一种基于确定性策略梯度学习的PHEV能量管理方法与流程
本发明涉及插电式混合动力汽车(plug-inhybridelectricvehicle,简称phev)能量管理技术,尤其涉及一种基于确定性策略梯度学习算法对phev能量进行包括策略训练、在线应用、效果检测、反馈更新等的闭环管理方法及其应用。
背景技术:
对于城市工况而言,插电式混合动力汽车(plug-inhybridelectricvehicle,简称phev)的节能减排优势非常突出,而如何协调各车载动力源间的能量分配,实现高效能量管理,对其优势发挥至关重要。由于phev装备有大容量动力电池,且能及时通过电网充电,故其动力电池荷电状态(stateofcharge,soc)可在较大范围内变动,稳持能量管理策略难以充分发挥phev的节能优势。目前商业应用中采用较多的规则式纯电动-电量稳持模式,电量消耗较快,且进入电量稳持模式后,燃油经济性提升空间将大幅受限。对于基于优化的phev能量管理策略,最具代表性的为基于动态规划的能量管理,通常可以获得全局最优的能量分配策略,但要求全局工况已知、计算资源需求大,难以在线应用。因此,许多能量管理策略基于或结合全局最优策略进行拓展,以在实时能量管理中复现全局最优策略的效果,例如,基于动态规划策略标定发动机经济性工作区域、设计规则式能量管理策略;利用全局最优策略得到的最优控制序列,利用有监督学习训练神经网络,然而此类策略容易受限于样本数据,在复杂工况下的泛化能力具有局限性。另一方面,为获取实际车辆行驶工况先验知识,一些能量管理策略通过行驶工况预测模型或智能交通系统,获取部分或全局phev行驶工况先验信息,结合模型预测控制、自适应最小燃油消耗策略设计响应的实时能量管理策略,或结合云端计算解决动态规划能量管理策略计算量大的问题。
相比于动态规划全局最优能量管理策略,对于同样采用马尔可夫决策过程(markovdecisionprocess,mdp)对能量管理问题进行建模的强化学习能量管理方法而言,其采用了迭代学习的方式以解决全局最优能量管理策略的复现,不依赖于未来行驶工况等先验信息,可实际应用的场景更广泛。然而,基于基本强化学习算法的能量管理策略,特别是采用表格式策略表征的强化学习算法,其训练效率和策略泛化能力仍有待提高。近年来,一些快速发展的深度强化学习方法,如确定性策略梯度算法、深层动作价值网络算法等,结合了深度学习强大的非线性表征能力,学习最优策略的效率和效果更好,并逐步在实际物理系统中取得突破性进展,显示了深度强化学习在复杂控制问题上的应用潜力。与此同时,逐渐出现的深度强化学习能量管理策略也展示了其良好的燃油经济性和鲁棒性。但是,目前基于深度强化学习方法的phev能量管理策略仍停留于训练和策略评估两个阶段,其策略训练、在线应用、效果检测、反馈更新的完整闭环应用体系尚未形成,这也是本领域亟待解决的问题,解决此问题对提高深度强化学习能量管理策略实际应用的可靠性也有着积极的意义。
技术实现要素:
针对上述本领域中存在的技术问题,本发明提供了一种基于确定性策略梯度学习算法对phev能量进行包括策略训练、在线应用、效果检测、反馈更新等的闭环管理方法,该方法具体包括以下步骤:
步骤一、利用深层神经网络(dnn)分别搭建动作网络(actor)和动作价值网络(critic),共同组成确定性策略梯度学习算法的基本网络框架(ac网络),以构建phev能量管理策略学习网络;并对所述ac网络参数进行初始化和状态数据的归一化处理;
步骤二、对所述动作价值网络进行预训练,定义并初始化用于存储后续训练产生的状态转移样本的存储空间作为经验池,获取初始时刻的状态向量,采用∈退火贪婪策略选择当前状态下的动作向量,存储当前时刻的状态转移样本,并对所述动作价值网络进行更新;以网络更新迭代次数作为critic网络预训练和ac网络训练是否满足要求的依据;
步骤三、基于所述步骤二中所选择的当前状态下的动作向量,获取动力系统的控制动作量和驾驶需求,计算phev动力系统的动力响应,并评估发动机燃油消耗水平,计算动力电池的状态转移,获取下一时刻状态向量并计算奖赏信号;
步骤四、对动力电池soc参考值初始化并更新soc偏差,并依次对累积行驶距离以及所述动力电池参考值进行更新;
步骤五、获取当前时刻状态向量并计算当前时刻动作向量,调整动作向量输出频率,动力系统响应动作向量后对下一时刻重复该步骤的能量管理策略在线应用过程;
