一种车辆智能驾驶纵向控制方法、系统及存储介质与流程
1.本技术实施例涉及自动驾驶技术领域,尤其涉及一种考虑驾驶风格的车辆智能驾驶纵向控制方法、系统及存储介质。
背景技术:
2.随着汽车技术的迅猛发展,汽车产业开始从手动驾驶向自动化智能驾驶领域发展。环境感知、运动预测规划、运动决策控制是智能驾驶技术中的三大核心技术。现今国内外的各大汽车生产制造商、科技公司以及科研院,对智能驾驶的研发大多以计算机视觉为核心,聚焦于环境感知与运动预测规划方面。而运动决策控制作为智能驾驶技术的核心部分,其性能的好坏直接决定着车辆的驾驶安全性和自动化程度。
3.运动决策控制分为横向控制和纵向控制两个部分:横向控制主要是通过一系列控制算法实现对车辆的实时转向控制,使车辆按照运动预测规划的行驶路线进行车道保持、自动换道、动态避障、掉头和转弯等;纵向控制主要是通过对车辆加、减速度的控制,使车辆能够以一定的安全行驶速度进行纵向运动,实现自动起停、跟随和巡航等。即,横向控制的目标是实现轨迹跟踪,纵向控制的目标是实现速度跟踪;通过对横纵向控制的耦合,使整个运动决策控制能够同时对车辆的转向和速度实现自动控制。
4.现实中的车辆运行轨迹等交通数据获取困难,并且车辆自动驾驶行为的很多探索都无法实验,这就需要借助仿真的方式去实现。通过实车试验确定的智能驾驶控制策略的置信度高,但所需时间长、经济成本高昂;将智能驾驶控制策略在仿真场景中进行调试,所需的时间少、安全性高、且经济成本低,但其得到的控制策略置信度低。因此,前期借助微观仿真平台预设计车辆智能驾驶控制策略,待仿真调试训练出成熟的控制策略后,再嵌入到车辆的智能驾驶计算平台(域控制器)硬件产品的开发中,在实车上进行调试与优化,实现兼顾功能和经济的车辆交付与量产的解决方案。
5.但是,现有的车辆智能驾驶控制方法,至少存在以下两个问题:1)重点关注车辆的驾驶安全性,而忽略行车效率和乘客舒适度;2)未考虑不同驾驶激进程度喜好的驾驶员对车辆智能驾驶功能的驾驶风格需求,无法改善用户体验。
技术实现要素:
6.针对现有技术的以上缺陷或改进需求,本技术的目的在于,提供一种车辆智能驾驶纵向控制方法、系统及存储介质,基于对驾驶员驾驶风格的考虑,优化纵向控制策略,可以实现兼具安全性、效率和舒适度体验的智能驾驶控制。
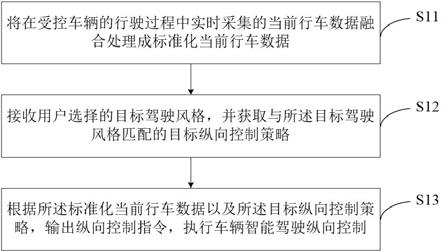
7.为实现上述目的,本技术第一实施例提供了一种车辆智能驾驶纵向控制方法,所述方法包括如下步骤:将在受控车辆的行驶过程中实时采集的当前行车数据融合处理成标准化当前行车数据;接收用户选择的目标驾驶风格,并获取与所述目标驾驶风格匹配的目标纵向控制策略;根据所述标准化当前行车数据以及所述目标纵向控制策略,输出纵向控制指令,执行车辆智能驾驶纵向控制。
8.在一些实施例中,所述方法进一步采用以下方式预先获取与不同驾驶风格匹配的相应预设纵向控制策略:预先配置与不同驾驶风格对应的初始纵向控制策略;在微观交通仿真平台中构建目标道路仿真场景;在所述目标道路仿真场景中进行不同初始纵向控制策略的训练和测试,获取相应的测试后的纵向控制策略;将所述测试后的纵向控制策略嵌入到车辆的智能驾驶域控制器的设计开发中;将开发完成的所述智能驾驶域控制器装载至实验车辆上,进行实车功能验证与性能联调,获取优化后的纵向控制策略作为与相应驾驶风格匹配的预设纵向控制策略。
