一种基于人机共驾理念的智能车辆集成式决策系统的制作方法
1.本发明涉及汽车自动驾驶技术领域,特别是一种基于人机共驾理念的智能车辆集成式决策系统。
背景技术:
2.随着汽车自动驾驶等级的提高,功能场景对车辆应对复杂多变场景下的自主决策能力的要求也在不断提升。传统的基于规则和人工设计的决策方法的比重会逐渐下降,学术界提出了很多基于数据驱动的ai算法来搭建决策模块,但是这类端到端的方法对数据量的需求较大,且具有不可解释性、不可预测的特点。如专利公开号cn113920484a基于单目rgb_d特征和强化学习的端到端自动驾驶决策方法,该专利基于相机的特征和强化学习进行端到端的自动驾驶决策,直接输出车辆的控制动作信号如刹车、油门、转向等,这种方法首先只考虑使用了单目相机的信息作为输入,并且端到端的直接输出控制指令,风险较高,实际可行性差。又如专利公开号cn112348201a一种基于联邦深度强化学习的自动驾驶群车的智能决策实现方法,该专利中引入了更多的传感器以及环境信息作为模型的输入,但是还没考虑到对人机共驾场景的适应,也并不具备全局上的一个多车之间的最优博弈决策能力。专利公开号cn113602284a人机共驾模式决策方法、装置、设备及存储介质中通过手表收集感应驾驶员的生理特征,为车辆功能的模式降级切换提供依据,但并未涉及到车辆在复杂场景下的行为决策。因此,亟需研发一种更为全面化的基于人机共驾理念的智能车辆集成式决策系统及决策方法,从而更好地进行决策。
技术实现要素:
3.本发明的目的在于,提供一种基于人机共驾理念的智能车辆集成式决策系统。本发明针对l2-l3级别自动驾驶人机共驾场景,实现了利用舱内信息指导车辆的道路行驶决策,提升系统的鲁棒性和安全性,同时利用外界行驶环境信息提升舱内乘客用户体验。
4.本发明的技术方案:一种基于人机共驾理念的智能车辆集成式决策系统,包括:
5.外界环境感知模块,用于将当前车辆外界环境传感信息进行处理,输出感知目标结果s
env
;
6.座舱感知模块,用于将座舱内感知系统的信息进行处理,输出感知结果s
cab
;
7.决策模块,用于将混合感知状态s=[s
env
,s
cab
]作为输入,并根据深度强化学习决策算法输出深度融合的决策动作a=[a
env
,a
cab
],决策动作a分两路输出,其中一路输出为针对车辆的行驶行为决策指令a
env
,另一路输出为座舱控制指令a
cab
;
[0008]
行驶行为控制模块,根据行驶行为决策指令a
env
对车辆的行驶状态进行适应性调整;
[0009]
舱内控制模块,根据座舱控制指令a
cab
对舱内执行设备进行适应性调整。
[0010]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,所述决策系统还包括规划模块,所述规划模块用于处理行驶行为决策指令a
env
,根据a
env
进行轨迹点规划,再输
出至行驶行为控制模块控制车辆的行驶状态。
[0011]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,所述决策系统还包括定位模块,所述定位模块用于将车辆的定位信息分别输出至决策模块、规划模块和行驶行为控制模块。
[0012]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,决策模块中深度强化学习决策算法采用的框架包括但不限于dqn、ddpg、a3c、ppo、sac中的一种强化学习框架。
[0013]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,决策模块中深度强化学习决策算法的使用过程包括:将混合感知状态s输入到当前网络参数为w的神经网络n中,从而输出决策值v,根据决策值v确定最终输出的决策动作a。
[0014]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,所述决策值v=[行驶决策v1,舱内决策(空调v2,灯光v3,音乐v4,车窗v5)],包含v1至v5的5类决策对象,在每一类决策对象中,根据贪婪策略选择最大数值所对应的决策作为最终的决策动作输出a=[a1,a2,a3,a4,a5]。
[0015]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,决策模块中深度强化学习决策算法的训练过程包括以下步骤:
[0016]
步骤1、初始化探索阈值e,初始化神经网络n的网络参数w;