步骤六、根据实时行驶车速更新速度转移概率矩阵,记录瞬时燃油消耗率,更新油耗移动平均值,检测是否需要更新能量管理策略;如需要更新,则执行生成新的训练工况,用于所述步骤一与步骤二对所建立的phev能量管理策略模型网络进行训练,从而实现所述模型网络的更新。
进一步地,所述步骤一为phev能量管理策略建模阶段,以确定性策略梯度算法为基础,分别建立能量管理参数化策略网络模型actor,和用于策略评估改进的动作价值函数参数化网络模型critic,并完成训练数据预处理。
此外,根据动力电池soc水平,需分别训练电量消耗阶段的能量管理策略πbm=μbm(s|θμ),和电量稳持阶段的能量管理策略πcs=μcs(s|θμ)。具体步骤如下:
(1.1)定义状态空间,建立电量消耗阶段能量管理策略πbm并训练,其状态空间维数为nstate=7,状态空间s和状态向量s(k)分别定义如下:
s={soc,δsoc,treq,preq,acc,v,d}
s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k),d(k)],s(k)∈s
其中,δsoc为soc偏差值,treq为需求驱动转矩,需求驱动功率preq=wreq·treq,wreq为需求驱动转速,acc为车辆加速度,v为车速,d为行驶距离,k为当前时刻。
(1.2)建立phev能量管理策略模型网络(actor网络),记为a=μ(s|θμ),μ表示actor网络,其网络参数为θμ,以状态向量s为输入,输出动作向量为a,策略网络结构为:输入层(输入维数与状态空间维数nstate相同)-全连接层(共三层,每层100个神经元,以线性整流函数为激活函数)-输出层(输出维数与动作空间维数naction相同,以sigmoid为激活函数);
(1.3)建立用于评估所述模型网络的动作价值网络(critic网络),具有两路支流的深层全连接神经网络,记为q=q(s,a|θq)=v(s|θv)+a(a|θa),q表示动作价值网络,其参数集合和动作价值输出分别为为θq和q,具体分为以θv为参数的状态价值网络支流v和以θa为参数的动作优势网络支流a;两路支流具有相同的隐含层结构(三层全连接层,每层100个神经元,以线性整流函数为激活函数);状态价值网络支流输入层输入维数与状态空间维数nstate相同,输出层为线性标量输出;动作优势网络支流输入层输入维数与动作空间维数naction相同,输出层为线性标量输出;
(1.4)初始化网络参数,采用xavier初始化方法,产生actor和critic网络的初始网络权重和偏置,具体地,产生区间
(1.5)建立用于稳定训练的目标网络,复制一套与步骤(1.2)-(1.4)所建立的actor和critic网络结构和参数均相同的网络,记为目标actor网络
(1.6)训练数据归一化预处理,选定训练工况,计算获得其速度序列、加速度序列、以及需求转矩和功率序列,并分别计算其均值和标准差并保存,按照标准归一化通用公式进行归一化处理
其中,mean(x)和std(x)分别表示输入数据x的均值和标准差。
当且仅当此时为电量消耗阶段策略训练,需对行驶距离d按最大行驶里程进行线性归一化。
进一步地,所述步骤二基于确定性策略梯度算法、优先经验回放的phev能量管理策略离线训练:
此步骤为基于确定性策略梯度算法的phev能量管理策略离线训练过程,主要涉及∈退火贪婪算法、优先经验回放、adam神经网络优化算法,以及对步骤三和步骤四的调用和交互;根据动力电池soc水平,分为电量消耗阶段的能量管理策略πbm=μbm(s|θμ),和电量稳持阶段的能量管理策略πcs=μcs(s|θμ)。以电量消耗阶段能量管理策略πbm的训练为例进行说明,其具体步骤如下:
(2.1)动作价值网络预训练,按训练工况时序,基于动态规划最优能量管理策略,产生最优状态转移样本数据,其中k时刻的转移样本记为e(k)={s(k),a(k),r(k),s(k+1)},其中s(k)为k时刻的状态向量,a(k)为动作向量,r(k)为奖赏,s(k+1)为k+1采样时刻的状态向量;冻结actor网络和目标actor网络参数,从所有最优样本数据中随机采样得到小批量样本,依据式以下公式计算critic网络更新梯度
其中,s表示s(k),以s′表示s(k+1),r表示r(k),γ为未来奖赏折扣系数,
(2.2)经验池初始化:定义存储空间以存储后续训练产生的状态转移样本ek,记作经验池d;定义随机过程
