人PCSK9蛋白的优势构象表位及其应用
人pcsk9蛋白的优势构象表位及其应用
技术领域
1.本发明涉及人pcsk9蛋白的优势构象表位及其应用,属于生物医药技术领域。
背景技术:
2.心血管疾病为致死率最高的疾病之一,低密度脂蛋白胆固醇(ldl-c)已被证实为心血管疾病发展的独立有效的危险因素之一,降低ldl-c水平能够有效减少心血管不良事件的发生率。目前临床使用的降胆固醇药物主要为他丁类药物,但由于患者服药后产生的转氨酶升高、肌痛和横纹肌溶解等不良事件的不断攀升对临床用药的选择和患者的耐受性产生了诸多不确定因素。
3.作为丝氨酸蛋白酶类的枯草杆菌蛋白酶家族的一员的前蛋白转化酶枯草溶菌素/kexin9型(pcsk9),已经成为近年来高胆固醇血症和心血管病防治的重要新靶标。该酶主要在肝脏中表达,分泌后会通过一种与低密度脂蛋白受体(ldl-r)直接结合,导致肝细胞表面ldl-r翻译后下调,引起循环ldl-c水平的升高。因此阻断或抑制pcsk9的表达或功能,可有效降低循环ldl-c水平。目前针对pcsk9蛋白靶点的研究方向主要包括单克隆抗体、小分子抑制剂、干扰肽、小分子干扰rna、反义寡核苷酸、基因编辑、模拟抗体蛋白药、疫苗等,其中进展最快的为单克隆抗体药物,目前单抗药物evolocumab(安进公司研发)和alirocumab(赛诺菲公司与再生元公司共同研发)已先后在欧洲、美国及中国获批上市,全球临床试验表明两种单抗药物可使各种患者群体的ldl-c水平降低40%~60%,表现出非常相似且强效的降低ldl-c作用。但由于单抗价格昂贵、药效时间有限和高免疫原性(产生抗药抗体)等缺陷,制约了其临床的广泛推广应用。相对于单克隆抗体而言,疫苗具有给药剂量小,制备成本低,药品经济负担低,作用持续时间长等优势,因此,开展psck9疫苗研究是一项很具潜力的选择,可用于高脂血症及动脉粥样硬化性等心血管疾病的长期治疗及预防。而寻找蛋白有效的表位是疫苗研发首要考虑问题。
4.人类pcsk9基因位于染色体1p32.3上,包含12个外显子并编码一个692个氨基酸残基的糖蛋白。pcsk9蛋白起初为在内质网合成时形成一个75kda的酶原,包含一个n端信号肽、一个前结构域(31-152残基)、一个催化结构域(153-452残基)和一个富含半光氨酸的c端结构域(453至692残基)。接着在内质网中pcsk9酶原去除信号肽序列后在152和153氨基酸残基位点间进行分子内自动催化裂解,形成一个14kda的前结构域片段和一个63kda成熟片段,前结构域仍以非共价键形式与催化结构域紧密连接并形成一个复合体,阻断了酶的底物结合位点,因此pcsk9没有蛋白酶活性,前结构域同时起着折叠伴侣和催化活性抑制剂的双重作用。最后,从内质网转运到高尔基体中,经过乙酰化等一系列修饰后最终分泌入血发挥作用。
技术实现要素:
5.本发明的目的是:利用噬菌体展示技术筛选得到能与已上市单克隆药物结合的优势多肽序列,再利用基因重组技术将优势多肽序列重组得到人pcsk9蛋白的优势构象表位,
本优势表位可用于血清单克隆抗体药物的检测,单克隆抗体药物筛选,pcsk9干扰肽新药及疫苗的研发等。
6.为了达到上述目的,本发明提供了一种人pcsk9蛋白的天然优势构象表位,为seq id no:1~4所示的多肽序列中的任意一种,所述的多肽序列能够特异性地结合抗pcsk9单抗药物。
7.优选地,所述的天然优势构象表位为seq id no:1或seq id no:2所示的多肽序列。
8.优选地,所述seq id no:1和seq id no:3所示的多肽序列具有重叠氨基酸序列:sipwnleritppryradeyqppdggslvev;所述seq id no:2和seq id no:4所示的多肽序列具有重叠氨基酸序列:agiaammlsaepeltlaelrqrlihfsakd。
9.优选地,所述的抗pcsk9单抗药物包括evolocumab和alirocumab单抗。
