一种用于检测单个CAR-T细胞的慢病毒载体拷贝数的方法及其应用
一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法及其应用
技术领域
1.本发明涉及生物技术领域,尤其涉及一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法及其应用。
背景技术:
2.car-t指嵌合抗原受体(chimeric antigen receptor,car)t细胞,是指将能识别某种肿瘤抗原的抗体单链可变区(single chain antibody fragment,scfv)与胞内信号区在体外偶联为一个嵌合蛋白,通过基因转导的方法转染体外培养的患者t细胞,使其表达嵌合抗原受体(car)。这一过程通过重组慢病毒载体进行导入,即外源基因(嵌合抗原受体,car)导入到宿主细胞(t细胞)。由于在转导过程中,慢病毒载体被随机插入宿主基因组内,插入的拷贝数和位点都不固定。当外源基因以低拷贝数(1或2个)插入时能较好的表达,而多拷贝数插入的外源基因表达不稳定甚至出现基因沉默现象。因此,测定car-t细胞基因组慢病毒载体的拷贝数,可以为car-t细胞靶点基因的表达情况提供依据。
3.现有技术中,拷贝数大多以dna为单位表示copys,无法精确定量每个细胞内的拷贝数,进而无法评估car的单细胞拷贝数对car-t细胞的影响。
技术实现要素:
4.有鉴于此,本发明提出了一种能够精确定量每个细胞内的拷贝数的慢病毒载体拷贝数的方法。
5.本发明的技术方案是这样实现的:第一方面,本发明提供了一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法,包括如下步骤:
6.s1,以β-globin为内参基因,设计β-globin的qpcr引物和探针,利用β-globin的质粒模板建立标准曲线1;
7.s2,设计目的基因的引物和探针,利用目的基因的质粒模板建立标准曲线2;
8.s3,分别使用β-globin和目的基因的qpcr引物对待测样本进行pcr扩增,从标准曲线1上计算出待测样本的β-globin拷贝数,从标准曲线2上计算出待测样品的car拷贝数,然后根据公式计算出目的基因相对细胞数的拷贝数;
9.目的基因相对细胞数的拷贝数计算公式为:
[0010][0011]
在以上技术方案的基础上,优选的,所述内参基因β-globin的核苷酸序列如seq id:no.1所示;所述内参基因β-globin上游引物的核苷酸序列如seq id:no.2所示,下游引物的核苷酸序列如seq id:no.3所示,探针的核苷酸序列如seq id:no.4所示。
[0012]
在以上技术方案的基础上,优选的,所述目的基因元件选自cd30 scfv、wpre、hiv-1ψ和rre中的至少一种。
[0013]
在以上技术方案的基础上,优选的,所述目的基因选自cd30 scfv和wpre。
[0014]
在以上技术方案的基础上,优选的,所述cd30 scfv的核苷酸序列如seq id:no.5,所述cd30 scfv上游引物的核苷酸序列如seq id:no.6所示,下游引物的核苷酸序列如seq id:no.7所示,探针的核苷酸序列如seq id:no.8所示。
[0015]
在以上技术方案的基础上,优选的,所述wpre的核苷酸序列如seq id:no.9,所述cd30 scfv上游引物的核苷酸序列如seq id:no.10所示,下游引物的核苷酸序列如seq id:no.11所示,探针的核苷酸序列如seq id:no.12所示。
[0016]
在以上技术方案的基础上,优选的,所述内参基因β-globin、目的基因cd30 scfv和wpre的探针5’端均标记有荧光基团,3’端均标记有淬灭基团fam;所述荧光基团选自vic、fam、tet、hex、cy3、cy5、texas red、lc red640和lc red705中的一种。
[0017]
pcr扩增的反应体系:aceq qpcr probe master mix15.0μl、pf primer 20μm 1.2μl、pr primer 20μm 1.2μl、probe 20μm 0.3μl、sample 5.0μl、rnase-free water 7.3μl、total30μl;pcr扩增的反应条件:95℃,5min;(95℃,10s;60℃,30s;)