(2.3)设k=0,获取初始时刻的状态向量s(0)=[soc(0),δsoc(0),treq(0),preq(0),acc(0),v(k),d(0)];更新训练回合数i=i+1;
(2.4)采用∈退火贪婪策略选择当前状态s(k)下的动作向量a(k)=[we(k),te(k)],以∈的概率选择使用随机过程
(2.5)存储当前时刻的状态转移样本e(k),以当前时刻动作向量a(k)作为输入,执行步骤三一次,获取e(k)={s(k),a(k),r(k),s(k+1)),并计算其采样概率p(k),若经验池中样本数量尚未达到上限,则将该样本e(k)存储入经验池d,返回执行步骤(2.4);否则删除最旧的转移样本,存入新产生的转移样本e(k),执行步骤(2.6)
其中,样本优先级pk=|δk|+ε,δk为时间差分误差:
(2.6)更新能量管理策略网络与动作价值网络,即更新ac网络;从经验池d中,服从样本采样概率,采样得到一小批量样本(32个),此过程记为优先经验回放;根据确定性策略梯度学习原理,以及各个样本,分别计算用于策略网络参数更新的梯度
其中,
(2.7)探索率衰减,将∈以线性规律衰减:
(2.8)若k<l-1,则k=k+1,并返回执行步骤(2.4),否则执行步骤(2.9);
(2.9)若i≤n,返回执行步骤(2.3),否则,终止训练,保存模型网络及其参数,作为训练好的能量管理策略模型网络;
(2.10)若尚未训练电量稳持阶段能量管理策略,执行此步骤,训练电量稳持阶段的能量管理策略πcs=μcs(s|θμ),μcs表示电量稳持阶段的能量管理策略网络:
针对电量稳持阶段的策略训练,其状态空间维数为nstate=6,状态空间s和状态向量s(k)分别如下式所示;之后,执行步骤(1.2)。
s={soc,δsoc,treq,preq,acc,v}
s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k)],s(k)∈s
否则,若此时训练不在云端服务器中执行,则将训练所得能量管理策略下载至车辆控制器,转向步骤五,否则转向步骤六的更新过程。
进一步地,用于完善phev能量管理策略的交互训练:实时评估策略的燃油经济性,提供用于策略更新的奖励信号。以功率分流式phev能量管理中,控制发动机转速we(k)和转矩te(k)为例,进行说明。具体实施方法如下:
(3.1)获取动力系统的控制动作量和驾驶需求,获取来自步骤(2.5)的动作量输入we(k)和te(k),即动作向量a(k)=[we(k),te(k)];获取来自驾驶员或既定工况的需求驱动转速wreq(k)和需求驱动转矩treq(k);对于初始时刻(k=0),有a(0)=[0,0],wreq(k)=0,treq(0)=0。
(3.2)计算phev动力系统的动力响应,并评估发动机燃油消耗水平,根据给定的动作向量,以行星排的力平衡和运动特性为基础,分别计算驱动电机的转速wmot(k)和转矩tmot(k),发电机的转速wgen(k)和转矩tgen(k);以发动机万有特性图为依据,计算发动机瞬时油耗
(3.3)计算动力电池状态转移,以动力电池内阻模型为基础,结合驱动电机和发电机台架试验效率特性,计算动力电池的放电或充电功率pbatt(k),从而计算动力电池下一采样时刻的荷电状态soc(k+1);
(3.4)获取下一时刻状态向量s(k+1),依据训练工况,获得下一时刻车辆行驶需求车速v(k+1)、加速度acc(k+1)、需求驱动转矩treq(k+1)、需求驱动功率preq(k+1);
若此时为电量消耗阶段能量管理策略训练,转入执行步骤四一次,获得更新后的空间域索引动力电池soc参考值socref(k+1)、行驶距离信息d(k+1)、soc偏差值δsoc(k+1);否则,计算socref(k+1)=socsust,δsoc(k+1)=soc(k)-socsust,其中socsust为soc稳持值;
之后,将上述各状态变量值合并作为下一时刻的状态向量s(k+1);
(3.5)计算奖赏信号,依据步骤(3.4)所得soc参考值socref(k+1),按照如下公式计算奖赏信号r(k):
其中,
进一步地,所述步骤四用于完善phev能量管理策略的交互训练:计算空间域索引的动力电池soc参考值用于引导策略训练。具体实施方法如下:
(4.1)初始化soc参考值,以phev充满电的时刻为起始时刻(k=0),若此时为初始时刻,此时的行驶距离记为d(0)=0,动力电池soc为初始值socinit,soc参考值初始化为socref(0)=socinit;否则,转到步骤(4.2);
(4.2)更新soc偏差:获取当前时刻的动力电池soc(k),计算soc偏差值为δsoc(k+1)=soc(k)-socref(k);
(4.3)更新累积行驶距离信息。记控制器采样周期为tsample,当前时刻车速和行驶距离分别为v(k)和d(k),新的行驶距离信息更新为d(k+1)=d(k)+v(k)·tsample;
(4.4)更新动力电池soc参考值。socref(k+1)=socinit-λ·d(k+1),其中动力电池soc在最大续驶里程(l=100km)内的期望下降速率为λ=(socinit-socsust)/l,socsust为动力电池电量预期稳持水平。
进一步地,所述步骤五为步骤(2)训练所得能量管理策略的在线应用,于实际phev动力系统中实现,具体包括以下步骤:
(5.1)获取当前时刻状态向量:若soc高于维持水平,从车辆实际动力系统获取状态向量s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k),d(k)]并执行步骤(1.6)进行归一化,选择电量消耗阶段能量管理策略作为当前策略π=πbm=μbm(s(k)|θμ),其中,状态量δsoc(k)和d(k)通过执行步骤四获得;否则,获取状态向量s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k)]并执行步骤(1.6)进行归一化,选择电量稳持能量管理策略π=πcs=μcs(s(k)|θμ),其中,状态量δsoc(k)=soc(k)-socsust;
(5.2)计算当前时刻动作向量:将步骤(5.1)所得状态向量输入相应的能量管理策略π,进行网络正向传播计算,输出当前时刻的实际动作向量areal,如下式所示:
areal(k)=z·μ(s(k)|θμ)
其中,μ为表征当前能量管理策略π的actor网络,其参数为θμ;向量z表示相应动作量的缩放系数,将网络输出的信号(范围0-1)映射到实际发动机转速、转矩区间;
(5.3)动作向量输出频率调整:鉴于实际车辆控制器采样频率较高,将动作向量输入采样保持器再输出,以降低动作向量变化频率,避免发动机频繁启停;
(5.4)动力系统响应:将步骤(5.3)输出的动作向量,发送至动力系统,动力系统响应动作向量,并发生状态转移;
(5.5)转向步骤(5.1),进行下一时刻车辆能量管理控制,直到行驶结束,车辆动力系统下电,结束能量管理进程。
进一步地,所述步骤六为能量管理策略的实时检测与训练更新,步骤(6.1)-(6.3)于车辆控制器中执行,步骤(6.3)-(6.4)于云端服务器中完成计算,预设衡量实际行驶工况与策略训练工况差异度的阈值dthreshold,以及燃油消耗水平上限ethreshold。具体包括如下步骤:
(6.1)根据实时行驶车速更新速度转移概率矩阵p:控制器采集并记录车辆行驶速度工况,每当行驶速度工况时长达到一小时,即time=3600s,根据此时长为time的实时工况,应用以下公式更新速度转移概率矩阵p:
ni(k)=ni(k-1)+δi
其中,速度状态空间以1m/s作为离散精度,状态数量共计m=20;k表示概率矩阵p的更新迭代次数;pij表示车速在1s后,由状态i转移至状态j的概率;δi表示在时长为time的行驶工况内,速度状态i的出现频数;δi(t)为布尔值,若t时刻的速度状态为状态i则为1,否则为0;δij表示在时长为time的行驶工况内,速度状态由i转移至j所出现的频数;δij(t)为布尔值,若t时刻的速度状态将由状态i转移至状态,则为1,否则为0;ni表示出现速度状态i的历史累积频数;
(6.2)记录瞬时燃油消耗率,更新油耗移动平均值e:与步骤(6.1)同步执行,记录瞬时燃油消耗率,每当记录时长为time后,利用以下公式更新空间距离上的油耗移动平均值e:
其中,
(6.3)检测是否需要更新能量管理策略:在步骤(6.1)和(6.2)完成一次更新后,计算实际工况速度转移概率矩阵p与训练工况速度状态转移矩阵t的kl散度dkl,作为实际工况与训练工况的差异度指标,如以下公式所示:
其中,t为根据训练工况计算所得速度状态转移概率矩阵;
