用于肽生产的组合物和方法与流程
用于肽生产的组合物和方法
1.公开内容的领域
2.本公开内容总体上涉及用于改进重组多肽产生的系统、组合物和方法。在特定实施方案中,包含编码包含多于一个连接肽的多肽的开放阅读框的构建体可用于简化或减少产生纯化肽所需的步骤数量,和/或增加纯化肽产物的产量。因此,本发明涉及包含上述构建体的核酸分子、包含所述核酸分子的细胞、包含所述核酸分子和/或细胞的系统和生产设备,以及包含和/或使用任何和所有前述内容的重组肽生产方法。
3.背景
4.纯化肽在许多应用中是有用的;例如,在诊断应用中,作为治疗剂,作为食物成分/添加剂,以及作为病原体抑制剂。短和中等大小的肽通常通过化学合成方法产生。然而,这些方法仅对于最短的肽是最经济的,并且翻译后修饰在化学合成期间不容易实现。此外,化学合成需要使用极其危险的化学品。
5.重组dna技术为化学合成提供了次优的替代品,尽管在某些情况下它是优选的。重组方法使用细胞的内源性蛋白质产生机构来生产异源肽。重组肽合成需要许多复杂的生化过程,包括转录、翻译、蛋白质折叠和翻译后修饰(例如,糖基化和二硫键形成),这些过程通常由酶催化。使用这些内源性过程生产重组肽的技术仍然具有挑战性,例如,由于它们在不同细胞中对相同前体多肽的不同操作。
6.此外,常规重组肽生产可获得的产率不足够高以与化学合成方法竞争大多数中等大小肽的合成。生产含有期望肽的串联重复序列的多肽是设计为解决这些问题的一种策略,尤其是为了提高产量。然而,使用化学物质或蛋白酶将肽从翻译的多肽上裂解下来的现有裂解策略在最终的肽产物中留下了额外的氨基酸。这些额外的氨基酸具有许多显著的缺点,这些缺点阻碍了肽的预期用途;例如,额外的氨基酸可能通过引发免疫原性响应而为医学应用带来问题,并且额外的氨基酸还可能干扰肽的生理功能。因此,需要昂贵的临床试验来验证它们在医学应用中的用途,即使不含额外氨基酸的肽的使用已经被批准。
7.使用串联重复序列增加肽生产产量的另外的障碍是嵌合蛋白必须被设计成使得裂解位点都可被裂解剂接近,否则将无法实现肽产量的预期增加。
8.已经提出了几种解决方案来解决达到重组肽生产技术的全部前景的一些前述障碍,但是没有一种解决方案足以提供通常可用于以高产量、成本有效且环境友好的方式、独立于肽长度且不形成包涵体地产生基本上所有具有精确预期序列的期望肽的生产平台。
9.美国专利第6,051,399号描述了通过在接头肽的氨基末端引入异源半胱氨酸和在羧基末端引入甲硫氨酸,从串联重复序列生产重组c-末端酰胺化肽的方法。这要求得到的肽不含游离半胱氨酸或甲硫氨酸。当这些氨基酸中的任何一种存在于期望的肽中时,不可能产生肽的精确序列。例如,当接头序列的c-末端以半胱氨酸结束时,肽的n-末端在裂解反应期间被亚氨基噻唑烷-羧基基团修饰。或者,当接头肽以甲硫氨酸开始时,则高丝氨酸内酯被引入肽中。这些修饰干扰了肽的许多应用,并且因此这些方法不适合可适用于任何肽生产的一般生产系统。此外,串联重复序列的设计应使得裂解序列易于被化学剂和蛋白酶接近。否则,需要串联重复序列的变性以暴露裂解位点。这可能是有问题的,特别是对于串
联重复序列的酶促裂解,因为酶本身在存在变性剂的情况下变性。
10.公开内容的概述
11.本公开内容描述了以增加产量的另外益处生产具有精确预期靶序列的重组产物肽的问题的解决方案,并且通过采用环境友好的试剂和方法以及通过消除方法步骤来限制所需的资源。因此,本公开内容提供了包含连接肽的构建体、系统和多肽,其在实施方案中用于有效地产生适用于许多应用(从营养到人类或动物的医疗和药物用途)的广泛的产物肽。
12.在实施方案中,酶催化的蛋白水解单独使用或与化学蛋白水解组合使用,以将包含多于一个肽重复序列的重组多肽裂解成由期望的靶氨基酸序列组成的产物肽。在特定的实施方案中,重组多肽可溶于水性环境;例如细胞(例如,细菌细胞诸如大肠杆菌(e.coli))的胞质溶胶。因此,本文的实施方案包括本文描述的含肽重复序列的多肽、编码这样的多肽的核酸、包含这样的构建体和/或多肽的宿主细胞和重组生产平台,以及使用前述生产由靶氨基酸序列组成的产物肽的方法。
13.因此,一些实施方案包括重组多肽(例如,翻译产物多肽),其包含多于一个具有靶序列的产物肽,还包含每个产物肽之间的至少一个中间“接头序列”,其中接头序列包含第一蛋白水解反应中蛋白酶的裂解位点,以产生中间肽,该中间肽随后被酶促或化学加工成由靶序列组成的产物肽。实例包括,其中产物肽具有相同的靶氨基酸序列的多肽,其中多肽包含两个具有不同靶氨基酸序列的产物肽的实例,以及其中多肽包含多于两个具有不同靶氨基酸序列的产物肽的实例。
14.在特定方面,多于一个中间肽和中间接头序列包含至少一个包含识别两或四个连续的碱性氨基酸的蛋白酶裂解位点(p.c.s.)的接头序列(例如,多于一个或所有接头序列)。用这样的蛋白酶蛋白水解多肽产生中间肽,所述中间肽包含产物肽的靶氨基酸序列羧基末端的碱性氨基酸。在本文的实例中,羧肽酶对中间肽的蛋白水解消除了剩余的额外碱性残基,产生由靶氨基酸序列组成的产物肽。
15.在特定方面,在接头序列中使用小氨基酸,尤其是甘氨酸,结合使用识别大量带电氨基酸的蛋白酶,可以确保裂解位点暴露于裂解试剂。
16.在特定方面,多于一个中间肽和中间接头序列包括至少一个接头序列(例如,多于一个或所有接头序列),所述接头序列包含氨基末端化学裂解序列(c.c.s.)和在p1’位置不留下无关(extraneous)氨基酸的蛋白酶裂解位点。在本文的实例中,用这样的蛋白酶蛋白水解多肽产生包含氨基末端c.c.s.的中间肽。在本文的实例中,中间肽的化学蛋白水解产生由靶氨基酸序列组成的产物肽。
17.在一些实施方案中,用一种或更多种逆转录病毒蛋白酶蛋白水解多肽可以单独使用或与一种或更多种另外蛋白酶组合使用。被逆转录病毒蛋白酶蛋白水解可以发生在分别在p1和p1’位置处具有芳香族残基和脯氨酸的1型裂解位点,或者在p1位置处具有疏水残基的2型裂解位点。依赖于固着键(sessile bond)的c-末端侧进行底物识别的逆转录病毒蛋白酶可以与在p1’位置处不留下氨基酸的其他蛋白酶组合用于多肽。
18.在实例中,重组多肽还包含至少一个肽单元,其不形成中间肽产物或接头序列的一部分;例如,在多肽的n-末端,或在多肽的c-末端。在某些实施方案中,多肽可以在多肽的n-末端和c-末端都包含这样的肽单元。这样的肽单元的非限制性实例包括改善检测、纯化
和/或增溶的标签;n-末端或c-末端加帽单元;受体;信号结构域;和靶向结构域。在特定实例中,重组多肽包含促进多肽纯化(例如亲和纯化)和/或增溶的标签。
19.一些实施方案包括包含编码本文描述的重组多肽的多核苷酸的核酸分子。实例包括被翻译产生重组多肽的核糖核酸(rna)分子;包含编码这样的rna分子(例如,包含在表达盒中)的多核苷酸的脱氧核糖核酸(dna)构建体;和/或dna分子(例如,表达载体、转化载体、稳定复制质粒和基因组分子(例如,包含构建体的染色体))。本文的dna构建体或分子可以包含一个或更多个调节序列;例如,在细胞或基于细胞的系统中起作用以启动可操作连接的多肽、转录终止序列、5
’‑
非翻译区(5
’‑
utr)和/或3
’‑
非翻译区(3
’‑
utr)的转录的启动子。
20.特定实施方案还包括识别两个或四个连续碱性氨基酸的蛋白酶和/或在p1’裂解位置处不留下无关氨基酸的蛋白酶,和/或编码所述蛋白酶的核酸构建体或分子。在特定实例中,本文描述编码重组多肽的dna构建体或分子还包含编码蛋白酶的多核苷酸。然而,特定的实例包括重组多肽;编码重组多肽和蛋白酶的dna构建体或分子;编码蛋白酶的dna构建体或分子,或前述的任何组合(例如,在生产细胞、细胞裂解物、生物反应器或偶联的无细胞转录-翻译系统中)。在一个非限制性实例中,编码蛋白酶的多核苷酸可以可操作地定位在dna分子中包含编码重组多肽的多核苷酸的构建体内,其中dna分子还可包含位于编码蛋白酶的多核苷酸和编码重组多肽的多核苷酸之间的至少一种另外的调节序列(例如,启动子或内部核糖体进入位点序列)。
21.本文的另外实施方案还包括用于生产由靶序列组成的前述产物肽的重组生产系统。例如,本文的特定实施方案包括包含编码至少一种重组多肽的dna构建体或分子的细胞、细胞裂解物、生物反应器和偶联的无细胞转录-翻译系统。在具体实例中,细胞、细胞裂解物、生物反应器或偶联的无细胞转录-翻译系统包含dna构建体或分子,该dna构建体或分子包含编码已被密码子优化以在细胞、细胞裂解物、生物反应器或偶联的无细胞转录-翻译系统中表达的重组多肽的多核苷酸(和/或编码另外肽单元的多核苷酸)。在这些和其他实例中,编码重组多肽的多核苷酸可以包含已经被密码子优化以编码具有相同靶氨基酸序列的产物肽的核苷酸序列;例如降低宿主细胞中rnai沉默的作用。
22.与前述一致,本文的一些实施方案包括产生至少一种由靶氨基酸序列组成的产物肽的方法;例如,适于预期用途(例如,在人类或动物中的医疗和药物用途)的靶氨基酸序列。如先前提及的,相对于常规重组生产方法,这样的方法产生由靶氨基酸序列组成的产物肽,没有另外的氨基酸或不期望的内部修饰,并且具有增加的产率和期望的反应参数(例如,有限的步骤、廉价的试剂和/或环境友好的试剂)。在实施方案中,将本发明的重组(例如,可溶性)多肽与蛋白酶接触(例如,通过在反应混合物中混合多肽和蛋白酶,通过在包含蛋白酶的细胞或基于细胞的系统中表达多肽,或反之亦然,或者通过在细胞或基于细胞的系统中表达多肽和蛋白酶二者),从而在蛋白酶的裂解位点裂解多肽,产生包含产物肽氨基酸序列的多于一个中间肽。蛋白酶可以是识别两个或四个连续碱性氨基酸的蛋白酶,或者是在p1’位置处不留下氨基酸的蛋白酶。在其中蛋白酶识别两个或四个连续碱性氨基酸的实施方案中,中间肽可以与去除第一蛋白水解步骤中剩余的碱性残基的第二蛋白酶(例如,羧肽酶)接触,从而产生由靶氨基酸序列组成的产物肽。在其中蛋白酶在p1’位置处不留下氨基酸的实施方案中,中间肽可以在适当的条件下与化学剂接触,从而通过化学蛋白水解
产生由靶氨基酸序列组成的产物肽。
23.在一些实施方案中,重组多肽可以在细胞或基于细胞的系统中产生,并从其纯化以分离多肽;例如且不限于,通过用结合包含在多肽内的标签的固定化剂(例如,小分子和抗体)亲和纯化。在一些实施方案中,产物肽可以从由第二蛋白酶或化学剂催化的第二蛋白水解反应中纯化。
24.从下面参考附图进行的详细描述中,前述和其他特征将变得更加明显。
25.附图简述