×
45。
[0018]
第二方面,本发明还提供了一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法在检测慢病毒载体拷贝数中的应用,所述慢病毒载体拷贝数为整合入平均每个car-t细胞基因组中的慢病毒载体拷贝数。
[0019]
第三方面,本发明还提供了一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法在检测待测样本中car拷贝数的应用。
[0020]
本发明的一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法及其应用相对于现有技术具有以下有益效果:
[0021]
(1)本发明以β-globin为内源参照基因、cd30 scfv和wpre为基因元件,能够稳定且有效地检测出整合入car-t细胞基因组中整合的病毒载体拷贝数,且能够换算成平均每个car-t细胞基因组中整合的病毒载体拷贝数。
[0022]
(2)本发明的β-globin是核单拷贝基因,一个细胞表达两个拷贝的β-globin基因,且在人的所有类型细胞中都稳定表达。
附图说明
[0023]
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中所需要使用的附图作简单地介绍,显而易见地,下面描述中的附图仅仅是本发明的一些实施例,对于本领域普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其他的附图。
[0024]
图1为本发明实施例二中β-globin序列及对应的qpcr引物、探针位置的示意图
[0025]
图2为本发明实施例二中mcd30-01car序列及对应的qpcr引物、探针位置的示意图;
[0026]
图3为本发明实施例二中wpre序列及对应的qpcr引物、探针位置的示意图;
[0027]
图4为本发明实施例六中mcd30-01质粒工作标准扩增曲线;
[0028]
图5为本发明实施例六中mcd30-01质粒工作标准扩增情况;
[0029]
图6为本发明实施例六中β-globin质粒工作标准扩增曲线;
[0030]
图7为本发明实施例六中β-globin质粒工作标准扩增情况;
[0031]
图8为本发明实施例六中wpre质粒工作标准扩增曲线;
[0032]
图9为本发明实施例六中wpre质粒工作标准扩增情况;
[0033]
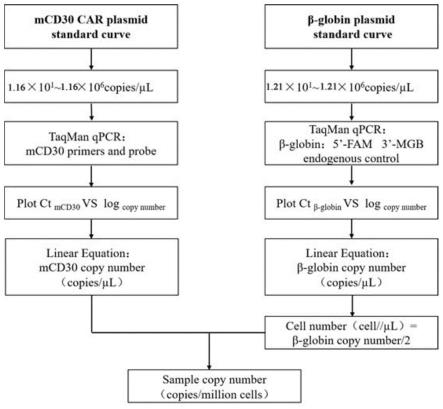
图10为本发明单个car-t细胞的慢病毒载体拷贝数的检测方法流程图。
具体实施方式
[0034]
下面将结合本发明实施方式,对本发明实施方式中的技术方案进行清楚、完整地描述,显然,所描述的实施方式仅仅是本发明一部分实施方式,而不是全部的实施方式。基于本发明中的实施方式,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施方式,都属于本发明保护的范围。
[0035]
本发明的一种用于检测单个car-t细胞的慢病毒载体拷贝数的方法,包括如下步骤:
[0036]
首先,建立两条标准曲线:第一是内源参照基因β-globin,用已知拷贝数的β-globin质粒标准品,建立标准曲线1;第二是使用已知起始拷贝数的带有目的基因(car基因)的质粒做标准品,可作出标准曲线2;其中横坐标代表ct值,纵坐标代表起始拷贝数的对数。
[0037]
其次,分别使用β-globin和目的基因(car基因)的qpcr引物对待测样本品进行pcr反应,获得样品关于β-globin反应的ct值,即可从标准曲线1上计算出该样品的β-globin的拷贝数(copys/μl);获得样品关于car的ct值,即可从标准曲线2上计算出该样品的car的拷贝数(copys/μl)。
[0038]
最后根据公式计算出目的基因相对细胞数的拷贝数;
[0039]
目的基因相对细胞数的拷贝数计算公式为:
[0040][0041]
β-globin是核单拷贝基因,一个人的细胞表达两个拷贝的β-globin,即细胞量表示为β-globin的拷贝数/2(cells/μl)。目的基因相对细胞数的拷贝数则可以表示为目的基因起始量与细胞个数起始量的比值,即拷贝数/细胞(copys/cells)。
