之间的接头。在一些实施方案中,接头包含氨基酸序列:sggssggssgsetpgtsesatpes(seq id no:359)。在一些实施方案中,融合蛋白或复合物包括一个或多个核定位信号。在一些实施方案中,核定位信号是双组分核定位信号。在一些实施方案中,多核苷酸可编程dna结合结构域与脱氨酶非共价缔合。
12、另一方面提供一种碱基编辑器系统,该系统包括本文所提供的融合蛋白或复合物中的任一者,以及一个或多个指导多核苷酸。在一些实施方案中,所述一个或多个指导多核苷酸靶向融合蛋白以实现与遗传疾病相关的单核苷酸多态性(snp)的a·t到g·c改变。在一些实施方案中,所述遗传疾病是1a型糖原贮积症(gsd1a)。在一些实施方案中,所述指导多核苷酸包含核糖核酸(rna)或脱氧核糖核酸(dna)。在一些实施方案中,指导多核苷酸包含核酸序列:5'-caguauggacacuguccaaa-3'(seq id no:370)。在一些实施方案中,指导序列包含以下核酸序列之一或由以下核酸序列之一组成:
13、caccaguauggacacuguccaaaguuuuaguacucugua augaaaauuacagaaucuacuaaaacaaggcaaaaugccgu guuuaucucgucaacuuguuggcgagauuuu(seq id no:409),或
14、ccaccaguauggacacuguccaaaguuuuaguacucugu aaugaaaauuacagaaucuacuaaaacaaggcaaaaugccg uguuuaucucgucaacuuguuggcgagauuuu(seq id no:410)。在一些实施方案中,所述指导多核苷酸在该指导的5'端和/或3'端包含一个或多个修饰过的核苷。在一些实施方案中,所述指导多核苷酸在该指导的5'端和/或3'端包含两个、三个、四个或更多个修饰过的核苷。在一些实施方案中,所述指导多核苷酸在该指导的5'端和/或3'端包含两个、三个、四个或更多个修饰过的核苷。在一些实施方案中,所述指导多核苷酸在该指导的5'端包含四个修饰过的核苷并在该指导的3'端包含四个修饰过的核苷。在一些实施方案中,修饰过的核苷包含2’o-甲基或硫代磷酸酯。在一些实施方案中,指导多核苷酸包含以下序列之一或基本上由以下序列之一组成:
15、mcsmasmcscaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagamusmusmusu(seq id no:409)或mcsmcsmasccaguauggacacuguccaa aguuuuaguacucuguaaugaaaauuacagaaucuacuaaa acaaggcaaaaugccguguuuaucucgucaacuuguuggcg agamusmusmusu(seq id no:410),其中“m”表示2'o-甲基并且“s”表示硫代磷酸酯。在一些实施方案中,指导多核苷酸包含核酸序列:5'-caguauggacacuguccaaa-3'(seq id no:370)。在一些实施方案中,指导多核苷酸包含以下核酸序列,从5'到3':cca ccaguauggacacuguc(seq id no:371);caccaguaugg acacugucc(seq id no:372);accaguauggacacugucc a(seq id no:373);ccaguauggacacuguccaa(seqid no:374);caguauggacacuguccaaa(seq id no:370);aguauggacacuguccaaag(seq idno:375);guauggaca cuguccaaaga(seq id no:376);或uauggacacugucca aagag(seq idno:377)。在一些实施方案中,腺苷脱氨酶变体结构域在cas蛋白的内部。
16、另一方面提供一种多核苷酸,该多核苷酸编码本文所提供的腺苷脱氨酶变体中的任一者、本文所提供的融合蛋白或复合物中的任一者或本文所提供的碱基编辑器系统中的任一者。在一个实施方案中,所述多核苷酸包含一个或多个修饰过的核苷或核苷酸。在一个实施方案中,所述多核苷酸是dna或rna。在实施方案中,所述多核苷酸包含选自由以下组成的组的修饰:2'-o-甲基(2'-ome)、硫代磷酸酯(ps)、2'-o-甲基硫代pace(msp)、2'-o-甲基-pace(mp)、2'-氟rna(2'-f-rna)和限制性乙基(s-cet)。
17、另一方面提供了一种细胞,该细胞包括本文所提供的多核苷酸中的任一者。
18、又另一方面提供了一种细胞,该细胞包括本文所提供的腺苷脱氨酶变体中的任一者、本文所提供的融合蛋白或复合物中的任一者和一个或多个指导多核苷酸、本文所提供的碱基编辑器系统中的任一者或本文所提供的多核苷酸中的任一者。
19、在上述方面的一些实施方案中,所述细胞是肝细胞、肝细胞前体或ipsc源性肝细胞。在一些实施方案中,所述细胞表达g6pc多肽。在一些实施方案中,所述细胞来自患有1a型糖原贮积症(gsd1a)的受试者。在一些实施方案中,所述细胞是体内、离体或体外的哺乳动物细胞。在一些实施方案中,所述细胞是人细胞。在一些实施方案中,融合蛋白和一个或多个指导多核苷酸在细胞中形成复合物。
20、另一方面,提供了一种治疗有需要受试者的遗传疾病的方法,其中该方法涉及向该受试者的细胞施用如本文所提供的碱基编辑器系统中的任一者或编码该碱基编辑器系统的多核苷酸。
21、另一方面,提供了一种治疗有需要受试者的遗传疾病的方法,其中该方法涉及向该受试者施用本文所提供的细胞中的任一者。
22、在上述方法的一些实施方案中,处理后,细胞表达能够催化d-葡萄糖6-磷酸水解为d-葡萄糖和正磷酸酯的g6pc多肽。在一些实施方案中,细胞对于受试者来说是自体的、同种异体的或异种的。在一些实施方案中,所述遗传疾病是1a型糖原贮积症(gsd1a)和/或其症状。在上述治疗方法的一个实施方案中,受试者在治疗后维持至少24小时的禁食期。
23、另一方面,提供了一种用于校正多核苷酸中的单核苷酸多态性(snp)的方法,其中该方法涉及使靶核苷酸序列与本文所提供的碱基编辑器系统中的任一者接触,该靶核苷酸序列的至少一部分位于该多核苷酸或其反向互补序列中;并在碱基编辑器靶向靶核苷酸序列时,通过使snp或其互补核碱基脱氨基来编辑该snp,其中使snp或其互补核碱基脱氨基将校正该snp。在一些实施方案中,snp与1a型糖原贮积症(gsd1a)相关。在一些实施方案中,snp在g6pc基因中。
24、另一方面,提供了一种编辑包含与1a型糖原贮积症(gsd1a)相关的单核苷酸多态性(snp)的葡萄糖-6-磷酸酶(g6pc)多核苷酸的方法,其中该方法包括使该g6pc多核苷酸接触本文所提供的融合蛋白或复合物中的任一者与一个或多个指导多核苷酸的复合物,并且其中所述指导多核苷酸中的一者或多者靶向所述碱基编辑器以实现与gsd1a相关的snp的a·t到g·c改变。
25、在上述方法的一些实施方案中,接触是在细胞、真核细胞、哺乳动物细胞或人类细胞中进行的。在一些实施方案中,snp将g6pc多肽中的谷氨酰胺(q)变为非谷氨酰胺(x)氨基酸或将精氨酸(r)变为非精氨酸(x)。在一些实施方案中,snp导致在第347位处具有非谷氨酰胺(x)氨基酸或在第83位处具有非精氨酸(x)氨基酸的g6pc多肽的表达。在一些实施方案中,碱基编辑器校正将在第347位处的非谷氨酰胺氨基酸(x)替换为谷氨酰胺或在第83位处的非精氨酸氨基酸(x)替换为精氨酸(r)。在一些实施方案中,snp使得g6pc多肽的表达在第347位氨基酸处或第83位的半胱氨酸处提前终止。在一些实施方案中,snp编码q347x和/或r83c中的一者或多者。在一些实施方案中,snp编码r83c。在一些实施方案中,编辑使indel的形成少于0.5%。在一些实施方案中,编辑挽救了g6pc的催化活性。在一些实施方案中,指导多核苷酸包含核酸序列:5'-caguauggaca cuguccaaa-3'(seq id no:370)。在一些实施方案中,指导多核苷酸包含以下核酸序列,从5'到3':ccaccaguauggacacuguc(seq id no:371);caccaguauggacacugucc(seq id no:372);accaguauggacacugucca(seq id no:373);cc aguauggacacuguccaa(seq id no:374);caguauggac acuguccaaa(seq id no:370);aguauggacacuguccaaag(seq id no:375);guauggacacuguccaaaga(seq id no:376);或uauggacacuguccaaagag(seq id no:377)。在所述方法的一些实施方案中,受试者在治疗后维持至少24小时的禁食期。
26、另一方面提供了一种载体,该载体包含本文所提供和描述的多核苷酸中的任一者。在一些实施方案中,所述载体是病毒载体。在一些实施方案中,所述病毒载体是逆转录病毒载体、腺病毒载体、慢病毒载体、疱疹病毒载体或腺相关病毒载体(aav)。
27、另一方面提供了一种组合物,该组合物包括本文所提供的融合蛋白或复合物中的任一者、本文所提供的碱基编辑器系统中的任一者、本文所提供的多核苷酸中的任一者、本文所提供的细胞中的任一者或本文所提供的载体中的任一者。在一些实施方案中,所述组合物还包括药学上可接受的赋形剂、载体或媒剂。在一些实施方案中,一个或多个指导多核苷酸和融合蛋白是一起或分开配制的。在一些实施方案中,所述组合物还包括适合在哺乳动物细胞中表达的核糖核颗粒(ribonucleoparticle)。在一些实施方案中,所述组合物还包括脂质。在一些实施方案中,所述组合物包含脂质纳米颗粒(lnp)。
28、另一方面提供了一种试剂盒,该试剂盒包括本文所提供的融合蛋白或复合物中的任一者、本文所提供的碱基编辑器系统中的任一者、本文所提供的多核苷酸中的任一者、本文所提供的细胞中的任一者、本文所提供的载体中的任一者或本文所提供的组合物中的任一者。在一些实施方案中,所述试剂盒还包括有关使用该试剂盒治疗1a型糖原贮积症(gsd1a)的书面说明。
29、另一方面提供了本文所提供和描述的融合蛋白或复合物中的任一者、本文所提供和描述的碱基编辑器系统中的任一者、本文所提供和描述的多核苷酸中的任一者、本文所提供和描述的细胞中的任一者、本文所提供和描述的载体中的任一者或本文所提供和描述的组合物中的任一者,其中该碱基编辑器包含如seq id no:396中所示的mrna序列。
30、另一方面提供了本文所提供和描述的融合蛋白或复合物中的任一者、本文所提供和描述的碱基编辑器系统中的任一者、本文所提供和描述的多核苷酸中的任一者、本文所提供和描述的细胞中的任一者、本文所提供和描述的载体中的任一者或本文所提供和描述的组合物中的任一者,其中该碱基编辑器包含如seq id no:397中所示的dna序列。
31、另一方面提供了本文所提供和描述的融合蛋白或复合物中的任一者、本文所提供和描述的碱基编辑器系统中的任一者、本文所提供和描述的多核苷酸中的任一者、本文所提供和描述的细胞中的任一者、本文所提供和描述的载体中的任一者或本文所提供和描述的组合物中的任一者,其中该碱基编辑器包含如seq id no:398中所示的氨基酸序列。
32、另一方面,提供了一种修饰过的指导rna(guide rna,grna),该grna包含修饰过的核苷酸,其中该grna从5'到3'包含选自由以下组成的组的多核苷酸序列:
33、caguauggacacuguccaaaguuuuaguacucuguaau gaaaauuacagaaucuacuaaaacaaggcaaaaugccgugu uuaucucgucaacuuguuggcgagauuuu(seq id no:404);
34、uuucaguauggacacuguccaaaguuuuaguacucugu aaugaaaauuacagaaucuacuaaaacaaggcaaaaugccg uguuuaucucgucaacuuguuggcgagauuuu(seq id no:405);
35、caguauggacacuguccaaaguuuuaguacucuggaaacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:406);
