鉴定小麦单倍型和/或千粒重性状的分子标记组合、引物对、试剂盒及其应用
1.本发明属于基因工程领域,具体涉及鉴定小麦单倍型和/或千粒重性状的分子标记组合、引物对、试剂盒及其应用。
背景技术:
2.小麦(triticum aestivum l.)是一种重要的粮食作物,为人类提供的食物热量约占卡路里消耗量的20%。小麦的籽粒产量取决于每亩面积的穗数、每穗粒数和粒重。当单位面积穗数和每穗粒数达到最佳水平时,增加粒重对于进一步提高小麦的产量至关重要。
3.淀粉是小麦籽粒的主要成分,约占小麦籽粒干重的75%左右。淀粉合成是一个复杂的过程,由六大类功能酶催化合成:agp-葡萄糖焦磷酸化酶(agpase)、颗粒结合淀粉合成酶(gbss)、淀粉合成酶(ss)、淀粉分支酶(be)、淀粉脱支酶(dbe)和淀粉磷酸化酶(pho)。agpase是淀粉生物合成过程中重要的酶,它催化葡萄糖-1-磷酸(g-1-p)转化为二磷酸腺苷(adp-glc)。直链淀粉主要由gbss合成,而支链淀粉的合成则由agpase、ss、be和dbe协同作用。pho被认为作用于颗粒表面,在磷酸化过程中发挥重要作用。
4.在高等植物中,agpase是一种异源四聚体酶,由两个较大的调节亚基(agpl)和两个较小的催化亚基(agps)组成,由taagps1a、taagps1b、taagps2、taagpl1和taagpl2所编码。在大多数双子叶植物的细胞中,agpase仅在质体中有活性,但它主要存在于禾本科作物谷粒胚乳中的细胞质内,如在大麦、水稻和玉米中分别占总agp酶活性的85%,90%和95%,表明胞质型agpase在这些作物的淀粉合成中起着至关重要的作用。
5.转录因子通过与靶基因上游的顺式作用元件特异性结合,来调控下游基因的表达,从而调控谷类作物生长发育和逆境胁迫应答。在小麦中,现有研究主要集中在编码淀粉合成相关酶基因的表达模式,而对调控淀粉合成相关酶基因表达的上游转录因子却研究较少。目前,研究人员通过分析淀粉合成基因taagpl1启动子上游的顺式作用元件,并利用酵母单杂交技术筛选到一个转录因子tabhlh39。基于转录因子tabhlh39开发功能标记,进行单倍型分析,并与千粒重性状进行关联分析寻找优异的单倍型,对于提高小麦千粒重、获得高产小麦新品种具有极其重要的意义。
技术实现要素:
6.本发明的目的在于提供鉴定小麦单倍型和/或千粒重性状的分子标记组合、引物对、试剂盒及其应用,检测小麦tabhlh39-5b基因优异等位变异,筛选和鉴定小麦单倍型和小麦千粒重性状,提高高千粒重小麦种质的选育效率。
7.本发明提供了鉴定小麦单倍型和/或千粒重性状的分子标记,所述小麦单倍型为hap1单倍型、hap2单倍型和hap3单倍型;
8.所述分子标记包括第一indel分子标记、第二indel分子标记、第一snp分子标记和第二snp分子标记;所述第一indel分子标记位于小麦tabhlh39-5b基因启动子区第-1212bp
处,存在核苷酸序列如seq id no.1所示的12bp碱基缺失;所述第二indel分子标记位于小麦tabhlh39-5b基因启动子区第-1489bp处,存在核苷酸序列如seq id no.2所示的275bp碱基缺失;所述第一snp分子标记位于小麦tabhlh39-5b基因启动子区第-1807bp处,存在g/-多态性;所述第二snp分子标记位于小麦tabhlh39-5b基因启动子区第-1805bp处,存在c/t多态性。
9.优选的,所述tabhlh39-5b基因启动子区的核苷酸序列如seq id no.3所示;所述tabhlh39-5b基因启动子区位于第-2067bp~-1bp。
10.本发明还提供了一种鉴定上述方案所述的分子标记组合的引物对,包括序列为seq id no.4所示的上游引物caps-f和序列为seq id no.5所示的下游引物caps-r。
11.本发明还提供了一种鉴定上述方案所述的分子标记组合的试剂盒,包括上述方案所述的引物对。
12.本发明还提供了一种鉴定小麦单倍型的方法,包括如下步骤:
13.利用上述方案所述的引物对对待测材料的基因组dna进行pcr扩增,得pcr扩增产物;
14.用限制性内切酶apa i对所述pcr扩增产物进行酶切,得到酶切产物;
15.当所述酶切产物为单一的1780bp的条带,待测材料为hap3单倍型小麦材料;
16.当所述酶切产物包括1879bp和188bp的两个短片段时,待测材料为hap1单倍型小麦材料;
17.当所述酶切产物包括1591bp和188bp的两个短片段时,待测材料为hap2单倍型小麦材料。
18.优选的,所述pcr扩增使用的反应体系以50μl计包括:待测材料的基因组dna 200ng,10μm上游引物caps-f 0.3μl,10μm下游引物caps-r 0.3μl,2