[0042]
目的基因选自选自cd30 scfv、wpre、hiv-1ψ和rre中的至少一种。
[0043]
内参基因β-globin的核苷酸序列如seq id:no.1所示,上游引物的核苷酸序列如seq id:no.2所示,下游引物的核苷酸序列如seq id:no.3所示,探针的核苷酸序列如seq id:no.4所示。
[0044]
cd30 scfv的核苷酸序列如seq id:no.5,上游引物的核苷酸序列如seq id:no.6所示,下游引物的核苷酸序列如seq id:no.7所示,探针的核苷酸序列如seq id:no.8所示。
[0045]
wpre的核苷酸序列如seq id:no.9,上游引物的核苷酸序列如seq id:no.10所示,下游引物的核苷酸序列如seq id:no.11所示,探针的核苷酸序列如seq id:no.12所示。
[0046]
β-globin、cd30 scfv、wpre探针序列的5’端均标记有荧光基团,3’端均标记有淬
灭基团fam;荧光基团选自vic、fam、tet、hex、cy3、cy5、texas red、lc red640和lc red705中的一种。
[0047]
实施例1标准品质粒构建和标准品的制备
[0048]
1.1.内参基因和目的基因的选择
[0049]
使用内参基因来归一化实验结果,作为一个合适的归一化因子,所有的待检样品中的内参基因的表达量必须是恒定不变的,它的表达不能因研究过程中的各个处理而发生改变,最常用的内参基因是那些在所有细胞类型中稳定表达的基因。β-globin是核单拷贝基因,一个细胞表达两个拷贝的β-globin基因,且在人的所有类型细胞中都稳定表达。本实施例以β-globin基因作为内参基因来归一化实验结果,β-globin核苷酸序列如seq id.1所示。
[0050]
来源于hiv-1型慢病毒载体上有许多顺式作用元件,例如cppt和wpre,其对慢病毒的包装效率影响很大。以car载体上的通用元件wpre(土拨鼠乙肝病毒转录后调控元件)为靶基因,其可以监控的car基因的表达量,达到通用型的目的;以car scfv为靶基因可以检测到,同样可以监控的car基因的表达量,达到特异性识别car的目的。cd30 scfv和wpre核苷酸序列分别如seq id.5和seq id.9所示。
[0051]
1.2.标准品质粒构建
[0052]
在上述β-globin、cd30 scfv和wpre基因序列两端用snapgene软件设计普通引物,扩增全长靶基因和内参基因dna片段,通过胶回收试剂盒纯化回收全长靶基因和内参基因dna片段。参考pclone007 versatile simple vector kit说明书,分别将全长靶基因和内参基因dna片段与t载体(pclone007)连接,构建质粒标准品pclone-wpre、pclone-cd30和pclone-β-globin。
[0053]
表1质粒标准品信息
[0054]
名称储存浓度(ng/μl)碱基数(bp)β-globin27.112038mcd30-01151.6111879wpre111.453283
[0055]
实施例2引物和探针设计
[0056]
良好的引物和探针设计是实时荧光定量pcr的最重要步骤之一。引物探针设计需确保引物探针对目的序列的特异性,且不会形成内部二级结构,并能避免每条引物的3’端自身或与其它引物之间形成互补杂交。采用primerexpress3.0软件设计引物和探针,设计原则如表2-4所示。
[0057]
表2探针设计原则
[0058]
[0059][0060]
表3引物设计原则
[0061][0062]
表4扩增子遵循原则
[0063]
指标扩增子长度70bp~150bptm值最大85℃gc含量40%~55%靶序列要扩增富含at的靶序列
[0064]
通过以上设计原则设计出的引物和探针分别在ncbi primer blast和rtprimerdb数据库中检索,确定其特异性。探针上荧光基团的标记。多重的实时荧光定量pcr的探针上的荧光基团之间不能相互干扰。探针5’端标记为fam,3’端标记为mgb。引物探针的溶解与分装。引物和探针干粉用nuclease-free water溶解到100μm,作为储备液,放-20℃储存。使用时取少量将储备液稀释到10μm,作为工作浓度,放4℃储存且不超过6个月。注意探针用棕色1.5ml离心管避光储存。
