一种自动驾驶车辆换道轨迹规划方法及系统
1.本发明属于车辆控制决策技术领域,涉及一种自动驾驶车辆换道轨迹规划方法及系统。
背景技术:
2.近年来,自动驾驶车辆在改善交通安全、提高能源效率和减轻交通拥堵方面具有巨大潜力,备受学术界和工业界的关注。换道是车辆驾驶过程中的一项基本任务,对车辆的安全行驶起着非常重要的作用,目前的换道轨迹规划方法存在复杂性高,数据依赖性强等问题,随着车辆智能化水平的提高,兼顾安全与交通效能的车辆换道轨迹规划逐渐成为自动驾驶车辆研究的热点之一。
技术实现要素:
3.为解决现有技术中存在的问题,本发明的目的在于提供一种自动驾驶车辆换道轨迹规划方法及系统,在考虑安全性、高效性、舒适性和燃油经济性的情况下,完成对自动驾驶车辆的换道轨迹规划。
4.为了达到上述目的,本发明提供如下技术方案:
5.一种自动驾驶车辆换道轨迹规划方法,包括如下过程:
6.获取车辆信息:所述车辆信息包括:换道车辆的速度、加速度和位置信息,以及周围车辆的速度、加速度和位置信息;
7.根据所述车辆信息、换道车辆与周围车辆的博弈换道决策模型、考虑安全性和时效性的博弈收益函数并利用博弈收益矩阵求解当前时刻换道车辆的最优换道决策;
8.根据所述最优换道决策,以降低燃油消耗和提高驾驶效率为目标,并利用基于深度强化学习的自动驾驶车辆换道轨迹规划模型,得到整个换道过程最优的序贯加速度决策信息;
9.利用车辆横纵向离散化运动学模型,通过所述最优的序贯加速度决策信息计算出换道过程中每个时间点换道车辆的车辆状态,根据换道车辆的车辆状态得出换道车辆的换道轨迹。
10.优选的,所述车辆横纵向离散化运动学模型的建立过程包括:
11.在xoy平面直角坐标系中,以x轴方向为车辆纵向行驶的方向,以y轴方向为车辆的横向行驶方向,解耦车辆运动学模型,并以δt为采样时间进行离散化,得到所述纵横向分离的离散化车辆运动学模型及约束条件如下:
12.v
xt
=v
x(t-1)
+a
xt
δt
13.v
yt
=v
y(t-1)
+a
yt
δt
14.[0015][0016]
0《v
xt
《v
x,max
,0《v
yt
《v
y,max
[0017][0018]
其中,v
xt
和v
yt
分别表示t时刻车辆的纵向速度和横向速度;v
x(t-1)
和v
y(t-1)
分别表示t-1时刻车辆的纵向速度和横向速度;t-1时刻为t时刻上一时刻;x
t
和y
t
分别表示t时刻车辆的纵坐标和横坐标;x
(t-1)
和y
(t-1)
分别表示t-1时刻车辆的纵坐标和横坐标;纵向加速度a
xt
和横向加速度a
yt
由每个时间步δt中车辆与算法交互得到,v
x,max
和v
y,max
分别是纵向速度的最大值和横向速度的最大值,x
max
和y
max
分别是纵向位置的最大值和横向位置的最大值,tf为换道的完成时间;
[0019]
通过运动学模型得到下一时刻车辆的位置和速度,直到车辆到达换道目标位置或驶离车道时终止状态结束。
[0020]
优选的,换道车辆与周围车辆的博弈换道决策模型如下:
[0021]
博弈的参与者为换道车辆m、目标车道跟随车辆fd和目标车道前车ld,换道车辆m的策略集为φ1={m1,m2},其中m1表示换道,m2表示不换道;目标车道跟随车辆fd和目标车道前车ld的策略集为φ2={d
i1
,d
i2
},i={fd,ld},其中d
i1
表示车辆i允许换道,d
i2
表示车辆i拒绝换道。
[0022]
优选的,考虑安全性和时效性的博弈收益函数如下:
[0023]rm
,rd=α1*r
safe
+α2*r
time
.