10.本发明还提供了一种人pcsk9蛋白的重组优势构象表位,为seq id no:5~8所示的重组序列中的任意一种,所述的重组序列由seq id no:1~4所示的多肽序列中的至少两种和柔性多肽接头重组而成,或由seq id no:1~4所示的多肽序列中的重叠序列和柔性多肽接头重组而成。
11.优选地,所述的重组优势构象表位由seq id no:1、seq id no:2所示的多肽序列和柔性多肽接头重组而成。
12.优选地,所述的重组优势构象表位中还包含pcsk9蛋白的v423~h449氨基酸序列:vineawfpedqrvltpnlvaalppsth。
13.优选地,所述的柔性多肽接头为(gly4ser)3柔性连接肽,其氨基酸序列为:ggggsggggsggggs。
14.本发明还提供了一种m13噬菌体展示载体pcantab5e-pro,为包含多克隆位点和(gly4ser)3接头对应的脱氧核苷酸序列的pcantab5e载体,所述的多克隆位点为ggcccagccggcc和ggtacc。
15.本发明还提供了一种m13重组噬菌体,包含如seq id no:9~12所示的核苷酸序列中的任意一种,所述seq id no:9~12所示的核苷酸序列用于编码上述的人pcsk9蛋白的重组优势构象表位。
16.本发明还提供了人pcsk9蛋白的重组优势构象表位的应用,不包括作为诊断方法和治疗方法的应用。
17.优选地,所述应用包括在制备抗pcsk9单克隆抗体药物或疫苗、pcsk9干扰肽新药或疫苗以及检测抗pcsk9单克隆抗体药物的试剂或试剂盒中的应用。
18.本发明的技术原理:
19.本发明利用2018年诺贝尔化学奖获奖技术噬菌体展示技术,将覆盖有成熟人pcsk9阅读框的不同肽段基因插入噬菌体外壳蛋白pⅲ基因中,将外源多肽展示于噬菌体颗粒的表面。这样外源多肽的基因型和表型可以巧妙的结合起来,展示在噬菌体表面的外源蛋白直接与其编码基因相关联,通过噬菌体繁殖扩增可直接进行外源蛋白的活性鉴定与序列分析,经特异性抗体的筛选,可获得特异结合的目的分子,而且通过“吸附”一“洗脱”一“扩增”的重复过程使含有目的蛋白的噬菌体得到上万倍至上亿倍的富集,从而得到pcsk9序列中优势结合的序列,再结合序列分析最终得到pcsk9优势构象表位。
20.与现有技术相比,本发明的有益效果在于:
21.1.本发明利用噬菌体展示的亲和筛选技术,可将外源多肽的基因型和表型巧妙的结合起来,展示在噬菌体表面的外源蛋白直接与其编码基因相关联,通过噬菌体繁殖扩增可直接进行外源蛋白的活性鉴定与序列分析,为优势靶点提供了最直接的证据,克服了目前对于药物作用于pcsk9蛋白的的靶点筛选多采用计算机模拟及人为推测,不能直接证明靶点的优越性的缺陷;
22.2.本发明是以现有临床证实有优越疗效上市的单抗药物为诱饵,钓取pcsk9蛋白众多表位的最优选择,得到pcsk9的优势构象表位,为后续新药研究靶点的选择提供了直接证据。
附图说明
23.图1a~d显示了噬菌体超载设计噬菌体展示文库四轮亲和筛选结果;
24.图2a~d显示了单抗超载设计噬菌体展示文库四轮亲和筛选结果;
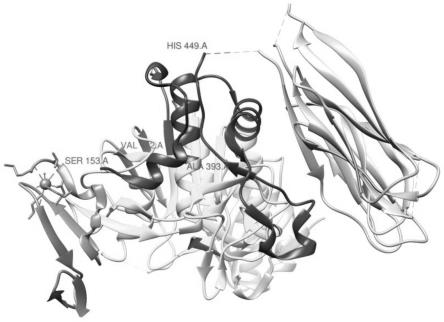
25.图3a、3c、3e、3g显示了四种重组优势构象表位在pcsk9空间结构位置,图3b、3d、3f、3h显示了从pcsk9蛋白表面观察四种重组优势构象表位的位置。
具体实施方式
26.为使本发明更明显易懂,兹以优选实施例,并配合附图作详细说明如下。
27.本发明第一方面是通过噬菌体展示技术,从成熟人pcsk9全长氨基酸序列(31~692aa)中筛选得到了均能够和目前临床在用的抗pcsk9单抗药物evolocumab和alirocumab最优结合的两段多肽和次优结合的两段多肽,这四段多肽均可特异性结合evolocumab和alirocumab单抗,最优结合的两段多肽分别对应pcsk9蛋白的s153~d212和a363~d422两段氨基酸序列,长度均为60个氨基酸,分别命名为pc3和ps6,其结合优势为pc3最优,ps6次最优,次优结合的两段多肽分别对应pcsk9蛋白的f122~v182和a393~g452两段氨基酸序列,长度分别为61和60个氨基酸,分别命名为ps2和pc7,其结合优势相当。这四段多肽的关系为pc3与ps2重叠30个氨基酸,ps6与pc7重叠30个氨基酸,其具体氨基酸序列见下,下划线表示重叠氨基酸序列:
28.①
pc3:
29.sipwnleritppryradeyqppdggslvevylldtsiqsdhreiegrvmvtdfenvpeed(seq id no:1);
30.②
ps6:
31.apgediigassdcstcfvsqsgtsqaaahvagiaammlsaepeltlaelrqrlihfsakd(seq id no:2);
32.③
ps2:
33.flvkmsgdllelalklphvdyieedssvfaqsipwnleritppryradeyqppdggslvev(seq id no:3);
34.④
pc7:
35.agiaammlsaepeltlaelrqrlihfsakdvineawfpedqrvltpnlvaalppsthgag(seq id no:4)。
36.本发明第二方面提供了筛选得到的优势序列在pcsk9蛋白空间结构的展示图,是通过对蛋白质数据库rcsb pdb公示的pcsk9晶体空间结构(id:2pmw和3bps)分析,发现pc3与ps6两段氨基酸序列在蛋白空间结构上有相邻区域,且该区域位于蛋白表面,结合噬菌体展示技术亲和筛选结果,可判定为pc3与ps6为pcsk9蛋白的重要构象表位,且在筛选得到的四段多肽的重叠氨基酸序列起到更为关键的作用。
37.本发明第三方面是提供了能够反应pcsk9优势构象表位的四种重组多肽,是通过分析pcsk9蛋白空间结构,利用基因重组技术将亲和筛选得到的优势序列加上柔性多肽接头重组而成,得到的四种重组多肽能够直接反应pcsk9蛋白的优势构象表位。四段重组肽名称分别为snrp1、snrp2、lnrp1和lnrp2,这四种多肽可以用于其具体组成如下:
38.①
snrp1:
39.sipwnleritppryradeyqppdggslvevggggsggggsggggsagiaammlsaepeltlaelrqrlihfsakdvineawfpedqrvltpnlvaalppsth(seq id no:5);
40.下划线部分为(gly4ser)3柔性连接肽,连接肽前为pc3与ps2重叠氨基酸序列,连接肽后包含ps6与ps7重叠氨基酸序列和pcsk9中v423~h449氨基酸序列。
41.②
snrp2:
42.sipwnleritppryradeyqppdggslvevggggsggggsggggsagiaammlsaepeltlaelrqrlihfsakd(seq id no:6);
43.下划线部分为(gly4ser)3柔性连接肽,连接肽前为pc3与ps2重叠氨基酸序列,连接肽后为ps6与ps7重叠氨基酸序列。
44.③
lnrp1:
45.sipwnleritppryradeyqppdggslvevylldtsiqsdhreiegrvmvtdfenvpeedggggsggggsggggsapgediigassdcstcfvsqsgtsqaaahvagiaammlsaepeltlaelrqrlihfsakdvineawfpedqrvltpnlvaalppsth(seq id no:7);
46.下划线部分为(gly4ser)3柔性连接肽,连接肽前为pc3氨基酸序列,连接肽后包含ps6氨基酸序列和pcsk9中v423~h449氨基酸序列。
47.④
lnrp2:
48.sipwnleritppryradeyqppdggslvevylldtsiqsdhreiegrvmvtdfenvpeedggggsggggsggggsapgediigassdcstcfvsqsgtsqaaahvagiaammlsaepeltlaelrqrlihfsakd(seq id no:8);
49.下划线部分为(gly4ser)3柔性连接肽,连接肽前为pc3氨基酸序列,连接肽后为ps6氨基酸序列。
