一种重组胶原重复序列蛋白的表达及其应用的制作方法
本发明涉及生物蛋白质,尤其涉及一种重组胶原重复序列蛋白的表达及其应用。
背景技术:
1、胶原蛋白是人体的皮肤、软骨、牙齿肌腱、韧带、内脏和血管的主要组成成分,是哺乳动物中最丰富的蛋白质之一(占总蛋白质量的25%-30%)。胶原蛋白是一种结构蛋白,能够起到支持、保护、连接等多种作用,其三螺旋结构是理化特性以及生物活性的基础,螺旋区段最大特征是氨基酸呈现gly-x-y重复序列(x和y通常分别是脯氨酸和4-羟基脯氨酸),能够形成链间氢键和静电相互总用,使得胶原蛋白的三螺旋结构更为稳定。我们人体正常皮肤中的胶原主要以i和iii型的胶原纤维形式存在,作用在皮肤的真皮层,维持着人体皮肤的正常组织结构,i型胶原蛋白纤维直径较粗,排列紧密,呈现致密的条束状,是构成皮肤的主体,iii型胶原蛋白是由三条α1(ⅲ)链(col3a1)组的同源三聚体,纤维较细,呈疏网状,散布于i型胶原周围,起支撑组织,维持皮肤弹性的作用,还具有保护血管神经,改善细胞微环境,促进伤愈合,减轻皮肤炎症的作用。
2、与i型胶原蛋白可通过刺激纤维细胞的方式促进新生不同,iii型胶原蛋白是骨髓细胞来源,当成年骨闭合后之后就会无法自体再生,虽然胶原蛋白的提取方法多种多样,但动物源胶原蛋白均为i型,且存在免疫原性、均一性差、传染病隐患等多个弊端,从动物组织提取iii型胶原蛋白仍存在难度大、纯度低、成本高等严峻问题,而通过基因工程技术制备的重组胶原蛋白与动物源胶原蛋白相比,降低了排斥反应、免疫原性以及病毒感染的风险,是目前解决胶原蛋白来源问题最有潜力的方法,如何通过基因工程开发一种免疫原性低、活性高的iii性胶原蛋白是亟需解决的技术问题。
技术实现思路
1、本发明提出了一种重组胶原重复序列蛋白的表达及其应用,构建了重组胶原重复序列蛋白的表达载体,包括三种含重复单元的氨基酸表达序列,以及组氨酸标签、融合标签、蛋白酶切割位点序列,蛋白表达量高,制成了促进小鼠胚胎成纤维细胞迁移活性较高的重组胶原重复序列蛋白。
2、本发明是通过以下技术方案实现的:
3、一种重组胶原重复序列蛋白,包括的氨基酸序列为cr1、cr2、cr3中的一种。
4、进一步的,所述cr1由310个氨基酸组成,基本重复单元为:gakgepgprgergeagipgvpgakgedgkd,来自人iii型胶原蛋白438~467的肽段,c端含有iii型胶原1191-1200片段,氨基酸序列如seq id no:1所示,dna序列如seq id no:2所示。
5、进一步的,所述cr2由430个氨基酸组成,基本重复单元为gergetgppgpagfpgapgqngepggkgergapgekgeggpp,来自人iii胶原蛋白798~839的肽段,c端含有iii型胶原1191-1200片段,氨基酸序列如seq id no:3所示,dna序列如seq id no:4所示。
6、进一步的,所述cr3,基本重复单元为gergppgpmgppgl agppgesgregap,由280个氨基酸组成,来自人i胶原蛋白992~1018对的肽段, c端含有iii型胶原1191-1200片段,氨基酸序列如seq id no:5所示,dna序列如seq id no:6所示。
7、本发明还提出了一种重组胶原重复序列蛋白的表达方法,步骤如下:
8、(1) 合成重组胶原重复序列蛋白cr1-3的dna序列;
9、(2) 将步骤(1)所述dna序列进行密码子优化后,拼接重组到表达载体上,酶切位点为ncoi和xhoi,于转化平板上转化细菌,构建重组基因工程菌;
10、(3) 从转化平板上选出单斑克隆菌,采用50 ml lb培养基(含100 mg/l氨苄),在37℃条件下过夜培养;
11、(4) 按照1:40的比例将步骤(3)所述单斑克隆菌转接至2 l lb培养基(含100 mg/l氨苄)中,37℃条件下培养至600nm波长处的吸光值(od600)为0.4-0.6,加入0.5 mm iptg在20℃条件下诱导蛋白的表达,得到混合菌液;