26.图1包括有助于说明本文实施方案的其他方面的图。图1a显示了用于生产产物肽的重组多肽的线性表示。如图1中所描绘的方案,重组多肽可以包含tag,如所示的,随后首先是包含在p1’位置处不留下氨基酸的蛋白酶(例如选自肠激酶、因子xa、胱天蛋白酶和颗粒酶b)的裂解位点的肽,并且然后是重复单元(ru),每个重复单元包含化学裂解序列(c.c.s.)、接头序列(l
nk
)、在p1’位置处不留下氨基酸的蛋白酶裂解位点(p.c.s.)和产物肽(图1b)。如图1c所示,用蛋白酶(“酶”)进行蛋白水解,释放中间肽,每个中间肽包含具有羧基末端化学裂解序列(c.c.s.)、接头序列(l
nk
)和蛋白酶裂解位点(p.c.s.)的产物肽。用合适的化学剂(“化学剂”)对中间肽进行化学裂解,产生由它们的靶氨基酸序列组成而不含无关氨基酸的产物肽。接头氨基酸被放置在c.c.s.和酶识别序列之间,并且对于每个重复单元可以是相同的或可变的。然而,gly、ala和ser三种氨基酸优选作为接头序列的最后一个氨基酸。
27.图2包括有助于说明本文实施方案的其他方面的图。图2a显示了用于生产产物肽的重组多肽的线性表示。重组多肽可包含tag,如所示的,随后首先是包含在p1’位置处不留下氨基酸的第一蛋白酶(例如选自肠激酶、因子xa、胱天蛋白酶和颗粒酶b)的裂解位点(蛋白酶1裂解位点(p1.c.s.))的肽,并且然后是重复单元(ru),每个重复单元包含第二蛋白酶(诸如hiv-1蛋白酶)的裂解位点(蛋白酶2裂解位点(p2.c.s.))、接头序列(l
nk
)、在p1’位置处不留下氨基酸的第一蛋白酶的裂解位点和产物肽(图2b)。如图2c所示,用第一蛋白酶(“酶1”)进行蛋白水解,释放肽产物和中间肽,所述中间肽各自包含产物肽、p2.c.s.、l
nk
和p1.c.s.。用第二蛋白酶(“酶2”)处理产生了由它们的靶氨基酸序列组成而不含无关氨基酸的产物肽。接头氨基酸被放置在p2.c.s.和p1.c.s.之间并且对于每个重复单元可以是相同的或可变的。然而,gly、ala和ser三种氨基酸优选作为接头序列的最后一个氨基酸。酶的添加顺序可以互换,或者它们可以同时添加。
28.图3包括有助于说明本文实施方案的基本潜在方面的图。图3a显示了用于分离(例如,包括纯化)产物肽的重组多肽的线性表示。重组多肽可以包含tag(例如选自亲和纯化标签和增溶标签),如所示的,随后是重复单元(ru)(图3b),每个重复单元都包含具有第一蛋白酶(“酶1”)(例如,选自弗林蛋白酶、蛋白质转化酶、神经内分泌转化酶和kexin)的裂解位点的肽,该第一蛋白酶在偶数个连续的碱性残基(2个至4个)的c-末端侧裂解。如图3c所示,用酶1进行蛋白水解,释放中间肽,每个中间肽包含产物肽和羧基末端碱性氨基酸(bm)。还如图3c所示,用羧肽酶(“酶2”)(例如选自cpn(也称为激肽酶i)、cpb、cpu和金属羧肽酶d(cpd))进一步蛋白水解中间肽,产生由它们的靶氨基酸序列组成而不含无关氨基酸的产物肽。
29.图4显示pet32a的质粒图,含有编码重组多肽的表达盒,所述重组多肽包含含有胰
高血糖素产物肽的串联重复单元。
30.图5显示了加硫氧还蛋白标签的胰高血糖素(四个重复序列)的生产和加工以及通过maldi-tof质谱对产物质量的确认。图5a显示了加硫氧还蛋白标签的胰高血糖素的四个重复序列在被胱天蛋白酶-7水解之前和之后的sds-page分析(tricine凝胶)。从左至右:蛋白质标志物、用胱天蛋白酶-7处理的加硫氧还蛋白标签的胰高血糖素、通过c18柱纯化的胰高血糖素和重复单元(ru—与接头序列和ntcb裂解序列以及胱天蛋白酶识别序列连接的胰高血糖素)、成熟胰高血糖素和加硫氧还蛋白标签的胰高血糖素。图5b显示了在胱天蛋白酶-7有限水解之前和之后加trx标签的胰高血糖素的四个重复序列的sds-page分析(tricine凝胶),产生所有预期的片段,表明所有设计的胱天蛋白酶裂解位点对蛋白酶几乎同等地可及。图5c显示了使用chca作为基质,对胰高血糖素和胰高血糖素重复单元(ru—附接到ntcb裂解序列、接头肽和胱天蛋白酶识别序列的胰高血糖素)的线性模式maldi-tof质谱分析。具有预期分子量的肽片段的存在证明该酶已经在指定位点正确裂解了胰高血糖素的加trx标签的串联重复序列。
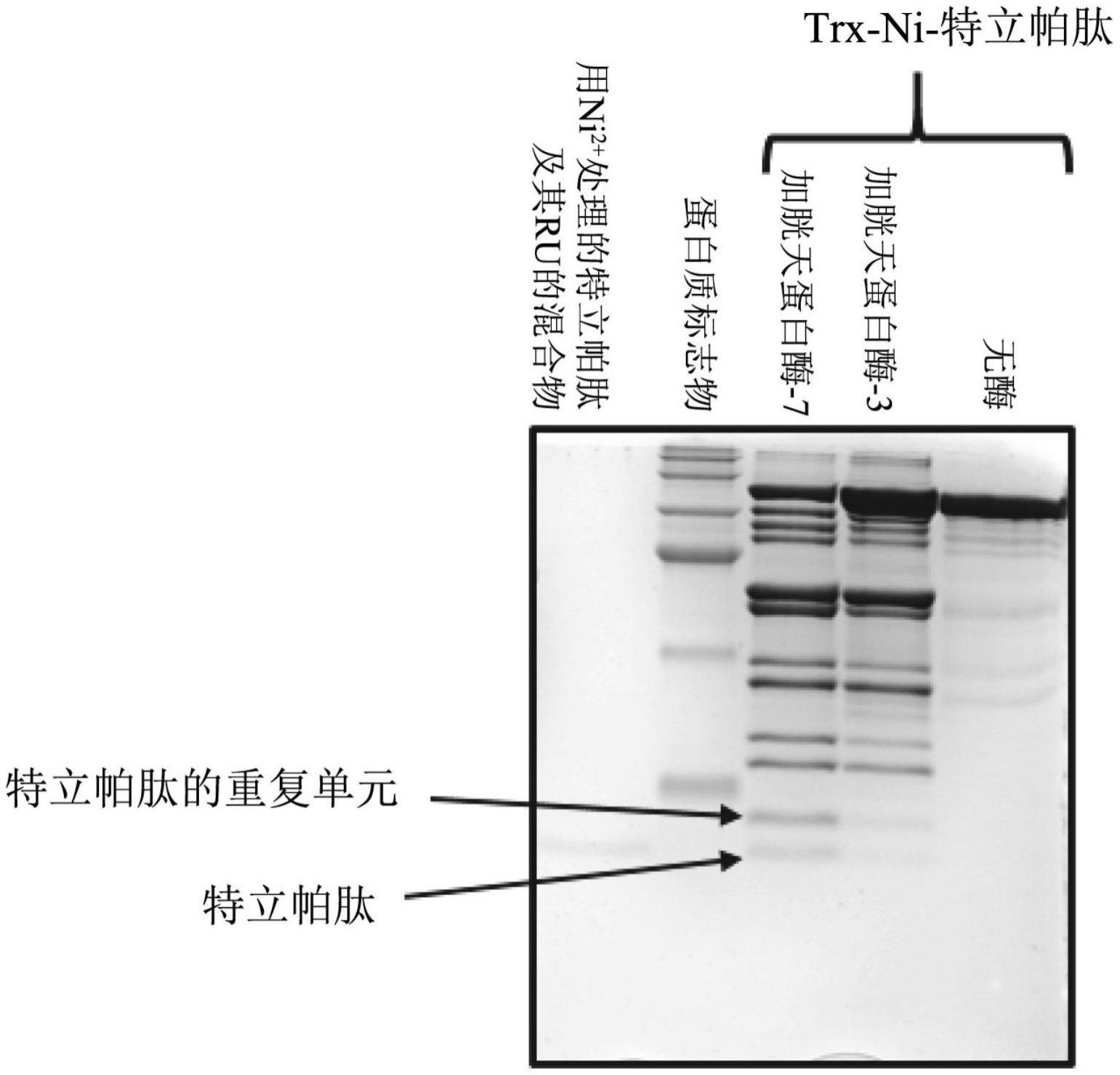
31.图6显示了加硫氧还蛋白标签的特立帕肽(teriparatide)的四个重复序列在大肠杆菌中的生产和通过胱天蛋白酶-3、胱天蛋白酶-7和hiv1蛋白酶的加工。图6a显示了胱天蛋白酶-7处理前trx-hiv特立帕肽(四个重复序列)(泳道1),和通过胱天蛋白酶-7水解trx-特立帕肽获得的hplc纯化的特立帕肽及其重复单元(泳道2)的sds-page(tricine)。图6b显示了trx-hiv特立帕肽的胱天蛋白酶水解条件可以设置为以sds-page(tricine)揭示的不溶性(泳道1)或可溶性(泳道2)形式产生特立帕肽和特立帕肽的重复单元。观察到的肽条带是在20.2分钟从biorad hipore c18柱洗脱的产物。泳道3显示成熟的特立帕肽。图6c显示了使用biorad-hipore c18柱对胱天蛋白酶-7处理后trx-hiv特立帕肽、四个重复序列的hplc分析。建立0.1%三氟乙酸中5%至90%乙腈的梯度持续30分钟的时间段。特立帕肽及其重复单元的混合物在20.2分钟洗脱。图6d显示了maldi-tof质谱证实了胱天蛋白酶-7对trx-特立帕肽(四个重复序列)(具有胱天蛋白酶-3/-7和hiv1蛋白酶识别位点)的正确加工。将干燥的肽溶解在水中,并且根据制造商的方案用rainin c18尖头清洗,并布点在maldi平板上。添加等体积的chca基质并干燥,然后以线性模式进行ms分析。
32.图7显示了具有胱天蛋白酶-3(-7)和ni
2+
裂解序列的加硫氧还蛋白标签的特立帕肽(四个重复序列)在大肠杆菌中的生产和加工。图7a显示了使用胱天蛋白酶-7完全水解trx-特立帕肽产生硫氧还蛋白(trx标签)、特立帕肽的重复单元和特立帕肽的sds-page分析(tricine)。图7b显示了用胱天蛋白酶-3和胱天蛋白酶-7有限水解trx-ni-特立帕肽(四个重复序列)并在50℃使用1mm浓度的nicl2将特立帕肽的重复单元转化为成熟特立帕肽的sds-page分析(tricine)。图7c显示了通过sds-page分析(甘氨酸)分析的通过与胱天蛋白酶-7在30℃孵育2小时,trx-特立帕肽(四个重复序列)的剂量依赖性裂解。图7d显示了在50℃用1mm nicl2处理后特立帕肽的重复单元完全转化为成熟特立帕肽,经maldi-tof质谱证实。chca用作基质。图7e显示了使用thermo q-exactive轨道阱质谱仪获得的特立帕肽及其包含ni
2+
裂解序列的重复单元的esi-ms分析。图7f和图7g分别显示了tricine和甘氨酸凝胶的预染色蛋白质标志物的分子量。
33.图8显示了具有ni
2+
裂解序列的加硫氧还蛋白标签的特立帕肽(四个重复序列)的水解及其被1mm和2mm nicl2、孵育时间为24小时,并且温度为23℃、37℃和50℃的裂解的
76。
42.本文实施方案的多肽和肽的氨基酸序列通常使用经典蛋白酶裂解命名法的术语来描述,将位于底物多肽的p1和p1’氨基酸之间的裂解位点括起来(《》),将位点描述为:
43.pn-p4-p3-p2-p1《》p1
’‑
p2
’‑
pn’44.核酸分子:如本文所用,术语“核酸分子”是指核苷酸的聚合形式,包括rna、cdna、基因组dna以及上述的合成形式和混合聚合物。核苷酸可以指核糖核苷酸、脱氧核糖核苷酸或任一类型核苷酸的修饰形式。核酸分子可以包括通过天然存在和/或非天然存在的核苷酸键连接在一起的天然存在和修饰的核苷酸中的一种或两种。
45.核酸分子可以包含在本文中称为“多核苷酸”的结构单元,其区分聚合物中核苷酸的物理顺序,与“核苷酸序列”不同,“核苷酸序列”是指物理多核苷酸中包含的信息。
46.外源性:本文中应用于核酸分子、多核苷酸、多肽和肽的术语“外源性”是指通常不存在于其特定环境或背景中的一种或更多种核酸分子、多核苷酸、多肽和肽。例如,如果宿主细胞被转化为使得其包含在自然界中未转化的宿主细胞中不存在的多核苷酸或表达在自然界中未转化的宿主细胞中不存在的多肽,则该多核苷酸或多肽对宿主细胞是外源的。此外,当质粒或载体通常不存在于宿主细胞的基因组中时,存在于宿主细胞中的质粒或载体中的多核苷酸对宿主细胞是外源的。术语“核酸分子”的范围内具体包括基因组核酸分子,诸如染色体或自我复制质粒,其包含通常不存在于宿主细胞的天然存在的染色体或质粒中的多核苷酸。术语“多核苷酸”具体包括那些整合在宿主细胞基因组dna中的多核苷酸;例如在转化事件之后。
47.异源:本文中应用于核酸分子、多核苷酸、多肽和肽的术语“异源”意指不同来源的。例如,如果宿主细胞用具有在自然界中未转化的宿主细胞中不存在的核苷酸序列的多核苷酸转化,则该多核苷酸对宿主细胞是异源的(和外源的)。此外,核酸构建体(例如,表达构建体)的不同元件(例如,启动子、增强子、编码序列、终止子等)可以彼此异源和/或与宿主细胞异源。本文使用的术语异源也可应用于一种或更多种多核苷酸、多肽或肽,它们在序列上与宿主细胞中已经存在的多核苷酸、多肽或肽相同,但现在连接到不同的另外多核苷酸或肽(例如,标签、标志物、报告基因或功能单元)和/或以不同的拷贝数、或细胞位置或区室存在。
48.如本文所用,“密码子优化”是指其中密码子已被选择为允许多肽在特定宿主生物或宿主细胞中有效表达的多核苷酸。用于表达多肽的示例性宿主生物体和宿主细胞(“表达宿主”)包括大肠杆菌、酿酒酵母(s.cerevisiae)、粟酒裂殖酵母(s.pombe)、巴斯德毕赤酵母(p.pastoris)、昆虫细胞、植物细胞和适用于该目的的许多哺乳动物细胞系的细胞(例如但不限于hela、jurkat、293、cho和cos细胞)。用于表达异源多肽的模式表达宿主是本领域已知的,并且密码子优化的异源核苷酸序列可以从这样的生物体中高表达的多肽的密码子使用频率推导。
49.序列同一性:如本文所用在两个多核苷酸、多肽或肽的上下文中的术语“序列同一性”或“同一性”是指两个序列中当在指定的比较窗口上为了最大对应性对齐时相同的核苷酸序列或氨基酸序列。
50.如本文所用,术语“序列同一性百分比”可以指通过在比较窗口上比较两个最佳对齐的序列而确定的值,其中为了两个序列的最佳对齐,比较窗口中的序列部分可以包括与
参考序列(不包括添加或缺失)相比的添加或缺失(例如,缺口)。百分比通过如下计算:确定两个序列中出现相同核苷酸或氨基酸残基的位置的数目,以产生匹配位置的数目,将匹配位置的数目除以比较窗中位置的总数目,并将结果乘以100以得到序列同一性的百分比。