50.本发明第四方面是提供了一种m13噬菌体展示载体,该展示载体是在pcantab5e载体基础上增加了多克隆位点和(gly4ser)3接头对应的脱氧核苷酸序列,能够更好地展示目的蛋白的构象,而不影响噬菌体滴度和感染菌体,该载体命名为pcantab5e-pro。
51.本发明第五方面是提供了展示有pcsk9优势构象表位的四种m13噬菌体,即m13phage-snrp1(seq id no:9)、m13phage-snrp2(seq id no:10)、m13phage-lnrp1(seq id no:11)和m13phage-lnrp2(seq id no:12),这四种噬菌体是由pcantab5e-pro载体和超级辅助噬菌体hyperphage m13k07δpiii在大肠杆菌tg1中包装而成,而且噬菌体的每个piii蛋白均有融合展示目的多肽,大大提高了噬菌体效价。
52.本发明的以下实施例中,所用到的实验仪器如表1所示、实验试剂如表2所示。
53.表1实验仪器
[0054][0055][0056]
表2实验试剂
[0057][0058][0059]
以下实施例中,噬菌体展示载体pcantab5e-pro是由pcantab5e改造而来,大肠杆菌tg1购买自上海碧云天生物技术有限公司,辅助噬菌体m13ko7购买自new england biolabs(neb)公司。
[0060]
实施例1pcsk9多肽片段噬菌体展示文库的构建
[0061]
1、实验方法
[0062]
(1)pcsk9阅读框序列制备
[0063]
从ncbi网站中获取人pcsk9基因信息,并从成熟mrna序列(nm_174936.4)中读取开放式阅读框序列,设计将第498位碱基c突变为t,以消除序列内部kpnⅰ酶切位点,便于后续克隆时酶切位点的选择,但不改变翻译后氨基酸序列。序列设计好后进行全基因合成,并测序确认序列的正确性。
[0064]
(2)引物设计
[0065]
结合pcsk9全基因开放式阅读框序列及各结构域划分及各功能区差异,去除信号肽序列和终止密码子,剩余基因序列为编码成熟人pcsk9蛋白的碱基序列,长度为1986bp,将其划分为11段设计引物,扩增对应片段命名为pc1~pc11,其中pc1和pc2片段均长183bp,为pcsk9的n端前结构域部分,其余均为180bp长度的碱基片段,其中pc3~pc7包含的序列为pcsk9的催化结构域,pc8~pc11中的序列为pcsk9的c端结构域;同时设计覆盖有pc1~pc11间隔的片段ps1~ps10,即每个ps片段是由相邻pc片段的各自一半碱基序列组成,具体引物序列如表3所示:
[0066]
表3引物序列
[0067]
[0068][0069]
引物中下划线为限制酶识别位点sfiⅰ和kpnⅰ,引物名称中f为上游引物,r为下游引物,pc1~pc11和ps1~ps10为对应设计扩增的21个碱基片段。
[0070]
(3)重组噬菌体展示载体构建和鉴定
[0071]
采用常规分子生物学方法以含有pcsk9基因阅读框序列的质粒为模板,扩增上述21个片段,并对产物进行纯化、酶切、再纯化后与酶切纯化后的pcantab5e-pro质粒连接,将连接产物转化大肠杆菌dh5α,对获得的单克隆菌落pcr鉴定,将鉴定阳性克隆送测序以确认重组质粒的正确性。
[0072]
(4)噬菌体展示文库的构建
[0073]
将鉴定正确的21种重组噬菌体载体分别转化大肠杆菌tg1,用单克隆菌培养后,加入m13ko7辅助噬菌体,制备出21种重组噬菌体,将各种噬菌体滴度调整一致后混合,即为噬菌体展示文库。
[0074]
2、实验结果
[0075]
(1)pcsk9阅读框序列的鉴定
[0076]
将全基因合成好的pcsk9阅读框碱基序列克隆至t载体,并测序,其碱基序列如seq id no:13所示:
[0077]