[0024]
其中,r
safe
和r
time
分别表示决策车辆考虑安全性和时效性所获得的收益;α1和α2均为权重系数,α1+α2=1,代表不同驾驶因素的重要程度;
[0025][0026][0027]
p
min
=v
mx-v
ldx
)tf[0028][0029][0030]
其中,v
mx
和v
mx
分别表示换道车辆的纵向速度和目标车道前车的纵向速度,p
head
为当前时刻两车的车头间距,a
mx
和a
ldx
为换道车辆和目标车道前车的纵向加速度;p
min
为当前状态下所需的最小安全距离;t0表示保持原状态下达到目的地所需的时间,x
target
为换道目标点的纵向坐标;tf表示换道的完成时间,由轨迹规划部分得出。
[0031]
优选的,所述博弈收益矩阵如表1:
[0032]
表1
[0033][0034]
其中,rm表示当前策略下换道车辆可得到的博弈收益,rd表示当前策略下目标车道车辆可得到的博弈收益;
[0035]
换道车辆与目标车道前车和跟随车分别进行博弈,得到四种博弈结果分别为:换道车辆进行换道,目标车道车辆允许换道;换道车辆进行换道,目标车道车辆拒绝换道;换道车辆不换道,目标车道车辆允许换道;换道车辆不换道,目标车道车辆拒绝换道;只有换道车辆选择换道策略,且目标车道前车和跟随车都做出允许换道的策略时,执行换道。
[0036]
优选的,求解当前时刻换道车辆的最优换道决策的过程包括:
[0037]
如果博弈矩阵中存在某一纯策略(d
in
,mn),i={fd,ld},n=1,2使得下式成立,则称(d
in
,mn)为当前博弈的纯策略纳什均衡,该策略为当前环境下车辆做出的最优换道决策,根据此决策确定所需求解的换道轨迹规划子问题,所述换道轨迹规划子问题包括:左换道、右换道或车道保持;
[0038][0039]
式中,d
in
,i={fd,ld},n=1,2,表示目标车道车辆i允许换道或者拒绝换道,mn,n=1,2表示换道车辆m换道或者不换道,φ1表示换道车辆m的策略集,m表示换道车辆策略集φ1中的任意策略,φ2表示目标车道跟随车辆fd和目标车道前车ld的策略集,di表示目标车道车辆i的策略集φ2中的任意策略。
[0040]
优选的,所述基于深度强化学习的自动驾驶车辆换道轨迹规划模型包括状态空间、动作空间以及奖励函数;
[0041]
所述状态空间中包含自动驾驶车辆换道所需要的全部信息,每个时刻均获取当前换道车辆的纵坐标x
t
、横坐标y
t
、纵向速度v
xt
和横向速度v
yt
;每一时刻的状态用一个四元组表示,s
t
=[x
t
,v
xt
;y
t
,v
yt
];
[0042]
所述动作空间定义自动驾驶车辆所采取的动作,结合车辆运动学纵横向解耦状态方程,用纵横向加速度作为自动驾驶车辆的动作,纵向加速度a
xt
的取值范围设定为[-2m/s2,2m/s2];横向加速度a
yt
的取值范围为[-0.2m/s2,0.2m/s2];每一时刻的动作用一个二元组表示,a
t
=[a
xt
;a
yt
]。
[0043]
所述奖励函数r
t
由沿目标车道中心线奖励ry、目标速度奖励rv、油耗奖励re和结束任务奖励rd四部分组成,具体如下:
[0044]rt
=w
yry
+w
vrv
+were+wdrd.
[0045]ry
=-|y
t-y
target
|
[0046]rv
=-a
xt
(v
xt-v
target
)
[0047]
re=ln(moe)
[0048][0049][0050]
其中,moe为瞬时燃油消耗,包括线性、二次和三次速度和加速度项的组合,l
k,q
和m
k,q
表示在速度的k次幂和加速度的q次幂下moe的模型系数,此项用瞬时燃油消耗作为惩罚项,使车辆学习到节能的换道方式;wy、wv、we和wd分别为不同收益的权重系数,表示其重要程度,c1和c2为常数,y
target
表示目标车道中心线的横向坐标,v
target
表示车辆到达换道终点时的目标速度,e为自然对数的底数。
[0051]
优选的,所述基于深度强化学习的自动驾驶车辆换道轨迹规划模型的训练过程包括:
[0052]
将变道车辆初始状态作为双延迟深度确定性策略梯度学习算法的输入,换道目标对应状态作为变道车辆的结束状态,进行双延迟深度确定性策略梯度学习算法训练,训练过程中先收集添加随机噪声的决策行为以及对应收益,并存放到经验回放池中,达到预设数量后进行批量选取进行训练,直到收益逐步稳定,双延迟深度确定性策略梯度学习算法收敛;
[0053]