51.用于比对序列以进行比较的方法是本领域公知的。各种程序和比对算法描述于,例如:smith和waterman(1981)adv.appl.math.2:482;needleman和wunsch(1970)j.mol.biol.48:443;pearson和lipman(1988)proc.natl.acad.sci.u.s.a.85:2444;higgins和sharp(1988)gene 73:237-44;higgins和sharp(1989)cabios 5:151-3;corpet等人.(1988)nucleic acids res.16:10881-90;huang等人.(1992)comp.appl.biosci.8:155-65;pearson等人.(1994)methods mol.biol.24:307-31;tatiana等人.(1999)fems microbiol.lett.174:247-50。对序列比对方法和同源性计算的详细考虑可以在例如altschul等人.(1990)j.mol.biol.215:403-10中找到。
52.美国国家生物技术信息中心(national center for biotechnology information,ncbi)基本局部比对搜索工具(blast
tm
;altschul等人.(1990))可从若干个来源获得,包括美国国家生物技术信息中心(national center for biotechnology information)(bethesda,md)和互联网上,用于与若干个序列分析程序结合使用。关于如何使用该程序确定序列同一性的描述可在互联网上blast
tm
的“帮助”章节下获得。对于核酸序列的比较,可以使用默认参数采用blast
tm
程序的“blast 2序列”功能。当通过这种方法评估时,与参考序列相似性增加的核苷酸或氨基酸序列将显示出增加的百分比同一性。
53.如本文关于核苷酸序列所用的,术语“基本上相同”是指超过85%相同的序列。例如,基本上相同的核苷酸序列可以与参考序列至少85.5%;至少86%;至少87%;至少88%;至少89%;至少90%;至少91%;至少92%;至少93%;至少94%;至少95%;至少96%;至少97%;至少98%;至少99%;或至少99.5%相同。
54.作为序列同一性的等价物,“特异性杂交”的结构特性可用于定义具有基本上相同核苷酸序列的多核苷酸。“特异性杂交”指示寡核苷酸探针和由特异性结合限定的靶多核苷酸之间发生序列特异性稳定结合所需的互补程度。只有当寡核苷酸与非靶多核苷酸的非特异性结合在适当的条件下不发生时,探针寡核苷酸才是可特异性杂交的,这是本领域技术人员对于任何探针-靶对都已知的。
55.杂交条件随着杂交探针和靶多核苷酸的组成和长度、杂交温度、杂交缓冲液的离子强度和洗涤条件而变化。对于特定的探针序列,测定特异性杂交所需的杂交条件的计算是可确定的,并且是本领域普通技术人员已知的;例如,sambrook等人.(ed.)molecular cloning:alaboratory manual,2
nd ed.,vol.1-3,cold spring harbor laboratory press,cold spring harbor,ny,1989,chapters 9and 11;以及hames和higgins(eds.)nucleic acid hybridization,irl press,oxford,1985中讨论了这样的计算。关于核酸杂交的另外详细说明和指导可以在例如tijssen,“overview of principles of hybridization and the strategy of nucleic acid probe assays,”in laboratory techniques in biochemistry and molecular biology-hybridization with nucleic acid probes,part i,chapter 2,elsevier,ny,1993;以及ausubel等人,eds.,current protocols in molecular biology,chapter 2,greene publishing and wiley-interscience,ny,1995中找到。
56.特异性杂交可以在“严格杂交条件”下进行测定,其中一个普遍适用的实例是在65℃在6x盐水-柠檬酸钠(ssc)缓冲液、5x denhardt溶液、0.5% sds和100μg剪切的鲑鱼睾丸dna中杂交,然后在65℃在2x ssc缓冲液和0.5% sds中,接着是1x ssc缓冲液和0.5% sds,并且最后是0.2x ssc缓冲液和0.5% sds中顺序洗涤15-30分钟。
57.标签:如本文所用的术语“标签”是指不形成由本文方法产生的中间肽或接头序列的一部分的肽单元,尽管应当理解,产物肽本身可以含有氨基酸基序,其能够达到使用常规“标签”的目的;例如,在亲和纯化中。在这点上,标签相对于其所在的多肽的剩余部分以及其中串联的肽是异质的、非同源的序列基序。标签可以共价连接到多肽的n-末端、c-末端或内部位点(例如,氨基酸侧链)。标签可用于检测、鉴定、选择、富集或纯化与标签共价连接的多肽。在一些实例中,标签是作为最初在宿主细胞或系统中翻译的多肽的一部分翻译的前导肽。在一些实例中,本文中的重组多肽包含允许检测、选择或纯化多肽的标签(“亲和标签”)。本文使用的特定亲和标签包括例如但不限于多组氨酸(例如(his6))、硫氧还蛋白、麦芽糖结合蛋白、谷胱甘肽-s-转移酶(gst)、avitag、钙调素标签、聚谷氨酸盐标签、flag-标签、ha-标签、myc-标签、s-标签、sbp-标签、softag 3、v5标签和xpress标签。
58.如本文所用的“重组体”是指通过重组方法有意修饰的氨基酸序列或核苷酸序列。本文的术语“重组多核苷酸”意指通常在体外通过内切核酸酶操纵核酸形成,呈通常在自然界中找不到的形式的多核苷酸(例如,核酸分子)。因此,线性形式的分离多核苷酸或通过连接非正常连接的dna分子在体外形成的表达载体都是重组多核苷酸的种类。据了解,在重组核酸分子被制造并引入宿主细胞后,它将非重组地复制;例如,使用宿主细胞的体内细胞机构而不是体外操作。然而,这样的核酸在重组产生后,尽管随后非重组地复制,出于本公开内容的目的仍然被认为是重组的。本文的术语“重组多肽”和“重组肽”具体地包括使用重组技术制备的多肽和肽;例如,通过在细胞或含有必要组分的无细胞系统中表达重组多核苷酸。
59.术语“载体”是指通常是双链的、可能插入了一段外源dna的一段dna。载体可以是例如质粒来源的。载体包含促进载体在宿主细胞中自主复制的“复制子”多核苷酸。载体通常用于将一种或更多种多核苷酸转运到合适的宿主细胞中。在宿主细胞中后,载体可以独立于宿主染色体dna或与宿主染色体dna一致地复制,并且可以产生载体及其插入的多核苷酸的若干个拷贝。此外,载体还可以含有必要的元件,这些元件允许插入的多核苷酸转录成mrna分子,或者以其他方式导致插入的多核苷酸复制到rna的多于一个拷贝中。一些表达载体还含有与插入的多核苷酸相邻的序列元件,其增加表达的mrna的半衰期,和/或允许mrna翻译成蛋白质分子。因此,由插入的多核苷酸编码的许多mrna和多肽分子可以快速合成。
60.保守取代:如本文所用,术语“保守取代”是指一个氨基酸残基被同一类中的另一个氨基酸取代的取代。非保守氨基酸取代是残基不属于同一类别的取代,例如,碱性氨基酸取代中性或非极性氨基酸。为了进行保守取代而定义的氨基酸的类别是本领域已知的。出于本公开内容的目的,肽可以被定义为包含与参考氨基酸序列具有一定量序列同一性(例如,与参考氨基酸序列至少90%相同)的氨基酸序列。在这样的情况下,相应地意味着肽可以包含具有所述序列同一性的氨基酸序列,其中肽氨基酸序列和参考氨基酸序列之间的差异是保守取代。
61.在一些实施方案中,保守取代包括用第一脂肪族氨基酸取代第二、不同的脂肪族
氨基酸。例如,如果第一氨基酸是gly;ala;pro;ile;leu;val和met之一,则第一氨基酸可以被选自gly;ala;pro;ile;leu;val和met的第二、不同氨基酸代替。在特定实例中,如果第一氨基酸是gly;ala;pro;ile;leu和val之一,则第一氨基酸可以被选自gly;ala;pro;ile;leu和val的第二、不同氨基酸代替。在涉及疏水脂肪族氨基酸取代的特定实例中,如果第一氨基酸是ala;pro;ile;leu和val之一,则第一氨基酸可以被选自ala;pro;ile;leu和val的第二、不同氨基酸代替。
62.在一些实施方案中,保守取代包括用第一芳香族氨基酸取代第二、不同的芳香族氨基酸。例如,如果第一氨基酸是his;phe;trp和tyr之一,则第一氨基酸可以被选自his;phe;trp和tyr的第二、不同氨基酸代替。在涉及取代不带电荷的芳香族氨基酸的特定实例中,如果第一氨基酸是phe;trp和tyr之一,则第一氨基酸可被选自phe;trp和tyr的第二、不同氨基酸代替。
63.在一些实施方案中,保守取代包括用第一疏水氨基酸取代第二、不同的疏水氨基酸。例如,如果第一氨基酸是ala;val;ile;leu;met;phe;tyr和trp之一,则第一氨基酸可以被选自ala;val;ile;leu;met;phe;tyr和trp的第二、不同氨基酸代替。在涉及取代非芳香族疏水性氨基酸的特定实例中,如果第一氨基酸是ala;val;ile;leu和met之一,则第一氨基酸可以被选自ala;val;ile;leu和met的第二、不同氨基酸代替。