[0017]
步骤2、将当前车辆的混合感知状态s=[s
env
,s
cab
]输入进神经网络n中,生成一个随机数e,
[0018]
若e≥e,则根据贪婪策略选择最大数值所对应的决策作为最终输出的决策动作a;
[0019]
若e<e,则随机生成决策动作a;
[0020]
步骤3、对此时处于混合感知状态s的车辆执行决策动作a,从而得到一个新的混合感知状态s’和奖励r,通过新的混合感知状态s’判断:
[0021]
若车辆发生碰撞,则得到终止标志flag=1;
[0022]
若车辆未发生碰撞,则flag=0;
[0023]
步骤4、将{s,a,s’,r,flag}这一组数据存入数据池中;
[0024]
步骤5、将s’赋值给s,车辆进入新的混合感知状态s’,同时将e*0.99999赋值给e,再进入步骤6;
[0025]
步骤6、从数据池中采集n组样本数据{sn,an,s
n’,rn,flagn},对于每一组样本数据计算当前决策目标值v
target
:
[0026]
若flag=1,则v
target
=r;
[0027]
若flag=0,则v
target
=r+γmax n(s
′
,w),其中γmax n(s
′
,w)的含义是将新的混合感知状态s’输入到当前网络参数为w的神经网络n中,根据贪婪策略输出最大的决策值,并乘以固定折扣值γ;
[0028]
步骤7、使用均方误差函数计算n个决策目标值v
target
的损失:
[0029]
步骤8、使用神经网络梯度反向传播来更新神经网络n的网络参数w,返回到步骤2,进行循环训练。
[0030]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,所述步骤3中奖励r
的函数为:r=a*安全性+b*效率性+c*舒适性+d*乘客体验,其中a、b、c、d分别代表各项评估指标的权重,安全性由碰撞惩罚计算,效率性由车速衡量,舒适性由换道惩罚以及加速度变化得出,乘客体验通过座舱内的感知系统给出。
[0031]
前述的一种基于人机共驾理念的智能车辆集成式决策系统中,所述步骤6中的固定折扣值γ=0.999。
[0032]
与现有技术相比,本发明的有益效果体现在:
[0033]
一、本发明改进了现有基于强化学习的端到端的自动驾驶决策方案中数据从仿真往实际迁移鸿沟大、训练难收敛、不可解释性等问题,也不同于那些完全基于人工设计规则的方法,本发明中提出的决策系统具备一定的自主应对复杂场景的能力;
[0034]
二、本发明利用深度强化学习框架,将l2-l3级别的自动驾驶系统与座舱系统集成为人机共驾系统,做成整车级别的包含车辆内外部的全局决策功能,提升安全性以及座舱内乘客的用户体验,其中,更是实现了利用舱内信息指导车辆的道路行驶决策提升系统的鲁棒性和安全性,同时利用外界行驶环境信息提升舱内乘客用户体验;
[0035]
三、本发明经过特殊设计的深度强化学习框架训练状态特征,提升了算法的泛化性和一致性,缩小了ai模型从仿真训练到实车部署之间的鸿沟,使大量的来自仿真环境的低成本数据能够很好地应用在实车上;同时,本发明结合了联邦学习和强化学习,为系统提供更多有价值的数据,提升技术迭代的效率。
附图说明
[0036]
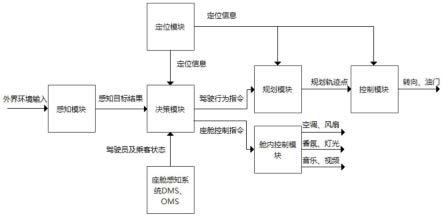
图1是本发明的系统框架结合决策流程的示意图;
[0037]
图2是实施例中的一种车辆驾驶场景;
[0038]
图3是深度强化学习决策算法的网络模型图。
具体实施方式
[0039]
下面结合附图和实施例对本发明作进一步的说明,但并不作为对本发明限制的依据。
[0040]
实施例:一种基于人机共驾理念的智能车辆集成式决策系统,系统结构参考图1所示,包括外界环境感知模块、座舱感知模块、决策模块、行驶行为控制模块、舱内控制模块、规划模块和定位模块,其中:
[0041]
外界环境感知模块,是用于将当前车辆外界环境传感信息进行处理,输出感知目标结果s
env
。
[0042]
座舱感知模块,是用于将座舱内感知系统的信息进行处理,输出感知结果s
cab
。
[0043]
即本发明中的强化学习的状态量为:外界环境传感器输入经过感知模块运算后得到的感知目标结果s
env
,以及座舱内感知系统的感知结果(包括乘客、驾驶员的状态等)s
cab
的拼接[s
env
,s
cab
]。
[0044]
为了实现以上数据的采集,人机共驾系统包含现有自动驾驶系统中自带的传感器:激光雷达、毫米波雷达、相机、超声波雷达等传感器,也涵盖了车内座舱感知系统:dms、oms,以充分收集车辆外部的道路信息以及车内的驾驶员、乘客的当前状态。
