基于深度强化学习的自动驾驶行为决策方法与流程
本发明涉及自动驾驶技术领域,特别涉及基于深度强化学习的自动驾驶行为决策方法。
背景技术:
随着汽车行业的发展,目前无人驾驶的汽车逐渐登上了历史的舞台。顾名思义,无人驾驶汽车就是无需人为操控,汽车具有自主行为能力。无人驾驶汽车的背后,是自动驾驶技术的研究和开发。自动驾驶技术是一项集环境感知、行为决策与动作执行三大功能于一体的智能系统。而行为决策作为连接环境感知与动作执行的中枢位置,成为自动驾驶技术的重中之重,也是无人驾驶技术研发的重点和难点。行为决策直接决定汽车的行驶速度、加速度和行驶方向,稍有差池,将可能产生严重的后果,可能危害到乘车人员的人身安全。
现有的基于机器人技术的自动驾驶行为决策方法,如中国专利申请公开号为cn109213148a,发明名称为″一种基于深度强化学习的车辆低速跟驰决策方法″,公开了低速跟驰的决策方法。主要通过环境感知、构建基于actor-critic框架的深度强化学习结构、对深度强化学习结构中的参数进行训练和更新直到损失值最小。这种方式代码量大,并且只能使用在设定好的或者是环境变量与训练环境相似的情况下才。这种建模的方式对于计算的要求非常大,需要自动驾驶车辆背上沉重的计算机。
技术实现要素:
为了解决现有技术问题,本发明的目的是公开一种基于深度强化学习的自动驾驶行为决策方法,可以减少行为决策中的计算量,并且使用较少的传感器就能实现环境感知。
本发明的目的是通过以下技术方案实现的:
基于深度强化学习的自动驾驶行为决策方法,包括以下步骤:
步骤s1、获取自动驾驶车辆周围的当前环境状态;
步骤s2、根据输入的当前环境状态和自动驾驶车辆的当前行为状态,在经验池中选择并输出自动驾驶车辆的动作行为,如果经验池中没有与当前环境状态对应的动作行为,则由深度强化学习结构计算并输出自动驾驶车辆的动作行为。
进一步地,所述的步骤s1具体包括:
步骤s101、通过rgb摄像头接收前方道路的环境信息,通过红外摄像头接收前方道路中被遮挡物体信息,通过固态激光雷达接受车身两侧的环境信息;
步骤s102、对环境信息数据进行环境感知检测;
步骤s103、对环境信息数据进行融合处理,得到当前环境状态。
进一步地,所述的融合处理的公式为
其中:h表示归一化值;g表示再缩放参数;x表示当前环境状态下的参数;μ表示均值;σ表示方差;b表示再平移参数。
进一步地,在经验池中选择并输出自动驾驶车辆的动作行为具体包括:
步骤s201、采集和学习人类驾驶员的驾驶经验,形成状态行为集合;
步骤s202、将状态行为集合放入经验池中进行存储,在遇到相同环境状态时,直接从经验池中选取相应的动作行为输出。
进一步地,所述的步骤s201具体包括:
步骤s2011、采集和学习人类驾驶员在不同时间和不同环境状态下的动作行为决策序列
步骤s2012、抽取动作行为对,并构建状态行为集合d={(s1,a1),(s2,a2),(s3,a3)......}。
进一步地,所述的步骤s202具体包括:
步骤s2021、构建经验池,将状态行为集合放入经验池中保存;