9.为实现上述目的,本技术第二实施例提供了一种车辆智能驾驶纵向控制系统,所述系统包括:传感器模组,用于在受控车辆的行驶过程中实时采集的当前行车数据,并融合处理成标准化当前行车数据;纵向控制决策模组,用于接收所述标准化当前行车数据以及用户选择的目标驾驶风格,并获取与所述目标驾驶风格匹配的目标纵向控制策略,以及根据所述标准化当前行车数据以及所述目标纵向控制策略,并输出纵向控制指令至纵向控制执行模组,由所述纵向决策控制执行模组执行车辆智能驾驶纵向控制。
10.为实现上述目的,本技术第三实施例提供了一种计算机可读存储介质,所述存储介质存储有计算机可执行程序,所述计算机可执行程序在被处理器执行时实现本技术所述的方法的步骤。
11.与现有技术相比,本技术实施例提供的车辆智能驾驶纵向控制方式,可以在满足纵向控制功能的同时,兼具行车效率、驾驶安全性和乘客舒适度;并通过配置与不同驾驶风格匹配的纵向控制策略,实现可以基于驾驶员驾驶风格的选择匹配相应的纵向控制策略,满足不同驾驶激进程度喜好的驾驶员对车辆智能驾驶功能的驾驶风格需求,改善了用户体验。
附图说明
12.为了更清楚地说明本技术实施例中的技术方案,下面将对实施例描述中所需要使用的附图作简要介绍。显而易见地,下面描述中的附图仅是本技术的一些实施例,对于本领域的普通技术人员来讲,在不付出创造性劳动的前提下,还可以根据这些附图获得其它的附图。
13.图1为本技术实施例提供的车辆智能驾驶纵向控制方法的流程示意图;图2为本技术实施例提供的获取与不同驾驶风格匹配的相应预设纵向控制策略方法的流程示意图;图3为本技术实施例所构建的仿真场景及车流情况示意图;图4为本技术实施例智能体与仿真环境的交互情况的示意图;图5为本技术实施例提供的车辆智能驾驶纵向控制系统的架构示意图。
具体实施方式
14.下面将结合本技术实施例中的附图,对本技术实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅是本技术一部分实施例,而不是全部的实施例。基于本技术中的实施例,本领域技术人员在没有作出创造性劳动前提下所获得的所有其它实施例,都属于本技术保护的范围。
15.需要说明的是,本技术的文件中涉及的术语“包括”和“具有”以及它们的变形,意图在于覆盖不排他的包含。术语“第一”、“第二”等是用于区别类似的对象,而不必用于描述特定的顺序或先后次序,除非上下文有明确指示,应该理解这样使用的数据在适当情况下可以互换。另外,在不冲突的情况下,本技术中的实施例及实施例中的特征可以相互组合。此外,在以下说明中,省略了对公知结构和技术的描述,以避免不必要地混淆本技术的概念。
16.本技术实施例中涉及的名词适推用于如下的解释:drl(deep reinforcement learning):深度强化学习;ttc(time to collision):碰撞时间;ppo(proximal policy optimization):近端策略优化算法trpo(trust region policy optimization)置信域策略优化算法。
17.在介绍本技术实施例车辆智能驾驶纵向控制方法之前,先介绍现今车辆自动驾驶的实现方式。车辆自动驾驶的实现如今有两大方向,分别是基于规则(rule
‑
based)和基于端到端(end
‑
to
‑
end)的自动驾驶系统。
18.基于规则的自动驾驶系统的实现方式是:顺序依次地将受控车辆的行驶过程分解为不同模块的多个子任务,大致分为传感、地图定位、路径规划与决策控制等过程。受控车辆通过车上各类传感器感知到如道路情况、车辆汇入、交通法规等静动态信息,形成完备的外部环境模型;受控车辆的智能驾驶域控制器根据行驶任务、外部环境等建立行为规则库,驾驶过程中根据实际情况在规则库中进行匹配与推理决策;决策后通过各层控制信号对受控车辆进行横纵向控制,实现特定场景下的自动驾驶。该方式的主要特点是:系统可解释性强,车辆的每一个行为都能得到演绎和解释;但是系统复杂性高,需要上千个模块去支持车辆的自动驾驶功能实现。