64.在一些实施方案中,保守取代包括用第一极性氨基酸取代第二、不同极性氨基酸。例如,如果第一氨基酸是ser;thr;asn;gln;cys;gly;pro;arg;his;lys;asp和glu之一,则第一氨基酸可以被选自ser;thr;asn;gln;cys;gly;pro;arg;his;lys;asp和glu的第二、不同氨基酸代替。在涉及取代不带电荷的极性氨基酸的特定实例中,如果第一氨基酸是ser;thr;asn;gln;cys;gly和pro之一,则第一氨基酸可以被选自ser;thr;asn;gln;cys;gly和pro的第二、不同氨基酸代替。在涉及带电极性氨基酸取代的特定实例中,如果第一氨基酸是his;arg;lys;asp和glu之一,则第一氨基酸可以被选自his;arg;lys;asp和glu的第二、不同氨基酸代替。在涉及带电极性氨基酸取代的另外实例中,如果第一氨基酸是arg;lys;asp和glu之一,则第一氨基酸可以被选自arg;lys;asp和glu的第二、不同氨基酸代替。在涉及带正电荷(碱性)极性氨基酸取代的特定实例中,如果第一氨基酸是his;arg和lys之一,则第一氨基酸可以被选自his;arg和lys的第二、不同氨基酸代替。在涉及带正电荷的极性氨基酸取代的其他实例中,如果第一氨基酸是arg或lys,则第一氨基酸可以被arg和lys的另一氨基酸代替。在涉及带负电荷(酸性)极性氨基酸取代的特定实例中,如果第一氨基酸是asp或glu,则第一氨基酸可以被asp和glu的另一氨基酸代替。
65.在一些实施方案中,保守取代包括用第一电中性氨基酸取代第二、不同的电中性氨基酸。例如,如果第一氨基酸是gly;ser;thr;cys;asn;gln和tyr之一,则第一氨基酸可被选自gly;ser;thr;cys;asn;gln和tyr的第二、不同氨基酸代替。
66.在一些实施方案中,保守取代包括用第一非极性氨基酸取代第二、不同的非极性氨基酸。例如,如果第一氨基酸是ala;val;leu;ile;phe;trp;pro和met之一,则第一氨基酸可以被选自ala;val;leu;ile;phe;trp;pro和met的第二、不同氨基酸代替。
67.在许多实例中,保守取代中代替第一氨基酸的特定第二氨基酸可以选择为使第一和第二氨基酸都属于的前述类别的数量最大化。因此,如果第一氨基酸是ser(极性、非芳香族和电中性氨基酸),则第二氨基酸可以是另一极性氨基酸(例如,thr;asn;gln;cys;gly;
pro;arg;his;lys;asp或glu);另一非芳香族氨基酸(例如,thr;asn;gln;cys;gly;pro;arg;his;lys;asp;glu;ala;ile;leu;val或met);或者另一电中性氨基酸(例如,gly;thr;cys;asn;gln或tyr)。然而,在这种情况下,可以优选第二氨基酸是thr;asn;gln;cys和gly之一,因为这些氨基酸共有所有根据极性、非芳香性和电中性的分类。本领域已知可任选用于选择保守取代中使用的特定第二氨基酸的另外标准。例如,当thr;asn;gln;cys和gly可用于保守取代ser时,cys可从选择中排除,以避免形成不期望的交联和/或二硫键。同样,gly可以从选择中排除,因为它缺少烷基侧链。在这种情况下,例如,为了保留侧链羟基基团的官能团,可以选择thr。然而,在保守取代中使用的特定第二氨基酸的选择最终在技术人员的判断范围内。
68.反应混合物:如本文所用,术语“反应混合物”是指包含盐、辅因子和/或足以进行修饰底物的酶促和/或化学活性的其他组分的体外水性体积。该术语具体包括将发生特定反应或一组反应的生物反应器、细胞裂解物或无细胞系统的内容物;例如,重组多肽(例如,可溶性多肽)的蛋白水解裂解和/或随后从中间肽中酶促和/或化学去除无关氨基酸以产生产物肽。含有反应混合物的生物反应器和其它容器的内容物可以在本领域已知的反应或多步反应期间交换;例如,以替换耗尽的试剂或减缓或停止特定反应,或启动不同的反应。
69.maldi-tof:术语“maldi”是指基质辅助的激光解吸/电离(matrix-assisted laser desorption/ionization),在该过程中分析物被嵌入光吸收分子(例如,烟酸、芥子酸或3-羟基吡啶甲酸)的固体或晶体“基质”中,然后通过激光照射解吸并从固相电离为气相或蒸汽相,并作为完整的分子离子向检测器加速。“基质”通常是在溶液中以10,000:1基质/分析物摩尔比与分析物混合的小有机酸。使用前可将基质溶液调节至中性ph。
70.术语“maldi-tof ms”是指基质辅助的激光解吸/电离飞行时间质谱。
71.液相色谱法。术语“液相色谱法”或“lc”是指当流体均匀地渗透通过精细分离物质的柱或通过毛细管通道时,选择性分离流体溶液的一种或更多种组分的过程。当该流体相对于固定相移动时,混合物的组分在一个或更多个固定相和主体流体(例如,流动相)之间的分布导致选择性分离。“液相色谱法”的实例包括高效液相色谱法(hplc)。
72.高效液相色谱法:术语“高效液相色谱法”(“hplc”)是指通过在压力下迫使流动相通过固定相(通常是密集填充的柱)来提高分离度的液相色谱法。本领域技术人员将理解,在这样的柱中的分离是一个分配过程,并且可以选择适用于使用的lc(包括hplc)、仪器和柱。
73.实时pcr。术语“实时pcr”(“rt pcr”)用于表示定量pcr技术的子集,该技术允许在整个pcr反应期间或实时检测pcr产物。实时pcr的原理通常在例如held等人."real time quantitative pcr"genome research 6:986-994(1996)中描述。通常,实时pcr在每个扩增循环测量信号。一些实时pcr技术依赖于在每个扩增循环完成时发出信号的荧光团。这样的荧光团的实例是在与双链dna结合时发射限定波长的荧光的荧光染料,诸如sybr绿。因此,由于pcr产物的积累,每个扩增循环期间双链dna的增加导致荧光强度的增加。
74.(ii)本技术的序列和剂
75.随附序列表中列出的核酸序列使用核苷酸碱基的标准字母缩写显示。仅显示了每个核酸序列的一条链,但是互补链被理解为包含在所展示链的任何提及中。在随附的序列表中:
76.seq id no:1-29显示了在两个或四个碱性残基后裂解多肽的蛋白酶的代表性识别序列,在特定实施方案中用于释放中间肽。
77.seq id no:30-45显示了在多肽裂解后在p1’位置处不留下氨基酸的蛋白酶的代表性识别序列,在特定实施方案中用于释放中间肽。
78.seq id no:46-56显示了代表性的化学裂解序列,在特定实施方案中用于从中间肽释放具有靶氨基酸序列的产物肽。
79.seq id no:57-83显示了代表性接头序列,在特定实施方案中用于例如提高反应效率。
80.seq id no:84-121显示了使用本文的组合物和方法可产生的代表性产物肽的靶氨基酸序列。seq id no:84-109显示了包含cys和/或met残基的代表性产物肽的靶氨基酸序列,使得该肽不适于本领域中依赖于在接头肽的氨基末端引入异源半胱氨酸和在羧基末端引入甲硫氨酸的某些方法。
81.seq id no:122-124、195显示了包含在本文某些重组多肽中的肽标签的代表性序列。
82.seq id no:125-173、189-194、196-199、201-202示出了包含某些产物肽的靶氨基酸序列的重组多肽的实例,以及包含在被去除以释放产物肽的多肽中的氨基酸序列的实例。
83.seq id no:174显示了图4的质粒图的序列。
84.seq id no:175-188、200显示了逆转录病毒蛋白酶的代表性识别序列,在特定实施方案中用于释放中间肽或从中间肽释放具有靶氨基酸序列的产物肽。
85.(iii)用途
86.裂解融合蛋白以获得感兴趣的多肽或肽原则上可以通过化学或生物化学方法实现,诸如使用蛋白水解酶(蛋白酶)的酶促裂解。这些方法采用通过水解肽键起作用的剂,并且裂解剂的特异性由被裂解的肽键处或附近的氨基酸残基的身份决定。非特异性裂解可能对感兴趣的多肽或肽的使用产生不利影响,例如,通过影响多肽或肽的活性,或通过用代表脱靶裂解事件的片段污染产物。因此,由于裂解位点可能出现在感兴趣的多肽或肽本身中的事实,融合多肽的酶促裂解受到限制。融合蛋白的低效或不完全裂解也可能发生,降低产量并向产物引入异质性,使得仅纯化一小部分期望的蛋白质。因此,虽然使用一个蛋白酶家族的多肽或肽生产平台可能适用于一种或几种产物,但如果不进行修改,它就不能适用于其他多肽或肽的生产。
87.本文的组合物和方法解决了与肽生产相关的另一个问题;常规方法会将无关氨基酸附接到裂解的期望的肽。当连接期望的肽产物的接头序列被裂解时,这些氨基酸通常存在。这些氨基酸经常影响所得肽的特性和/或给使用带来监管难题(regulatory difficulties),特别是当肽预期用于人类受试者时。本文的组合物和方法可用于获得与在含有多于一种肽的融合多肽中重组表达肽相关的益处(例如,产量增加),而不会在期望的肽产物中产生无关氨基酸。为了实现这些结果,本文的实施方案提供了具有酶可裂解接头序列的肽串联体,所述接头序列包含以特定方式布置的元件。
88.在一些实施方案中,串联体包含在两个或四个碱性残基(bm)后裂解的蛋白酶的识别位点、接头序列(l
nk
)、期望的肽产物(dp)、下一个两个或四个碱性残基蛋白酶识别位点
(bm)和另外的期望的肽产物(dp),并且还可以包含不形成期望的肽或蛋白质或接头序列的一部分的至少一个肽单元;例如,促进纯化、增溶或二者的tag。这样的实施方案中的串联体以下列布置包括这些元件:
89.[tag]
–
l
nk-(b
m-l
nk-b
m-dp)n[0090]
或者
[0091]
met
–
(dp-b
m-l
nk-bm)n–
[tag],
[0092]
其中重复序列的数目“n”在技术人员的判断范围内,并且取决于特定期望的肽产物的长度和融合蛋白表达系统。
[0093]
在用在两个或四个碱性残基后裂解的蛋白酶(例如,弗林蛋白酶、蛋白质转化酶、神经内分泌转化酶1或kexin)对串联体多肽进行蛋白水解裂解后,产生dp-bm和dp(以及另外的met-dp,如果使用tag,则取决于tag的位置),以及不含dp的tag-bm和l
nk-bm产物。用羧肽酶(例如,羧肽酶n、羧肽酶b、羧肽酶u或金属羧肽酶d)处理所得产物,从而转化dp-bm到dp,不含无关氨基酸。在使用特定表达宿主(例如,大肠杆菌)的实例中,从重组多肽去除初始甲硫氨酸残基,这在使用串联体c-末端tag的应用中可以是有用的。
[0094]
在前述和另外的实施方案中,串联体包含识别特定的靶氨基酸序列并且在裂解后在p1’位置处不留下氨基酸的蛋白酶的识别位点、期望的肽产物(dp)、以及接头序列和化学裂解序列(c.c.s.-l
nk
),并且还可以包含不形成期望的肽或蛋白质或接头序列(例如,tag)的一部分的至少一个肽单元。这样的实施方案中的串联体以下列布置包括这些元件:
[0095]
[tag]
–
l
nk-p.c.s.-dp
–
[(c.c.s.-l
nk
)-p.c.s.-dp]n[0096]
或者
[0097]
met-dp
–
[(c.c.s.-l
nk
)-p.c.s.-dp]n–
c.c.s.