36、ccaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:407);
37、accaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:408);
38、caccaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:409);
39、ccaccaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:410);
40、caguauggacacuguccaaaguuuuaguacucuguagaaauacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:411);
41、caguauggacacuguccaaaguuuuaguacucugcggaaacgcagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagauuuu(seq id no:412);
42、caguauggacacuguccaaaguuuuaguacucgaaagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaa cuuguuggcgagauuuu(seq id no:413);
43、caguauggacacuguccaaaguuuuaguacccgaaagca ucuacuaaaacaaggcaaaaugccguguuuaucucgucaac uuguuggcgagauuuu(seq id no:414);和
44、caguauggacacuguccaaaguuuuaguacucuguaau gaaaauuacagaaucuacuaaaacaaggcaaaaugccgugu uuaucucgucaacuuguuggcgagauuuu(seq id no:415)。
45、在一些实施方案中,所述指导包含至少约50%-75%的修饰过的核苷酸。在一些实施方案中,所述指导包含至少约85%的修饰过的核苷酸。在一些实施方案中,在grna 5'端处的至少约1-5个核苷酸被修饰并且在grna 3'端处的至少约1-5个核苷酸被修饰。在一些实施方案中,在grna的5'末端和3'末端各有至少约3-5个连续核苷酸被修饰。在一些实施方案中,存在于正向重复序列或反向重复序列中的核苷酸中有至少约20%被修饰。在一些实施方案中,存在于正向重复序列或反向重复序列中的核苷酸中有至少约50%被修饰。在一些实施方案中,存在于正向重复序列或反向重复序列中的核苷酸中有至少约50%-75%被修饰。在一些实施方案中,存在于正向重复序列或反向重复序列中的核苷酸中有至少约100被修饰。在一些实施方案中,存在于grna骨架中存在的发夹中的核苷酸中有至少约20%或更高百分比被修饰。在一些实施方案中,存在于grna骨架中存在的发夹中的核苷酸中有至少约50%或更高百分比被修饰。在一些实施方案中,指导包含可变长度的原间隔序列。在一些实施方案中,指导包含20-40个核苷酸的原间隔序列。在一些实施方案中,指导包括含至少约20-25个核苷酸或至少约30-35个核苷酸的原间隔序列。在一些实施方案中,原间隔序列包含修饰过的核苷酸。在一些实施方案中,指导包括以下中的两者或更多者:
46、在grna 5'端处的至少约1-5个核苷酸被修饰并且在grna 3'端处的至少约1-5个核苷酸被修饰;
47、存在于正向重复序列或反向重复序列中的核苷酸中有至少约20%被修饰;
48、存在于正向重复序列或反向重复序列中的核苷酸中有至少约50%-75%被修饰;
49、存在于grna骨架中存在的发夹中的核苷酸中有至少约20%或更高百分比被修饰;
50、可变长度的原间隔序列;和
51、包含修饰过的核苷酸的原间隔序列。
52、在修饰过的grna的一些实施方案中,该grna包含一个或多个选自由以下组成的组的修饰:2′-o-甲基(2'-ome)、硫代磷酸酯(ps)、2′-o-甲基硫代pace(msp)、2′-o-甲基-pace(mp)、2'-氟rna(2'-f-rna)和限制性乙基(s-cet)。在实施方案中,grna包含2'-o-甲基或硫代磷酸酯修饰。在一个实施方案中,grna包含2'-o-甲基或硫代磷酸酯修饰。在一个实施方案中,修饰使碱基编辑增加至少约2倍。
53、另一方面,提供了一种修饰过的指导rna(grna),其中该grna包含选自以下的核酸序列,从5'到3':
54、mcsmasmgsmuaumgmgmacamcuguccaaamguuuumamgmuacucmugmumamamugmaaamamumumacmagaaucuacmumaaaacaaggcaamaaugmccmgugumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:404);
55、musmusmuscagmuaumgmgmacamcuguccaaamguuuumamgmuacucmugmumamamugmaaamamumumacmagaaucuacmumaaaacaaggcaamaaugmccmgugumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:405);
56、mcsmasgsmuaumgmgmamcamcmuguccaamamgumuumumamgmuacumcmumgmumamamugmamamamamumumacmamgaamucuacmumamaaacaagmgcaamaaugmcmcmgugmumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:404);
57、mcsmasgsmumaumgmgmamcamcuguccaamamguuumuamgmuacumcmumgmumamamumgmamamamamumumamcmamgmaamucuacumamaaacaamgmgmcmamamaaumgmcmcgugmumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:404);或
58、mcsmasgsmumaumgmgmamcamcmugucmcmaamamgmumumumumamgmuamcmumcmumgmumamamumgmamamamamumumamcmamgmamamucuacmumamamaamcamamgmgmcmamamaaumgmcmcmgmugmumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:404)。
59、另一方面,提供了一种修饰过的指导rna(grna),该grna包含选自以下的核酸序列,从5'到3':
60、mcsmasmgsuauggacacuguccaaaguuuuaguacmumcmumgmumamamumgmamamamamumumamcmamgmaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagausmusmusmu(seqid no:404);
61、mcsmasmgsuauggacacuguccaaaguuuuaguacmumcmumgmumamamumgmamamamamumumamcmamgmaaucuacuaaaacaaggcaaaaugccgugumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:404);
62、mcsmasmgsmuaumgmgmacamcuguccaaamguuuuaguacmumcmumgmumamamumgmamamamamumumamcmamgmaaucuacuaaaacaaggcaaaaugccmgugumumuamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmausmusmusmu(seq id no:404);
63、mcsmasmgsuauggacacuguccaaaguuuuaguacmumcmumggmamamamcmamgmaaucuacuaaaacaaggcaaaaugccgugumumumamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmamusmusmusmu(seq id no:406);或
64、mcsmasmgsmuaumgmgmacamcuguccaaamguuuuaguacmumcmumgmgmamamamcmamgmaaucuacuaaaacaaggcaaaaugccmgugumumuamumcmumcmgmumcmamamcmumumgmumumgmgmcmgmamgmausmusmusmu(seq id no:406)。
65、另一方面,提供了一种修饰过的指导rna(grna),该grna包含选自以下的核酸序列,从5'到3':
66、mcsmcsmasguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagamusmusmusu(seq id no:407);
67、masmcsmcsaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagamusmusmusu(seq id no:408);
68、mcsmasmcscaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagamusmusmusu(seq id no:409);或
69、mcsmcsmasccaguauggacacuguccaaaguuuuaguacucuguaaugaaaauuacagaaucuacuaaaacaaggcaaaaugccguguuuaucucgucaacuuguuggcgagamusmusmusu(seq id no:410)。
70、另一方面,提供了一种修饰过的指导rna(grna),该grna包含选自以下的核酸序列,从5'到3':
71、mcsmasmgsuauggacacuguccaaaguuuuaguacucug uagaaauacagaaucuacuaaaacaaggcaaaaugccgugu uuaucucgucaacuuguuggcgagausmusmusmu(seq id no:411);
72、mcsmasmgsuauggacacuguccaaaguuuuaguacucug cg gaaa cgcagaaucuacuaaaacaaggcaaaaugccgug uuuaucucgucaacuuguuggcgagausmusmusmu(seq id no:412);
73、mcsmasmgsuauggacacuguccaaaguuuuaguacucug gaaacagaaucuacuaaaacaaggcaaaaugccguguuuau cucgucaacuuguuggcgagausmusmusmu(seq id no:406);
74、mcsmasmgsuauggacacuguccaaaguuuuaguacucga aagaaucuacuaaaacaaggcaaaaugccguguuuaucucg ucaacuuguuggcgagausmusmusmu(seq id no:413);或
75、mcsmasmgsuauggacacuguccaaaguuuuaguacccga aagcaucuacuaaaacaaggcaaaaugccguguuuaucucg ucaacuuguuggcgagausmusmusmu(seq id no:414)。
76、另一方面,提供了一种修饰过的指导rna(grna),其中该grna包含选自以下的核酸序列,从5'到3':
77、mcsmasmgsuauggacacuguccaaaguuuuaguacucug uaaugaaaauuacagaaucuacuaaaacaaggcaaaaugcc guguuuaucucgucaacuuguuggcgagausmusmusmu(seq id no:415);或