12、(5) 将步骤(4)所述混合菌液经7000 rpm离心10 min,收集菌体,菌体沉淀加入10mm咪唑pbs溶液(ph7.5)重悬,高压破碎细菌,4°c,11000 rpm离心15 min,取上清与平衡好的5 ml镍柱孵育,重力洗脱,用10 mm pbs溶液(ph7.5)洗去杂蛋白,300 mm咪唑的pbs溶液(ph7.5)进行洗脱,超滤管超滤进行浓缩并除去咪唑,得到前体重组胶原重复序列蛋白的pbs溶液;
13、(6) 按1 mg:2 u的比例向前体重组胶原重复序列蛋白pbs溶液加入蛋白酶,4℃过夜反应,sds-page检测反应完全,蛋白混合溶液与镍柱孵育,除掉标签蛋白和酶,即得改性前重组胶原重复序列蛋白溶液;
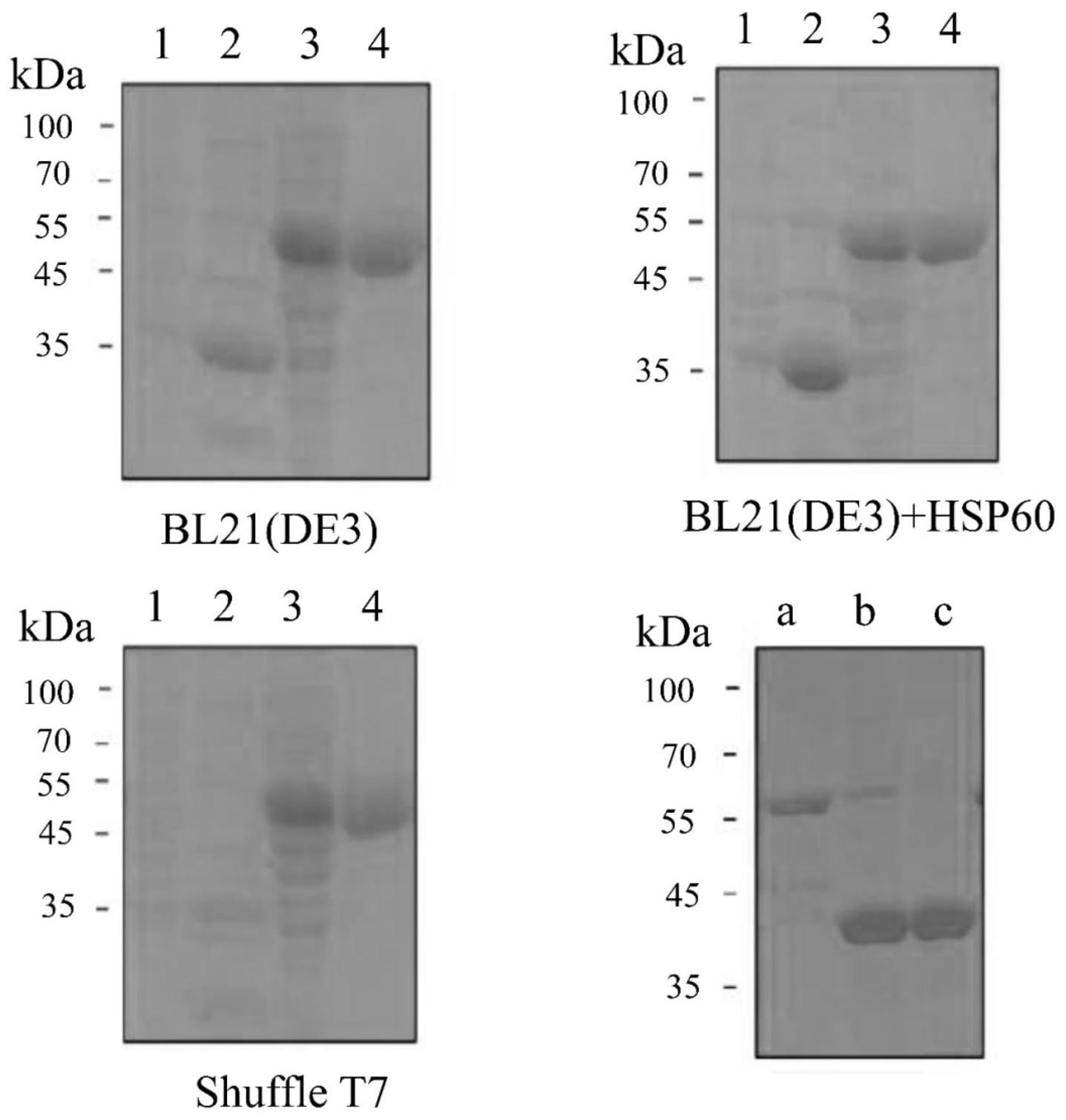
14、(7) 将步骤(6)所得改性前重组胶原重复序列蛋白溶液于磷酸盐缓冲溶液(ph=9.0)在4°c透析3 d,按体积比10:1的比例加入含有辛烯基琥珀酸酐的二甲基亚砜,每毫升二甲基亚砜加入20 mg辛烯基琥珀酸酐,反应体系在15°c下搅拌4 h后,在4°c下与去离子水透析3 d,制得重组胶原重复序列蛋白溶液。
15、进一步的,步骤(2)所述表达载体为pet32a(+),细菌为大肠杆菌。
16、进一步的,所述pet32a(+)表达载体包括组氨酸标签、融合标签(seq id no:7-12)和蛋白酶切割位点的氨基酸序列(seq id no:13-17)。
17、进一步的,所述融合标签为麦芽糖结合蛋白(mbp)、 半胱氨酸蛋白酶(cpd)、 谷胱甘肽巯基转移酶(gst)、 本载脂蛋白格a1(apoi)、 硫氧还蛋白(trxa)、绿色荧光蛋白(gfp)、杂交融合标签中的一种。
18、进一步的,所述蛋白酶切割位点序列为烟草蚀纹病毒酶切序列(tev)、凝血酶切序列(thrombin)、肠激酶切序列(ek)、因子xa酶切序列(factor-xa)、鼻病毒3c酶切序列(hrv3c)中的一种。
19、进一步的,所述大肠杆菌为bl21 (de3)、bl21 (de3) plyss、bl21star (de3)、bl21star (de3) plyss、rosetta (de3)、rosetta (de3) plyss、origamib (de3)、origamib (de3) plyss、shuffle t7、blr (de3)、blr (de3) plyss、b834 (de3)、 b834(de3) plyss、bl21(de3)+hsp60中的一种或多种。
20、进一步的,步骤(4)所述37℃培养条件,在采用shuffle t7大肠杆菌时为30℃。
21、本发明还提供了一种重组胶原重复序列蛋白在制备促进细胞迁移活性产品和皮肤修复产品中的应用,包括以下步骤:
22、a. 将制得的重组胶原重复序列蛋白溶液于60℃、绝对压强为0.08mpa的条件下浓缩至原体积的20%,通过喷雾干燥制成胶原蛋白粉末;
23、b. 将重组胶原重复序列蛋白溶液或胶原蛋白粉末添加至细胞培养基中,可制得促进细胞迁移活性培养基,发挥促进细胞迁移的作用;
24、c. 按1 g:1 l的比例,将胶原蛋白粉末与蒸馏水混匀,涂抹至皮肤受损处,此外还可将胶原蛋白粉末添加至护肤品或药用敷料中,发挥皮肤修复的效果。
25、进一步的,本发明所述的dna和氨基酸序列如下所示:
26、<cr1; aa; seq id no:1>:
27、gakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgakgepgprgergeagipgvpgakgedgkdgapgpccggv;
28、<cr1; dna; seq id no:2>:
29、ccatggctggtgcaaaaggcgaaccgggtccgcgtggtgaacgcggtgaagcaggtattccgggtgtgccgggcgcaaaaggcgaggatggtaaagatggtgcaaaaggtgaaccgggtcctcgcggtgaacgtggcgaagccggcattccgggtgttccgggcgccaaaggcgaagatggtaaagacggtgcaaaaggagaaccgggcccgcgtggtgagcgtggtgaagctggcattccgggcgttccgggtgcaaaaggggaagatggcaaagatggtgcgaaaggtgaacctggtccgcgcggcgaacgtggtgaagcaggcattccgggagtgccgggtgcaaagggtgaagatggtaaggatggtgccaaaggcgagccgggtccgcgcggtgaacgcggcgaggcaggtattcctggcgtgccgggtgcgaaaggcgaagacggtaaagatggcgcaaaaggtgagccgggcccgcgcggtgagcgtggcgaggcaggcattcctggcgttccgggcgcaaagggtgaggatggtaaggacggtgcaaagggcgaaccgggccctcgcggtgagagaggtgaagcaggaattccgggtgtcccgggcgcaaaaggagaggatggcaaagacggtgcgaaaggagaacctggcccgcgtggcgaacgcggtgaggcaggtatcccgggtgtgcctggtgccaaaggtgaagatggcaaggatggcgccaaaggtgagcctggcccgcgcggcgagcgtggtgaggcaggcataccgggcgttcctggcgcaaaaggggaggatggtaaagatggagccaaaggcgaacctggccctcgtggcgaacgtggcgaggctggtattccgggcgtgccgggagccaaaggtgaagacggtaaggatggcgcaccgggtccgtgttgtggtggcgtgtaactcgag;
30、<cr2; aa; seq id no:3>:
31、gergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgergetgppgpagfpgapgqngepggkgergapgekgeggppgapgpccggv;
32、<cr2; dna; seq id no:4>:
33、ccatggctggtgaacgtggtgaaacaggtccgcctggtcctgcaggttttccgggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaaccggtcctcctggtccggcaggttttccgggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctcctggtccggcaggttttccgggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaaccggtcctcctggtccggcaggttttcctggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctcctggtccggcaggttttcctggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctcctggtcctgcaggttttccgggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctccgggtccggcaggttttcctggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctcctggtccggcaggttttcctggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctcctggtccggcaggttttccgggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgaacgtggtgaaacaggtcctcctggtcctgcaggttttccgggtgcacctggtcaaaatggtgaaccgggtggtaaaggtgaacgtggtgcaccgggtgaaaaaggtgaaggtggtccgccgggtgcaccgggtccgtgttgtggtggttaactcgag;