atgggcaccgtcagctccaggcggtcctggtggccgctgccactgctgctgctgctgctgctgctcctgggtcccgcgggcgcccgtgcgcaggaggacgaggacggcgactacgaggagctggtgctagccttgcgttccgaggaggacggcctggccgaagcacccgagcacggaaccacagccaccttccaccgctgcgccaaggatccgtggaggttgcctggcacctacgtggtggtgctgaaggaggagacccacctctcgcagtcagagcgcactgcccgccgcctgca
ggcccaggctgcccgccggggatacctcaccaagatcctgcatgtcttccatggccttcttcctggcttcctggtgaagatgagtggcgacctgctggagctggccttgaagttgccccatgtcgactacatcgaggaggactcctctgtctttgcccagagcatcccgtggaacctggagcggattacccctccacggtatcgggcggatgaataccagccccccgacggaggcagcctggtggaggtgtatctcctagacaccagcatacagagtgaccaccgggaaatcgagggcagggtcatggtcaccgacttcgagaatgtgcccgaggaggacgggacccgcttccacagacaggccagcaagtgtgacagtcatggcacccacctggcaggggtggtcagcggccgggatgccggcgtggccaagggtgccagcatgcgcagcctgcgcgtgctcaactgccaagggaagggcacggttagcggcaccctcataggcctggagtttattcggaaaagccagctggtccagcctgtggggccactggtggtgctgctgcccctggcgggtgggtacagccgcgtcctcaacgccgcctgccagcgcctggcgagggctggggtcgtgctggtcaccgctgccggcaacttccgggacgatgcctgcctctactccccagcctcagctcccgaggtcatcacagttggggccaccaatgcccaagaccagccggtgaccctggggactttggggaccaactttggccgctgtgtggacctctttgccccaggggaggacatcattggtgcctccagcgactgcagcacctgctttgtgtcacagagtgggacatcacaggctgctgcccacgtggctggcattgcagccatgatgctgtctgccgagccggagctcaccctggccgagttgaggcagagactgatccacttctctgccaaagatgtcatcaatgaggcctggttccctgaggaccagcgggtactgacccccaacctggtggccgccctgccccccagcacccatggggcaggttggcagctgttttgcaggactgtatggtcagcacactcggggcctacacggatggccacagccgtcgcccgctgcgccccagatgaggagctgctgagctgctccagtttctccaggagtgggaagcggcggggcgagcgcatggaggcccaagggggcaagctggtctgccgggcccacaacgcttttgggggtgagggtgtctacgccattgccaggtgctgcctgctaccccaggccaactgcagcgtccacacagctccaccagctgaggccagcatggggacccgtgtccactgccaccaacagggccacgtcctcacaggctgcagctcccactgggaggtggaggaccttggcacccacaagccgcctgtgctgaggccacgaggtcagcccaaccagtgcgtgggccacagggaggccagcatccacgcttcctgctgccatgccccaggtctggaatgcaaagtcaaggagcatggaatcccggcccctcaggagcaggtgaccgtggcctgcgaggagggctggaccctgactggctgcagtgccctccctgggacctcccacgtcctgggggcctacgccgtagacaacacgtgtgtagtcaggagccgggacgtcagcactacaggcagcaccagcgaaggggccgtgacagccgttgccatctgctgccggagccggcacctggcgcaggcctcccaggagctccagtga。
[0078]
(2)重组噬菌体展示载体的鉴定结果
[0079]
构建的含有21种重组噬菌体展示载体的单克隆菌,先经过pcr鉴定,与dna marker比对的琼脂糖凝胶电泳结果表明,鉴定扩增出的目的片段均在180bp左右,将初步鉴定的阳性单菌落培养后送测序,测序结果与设计一致。
[0080]
(3)噬菌体展示文库结果
[0081]
对制备21种重组噬菌体进行滴度测定后,将每种噬菌体滴度均调整为10
11
cfu大小后混合,即得到滴度为10
11
cfu大小的噬菌体展示文库。
[0082]
实施例2pcsk9多肽片段噬菌体展示文库的亲和筛选
[0083]
本实施例中主要是通过两种噬菌体展示文库亲和筛选设计,一种是噬菌体超载设计,目的是快速找到21种pcsk9短肽中最优结合序列,另一种是单抗超载设计,目的是给予21种pcsk9短肽充足的结合机会,以考察不同多肽片段结合的优劣竞争关系,以分析得到pcsk9最优构象表位。
[0084]
1、实验方法
[0085]
(1)噬菌体超载设计噬菌体展示文库的亲和筛选
[0086]
为先将两种单克隆抗体evolocumab和alirocumab分子用ph9.6碳酸盐缓冲液稀释
成10μg/ml,每孔加入100μl包被于酶标排条板上,用无蛋白封闭液封闭过夜,tbst洗涤,每孔加入100μl 10
11
cfu噬菌体文库,37℃震荡反应3小时,tbst洗涤后,每孔加入100μl对数期的大肠杆菌tg1,37℃震荡反应1小时,收集孔中菌液,取1μl涂布平板,其余加入m13ko7辅助噬菌体后扩大培养过夜,离心后收集上清即为筛选后的噬菌体文库。如此重复4轮,将每轮平板中的单克隆菌落随机挑取21个送测序检测。
[0087]
(2)单抗超载设计噬菌体展示文库的亲和筛选
[0088]
方法与上述步骤(1)相同,将单克隆抗体稀释成20μg/ml包被在酶标板上,每孔加入100μl 10
10
cfu噬菌体文库进行亲和筛选,同样重复4轮,从每轮筛选涂布的每个平板中分别随机挑取单克隆菌落21个送测序检测。
[0089]
2、实验结果
[0090]
(1)噬菌体超载设计噬菌体展示文库的亲和筛选结果
[0091]
对于亲和筛选过程进行了2复孔设计,每孔独立筛选,独立检测,对测序结果进行序列比对,对比对结果显示的对应肽段汇总计数,结果如表4所示:
[0092]
表4噬菌体超载设计噬菌体展示文库的亲和筛选结果
[0093]
[0094][0095]
表4中pc1~pc11与ps1~ps10为21种pcsk9的肽段,p1~p4表示四轮筛选过程,a1、a2表示单克隆抗体alirocumab包被的复孔,e1、e2表示单克隆抗体evolocumab包被的复孔,对表中数据换算成百分率后制得四轮亲和筛选结果,如图1a-d所示,结果表明在噬菌体量足够大的情况下,快速找到了最优结合序列pc3和次最优结合序列ps6。
[0096]
(2)单抗超载设计噬菌体展示文库的亲和筛选结果
[0097]
同样对于亲和筛选过程进行了2复孔设计,每孔独立筛选,独立检测,对测序结果进行序列比对,对比对结果显示的对应肽段汇总计数,结果如表5所示:
[0098]
表5单抗超载设计噬菌体展示文库的亲和筛选结果
[0099]
[0100][0101]