–
[tag],
[0098]
其中重复序列的数目“n”在技术人员的判断范围内,并且取决于特定期望的肽产物的长度和融合蛋白表达系统。
[0099]
在用裂解后在p1’位置处不留下氨基酸的蛋白酶(例如,肠激酶、凝血因子x(因子xa)、胱天蛋白酶或颗粒酶b)对串联体多肽进行蛋白水解裂解后,产生met-dp-(c.c.s.-l
nk-p.c.s.)和dp-(c.c.s.-l
nk-p.c.s.)。在使用特定表达宿主(例如,大肠杆菌)的实例中,从met-dp-c.c.s.-p.c.s.肽去除初始甲硫氨酸,仅产生dp-(c.c.s.-l
nk-p.c.s.)。然后用适当的位点特异性蛋白水解化学剂(例如,2-硝基-5-硫氰酸(ntcb)、ni
2+
或pd
2+
)处理产物,从而转化dp-(c.c.s.-l
nk-p.c.s.)为期望的肽产物,不含不是靶氨基酸序列一部分的无关氨基酸。
[0100]
与前述一致,本公开内容的实施方案提供了包含串联的中间肽和包含特定蛋白酶裂解位点的中间接头序列的重组多肽,以及编码其的多核苷酸。在特定的实施方案中,重组多肽可溶于水性环境;例如,使得它们不在重组生产细胞中形成包涵体。蛋白酶催化多肽序列特异性裂解成中间肽,中间肽随后被酶促或化学加工成由期望的靶序列组成的产物肽;例如,不含任何无关氨基酸的靶氨基酸序列。在特定实例中,前述多肽包含1-150个串联的肽单元(例如但不限于2-150个、3-150个、2-10个、2-20个、3-20个、2-10个或3-10个),其选择根据技术人员的判断,并且可以取决于诸如肽的长度和所采用的特定宿主或表达系统的因素。特定的多肽可以包含含有相同产物肽的中间肽,或者它们可以包含具有不同产物肽的若干种中间肽,如下文描述布置在多肽中。
[0101]
在第一方面,催化重组多肽序列特异性裂解成中间肽的蛋白酶在两个或四个碱性氨基酸残基(k或l)后裂解,并且中间肽包含产物肽和蛋白水解反应后剩余的两个或四个碱性氨基酸。可以在本文的实施方案中使用的具有两个或四个碱性氨基酸残基识别位点的蛋白酶的实例包括例如,具有[r/k]xn[r/k]
↓
的一般识别位点的蛋白质转化酶,其中n是0或2或4或6(例如,seq id no:1和seq id no:27-29)(优选的序列是rx[r/k]r
↓
(seq id no:14),其中x优选为碱性残基),弗林蛋白酶(识别位点rx[r/k]r
↓
(seq id no:14)),神经内分泌转化酶1(识别位点(r/k)r
↓
(seq id no:2))和kexin(识别位点(r/k)r
↓
(seq id no:2))。因此,在特定实例中,重组多肽可包含蛋白酶识别位点,其包含选自由以下组成的组的氨基酸序列:rr(seq id no:3)(kexin;神经内分泌转化酶1)、kr(seq id no:4)(kexin;神经内分泌转化酶1)、[r/k][r/k][r/k]r(seq id no:17)(kexin;神经内分泌转化酶1;蛋白质转化酶)、r[r/k][r/k]r(seq id no:18)(kexin;神经内分泌转化酶1;弗林蛋白酶;蛋白质转化酶)、rrrr(seq id no:19)(kexin;神经内分泌转化酶1;弗林蛋白酶;蛋白质转化酶)、rkrr(seq id no:20)(kexin;神经内分泌转化酶1;弗林蛋白酶;蛋白质转化酶)、rrkr(seq id no:21)(kexin;神经内分泌转化酶1;弗林蛋白酶;蛋白质转化酶)、rkkr(seq id no:22)(kexin;神经内分泌转化酶1;弗林蛋白酶;蛋白质转化酶)、krrr(seq id no:23)(kexin;神经内分泌转化酶1;蛋白质转化酶)、kkrr(seq id no:24)(kexin;神经内分泌转化酶1;蛋白质转化酶)、krkr(seq id no:25)(kexin;神经内分泌转化酶1;蛋白质转化酶)和kkkr(seq id no:26)(kexin;神经内分泌转化酶1;蛋白质转化酶)。
[0102]
在第二方面,催化重组多肽序列特异性裂解成中间肽的蛋白酶在裂解后在p1’位置处不留下氨基酸,并且中间肽包含产物肽和接头序列以及序列特异性化学裂解位点。可用于本文实施方案中的裂解多肽而不在p1’位置处留下氨基酸的蛋白酶的实例包括例如表1中列出的蛋白酶。
[0103]
表1.裂解后在p1’位置处不留下氨基酸的蛋白酶。
[0104][0105]
*紧接裂解位点的氨基酸(例如,p4-p3-p2-p1
↓
、p5-p4-p3-p2-p1
↓
等)
[0106]
因此,在特定实例中,重组多肽可以包含seq id no:30的蛋白酶识别位点。例如,重组多肽可以包含含有选自由以下组成的组的氨基酸序列的蛋白酶识别位点:seq id no:31-45(例如,seq id no:31、seq id no:34、seq id no:36、seq id no:37、seq id no:38、seq id no:40、seq id no:41、seq id no:44和seq id no:45中的任一个)。例如,用于通过肠激酶蛋白水解的重组多肽可以包含seq id no:31。作为另外的实例,用于通过胱天蛋白
no:46(ntcb裂解位点);seq id no:49,其中p1’在中性至酸性ph是pro,但在ph=2可以是gly(pd
2+
裂解位点);和seq id no:53,其中p2’和p4’优选为大体积/疏水的,并且p2’不是pro(ni
2+
识别位点)。例如,ntcb裂解位点可以包含选自由seq id no:47和seq id no:48组成的组的氨基酸序列,pd
2+
裂解位点可以包含选自由seq id no:50-52组成的组的氨基酸序列,并且ni
2+
裂解位点可以包含选自由seq id no:54-56组成的组的氨基酸序列。在特定实例中使用的化学裂解位点包括seq id no:47、seq id no:48、seq id no:50、seq id no:51、seq id no:54和seq id no:56。
[0114]
因此,包含含有产物肽的串联单元的重组多肽由氨基酸序列限定,该氨基酸序列在特定实施方案中取决于串联单元中的第一蛋白酶(例如,具有两个或四个碱性氨基酸识别位点的蛋白酶,或在裂解产物中不留下p1’氨基酸的蛋白酶)和羧肽酶或化学裂解剂的选择。
[0115]
在特定实例中,包含根据第一方面的单元的重组多肽包含氨基酸序列[产物肽n]-[(seq id no:1)-l
nk-(seq id no:1)]-[产物肽
n+1
],其中n对应于该单元在多肽中的位置(例如,如果多肽中的第三和第四产物肽被(seq id no:1)-l
nk-(seq id no:1)分开,n=3,并且n+1=4)。在包含根据第一方面的单元的重组多肽的具体实例中,使用kexin、神经内分泌转化酶1、弗林蛋白酶或蛋白质转化酶作为具有2个或4个碱性氨基酸识别位点的蛋白酶,重组多肽可以例如包括:[产物肽]-[(seq id no:18)-l
nk-(seq id no:18)]-[产物肽]。
[0116]
在特定实例中,包含根据第二方面的单元的重组多肽可以包括例如[产物肽n]-c.c.s.-l
nk-p.c.s.-[产物肽
n+1
],其中c.c.s.包括seq id no:46、seq id no:49或seq id no:53,并且p.c.s.是seq id no:30。在包含根据第二方面的单元的重组多肽的具体实例中,使用胱天蛋白酶-3或胱天蛋白酶-7作为在裂解产物中不留下p1’氨基酸残基的蛋白酶,重组多肽可以例如包括以下氨基酸序列中的至少一种:[产物肽n]-[((seq id no:46)
↓
l
nk
)-(seq id no:33)-产物肽
n+1
](用于用ntcb的化学裂解);[产物肽n]-[(
↓
(seq id no:49)-l
nk
)-(seq id no:33)-产物肽
n+1
](用于用pd
2+
的化学裂解);和[产物肽n]-[(
↓
(seq id no:53)-l
nk
)-(seq id no:33)-产物肽
n+1
](用于用ni
2+
的化学裂解)。使用胱天蛋白酶-3或胱天蛋白酶-7作为在裂解产物中不留下p1’氨基酸残基的蛋白酶的前述实例中的p.c.s.可以是seq id no:34。在前述实例中,在裂解产物中不留下p1’氨基酸的不同蛋白酶的裂解位点的取代使多肽适应使用不同蛋白酶的应用。本文中的重组多肽可以包含前述元件的不同组合;例如,包含同一类蛋白酶的裂解位点(例如,同一蛋白酶的不同裂解位点),或包含不同蛋白酶的裂解位点(例如,分别释放不同的产物肽)。此外,在特定实施方案中,包含在多肽的串联单元中的产物肽可以是相同的肽,但是在其他实施方案中,串联单元可以包含不同的产物肽。
[0117]
本文实施方案中使用的接头序列可以包含0和50之间的任意数量的氨基酸。因此,在某些实例中,接头序列包含0、1、2、3、4、5、6、7、8、9、10、11、12、13、14、15、16、17、18、19、20、21、22、23、24、25、26、27、28、29、30、31、32、33、34、35、36、37、38、39、40、41、41、42、43、44、45、46、47、48、49或50个氨基酸。在具体实例中,接头序列的长度可以是1个或2个氨基酸。在特定实施方案中,接头序列包含小氨基酸(例如,ala、ser、gly和聚甘氨酸),例如,以增加识别位点对蛋白酶的暴露,和/或降低半胱氨酸之间二硫化物形成的可能性。例如,在cys用于ntcb裂解的情况下,接头序列中gly的存在和用于ntcb裂解的cys除了改善暴露于
蛋白水解裂解位点之外,还减少了二硫键的形成,从而使重组多肽更易于ntcb裂解。因此,我们可以说任何氨基酸,但更优选甘氨酸,并且优选丝氨酸或ala。然而,在一些实施方案中不需要ala、ser和gly的存在。对于许多应用,ala、ser和gly是大多数蛋白酶偏好的,因为暴露增加,但这不是强制性的。因此,在特定实施方案中,接头序列可以包含任何氨基酸,并且优选包含gly、ser和/或ala,更优选包含gly。在本文的实施方案中有用的接头序列的实例包括seq id no:57-83和seq id no:123。本文的具体实例包括选自由gly、seq id no:61、seq id no:62、seq id no:82、seq id no:83、seq id no:74和seq id no:123组成的组的接头序列。
[0118]
在一些实施方案中,串联单元的接头序列是相同的。然而,在另外的实例中,接头序列是不同的。应当理解,除了特定应用的特定要求之外,接头序列中氨基酸的具体身份不是关于本文实施方案的一般描述的必要方面,如已知的和在技术人员的判断范围内。
[0119]
在本文的某些实施方案中有用的包含在接头序列中的氨基酸序列的说明性和非限制性实例包括:gnsm,其中n=1-4和m=1-4(例如,[ggggs(seq id no:67)]n);kesgsvsseqlaqfrsld(seq id no:77);egkssgsgseskst(seq id no:78);gsagsaagsge(f/g)(seq id no:79),例如,gsagsaagsgef(seq id no:80)或gsagsaagsgeg(seq id no:81);a(eaaak)na(例如,包含eaaaka(seq id no:75)和aeaaak(seq id no:76)的接头序列);和(x/p)n(s/g),例如p(s/g)(seq id no:68)、ps(seq id no:57)、pg(seq id no:58)、pp(s/g)(seq id no:72)、px(s/g)(seq id no:70)、(s/g)(seq id no:71)、gly、ser、pp(s/g)(seq id no:72)、(a/k/e)(s/g)(seq id no:73)、as(seq id no:59)、ag(seq id no:60)、ks(seq id no:63)、kg(seq id no:64)、es(seq id no:65)或eg(seq id no:66)。