19.基于端到端的自动驾驶系统的实现方式是:将复杂的驾驶任务看作一个系统,以整体系统的方式借助深度学习以端到端的形式去实现所有的驾驶功能。受控车辆通过车上各类传感器感知到如道路情况、车辆汇入、交通法规等静动态信息;经过特征提取与神经网络处理;以“试错”的方式和仿真交通环境产生交互,进行大量训练与迭代学习,以最大化累计回报得到最优驾驶决策;决策后通过各层控制信号对受控车辆进行横纵向控制,实现特定场景下的自动驾驶。该方式的主要特点是:系统复杂性低,不需要对整车系统进行复杂拆解;但是系统可解释性差,由于采取强化学习,无法用准确的数学表达式去解释车辆每一步的行为决策。
20.在合适的环境下选择这两种实现方式的其中之一,有时还需要这两种方式相融合去解决实际问题。
21.请参阅图1,其为本技术实施例提供的车辆智能驾驶纵向控制方法的流程示意图。如图1所示,本实施例所述的方法包括如下步骤:s11、将在受控车辆的行驶过程中实时采集的当前行车数据融合处理成标准化当前行车数据;s12、接收用户选择的目标驾驶风格,并获取与所述目标驾驶风格匹配的目标纵向控制策略;s13、根据所述标准化当前行车数据以及所述目标纵向控制策略,输出纵向控制指令,执行车辆智能驾驶纵向控制。本实施例所述的方法适用于目标道路场景下对于受控车辆(自动驾驶车辆)的纵向跟驰行为进行控制,以下给出详细解释说明。
22.关于步骤s11、将在受控车辆的行驶过程中实时采集的当前行车数据融合处理成标准化当前行车数据。
23.具体地,在本步骤中,可以采用传感器模组在受控车辆的行驶过程中实时采集当前行车数据。传感器模组可以包括摄像头、激光雷达、毫米波雷达、超声波雷达、高精度地图等设备;这些设备按照功能使用分布在受控车辆的车身周围,负责探知受控车辆的当前行车数据。当前行车数据可以包括人员信息(例如驾驶员的疲劳状态,还可以收集驾驶员的年龄、性别,以辅助进行纵向控制策略的决策)、道路信息(道路类型、车道数、限速信息等)、环境信息(光照水平、天气情况、交通状况等)、受控车辆的运动状态(包括自车速度、自车加速度、车头间距等,还可以收集车辆的制动性能以辅助进行纵向控制策略的决策)、周围车辆运动状态等。可以由智能驾驶域控制器对当前行车数据接收并进行融合处理,处理成智能驾驶的决策控制模组可识别的标准化当前行车数据,从而分别用于自动驾驶运行状态决策、纵向控制。
24.关于步骤s12、接收用户选择的目标驾驶风格,并获取与所述目标驾驶风格匹配的目标纵向控制策略。
25.具体地,在本步骤中,用户可以根据控制屏幕(例如受控车辆的中控屏幕、或具有触控功能、并加载有本技术车辆智能驾驶纵向控制方法的用户终端设备的触控屏幕)上的软开关的提示,选择符合自身喜好的目标驾驶风格。可以提高决策控制模组根据预先获取的纵向控制策略,以及不同驾驶风格与纵向控制策略的匹配关系,获取与用户所选驾驶风格匹配的纵向控制策略。自动驾驶车辆是通过智能驾驶系统来实现自动化行驶,其中,纵向控制利用接收到的自车车速和自车加速度信息、前后车辆运动状态、跟车间距以及目标纵向控制策略,进行综合决策和计算,完成控制受控车辆行驶所需的目标车速、加/减速度实时控制。 对于纵向控制,实现效率优化、提高安全性和乘客舒适度体验对车辆的智能驾驶域控制器的设计开发具有重要意义。