表中pc1~pc11与ps1~ps10为21种pcsk9的肽段,p1~p4表示四轮筛选过程,a3、a4表示单克隆抗体alirocumab包被的复孔,e3、e4表示单克隆抗体evolocumab包被的复孔,对表中数据换算成百分率后制得四轮亲和筛选结果如图2a~d所示,结果表明在单抗数量占优的情况下,噬菌体各展示肽段之间展示了激烈的竞争关系,最终不仅证实了pc3和ps6为最优结合序列和次最优结合序列,而且找到了两段次优结合序列,并且这两段次优序列与最优序列间有重叠关系,更进一步证实了pc3-ps6在构象表位的存在。
[0102]
实施例3展示有四种pcsk9构象表位重组噬菌体的制备及鉴定
[0103]
本实施例是通过分析实施例2中亲和筛选的结果,再结合pcsk9蛋白空间结构,利用基因重组技术将前述第一方面得到的优势序列的碱基片段进行重组,优势片段间加入了柔性连接肽(gly4ser)3的碱基序列,以便可以更好地展示pcsk9的优势构象表位。
[0104]
1、实验方法
[0105]
(1)引物设计
[0106]
采用overlappcr方法对优势碱基序列进行基因重组,得到snrp1、snrp2、lnrp1和lnrp2四种重组序列,引物序列如表6所示:
[0107]
表6引物序列
[0108][0109]
表6中引物序列中单下划线为限制酶识别位点sfiⅰ和kpnⅰ,双下划线为overlap段,也为柔性连接肽(gly4ser)3的碱基序列,列引物名称中f为上游引物,r为下游引物。以pcsk9开放式读码框序列为模板,引物sfkpc3-f、lapsur1、lapsdf2、lsr扩增得到snrp1重组序列,引物sfkpc3-f、laplur2、lapsdf2、sfkpc6-r扩增得到snrp2重组序列,引物sfkpc3-f、lapsur1、lapldf1、lsr扩增得到lnrp1重组序列,引物sfkpc3-f、lapsur1、lapldf1、sfkpc6-r扩增得到lnrp2重组序列。
[0110]
(3)重组噬菌体展示载体构建和鉴定
[0111]
采用常规分子生物学方法扩增得到snrp1、snrp2、lnrp1和lnrp2四种重组序列,对产物进行纯化后克隆至t载体中,pcr鉴定阳性克隆送测序,以鉴定正确的单克隆菌为模板扩增snrp1、snrp2、lnrp1和lnrp2四种重组序列,扩增产物再经纯化、酶切、再纯化后与酶切纯化后的pcantab5e-pro质粒连接,将连接产物转化大肠杆菌dh5α,随机挑取单克隆菌落pcr鉴定,将鉴定阳性克隆送测序以确认重组质粒的正确性。
[0112]
(4)四种pcsk9构象表位重组噬菌体的制备及鉴定
[0113]
将鉴定正确的4种重组噬菌体载体分别转化大肠杆菌tg1,用单克隆菌培养后,加入m13ko7辅助噬菌体,制备出4种重组噬菌体,并进行滴度测定。
[0114]
2、实验结果
[0115]
(1)四种重组序列的制备及鉴定
[0116]
将overlappcr扩增制备的四种重组碱基序列克隆至t载体,并最终经测序鉴定其序列的完整性,测序得到的4种碱基序列如下,下划线表示柔性连接肽碱基序列:
[0117]
snrp1(seq id no:9):
[0118]
agcatcccgtggaacctggagcggattacccctccacggtatcgggcggatgaataccagccccccgacggaggcagcctggtggaggtgggtggcggcggaagtggcggtggcggaagcggcggtggtggatctgctggcatt
gcagccatgatgctgtctgccgagccggagctcaccctggccgagttgaggcagagactgatccacttctctgccaaagatgtcatcaatgaggcctggttccctgaggaccagcgggtactgacccccaacctggtggccgccctgccccccagcacccat;
[0119]
snrp2(seq id no:10):
[0120]