[0120]
具有一个或更多个带电残基的接头序列可有助于裂解序列的可及性,从而消除对变性剂的需要,从而去除对产物肽程序中使用的蛋白水解酶的任何变性作用。可选地,用于肽生产的接头和裂解序列可以共同具有至少一个带电残基和一个极性残基,以便在不使用变性剂的情况下维持裂解位点的可及性。在一些实施方案中,接头可以在裂解序列之间具有小氨基酸,诸如甘氨酸,其中裂解序列具有至少一个带电残基和一个极性残基。
[0121]
根据本文实施方案的重组多肽的串联单元中包含的产物肽可以是任何感兴趣的肽。在特定实施方案中,产物肽包含生物活性,并对生物体或微生物具有直接或间接作用。例如,特定产物肽可以具有肽激素活性和/或受体结合活性、蛋白质或受体修饰活性,或者可以防止受体或蛋白质被另一个分子激活、抑制或修饰。在一些实例中,产物肽对代谢综合征具有直接或间接的作用(例如,调节胆固醇水平、血压水平、胰岛素水平、情绪、饱腹感和/或代谢疾病和/或与个人护理或治疗应用相关的生物活性)。
[0122]
产物肽可以具有任何大小,但通常包含少于1500个氨基酸;例如,少于1000个氨基酸、少于800个氨基酸、少于700个氨基酸、少于600个氨基酸、少于500个氨基酸、少于400个氨基酸、少于300个氨基酸、少于250个氨基酸、少于200个氨基酸、少于150个氨基酸、甚至少于140个氨基酸、少于130个氨基酸、少于120个氨基酸、少于110个氨基酸、少于100个氨基酸、少于90个氨基酸、少于80个氨基酸、少于70个氨基酸、少于60个氨基酸、或少于或等于50个氨基酸。在具体实例中,产物肽具有少于50个氨基酸;例如49、48、47、46、45、44、43、42、41、40、39、38、37、36、35、34、33、32、31、30、29、28、27、26、25、24、23、22、21、20、19、18、17、16、15、14、13、12、11或10个或更少的氨基酸。在特定实施方案中,产物肽包含至少一个甲硫
氨酸残基、至少一个半胱氨酸残基或甲硫氨酸和半胱氨酸残基两者中的至少一个;这样的肽不能通过使用在接头肽中引入n-末端半胱氨酸和c-末端甲硫氨酸从串联重复序列产生肽的某些方法有效地产生。
[0123]
可使用本文的组合物和方法产生的代表性肽包括胰高血糖素、艾塞那肽、舍莫瑞林、奈西立肽(利尿钠肽b)、替度鲁肽、[cys(acm)20,31]表皮生长因子(20-31)、ace2α1螺旋序列、t1肽、gtp结合蛋白片段,gα、l-选择素肽、肽标准品1、acth(1-39)(acthar)、acth(1-24)、西那普肽(sinapultide)(kl4)、替度鲁肽、胸腺法新(thymalfasin)、载脂蛋白b合成肽、甘丙肽、tau肽(45-73)(外显子2/插入1结构域)、来匹卢定(lepirudin)、普兰利肽、降钙素、半胱氨酸蛋白酶抑制剂、生长抑素、megainin 1、megainin 2、促肾上腺皮质激素、特立帕肽、替莫瑞林、抑肽酶、比伐卢定、恩夫韦肽、促胰液素、短杆菌素d、格拉默、加压素和催产素。
[0124]
如先前指示的,本文中的重组多肽还可以包含至少一个不形成中间肽产物一部分的肽单元;例如,在多肽的n-末端或c-末端,或在接头序列中(例如,在接头序列中的his6标签,为生产和/或纯化过程提供灵活性)。在本文中称为“标签”的这样的肽单元可以赋予或增加重组多肽上的任何一种或更多种期望的功能;例如,检测、纯化、增溶、防止降解、适当折叠(伴侣活性)、翻译后修饰、n-末端或c-末端加帽(加帽单元优选比蛋白质的其余部分更亲水,并且因此屏蔽疏水部分以增加溶解性)((kohl等人.(2003)proc.natl.acad.sci u.s.a.100:1700-5))、受体活性、信号传导活性、分泌和靶向。在特定实例中,重组多肽包含促进多肽纯化(例如亲和纯化)和/或增溶的标签。在其中重组多肽将从宿主细胞分泌的应用中,可以向多肽中添加适当的信号肽,以便将合成的多肽导向宿主细胞的分泌途径。这样的信号肽是本领域已知的,并且通常可以使用异源信号肽和宿主细胞天然的信号肽。前述肽标签的非限制性实例是熟知的,并且是在本领域中通常使用的;例如硫氧还蛋白(trxa)、his6、myc、t7、hsv、v5、ha、flag、strep-标签、gfp、几丁质结合蛋白、gst、mbt、nusa、if2、纤维素结合模块、芽孢杆菌rna酶、igg结合结构域zz、gb1和sumo。用于本文方法的重组多肽可以在任何重组表达系统中产生;例如,在细胞培养物中,或在无细胞系统中,诸如细胞裂解物或偶联转录/翻译系统中,并且然后从其纯化,例如但不限于,通过用结合包含在多肽内的标签的固定化剂(例如,小分子和抗体)亲和纯化。
[0125]
在一些实施方案中,用包含编码重组多肽(例如,可溶于细胞胞质溶胶的多肽)的多核苷酸的表达或克隆载体转染或转化宿主细胞,并在常规营养培养基中培养宿主细胞。培养条件,诸如溶质组成、温度和ph,可以从许多已知支持特定宿主细胞生长的条件的任一种中选择。一般来说,最大化细胞培养生产率的原理、方案和实用技术是熟知的,并且对本领域技术人员来说是广泛可用的。
[0126]
逆转录病毒蛋白酶通过在有限数量的位点水解病毒多聚蛋白在病毒复制中发挥重要作用。病毒蛋白酶的一般特征是缺乏不同的底物识别序列,尽管易切断键(scissile bond)侧翼的氨基酸必须具有一般特征才能被这些蛋白酶识别。在这种情况下,观察到逆转录病毒蛋白酶与其他病毒蛋白的交叉活性(如例如(2010)viruses 2010 2(1):147中所描述)。为这些蛋白酶定义了两种类型的裂解位点;类型1在p1和p1’位置处具有芳香族残基和脯氨酸,并且类型2在p1位置处具有疏水残基。此外,可以鉴定占据p2和p2’位置的氨基酸的一般特性。该特征为底物结合口袋提供了一定的灵活性,底物结合口袋可用于水解
多聚蛋白,而不随机裂解底物。例如,当hiv1蛋白酶表现为1型蛋白酶时,分别在p2和p1位置偏好asn和tyr或phe。因此,在c-末端具有asn-phe的肽如特立帕肽的重复单元可以用在p1’、p2’和p3’位置处含有pro-val-gln(seq id no:182)后跟许多氨基酸的接头肽来定制,以为在p1’位置处不留下氨基酸的另一种蛋白酶如胱天蛋白酶提供灵活性和识别。有趣的是,完全相同的hiv蛋白酶识别p2-p1位置处的val-leu、ile-met、ile-leu。这种底物识别的多样性可以在其他逆转录病毒蛋白酶中看到。因此,在hiv和其他逆转录病毒蛋白酶中观察到的对p2和p1位置处的两个连续疏水残基(seq id no:200),特别是val-leu、ile-leu和leu-leu的偏好,可以用于生产肽如分泌素的串联重复序列。在例如(2010)viruses 2010 2(1):147的图2中列举了1型和2型裂解位点。
[0127]
在一些实施方案中,多肽可以用具有蛋白水解识别序列的串联重复序列(经历有限水解)进行工程化,以产生肽标准品。例如,胱天蛋白酶在30℃大约两个小时失去活性。本领域技术人员将会理解,通过将酶应用于多肽,可以产生具有各种大小和精确分子量的肽。产生的肽标准品可用于sds-page凝胶、校准尺寸排阻和反相柱以及质谱应用。
[0128]
提供以下实施例来说明某些特定特征和/或实施方案。这些实施例不应被解释为将公开内容限制于所示例的特定特征或实施方案。
[0129]
多肽被工程化用于生产表2中列出的重组肽。多肽被工程化成包含元件“b
m”、“l
nk”和“dp”,其中bm是在两个或四个碱性残基后裂解的蛋白酶的识别位点,l
nk
是接头序列,并且dp是重组肽。多肽被工程化成包含一串具有序列b
m-l
nk-b
m-dp的单元的串联体,其中串联体串前面有序列b
m-dp或dp-bm的单元,其中串联体串前面有met残基。将多肽修饰为含有纯化标签(tag),使得多肽具有氨基酸序列[tag]
–
l
nk-(b
m-l
nk-b
m-dp)n或met
–
(dp-bm)n–
[tag]。
[0130]
表2.重组肽。
[0131]
[0132]
(iv)实施例
[0133]
实施例1:使用胱天蛋白酶-7和ntcb生产胰高血糖素
[0134]
将重组多肽工程化为使用胱天蛋白酶-7和ntcb产生由靶氨基酸序列hsqgtftsdyskyldsrraqdfvqwlmnt(seq id no:84)组成而不含无关氨基酸的胰高血糖素。多肽被工程化成包含间隔的四个重复序列,其中三个肽重复序列分别具有半胱氨酸的化学裂解位点,随后是甘氨酸和devd序列作为胱天蛋白酶识别序列(图4)。在接头序列中使用小氨基酸,特别是甘氨酸,结合使用识别大量带电氨基酸(例如devd序列中四个氨基酸中的三个带电的(asp和glu)肽)的蛋白酶(例如胱天蛋白酶-3或-7),可以促进裂解位点暴露于裂解试剂。由于胰高血糖素肽中不存在半胱氨酸,选择这种氨基酸来促进ntcb蛋白水解。选择胱天蛋白酶-7识别位点(seq id no:33)来指导酶促蛋白水解,而不在裂解产物中留下p1’氨基酸。选择包含ntcb裂解序列(seq id no:46)的氨基酸序列来指导从中间肽产物去除接头序列和胱天蛋白酶-7识别位点。在ntcb裂解序列和胱天蛋白酶-7识别位点之间放置gly
接头,以增加胱天蛋白酶-7识别序列的暴露,增加胱天蛋白酶裂解的效率,并降低重复序列的半胱氨酸之间二硫化物形成的可能性。在重组多肽中,蛋白酶识别位点用v形(《》)包围,化学裂解序列用大括号({})包围,并且接头用中括号([])包围:
[0135][0136]
然后将硫氧还蛋白标签添加到多肽以产生:
[0137][0138]
在30℃,加硫氧还蛋白标签的多肽在1l lb培养基中的bl21-de3大肠杆菌细胞中从dna构建体重组表达7小时。将细胞糊状物重悬于50mm tris-hcl、100mm nacl、5mm咪唑、0.5% triton x-100、ph 8.0中,然后轻柔超声处理。以20,000
×
g离心15分钟后,将上清液与ni-nta树脂在4℃孵育1小时。用50mm tris-hcl、500mm nacl、10mm咪唑、ph 8.0洗涤树脂。然后,用50mm tris-hcl,ph 8.0中300mm咪唑、10mmβ-巯基乙醇、10%甘油洗脱多肽。如通过sds-page确定的,每1l培养物获得大约100mg蛋白质的产量(图5a、图5b)。
[0139]
在30℃用1mg重组加组氨酸标签的胱天蛋白酶-7处理纯化的多肽4小时,在seq id no:34识别位点裂解多肽。使用配备有biorad hipore c18柱的agilent 1260infinity hplc系统从硫氧还蛋白标签和蛋白酶分离期望的肽。因此,在0.1%三氟乙酸或甲酸中以1ml/min的流量从5%到90%建立20分钟的乙腈梯度。在这些步骤结束时,成熟胰高血糖素和在其c-末端具有氨基酸序列cgdevd(seq id no:128)的胰高血糖素的混合物在20.4分钟的时间点获得。将肽布点在maldi平板上,然后添加等体积的饱和chca基质。然后在irvine大学质谱设施中使用ab sciex 5800maldi-tof质谱仪,使用tof/tof系列探索者软件v4 build 8确定肽的质量(图5c)。质谱分析前,根据制造商方案,使用rainin pt-c18-96 ps c18 10μl尖头对不是通过c18反相柱获得的样品进行脱盐。
[0140]
为了从胰高血糖素中间肽的c-末端释放cgdevd(seq id no:128),在氩气下用1mm二硫苏糖醇(dtt)或10
×
至20
×