×
kod onetm pcr master mix 25μl和余量的ddh2o;
19.所述pcr扩增反应的程序为:第一阶段94℃预变性3min;第二阶段98℃变性10s,59℃退火30s,68℃延伸3min,32个循环;第三阶段:68℃终延伸5min。
20.本发明还提供了上述方案所述的分子标记组合或所述的引物对或所述的试剂盒或所述的方法在小麦育种中的应用。
21.优选的,所述应用中选取hap2单倍型小麦材料用于育种。
22.本发明还提供了上述方案所述的分子标记组合或所述的引物对或所述的试剂盒或所述的方法在筛选高千粒重小麦中的应用。
23.本发明还提供了一种分子标记辅助选育高千粒重小麦的方法,利用上述方案所述引物对对目标小麦进行分子标记,筛选hap2单倍型小麦材料。
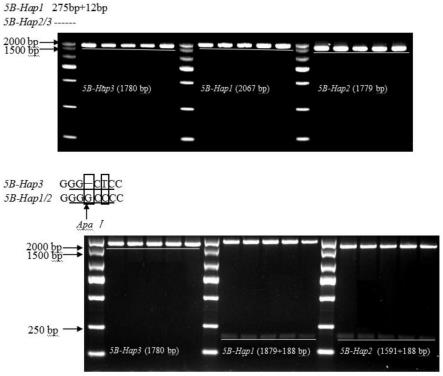
24.本发明提供了鉴定小麦单倍型和/或千粒重性状的分子标记,所述小麦单倍型为hap1单倍型、hap2单倍型和hap3单倍型;所述分子标记包括第一indel分子标记、第二indel分子标记、第一snp分子标记和第二snp分子标记;所述第一indel分子标记位于小麦tabhlh39-5b基因启动子区第-1212bp处,存在核苷酸序列如seq id no.1所示的12bp碱基缺失;所述第二indel分子标记位于小麦tabhlh39-5b基因启动子区第-1489bp处,存在核苷酸序列如seq id no.2所示的275bp碱基缺失;所述第一snp分子标记位于小麦tabhlh39-5b基因启动子区第-1807bp处,存在g/-多态性,其中-表示缺失突变;所述第二snp分子标记位
于小麦tabhlh39-5b基因启动子区第-1805bp处,存在c/t多态性。
25.hap2单倍型和hap3单倍型相较于hap1单倍型包含2个indel:-1212bp含有12bp碱基缺失,如seq id no.1所示;-1489bp含有275bp碱基缺失,命名为大片段1,如seq id no.2所示。因此,indel-1489/-1212可用于区分hap1单倍型与hap2单倍型/hap3单倍型;caps 1807/1805区别hap3单倍型与hap1/hap2单倍型。hap1单倍型和hap2单倍型之间存在两个snp标记:小麦tabhlh39-5b基因启动子区第-1807bp处存在g/-多态性,第-1805bp处存在c/t多态性,即两个位点位于序列(gggccc),gggccc可以被限制性内切酶apa i识别并切开,gg-ctc不能被切开,即hap1单倍型和hap 2单倍型位于序列gggccc内,可被限制性内切酶apa i识别并切开,而hap3单倍型则不能被切开。
26.利用本发明所述分子标记能将hap1单倍型、hap2单倍型和hap3单倍型小麦区分开,并且,hap2单倍型小麦品种的平均千粒重显著高于hap1和hap3单倍型,hap2为高千粒重优异单倍型。据此,本发明可进一步将高千粒重小麦和低千粒重的小麦区分开。
27.本发明采用casp分子标记引物对检测小麦中与单倍型和千粒重相关的tabhlh39-5b基因的等位变异,只需通过简单的dna提取、pcr特异性扩增、酶解检测即可完成对样品的鉴别,便于鉴定小麦单倍型以及检测和筛选具有高千粒重的小麦品种或品系,可大大加快小麦高产品种的选育进程。
附图说明
28.为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例中所需要使用的附图作简单地介绍。
29.图1为tabhlh39-5b编码区与启动子的pcr扩增结果,其中(a)为tabhlh39-5b启动子的pcr扩增结果,(b)为tabhlh39-5b编码区片段的pcr扩增结果;
30.图2为tabhlh39-5b启动子与编码区序列在普通六倍体小麦中的变异位点与形成的三种单倍型(hap1-3);
31.图3为tabhlh39-5b在两种单倍型小麦材料中的thousand kernel weight(tkw)分析;
32.图4为tabhlh39-5b启动子单倍型cleaved amplified polymorphic sequences(caps)分子标记的开发;
33.图5为异源六倍体(bbaadd)小麦材料中tabhlh39-5b启动子序列的比对结果;
34.图6为异源六倍体(bbaadd)小麦材料中tabhlh39-5b基因组编码区域序列在的比对结果。
具体实施方式
35.本发明提供了鉴定小麦单倍型和/或千粒重性状的分子标记,所述小麦单倍型为hap1单倍型、hap2单倍型和hap3单倍型;