agcatcccgtggaacctggagcggattacccctccacggtatcgggcggatgaataccagccccccgacggaggcagcctggtggaggtgggtggcggcggaagtggcggtggcggaagcggcggtggtggatctgctggcattgcagccatgatgctgtctgccgagccggagctcaccctggccgagttgaggcagagactgatccacttctctgccaaagat;
[0121]
lnrp1(seq id no:11):
[0122]
agcatcccgtggaacctggagcggattacccctccacggtatcgggcggatgaataccagccccccgacggaggcagcctggtggaggtgtatctcctagacaccagcatacagagtgaccaccgggaaatcgagggcagggtcatggtcaccgacttcgagaatgtgcccgaggaggacggtggcggcggaagtggcggtggcggaagcggcggtggtggatctgccccaggggaggacatcattggtgcctccagcgactgcagcacctgctttgtgtcacagagtgggacatcacaggctgctgcccacgtggctggcattgcagccatgatgctgtctgccgagccggagctcaccctggccgagttgaggcagagactgatccacttctctgccaaagatgtcatcaatgaggcctggttccctgaggaccagcgggtactgacccccaacctggtggccgccctgccccccagcacccat;
[0123]
lnrp2(seq id no:12):
[0124]
agcatcccgtggaacctggagcggattacccctccacggtatcgggcggatgaataccagccccccgacggaggcagcctggtggaggtgtatctcctagacaccagcatacagagtgaccaccgggaaatcgagggcagggtcatggtcaccgacttcgagaatgtgcccgaggaggacggtggcggcggaagtggcggtggcggaagcggcggtggtggatctgccccaggggaggacatcattggtgcctccagcgactgcagcacctgctttgtgtcacagagtgggacatcacaggctgctgcccacgtggctggcattgcagccatgatgctgtctgccgagccggagctcaccctggccgagttgaggcagagactgatccacttctctgccaaagat。
[0125]
(2)四种pcsk9构象表位重组噬菌体的制备及鉴定
[0126]
经测定制备得到的4种展示有pcsk9优势构象表位的重组噬菌体的滴度均可达到10
11
cfu,证明已在噬菌体颗粒表面的pⅲ蛋白上成功展示,同时对这4种优势表位的多肽在pcsk9蛋白晶体结构进行了定位分析,确认了pc3-ps6优势构象表位的存在,结果如图3a~h所示,结果表明此表位序列主要在蛋白结构表面,且没有被前结构域结合位点和ldlr结合和位点覆盖,可以判定此处应为目前发现的pcsk9优势构象表位,为后续药物研发的靶点选择提供了有力的证据。
[0127]
本发明通过噬菌体展示技术筛选得到人pcsk9蛋白的天然优势序列,并对优势序列进行了基因重组,得到了四种能够反应pcsk9优势构象表位的重组多肽的序列信息,该序列可以直接进行蛋白表达或构建重组病毒颗粒等,以用于后续特异性抗体药物血药浓度检测试剂盒开发、抗pcsk9单克隆抗体药物的筛选及降胆固醇干扰肽药物研发及用于高胆固醇血症防治的pcsk9疫苗研发等。
[0128]
上述实施例仅为本发明的优选实施例,并非对本发明任何形式上和实质上的限制,应当指出,对于本技术领域的普通技术人员,在不脱离本发明的前提下,还将可以做出若干改进和补充,这些改进和补充也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1