步骤s2022、将当前环境状态与状态行为集合中的环境状态做对比,若匹配成功,则直接输出该环境状态对应的动作行为;若匹配不成功,则由深度强化学习结构计算并输出动作行为。
进一步地,由深度强化学习结构计算并输出自动驾驶车辆的动作行为具体包括:
步骤s211、构建基于ppo算法框架的深度强化学习结构;
步骤s212、对深度强化学习结构进行训练;
步骤s213、由训练完成的深度强化学习结构根据当前环境状态和自动驾驶车辆的当前行为状态计算并输出动作行为。
进一步地,所述的深度强化学习结构是actor-critic网络结构,所述的actor-critic网络结构包括n层深度卷积神经网络,所述深度卷积神经网络网络由一维卷积层、relu层和输出层组成。
进一步地,所述的步骤s212具体包括:
步骤s2121、actor卷积网络根据当前环境状态选择合适的动作行为,并且不断迭代,得到每个环境状态下选择每个动作行为的合理概率,critic卷积网络也不断迭代,不断完善每个环境状态下选择的每一个动作行为的奖惩值;
步骤s2122、做策略函数的近似函数;
步骤s2123、做状态价值函数的近似函数;
步骤s2124、做动作价值函数的近似函数;
步骤s2125、计算actor的损失函数;
步骤s2126、计算critic的损失函数;
步骤s2127、重复步骤s2121至步骤s2124,直到迭代达到最大步数或步骤s2125和步骤s2126的损失值小于给定阈值;
步骤s2128、加入正则化函数,减小计算的误差。
本发明的基于深度强化学习的自动驾驶行为决策方法,采用rgb摄像头和红外摄像头采集前方道路信息,不受时间和地点的限制,可以在夜间、光线条件不好或有遮挡的情况下实现环境感知。只需在车身两侧安装固态激光雷达感知车身两侧的环境信息,减少了传感器的使用。使得行为决策不受环境因素的限制,可以在任意环境的道路上行驶,不需要预先设定和建模,因此,本发明的方法具有非常强的通用和灵活性。
通过模仿学习人类驾驶员的驾驶经验并形成经验池,行为决策时优先获取与经验池中环境相似的动作输出,不仅解决了计算量大、代码冗长且繁琐的问题,并且通过模仿学习使得自动驾驶车辆更接近人类的驾驶习惯,有利于解决有人车和无人车在路上并存的问题,更重要的是提升了安全性。
附图说明
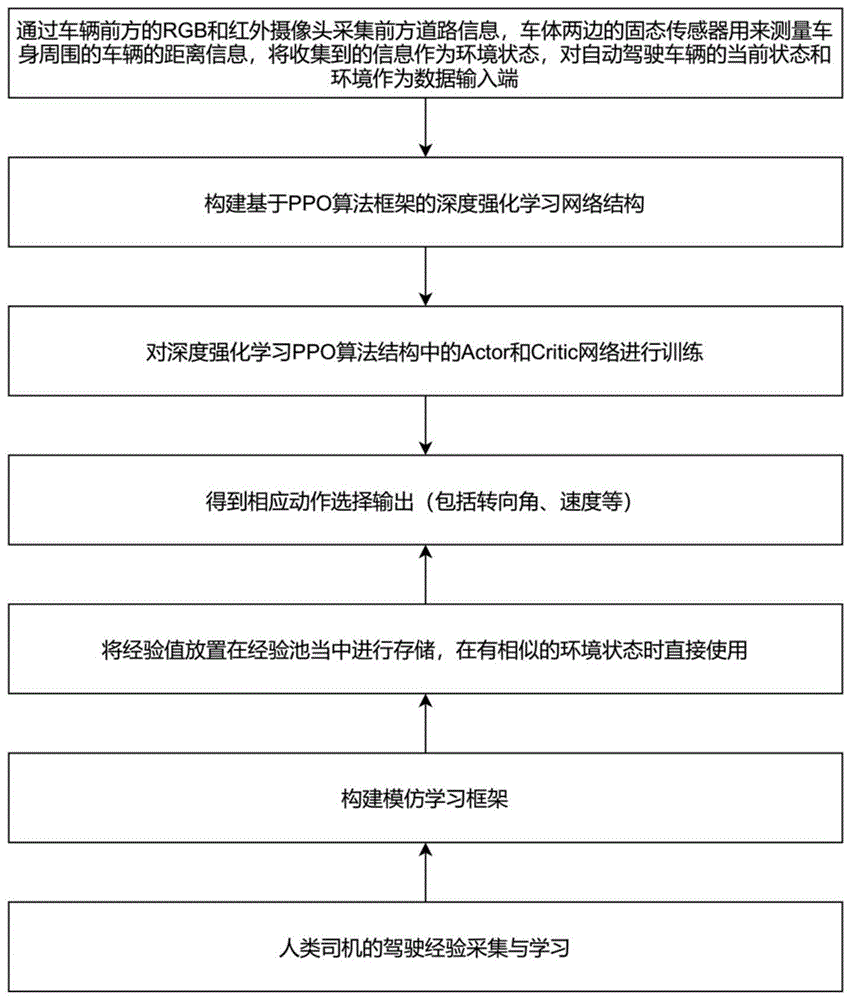
图1为本发明的基于深度强化学习的自动驾驶行为决策方法的框图;
图2为本发明中的环境感知所使用的传感器的摆放位置示意图;
图3为本发明实施例中基于ppo算法框架的深度强化学习结构的示意图;
图4为本发明中ppo算法框架中的actor-critic网络结构示意图;
图5为本发明中模仿学习人类驾驶经验的算法结构;
图6为正则化方法的工作原理图。
具体实施例
下面结合附图对本公开实施例进行详细描述。