摩尔过量的ekathiol还原半胱氨酸,同时在室温、ph=8摇动2小时。将含有还原蛋白的上清液转移到含有5倍至10倍于巯基基团数量的ntcb的新试管中。将试管在氩气下密封,并在40℃孵育60分钟。然后,使用旋转柱或c18反相hplc系统过滤出试剂。最后,通过tris碱将ph增加到9并在37℃孵育16个小时后,在seq id no:48ntcb裂解位点完成氰基化肽或蛋白质的裂解。鉴于胰高血糖素以组氨酸开始,该实验显示,即使p1’残基不是小氨基酸如gly、ala、ser或芳香族残基时,胱天蛋白酶-7也有效地裂解嵌合蛋白,如先前指示的(fuentes-prior&salvesen biochem j.2004dec 1;384(pt 2):201
–
232)。此外,前体蛋白几乎完全消化成三个主要片段,证实了所有设计的胱天蛋白酶-3/-7识别序列都被该酶加工。最后,有限水解产生所有预期的片段,指示所有设计的酶识别位点
或多或少以相似的程度与蛋白酶接触,并且没有建立分子内和分子间的二硫键,二硫键将限制设计的蛋白水解序列对蛋白酶的接触。最后,以可溶形式生产蛋白质证实了蛋白质的正确设计,防止可能导致不溶性纠缠沉淀的分子间二硫键形成。
[0141]
实施例2:使用胱天蛋白酶和化学裂解剂生产胰高血糖素
[0142]
将多肽工程化为使用胱天蛋白酶和pd
2+
产生不含无关氨基酸的胰高血糖素。由于胰高血糖素也缺乏脯氨酸,所以使用脯氨酸-组氨酸二肽代替选择半胱氨酸作为化学裂解位点。加硫氧还蛋白标签的胰高血糖素串联重复序列被工程化成包含胱天蛋白酶识别位点(seq id no:32)、包含pd
2+
化学裂解序列的氨基酸序列(seq id no:50)和接头序列(seq id no:61),产生如下加硫氧还蛋白标签的多肽氨基酸序列:
[0143][0144]
将含有胰高血糖素肽的加硫氧还蛋白标签的多肽在bl21-de3大肠杆菌中表达,每1l培养物的产量为大约100mg蛋白质。如实施例1中描述的,用胱天蛋白酶-7进行多肽的纯化和处理:融合蛋白以可溶性形式产生,并使用ni-nta柱纯化。然后用胱天蛋白酶-7处理,胱天蛋白酶-7将蛋白质在seq id no:34识别位点裂解成其组分。使用ni-nta亲和柱从反应混合物去除硫氧还蛋白标签和胱天蛋白酶-7,两者都具有组氨酸标签。在这些步骤结束时,获得成熟胰高血糖素和胰高血糖素与在其c-末端包含胰高血糖素、胱天蛋白酶识别位点、接头序列和pd
2+
裂解位点phggdevd(seq id no:131)的中间肽产物的混合物。为了从胰高血糖素的c-末端释放phggdevd(seq id no:131),用等摩尔量的pd(ii)在ph 2处理混合物2小时,在pro-his pd
2+
化学裂解位点处裂解中间肽产物。然后,使用旋转柱或c18反相hplc系统过滤试剂。
[0145]
接下来,将多肽工程化为具有硫氧还蛋白标签和包含胰高血糖素肽、胱天蛋白酶-7识别序列(seq id no:33)、ni
2+
化学裂解位点(seq id no:53)和gly接头的四个重复序列,产生以下序列:
[0146][0147]
在用胱天蛋白酶-7处理以在seq id no:34处裂解,并去除硫氧还蛋白标签和蛋白酶之后,在50℃将20mm的重组蛋白与100mm hepes缓冲液,ph 8.2中2mm nicl2和120mm nacl中一起孵育过夜,在seq id no:56化学裂解位点处裂解中间肽产物以从胰高血糖素的
c-末端去除无关氨基酸srhwgdevd(seq id no:134)。
[0148]
实施例3:使用kexin与羧肽酶生产利拉鲁肽
[0149]
将多肽工程化为产生由靶氨基酸序列haegtftsdvssylegqaakeefiawlvrgrg(seq id no:110)组成的利拉鲁肽。由于利拉鲁肽中不存在两个连续的碱性残基,该多肽被工程化成包含四个包含利拉鲁肽的肽重复序列和由gly-ser接头分开的两个kexin识别位点(seq id no:2)。将硫氧还蛋白标签添加到n-末端以促进多肽的纯化:
[0150][0151]
用kexin处理纯化的重组多肽以在蛋白酶识别位点裂解多肽,产生成熟形式的利拉鲁肽和中间肽产物的混合物,所述中间肽产物包含在c-末端具有两个碱性残基(rr或kr)的利拉鲁肽。用羧肽酶b处理这些中间肽去除了这些额外的碱性氨基酸,产生成熟的利拉鲁肽。
[0152]
将包含利拉鲁肽的加硫氧还蛋白标签的多肽于37℃在1l lb培养基中在bl21-de3细胞中表达7个小时。将细胞糊状物重悬于50mm tris-hcl、100mm nacl、5mm咪唑、0.5% triton x-100、ph 8.0中,然后轻柔超声处理。以20,000
×
g离心15分钟后,将上清液与ni-nta树脂在4℃孵育1小时。用50mm tris-hcl、500mm nacl、10mm咪唑、ph 8.0洗涤树脂。接下来用50mm tris-hcl中的300mm咪唑(ph,8.0)、10mmβ-巯基乙醇、10%甘油洗脱蛋白质。通过sds-page确定多肽的纯度。
[0153]
用100u加组氨酸标签的kex2蛋白酶在37℃在200mm bis-tris缓冲液,ph=7,加0.01%triton x-100、1mm cacl2中处理纯化的多肽4小时,在arg-arg和lys-arg kexin识别位点裂解多肽。将反应物与ni-nta柱孵育60分钟以去除标签和加his标签的蛋白酶。短暂离心后,将上清液转移到新试管中,在试管中添加羧化酶b,并在23℃孵育60分钟。最后,使用c8或c18柱通过反相hplc从接头序列和个体氨基酸纯化利拉鲁肽。
[0154]
实施例4:使用胱天蛋白酶和pd2+生产利拉鲁肽
[0155]
利拉鲁肽不具有脯氨酸,这允许该氨基酸被包含在pd
2+
离子的裂解位点中。此外,不存在胱天蛋白酶识别位点。因此,工程化了用于使用胱天蛋白酶-3或胱天蛋白酶-7和pd
2+
生产利拉鲁肽的多肽,并添加n-末端硫氧还蛋白纯化标签:
[0156][0157]
纯化的重组蛋白首先用胱天蛋白酶-3或胱天蛋白酶-7消化,以在胱天蛋白酶-3/胱天蛋白酶-7识别位点(seq id no:33)裂解多肽,并且由于在胱天蛋白酶和标签中都存在六组氨酸,用ni-nta柱去除标签和胱天蛋白酶。接下来,用pd
2+
离子处理得到的中间产物肽haegtftsdvssylegqaakeefiawlvrgrgphggdevd(seq id no:140),这在pd
2+
化学裂解序列(seq id no:50)处裂解中间肽以从c-末端去除无关氨基酸,产生利拉鲁肽。
[0158]
如实施例1中描述的产生和纯化含有串联重复序列与利拉鲁肽的加硫氧还蛋白标签的多肽:在30℃在50mm hepes、ph 7.4、100mm nacl、10%甘油、0.1mm edta、10mm二硫苏糖醇和0.1% chaps中用1mg重组加his6标签的胱天蛋白酶-7蛋白酶处理纯化的蛋白质4小时,这在seq id no:34处裂解多肽。将反应物与ni-nta树脂孵育60分钟以去除标签和蛋白酶。短暂离心后,将上清液转移到新试管中,向试管中添加等摩尔量的顺式-[pd-(en)(h)2o)4]
2+
、pd(ii)试剂,并在60℃,ph 4孵育过夜,其在seq id no:51处裂解中间肽产物。最后,使用c8或c18柱通过反相hplc从接头序列和个体氨基酸纯化利拉鲁肽。
[0159]
在另一个实例中,cys取代了pro-his二肽,并且使用ntcb去除无关氨基酸。
[0160]
实施例5:使用胱天蛋白酶和ni
2+
生产胰岛素
[0161]
胰岛素的成熟形式由通过两个二硫键连接的b链和a链组成。
[0162]
胰岛素链-b:fvnqhlcgshlvealylvcgergffytpkt(seq id no:108)
[0163]
胰岛素链-a:giveqcctsicslyqlenycn(seq id no:107)
[0164]
为了产生胰岛素,将含有两个重复链-a和两个重复链-b的多肽工程化为用胱天蛋白酶和ni
2+
处理分离,其含有胱天蛋白酶识别位点(seq id no:32)、ni
2+
化学裂解位点(seq id no:53)和gly接头,使得多肽具有以下序列:
[0165][0166]
纯化的重组多肽首先在胱天蛋白酶识别位点用胱天蛋白酶-3或胱天蛋白酶-7消化,并且用ni-nta柱去除胱天蛋白酶。接下来,用ni
2+
离子处理所得的中间肽产物,这从c-末端去除了无关的srhwgdevd(seq id no:134)氨基酸,产生胰岛素b-链肽和a-链肽的混合物。
[0167]
于30℃在50mm hepes、ph 7.4、100mm nacl、10%甘油、0.1mm edta、10mm二硫苏糖醇和0.1% chaps中用1mg重组加组氨酸标签的胱天蛋白酶-7蛋白酶处理纯化的多肽4小时,在seq id no:127处裂解多肽,产生包含胰岛素b-链或胰岛素a-链和seq id no:134的
中间肽产物。将反应物与ni-nta树脂孵育60分钟以去除蛋白酶。短暂离心后,于45℃将上清液与100mm hepes缓冲液,ph 8.2中0.5mm nicl2一起孵育过夜,在seq id no:56处裂解中间肽产物,从c-末端去除无关氨基酸(seq id no:134)。最后,使用c8或c18柱通过反相hplc从接头序列和个体氨基酸纯化胰岛素肽。
[0168]
实施例6:使用kexin和羧肽酶生产胰岛素
[0169]
为了使用kexin和羧肽酶产生胰岛素,设计了包含链-a的两个重复和链-b的两个重复的多肽,其中重复序列在胰岛素链肽的c-末端包含被接头序列(seq id no:62)分开的两个kexin识别位点(seq id no:2)。所得多肽包括以下氨基酸序列:
[0170][0171]
含有胰岛素b链和a链重复序列的多肽在1l lb培养基中于37℃在bl21-de3细胞中表达7个小时。将细胞糊状物重悬于50mm tris-hcl、100mm nacl、5mm咪唑、0.5% triton x-100、ph 8.0中,然后轻柔超声处理。以20,000
×
g离心15分钟后,将上清液与ni-nta树脂在4℃孵育1小时。用50mm tris-hcl、500mm nacl、10mm咪唑、ph 8.0洗涤树脂。接下来用50mm tris-hcl中的300mm咪唑(ph,8.0)、10mmβ-巯基乙醇、10%甘油洗脱蛋白质。通过sds-page确定多肽的纯度。
[0172]
于37℃在200mm bis-tris缓冲液,ph 7,加0.01% triton x-100,1mm cacl2中用100u加组氨酸标签的kex2蛋白酶处理纯化的多肽4小时,在seq id no:3和seq id no:4处裂解多肽,得到中间肽产物fvnqhlcgshlvealylvcgergffytpkt《rr》(seq id no:143)和giveqcctsicslyqlenycn《rr》(seq id no:144)。将反应物与ni-nta柱孵育60分钟,以去除加his标签的蛋白酶。短暂离心后,将上清液转移到新试管中,在试管中添加羧肽酶b,并在23℃孵育60分钟去除c-末端arg-arg二肽。最后,使用c8或c18柱通过反相hplc从接头序列和个体氨基酸纯化胰岛素肽。
[0173]
实施例7:使用蛋白酶生产特立帕肽
[0174]
特立帕肽不具有脯氨酸,并且最后两个氨基酸以天冬酰胺和苯丙氨酸终止,天冬酰胺和苯丙氨酸是包括hiv-1蛋白酶在内的许多逆转录病毒蛋白酶的偏好序列。这允许在最后一个氨基酸后立即包含脯氨酸作为hiv-1蛋白酶的裂解位点。此外,不存在胱天蛋白酶裂解位点,因此将具有n-末端标签的重组多肽工程化为用于使用胱天蛋白酶-3或胱天蛋白酶-7和hiv蛋白酶生产特立帕肽,其包含胱天蛋白酶-3/胱天蛋白酶-7裂解位点(seq id no:33)、hiv-蛋白酶裂解位点和重复单元n-末端处的pro-异亮氨酸-丝氨酸:
[0175][0176]
在本实施例中可以理解,ser残基可以用作hiv1-蛋白酶识别序列的一部分和接头序列的一部分二者。特立帕肽c-末端处的nf二肽和作为接头序列的pis设计的组合产生了
hiv1-蛋白酶识别序列。因此,在大肠杆菌中设计并产生以下嵌合蛋白:
[0177]