26.在一些实施例中,步骤s12进一步包括:1)根据接收到的用户选择的目标驾驶风格,获取与所述目标驾驶风格匹配的预设纵向控制策略并显示相应的预设纵向控制参数;2)接收用户对所显示的预设纵向控制参数进行的调整,获取所述目标纵向控制策略。也即,对于更个性化的驾驶需求,用户可在选定驾驶风格后,根据控制屏幕上的指示信息,在符合安全驾驶规则的基础上进一步改变选定驾驶风格所对应的纵向控制策略中的目标车速、跟车间距等参数值,获取更符合自身喜好的纵向控制策略,提高用户驾乘体验的满意度,甚至可以达到“千人千面”的驾驶需求。
27.请参阅图2,其为本技术实施例提供的获取与不同驾驶风格匹配的相应预设纵向控制策略方法的流程示意图。如图2所示,在一些实施例中,本实施例所述的方法进一步采用以下方式预先获取与不同驾驶风格匹配的相应预设纵向控制策略:s201、预先配置与不同驾驶风格对应的初始纵向控制策略;s202、在微观交通仿真平台中构建目标道路仿真场景;s203、在所述目标道路仿真场景中进行不同初始纵向控制策略的训练和测试,获取相应的测试后的纵向控制策略;s204、将所述测试后的纵向控制策略嵌入到车辆的智能驾驶域控制器的设计开发中;s205、将开发完成的所述智能驾驶域控制器装载至实验车辆上,进行实车功能验证与性能联调,获取优化后的纵向控制策略作为与相应驾驶风格匹配的预设纵向控制策略。
28.在一些实施例中,步骤s201所述的预先配置与不同驾驶风格对应的初始纵向控制策略进一步包括:配置自动驾驶车辆的状态空间、动作空间与回报函数,并通过分别调整回报函数中效率的系数、安全性的系数及舒适度的系数,以确定至少三种不同驾驶风格对应的初始纵向控制策略。例如,通过调整回报函数中效率、安全性及舒适度这三项的系数,可以确定柔和模式、标准模式与敏捷模式的不同驾驶风格。其中,柔和模式下驾驶员相对保守与谨慎,他们以牺牲效率的方式来换取驾驶过程中的安全感,同时,他们对舒适度方面的要求也更高些;在这种情况下,效率的系数就设置的相对小一些(比其它模式的效率的系数小),安全性的系数设置的相对大一些(比其它模式的安全性的系数大),舒适度的系数也设置的相对大一些(比其它模式的舒适度的系数大)。标准模式下的系数设置基本符合大部分驾驶员的主观感受,效率的系数、安全性的系数、舒适度的系数均设置的相对适中。敏捷模式下驾驶员相对激进与大胆,他们在保证安全性的前提下希望获得更高的效率,同时,他们对舒适度方面的要求不太高;在这种情况下,效率的系数就设置的相对大一些(比其它模式的效率的系数大),安全性的系数设置的相对适中(例如可以和标准模式的安全性的系数相同),舒适度的系数则设置的相对小一些(比其它模式的舒适度的系数小)。
29.在一些实施例中,所述状态空间包括以下环境信息的至少其中之一:所述自动驾驶车辆的自车速度、自车与前车的速度差、自车与后车的速度差、自车与前车的车头间距以及自车与后车的车头间距。
30.在仿真中,将自动驾驶车辆虚拟化为智能体,借助深度强化学习,定义智能体的状态空间、动作空间与回报函数。
31.具体地,智能体的状态空间s涵盖的环境信息主要是车速和车头间距两部分.状态空间s可以采用如下公式表示:s=(v,
∆
v1,
∆
v2,h1,h2);其中,v为自车速度,
∆
v1为自车与前车的速度差,
∆
v2为自车与后车的速度差;h1为自车与前车的车头间距,h2为自车与后车的车头间距。
32.在一些实施例中,所述动作空间为所述自动驾驶车辆在纵向跟驰行为中每一步执行的动作,所述动作包括所述自动驾驶车辆的每一步执行的自车加速度;其中,所述自车加速度大于或等于所述自动驾驶车辆的最大减速度阈值、且小于或等于所述自动驾驶车辆的最大加速度阈值。