[0065]
实施例3样品处理
[0066]
一种用于检测慢病毒载体拷贝数的方法,采用检测试剂对待测样本进行荧光定量pcr,具体包括以下步骤。
[0067]
3.1细胞裂解
[0068]
取约5~6
×
106个细胞,在培养基中加入25u cryonasetm cold-active nuclease,4℃消化1h;室温,500g,离心5min,用移液器移除大部分培养基,留约100μl培养基,将细胞吹匀;加入1ml dnazol,轻轻吹打约50次(如果不立即提取则放-20℃暂存,提取时从-20℃取出,待其融化后轻轻吹打10次)。
[0069]
3.2 dna沉淀
[0070]
向上述细胞匀浆液中加入0.5ml无水乙醇,上下颠倒10次,室温放置1~3min,可见白色dna沉淀;4℃,18000g,离心15min。
[0071]
3.3 dna洗涤
[0072]
去除上清,加入1ml 75%乙醇洗涤,上下颠倒5次,室温放置1~3min;4℃,15000g,离心5min;去除上清(注意尽量吸取干上清),开盖静置使沉淀风干(沉淀由白色变为透明)。
[0073]
3.4 dna溶解
[0074]
加入适量体积的8mm naoh溶液(根据沉淀大小),4℃溶解过夜;加入0.1m hepes调ph至8.4。(按1ml 8mm naoh加入86μl 0.1m hepes计算)。
[0075]
3.5 dna浓度测定
[0076]
用超微量紫外分光光度计q5000测定dna浓度及a260nm/a230nm,a260nm/a280nm等。
[0077]
实施例4质粒标准品的稀释
[0078]
4.1 mcd30-01质粒工作标准品稀释
[0079]
mcd30-01质粒工作标准品浓度为151.61ng/μl,通过如下公式换算成拷贝数:质粒拷贝数(copies/μl)=6.02
×
10
14
×
质粒浓度(ng/μl)/(质粒碱基数
×
660),换算后mcd30-01质粒工作标准品拷贝数为1.16
×
10
10
copies/μl。从-20℃冰箱中取出mcd30-01质粒工作标准品储存液,在室温下融化,待完全融化后,轻弹管底,短时间快速离心10s。mcd30-01质粒工作标准品稀释操作如下表5所示。
[0080]
表5mcd30-01质粒工作标准品配制
[0081]
管号稀释体积浓度1标准品储存液10μl+90rnase-free water1.16
×
109210μl1号管+90rnase-free water1.16
×
108310μl2号管+90rnase-free water1.16
×
107410μl3号管+90rnase-free water1.16
×
106510μl4号管+90rnase-free water1.16
×
105610μl5号管+90rnase-free water1.16
×
104710μl6号管+90rnase-free water1.16
×
103810μl7号管+90rnase-free water1.16
×
102[0082]
根据所要检测的标准曲线及待测样本数,计算所需反应孔数,做3个重复孔/样。反应孔数=(5个浓度梯度的标准曲线+1个无模板对照ntc+1个水为模板的对照neg+待测样
本)
×
3,在计算的反应孔数上多加2个反应孔数,按表6所示反应,除去模板,配制car拷贝数检测主反应混合液。
[0083]
表6拷贝数检测反应体系
[0084][0085][0086]
以25μl/孔将主反应体系分装到透明八联管中,以5μl/孔加入1.16
×
106、1.16
×
105、1.16
×
104、1.16
×
103、1.16
×
102mcd30-01质粒工作标准品和待检测样本。
[0087]
4.2β-globin质粒工作标准品稀释
[0088]
β-globin质粒工作标准品浓度为27.11ng/μl,通过如下公式换算成拷贝数:质粒拷贝数(copies/μl)=6.02
×
10
14
×
质粒浓度(ng/μl)/(质粒碱基数
×
660),换算后β-globin质粒工作标准品拷贝数为1.21
×
10
10
copies/μl。从-20℃冰箱中取出β-globin质粒工作标准品储存液,在室温下融化,待完全融化后,轻弹管底,短时间快速离心10s。β-globin质粒工作标准品稀释操作如下表7所示.