以下通过特定的具体实例说明本公开的实施方式,本领域技术人员可由本说明书所揭露的内容轻易地了解本公开的其他优点与功效。显然,所描述的实施例仅仅是本公开一部分实施例,而不是全部的实施例。本公开还可以通过另外不同的具体实施方式加以实施或应用,本说明书中的各项细节也可以基于不同观点与应用,在没有背离本公开的精神下进行各种修饰或改变。需说明的是,在不冲突的情况下,以下实施例及实施例中的特征可以相互组合。基于本公开中的实施例,本领域普通技术人员在没有作出创造性劳动前提下所获得的所有其他实施例,都属于本公开保护的范围。
基于深度强化学习的自动驾驶行为决策方法,如图1所示。自动驾驶车辆的动作行为通过两种方式获得,第一种方式是:由深度强化学习结构根据输入的当前环境状态数据和自动驾驶车辆的当前行为状态数据计算得出。第二种方式是:根据输入的当前环境状态数据和自动驾驶车辆的当前行为状态数据,在构建好的经验池中选择动作行为。经验池是自动驾驶车辆通过模仿学习人类驾驶经验获得的。当前环境状态数据包括自动驾驶车辆前方障碍物、车道线等道路信息,以及前方障碍物、车道线等距离车头的空间距离,车身两侧的障碍物和车道线距离车身侧面的空间距离等。自动驾驶车辆的当前行为状态数据包括车辆的行驶速度、加速度、转向等信息。
本发明的基于深度强化学习的自动驾驶行为决策方法具体包括以下步骤:
步骤s1、获取自动驾驶车辆周围的当前环境状态数据。
进一步地,在本发明公开的一种实施例中,获取自动驾驶车辆周围的当前环境状态数据,包括:通过车辆前方的rgb摄像头和红外摄像头采集前方道路的信息,通过车辆左右两侧的固态激光雷达测量左右两侧车辆或障碍物的距离信息,这两组信息作为输入,对自动驾驶车辆当前所处的环境状态进行表述。自动驾驶车辆当前所处的环境状态包括自动驾驶车辆前方是否有行人、是否有车辆、是否有如车道线之类的道路信息、是否有其他障碍物,以及它们距离车头的空间距离。
步骤s1具体包括:
步骤s101、通过rgb摄像头接收前方道路的环境信息。环境信息包括但不限于:车道线相对于车头的空间位置、交通标识相对于车头的空间位置、行人相对于车头的空间位置、车辆相对于车头的空间位置等。
通过红外摄像头接收前方道路中被遮挡物体信息,以及在夜间或视线效果极差的情况下接收前方道路的环境信息。包括但不限于:行人、车辆、道路周边障碍物等。
通过固态激光雷达接受车身两侧的环境信息。包括但不限于:当前车身周围的车辆、障碍物、障碍物与车身的距离、周围的车辆与车身的距离。
现有的自动驾驶技术中的环境感知部分,一般情况下需要较多的传感器去感应周围环境信息,如在车身周围安装激光雷达、固态激光雷达、多路摄像头及其他传感器,导致自动驾驶车辆成本增加。本发明只需在车头安装一个rgb摄像头和一个红外摄像头,在车身两侧各安装一个固态激光雷达。降低了自动驾驶车辆的成本。
步骤s102、对环境信息数据进行环境感知检测。
包括通过mobilenet+vgg算法的方式对道路中的障碍物进行检测和识别。通过fullyconvolutionalnetworks图像分割技术对道路信息进行分割处理。
步骤s103、对环境信息数据进行融合处理。
进一步地,对环境信息数据进行融合的具体过程为:根据数据归一化(normalization)公式,对环境信息数据做融合处理,得到当前的环境状态s。数据归一化公式为:
其中:h表示归一化值;g表示再缩放参数;x表示当前环境状态下的参数,包括自动驾驶车辆前方障碍物和车道线等距离车头的空间距离,车身两侧的障碍物和车道线距离车身侧面的空间距离等;μ表示均值;σ表示方差;b表示再平移参数。
步骤s2、根据输入的当前环境状态和自动驾驶车辆的当前行为状态,由深度强化学习结构计算并输出自动驾驶车辆的动作行为,或者在构建好的经验池中选择并输出自动驾驶车辆的动作行为。
优先在构建好的经验池中选择并输出自动驾驶车辆的动作行为,如果在经验池匹配不到,则由深度强化学习结构计算并输出自动驾驶车辆的动作行为。在经验池中选择动作行为可以减少自动驾驶车辆的计算量,解决了计算量大、代码冗长且繁琐的问题。经验池是根据人类驾驶习惯形成的,经验池中的动作行为更接近人类的驾驶习惯,有利于解决有人车和无人车在路上并存的问题,更重要的是提升了安全性。
进一步地,在本发明公开的一种实施例中,在构建好的经验池中选择并输出自动驾驶车辆的动作行为具体包括以下步骤:
步骤s201、采集和学习人类驾驶员的驾驶经验,形成状态行为集合。
具体包括:
步骤s2011、采集和学习人类驾驶员在不同时间和不同环境状态下的动作行为决策序列
步骤s2012、抽取动作行为对,并构建状态行为集合d={(s1,a1),(s2,a2),(s3,a3)......}。
状态行为集合中(s1,a1)表示一个状态行为对,一种环境状态对应一个动作行为。输入状态为汽车摄像头所观测到的画面ot。动作即为转向角度,根据人类驾驶员提供的环境状态对应的动作行为对来学习得到驾驶中的转向行为策略。
步骤s202、将状态行为集合放入建立的经验池中进行存储,在遇到相同环境状态时,可以直接从经验池中选取相应的动作行为输出。
步骤s2021、构建经验池,将状态行为集合放入经验池中保存。
步骤s2022、将当前环境状态与状态行为集合中的环境状态做对比,若匹配成功,则直接输出该环境状态对应的动作行为;若匹配不成功,则由深度强化学习结构计算并输出动作行为。
进一步地,在本发明公开的一种实施例中,由深度强化学习结构计算并输出自动驾驶车辆的动作行为具体包括以下步骤:
步骤s211、构建基于ppo算法框架的深度强化学习结构。
深度强化学习结构的目的是以当前的环境状态s、及自动驾驶车辆的当前行为状态w作为输入,自动驾驶车辆的动作行为a作为输出。动作行为a包括转向角、加速度和刹车。
具体地,通过ppo算法框架,构建actor-critic网络结构。actor-critic网络结构包括n层的深度卷积神经网络,深度卷积神经网络网络由一维卷积层、relu层(rectifiedlinearunit,线性整流层)和输出层组成。
当前环境状态s和自动驾驶汽车的当前行为状态首先通过一维卷积层和relu层获得一个中间特征向量,然后再通过若干次的学习和迭代,最后通过输出层输出自动驾驶汽车的动作行为。
一维卷积层用于采集视觉传感器(rgb摄像头和红外摄像头)获取的图片,提取图片中的环境状态特征和行为状态特征。relu层用于将环境状态特征和行为状态特征对应到具体的动作行为,输出层用于输出动作行为。
步骤s212、对深度强化学习结构进行训练。