若dkl(p||t)>dthreshold即训练工况差异度的阈值,且燃油消耗率移动平均值e>ethreshold即燃油消耗水平上限,则向云端服务器发送请求,从计算云端执行步骤(6.4)至步骤(6.6),以更新能量管理策略;同时,车辆控制器返回继续执行步骤(6.1);
(6.4)生成新的训练工况:云端服务器获取当前的实际工况速度状态转移概率矩阵p,将车辆行驶速度状态转移视为马尔科夫过程,采用马尔科夫链蒙特卡洛模拟方法,生成与原始训练工况时长相同的新工况;
(6.5)策略训练:以新生成的训练工况为输入,于云端服务器中执行步骤一至步骤二,重新训练新的电量消耗阶段能量管理策略πbm和电量稳持阶段能量管理策略πcs;
(6.6)策略更新:通过车载无线通讯,将新策略从云端下载至整车控制器以更新旧策略,同时更新控制器中的速度状态转移概率矩阵t=p;此时,步骤五将正常执行,当且仅当步骤(5.1)被执行时,新策略生效。
通过上述本发明所提供的方法,实现了基于确定性策略梯度学习的phev能量管理中包括策略训练、在线应用、效果检测、反馈更新等多个方面的闭环应用,相对于现有技术具有更高的精确度,大大提高了phev能量管理的效率与可靠性,具有当前的诸多管理策略所不具备的有益效果。
附图说明
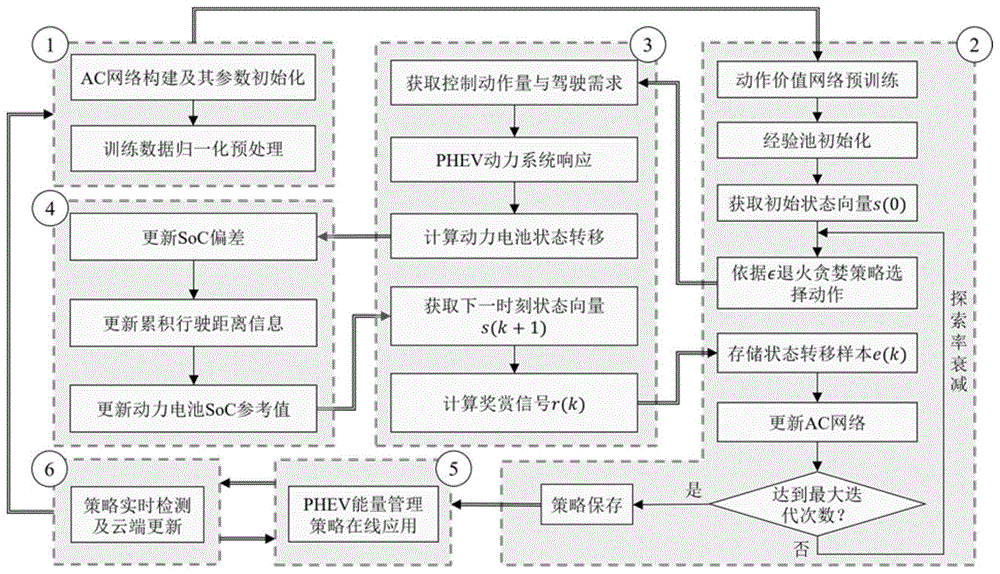
图1为本发明所提供方法的流程示意图
图2为actor网络与critic网络结构示意图
图3为基于确定性策略梯度方法的phev能量管理策略离线训练过程示意图
图4为phev能量管理策略的在线应用
图5为能量管理策略实时检测及更新
具体实施方式
下面将结合附图对本发明的技术方案进行清楚、完整地描述,显然,所描述的实施例是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
本发明所提供的一种基于确定性策略梯度学习的phev能量管理方法,如图1所示,具体包括以下步骤:
步骤一、利用深层神经网络(dnn)分别搭建动作网络(actor)和动作价值网络(critic),共同组成确定性策略梯度学习算法的基本网络框架(ac网络),以构建phev能量管理策略模型学习;并对所述ac网络参数进行初始化和状态数据的归一化处理;
步骤二、对所述动作价值网络进行预训练,定义并初始化用于存储后续训练产生的状态转移样本的存储空间作为经验池,获取初始时刻的状态向量,采用∈退火贪婪策略选择当前状态下的动作向量,存储当前时刻的状态转移样本,并对所述动作价值网络进行更新;以网络更新迭代次数作为critic网络预训练和ac网络训练是否满足要求的依据;
步骤三、基于所述步骤二中所选择的当前状态下的动作向量,获取动力系统的控制动作量和驾驶需求,计算phev动力系统的动力响应,并评估发动机燃油消耗水平,计算动力电池的状态转移,获取下一时刻状态向量并计算奖赏信号;
步骤四、对动力电池soc参考值初始化并更新soc偏差,并依次对累积行驶距离以及所述动力电池参考值进行更新;
步骤五、获取当前时刻状态向量并计算当前时刻动作向量,调整动作向量输出频率,动力系统响应动作向量后对下一时刻重复该步骤的能量管理策略在线应用过程;
步骤六、根据实时行驶车速更新速度转移概率矩阵,记录瞬时燃油消耗率,更新油耗移动平均值,检测是否需要更新能量管理策略;如需要更新,则执行生成新的训练工况,用于所述步骤一与步骤二对所建立的phev能量管理策略模型网络进行训练,从而实现所述模型网络的更新。
进一步地,所述步骤一为phev能量管理策略建模阶段,以确定性策略梯度算法为基础,分别建立如图2所示的能量管理参数化策略网络模型actor,和用于策略评估改进的动作价值函数参数化网络模型critic,并完成训练数据预处理。
此外,根据动力电池soc水平,需分别训练电量消耗阶段的能量管理策略πbm=μbm(s|θμ),和电量稳持阶段的能量管理策略πcs=μcs(s|θμ)。具体步骤如下:
(1.1)定义状态空间,建立电量消耗阶段能量管理策略πbm并训练,其状态空间维数为nstate=7,状态空间s和状态向量s(k)分别定义如下:
s={soc,δsoc,treq,preq,acc,v,d}
s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k),d(k)],s(k)∈s