34、<cr3; aa; seq id no:5>:
35、gergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgergppgpmgppglagppgesgregapgapgpccggv;
36、<cr3; dna; seq id no:6>:
37、cccatggctggtgaacgtggtccgccgggtccgatgggccctcctggtttagcaggtccgccgggcgaaagcggccgcgagggtgcacctggtgaacgtggcccgccgggtcctatgggccctccgggtttagcaggcccgccgggcgagagtggtcgtgaaggtgcaccgggtgaacgcggtccgccgggacctatgggcccacctggtctggccggccctcctggcgaaagtggccgtgaaggtgcgccgggtgaacgtggaccgccgggtccaatgggtccgcctggtctggcgggccctcctggagaaagtggccgcgaaggtgccccgggtgaacggggtcctccgggtcctatgggtccgccaggtctggcaggcccgcctggtgaaagtggccgggaaggtgcccctggtgaacgcggaccgccgggccctatgggtcctcctggtctggctggtccgccgggggaaagtggcagagaaggcgcaccgggtgagcgtggcccgcctggccctatgggacctcctggtcttgccggcccgccgggagaaagcggtcgtgaaggcgcacctggcgaacgcggtcctccgggccctatgggcccgcctggattagccggcccgcctggggaaagcggccgtgagggtgctccgggtgaaagaggtccgccgggcccaatgggcccgccggggctggcaggtcctcctggcgagtcaggtcgcgaaggtgcgcctggcgaacgtggtcctccgggacctatgggtccaccgggcctggctggtcctccgggggagagcggtcgtgagggtgcaccaggtccgtgctgtggcggtgtttaactcgag;
38、<麦芽糖结合蛋白(mbp)融合标签; aa; seq id no:7>:
39、mkieegklviwingdkgynglaevgkkfekdtgikvtvehpdkleekfpqvaatgdgpdiifwahdrfggyaqsgllaeitpdkafqdklypftwdavryngkliaypiavealsliynkdllpnppktweeipaldkelkakgksalmfnlqepyftwpliaadggyafkyengkydikdvgvdnagakagltflvdliknkhmnadtdysiaeaafnkgetamtingpwawsnidtskvnygvtvlptfkgqpskpfvgvlsaginaaspnkelakeflenylltdegleavnkdkplgavalksyeeelakdpriaatmenaqkgeimpnipqmsafwyavrtavinaasgrqtvdealkdaqt;
40、<半胱氨酸蛋白酶(cpd)融合标签; aa; seq id no:8>:
41、maladgkilhnqnvnswgpitvtpttdggetrfdgqiivqmendpvvakaaanlagkhaessvvvqldsdgnyrvvygdpskldgklrwqlvghgrdhsetnntrlsgysadelavklakfqqsfnqaeninnkpdhisivgcslvsddkqkgfghqfinamdanglrvdvsvrsselavdeagrkhtkdangdwvqkaennkvslswdaqg;
42、<谷胱甘肽巯基转移酶(gst)融合标签; aa; seq id no:9>:
43、mspilgywkikglvqptrllleyleekyeehlyerdegdkwrnkkfelglefpnlpyyidgdvkltqsmaiiryiadkhnmlggcpkeraeismlegavldirygvsriayskdfetlkvdflsklpemlkmfedrlchktylngdhvthpdfmlydaldvvlymdpmcldafpklvcfkkrieaipqidkylksskyiawplqgwqatfgggdhppk;
44、<本载脂蛋白格a1 (apoi)融合标签; aa; seq id no:10>:
45、mlklldnwdsvtstfsklreqlgpvtqefwdnleketeglrqemskdleevkakvqpylddfqkkwqeemelyrqkveplraelqegarqklhelqeklsplgeemrdrarahvdalrthlapysdelrqrlaarlealkenggarlaeyhakatehlstlsekakpaledlrqgllpvlesfkvsflsaleeytkklntq;
46、<硫氧还蛋白(trxa)融合标签; aa; seq id no:11>:
47、msdkiihltddsfdtdvlkadgailvdfwaewcgpckmiapildeiadeyqgkltvaklnidqnpgtapkygirgiptlllfkngevaatkvgalskgqlkefldanla;
48、<绿色荧光蛋白(gfp)融合标签氨基酸seq id no:12>:
49、mskgeelftgvvpilveldgdvnghkfsvrgegegdatngkltlkficttgklpvpwptlvttltygvqcfsrypdhmkrhdffksampegyvqertisfkddgtyktraevkfegdtlvnrielkgidfkedgnilghkleynfnshnvyitadkqkngikanfkirhnvedgsvqladhyqqntpigdgpvllpdnhylstqsvlskdpnekrdhmvllefvtaagithg;
50、<烟草蚀纹病毒酶切序列(tev); aa; seq id no:13>:
51、enlyfqg;
52、<凝血酶切序列(thrombin); aa; seq id no:14>:
53、lvprgs;
54、<肠激酶切序列(ek); aa; seq id no:15>:
55、ddddk;
56、<因子xa酶切序列(factor-xa); aa; seq id no:16>:
57、iegr;
58、<鼻病毒3c酶切序列(hrv3c); aa; seq id no:17>:
59、levlfqgp。
60、与现有技术相比,本发明具有以下有益效果:
61、(1) 本发明采用基因重组技术制得了一种重组胶原重复序列蛋白,选择人体来源的i型和iii型胶原蛋白序列作为重复序列,与动物来源的i型胶原蛋白相比,具有无病毒传播隐患、低免疫原性等优点。
62、(2) 本发明采用辛烯基琥珀酸酐对蛋白进行酰化改性,改性后的蛋白既有亲水基团又有疏水基团,具有良好的水溶性、表面活性以及热稳定性也增强,蛋白酰化后促进细胞迁移的性能也增强,且不会破坏胶原蛋白二聚体结构,操作简单,原料易得,且在ph为9的缓冲液中进行反应,避免了反应过程中产生的羧酸导致反应体系的 ph 值下降,从而使反应速率降低的现象。
63、(3) 本发明所得一种重组胶原重复序列蛋白,可形成具有胶原特性的二聚体结构和(gly-x-y)n重复氨基酸序列。
64、(4) 本发明采用的pet32a(+)载体包含组氨酸标签、融合标签和蛋白酶切割位点的氨基酸序列,便于蛋白质的纯化;采用不同种类的大肠杆菌表达菌株进行重组胶原重复序列蛋白的表达,蛋白表达量高;采用酶切除重组胶原重复序列蛋白带有的融合标签,得到的蛋白纯度较高。
65、(5) 本发明得到的重组胶原重复序列蛋白具有促进细胞迁移的活性,活性高于锦波的重组胶原蛋白hc16,皮肤修复效果好,可广泛应用于促进细胞迁移活性产品和皮肤修复产品的制备。
- 还没有人留言评论。精彩留言会获得点赞!