36.所述分子标记包括第一indel分子标记、第二indel分子标记、第一snp分子标记和第二snp分子标记;所述第一indel分子标记位于小麦tabhlh39-5b基因启动子区第-1212bp处,存在核苷酸序列如seq id no.1所示的12bp碱基缺失;所述第二indel分子标记位于小麦tabhlh39-5b基因启动子区第-1489bp处,存在核苷酸序列如seq id no.2所示的275bp碱
基缺失;所述第一snp分子标记位于小麦tabhlh39-5b基因启动子区第-1807bp处,存在g/-多态性;所述第二snp分子标记位于小麦tabhlh39-5b基因启动子区第-1805bp处,存在c/t多态性。
37.在本发明中,seq id no.1所示的12bp碱基缺失的核苷酸序列具体为:cccctctcccct。
38.在本发明中,seq id no.2所示的275bp碱基缺失的核苷酸序列具体为:
39.ctggtcacaatgggcaagaacataagctagtaacttcacacatccctagactatgttactacctccatagtgggtaggaacatctatgtagtgtcatgcaatgatgtatttattaggttatagactcattgtttcttggaatgtgtgatgttccggtaacttagctagttaccacaagcacctctctcttcattaaatacgtgccacataagcaaagttgtattgaagtgtgtgatgttactcctaagttcctccccactgtgaccagccttagg。
40.在本发明中,所述tabhlh39-5b基因启动子区的核苷酸序列如seq id no.3所示;所述tabhlh39-5b基因启动子区位于第-2067bp~-1bp。
41.在本发明中,seq id no.3所示的核苷酸序列具体为:
42.gcccccaagtaatacccaatataaaactgtcacgtctgattttacgtaaggtacgcaaagatatttacttaggtgtagctttactcttatcgaaccgagcaatgctacacctacgtagcaatctatacctaattaacgtaacagcttacgtggccttttttggttagaggaaatcaggggagggggccccacccgttgaaatcagggggcggtgaaaggattagttaggctggtcacaatgggcaagaacataagctagtaacttcacacatccctagactatgttactacctccatagtgggtaggaacatctatgtagtgtcatgcaatgatgtatttattaggttatagactcattgtttcttggaatgtgtgatgttccggtaacttagctagttaccacaagcacctctctcttcattaaatacgtgccacataagcaaagttgtattgaagtgtgtgatgttactcctaagttcctccccactgtgaccagccttagggaggtttcgtaagattacgtaggcttttacgtaggtgtagcatttttatattgaacccacctcatgattgcagcccgtggccgtcatacagcgcgatacgcgcggcagggttttacccctcccctcgaaatggcaaaagccggcgggacacagaaaacggcatacatgcatgcacgcgcccttccctatgcagcagcaagcaggcgcaaggtgtactcacgcgtctgctctccaatcattcgcccgtccctccgggacccctcccctctcccctccctccgtctctctcctcctcctcctccacatccctctctccccttcttctatccctttctccctcccccgtctctgtccgcgggaatccacttctcttcagcccacagccacaatgttgcgcggctgcttaaaagccactgcgggtgccaagcacaggttcccccgctacccgcccgctcttctccttcctccccctcactagcctctcctccctccaagccaagaagagagccgcggcccgctgactgagcatcctcccggagaagcttccttagccggtgctggatcttgcagccagactggttagttcttgttcttccatggctgctggctcagttcccccctctgctttctcattacggttctccaaaatccgcgtccctaatgcgtgttttccagtctcttctgaaacctgatgtggatttcaccatatccactggtcttaacggcataatcctagtttttatactgcttgtaaagcttccaggtctttgtaaatcacttttctgaacctcttcgcttttcctataaaatactacctcttctcagcatcttaacagaaaaataaaatatattttaaaatgatactctattgctagtgctctgtagacttgattgatgagtggattaaaagaacgaataaacaaatcccttttgtgaagccttttcactgtgttagctggttgctagctgctcctctgcatgtgctgcaggcaggtttacatgaccggtaggtttcctgcaggcaggctccccgtactgcatctacctttccttttttttcccatcattggcctccctgttcctcacactgcatagcccagctgctttttttatacatatttttggcaattttatatctgagatttcctttgctaccagaagttcttttttttttttagaactatcggaggttcaaaacattattatttccatagttggttctgtctggcatcgcacatgccctgcttgcttcatatgtagccaaatcaggctatgctgcaggatccttggcaagaggcacatttttctatcgagcagtctcttctcgttgccaatcaaatttaaaataccatgccgcatgcacatgaagcaaggtttctcagctgatttcgttgtttgattcttgccatctcctctgtttgcttcggcatgcagcgtgcactctgcggtgaagtgaatcgccgg
tcgatgcttgtgatgatctgagccatgagccaattcgtgccagattggggaaacatgggcgacatctccaggccactcgggtttgctcttgaatcttga。
43.本发明所述tabhlh39-5b基因编码区序列在小麦基因组基因库(http://plants.ensembl.org/triticum_aestivum/info/index)中的登录号为traescs5b02g380200,所述tabhlh39-5b基因编码区cds序列如seq id no.6所示,具体为:
44.atgagccaattcgtgccagattggggaaacatgggcgacatctccaggccactcgggtttgctcttgaatcttgatcgcttgatgcaatggagtttgtggtgtcatatctgcgttacaggctagtactggttactgacctttttgtgcttaatttcgtggctgcagggaagacgatgacctcatggagctgctgtggtgcaacggcaatgtcgtcatgcagagccagggtcatcggaagctgccgccgaggcctgagaaggttccggcgccgccggtggtgcaagaagacgaggccggcctgtggttcccgttcgccctcgctgactcgctcgacaaggacatcttccaggacctcttctgcgaagaaccaccgggggcggccggcgtcgacggctccagcaggcagcaatcgatgagcctggccgactgcggcgacaacgccggcggcttccagtcagacctcgtccaggctcgcgccgggaaggcagcgatggaggagggcgcgtcgtcgacgctgagcgcgatgggggcgagcttctgcgggagcaaccaggtgcaggtgcagggcgcggtgagcgaccacgggcgcgccggccacgccactgcctatggcgacggcggagcgggcagcgctctgccctcggcggtggggagcgtaaatgcaaacgccagaggcaggggccacgaggccaccgtggcctcctcgtcggggcggtccaactacagcttcggcgtcaccgccactaccaccaccaccaccggcaccgagccgacgagcacgagcaaccggagcagcaagagcaagcgggggctcgacacggaggactcggagagccccagcgaggacgccgagtcagagtccttggtgctggagcgcaagccgccccagaagctcacgacggcgcggaggagccgcgccgccgaggtgcacaacctctccgagagggtgcgttgcgtcattaatttcttcttgtgcgatcaatggtcaattgttcattccgatcaaaaaaaaaatggtcaattgttcattacaacatctctggcgctgactctggcggttgcagaggagacgagacaggatcaacgagaagatgcgagccctgcaagagctcataccccactgcaacaaggtgaccaaatttctttgctcgatcagccaacgtacgtaccagtttagttttactgattaatctgctcgatttgtgggttttgtgatgggcggcatgcagactgacaaggcgtcgatgctggacgaggcgatcgagtacctgaagacgctgcagatgcaggtgcagatgatgtggatgggcagcggcatggcgccgccggcggtgatgttcccgggcatgcagatgcaccagtacctgccgcagatgggcccgtccatggcgcggatgcccttcatggcgccgccgcagcagggccacggcgtgagcctgccggagcagtacgcgcacttcctcggcgtcaacccccaccaccacctgcagccgccggcccaccaccaccaggttccgtccgtccgcccggcaaccgccaaaaccgtatccatttccaacgcccccgccgtcttttccaccctccctaacacgtaagatggacgtttcttccggcagcatttcgcgcaggggctgggctactacccgctaggggcgaaggccctgcagcaaagtccggcgctccaccacgtgtccaatggcaacgccggcggtggcacgcctgccgctaccgccaacgccacgccggggaacgcgatacacccaaacaaaagatga。
45.本发明还提供了一种鉴定上述方案所述的分子标记组合的引物对,包括序列为seq id no.4所示的上游引物caps-f和序列为seq id no.5所示的下游引物caps-r。
46.在本发明中,seq id no.4所示的上游引物caps-f的核苷酸序列具体为:gcccccaagtaatacccaat,seq id no.5所示的下游引物caps-r的核苷酸序列具体为:tcaagattcaagagcaaacc。利用本发明所述引物对能够检测小麦中与单倍型和千粒重相关的tabhlh39-5b基因的等位变异,检测和筛选具有高千粒重的小麦品种或品系,可大大加快小麦高产品种的选育进程。
47.本发明还提供了一种鉴定上述方案所述的分子标记组合的试剂盒,包括上述方案所述的引物对。在本发明中,所述试剂盒优选的还包括pcr扩增用试剂和酶切用试剂;所述酶切用试剂优选的包括限制性内切酶apa i。在本发明中,所述限制性内切酶apa i优选的
购自于大连宝生物公司。
48.本发明还提供了一种鉴定小麦单倍型的方法,包括如下步骤:
49.利用上述方案所述的引物对对待测材料的基因组dna进行pcr扩增,得pcr扩增产物;
50.用限制性内切酶apa i对所述pcr扩增产物进行酶切,得到酶切产物;
51.当所述酶切产物为单一的1780bp的条带,待测材料为hap3单倍型小麦材料;当所述酶切产物包括1879bp和188bp的两个短片段时,待测材料为hap1单倍型小麦材料;当所述酶切产物包括1591bp和188bp的两个短片段时,待测材料为hap2单倍型小麦材料。
52.本发明首先提取待测材料的基因组dna。本发明所述待测材料优选为小麦。本发明对所述小麦的种类没有特殊要求,任何种类的小麦均可。本发明对所述待测小麦基因组dna提取的方法没有特殊限定,采用本领域常规的植物细胞基因组提取方法即可。在本发明具体实施过程中,以待测小麦叶片或其他组织为材料,利用ctab法进行提取。本发明所述ctab法按照常规方法进行。
53.得到待测材料的基因组dna后,本发明以待测材料的基因组dna为模板,利用上述方案所述的引物对对待测材料的基因组dna进行pcr扩增,得pcr扩增产物。
54.在本发明中,所述pcr扩增使用的反应体系以50μl计,优选的包括:待测材料的基因组dna200 ng,10μm上游引物caps-f 0.3μl,10μm下游引物caps-r 0.3μl,2
×
kod onetm pcr master mix 25μl和余量的ddh2o;所述kod onetm pcr master mix购买自东洋纺生物公司。本发明所述小麦基因组dna的浓度优选为100~200ng/μl;所述基因组dna的od