[0045]
决策模块,是用于将混合感知状态s=[s
env
,s
cab
]作为输入,并根据深度强化学习
决策算法输出深度融合的决策动作a=[a
env
,a
cab
],决策动作a分两路输出,其中一路输出为针对车辆的行驶行为决策指令a
env
,如变道、直行、左转、右转、停车等,由后续的下游规划模块以及行驶行为控制模块去做进一步的解释和执行;另一路输出为座舱控制指令a
cab
,如空调的功率、灯光开关、各种类型音乐的播放等。
[0046]
举例:检测到外界车流较多、天气状况恶劣的情况下,可以改变氛围灯为红色,同时输出的行为决策偏向于保守,尽量避免超车和换道;当检测到驾驶员精神不振时,可以舱内播放提神的音乐,同时整车放缓车速。
[0047]
本发明中针对强化学习的状态量做了特殊设计,不再是将传感器的原始输入或经过特征提取后的特征向量作为输入,而是保留了上游的感知模块(见图1),将感知算法输出的目标结果作为状态量的一部分,同时接入座舱内的司机、乘客状态信息,进行综合的针对性决策。
[0048]
决策模块中深度强化学习决策算法采用的框架包括但不限于dqn、ddpg、a3c、ppo、sac中的一种强化学习框架。
[0049]
行驶行为控制模块,能根据行驶行为决策指令a
env
对车辆的行驶状态进行适应性调整。
[0050]
舱内控制模块,能根据座舱控制指令a
cab
对舱内执行设备进行适应性调整。
[0051]
规划模块,用于处理行驶行为决策指令a
env
,根据a
env
进行轨迹点规划,再输出至行驶行为控制模块控制车辆的行驶状态。
[0052]
定位模块,用于将车辆的定位信息分别输出至决策模块、规划模块和行驶行为控制模块。
[0053]
当强化学习决策算法模型在仿真环境训练时,使用相同的混合感知状态输入[s
env
,s
cab
],即把经过感知模块处理后的目标数据作为输入,避免了由仿真和现实中原始环境的差异带来的偏差。奖励函数的设计:r=a*安全性+b*效率性+c*舒适性+d*乘客体验,其中a、b、c、d分别代表各项评估指标的权重。安全性由碰撞惩罚计算、效率性由车速衡量、舒适性由换道惩罚得出、乘客体验通过座舱内的感知系统给出。
[0054]
每当决策系统根据当前混合感知状态s=[s
env
,s
cab
],采取决策动作a=[a
env
,a
cab
],收获奖励r以及进入下一决策周期的混合感知状态s’时,即收集到一组经验[s,a,r,s’]。所有部署了本发明中的决策系统的智能车辆将自身经验定期上传存于云端经验池中进行共享。
[0055]
每个智能车辆可以定期将自己的强化学习决策算法模型上传至云服务器中,通过横向联邦学习的方式训练迭代模型,再下载到本地进行模型替换更新。对经验数据在不侵犯法律法规的情况下,进行最大限度地利用。
[0056]
下面通过一个实例来演示本发明决策系统中深度强化学习决策算法的使用过程及深度强化学习决策算法的训练过程。
[0057]
决策算法的使用过程:
[0058]
本发明中提出的决策算法框架通过特殊设计的状态量(混合感知状态s)输入来规避仿真训练到实际部署的鸿沟:即不再需求传感器原始信号作为算法的输入(因为仿真环境很难做到对现实场景的完全还原,导致仿真传感器输出的信号会和实际有很大的偏差,基于仿真中的传感器信号训练的ai算法模型就很难在实际中进行应用)。本发明中的决策
算法选择使用感知模块运算后的目标及结果作为输入。
[0059]
比如当汽车a行驶在高速路上时,参考图2,传感器可以感知到周围的车b、c、d、e,则决策算法输入的外界感知结果s
env
会是[b车相对位置,b车速度,b车加速度,b车朝向,c车相对位置,c车速度,c车加速度,c车朝向,d车相对位置,d车速度,d车加速度,d车朝向,e车相对位置,e车速度,e车加速度,e车朝向],假如此时检测到舱内驾驶员由于困意导致注意力级别不高,感觉寒冷且心情不佳,则此时座舱内的感知结果s
cab
=[驾驶员注意力级别,体感温度,心情指数],决策算法的输入会是s=[s
env
,s
cab
]。
[0060]
决策算法的网络模型可采用如图3所示的全连接网络结构,其中输入的节点个数与混合感知状态量[s
env
,s
cab