33.接上述实施例,具体地,智能体的动作空间是智能体在纵向跟驰行为中每一步执行的动作,它表示智能体每一步执行的自车加速度,即具体的加速/减速值;但加速/减速值大小不能超过自动驾驶车辆设计要求的最大加速/减速值。动作空间a可以采用如下公式表示:a=(c),c∈[c
min
,c
max
];其中,c为自车加速度;c
min
为最大减速度,c
max
为最大加速度。标准模式下,c
min
取值可以为
‑
7.5m/s2,c
max
取值可以为2.9m/s2。
[0034]
在一些实施例中,所述回报函数采用自车速度描述所述自动驾驶车辆的效率,采用碰撞时间指标来评判所述自动驾驶车辆的在行驶中的安全性,采用自车加速度和自车加速度变化率描述所述自动驾驶车辆的乘客的舒适度,并为不同驾驶风格对应的初始纵向控制策略配置相应的效率的系数、安全性的系数及舒适度的系数。
[0035]
接上述实施例,本实施例兼顾安全性、效率及乘客舒适度,设计了相应的智能体回报函数。一方面,智能体需以较高的车速(即效率要求)在仿真环境中驾驶;另一方面,智能体在仿真环境中驾驶要满足安全性条件,本实施例采用ttc指标来评判智能体在行驶中的安全性;同时,回报函数的设计也要适当考虑乘客的舒适度体验,本实施例采用加速度和加速度变化率来描述乘客的舒适度感受。具体地,所述回报函数r采用以下公式表示:其中,v为自车速度,v
des
为自车目标车速,t
ttc
为碰撞时间值,t
max
为碰撞时间阈值,c为自车加速度,a
max
为乘客感到舒适的最大加速度,j为自车加速度变化率,j
max
为乘客感到舒适的最大加速度变化率,a为效率的系数,b为安全性的系数,c为舒适度的系数。碰撞时间值t
ttc
可以通过为自车与前车的车头间距除以前后两车的速度差计算得到。
[0036]
在驾驶风格为标准模式下,系数a、b、c的取值可以分别为1,0.5,0.5。碰撞时间阈值t
max
一般取1.5秒;根据各品牌不同车型实际情况,可以设置相应的自车目标车速v
des
,本实施例中设置默认值为30m/s2;乘客感到舒适的最大加速度a
max
可以取4m/s2;乘客感到舒适的最大加速度变化率j
max
可以取2m/s3。
[0037]
通过调整回报函数中效率、安全性及舒适度这三项的系数,可以确定柔和模式、标准模式与敏捷模式的不同驾驶风格。一实施例的不同驾驶风格下回报函数各项系数设置情况可以参考表1所示。
[0038]
表1 不同驾驶风格下回报函数各项系数设置情况。
[0039]
在一些实施例中,所述方法进一步包括:通过对以下参数的至少其中之一采用不同配置,以进一步区分不同驾驶风格对应的初始纵向控制策略:激活车速、纵向最大加减速度及其变化率、跟车间距、急加速响应时间。即,除了改变回报函数中各项系数值以区分不同驾驶风格的纵向控制策略外,在驾驶时还可以对激活车速、纵向最大加减速度及其变化率、跟车间距、急加速响应时间等参数设置不同值,以进一步区分不同驾驶风格,并优化驾驶策略。以激活车速为例,柔和模式和标准模式下激活车速可以取当前车速值,而敏捷模式下激活车速取允许限速值。
[0040]
在一些实施例中,步骤s203所述的在所述目标道路仿真场景中进行不同初始纵向控制策略的训练和测试,获取相应的测试后的纵向控制策略的步骤进一步包括:1)选择基于策略梯度的算法,构建卷积网络模型,以对所述初始纵向控制策略进行多次迭代深度强化学习训练,得到训练后的纵向控制策略;2)将配置所述训练后的纵向控制策略的自动驾