78、mcsmasmgsuauggacacuguccaaaguuuuaguacucug uaaugaaaauuacagaaucuacuaaaacaaggcaaaaugcc guguuuaucucgucaacuuguuggcgagamusmusmusu(seq id no:415)。
79、在上述修饰过的grna中,“m”表示2'-o-甲基,并且“s”表示硫代磷酸酯。
80、另一方面,提供了一种配制物,该配制物包含脂质纳米颗粒,该脂质纳米颗粒包含表达碱基编辑器的mrna和grna,其中该碱基编辑器包含cas9结构域和至少一种腺苷脱氨酶变体,参照以下seq id no:1,该变体包含v82g、y147t/d、q154s,以及l36h、i76y、f149y、n157k和d167n中的一者或多者:
81、msevefsheywmrhaltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1),或另一腺苷脱氨酶中的相应改变;并且所述grna包含caguauggacacuguccaaa(seq id no:370)。
82、另一方面,提供了一种配制物,该配制物包含脂质纳米颗粒,该脂质纳米颗粒包含:表达碱基编辑器的mrna,其中该碱基编辑器包含cas9结构域和至少一种腺苷脱氨酶变体,参照以下seq id no:1,该变体包含v82g、y147t/d、q154s,以及l36h、i76y、f149y、n157k和d167n中的一者或多者:
83、msevefsheywmrhaltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1),或另一腺苷脱氨酶中的相应改变;以及grna,该grna包含caguauggacacuguccaaa(seq id no:370)。
84、在上述配制物的一些实施方案中,腺苷脱氨酶变体结构域包含seq id no:1中的以下变化组合:i76y+v82g+y147d+f149y+q154s+d167n;或另一腺苷脱氨酶中的相应改变。在一些实施方案中,grna包含2'-o-甲基和/或硫代磷酸酯修饰。在一些实施方案中,grna包含2'-o-甲基和硫代磷酸酯修饰。在一些实施方案中,mrna包含一种或多种假尿苷。在一些实施方案中,mrna包含n1-甲基假尿苷(m1ψ)。
85、本文所描述的其它方面提供了修饰过的指导rna序列(grna)(例如大量修饰(heavily modified)的grna序列或“heavy mods”),如实施例5中所述和seq id no:404-415中所示。
86、定义
87、除非另有定义,否则本文所使用的所有技术和科学术语均具有相关领域技术人员通常理解的含义。以下参考文献为技术人员提供了本公开和本文所描述的实施方案中使用的许多术语的一般定义:singleton等人,dictionary of microbiology and molecularbiology(第2版,1994);the cambridge dictionary of science and technology(walker编辑,1988);the glossary of genetics,第5版,r.rieger等人(编辑),springer verlag(1991);以及hale和marham,the harper collins dictionary of biology(1991)。
88、在本文中,除非另外确切说明,否则单数的使用包括复数。必须指出的是,除非上下文另有明确规定,否则如说明书和所附权利要求中所用,单数形式“一种/个(a)”、“一种/个(an)”和“所述(the)”包括多种/个指示物。在本技术中,除非另有说明,否则"或"的使用是指"和/或"。此外,术语“包括(including)”以及其它形式,如“包括(includes)”和“包括(included)”的使用是非限制性的。
89、如本说明书和权利要求中所使用,词语“包含(comprising)”(以及包含(comprising)的任何形式,如“包含(comprise)”和“包含(comprises)”)、“具有(having)”(以及具有(having)的任何形式,如“具有(have)”和“具有(has)”)、“包括(including)”(以及包括(including)的任何形式,如“包括(includes)”和“包括(include)”),或“含有(containing)”(以及含有(containing)的任何形式,如“包含(contains)”和“含有(contain)”)是包容性的或开放式的,并且不排除附加的、未提及的要素或方法步骤。指定为“包含”一种或多种特定组分或者一种或多种要素的任何实施方案在一些实施方案中也被视为“由该一种或多种特定组分或者一种或多种要素组成”或“基本上由一种或多种特定组分或者一种或多种要素组成”特定组件或元件。经审慎考虑,本说明书中讨论的任何实施方案都可以通过本公开的任何方法或组合物实现,并且反之亦然。此外,本公开的组合物可用于实现本公开的方法。
90、术语“约”或“大约”意指由本领域普通技术人员确定的特定值处于可接受的误差范围内。所述误差范围将部分取决于所述值的测量或确定方式,即,测量系统的限制。
91、本文所提供的范围应理解为所述范围内所有值的简写。例如,1到50的范围应理解为包括来自由以下组成的组的任何数字、数字组合或子范围:1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49或50。
92、在本说明书中提到“一些实施方案”、“一个实施方案(an embodiment/oneembodiment)”、“其它实施方案”意味着结合所述实施方案描述的特定特征、结构或特性包括在本公开的至少一些实施方案中,但未必包括在所有实施方案中。
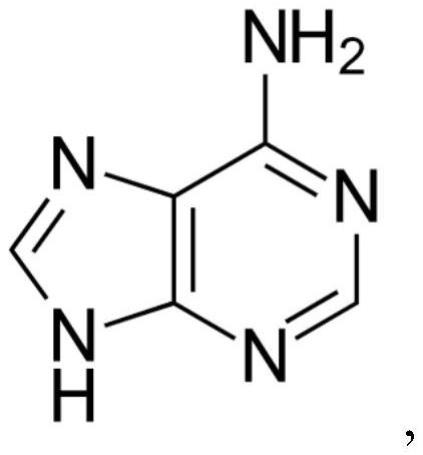
93、“腺嘌呤”或“9h-嘌呤-6-胺”是指分子式为c5h5n5的嘌呤核碱基,具有结构对应于cas号73-24-5。
94、“腺苷”或“4-氨基-1-[(2r,3r,4s,5r)-3,4-二羟基-5-(羟甲基)氧杂环戊烷-2-基]嘧啶-2(1h)-酮“是指通过糖苷键连接到核糖的腺嘌呤分子,具有结构对应于cas号65-46-3。其分子式是c10h13n5o4。
95、“腺苷脱氨酶”或“腺嘌呤脱氨酶”是指能够催化腺嘌呤或腺苷水解脱氨的多肽或其片段。在一些实施方案中,脱氨酶或脱氨酶结构域是催化腺苷水解脱氨成肌苷或脱氧腺苷水解脱氨成脱氧肌苷的腺苷脱氨酶。在一些实施方案中,腺苷脱氨酶催化脱氧核糖核酸(dna)中的腺嘌呤或腺苷水解脱氨。本文所提供的腺苷脱氨酶(例如工程改造的腺苷脱氨酶、进化的腺苷脱氨酶)可以来自任何生物体(例如真核生物、原核生物),包括但不限于藻类、细菌、真菌、植物、无脊椎动物(例如昆虫)和脊椎动物(例如两栖动物、哺乳动物)。在一些实施方案中,腺苷脱氨酶是具有一个或多个改变的腺苷脱氨酶变体并且能够使靶多核苷酸(例如dna、rna)中的腺嘌呤和胞嘧啶脱氨基。在一些实施方案中,靶多核苷酸是单链或双链的。在一些实施方案中,腺苷脱氨酶变体能够使dna中的腺嘌呤和胞嘧啶脱氨基。在一些实施方案中,腺苷脱氨酶变体能够使单链dna中的腺嘌呤和胞嘧啶脱氨基。在一些实施方案中,腺苷脱氨酶变体能够使rna中的腺嘌呤和胞嘧啶脱氨基。
96、“腺苷脱氨酶活性”是指催化多核苷酸中的腺嘌呤或腺苷脱氨为鸟嘌呤。在一些实施方案中,本文所提供的腺苷脱氨酶变体维持腺苷脱氨酶活性(例如是参考腺苷脱氨酶(例如tada*8.20或tada*8.19)的活性的至少约30%、40%、50%、60%、70%、80%、90%或更高百分比)。
97、“腺苷碱基编辑器(abe)”是指包含腺苷脱氨酶的碱基编辑器。
98、“腺苷碱基编辑器8(abe8)多肽”或“abe8”是指包含腺苷脱氨酶变体的如本文所定义的碱基编辑器,该腺苷脱氨酶变体在以下参照序列的第82位和/或第166位氨基酸处包含改变:msevefsheywmr haltlakrarderevpvgavlvlnnrvigegwnraiglhdptahaeimalrqgglvmqnyrlidatlyvtfepcvmcagamihsrigrvvfgvrnaktgaagslmdvlhypgmnhrveitegiladecaallcyffrmprqvfnaqkkaqsstd(seq id no:1)。在一些实施方案中,abe8相对于参照序列包含如本文所描述之其它变化。
99、“腺苷碱基编辑器8(abe8)多核苷酸”是指编码abe8多肽的多核苷酸。
100、“腺苷脱氨酶多核苷酸”是指编码腺苷脱氨酶多肽的多核苷酸。在特定实施方案中,腺苷脱氨酶多核苷酸编码腺苷脱氨酶变体,该变体包含v82g、y147t/d、q154s,以及l36h、i76y、f149y、n157k和d167n中的一者或多者。在一些实施方案中,腺苷脱氨酶多核苷酸编码包含以下改变组合之一的腺苷脱氨酶变体:v82g+y147t+q154s;i76y+v82g+y147t+q154s;l36h+v82g+y147t+q154s+n157k;v82g+y147d+f149y+q154s+d167n;l36h+v82g+y147d+f149y+q154s+n157k+d167n;l36h+i76y+v82g+y147t+q154s+n157k;i76y+v82g+y147d+f149y+q154s+d167n;或l36h+i76y+v82g+y147d+f149y+q154s+n157k+d167n。
101、在一些实施方案中,脱氨酶或脱氨酶结构域是来自生物体,例如来自人、黑猩猩、大猩猩、猴、牛、狗、大鼠或小鼠的天然存在的脱氨酶的变体。在一些实施方案中,脱氨酶或脱氨酶结构域在自然界中不存在。例如,在一些实施方案中,脱氨酶或脱氨酶结构域与天然存在的脱氨酶具有至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少91%、至少92%、至少93%、至少94%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.1%、至少99.2%、至少99.3%、至少99.4%、至少99.5%、至少99.6%、至少99.7%、至少99.8%或至少99.9%同一性。在一些实施方案中,腺苷脱氨酶来自细菌,例如大肠杆菌(e.coli)、金黄色葡萄球菌、枯草芽孢杆菌(b.subtilis)、伤寒沙门氏菌(s.typhi)、腐败希瓦氏菌(s.putrefaciens)、流感嗜血杆菌(h.influenzae)、新月柄杆菌(c.crescentus)或硫还原地杆菌(g.sulfurreducens)。
102、在一些实施方案中,腺苷脱氨酶是tada脱氨酶。在一些实施方案中,tada脱氨酶是大肠杆菌tada(ectada)脱氨酶或其片段。在一些实施方案中,ectada脱氨酶是截短的ectada。例如,相对于全长ectada,截短的ectada可能缺少一个或多个n末端氨基酸。在一些实施方案中,相对于全长ectada,截短的ectada可能缺少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、6、17、18、19或20个n末端氨基酸残基。在一些实施方案中,相对于全长ectada,截短的ectada可能缺少1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、6、17、18、19或20个c末端氨基酸残基。在一些实施方案中,ectada脱氨酶不包含n末端甲硫氨酸。在一些实施方案中,tada脱氨酶是n末端截短的tada。在特定实施方案中,tada是以引用的方式整体并入本文中的pct/us2017/045381中所描述的tada中的任一者。