其中,δsoc为soc偏差值,treq为需求转矩,需求驱动功率preq=wreq·treq,wreq为需求驱动转速,acc为车辆加速度,v为车速,d为行驶距离,k为当前时刻。
(1.2)建立phev能量管理策略模型网络(actor网络),记为a=μ(s|θμ),μ表示actor网络,其网络参数为θμ,以状态向量s为输入,输出动作向量为a,策略网络结构为:输入层(输入维数与状态空间维数nstate相同)-全连接层(共三层,每层100个神经元,以线性整流函数为激活函数)-输出层(输出维数与动作空间维数naction相同,以sigmoid为激活函数);
(1.3)建立用于评估所述模型网络的动作价值网络(critic网络),具有两路支流的深层全连接神经网络,记为q=q(s,a|θq)=v(s|θv)+a(a|θa),q表示动作价值网络,其参数集合和动作价值输出分别为θq和q,具体分为以θv为参数的状态价值网络支流v和以θa为参数的动作优势网络支流a;两路支流具有相同的隐含层结构(三层全连接层,每层100个神经元,以线性整流函数为激活函数);状态价值网络支流输入层输入维数与状态空间维数nstate相同,输出层为线性标量输出;动作优势网络支流输入层输入维数与动作空间维数naction相同,输出层为线性标量输出;
(1.4)初始化网络参数,采用xavier初始化方法,产生actor和critic网络的初始网络权重和偏置,具体地,产生区间
(1.5)建立用于稳定训练的目标网络,复制一套与步骤(1.2)-(1.4)所建立的actor和critic网络结构和参数均相同的网络,记为目标actor网络a=
(1.6)训练数据归一化预处理,选定训练工况,计算获得其速度序列、加速度序列、以及需求转矩和功率序列,并分别计算其均值和标准差并保存,按照标准归一化通用公式进行归一化处理
其中,mean(x)和std(x)分别表示输入数据x的均值和标准差。
当且仅当此时为电量消耗阶段策略训练,需对行驶距离d按最大行驶里程进行线性归一化。
进一步地,所述步骤二为基于确定性策略梯度算法的phev能量管理策略离线训练过程,主要涉及∈退火贪婪算法、优先经验回放、adam神经网络优化算法,以及对步骤三和步骤四的调用和交互;根据动力电池soc水平,分为电量消耗阶段的能量管理策略πbm=μbm(s|θμ),和电量稳持阶段的能量管理策略πcs=μcs(s|θμ)。以电量消耗阶段能量管理策略πbm的训练为例进行说明,如图3所示,其具体步骤如下:
(2.1)动作价值网络预训练,按训练工况时序,基于动态规划最优能量管理策略,产生最优状态转移样本数据,其中k时刻的转移样本记为e(k)={s(k),a(k),r(k),s(k+1)},其中s(k)为k时刻的状态向量,a(k)为动作向量,r(k)为奖赏,s(k+1)为k+1采样时刻的状态向量;冻结actor网络和目标actor网络参数,从所有最优样本数据中随机采样得到小批量样本,依据式以下公式计算critic网络更新梯度
其中,s表示s(k),以s′表示s(k+1),r表示r(k),y为未来奖赏折扣系数,
(2.2)经验池初始化:定义存储空间以存储后续训练产生的状态转移样本ek,记作经验池d;定义随机过程
(2.3)设k=0,获取初始时刻的状态向量s(0)=[soc(0),δsoc(0),treq(0),preq(0),acc(0),v(k),d(0)];更新训练回合数i=i+1;
(2.4)采用∈退火贪婪策略选择当前状态s(k)下的动作向量a(k)=[we(k),te(k)],以∈的概率选择使用随机过程
(2.5)存储当前时刻的状态转移样本e(k),以当前时刻动作向量a(k)作为输入,执行步骤三一次,获取e(k)={s(k),a(k),r(k),s(k+1)},并计算其采样概率p(k),若经验池中样本数量尚未达到上限,则将该样本e(k)存储入经验池d,返回执行步骤(2.4);否则删除最旧的转移样本,存入新产生的转移样本e(k),执行步骤(2.6)
其中,样本优先级pk=|δk|+ε,δk为时间差分误差:
(2.6)更新能量管理策略网络与动作价值网络,即更新ac网络;从经验池d中,服从样本采样概率,采样得到一小批量样本(32个),此过程记为优先经验回放;根据确定性策略梯度学习原理,以及各个样本,分别计算用于策略网络参数更新的梯度
其中,
(2.7)探索率衰减,将∈以线性规律衰减:
(2.8)若k<l-1,则k=k+1,并返回执行步骤(2.4),否则执行步骤(2.9);
(2.9)若i≤n,返回执行步骤(2.3),否则,终止训练,保存模型网络及其参数,作为训练好的能量管理策略模型网络;
(2.10)若尚未训练电量稳持阶段能量管理策略,执行此步骤,训练电量稳持阶段的能量管理策略πcs=μcs(s|θμ),μcs表示电量稳持阶段的能量管理策略网络:
针对电量稳持阶段的策略训练,其状态空间维数为nstate=6,状态空间s和状态向量s(k)分别如下式所示;之后,执行步骤(1.2)。
s={soc,δsoc,treq,preq,acc,v}
s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k)],s(k)∈s
否则,若此时训练不在云端服务器中执行,则将训练所得能量管理策略下载至车辆控制器,转向步骤五,否则转向步骤六的更新过程。
进一步地,用于完善phev能量管理策略的交互训练:实时评估策略的燃油经济性,提供用于策略更新的奖励信号。以功率分流式phev能量管理中,控制发动机转速we(k)和转矩te(k)为例,进行说明。具体实施方法如下:
(3.1)获取动力系统的控制动作量和驾驶需求,获取来自步骤(2.5)的动作量输入we(k)和te(k),即动作向量a(k)=[we(k),te(k)];获取来自驾驶员或既定工况的需求驱动转速wreq(k)和需求驱动转矩treq(k);对于初始时刻(k=0),有a(0)=[0,0],wreq(k)=0,treq(0)=0。
(3.2)计算phev动力系统的动力响应,并评估发动机燃油消耗水平,根据给定的动作向量,以行星排的力平衡和运动特性为基础,分别计算驱动电机的转速wmot(k)和转矩tmot(k),发电机的转速wgen(k)和转矩tgen(k);以发动机万有特性图为依据,计算发动机瞬时油耗
(3.3)计算动力电池状态转移,以动力电池内阻模型为基础,结合驱动电机和发电机台架试验效率特性,计算动力电池的放电或充电功率pbatt(k),从而计算动力电池下一采样时刻的荷电状态soc(k+1);
(3.4)获取下一时刻状态向量s(k+1),依据训练工况,获得下一时刻车辆行驶需求车速v(k+1)、加速度acc(k+1)、需求驱动转矩treq(k+1)、需求驱动功率preq(k+1);
若此时为电量消耗阶段能量管理策略训练,转入执行步骤四一次,获得更新后的空间域索引动力电池soc参考值socref(k+1)、行驶距离信息d(k+1)、soc偏差值δsoc(k+1);否则,计算socref(k+1)=socsust,δsoc(k+1)=soc(k)-socsust,其中socsust为soc稳持值;
之后,将上述各状态变量值合并作为下一时刻的状态向量s(k+1);
(3.5)计算奖赏信号,依据步骤(3.4)所得soc参考值socref(k+1),按照如下公式计算奖赏信号r(k):
其中,
进一步地,所述步骤四用于完善phev能量管理策略的交互训练:计算空间域索引的动力电池soc参考值用于引导策略训练。具体实施方法如下:
(4.1)初始化soc参考值,以phev充满电的时刻为起始时刻(k=0),若此时为初始时刻,此时的行驶距离记为d(0)=0,动力电池soc为初始值socinit,soc参考值初始化为socref(0)=socinit;否则,转到步骤(4.2);
(4.2)更新soc偏差:获取当前时刻的动力电池soc(k),计算soc偏差值为δsoc(k+1)=soc(k)-socref(k);
(4.3)更新累积行驶距离信息。记控制器采样周期为tsample,当前时刻车速和行驶距离分别为v(k)和d(k),新的行驶距离信息更新为d(k+1)=d(k)+v(k)·tsample;
(4.4)更新动力电池soc参考值。socref(k+1)=socinit-λ·d(k+1),其中动力电池soc在最大续驶里程(l=100km)内的期望下降速率为λ=(socinit-socsust)/l,socsust为动力电池电量预期稳持水平。
进一步地,所述步骤五为步骤(2)训练所得能量管理策略的在线应用,于实际phev动力系统中实现,如图4所示,具体包括以下步骤:
(5.1)获取当前时刻状态向量:若soc高于维持水平,从车辆实际动力系统获取状态向量s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k),d(k)]并执行步骤(1.6)进行归一化,选择电量消耗阶段能量管理策略作为当前策略π=πbm=μbm(s(k)|θμ),其中,状态量δsoc(k)和d(k)通过执行步骤四获得;否则,获取状态向量s(k)=[soc(k),δsoc(k),treq(k),preq(k),acc(k),v(k)]并执行步骤(1.6)进行归一化,选择电量稳持能量管理策略π=πcs=μcs(s(k)|θμ),其中,状态量δsoc(k)=soc(k)-socsust;
(5.2)计算当前时刻动作向量:将步骤(5.1)所得状态向量输入相应的能量管理策略π,进行网络正向传播计算,输出当前时刻的实际动作向量areal,如下式所示:
areal(k)=z·μ(s(k)|θμ)
其中,μ为表征当前能量管理策略π的actor网络,其参数为θμ;向量z表示相应动作量的缩放系数,将网络输出的信号(范围0-1)映射到实际发动机转速、转矩区间;
(5.3)动作向量输出频率调整:鉴于实际车辆控制器采样频率较高,将动作向量输入采样保持器再输出,以降低动作向量变化频率,避免发动机频繁启停;
(5.4)动力系统响应:将步骤(5.3)输出的动作向量,发送至动力系统,动力系统响应动作向量,并发生状态转移;
(5.5)转向步骤(5.1),进行下一时刻车辆能量管理控制,直到行驶结束,车辆动力系统下电,结束能量管理进程。
进一步地,所述步骤六为能量管理策略的实时检测与训练更新,步骤(6.1)-(6.3)于车辆控制器中执行,步骤(6.3)-(6.4)于云端服务器中完成计算,预设衡量实际行驶工况与策略训练工况差异度的阈值dthreshold,以及燃油消耗水平上限ethreshold。具体包括如下步骤:
(6.1)根据实时行驶车速更新速度转移概率矩阵p:控制器采集并记录车辆行驶速度工况,每当行驶速度工况时长达到一小时,即time=3600s,根据此时长为time的实时工况,应用以下公式更新速度转移概率矩阵p:
ni(k)=ni(k-1)+δi
其中,速度状态空间以1m/s作为离散精度,状态数量共计m=20;k表示概率矩阵p的更新迭代次数;pij表示车速在1s后,由状态i转移至状态j的概率;δi表示在时长为time的行驶工况内,速度状态i的出现频数;δi(t)为布尔值,若t时刻的速度状态为状态i则为1,否则为0;δij表示在时长为time的行驶工况内,速度状态由i转移至j所出现的频数;δij(t)为布尔值,若t时刻的速度状态将由状态i转移至状态j则为1,否则为0;ni表示出现速度状态i的历史累积频数;
(6.2)记录瞬时燃油消耗率,更新油耗移动平均值e:与步骤(6.1)同步执行,记录瞬时燃油消耗率,每当记录时长为time后,利用以下公式更新空间距离上的油耗移动平均值e:
其中,
(6.3)检测是否需要更新能量管理策略:在步骤(6.1)和(6.2)完成一次更新后,计算实际工况速度转移概率矩阵p与训练工况速度状态转移矩阵t的kl散度dkl,作为实际工况与训练工况的差异度指标,如以下公式所示:
其中,t为根据训练工况计算所得速度状态转移概率矩阵;
若dkl(p||t)>dthreshold即训练工况差异度的阈值,且燃油消耗率移动平均值e>ethreshold即燃油消耗水平上限,则向云端服务器发送请求,从计算云端执行步骤(6.4)至步骤(6.6),以更新能量管理策略;同时,车辆控制器返回继续执行步骤(6.1);
(6.4)生成新的训练工况:云端服务器获取当前的实际工况速度状态转移概率矩阵p,将车辆行驶速度状态转移视为马尔科夫过程,采用马尔科夫链蒙特卡洛模拟方法,生成与原始训练工况时长相同的新工况;
(6.5)策略训练:以新生成的训练工况为输入,于云端服务器中执行步骤一至步骤二,重新训练新的电量消耗阶段能量管理策略πbm和电量稳持阶段能量管理策略πcs;
(6.6)策略更新:通过车载无线通讯,将新策略从云端下载至整车控制器以更新旧策略,同时更新控制器中的速度状态转移概率矩阵t=p;此时,步骤五将正常执行,当且仅当步骤(5.1)被执行时,新策略生效。
尽管已经示出和描述了本发明的实施例,对于本领域的普通技术人员而言,可以理解在不脱离本发明的原理和精神的情况下可以对这些实施例进行多种变化、修改、替换和变型,本发明的范围由所附权利要求及其等同物限定。
- 还没有人留言评论。精彩留言会获得点赞!