利用ppo算法框架中的actor-critic网络结构进行动作选择训练,通过训练得到策略函数πθ(s,a)、状态价值函数
具体地,对深度强化学习结构进行训练包括以下步骤:
步骤s2121、actor卷积网络根据当前环境状态s选择合适的动作行为a,并且不断迭代,得到每一个环境状态下选择每个动作行为的合理概率,critic卷积网络也不断迭代,不断完善每个环境状态下选择的每一个动作行为的奖惩值。
步骤s2122、做策略函数的近似函数。
πθ(s,a)=p(a|s,θ)≈π(a|s)公式(2)
其中s表示当前环境状态;a表示动作行为;θ表示策略参数。
步骤s2123、做状态价值函数的近似函数。
s表示当前环境状态,w表示当前行为状态,π表示策略,
步骤s2124、做动作价值函数的近似函数。
s表示当前环境状态,w表示当前行为状态,a表示动作行为,
步骤s2125、计算actor的损失函数。
clip表示ppo-clip算法的简称,依靠对目标函数的专门裁剪来减小新老策略的差异的ppo算法版本,s表示计算熵值,ltclip+s表示value(值)函数的损失函数,θ表示策略参数,ltclip(θ)表示在策略参数θ条件下第t个动作损失函数,c2表示系数2(可根据需要设定),s[πθ](st)表示在第t个环境状态下,其参数为θ的策略π的熵的值。
步骤s2126、计算critic的损失函数。
td表示td(temporedifference,时序差分)误差(td-error)的缩写,losstd表示时序差分误差的损失函数,t表示总目标的个数,c1表示系数1(可自己定义),∑表示函数求和符号,vθ(st)表示第t个的状态下策略参数θ的值函数,
步骤s2127、重复步骤s2121至步骤s2124,直到迭代达到最大步数或步骤s2125和步骤s2126的损失值小于给定阈值。
步骤s2128、加入正则化层dropout,以减小计算的误差。
正则化的本质就是给模型加一些规则限制,约束要优化参数,其常用方式为在目标函数后面添加一个系数的″惩罚项″,目的为了防止系数过大从而让模型变得复杂,防止过拟合。dropout是一种计算方便但功能强大的正则化方法,适用于神经网络。他的基本步骤是在每一次的迭代中,随机删除一部分节点,只训练剩下的节点。每次迭代都会随机删除,每次迭代删除的节点也都不一样,相当于每次迭代训练的都是不一样的网络,通过这样的方式降低节点之间的关联性以及模型的复杂度,从而达到正则化的效果。
dropout工作原理图如图6所示。
步骤s213、由训练完成的深度强化学习结构根据当前环境状态计算并输出动作行为。
经过上述长期的训练、模拟和测试,自动驾驶汽车可以根据较少的传感器信息,完成全天候、全环境的自动驾驶行为决策。
以上仅为说明本发明的实施方式,并不用于限制本发明,对于本领域的技术人员来说,凡在本发明的精神和原则之内,不经过创造性劳动所作的任何修改、等同替换、改进等,均应包含在本发明的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!