103、在一些实施方案中,tada脱氨酶是tada变体。在一些实施方案中,tada变体是tada*7.10,它包含v82g、y147t/d、q154s以及以下中的一者或多者:l36h、i76y、f149y、n157k和d167n。在一些实施方案中,tada变体是tada*7.10,它包含选自以下的改变组合:v82g+y147t+q154s;i76y+v82g+y147t+q154s;l36h+v82g+y147t+q154s+n157k;v82g+y147d+f149y+q154s+d167n;l36h+v82g+y147d+f149y+q154s+n157k+d167n;l36h+i76y+v82g+y147t+q154s+n157k;i76y+v82g+y147d+f149y+q154s+d167n;或l36h+i76y+v82g+y147d+f149y+q154s+n157k+d167n。在一些实施方案中,tada变体是msp605、msp680、msp823、msp824、msp825、msp827、msp828或msp829。
104、“施用”在本文中指的是向患者或受试者提供一种或多种本文所述的组合物。
105、“试剂”是指任何小分子化合物、抗体、核酸分子或多肽,或其片段。
106、“改变”是指通过标准本领域已知的方法,例如本文所述的方法所检测到的基因或多肽的结构、表达水平或活性的变化(例如增加或减少)。如本文所使用,改变包括多核苷酸或多肽序列的变化或表达水平的变化,例如10%变化、25%变化、40%变化、50%变化或更高百分比变化。
107、“改善”是指减轻、抑制、减弱、减少、停滞或稳定疾病的发展或进展。
108、“类似物”是指不相同但具有类似功能或结构特征的分子。例如,多核苷酸或多肽类似物保留了相应天然存在的多核苷酸或多肽的生物活性,同时具有某些修饰,所述修饰使该类似物的功能相对于天然存在的多核苷酸或多肽的功能有所增强。这些修饰可以增加类似物对dna的亲和力、效率、特异性、蛋白酶或核酸酶抗性、膜渗透性和/或半衰期,而不改变例如配体结合。类似物可包括非天然核苷酸或氨基酸。
109、“碱基编辑器(be)”或“核碱基编辑器多肽(nbe)”是指结合多核苷酸并具有核碱基修饰活性的试剂。在各个实施方案中,碱基编辑器包含核碱基修饰多肽(例如脱氨酶)和多核苷酸可编程核苷酸结合结构域(例如cas9或cpf1)以及指导多核苷酸(例如指导rna(grna))。碱基编辑器的代表性核酸和蛋白质序列在序列表中以seq id no:2-11和378提供。
110、“碱基编辑活性”是指以化学方式改变多核苷酸内的碱基的作用。在一个实施方案中,第一个碱基被转化为第二个碱基。在一个实施方案中,碱基编辑活性是腺苷或腺嘌呤脱氨酶活性,例如将a·t变为g·c。
111、在一些实施方案中,碱基编辑活性是通过编辑效率评估的。碱基编辑效率可以通过任何适合的方式测量,例如通过sanger测序或下一代测序测量。在一些实施方案中,碱基编辑效率是通过具有利用碱基编辑器实现的核碱基转化的总测序读段的百分比,例如具有靶a·t碱基对转化为g·c碱基对或靶c·g碱基对转化为t·a碱基对的总测序读段的百分比测量。在一些实施方案中,当在细胞群中进行碱基编辑时,碱基编辑效率是通过具有碱基编辑器实现的核碱基转化的总细胞的百分比测量。
112、术语“碱基编辑器系统”是指用于编辑靶核苷酸序列的核碱基的分子间复合物。在各个实施方案中,碱基编辑器(be)系统包括(1)多核苷酸可编程核苷酸结合结构域、用于使靶核苷酸序列中的核碱基脱氨基的脱氨酶结构域(例如胞苷脱氨酶或腺苷脱氨酶);和(2)与该多核苷酸可编程核苷酸结合结构域结合的一个或多个指导多核苷酸(例如指导rna)。在各个实施方案中,碱基编辑器(be)系统包含选自腺苷脱氨酶或胞苷脱氨酶的核碱基编辑器结构域,以及具有核酸序列特异性结合活性的结构域。在一些实施方案中,碱基编辑器系统包括(1)碱基编辑器(be),它包含多核苷酸可编程dna结合结构域和用于使靶核苷酸序列中的一个或多个核碱基脱氨基的脱氨酶结构域;和(2)与该多核苷酸可编程dna结合结构域结合的一个或多个指导rna。在一些实施方案中,多核苷酸可编程核苷酸结合结构域是多核苷酸可编程dna结合结构域。在一些实施方案中,碱基编辑器是胞苷碱基编辑器(cbe)。在一些实施方案中,碱基编辑器是腺嘌呤或腺苷碱基编辑器(abe)。在一些实施方案中,碱基编辑器是腺嘌呤或腺苷碱基编辑器(abe)或胞苷或胞嘧啶碱基编辑器(cbe)。
113、术语“cas9”或“cas9结构域”是指包含cas9蛋白或其片段(例如包含cas9的有活性、无活性或有部分活性的dna切割结构域和/或cas9的grna结合结构域的蛋白质)的rna引导性核酸酶。cas9核酸酶有时也称为casnl核酸酶或crispr(成簇规则间隔短回文重复序列)相关核酸酶。
114、术语“cas9”或“cas9结构域”是指包含cas9蛋白或其片段(例如包含cas9的有活性、无活性或有部分活性的dna切割结构域和/或ca s9的grna结合结构域的蛋白质)的rna引导性核酸酶。cas9核酸酶有时也称为casnl核酸酶或crispr(成簇规则间隔短回文重复序列)相关核酸酶。crispr是一种适应性免疫系统,可提供针对移动遗传元件(病毒、转座元件和缀合性质粒)的保护。crispr簇含有间隔序列、与先行移动元件互补的序列和靶侵入核酸。crispr簇被转录并加工成crispr rna(crrna)。在ii型crispr系统中,前体cr rna的正确加工需要反式编码的小rna(tracrrna)、内源性核糖核酸酶3(rnc)和cas9蛋白。tracrrna用作核糖核酸酶3辅助的前体crrna加工的指导。随后,cas9/crrna/tracrrna以核酸内切水解方式切割与间隔序列互补的线性或环状dsdna靶。不与crrna互补的靶链首先以核酸内切水解方式切割,然后沿3'-5'以核酸外切水解方式修剪。在自然界中,dna结合和切割典型地需要蛋白质和两种rna。然而,单指导rna(“sgrna”或简称“grna”)可被工程改造成将crr na和tracrrna的各个方面并入单个rna种类中。参见例如jinek m.等人,science 337:816-821(2012),其全部内容特此以引用的方式并入。cas9识别crispr重复序列中的短基序(pam或原间隔序列相邻基序),以帮助区分自身序列与非自身序列。cas9核酸酶序列和结构是本领域技术人员众所周知的(参见例如“complete genome sequen ce of an m1 strain ofstreptococcus pyogenes.”ferretti等人,proc.natl.acad.sci.u.s.a.98:4658-4663(2001);“crispr rna matura tion by trans-encoded small rna and host factorrnase iii.”deltc heva e.等人,nature 471:602-607(2011);及“a programmable dual-rna-guided dna endonuclease in adaptive bacterial immunity.”jine k m.等人,science 337:816-821(2012),各文献的完整内容以引用的方式并入本文中)。cas9直系同源物已在各种物种中得到描述,包括但不限于化脓性链球菌和嗜热链球菌。基于本公开,本领域技术人员将易于了解其它适合的cas9核酸酶和序列,并且此类cas9核酸酶和序列包括来自chylinski,rhun和charpentier,“the tracrrna and cas9 families of type iicrispr-cas immunity systems”(2013)rn a biology 10:5,726-737中所公开的生物体和基因座的cas9序列;该文献的全部内容以引用的方式并入本文中。
115、核酸酶失活型cas9蛋白可互换地称为“dcas9”蛋白(表示核酸酶“死亡”型cas9)或无催化活性型cas9。用于产生具有无活性dna切割结构域的cas9蛋白(或其片段)的方法是已知的(参见例如jinek等人,science.337:816-821(2012);qi等人,“repurposing crispras an rna-guided platform for sequence-specific control of gene expression”(2013)cell.28;152(5):1173-83,各文献的全部内容均以引用的方式并入本文)。例如,已知cas9的dna切割结构域包括两个子结构域,即hnh核酸酶子结构域和ruvc1子结构域。hnh子结构域切割与grna互补的链,而ruvc1子结构域切割非互补链。这些子结构域内的突变可以使cas9的核酸酶活性沉默。例如,突变d10a和h840a使化脓性链球菌cas9的核酸酶活性完全失活(jinek等人,science.337:816-821(2012);qi等人,cell.28;152(5):1173-83(2013))。在一些实施方案中,dcas9对应于或者部分地或全部地包含具有一个或多个使cas9核酸酶活性失活的突变的cas9氨基酸序列。在一些实施方案中,dcas9结构域包含d10a和h840a突变或另一个cas9中的相应突变。在一些实施方案中,cas9核酸酶具有无活性(例如失活的)dna切割结构域,即,cas9是切口酶,称为“ncas9”蛋白(表示“切口酶”cas9)。应当理解,另外的cas9蛋白(例如核酸酶失活型cas9(dcas9)、cas9切口酶(ncas9)或核酸酶活性型cas9),包括其变体和同源物在内,都在本公开的范围内。示例性cas9蛋白包括但不限于本文所提供的那些。在一些实施方案中,cas9蛋白是核酸酶失活型cas9(dcas9)。在一些实施方案中,cas9蛋白是cas9切口酶(ncas9)。在一些实施方案中,cas9蛋白是核酸酶活性型cas9。
116、在一些实施方案中,提供了包含cas9片段的蛋白质。例如,在一些实施方案中,蛋白质包含两个cas9结构域之一:(1)cas9的grna结合结构域;或(2)cas9的dna切割结构域。在一些实施方案中,包含cas9或其片段的蛋白质被称为“cas9变体”。cas9变体与cas9或其片段共有同源性。例如,cas9变体与野生型cas9具有至少约70%的同一性、至少约80%的同一性、至少约90%的同一性、至少约95%的同一性、至少约96%的同一性、至少约97%的同一性、至少约98%的同一性、至少约99%的同一性、至少约99.5%的同一性或至少约99.9%的同一性。在一些实施方案中,cas9变体相较于野生型cas9可以具有1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、21、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、42、43、44、45、46、47、48、49、50个或更多氨基酸变化。在一些实施方案中,cas9变体包含cas9的片段(例如grna结合结构域或dna切割结构域),使得该片段与野生型cas9的相应片段具有至少约70%的同一性、至少约80%的同一性、至少约90%的同一性、至少约95%的同一性、至少约96%的同一性、至少约97%的同一性、至少约98%的同一性、至少约99%的同一性、至少约99.5%的同一性或至少约99.9%的同一性。在一些实施方案中,所述片段是相应野生型cas9氨基酸长度的至少30%、至少35%、至少40%、至少45%、至少50%、至少55%、至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少95%相同、至少96%、至少97%、至少98%、至少99%或至少99.5%。
117、在一些实施方案中,所述片段的长度是至少100个氨基酸。在一些实施方案中,所述片段的长度是至少100、150、200、250、300、350、400、450、500、550、600、650、700、750、800、850、900、950、1000、1050、1100、1150、1200、1250或至少1300个氨基酸。