msdkiihltddsfdtdvlkadgailvdfwaewcgpckmiapildeiadeyqgkltvaklnidqnpgtapkygirgiptlllfkngevaatkvgalskgqlkefldanlagsgsghmhhhhhhssglvprgsgmketaaakferqhmdspdlgtddddkamadigsgdevdsvseiqlmhnlgkhlnsmervewlrkklqdvhnfpisdevdsvseiqlmhnlgkhlnsmervewlrkklqdvhnfpisdevdsvseiqlmhnlgkhlnsmervewlrkklqdvhnfpisdevdsvseiqlmhnlgkhlnsmervewlrkklqdvhnf(seq id no:191)(图6a)。
[0178]
使用胱天蛋白酶-3或胱天蛋白酶-7对seq id no:191的重组多肽进行蛋白水解,在seq id no:34处裂解多肽,产生成熟特立帕肽和中间肽产物svseiqlmhnlgkhlnsmervewlrkklqdvhnfpisdevd(seq id no:192)的混合物(图6a)。hiv-1蛋白酶催化的蛋白水解去除无关的pisdevd(seq id no:193)氨基酸以产生成熟的特立帕肽(图6b)。胱天蛋白酶-3处理的用硫氧还蛋白加标签的特立帕肽的四个重复序列的hplc分析产生五个峰(图6c)。在3.8分钟和5.9分钟的峰是杂质,而在20.2分钟、20.4分钟和22.8分钟的峰分别属于特立帕肽、其重复单元和硫氧还蛋白标签。通过maldi-tof质谱仪获得的20.2处和20.4处洗脱峰的质量证实了,特立帕肽及其重复单元确实在指定的时间点被洗脱(图6d)。
[0179]
具有n-末端标签的多肽也被工程化为用于使用kexin和羧肽酶b生产利拉鲁肽,其包含kexin裂解位点(seq id no:3和seq id no:4)和羧肽酶c裂解位点:
[0180][0181]
使用kexin对seq id no:148的重组多肽进行蛋白水解,在seq id no:3和seq id no:4处裂解多肽,产生成熟利拉鲁肽和中间肽产物haegtftsdvssylegqaakeefiawlvrgrg(seq id no:110)和haegtftsdvssylegqaakeefiawlvrgrg《rr》(seq id no:194)的混合物。羧肽酶c催化的蛋白水解去除无关的rr和kr氨基酸以产生成熟的利拉鲁肽。
[0182]
具有n-末端标签的多肽也被工程化为用于使用肠激酶和ni
2+
生产利拉鲁肽,其包含肠激酶裂解位点(seq id no:31)、ni
2+
裂解位点和接头序列:
[0183][0184]
使用肠激酶对seq id no:153的重组多肽进行蛋白水解,在seq id no:31处裂解多肽,产生成熟利拉鲁肽和中间肽产物haegtftsdvssylegqaakeefiawlvrgrgsrhwg《ddddk》(seq id no:155)的混合物。ni
2+
催化水解去除了无关的srhwgddddk(seq id no:154)氨基酸以产生成熟的利拉鲁肽。
[0185]
从上述重组多肽生产和纯化利拉鲁肽后,分别用胱天蛋白酶-3或胱天蛋白酶-7、kexin或肠激酶以及羧肽酶c顺序或同时处理多肽,并将所得成熟肽与接头序列一起进行反相色谱以进一步纯化。
[0186]
实施例8:使用胱天蛋白酶、kexin和羧肽酶生产胰岛素
[0187]
为了使用胱天蛋白酶、kexin和羧肽酶产生胰岛素,将若干种加his标签的多肽工程化为包含两个、三个、四个或七个包含胰岛素b-链或a-链亚基、胱天蛋白酶识别位点(seq id no:32)、kexin识别位点(seq id no:2)和接头序列(seq id no:82或seq id no:83)的重复序列。
[0188]
2个a-链和b-链亚基:
[0189][0190]
3个a-链和b-链亚基:
[0191][0192]
4个a-链和b-链亚基:
[0193][0194]
7个a-链和b-链亚基:
[0195][0196]
当纯化的蛋白质附接到ni-nta柱时,用kexin和羧肽酶b处理任何多肽。kexin在seq id no:3和seq id no:4处裂解多肽以产生中间肽:
[0197][0198]
和成熟胰岛素a-链(seq id no:107),而羧肽酶b也去除无关的c-末端氨基酸以产生以下产物混合物:
[0199][0200]
和成熟胰岛素a-链(seq id no:107)。
[0201]
然后用pbs缓冲液洗涤柱。这去除了接头肽和碱性氨基酸。然后,将加his标签的胱天蛋白酶-7添加到柱,导致加his标签的前肽在seq id no:34处从成熟胰岛素水解。由于水解,成熟的胰岛素从柱释放。
[0202]
实施例9:使用胱天蛋白酶和羧肽酶在经遗传修饰产生kexin的宿主中生产胰岛素
[0203]
为了在经遗传修饰以产生kexin的宿主中使用胱天蛋白酶、kexin和羧肽酶产生胰岛素,将含有b-链和a-链胰岛素亚基重复序列的几种多肽工程化为包含胱天蛋白酶识别序列(seq id no:32)、kexin识别序列(seq id no:2)和接头序列(seq id no:74或seq id no:123):
[0204][0205]
根据制造商的说明,使用pichia
tm
表达系统(validogen)进行本实施例中成熟胰岛素的生产和加工。使用电穿孔将含有编码工程化多肽的多核苷酸的pic3.5载体克隆转化到pichia
tm
巴斯德毕赤酵母菌株中。通过实时pcr筛选转化体是否存在构建体的dna序列,并将表现出最高水平的克隆用于扩大规模。对于大规模生产,于30℃将细胞在500ml缓冲的微量甘油培养基中培养过夜,通过离心收获,洗涤并重悬于50ml缓冲的微量甲醇培养基中。16小时后收获培养上清液,并如先前对胰高血糖素描述的纯化重组多肽。
[0206]
因为遗传修饰的宿主菌株产生缺乏er信号传导序列和跨膜区的kexin(kex2),所以seq id no:164的多肽在宿主内部在seq id no:3处被裂解,产生中间肽产物ghhhhhhdevdfvnqhlcgshlvealylvcgergffytpktrr(seq id no:166)和hhhhhhdevdgiveqcctsicslyqlenycnrr(seq id no:167)。
[0207]
类似地,seq id no:165的多肽在宿主内部在seq id no:3处被裂解,产生中间肽ghhhhhhdevdgiveqcctsicslyqlenycnrr(seq id no:168)和hhhhhhdevdfvnqhlcgshlvealylvcgergffytpktrr(seq id no:169)。
[0208]
用羧肽酶b和胱天蛋白酶-7的组合顺序或同时处理前述所得肽混合物中的任一种,产生胰岛素链a和链b,没有任何无关氨基酸。
[0209]
在另一个实例中,对宿主进行遗传修饰以除kexin之外还表达羧肽酶b,使得在宿主中产生的中间肽包含氨基酸序列ghhhhhhdevdfvnqhlcgshlvealylvcgergffytpkt(seq id no:170)和hhhhhhdevdgiveqcctsicslyqlenycn(seq id no:171);或者ghhhhhhdevdgiveqcctsicslyqlenycn(seq id no:172)和hhhhhhdevdfvnqhlcgshlvealylvcgergffytpkt(seq id no:173)。用胱天蛋白酶-3或胱天蛋白酶-7在seq id no:34处对这些肽的蛋白水解产生不含任何无关氨基酸的胰岛素链a和链b。
[0210]
实施例10:使用胱天蛋白酶和ni
2+
生产特立帕肽
[0211]
多肽被工程化为含有硫氧还蛋白标签和四个包含特立帕肽的重复序列、胱天蛋白酶-7(-3)识别序列(seq id no:33)、ni
2+
化学裂解位点(seq id no:53)和接头序列,产生以下序列:
[0212][0213]
于30℃在50mm hepes、ph 7.4、100mm nacl、10%甘油、0.1mm edta、5mmβme中用50微克重组加组氨酸标签的胱天蛋白酶-7处理5mg纯化的多肽过夜,在seq id no:34处裂解多肽以产生特立帕肽和与接头肽seq id no:201连接的特立帕肽(图7a)。取决于条件,产物可以以可溶或不可溶的形式获得。通过离心沉淀具有高浓度蛋白质的过夜消化样品,并将沉淀溶解在5%乙腈和0.1%三氟乙酸中。样品通过hi-pore c18 bio-rad柱进行分析。特立帕肽及其重复单元通常在20.2分钟和20.4分钟洗脱。将含有特立帕肽和附接到接头序列的特立帕肽的级分置于speedvac中以蒸发溶剂。于50℃将所得肽溶解在50mm hepes缓冲液ph 8.2中的2mm nicl2、120mm nacl中过夜,在seq id no:56化学裂解位点处裂解中间肽产物以从特立帕肽的c-末端去除无关氨基酸srhwsdevd(seq id no:202)(图7b)。裂解的程度取决于酶的浓度和底物的量(图7c)。maldi-tof-ms分析证实产生了分子量为4117.76的正确特立帕肽。将从反相柱获得的总浓度为大约200ng/微升的特立帕肽及其重复单元的混合物以10μl/分钟的流量注入thermo-q-exactive orbitrap质谱仪。原始数据由xcalibur软件在400到2000的范围内获得,并由牛津大学的unidec软件解卷积(图7e)(ref doi:10.1021/acs.analchem.5b00140.)。获得的质量与计算的分子质量非常一致。为了评估设计的胱天蛋白酶裂解位点的可及性,进行纯化的trx-ni-特立帕肽的部分水解(图7b)。胱天蛋白酶-3或-7对多肽的有限水解产生12个可能的片段,指示所有设计的酶识别位点确实以相似的程度对蛋白酶是可及的。也进行用nicl2水解纯化的trx-ni-特立帕肽。(图8a)。在1mm浓度的nicl2的最佳水解温度为50℃。分子量低于10kda的产物的maldi-tof质谱分析揭示了m/z值为5247.6和2989.7的两个主峰;前者属于特立帕肽重复单元的氧化形式,并且后者是杂质(图8b)。
[0214]
实施例11:其他感兴趣肽的生产
[0215]
含有包含下列肽的串联重复序列的重组多肽以上文针对胰高血糖素、利拉鲁肽和胰岛素详细描述的方式进行工程化。使用蛋白酶和羧肽酶或蛋白酶和蛋白水解化学剂的组合从多肽分离产物肽(也如所述进行):
[0216]
艾塞那肽、舍莫瑞林、奈西立肽(利尿钠肽b)和替度鲁肽;这些肽不能使用在含有串联重复序列的多肽的接头肽中引入n-末端半胱氨酸的方法来产生,因为肽的n-末端在裂解反应期间被亚氨基噻唑烷-羧基基团修饰以释放产物肽。
[0217]
[cys(acm)20,31]表皮生长因子(20-31);使用本文实施方案产生该肽在产物中保留了标签,如果接头序列中包含kex2以外的蛋白酶,该标签可用于纯化。
[0218]
ace2α1螺旋序列;ace2肽酶结构域(pd)α1螺旋对于结合刺突(s)蛋白的sars-cov-2-rbd是重要的。选自ace2α1螺旋序列的23个残基ieeqaktfldkfnheaedlfyqs(seq id no:
111)以亚纳摩尔结合特异性识别sars-cov-2-rbd。这种肽与sars-cov-2-rbd的结合可以阻断病毒进入宿主细胞。使用本文的实施方案生产该肽允许生产包含含有该肽的串联重复序列的多肽,该串联重复序列多肽可用于免疫以产生针对covid-刺突蛋白受体的中和抗体。
[0219]
t1肽、gtp结合蛋白片段gα、l-选择素、肽标准品1(氨基酸分析);这些肽都含有内部cys和met氨基酸两者,并且因此无法通过常规方法以它们的精确序列表达。
[0220]
虽然说明书描述了本发明的特定实施方案,但是本领域普通技术人员可以在不脱离本发明概念的情况下设计本发明的变化形式。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1