自动与人工混合驾驶场景下的智能车辆横向控制方法
1.本发明属于自动驾驶技术领域。
背景技术:
2.自动驾驶是当前交通领域最为热门的领域之一,带有多个匝道出口的多车道单向高速公路路段是自动驾驶的典型场景。在该场景中,自动驾驶与人工驾驶车辆之间存在着复杂的、动态的交互作用,因此,自动驾驶车辆要求根据自身、周边自动驾驶与人工驾驶车辆状态、道路结构以及自身出行终点等信息,确定自动驾驶车辆的控制策略,尤其是自动驾驶车辆的横向控制策略,由于人工驾驶车辆与自动驾驶车辆处于混行状态,车辆个体决策之间存在着较强的博弈耦合关系,以往单智能体强化学习类方法(例如q学习等)难以做出合理的决策,同时由于每个决策个体车辆的感知信息范围受限,无法获取全域环境信息,所以存在横向变道过程中存在安全性、舒适性差的问题。
技术实现要素:
3.本发明目的是为了解决现有自动驾驶车辆在人工驾驶车辆与自动驾驶车辆处于混行状态时,横向控制过程中存在安全性、舒适性差的问题,提出了自动与人工混合驾驶场景下的智能车辆横向控制方法。
4.本发明所述自动与人工混合驾驶场景下的智能车辆横向控制方法,包括:
5.步骤一、根据目标车辆所处环境中的车辆状态信息建立智能体拓扑图,所述车辆包括自动驾驶车辆和人工驾驶车辆;
6.步骤二、对所述智能体拓扑图中顶点的特征进行提取;获取智能体拓扑图中每个顶点的特征;
7.步骤三、将智能体拓扑图中每个顶点的特征输入至深度拓扑图卷积网络,获得智能体拓扑图每个顶点之间的交互作用,根据智能体拓扑图中每个顶点之间的交互作用获取每个顶点的表征特征;
8.步骤四、利用智能体拓扑图中每个顶点的表征特征,利用深度估值网络获取自动驾驶车辆所有横向动作的估值;
9.步骤五、按照95%的概率使目标车辆执行估值最大的动作,按照5%的概率使目标车辆执行其他横向动作。
10.进一步地,本发明中,步骤一之前还包括:获取目标车辆所处环境中的车辆状态的步骤,具体为:
11.使目标车辆与其所处环境中的所有自动驾驶车辆建立通信连接,获取自动驾驶车辆的状态,采用传感器采集距离自身y米范围内的人工驾驶车辆的状态,y为正数。
12.进一步地,本发明中,y为200。
13.进一步地,本发明中,步骤一中,智能体拓扑图表示为:
14.15.其中,分别表示拓扑图的顶点集合、边集合和邻接矩阵,拓扑图中的每个顶点表示一辆自动驾驶车或者一辆人工驾驶车,拓扑图中的边为任意两个顶点i,j之间存在的连接关系,表示两辆车辆之间存在信息共享,所述邻接矩阵根据车辆所处环境中的车辆状态信息建立。
16.进一步地,本发明中,步骤二中,智能体拓扑图中每个顶点的特征包括:车辆的速度、车辆的纵向位置、车辆所处的车道编号、车辆在当前时刻横向动作意愿和车辆是否为自动驾驶车辆;其中,车辆的纵向位置以目标车辆为参照点获取,车辆所处的车道编号采用独热码的方式编码,车辆在当前时刻横向动作包括:保持当前车道,向左变道和向右变道。
17.进一步地,本发明中,深度拓扑图卷积网络包括三个全连接层、三个激活函数relu层、一个拓扑图卷积层和一个拼接层。
18.进一步地,本发明中,步骤三中,将智能体拓扑图中每个顶点的特征依次经一个全连接层和激活函数relu层对顶点的特征增强后,再依次经过一个全连接层和激活函数relu层对顶点的特征再次增强后传输至拓扑图卷积层,所述拓扑图卷积层采用双层的gcn网络对再次增强后的顶点特征和拓扑图邻接矩阵进行空间特征信息聚合,获取车辆智能体间交互作用的表征向量,所述车辆智能体间交互作用的表征向量依次经过一个全连接层和激活函数relu层后经拼接层进行拼接,获取每个顶点的表征特征。