118、在一些实施方案中,cas9是指来自以下的cas9:溃疡棒状杆菌(corynebacteriumulcerans)(ncbi参考序列:nc_015683.1,nc_017317.1);白喉棒状杆菌(corynebacteriumdiphtheria)(ncbi参考序列:nc_016782.1、nc_016786.1);食蚜蝇螺原体(spiroplasmasyrphidicola)(ncbi参考序列:nc_021284.1);中间普氏菌(prevotella intermedia)(ncbi参考序列:nc_017861.1);台湾螺原体(spiroplasma taiwanense)(ncbi参考序列:nc_021846.1);海豚链球菌(streptococcus iniae)(ncbi参考序列:nc_021314.1);波罗的海贝尔氏菌(belliella baltica)(ncbi参考序列:nc_018010.1);扭曲冷弯曲菌(psychroflexus torquisi)(ncbi参考序列:nc_018721.1);嗜热链球菌(ncbi参考序列:yp_820832.1)、无害李斯特氏菌(listeria innocua)(ncbi参考序列:np_472073.1)、空肠弯曲杆菌(campylobacter jejuni)(ncbi参考序列:yp_002344900.1)或脑膜炎奈瑟氏菌(neisseria meningitidis)(ncbi参考序列:yp_002342100.1)或来自任何其它生物体的cas9。
119、在一些实施方案中,cas9来自脑膜炎奈瑟氏菌(nme)。在一些实施方案中,cas9是nme1、nme2或nme3。在一些实施方案中,nme1、nme2或nme3的pam相互作用结构域分别是n4gat、n4cc和n4caaa(参见例如,edraki,a.等人,a compact,high-accuracy cas9with adinucleotide pam for in vivo genome editing,molecular cell(2018))。
120、在一些实施方案中,本文所提供的cas9融合蛋白包含cas9蛋白的全长氨基酸序列,例如本文所提供的cas9序列之一。然而,在其它实施方案中,本文所提供的融合蛋白不包含全长cas9序列,而仅包含其一个或多个片段。例如,在一些实施方案中,本文所提供的cas9融合蛋白包含cas9片段,其中该片段结合crrna和tracrrna或sgrna,但不包含功能性核酸酶结构域,例如,因为它仅包含核酸酶结构域的截短形式,或根本没有核酸酶结构域。本文提供了适合cas9结构域和cas9片段的示例性氨基酸序列,并且cas9结构域和片段的其它适合序列对于本领域技术人员而言将是显而易见的。
121、在一些实施方案中,cas9是指来自古生菌(例如纳米古生菌(nanoarchaea))的cas9,古生菌构成单细胞原核微生物的域和界。在一些实施方案中,cas9是指casx或casy,它们在例如burstein等人,“new crispr-cas systems from uncultivated microbes”中有描述。cell res.2017feb 21.doi:10.1038/cr.2017.21中有描述,该文献的全部内容特此以引用的方式并入。使用基因组解析的宏基因组学,鉴别出了许多crispr-cas系统,包括在生命树古生菌域首次报导的cas9。这种不同的cas9蛋白是作为活性crispr-cas系统的一部分在研究很少的纳米古生菌中发现的。在细菌中,发现了两个以前未知的系统,即crispr-casx和crispr-casy,它们是迄今所发现的最紧凑的系统之一。在一些实施方案中,cas9是指casx或casx的变体。在一些实施方案中,cas9是指casy或casy的变体。应当理解,其它rna引导性dna结合蛋白也可以用作核酸可编程dna结合蛋白(napdnabp),并且在本公开的范围内。
122、在特定实施方案中,可用于本文所述方法中的napdnabp包括环形序列重组体(circular permutant),这些在本领域中是已知的并且例如在oakes等人,cell 176,254–267,2019中有描述。
123、“共同施用(co-administration)”或“共同施用(co-administered)”是指在治疗过程中施用两种或更多种治疗剂或药物组合物。这种共同施用可以是同时施用或依序施用。在治疗过程中,在施用第一种药物组合物或治疗剂之后的任何时间都可以发生后施用的治疗剂或药物组合物的依序施用。
124、术语“保守氨基酸取代”或“保守突变”是指一个氨基酸被具有共同性质的另一个氨基酸取代。定义单个氨基酸之间的共同性质的一种功能方法是分析同源生物体相应蛋白质之间氨基酸变化的归一化频率(schulz,g.e.和schirmer,r.h.,principles of proteinstructure,springer-verlag,new york(1979))。根据此类分析,可以定义数组氨基酸,其中一组内的氨基酸优先相互交换,并因此,在它们对整体蛋白质结构的影响方面彼此最相似(schulz,g.e.和schirmer,r.h.,同上)。保守突变的非限制性实例包括氨基酸的氨基酸取代,例如赖氨酸取代精氨酸,反之亦然,这样可以维持正电荷;谷氨酸取代天冬氨酸,反之亦然,这样可以维持负电荷;苏氨酸取代丝氨酸,这样可以维持游离的-oh;以及谷氨酰胺取代天冬酰胺,这样可以维持游离的–nh2。
125、本文可互换使用的术语“编码序列”或“蛋白质编码序列”是指编码蛋白质的多核苷酸区段。编码序列也可称为开放阅读框。所述区域或序列以更靠近5'端的起始密码子和更靠近3'端的终止密码子为界。对本文所述碱基编辑器有用的终止密码子包括以下:
126、谷氨酰胺cag→tag终止密码子
127、caa→taa
128、精氨酸cga→tga
129、色氨酸tgg→tga
130、tgg→tag
131、tgg→taa
132、“密码子优化”是指通过用感兴趣宿主细胞的基因中较常使用或最常使用的密码子替代天然序列的至少一个密码子(例如约或超过约1、2、3、4、5、10、15、20、25、50个或更多密码子),同时维持天然氨基酸序列来修饰核酸序列以增强该宿主细胞中的表达的一种方法。各种物种对特定氨基酸的某些密码子表现出特定的偏好。密码子偏好(生物体之间密码子使用的差异)通常与信使rna(mrna)的翻译效率相关,而mrna的翻译效率又被认为取决于所翻译的密码子的性质和特定转运rna(trna)分子的可用性等。细胞中所选trna的优势一般是肽合成中最常使用的密码子的反映。因此,可以基于密码子优化来定制基因以在给定生物体中实现最佳基因表达。密码子使用表很容易获得,例如在www.kazusa.orjp/codon/上可得到的“密码子使用数据库”(2002年7月9日访问),并且这些表可以通过多种方式进行修改。参见nakamura,y.等人,“codon usage tabulated from the international dnasequence databases:status for the year 2000”nucl.acids res.28:292(2000)。用于对特定序列进行密码子优化以在特定宿主细胞中表达的计算机算法也是可用的,例如geneforge(aptagen;jacobus,pa.)也是可用的。在一些实施方案中,编码工程改造的核酸酶的序列中的一个或多个密码子(例如1、2、3、4、5、10、15、20、25、50个或更多个密码子,或是所有密码子)对应于特定氨基酸的最常用密码子。
133、“复合物”是指两个或更多个分子的组合,其相互作用依赖于分子间力。分子间力的非限制性实例包括共价和非共价相互作用。非共价相互作用的非限制性实例包括氢键、离子键、卤素键、疏水键、范德华相互作用(例如偶极-偶极相互作用、偶极诱导的偶极相互作用和伦敦色散力(london dispersion force))和π效应。在一个实施方案中,复合物包含多肽、多核苷酸或一个或多个多肽与一个或多个多核苷酸的组合。在一个实施方案中,复合物包含:一个或多个多肽,该一个或多个多肽缔合形成碱基编辑器(例如包含核酸可编程dna结合蛋白如cas9与脱氨酶的碱基编辑器);以及多核苷酸(例如指导rna)。在一个实施方案中,复合物通过氢键保持在一起。应当理解,碱基编辑器的一种或多种组分(例如脱氨酶或核酸可编程dna结合蛋白)可以共价或非共价缔合。作为一个例子,碱基编辑器可以包括与核酸可编程dna结合蛋白共价连接(例如通过肽键)的脱氨酶。或者,碱基编辑器可以包括非共价缔合的脱氨酶和核酸可编程dna结合蛋白(例如,其中碱基编辑器的一种或多种组分以反式提供并直接地或通过如蛋白质或核酸之类另一个分子缔合)。在一个实施方案中,复合物的一种或多种组分通过氢键保持在一起。
134、“胞嘧啶”或“4-氨基嘧啶-2(1h)-酮”是指分子式为c4h5n3o,具有结构且对应于cas号71-30-7的嘌呤核碱基。
135、“胞苷”是指通过糖苷键连接到核糖的胞嘧啶分子,具有结构并且对应于cas号65-46-3。其分子式为c9h13n3o5。
136、“胞苷碱基编辑器(cbe)”是指包含胞苷脱氨酶的碱基编辑器。
137、“胞苷碱基编辑器(cbe)多核苷酸”是指包含cbe的多核苷酸。
138、“胞苷脱氨酶”或“胞嘧啶脱氨酶”是指能够使胞苷或胞嘧啶脱氨基的多肽或其片段。在一个实施方案中,胞苷脱氨酶将胞嘧啶转化为尿嘧啶或将5-甲基胞嘧啶转化为胸腺嘧啶。术语“胞苷脱氨酶”和“胞嘧啶脱氨酶”在整个申请中可互换使用。海七鳃鳗(petromyzon marinus)胞嘧啶脱氨酶1(pmcda1)(seq id no:13-14)、激活诱导型胞苷脱氨酶(aicda)(seq id no:15-21)和apobec(seq id no:12-61)是示例性胞苷脱氨酶。其它示例性胞苷脱氨酶(cda)序列在序列表中以seq id no:62-66和seq id no:67-189提供。
139、“胞嘧啶”是指分子式为c4h5n3o的嘧啶核碱基。
140、“胞嘧啶脱氨酶活性”是指催化胞嘧啶或胞苷的脱氨基作用。在一个实施方案中,具有胞嘧啶脱氨酶活性的多肽将氨基转化为羰基。在一个实施方案中,胞嘧啶脱氨酶将胞嘧啶转化为尿嘧啶(即,c转化为u)或将5-甲基胞嘧啶转化为胸腺嘧啶(即,5mc转化为t)。在一些实施方案中,本文所提供的胞嘧啶脱氨酶相对于参考胞嘧啶脱氨酶具有增加的胞嘧啶脱氨酶活性(例如至少10倍、20倍、30倍、40倍、50倍、60倍、70倍、80倍、90倍、100倍或更高倍数)。
141、如本文所使用,术语“脱氨酶”或“脱氨酶结构域”是指催化脱氨基反应的蛋白质或其片段。示例性脱氨酶包括胞苷脱氨酶和腺苷脱氨酶。
142、“检测”是指鉴别待检测分析物的存在、不存在或量。
143、“可检测标记”是指这样一种组合物,该组合物当与感兴趣分子连接时,使后者能够通过光谱、光化学、生物化学、免疫化学或化学方式检测。例如,有用的标记包括放射性同位素、磁珠、金属珠、胶体颗粒、荧光染料、电子致密试剂、酶(例如常用于酶联免疫吸附测定(elisa)者)、生物素、洋地黄毒苷(digoxigenin)或半抗原。
144、“疾病”是指损害或干扰细胞、组织或器官的正常功能的任何疾患或病症。疾病的一个实例包括1型糖原贮积症(又称为gsd1或冯吉尔克氏病)。在一些实施方案中,gsd1是1a型(gsd1a)。
145、如本文所使用,术语“有效量”是指足以引发所需生物反应的生物活性剂的量。在一些实施方案中,有效量是使疾病症状相对于未治疗患者改善所需的量。用于实践治疗方法和疾病治疗的活性剂的有效量取决于施用方式、受试者的年龄、体重和一般健康状况而变化。最终,主治医师或兽医将决定适当的量和剂量方案。此类量被称为“有效”量。在一个实施方案中,有效量是足以在细胞(例如体外细胞、体内细胞或离体细胞)中的感兴趣基因(例如g6pc)中引入改变的本文所述碱基编辑器(例如包含可编程dna结合蛋白、核碱基编辑器和grna的融合蛋白)的量。在一个实施方案中,有效量是实现治疗效果(例如减少或控制gsd1a或其症状或疾患)所需的碱基编辑器的量。此类治疗作用无需足以改变受试者、组织或器官的所有细胞中的g6pc,而是仅改变受试者、组织或器官中存在的约1%、5%、10%、25%、50%、75%或更高百分比的细胞中的g6pc。在一个实施方案中,有效量足以改善gsd1a的一种或多种症状。