驶车辆加载到所述目标道路仿真场景进行多次测试,通过所述自动驾驶车辆与所述目标道路仿真场景中的交通环境的交互和反馈,优化所述训练后的纵向控制策略,获取相应的测试后的纵向控制策略。
[0041]
在目标道路场景下,对于自动驾驶车辆的纵向跟驰行为,通过将自动驾驶车辆看作智能体,通过定义智能体的状态空间、动作空间与回报函数,借助深度强化学习训练,并使智能体在仿真环境中进行测试,通过与仿真环境中的交通环境的交互和反馈,学习到最优纵向控制策略。可以选择基于策略梯度的算法,如trpo、ppo等算法;确定训练算法后,构建卷积网络模型,并对模型涉及到的各超参数(如学习率、折扣率等)调参;通过选定的算法以及构建的模型,在仿真环境中对配置了相应纵向控制策略的智能体进行训练,经过多次迭代学习后得到最优驾驶决策作为训练后的纵向控制策略。将采用训练后的纵向控制策略的智能体加载到仿真平台上进行多次测试,通过与仿真环境中的交通环境的交互和反馈,根据智能体性能表现进行优化,获取相应的测试后的纵向控制策略。
[0042]
以下以高快速道路场景为例,对本技术考虑驾驶风格的车辆智能驾驶纵向控制策略的获取的基本工作流程作进一步解释说明。
[0043]
第一步,智能驾驶纵向控制策略制定,即预先配置与不同驾驶风格对应的初始纵向控制策略。具体地,制定一种兼顾行车效率、驾驶安全性与乘客舒适度,并考虑不同驾驶风格的纵向控制策略;可参考上述实施例的步骤s201所述。
[0044]
第二步,仿真场景构建与车流加载,即在微观交通仿真平台中构建本实施例适用的高快速道路仿真场景,并将自动驾驶车辆与手动驾驶车辆加载到仿真场景中。所构建的仿真场景及车流情况如图3所示,其中,自动驾驶车辆31(智能体)采用本技术制定的智能驾驶纵向控制策略,手动驾驶车辆32采用仿真平台自带的gm(general motors,通用型汽车)车辆跟驰模型,箭头示意车辆行驶方向。
[0045]
第三步,进行纵向控制策略训练与仿真测试。即在仿真场景中多次训练确定最终纵向控制策略的各超参数值及模型网络结构,并通过智能体与仿真场景中的交通环境(仿真环境)的交互和反馈,优化所述训练后的纵向控制策略,获取相应的测试后的纵向控制策略。智能体与仿真环境的交互情况如图4所示,其中,不同的纵向控制策略π会控制智能体执行不同的动作a,与仿真环境的交互会反馈相应的状态s与回报函数r,从而通过多次测试优化纵向控制策略。
[0046]
第四步,智能驾驶域控制器的设计与开发。即,将第三步训练测试得到的智能驾驶纵向控制策略嵌入到智能驾驶域控制器的设计开发中,在车辆的智能驾驶域控制器开发中采用该测试成熟的纵向控制策略。
[0047]
第五步,实车功能验证与性能联调。将开发完成的智能驾驶域控制器装载在实验车辆上后,进行实车功能验证与性能联调。在多次实车测试达到功能安全和性能精度要求,同时保证智能驾驶域控制器与车辆的其它模块(如智能座舱、智慧灯光系统等)的交互,使车辆在目标场景上可以自主顺利地完成驾驶任务,则可以实现搭载该智能驾驶域控制器的车辆交付与量产。
[0048]
关于步骤s13、根据所述标准化当前行车数据以及所述目标纵向控制策略,输出纵向控制指令,执行车辆智能驾驶纵向控制。
[0049]
具体地,在本步骤中,可以由智能驾驶域控制器根据所述标准化当前行车数据以
及所述目标纵向控制策略,调整当前纵向控制的各项参数值,并输出纵向控制指令,以支配受控车辆的油门和刹车,使车辆实现自动加减速,完成目标场景下的车辆智能驾驶纵向控制。
[0050]