训练过程中双延迟深度确定性策略梯度学习算法的评价网络和策略网络的损失计算如下:
[0054][0055][0056]
优选的,根据最优换道决策,以降低燃油消耗和提高驾驶效率为目标,并利用基于深度强化学习的自动驾驶车辆换道轨迹规划模型,得到整个换道过程最优的序贯加速度决策信息时,根据收敛后双延迟深度确定性策略梯度学习算法,对双延迟深度确定性策略梯度学习算法输入当前车辆的初始状态和换道目标状态,求解基于深度强化学习的自动驾驶车辆换道轨迹规划模型,得到整个换道过程最优的序贯加速度决策信息。
[0057]
本发明还提供了一种自动驾驶车辆换道轨迹规划系统,包括:
[0058]
获取环境信息模块:用于获取车辆信息,所述车辆信息包括:换道车辆的速度、加速度和位置信息,以及周围车辆的速度、加速度和位置信息;
[0059]
换道决策模块:用于根据所述车辆信息、换道车辆与周围车辆的博弈换道决策模型、考虑安全性和时效性的博弈收益函数并利用博弈收益矩阵求解当前时刻换道车辆的最优换道决策;
[0060]
换道轨迹规划模块:用于根据所述最优换道决策,以降低燃油消耗和提高驾驶效率为目标,并利用基于深度强化学习的自动驾驶车辆换道轨迹规划模型,得到整个换道过程最优的序贯加速度决策信息;
[0061]
仿真模块:用于利用车辆横纵向离散化运动学模型,通过所述最优的序贯加速度决策信息计算出换道过程中每个时间点换道车辆的车辆状态,根据换道车辆的车辆状态得出换道车辆的换道轨迹。
[0062]
与现有技术相比,本发明具有如下有益效果:
[0063]
本发明使用能够处理连续控制量的双延迟深度确定性策略梯度算法(twin delayed deep deterministic policy gradient,td3),能够实现对车辆速度,加速度的控制,解决了使用dqn算法将动作空间离散化造成的丢失精度控制问题,以及使用ddpg算法会出现的收益函数估值过高的问题,能够较为准确的对车辆控制行为进行评估,同时td3算法的延迟更新策略,使其平均训练速度与ddpg相比提升了10.5%。通过车辆与环境进行交互,存储得到的历史经验数据对网络进行训练,不需要像机器学习一样通过大量的真实换道数据来训练,节省了对数据进行清洗、筛选等预处理操作,提高了灵活性。在奖励函数中考虑了瞬时燃油消耗量和目标速度控制,减低了换道过程中的燃油消耗量,最终得到安全,舒适,绿色的换道轨迹。
附图说明
[0064]
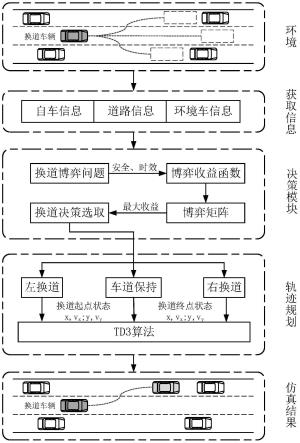
图1为本发明自动驾驶车辆换道轨迹规划方法的总体框架图;
[0065]
图2为本发明的td3网络结构示意图;
[0066]
图3(a)为本发明实施例1左换道轨迹示意图,图3(b)为本发明实施例1中训练前后每回合油耗对比图,图3(c)为本发明实施例1中速度控制曲线;
[0067]
图4(a)为本发明实施例2右换道轨迹示意图,图4(b)为本发明实施例2中训练前后每回合油耗对比图,图4(c)为本发明实施例2中速度控制曲线;
[0068]
图5(a)为本发明的所用td3算法与其他(ddpg)算法的左换道训练时间对比实验图,图5(b)为本发明的所用td3算法与其他(ddpg)算法的右换道训练时间对比实验图。
具体实施方式
[0069]
下面将结合附图对本发明进行详细的描述。
[0070]
参照图1,本发明的自动驾驶车辆换道轨迹规划总体框架图,包括获取环境信息模块,换道决策模块,换道轨迹规划模块以及仿真模块。环境感知层中自动驾驶车辆搭载了车载摄像头、激光雷达、毫米波雷达等传感器实现对环境信息的感知,并且能够以lte-v2x的通信方式在低延时、无丢包的情况下获取周围车辆的速度、加速度、位置信息;行为决策层车辆利用纯策略博弈换道决策模型,在保障安全的条件下,确定车辆行驶行为;轨迹规划层利用基于深度强化学习的换道轨迹优化算法,构建考虑换道油耗和舒适性的自动驾驶车辆纵横向换道轨迹。
[0071]
主要包括以下步骤:
[0072]
步骤1,自动驾驶车辆行驶过程中,利用车载感知、通信设备在低延时、无丢包的情况下获取换道车辆和周围车辆的速度、加速度、位置信息。
[0073]
步骤2,解耦自动驾驶车辆的横纵向运动学约束,建立车辆横纵向离散化运动学模型。
[0074]
步骤3,根据步骤1获取的车辆信息,建立换道车辆与周围车辆的博弈换道决策模
型,构建考虑安全性和时效性的博弈收益函数,并利用博弈收益矩阵求解当前时刻换道车辆的最优换道决策。
[0075]