146、在一些实施方案中,本文所提供的融合蛋白的有效量,例如包含ncas9结构域和脱氨酶结构域(例如腺苷脱氨酶)的核碱基编辑器的有效量是指足以诱导编辑被本文所述核碱基编辑器特异性结合和编辑的靶位点的融合蛋白的量。技术人员应理解,一种试剂,例如融合蛋白、核酸酶、杂合蛋白、蛋白质二聚体、蛋白质(或蛋白质二聚体)和多核苷酸的复合物,或多核苷酸的有效量可以取决于各种因素而变化,例如所需生物反应,例如特定等位基因、基因组或待编辑的靶位点,作为靶的细胞或组织,和/或所使用的试剂。
147、“片段”是指多肽或核酸分子的一部分。这个部分占参照核酸分子或多肽全长的至少约10%、20%、30%、40%、50%、60%、70%、80%或90%。一个片段可以含有10、20、30、40、50、60、70、80、90或100、200、300、400、500、600、700、800、900或1000个核苷酸或氨基酸。
148、“葡萄糖-6-磷酸酶(g6pc)多肽”是指与ncbi登录号aaa16222.1具有至少约95%氨基酸序列同一性的多肽或其片段。野生型g6pc多肽能够催化d-葡萄糖6-磷酸水解为d-葡萄糖和正磷酸盐,而包含有害突变的g6pc多肽缺乏催化活性或具有降低的催化活性。在特定实施方案中,提供了一种编辑g6pc多核苷酸的方法,其中该方法包括与1a型糖原贮积症(gsd1a)相关的单核苷酸多态性(snp)。在一个实施方案中,在与gsd1a相关的snp处a·t到g·c改变将g6pc多肽中的谷氨酰胺(q)变为非谷氨酰胺(x)氨基酸。在另一个实施方案中,与gsd1a相关的snp处的a·t到g·c改变将g6pc多肽中的精氨酸(r)变为非精氨酸(x)。在一个实施方案中,与gsd1a相关的snp使得表达出在第347位具有非谷氨酰胺(x)氨基酸或在第83位具有非精氨酸(x)氨基酸的g6pc多肽。在一个实施方案中,碱基编辑器校正用非谷氨酰胺氨基酸(x)替代第347位处的谷氨酰胺。在另一个实施方案中,碱基编辑器校正用非精氨酸氨基酸(x)替代第83位处的精氨酸。与gsd1a相关的突变是本领域已知的并且例如在chou等人,hum.mutat.29:921-930,2008中有描述,该文献以引用的方式并入本文中。用于检测葡萄糖-6-磷酸酶活性的方法是本领域已知的并且例如在varga等人,int.j.mol.sci.2019,20,5039中有描述,该文献以引用的方式并入本文。
149、在特定实施方案中,g6pc相对于以下参照序列包含一个或多个改变。在特定实施方案中,与gsd1a相关的g6pc包含一个或多个选自q347x和r83c的突变。来自智人(homosapiens)的示例性g6pc氨基酸序列提供如下:
150、
151、“葡萄糖-6-磷酸酶(g6pc)多核苷酸”是指编码g6pc多肽的核酸分子,以及与其表达相关的内含子、外显子和调控序列,或其片段。在实施方案中,g6pc多核苷酸是与g6pc表达相关和/或g6pc表达所需的基因组序列、mrna或基因。下面提供了来自智人的示例性g6pc核苷酸序列(genbank:u01120.1):
152、
153、
154、
155、
156、
157、
158、
159、“指导多核苷酸”是指对靶序列具有特异性并且可以与多核苷酸可编程核苷酸结合结构域蛋白(例如cas9或cpf1)形成复合物的多核苷酸或多核苷酸复合物。在一个实施方案中,指导多核苷酸是指导rna(grna)。grna可以呈两个或更多个rna的复合物形式存在,或呈单个rna分子形式存在。
160、“异二聚体”是指包含两个结构域的融合蛋白,该两个结构域是例如野生型tada结构域和tada结构域的变体或两个变体tada结构域。
161、“异源的”或“外源的”是指这样一种多核苷酸或多肽,该多核苷酸或多肽1)已通过实验方式并入在自然界中通常未发现该多核苷酸或多肽的多核苷酸或多肽序列中;或2)已通过实验方式放入通常不包含该多核苷酸或多肽的细胞中。在一些实施方案中,“异源”是指多核苷酸或多肽已通过实验方式放入非天然环境中。在一些实施方案中,异源多核苷酸或多肽来源于第一物种或宿主生物体,并且被并入来源于第二物种或宿主生物体的多核苷酸或多肽中。在一些实施方案中,第一物种或宿主生物体不同于第二物种或宿主生物体。在一些实施方案中,异源多核苷酸是dna。在一些实施方案中,异源多核苷酸是rna。
162、“杂交”是指互补核碱基之间的氢键合,该氢键合可以是watson-crick、hoogsteen或反向hoogsteen氢键合。例如,腺嘌呤和胸腺嘧啶是通过形成氢键来配对的互补核碱基。
163、“增加”是指至少10%、25%、50%、75%或100%的正向改变。
164、术语“碱基修复抑制剂”或“ibr”是指能够抑制核酸修复酶如碱基切除修复(ber)酶的活性的蛋白质。在一些实施方案中,ibr是肌苷碱基切除修复的抑制剂。示例性碱基修复抑制剂包括以下各物的抑制剂:ape1、endo iii、endo iv、endo v、endo viii、fpg、hoggl、hneill、t7 endol、t4pdg、udg、hsmugl和haag。在一些实施方案中,ibr是endo v或haag的抑制剂。在一些实施方案中,ibr是无催化活性的endov或无催化活性的haag。在一些实施方案中,碱基修复抑制剂是endo v或haag的抑制剂。在一些实施方案中,碱基修复抑制剂是无催化活性的endo v或无催化活性的haag。
165、在一些实施方案中,碱基修复抑制剂是尿嘧啶糖基化酶抑制剂(ugi)。ugi是指能够抑制尿嘧啶-dna糖基化酶碱基切除修复酶的蛋白质。在一些实施方案中,ugi结构域包含野生型ugi或野生型ugi的片段。在一些实施方案中,本文所提供的ugi蛋白质包括ugi的片段和与ugi或ugi的片段同源的蛋白质。在一些实施方案中,碱基修复抑制剂是肌苷碱基切除修复抑制剂。在一些实施方案中,碱基修复抑制剂是“无催化活性的肌苷特异性核酸酶”或“失活型肌苷特异性核酸酶”。不希望受任何特定理论的束缚,无催化活性的肌苷糖基化酶(例如烷基腺嘌呤糖基化酶(aag))可以结合肌苷,但不能产生脱碱基位点或去除肌苷,由此在空间上阻止新形成的肌苷部分进行dna损伤/修复机制。在一些实施方案中,无催化活性的肌苷特异性核酸酶能够结合核酸中的肌苷但不切割核酸。非限制性示例性无催化活性的肌苷特异性核酸酶包括无催化活性的烷基腺苷糖基化酶(aag核酸酶),例如来自人的aag核酸酶,以及无催化活性的核酸内切酶v(endov核酸酶),例如来自大肠杆菌的endov核酸酶。在一些实施方案中,无催化活性的aag核酸酶包含e125q突变或另一种aag核酸酶中的相应突变。
166、“内含肽(intein)”是能够自我切除并在称为蛋白质剪接的过程中通过肽键接合剩余片段(外显肽(extein))的蛋白质片段。
167、术语“分离的”、“纯化的”或“生物纯的”是指材料在不同程度上不含其天然状态下通常伴随的组分。“分离”表示与原始来源或环境的分开的程度。“纯化”表示高于分离的分开程度。“纯化的”或“生物纯的”蛋白质充分不含其它物质,因此任何杂质都不会对蛋白质的生物性质产生实质性影响或导致其它不利后果。也就是说,如果本文所描述的核酸或肽在通过重组dna技术产生时大体上不含细胞材料、病毒材料或培养基,或者在化学合成时大体上不含化学前体或其它化学品,则它是纯化的。纯度和均质性典型地使用分析化学技术来确定,例如聚丙烯酰胺凝胶电泳或高效液相色谱法。术语“纯化的”可以表示核酸或蛋白质在电泳凝胶中产生基本上一个条带。对于可以进行修饰,例如进行磷酸化或糖基化的蛋白质,不同的修饰可能会产生不同的分离蛋白质,这些蛋白质可以分开纯化。
168、“分离的多核苷酸”是指这样一种核酸(例如dna),该核酸不含在作为所述核酸分子来源的生物体的天然基因组中侧接该基因的基因。因此,这一术语包括例如重组dna,该重组dna被并入载体中;并入自主复制的质粒或病毒中;或并入原核生物或真核生物的基因组dna中;或者作为独立于其它序列的独立分子(例如通过pcr或限制性核酸内切酶消化产生的cdna或基因组或cdna片段)存在。此外,这一术语还包括从dna分子转录的rna分子,以及作为编码额外多肽序列的杂交基因的一部分的重组dna。
169、“分离的多肽”是指已与其天然伴随的组分分离的所描述的多肽。典型地,当多肽不含按重量计至少60%的与其天然缔合的蛋白质和天然存在的有机分子时,该多肽是“分离的”。优选地,制剂包含按重量计至少75%,更优选至少90%,并且最优选至少99%的本文所描述的多肽。本文所描述的分离的多肽可以例如通过从天然来源提取;通过表达编码此类多肽的重组核酸;或通过化学合成蛋白质来获得。纯度可以通过任何适当的方法,例如柱色谱法、聚丙烯酰胺凝胶电泳或通过hplc分析测量。
170、如本文所使用,术语“接头”是指连接两个部分的分子。在一个实施方案中,术语“接头”是指共价接头(例如共价键)或非共价接头。
171、“标记物”是指表达水平或活性的变化与疾病或病症如gsd1a和/或其症状相关的任何蛋白质或多核苷酸。
172、如本文所使用,术语“突变”指序列,例如核酸或氨基酸序列内的残基被另一残基取代,或序列内一个或多个残基的缺失或插入。突变在本文中典型地通过鉴别原始残基,随后该残基在序列内的位置以及新取代的残基的身份来描述。用于进行本文所提供的氨基酸取代(突变)的各种方法是本领域中众所周知的,并且由例如green和sambrook,molecularcloning:a laboratory manual(第4版,cold spring harbor laboratory press,coldspring harbor,n.y.(2012))提供。
173、术语“非保守突变”涉及不同组之间的氨基酸取代,例如赖氨酸取代色氨酸,或苯丙氨酸取代丝氨酸等。在这种情况下,非保守氨基酸取代优选不会干扰或抑制功能变体的生物活性。非保守氨基酸取代可以增强功能变体的生物活性,使得功能变体的生物活性与野生型蛋白相比增加。
174、术语“核定位序列”、“核定位信号”或“nls”是指促进蛋白质输入至细胞核中的氨基酸序列。核定位序列在本领域中是已知的并且描述于例如plank等人的国际pct申请pct/ep2000/011690中,该案于2000年11月23日提出申请,并于2001年5月31日以wo/2001/038547公布,其中示例性核定位序列的公开内容以引用的方式并入本文。在其它实施方案中,nls是优化的nls,例如koblan等人,nature biotech.2018doi:10.1038/nbt.4172所描述。在一些实施方案中,nl s包含氨基酸序列在一些实施方案中,nls包含氨基酸序列krtadgsefespkkkrkv(seq id no:190)、krpaatkkagqakkkk(seq id no:191)、kktelqttnaenktkkl(seq id no:192)、krgindrnfwrgengrktr(seq id no:193)、rksgkiaaivv krprk(seq id no:194)、pkkkrkv(seq id no:195)或mdsllmnrrkflyqfknvrwakgrretylc(seq id no:196)。
175、术语“核碱基”、“含氮碱基”或“碱基”在本文中可互换使用,意思指形成核苷的含氮生物化合物,核苷又是核苷酸的组分。核碱基形成碱基对并依序堆叠的能力直接产生长链螺旋结构,例如核糖核酸(rna)和脱氧核糖核酸(dna)。五种核碱基,即腺嘌呤(a)、胞嘧啶(c)、鸟嘌呤(g)、胸腺嘧啶(t)和尿嘧啶(u),被称为主要碱基或经典碱基。腺嘌呤和鸟嘌呤来源于嘌呤,而胞嘧啶、尿嘧啶和胸腺嘧啶来源于嘧啶。dna和rna还可以含有其它修饰过的(非主要)碱基。非限制性示例性的修饰过的核碱基可包括次黄嘌呤、黄嘌呤、7-甲基鸟嘌呤、5,6-二氢尿嘧啶、5-甲基胞嘧啶(m5c)和5-羟甲基胞嘧啶。次黄嘌呤和黄嘌呤可以通过诱变剂的存在产生,二者都是通过脱氨作用(用羰基置换胺基)产生的。次黄嘌呤可以从腺嘌呤修饰得到。黄嘌呤可以从鸟嘌呤修饰得到。尿嘧啶可由胞嘧啶脱氨基产生。“核苷”由一个核碱基和一个五碳糖(核糖或脱氧核糖)组成。核苷的实例包括腺苷、鸟苷、尿苷、胞苷、5-甲基尿苷(m5u)、脱氧腺苷、脱氧鸟苷、胸苷、脱氧尿苷和脱氧胞苷。具有修饰过的核碱基的核苷的实例包括肌苷(i)、黄苷(x)、7-甲基鸟苷(m7g)、二氢尿苷(d)、5-甲基胞苷(m5c)和假尿苷(ψ)。“核苷酸”由一个核碱基、一个五碳糖(核糖或脱氧核糖)和至少一个磷酸酯基组成。