根据以上内容可以看出,本技术实施例提供的车辆智能驾驶纵向控制方法可以在满足纵向控制功能的同时,兼具行车效率、驾驶安全性和乘客舒适度;并通过配置与不同驾驶风格匹配的纵向控制策略,实现可以基于驾驶员驾驶风格的选择匹配相应的纵向控制策略,满足不同驾驶激进程度喜好的驾驶员对车辆智能驾驶功能的驾驶风格需求,改善了用户体验。
[0051]
基于同一发明构思,本技术还提供了一种车辆智能驾驶纵向控制系统。
[0052]
请参阅图5,其为本技术实施例提供的车辆智能驾驶纵向控制系统的架构示意图。如图5所示,本实施例所述的系统50包括传感器模组51、纵向控制决策模组52以及纵向控制执行模组53。
[0053]
具体地,所述传感器模组51用于在受控车辆的行驶过程中实时采集的当前行车数据,并融合处理成标准化当前行车数据。所述纵向控制决策模组,用于接收所述标准化当前行车数据以及用户选择的目标驾驶风格,并获取与所述目标驾驶风格匹配的目标纵向控制策略,以及根据所述标准化当前行车数据以及所述目标纵向控制策略,并输出纵向控制指令至纵向控制执行模组,由所述纵向决策控制执行模组执行车辆智能驾驶纵向控制。其中,纵向控制决策模组52以及纵向控制执行模组53可以为集成于车辆的智能驾驶域控制器的功能模块。
[0054]
需要说明的是,本说明书中的各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同/相似的部分互相参见即可。对于本实施例公开的系统实施例而言,由于其与上述实施例公开的方法实施例相对应,所以描述的比较简单,相关之处参见方法实施例的部分说明即可。
[0055]
根据以上内容可以看出,本技术实施例提供的车辆智能驾驶纵向控制系统可以在满足纵向控制功能的同时,兼具行车效率、驾驶安全性和乘客舒适度;并通过配置与不同驾驶风格匹配的纵向控制策略,实现可以基于驾驶员驾驶风格的选择匹配相应的纵向控制策略,满足不同驾驶激进程度喜好的驾驶员对车辆智能驾驶功能的驾驶风格需求,改善了用户体验。
[0056]
本领域普通技术人员可以理解实现上述方法实施方式中的全部或部分步骤是可以通过程序来指令相关的硬件来完成,所述的程序可以存储于计算机可读取存储介质中,这里所称得的存储介质,如:rom/ram、磁碟、光盘等。即,本技术还公开了一种计算机可读存储介质,所述计算机可读存储介质内存储有计算机可执行程序,所述计算机可执行程序被执行时,实现本技术上述实施例所述的方法。所述计算机可执行程序可以置于随机存储器(ram)、内存、只读存储器(rom)、电可编程rom、电可擦除可编程rom、寄存器、硬盘、可移动磁盘、cd
‑
rom、或技术领域内所公知的任意其它形式的存储介质中。
[0057]
本领域技术人员应该还可以进一步意识到,结合本文中所公开的实施例描述的各示例的系统及方法步骤,能够以电子硬件、计算机软件或者二者的结合来实现,为了清楚地说明硬件和软件的可互换性,在上述说明中已经按照功能一般性地描述了各示例的组成及步骤。这些功能究竟以硬件还是软件方式来执行,取决于技术方案的特定应用和设计约束
条件。本领域技术人员可以对每个特定的应用来使用不同方法来实现所描述的功能,但是这种实现不应认为超出本技术的范围。
[0058]
以上所述,仅为本技术的具体实施方式,但本技术的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本技术揭露的技术范围内,可轻易想到变化或替换,都应涵盖在本技术的保护范围之内。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1