19.进一步地,本发明中,深度估值网络和深度拓扑图卷积网络均为采用深度q学习的方法训练后的网络。
20.进一步地,本发明中,深度估值网络和深度拓扑图卷积网络中的奖励函数为:
21.r=10
×ri-100rc+2
×rs-0.3
×rl
22.其中,ri为意图达成奖励、rc为碰撞惩罚、rs为平均速度奖励,r
l
为换车道惩罚,r为综合奖励。
23.本发明针对的是在带有多个出口匝道的多车道单向高速公路路段中,存在自动驾驶(完全由机器来进行车辆的横向和纵向控制)以及人工驾驶(由人类驾驶员进行车辆控制)两种车辆混行的交通状态下,自动驾驶车辆如何根据2种类型的智能体(具体指人工驾驶和自动驾驶两种类型的车辆)之间的交互作用、相互影响,做出智能化的车辆横向控制决策,从而最大限度保障整体交通安全性,缩短整体出行时间和保障出行舒适性。
附图说明
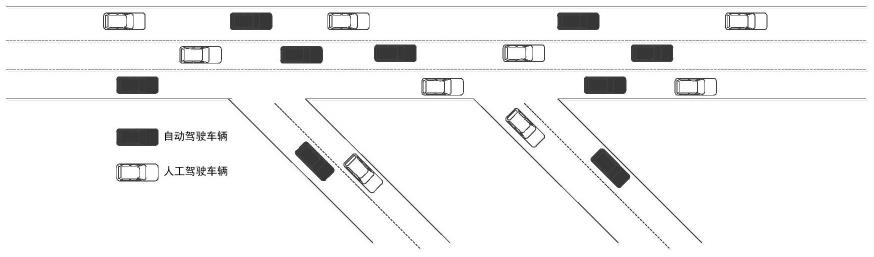
24.图1是自动驾驶与人工驾驶混行交通场景示意图;
25.图2是本发明所述自动与人工混合驾驶场景下的智能车辆横向控制方法流程图;
26.图3是智能体拓扑图中每个顶点的特征输入至深度拓扑图卷积网络对智能体拓扑图每个顶点之间的交互作用建模示意图。
具体实施方式
27.下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整地描述,显然,所描述的实施例仅仅是本发明一部分实施例,而不是全部的实施例。基于本发明中的实施例,本领域普通技术人员在没有作出创造性劳动的前提下所获得的所有其他实施例,都属于本发明保护的范围。
28.需要说明的是,在不冲突的情况下,本发明中的实施例及实施例中的特征可以相互组合。
29.具体实施方式一:下面结合图1至图3说明本实施方式,本实施方式所述自动与人工混合驾驶场景下的智能车辆横向控制方法,包括:
30.步骤一、根据目标车辆所处环境中的车辆状态信息建立智能体拓扑图,所述车辆包括自动驾驶车辆和人工驾驶车辆;
31.步骤二、对所述智能体拓扑图中顶点的特征进行提取;获取智能体拓扑图中每个顶点的特征;
32.步骤三、将智能体拓扑图中每个顶点的特征输入至深度拓扑图卷积网络,获得智能体拓扑图每个顶点之间的交互作用,根据智能体拓扑图中每个顶点之间的交互作用获取每个顶点的表征特征;
33.步骤四、利用智能体拓扑图中每个顶点的表征特征,利用深度估值网络获取自动驾驶车辆所有横向动作的估值;
34.步骤五、按照95%的概率使目标车辆执行估值最大的动作,按照5%的概率使目标车辆执行其他横向动作。
35.进一步地,本发明中,步骤一之前还包括:获取目标车辆所处环境中的车辆状态的步骤,具体为:
36.使目标车辆与其所处环境中的所有自动驾驶车辆建立通信连接,获取自动驾驶车辆的状态,采用传感器采集距离自身y米范围内的人工驾驶车辆的状态,y为正整数。
37.进一步地,本发明中,y为200。
38.进一步地,本发明中,步骤一中,智能体拓扑图表示为:
[0039][0040]
其中,分别表示拓扑图的顶点集合、边集合和邻接矩阵,拓扑图中的每个顶点表示代表一辆自动驾驶车或者一辆人工驾驶车,拓扑图中的边为任意两个顶点i,j之间存在的连接关系,表示两辆车辆之间存在信息共享,所述邻接矩阵根据车辆所处环境中的车辆状态信息建立。
[0041]