176、如本文所使用,术语“核酸”和“核酸分子”是指包含核碱基和酸性部分的化合物,例如核苷、核苷酸或核苷酸聚合物。典型地,聚合核酸,例如包含三个或更多个核苷酸的核酸分子是线性分子,其中相邻的核苷酸通过磷酸二酯键联彼此连接。在一些实施方案中,“核酸”是指单独的核酸残基(例如核苷酸和/或核苷)。在一些实施方案中,“核酸”是指包含三个或更多个单独核苷酸残基的寡核苷酸链。如本文所使用,术语“寡核苷酸”和“多核苷酸”可互换使用以指代核苷酸聚合物(例如至少三个核苷酸的链段)。在一些实施方案中,“核酸”涵盖rna以及单链和/或双链dna。核酸可以是天然存在的,例如在基因组、转录物、mrna、trna、rrna、sirna、snrna、质粒、粘粒、染色体、染色单体或其它天然存在的核酸分子的情形中。另一方面,核酸分子可以是非天然存在的分子,例如重组dna或rna、人工染色体、工程改造的基因组或其片段,或合成dna、rna、dna/rna杂交体,或包括非天然存在的核苷酸或核苷。此外,术语“核酸”、“dna”、“rna”和/或类似术语包括核酸类似物,例如具有非磷酸二酯主链的类似物。核酸可以从天然来源中纯化;使用重组表达系统产生并任选地纯化;化学合成等。在适当的情况下,例如,在化学合成分子的情况下,核酸可包含核苷类似物,例如具有化学修饰的碱基或糖以及主链修饰的类似物。除非另有说明,否则核酸序列以5'至3'方向呈现。在一些实施方案中,核酸是或包含天然核苷(例如腺苷、胸苷、鸟苷、胞苷、尿苷、脱氧腺苷、脱氧胸苷、脱氧鸟苷和脱氧胞苷);核苷类似物(例如2-氨基腺苷、2-硫代胸苷、肌苷、吡咯并嘧啶、3-甲基腺苷、5-甲基胞苷、2-氨基腺苷、c5-溴尿苷、c5-氟尿苷、c5-碘尿苷、c5-丙炔基-尿苷,c5-丙炔基-胞苷、c5-甲基胞苷、2-氨基腺苷、7-脱氮腺苷、7-脱氮鸟苷、8-氧代腺苷、8-氧代鸟苷、o(6)-甲基鸟嘌呤和2-硫代胞苷);化学修饰的碱基;以生物方式修饰的碱基(例如甲基化碱基);插入碱基;修饰过的糖(例如2'-氟核糖、核糖、2'-脱氧核糖、阿拉伯糖和己糖);和/或修饰过的磷酸酯基团(例如硫代磷酸酯和5'-n-氨基磷酸酯键联)。在一些实施方案中,本文所述的多核苷酸包含以下修饰中的一者或多者:2'-o-甲基(2'-ome)、硫代磷酸酯(ps)、2'-o-甲基硫代pace(msp)、2'-o-甲基(2'-ome)、2'-o-甲基-pace(mp)、2'-氟rna(2'-f-rna)和限制性乙基(constrained ethyl)(s-cet)。
177、术语“核酸可编程dna结合蛋白”或“napdnabp”可与“多核苷酸可编程核苷酸结合结构域”互换使用,意思指与核酸(例如dna或rna)缔合的蛋白质,例如将napdnabp引导到特定核酸序列的指导核酸或指导多核苷酸(例如grna)。在一些实施方案中,多核苷酸可编程核苷酸结合结构域是多核苷酸可编程dna结合结构域。在一些实施方案中,多核苷酸可编程核苷酸结合结构域是多核苷酸可编程rna结合结构域。在一些实施方案中,多核苷酸可编程核苷酸结合结构域是cas9蛋白。cas9蛋白可以与指导rna缔合,该指导rna将cas9蛋白引导至与该指导rna互补的特定dna序列。在一些实施方案中,napdnabp是cas9结构域,例如核酸酶活性型cas9、cas9切口酶(ncas9)或无核酸酶活性型cas9(dcas9)。核酸可编程dna结合蛋白的非限制性实例包括cas9(例如dcas9和ncas9)、cas12a/cpfl、cas12b/c2cl、cas12c/c2c3、cas12d/casy、cas12e/casx、cas12g、cas12h、cas12i和cas12j/casφ(cas12j/casphi)。cas酶的非限制性实例包括cas1、cas1b、cas2、cas3、cas4、cas5、cas5d、cas5t、cas5h、cas5a、cas6、cas7、cas8、cas8a、cas8b、cas8c、cas9(又称为csn1或csx12)、cas10、cas10d、cas12a/cpfl、cas12b/c2cl(例如seq id no:232)、cas12c/c2c3、cas12d/casy、cas12e/casx、cas12g、cas12h、cas12i、cas12j/casφ、cpf1、csy1、csy2、csy3、csy4、cse1、cse2、cse3、cse4、cse5e、csc1、csc2、csa5、csn1、csn2、csm1、csm2、csm3、csm4、csm5、csm6、cmr1、cmr3、cmr4、cmr5、cmr6、csb1、csb2、csb3、csx17、csx14、csx10、csx16、csax、csx3、csx1、csx1s、csx11、csf1、csf2、cso、csf4、csd1、csd2、cst1、cst2、csh1、csh2、csa1、csa2、csa3、csa4、csa5、ii型cas效应蛋白、v型cas效应蛋白、vi型cas效应蛋白、carf、ding、它们的同源物,或它们的修饰或工程改造形式。其它核酸可编程dna结合蛋白也在本公开的范围内,但它们可能没有在本公开中具体列出。参见例如makarova等人“classification andnomenclature of crispr-cas systems:where from here?”crispr j.2018年10月;1:325-336.doi:10.1089/crispr.2018.0033;yan等人,“functionally diverse type vcrispr-cas systems”science.2019年1月4日;363(6422):88-91.doi:10.1126/science.aav7271,各文献的完整内容特此以引用的方式并入。示例性核酸可编程dna结合蛋白和编码核酸可编程dna结合蛋白的核酸序列在序列表中以seq id no:197-230提供。
178、如本文所使用,术语“核碱基编辑结构域”或“核碱基编辑蛋白”是指可催化rna或dna中的核碱基修饰,例如催化胞嘧啶(或胞苷)变为尿嘧啶(或尿苷)或胸腺嘧啶(或胸苷)和腺嘌呤(或腺苷)变为次黄嘌呤(或肌苷)的脱氨基作用以及非模板核苷酸添加和插入的蛋白质或酶。在一些实施方案中,核碱基编辑结构域是脱氨酶结构域(例如腺嘌呤脱氨酶或腺苷脱氨酶;或胞苷脱氨酶或胞嘧啶脱氨酶)。
179、如本文所使用,如在“获得试剂”中的“获得”包括合成、购买或以其它方式获取该试剂。
180、如本文所使用,“患者”或“受试者”是指被诊断患有、有风险患有或发展或者怀疑患有或发展疾病或病症的哺乳动物受试者或个体。在一些实施方案中,术语“患者”是指发展疾病或病症的可能性高于平均水平的哺乳动物受试者。示例性患者可以是能够受益于本文所公开的疗法的人类、非人类灵长类动物、猫、狗、猪、牛、猫、马、骆驼、大羊驼、山羊、绵羊、啮齿动物(例如小鼠、兔、大鼠或豚鼠)和其它哺乳动物。示例性人类患者可以是男性和/或女性。
181、“有需要的患者”或“有需要的受试者”在本文中指被诊断患有、有风险或患有、预定患有或怀疑患有疾病或病症的患者,该疾病或病症例如但不限于1型糖原贮积症(gsd1或冯吉尔克氏病)。
182、术语“致病性突变”、“致病性变异”、“引起疾病的突变”、“引起疾病的变异”、“有害突变”或“易感突变”是指增加个体患某种疾病或病症的易感性或倾向的基因改变或突变。在一些实施方案中,致病性突变包含至少一个野生型氨基酸被基因编码的蛋白质中的至少一个致病性氨基酸取代。
183、术语“药学上可接受的载体”是指参与将化合物从身体的一个部位(例如递送部位)载运或运输到另一部位(例如身体的器官、组织或部分)的药学上可接受的材料、组合物或媒剂,例如液体或固体填充剂、稀释剂、赋形剂、制造助剂(例如润滑剂、滑石硬脂酸镁、硬脂酸钙或硬脂酸锌,或硬脂酸)或溶剂囊封材料。药学上可接受的载体在与配制物中的其它成分相容并且对受试者的组织无害(例如生理上相容、无菌、生理ph等)的意义上是“可接受的”。“赋形剂”、“载体”、“药学上可接受的载体”、“媒剂”等术语在本文中可互换使用。
184、术语“药物组合物”是指被配制用于药物用途的组合物。在一些实施方案中,药物组合物还包含药学上可接受的载体。在一些实施方案中,药物组合物包含额外的试剂(例如用于特异性递送、增加半衰期或其它治疗性化合物)。
185、术语“蛋白质”、“肽”、“多肽”和其语法等效物在本文中可互换地使用,并且指通过肽(酰胺)键连接在一起的氨基酸残基的聚合物。蛋白质、肽或多肽可以是天然存在的、重组的或合成的,或其任何组合。
186、如本文所使用,术语“融合蛋白”是指包含来自至少两种不同蛋白质的蛋白质结构域的杂交多肽。
187、“启动子”意谓导引核酸转录的一系列核酸控制序列。启动子包括靠近转录起始位点的必要核酸序列。启动子还任选地包括远端增强子或阻遏子序列元件。“组成型启动子”是有持续活性并且不受外部信号或分子调控的启动子。相比之下,“诱导型启动子”的活性受外部信号或分子(例如转录因子)调控。举个例子,启动子可以是cmv启动子。
188、本文在蛋白质或核酸的情形中使用的术语“重组”是指不存在于自然界中,而是人类工程改造的产物的蛋白质或核酸。例如,在一些实施方案中,重组蛋白或核酸分子包含的氨基酸或核苷酸序列相较于任何天然存在的序列包含至少一个、至少两个、至少三个、至少四个、至少五个、至少六个或至少七个突变。
189、“减少”是指至少10%、25%、50%、75%或100%的负面改变。
190、“参照”是指标准或对照条件。在一个实施方案中,参照是野生型细胞或健康细胞。例如,在一些实施方案中,参照是未患gsd1a的受试者的细胞。在一些实施方案中,参照是具有正常或野生型葡萄糖-6-磷酸酶活性的细胞。在其它实施方案中,参照是未处理细胞,该细胞未经历测试条件,或经历安慰剂或生理盐水、培养基、缓冲液和/或不含感兴趣多核苷酸的对照载体,但不限于此。
191、“参照序列”是用作序列比较基础的确定的序列。参照序列可以是指定序列的子集或全部;例如,全长cdna或基因序列的一个区段,或完整cdna或基因序列。对于多肽,参照多肽序列的长度一般是至少约16个氨基酸、至少约20个氨基酸、至少约25个氨基酸、约35个氨基酸、约50个氨基酸或约100个氨基酸。对于核酸,参照核酸序列的长度一般是至少约50个核苷酸、至少约60个核苷酸、至少约75个核苷酸、约100个核苷酸或约300个核苷酸或其附近或其间的任何整数。在一些实施方案中,参照序列是感兴趣蛋白质的野生型序列。在其它实施方案中,参照序列是编码野生型蛋白质的多核苷酸序列。
192、术语“rna可编程核酸酶”和“rna引导性核酸酶”与一个或多个并非切割靶的rna一起使用(例如结合或缔合)。在一些实施方案中,rna可编程核酸酶当与rna形成复合物时,可称为核酸酶:rna复合物。典型地,结合的rna称为指导rna(grna)。在一些实施方案中,rna可编程核酸酶是(crispr相关系统)cas9核酸内切酶,例如来自化脓性链球菌的cas9(csnl)。
193、术语“单核苷酸多态性(snp)”是在基因组中特定位置处发生的单个核苷酸的变异,其中每个变异在群体内以某种可感知的程度存在(例如>1%)。
194、“特异性结合”是指识别并结合本文所描述的多肽和/或核酸分子,但大体上不识别和结合样品,例如生物样品中的其它分子的核酸分子、多肽或其复合物(例如核酸可编程dna结合蛋白、指导核酸)、化合物或分子。
195、“大体上相同”是指多肽或核酸分子与参照氨基酸序列表现出至少50%的同一性。在一个实施方案中,参照序列是野生型氨基酸或核酸序列。在另一个实施方案中,参照序列是本文所述氨基酸或核酸序列中的任一者。在一个实施方案中,此类序列在氨基酸水平或核酸水平上与用于比较的序列具有至少60%、80%、85%、90%、95%或甚至99%的同一性。