[0089]
表7β-globin质粒工作标准品配制
[0090]
管号稀释体积浓度1标准品储存液10μl+90rnase-free water1.21
×
109210μl1号管+90rnase-free water1.21
×
108310μl2号管+90rnase-free water1.21
×
107410μl3号管+90rnase-free water1.21
×
106510μl4号管+90rnase-free water1.21
×
105610μl5号管+90rnase-free water1.21
×
104710μl6号管+90rnase-free water1.21
×
103810μl7号管+90rnase-free water1.21
×
102[0091]
根据所要检测的标准曲线及待测样本数,计算所需反应孔数,做3个重复孔/样。反应孔数=(5个浓度梯度的标准曲线+1个无模板对照ntc+1个水为模板的对照neg+待测样本)
×
3,在计算的反应孔数上多加2个反应孔数,按下表6所示反应,除去模板,配制β-globin拷贝数检测主反应混合液。
[0092]
表8拷贝数检测反应体系
[0093]
反应体系添加量(μl)
aceq qpcr probe master mix15.0f primer(20μm)1.2r primer(20μm)1.2probe(20μm)0.3sample5rnase-free water7.3total30
[0094]
以25μl/孔将主反应体系分装到透明八联管中,以5μl/孔加入1.21
×
106、1.21
×
105、1.21
×
104、1.21
×
103、1.21
×
102copies/μlβ-globin质粒工作标准品和待检测样本。
[0095]
4.3 wpre质粒工作标准品稀释
[0096]
wpre质粒工作标准品浓度为111.45ng/μl,通过如下公式换算成拷贝数:质粒拷贝数(copies/μl)=6.02
×
10
14
×
质粒浓度(ng/μl)/(质粒碱基数
×
660),换算后wpre质粒工作标准品拷贝数为3.10
×
10
10
copies/μl。从-20℃冰箱中取出β-globin质粒工作标准品储存液,在室温下融化,待完全融化后,轻弹管底,短时间快速离心10s。β-globin质粒工作标准品稀释操作如下表9所示.
[0097]
表9wpre质粒工作标准品配制
[0098][0099][0100]
根据所要检测的标准曲线及待测样本数,计算所需反应孔数,做3个重复孔/样。反应孔数=(5个浓度梯度的标准曲线+1个无模板对照ntc+1个水为模板的对照neg+待测样本)
×
3,在计算的反应孔数上多加2个反应孔数,按下表10所示反应,除去模板,配制car拷贝数检测主反应混合液。
[0101]
表10拷贝数检测反应体系
[0102]
反应体系添加量(μl)aceq qpcr probe master mix15.0f primer(20μm)1.2r primer(20μm)1.2probe(20μm)0.3sample5
rnase-free water7.3total30
[0103]
以25μl/孔将主反应体系分装到透明八联管中,以5μl/孔加入3.10
×
106、3.10
×
105、3.10
×
104、3.10
×
103、3.10
×
102copies/μ lwpre质粒工作标准品和待检测样本。
[0104]
实施例5样品检测
[0105]
打开cfx connecttm real-time system荧光定量pcr仪,放入八联管。在protocol标签下创建qpcr反应程序,如表11所示。在plate标签下创建2个检测目标target,分别命名为β-globin、mcd30和wpre,选择报告荧光基团为fam。运行程序,选择保存路径,点击保存。
[0106]
表11 qpcr反应程序
[0107][0108][0109]
实施例6结果分析
[0110]
6.1 mcd30-01质粒工作标准曲线的建立
[0111]
mcd30-01质粒工作标准曲线的建立与car-t细胞gdna样本car基因拷贝数检测1.16
×
106~1.16
×
102copies/μl系列稀释mcd30-01质粒工作标准品扩增曲线呈标准s型,且间距相等。1.16
×
106copies/μl的标准品大概在22个循环的时候进入指数扩增期,此后的标准品依次延迟3-4个循环,1.16
×
102copies/μl大概在35个循环的时候进入指数扩增期。阴性对照rnase-free water和空白对照ntc的扩增曲线无抬头,扩增曲线见图4所示。标准曲线是仪器据测得的ct值自动给出的,mcd30-01质粒工作标准品在1.16
×
106~1.16
×