260
/od
280
比值优选为0.6~0.8;所述pcr扩增反应的程序为:第一阶段94℃预变性3min;第二阶段98℃变性10s,59℃退火30s,68℃延伸3min,32个循环;第三阶段:68℃终延伸5min。
55.本发明在所述pcr扩增完成后,优选的将pcr扩增产物保存于4℃。本发明以不同单倍型小麦品种dna为模板,利用所述引物对,扩增不同单倍型小麦中的tabhlh39-5b基因启动子区片段(-2067bp~-1bp),均能获得单一扩增条带,其中hap1单倍体扩增片段的长度为2067bp,hap 2单倍体扩增片段的长度为1779bp,hap 3单倍体扩增片段的长度为1780bp。
56.得pcr扩增产物后,对其扩增产物进行回收,并测定浓度。本发明用限制性内切酶apa i对所述pcr扩增产物进行酶切,得到酶切产物;得到酶切产物后,本发明检测酶切产物的多态性,根据检测结果判断小麦中tabhlh39-5b基因的等位变异类型。本发明所述检测优选采用琼脂糖凝胶电泳进行分析。当所述酶切产物为单一的1780bp的条带,待测材料为hap3单倍型小麦材料;当所述酶切产物包括1879bp和188bp的两个短片段时,待测材料为hap1单倍型小麦材料;当所述酶切产物包括1591bp和188bp的两个短片段时,待测材料为hap2单倍型小麦材料。
57.在本发明中,所述酶切使用的反应体系以10μl计,优选的包括:pcr扩增产物300ng、apai 0.5μl、buffer 1μl、bsa1μl,补ddh2o至10μl。
58.本发明还提供了上述方案所述的分子标记组合或所述的引物对或所述的试剂盒或所述的方法在小麦育种中的应用;在本发明中,所述应用中选取hap2单倍型小麦材料用于育种。
59.本发明还提供了上述方案所述的分子标记组合或所述的引物对或所述的试剂盒或所述的方法在筛选高千粒重小麦中的应用。
60.本发明还提供了一种分子标记辅助选育高千粒重小麦的方法,利用上述方案所述引物对对目标小麦进行分子标记,筛选hap2单倍型小麦材料进行后续筛选。
61.为了进一步说明本发明,下面结合附图和实施例对本发明提供的技术方案进行详细地描述,但不能将它们理解为对本发明保护范围的限定。
62.实施例1
63.1.材料
64.本实施例选用252份普通小麦品种、详细信息见表1。用于pcr扩增的高保真pcr酶kod onetm pcr master mix购自于东洋纺生物公司,平末端克隆载体zt4-blunt购自于庄盟生物公司,apa i限制性内切酶购自于大连宝生物公司,其他药品为国产分析纯。
65.表1 本实施例所用六倍体小麦品种
66.67.68.69.70.71.72.73.[0074][0075]
2.引物设计
[0076]
首先根据tabhlh39基因的三拷5a、5b、5d在小麦基因组数据库中的序列差异,设计5b特异的启动子扩增引物(tabhlh39-5b-promoter-sf:gcccccaagtaatacccaat,如seq id no.4所示/sr:tcaagattcaagagcaaacc,如seq id no.5所示)和编码区扩增引物tabhlh39-5b-cds-sf:tttcgttgtttgattcttgc,如seq id no.7所示/sr:gctgcgacctttcatttc,如seq id no.8所示)。引物合成与测序由河南尚亚生物技术公司完成。
[0077]
3.小麦基因组dna的提取
[0078]
采用ctab法提取小麦总dna。首先将小麦叶片或其他组织液氮速冻研磨,加入1ml预热的ctab抽提液,65℃水浴1h。常温,12000g离心10min后,取上清并加入等体积的氯仿:异戊醇(24:1)混合液振荡。12000g离心10min,将上清转移至新管,加入2倍体积无水乙醇混匀,-20℃静置30min。再离心去上清,用75%乙醇洗涤两遍,晾干后,加入100μl无菌水溶解dna。
[0079]
4.taagpl1-1b基因启动子及编码区的扩增与测序
[0080]
使用高保真pcr酶kod onetm pcr master mix扩增目的片段。利用tabhlh39-5b-promoter-sf/sr,tabhlh39-5b-cds-sf/sr这两对引物,以199个六倍体小麦dna为模板来扩增tabhlh39-5b的启动子与编码域序列。pcr体系中包含:25μl 2
×
kod onetm pcr master mix,10μm上下游引物各0.3μl,200ng dna模板,补充ddh2o至总体积50μl。pcr反应程序为:
第一步,94℃3min;第二步,98℃10s,59℃30s,68℃3min,32个循环;第三步,68℃5min。扩增结果如图1所示,tabhlh39-5b的启动子扩增片段为2067bp,编码区扩增片段为2183bp。分别回收199个品种的pcr扩增目的片段,并与zt4-blunt克隆载体连接,转化大肠杆菌,挑取三个以上阳性克隆,用通用引物t7-f/r测序。
[0081]
5.taagpl1-1b基因启动子与编码区的序列比对与单倍型分析
[0082]
使用dnaman软件(http://www.lynnon.com)对测序结果进行拼接并进行序列比对。异源六倍体(bbaadd)小麦材料中tabhlh39-5b启动子序列的比对结果如图5;异源六倍体(bbaadd)小麦材料中tabhlh39-5b基因组编码区域序列在的比对结果参见图6。序列比对结果发现在252个小麦品种中的tabhlh39-5b编码区中(1~1776bp)存在3个snp(110bp t/g,752bpa/c,1165bpa/g),其中1个snp(752bpa/c)位于外显子上,但不会引起编码氨基酸的改变,属于无义突变位点。在启动子区域(-2067bp~-1bp)存在10个snp多态性变异位点,通过dnasp 5.10软件(http://www.ub.edu/dnasp)对启动子进行单倍型鉴定,结果发现这13个snp紧密连锁形成三种单倍型,分别命名为tabhlh39-5b-hap1、tabhlh39-5b-hap2、tabhlh39-5b-hap3(图2)。
[0083]
6.不同单倍型小麦品种在六倍体小麦中的千粒重分析
[0084]
不同单倍型小麦品种在六倍体小麦中的千粒重,详细信息见附表1,通过分析(表2)结果如图3所示,在hap2单倍型小麦品种的平均千粒重显著高于hap1和hap3单倍型,可表明hap2为高千粒重优异单倍型。
[0085]
表2 六倍体小麦tabhlh39-5b单倍型千粒重
[0086][0087]
注:表2中a、b表示**(差异显著)。
[0088]
7.caps分子标记开发
[0089]
由于tabhlh39-5b三种单倍型的差异是单碱基的差异(snp)与插入缺失的差异(indel),根据这些差异可以开发酶切扩增多态性(caps)分子标记。首先根据插入缺失的差异(indel)对tabhlh39-5b三种单倍型序列差异进行分析,hap2/hap 3相较于hap1其中包含2个indel:-1212bp含有12bp碱基缺失,如seq id no.1所示;-1489bp含有275bp碱基缺失,命名为大片段1,如seq id no.2所示。因此,indel-1489/-1212可用于区分hap1与hap 2/hap 3。
[0090]
利用dcaps finder 2.0http://helix.wustl.edu/dcaps/dcaps.html)对tabhlh39-5b三种单倍型序列差异进行分析,hap1/hap 2其中两个snp:-1807bp(g/-)和-1805bp(c/t)即两个位点位于序列(gggccc),gggccc可以被限制性内切酶apa i识别并切开,gg-ctc不能被切开,即hap1与hap2位于序列gggccc内,可被限制性内切酶apa i识别并切开,而hap 3则不能被切开。基于此处序列差异开发分子标记,命名为caps-1807/-1805。以不同单倍型小麦品种dna为模板,扩增不同单倍型小麦中的tabhlh39-5b片段(-2067bp
~-1bp),均能获得单一扩增条带,其中hap 1(2067bp),hap 2(1779bp),hap 3(1780bp)。使用购自于大连宝生物公司的apa i限制性内切酶对纯化的pcr产物进行酶切,酶切使用的反应体系以10μl计包括:pcr扩增产物300ng,apa i 0.5μl,buffer 1μl、bsa1μl,补ddh2o至10μl。电泳检测结果发现hap3单倍型小麦品种扩增产物经酶切后仍为单一的1780bp的条带,而hap1单倍型材料的扩增产物经酶切后则变为两个片段,分别为1879bp和188bp,hap2单倍型材料的扩增产物经酶切后则变为两个片段,分别为1591bp和188bp。因此,caps
ꢀ‑
1807/-1805分子标记能够区分hap3与hap 1/hap 2,可应用于高千粒重小麦新品种的分子设计育种。
[0091]
尽管上述实施例对本发明做出了详尽的描述,但它仅仅是本发明一部分实施例,而不是全部实施例,人们还可以根据本实施例在不经创造性前提下获得其他实施例,这些实施例都属于本发明保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1