196、序列同一性典型地使用序列分析软件(例如威斯康星大学生物技术中心(university of wisconsin biotechnology center),1710university avenue,madison,wis.53705的genetics computer group的序列分析软件包,blast、bestfit、gap或pileup/prettybox程序)测量。此类软件通过将同源性程度指定给各种取代、缺失和/或其它修饰来匹配相同或相似的序列。保守取代典型地包括以下各组内的取代:甘氨酸、丙氨酸;缬氨酸、异亮氨酸、亮氨酸;天冬氨酸、谷氨酸、天冬酰胺、谷氨酰胺;丝氨酸、苏氨酸;赖氨酸、精氨酸;以及苯丙氨酸、酪氨酸。在确定同一性程度的示例性方法中,可以使用blast程序,其中在e-3与e-100之间的概率分数指示密切相关的序列。
197、例如,使用cobalt时利用以下参数:
198、a)比对参数:空位罚分-11,-1,以及末端空位罚分(end-gap penalty)-5,-1;
199、b)cdd参数:使用rps blast;blast e值0.003;查找保守列并重新计算,以及
200、c)查询聚类参数:使用查询集群;字号4;最大集群距离0.8;alphabet regular。
201、例如,使用emboss needle时利用以下参数:
202、a)矩阵:blosum62;
203、b)空位开放(gap open):10;
204、c)空位延伸(gap extend):0.5;
205、d)输出格式:成对;
206、e)末端空位罚分(end gap penalty):错误;
207、f)末端空位开放(end gap open):10;以及
208、g)末端空位延伸(end gap extend):0.5。
209、可用于本发明方法中的核酸分子包括编码本发明多肽或其片段的任何核酸分子。此类核酸分子不需要与内源核酸序列100%相同,但典型地会表现出相当大的同一性。与内源序列具有“相当大的同一性”的多核苷酸典型地能够与双链核酸分子的至少一条链杂交。可用于本发明方法中的核酸分子包括编码本发明多肽或其片段的任何核酸分子。此类核酸分子不需要与内源核酸序列100%相同,但典型地会表现出相当大的同一性。与内源序列具有“相当大的同一性”的多核苷酸典型地能够与双链核酸分子的至少一条链杂交。“杂交”是指在各种严格度条件下配对以在互补多核苷酸序列(例如本文所描述的基因)或其部分之间形成双链分子。(参见例如wahl,g.m.和s.l.berger(1987)methods enzymol.152:399;kimmel,a.r.(1987)methods enzymol.152:507)。
210、例如,严格的盐浓度通常小于约750mm nacl和75mm柠檬酸三钠,优选小于约500mmnacl和50mm柠檬酸三钠,并且更优选小于约250mm nacl和25mm柠檬酸三钠。低严格度杂交可在不存在有机溶剂,例如甲酰胺的情况下获得,而高严格度杂交可在至少约35%甲酰胺,并且更优选至少约50%甲酰胺存在下获得。严格的温度条件通常包括至少约30℃,更优选至少约37℃并且最优选至少约42℃的温度。变化的其它参数,如杂交时间、清洁剂例如十二烷基硫酸钠(sds)的浓度以及包含或不包含载体dna,是本领域技术人员众所周知的。通过根据需要组合这些不同的条件来实现各种严格度水平。在一个优选实施方案中,杂交将在30℃下于750mm nacl、75mm柠檬酸三钠和1% sds中发生。在一个更优选的实施方案中,杂交将在37℃下于500mm nacl、50mm柠檬酸三钠、1% sds、35%甲酰胺和100μg/ml变性鲑鱼精dna(ssdna)中发生。在一个最优选的实施方案中,杂交将在42℃下于250mm nacl、25mm柠檬酸三钠、1%sds、50%甲酰胺和200μg/ml ssdna中发生。这些条件的有用变化对本领域技术人员来说将是显而易见的。
211、对于大多数应用,杂交后的洗涤步骤的严格度也会有所不同。洗涤严格度条件可以通过盐浓度和温度来定义。如上所述,可通过降低盐浓度或通过增加温度来增加洗涤严格度。例如,洗涤步骤中的严格盐浓度优选小于约30mm nacl和3mm柠檬酸三钠,并且最优选小于约15mm nacl和1.5mm柠檬酸三钠。洗涤步骤中的严格温度条件通常包括至少约25℃,更优选至少约42℃,甚至更优选至少约68℃的温度。在一个实施方案中,洗涤步骤将在25℃下于30mm nacl、3mm柠檬酸三钠和0.1% sds中发生。在另一个实施方案中,洗涤步骤将在42℃下于15mm nacl、1.5mm柠檬酸三钠和0.1% sds中发生。在一个更优选的实施方案中,杂交将在68℃下于15mm nacl、1.5mm柠檬酸三钠和0.1% sds中发生。这些条件的其它变化对本领域技术人员来说将是显而易见的。杂交技术是本领域技术人员众所周知的,并在例如以下中有描述:benton和davis(science 196:180,1977);grunstein和hogness(proc.natl.acad.sci.,usa 72:3961,1975);ausubel等人(current protocols inmolecular biology,wiley interscience,new york,2001);berger和kimmel(guide至molecular cloning techniques,1987,academic press,new york);以及sambrook等人,molecular cloning:a laboratory manual,cold spring harbor laboratory press,newyork。
212、“分裂”是指分成两个或更多个片段。
213、“分裂的cas9蛋白”或“分裂的cas9”是指以两个独立核苷酸序列编码的n末端片段和c末端片段形式提供的cas9蛋白。对应于cas9蛋白的n末端部分和c末端部分的多肽可以被剪接以形成“重构的”cas9蛋白。
214、“受试者”是指哺乳动物,包括但不限于人类或非人类哺乳动物,例如牛科动物、马科动物、犬科动物、羊科动物或猫科动物。受试者包括牲畜、为产生劳动力并提供商品(例如食物)而饲养的家养动物,包括但不限于牛、山羊、鸡、马、猪、兔和绵羊。
215、“大体上相同”是指一个多肽或核酸分子与参照氨基酸序列(例如本文所述氨基酸序列中的任一者)或核酸序列(例如本文所述核酸序列中的任一者)表现出至少50%的同一性。在一个实施方案中,此类序列在氨基酸水平或核酸水平上与用于比较的序列具有至少60%、80%或85%、90%、95%或甚至99%的同一性。
216、序列同一性典型地使用序列分析软件(例如威斯康星大学生物技术中心,1710university avenue,madison,wis.53705的genetics computer group的序列分析软件包,blast、bestfit、cobalt、emboss needle、gap或pileup/prettybox程序)测量。此类软件通过将同源性程度指定给各种取代、缺失和/或其它修饰来匹配相同或相似的序列。保守取代典型地包括以下各组内的取代:甘氨酸、丙氨酸;缬氨酸、异亮氨酸、亮氨酸;天冬氨酸、谷氨酸、天冬酰胺、谷氨酰胺;丝氨酸、苏氨酸;赖氨酸、精氨酸;以及苯丙氨酸、酪氨酸。在确定同一性程度的示例性方法中,可以使用blast程序,其中在e-3与e-100之间的概率分数指示密切相关的序列。
217、例如,使用cobalt时利用以下参数:
218、a)比对参数:空位罚分-11,-1以及末端空位罚分-5,-1,
219、b)cdd参数:使用rps blast;blast e值0.003;查找保守列并重新计算,以及
220、c)查询聚类参数:使用查询集群;字号4;最大集群距离0.8;alphabet regular。
221、例如,使用emboss needle时利用以下参数:
222、a)矩阵:blosum62;
223、b)空位开放:10;
224、c)空位延伸:0.5;
225、d)输出格式:成对;
226、e)末端空位罚分:错误;
227、f)末端空位开放:10;以及
228、g)末端空位延伸:0.5。
229、术语“靶位点”是指核酸分子内被核碱基编辑器修饰的序列。在一个实施方案中,靶位点通过脱氨酶或包含脱氨酶(例如腺嘌呤脱氨酶)的融合蛋白脱氨基。
230、如本文所使用,“转导”是指通过病毒载体将基因或遗传物质转移至细胞。
231、如本文所使用,“转化”是指在细胞中引入基因变化的程序,该基因变化是通过引入外源核酸而产生的。
232、“转染”是指通过化学或物理方式将基因或遗传物质转移到细胞中。
233、“易位”是指非同源染色体之间核酸区段的重排。
234、如本文所使用,术语“治疗(treatment)”、“治疗(treating)”等是指减轻或改善病症和/或其相关症状,或获得期望的药理和/或生理作用。应当理解,尽管不排除完全消除病症、疾患或其相关症状的情形,但治疗病症或病症不需要完全消除病症、疾患或其相关症状。在一些实施方案中,所述作用是治疗性的,即,但不限于,所述作用部分地或完全地减少、减小、废除、减轻、缓解疾病和/或由该疾病引起的不利症状,降低该疾病和/或由该疾病引起的不利症状的强度,或治愈该疾病和/或由该疾病引起的不利症状。在一些实施方案中,所述作用是预防性的,即,该作用保护或预防疾病或疾患的发生或复发。为此,目前公开的方法包括施用治疗有效量的如本文所述的组合物。
235、“尿嘧啶糖基化酶抑制剂”或“ugi”是指抑制尿嘧啶切除修复系统的试剂。在一个实施方案中,所述试剂是结合宿主尿嘧啶-dna糖基化酶并防止从dna去除尿嘧啶残基的蛋白质或其片段。在一个实施方案中,ugi是能够抑制尿嘧啶-dna糖基化酶碱基切除修复酶的蛋白质、其片段或结构域。在一些实施方案中,ugi结构域包含野生型ugi或其修饰形式。在一些实施方案中,ugi结构域包含下文所阐述的示例性氨基酸序列的片段。在一些实施方案中,ugi片段包含的氨基酸序列包含至少60%、至少65%、至少70%、至少75%、至少80%、至少85%、至少90%、至少至少95%、至少96%、至少97%、至少98%、至少99%或100%的以下所提供的示例性ugi序列。在一些实施方案中,ugi包含与下文所阐述的示例性ugi氨基酸序列或其片段同源的氨基酸序列。在一些实施方案中,ugi或其一部分与下文所阐述的野生型ugi或ugi序列或其部分具有至少70%、至少75%、至少80%、至少85%、至少90%、至少95%、至少96%、至少97%、至少98%、至少99%、至少99.5%、至少99.9%或100%的同一性。
236、示例性ugi包含如下氨基酸序列:
237、>splp14739iungi_bppb2尿嘧啶-dna糖基化酶抑制剂
238、mtnlsdiieketgkqlviqesilmlpeeveevignkpesdilvh taydestdenvmlltsdapeykpwalviqdsngenkikml(seq id no:231)。
239、术语“载体”是指将核酸序列引入细胞中,由此产生转化的细胞的手段。载体包括质粒、转座子、噬菌体、病毒、脂质体和附加体。“表达载体”是包含打算在接受者细胞中表达的核苷酸序列的核酸序列。表达载体可以包括用以促进和/或帮助被引入序列的表达的额外核酸序列,例如起始序列、终止序列、增强子序列、启动子序列和分泌序列。
240、在本文变量的任何定义中关于化学基团清单的叙述包括将该变量定义为任何单个基团或所列基团的组合。本文关于变量或方面的实施方案的叙述包括呈任何单个实施方案形式或与任何其它实施方案或其部分的组合形式的该实施方案。
241、本文所提供的任何组合物或方法均可以与本文所提供的任何其它组合物和方法中的一者或多者组合。
242、dna编辑已成为通过在基因水平上校正致病性突变来改变疾病状态的可行手段。直到最近,所有dna编辑平台都是通过在指定基因组位点处诱导dna双链断裂(dsb)并依赖于内源性dna修复途径以半随机方式确定产物结果,从而产生复杂的遗传产物群来起作用。尽管可以通过同源定向修复(hdr)途径实现精确的、用户定义的修复结果,但有许多挑战阻碍了在治疗相关细胞类型中使用hdr进行高效修复。在实践中,相对于竞争性、易错非同源末端接合途径,这一途径的效率低下。此外,hdr严格限制于细胞周期的g1期和s期,阻止有丝分裂后细胞中dsb的精确修复。因此,已证明很难或不可能在这些群体中以用户定义的、可编程的方式高效地改变基因组序列。
- 还没有人留言评论。精彩留言会获得点赞!