102copies/μl的范围内呈线性关系,相关系数r2为0.998,斜率为-3.241,扩增效率e为103.5%,标准曲线如图5。
[0112]
6.2β-globin质粒工作标准曲线的建立
[0113]
β-globin质粒工作标准曲线的建立与car-t细胞gdna样本car基因拷贝数检测1.21
×
106~1.21
×
102copies/μl系列稀释β-globin质粒工作标准品扩增曲线呈标准s型,且间距相等。1.16
×
106copies/μl的标准品大概在20个循环的时候进入指数扩增期,此后的标准品依次延迟3到4个循环,1.16
×
102copies/μl大概在34个循环的时候进入指数扩增期。阴性对照rnase-free waterneg和空白对照ntc的扩增曲线无抬头,扩增曲线见图6所示。标准曲线是仪器据测得的ct值自动给出的,β-globin质粒工作标准品在1.16
×
106~1.16
×
102copies/μl的范围内呈线性关系,相关系数r2为0.998,斜率为-3.354,扩增效率e为98.7%,标准曲线如图7。
[0114]
6.3 wpre质粒工作标准曲线的建立
[0115]
wpre质粒工作标准曲线的建立与car-t细胞gdna样本car基因拷贝数检测3.10
×
106~3.10
×
102copies/μl系列稀释wpre质粒工作标准品扩增曲线呈标准s型,且间距相等。3.10
×
106copies/μl的标准品大概在22个循环的时候进入指数扩增期,此后的标准品依次
延迟3到4个循环,1.16
×
101copies/μl大概在35个循环的时候进入指数扩增期。阴性对照rnase-free waterneg和空白对照ntc的扩增曲线无抬头,扩增曲线见图8所示。标准曲线是仪器据测得的ct值自动给出的,wpre质粒工作标准品在3.10
×
106~3.10
×
102copies/μl的范围内呈线性关系,相关系数r2为0.999,斜率为-3.406,扩增效率e为96.6%,标准曲线如图9。
[0116]
以上mcd30-01质粒工作标准曲线、β-globin质粒工作标准曲线和wpre质粒工作标准曲线的验证,证明三种质粒工作标准曲线都能够稳定正常的扩增,对应的引物及探针也分别能够有效特异地识别目的基因。
[0117]
实施例7临床car t细胞样本的检测
[0118]
按照上述实验方法对同一样本进行car基因的检测,通过三种质粒工作标准曲线,推算出平均每个car t细胞内慢病毒拷贝数的数量。yzc0103202203002-02为cart细胞样本,tzc0103202203002-01为t细胞样本。三种质粒工作标准曲线分别如表12、表13、表14所示,car t细胞样本(yzc0103202203002-02)的基因检测数据分别如表15、表16、表17所示;car t细胞样本yzc0103202203002-02和t细胞样本tzc0103202203002-01的最终分析结果如表18所示。结果显示使用β-globin与cd30 scfv作为特异性的引物组合检测cart细胞的慢病毒载体拷贝数的数据为0.79copys/cell,而对应的对照t细胞则是0copys/cell,结果说明该检测组合的能够有效且特异检测car基因的表达;使用wpre与cd30 scfv作为特异性的引物组合检测car t细胞的慢病毒载体拷贝数的数据为0.82copys/cell,而对应的对照t细胞则是0copys/cell,结果说明该检测组合的能够有效且特异检测car基因的表达。更重要的是,两种检测方法的结果几乎一致,说明该检测方法的可行性。
[0119]
表12β-globin质粒工作标准品检测数据以及标准曲线
[0120][0121]
表13 mcd30-01质粒工作标准品检测数据以及标准曲线
[0122][0123]
表14 wpre质粒工作标准品检测数据以及标准曲线
[0124][0125]
表15样品β-globin基因检测数据
[0126][0127]
表16样品car基因检测数据
[0128][0129]
表17样品wpre基因检测数据
[0130][0131]
表18结果分析
[0132][0133]
综上所述,本发明针对car-t细胞质量控制的需要,分析常用的慢病毒载体序列,β-globin、cd30 scfv的引物组合和wpre、cd30 scfv的引物组合分别针对特异性和通用型的引物而开发设计,均可有效应用于单个细胞的慢病毒载体拷贝数的检测。利用数字pcr技术配合此引物和探针可对car-t细胞基因组中病毒载体拷贝数准确定量,为car-t细胞治疗产品的有效性和安全性提供保障。
[0134]
以上所述仅为本发明的较佳实施方式而已,并不用以限制本发明,凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1