]的矩阵维度相关,如本例中是19个输入节点(为了附图具有较好的显示效果,图3只表示网络模型的作用原理,并未将19个输入节点全部画出来),分别对应[b车相对位置,b车速度,b车加速度,b车朝向,c车相对位置,c车速度,c车加速度,c车朝向,d车相对位置,d车速度,d车加速度,d车朝向,e车相对位置,e车速度,e车加速度,e车朝向,驾驶员注意力级别,体感温度,心情指数]。而输出的决策值v=[行驶决策v1,舱内决策(空调v2,灯光v3,音乐v4,车窗v5)],详情:
[0061][0062]
针对v1,由于在高速场景,所以不需要考虑假如转弯决策行为,如果在城市场景则还可加入转弯,掉头等决策。
[0063][0064]
针对v2,还可以加入功率增大、减小等选项。
[0065][0066]
针对v3,还可以加入其他颜色,以及氛围灯光模式。
[0067][0068]
针对v4,也可加入驾驶员预设的喜好音乐。
[0069][0070]
本例中输出的决策值v一共会有18个值,包含v1到v5的5类决策对象。最终在每一类决策对象中,根据贪婪策略只选择v值最大的决策作为最终的决策动作输出a=[a1,a2,a3,a4,a5]。假如根据本例中的混合感知状态输入:
[0071][0072][0073][0074][0075][0076]
根据输入的混合感知状态量,完整合理的决策动作输出值应该是a=[减速,空调升温,氛围灯切换成黄色,打开提神音乐,关闭窗户],下游的规划模块及行驶行为控制模块
根据减速决策指令执行相应的动作,舱内的执行器(音响、空调、灯、车窗等)也根据相应的决策指令进行控制。
[0077]
决策算法的训练过程:
[0078]
以上已经介绍了深度强化学习决策算法的使用过程,包括:将混合感知状态s输入到当前网络参数为w的神经网络n中,从而输出决策值v,即v=n(s,w),根据决策值v确定最终输出的决策动作a。
[0079]
基于以上算法的训练过程包括以下步骤:
[0080]
步骤1、初始化探索阈值e=0.8(可以自由调整),初始化神经网络n的网络参数w。
[0081]
步骤2、将当前车辆的混合感知状态s=[s
env
,s
cab
](可以来自于仿真环境或者实际行车过程中采集的数据)输入进神经网络n中,生成一个随机数e,
[0082]
假设e=0.9,则满足e≥e,采取的决策行为依照先前的贪婪策略,直接选择v值最大的决策动作a;
[0083]
若e<e,则随机生成决策动作a。
[0084]
步骤3、对此时处于混合感知状态s的车辆执行决策动作a,从而得到一个新的混合感知状态s’和奖励r,奖励函数的设计:r=a*安全性+b*效率性+c*舒适性+d*乘客体验,其中a、b、c、d分别代表各项评估指标的权重。安全性由碰撞惩罚计算(如发生碰撞则安全性=-100)、效率性由车速衡量(如效率性=当前车速)、舒适性由换道惩罚以及加速度变化得出(如舒适性=-10*换道行为次数-10*加速度变化)、乘客体验通过座舱内的感知系统给出(如乘客体验=乘客心情指数*5);通过新的混合感知状态s’和奖励r判断:
[0085]
若车辆发生碰撞,则得到终止标志f1ag=1;
[0086]
若车辆未发生碰撞,则f1ag=0。
[0087]
步骤4、将{s,a,s’,r,flag}这一组数据存入数据池中。
[0088]
步骤5、将s’赋值给s,车辆进入新的混合感知状态s’,同时将e*0.99999赋值给e(让探索阈值e逐步减少),再进入步骤6。
[0089]
步骤6、从数据池中采集n组样本数据{sn,an,sn′
,rn,flagn},对于每一组样本数据计算当前决策目标值v
target
:
[0090]
若flag=1,则v
target
=r;
[0091]
若flag=0,则v
target
=r+γmax n(s
′
,w),其中γmax n(s
′
,w)的含义是将新的混合感知状态s’输入到当前网络参数为w的神经网络n中,根据贪婪策略输出最大的决策值,并乘以固定折扣值γ,γ一般为接近1的小数,本例中的γ=0.999。
[0092]
步骤7、使用均方误差函数计算n个决策目标值v
target
的损失:
[0093]
步骤8、使用神经网络梯度反向传播来更新神经网络n的网络参数w,返回到步骤2,进行循环训练。
[0094]
以上仅是本发明的优选实施方式,本发明的保护范围并不仅仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围。应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,这些改进和润饰也应视为本发明的保护范围。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1