进一步地,本发明中,步骤二中,智能体拓扑图中每个顶点的特征包括:车辆的速度、车辆的纵向位置、车辆所处的车道编号、车辆在当前时刻横向动作意愿和车辆是否为自动驾驶车辆;其中,车辆的纵向位置以目标车辆为参照点获取,车辆所处的车道编号采用独热码的方式编码,车辆在当前时刻横向动作包括:保持当前车道,向左变道和向右变道。
[0042]
进一步地,本发明中,深度拓扑图卷积网络包括三个全连接层、三个激活函数relu层、一个拓扑图卷积层和一个拼接层。
[0043]
进一步地,本发明中,步骤三中,将智能体拓扑图中每个顶点的特征依次经一个全连接层和激活函数relu层对顶点的特征增强后,再依次经过一个全连接层和激活函数relu层对顶点的特征再次增强后传输至拓扑图卷积层,所述拓扑图卷积层采用双层的gcn网络对再次增强后的顶点特征和拓扑图邻接矩阵进行空间特征信息聚合,获取车辆智能体间交互作用的表征向量,所述车辆智能体间交互作用的表征向量依次经过一个全连接层和激活函数relu层后经拼接层进行拼接,获取每个顶点的表征特征。
[0044]
进一步地,本发明中,深度估值网络和深度拓扑图卷积网络均为采用深度q学习的方法训练后的网络。
[0045]
进一步地,本发明中,深度估值网络和深度拓扑图卷积网络中的奖励函数为:
[0046]
r=10
×ri-i00rc+2
×rs-0.3
×rl
[0047]
其中,ri为意图达成奖励、rc为碰撞惩罚、rs为平均速度奖励,r
l
为换车道惩罚,r为综合奖励。
[0048]
本发明的具体过程为:
[0049]
(1)构建智能体拓扑图;根据任意考察时刻t,驾驶场景中人工驾驶与自动驾驶混行状态,构建智能体拓扑图,表示为其中分别表示拓扑图的顶点集合、边集合和邻接矩阵。拓扑图的每个顶点均代表一辆自动驾驶车或者一辆人工驾驶车,如图2中,黑色顶点代表自动驾驶车辆,灰色顶点代表人工驾驶车辆。拓扑图中任意两个顶点i,j之间存在连接关系,则表明它们所代表的车辆之间存在信息的共享。本方法中假设:1)所有车辆都和自身之间有信息共享,也就是拓扑图中所有顶点存在自连接;2)所有自动驾驶车和自动驾驶车之间存在信息共享,也就是拓扑图中黑色和黑色顶点之间必定存在连接;3)所有自动驾驶车和其传感器感知范围内(以自动驾驶车辆所在位置为中心,半径为200米的范围)的车辆建立通信连接,存在信息共享。根据这些假设,可以构建任意考察时刻驾驶场景中的拓扑图的邻接矩阵
[0050]
(2)定义拓扑图中任意顶点的特征;任意考察时刻t的拓扑图中任意顶点的特征表示为[vi,xi,li,ii,fi],其中,vi表示顶点i所代表车辆的速度;xi表示顶点i所代表车辆所处的纵向(行车方向)的位置;li表示顶点i所代表车辆所处的车道编号,采用独热码的方式进行编码;ii表示顶点i所代表车辆在当前时刻的意愿,包括:保持当前车道,向左变道和向右变道,采用独热码方式进行编码;fi表示顶点i所代表车辆是否为自动驾驶车辆,如果是为1,否则为0。
[0051]
(3)采用深度拓扑图卷积网络对车辆智能体之间的交互作用进行建模;通过深度拓扑图卷积网络,建模当前时刻拓扑图内各顶点所代表车辆智能体之间的交互作用,最终通过图卷积操作,生成每个顶点所代表车辆的决策模型输入状态。具体流程如图3所示。
[0052]
将第(2)步中所构建的拓扑图特征,首先经过一个全连接层,将每个顶点的特征维度放大,起到特征表达增强的作用,然后将放大维度的特征通过激活函数relu;把输出的结果,通过同样的操作步骤,再经过一个全连接层和一个激活函数relu层,从而得到特征增强后的拓扑图特征。进一步,将增强后的拓扑图特征和拓扑图邻接矩阵共同输入到图卷积模块,采用双层的gcn网络进行空间特征信息聚合,将聚合结果再输入给一个全连接层和一个激活函数relu层,得到对车辆智能体间交互作用进行建模后的表征向量,再将其与拓扑图特征经过第一个全连接层和激活函数relu层所获得的增强特征进行拼接操作,最终作为每个顶点的表征特征。
[0053]
(4)采用深度估值网络计算特定输入状态下,每个顶点(如果其为自动驾驶车辆)下的横向动作估值。深度估值网络采用双层全连接神经网络,以第(3)步中每个顶点的表征特征为输入,分别计算每个可能横向控制决策(包括保持车道、向左换道和向右换道)下的未来收益估值。
[0054]
(5)根据估值结果,选择横向控制决策执行。在第(4)步估值的基础上,以95%的概
率执行估值最大的动作,以5%的概率随机执行任意可行动作。
[0055]
深度拓扑图卷积网络与深度估值网络的训练方法:
[0056]
第(3)、(4)步中的深度神经网络需要经过训练才能够使用。训练的目的是确定(3)、(4)步中的深度神经网络的具体权重值。整体上,采用深度q学习的方法,将这两个网络拼接在一起进行整体训练,具体步骤为:
[0057]
①
构建深度网络训练样本采集的仿真环境。仿真环境由微观交通流仿真软件sumo负责搭建,模拟人工驾驶车辆和自动驾驶车辆的混合出行状态。首先,在sumo中构建如图1所示的道路场景,仿真开始后,人工车辆按照每1秒1辆车的频率产生,自动驾驶车辆按照每2秒1辆车的频率产生,车辆均从道路最左侧产生,由左向右行驶。仿真环境负责产生自动驾驶车辆感知的状态和接收自动驾驶以及人工驾驶决策行为,并对应执行。
[0058]
②
确定人工驾驶车辆的控制策略和自动驾驶车辆的控制策略。对于人工驾驶车辆和自动驾驶车辆的控制策略均包括横向控制策略和纵向控制策略。横向控制策略负责在车道之间进行变换,纵向控制策略负责在行进方向上车辆的加减速。对于人工驾驶车辆,其横向控制和纵向控制均采用sumo内置的车辆控制逻辑,即mobil和idm模型;对于自动驾驶车辆,其纵向控制采用sumo内置的idm模型,其横向控制策略采用本发明提出的方法。
[0059]
③
自动驾驶车辆的横向控制动作集合。自动驾驶车辆的横向控制动作包括3种,分别是保持当前车道、向左变道和向右变道。
[0060]
④
自动驾驶车辆的横向控制的奖励函数定义。自动驾驶车辆控制动作的奖励函数,用于衡量执行一个特定横向控制动作,所能获得的即时收益。奖励函数包括4个组成部分:意图达成奖励ri、碰撞惩罚rc、平均速度奖励rs和换车道惩罚r
l
。综合奖励r的具体计算公式为:r=10
×ri-100rc+2
×rs-0.3
×rl
。
[0061]
⑤
训练深度拓扑图卷积网络与深度估值网络。依据自动驾驶车辆状态、动作和奖励函数的定义,采用深度q学习算法,对深度拓扑图卷积网络与深度估值网络所构成的串行整体网络进行训练。
[0062]
虽然在本文中参照了特定的实施方式来描述本发明,但是应该理解的是,这些实施例仅仅是本发明的原理和应用的示例。因此应该理解的是,可以对示例性的实施例进行许多修改,并且可以设计出其他的布置,只要不偏离所附权利要求所限定的本发明的精神和范围。应该理解的是,可以通过不同于原始权利要求所描述的方式来结合不同的从属权利要求和本文中所述的特征。还可以理解的是,结合单独实施例所描述的特征可以使用在其他所述实施例中。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1