步骤4,根据步骤3得到的最优换道决策,以降低燃油消耗和提高驾驶效率为目标,建立了基于深度强化学习的自动驾驶车辆换道轨迹规划模块,得到整个换道过程最优的序贯加速度决策信息。
[0076]
步骤5,利用步骤2车辆横纵向离散化运动学模型,通过步骤4得到的加速度决策信息计算出换道过程中每个时间点的车辆状态,车辆状态包括车辆速度、横向位置、纵向位置,最终得出车辆的换道轨迹。
[0077]
实施例1:如图3(c)所示,本实施例中,仿真车道场景设置为:换道车辆的初始位置在右车道中心线起点(1.75,0)处,初始速度在12m/s(43.2km/h)~20m/s(72km/h)中随机初始化,周围车辆的行驶速度为16m/s(57.6km/h),换道车辆与原始车道前车的车头间距为50m,与目标车道前后车的车头间距均为60m,目标位置为左车道中心线(-1.75,100)处,博弈收益中的权重系数α1,α2分别取0.6和0.4。
[0078]
实施例2:如图4(c)所示,本实施例中,仿真车道场景设置为:换道车辆的初始位置在左车道中心线起点(-1.75m,0m)处,初始速度为15m/s(54km/h)~25m/s(90km/h)中随机初始化,周围车辆的行驶速度为20m/s(72km/h),换道车辆与原始车道前车的车头间距为50m,与目标车道前后车的车头间距均为60m,目标位置为右车道中心线(1.75,120)处,博弈收益中的权重系数α1,α2分别取0.6和0.4。
[0079]
步骤2具体包括如下步骤:
[0080]
步骤2.1,x轴方向为车辆纵向行驶的方向,y轴方向为车辆的横向行驶方向,解耦车辆运动学模型,并以δt为采样时间进行离散化,得到纵横向分离的离散化车辆运动学模型约束条件如下:
[0081]vxt
=v
x(t-1)
+a
xt
δt
ꢀꢀꢀ
(1)
[0082]vyt
=v
y(t-1)
+a
yt
δt
ꢀꢀꢀ
(2)
[0083][0084][0085]
0《v
xt
《v
x,max
,0《v
yt
《v
y,max
ꢀꢀꢀ
(5)
[0086][0087]
其中v
xt
,v
yt
分别表示t时刻车辆的纵向速度和横向速度,x
t
和y
t
分别表示t时刻车辆的纵、横坐标。纵、横向加速度a
xt
,a
yt
则由每个时间步δt中车辆与算法交互得到,v
x,max
和v
y,max
分别是纵横向速度的最大值,x
max
和y
max
分别是纵横向位置的最大值,tf为换道的完成时间。从而通过运动学模型得到下一时刻车辆的位置和速度,直到车辆到达换道目标位置或驶离车道时终止状态结束。
[0088]
步骤3具体包括如下步骤:
[0089]
步骤3.1,博弈换道决策模型建立,博弈的参与者为换道车辆m和目标车道跟随车辆fd和目标车道前车ld,换道车辆m的策略集为φ1={m1,m2},为两种纯策略,其中m1表示换道,m2表示不换道;目标车道车辆fd,ld的策略集为φ2={d
i1
,d
i2
},i={fd,ld},其中d
i1
表示
车辆i允许换道,d
i2
表示车辆i拒绝换道。
[0090]
步骤3.2,博弈换道决策收益函数建立,以确保换道的安全性和提高换道的效率为目的,建立体现安全和驾驶效率的收益函数,换道车辆和目标车道车辆的收益函数定义如下:
[0091]rm
,rd=α1*r
safe
+α2*r
time
.
ꢀꢀꢀ
(7)
[0092]
其中,r
safe
,r
time
表示决策车辆考虑安全性和时效性所获得的收益,其计算公式如(8)~(12);α1,α2为权重系数,α1+α2=1,代表不同驾驶因素的重要程度。
[0093][0094][0095][0096][0097][0098]
其中v
mx
和v
mx
分别表示换道车辆和目标车道前车的纵向速度。p
head
为当前时刻两车的车头间距,a
mx
和换道车辆和目标车道前车的纵向加速度。p
min
为当前状态下所需的最小安全距离(以换道车辆m和目标车道前车ld为例),当两车匀速运动时,可写成公式(10);t0表示保持原状态下达到目的地所需的时间,x
target
为换道目标点的纵向坐标;tf表示换道的完成时间,可由轨迹规划部分得出。
[0099]
步骤3.3,根据步骤3.2的博弈收益计算公式得到每种换道策略的博弈收益,列出博弈收益矩阵,博弈收益矩阵中收益最大的策略即为当前的博弈换道决策。博弈收益矩阵如下:
[0100]
表1
[0101][0102][0103]
表1中,换道车辆与目标车道前车和跟随车分别进行博弈,得到四种博弈结果为:换道车进行换道,目标车道车辆允许换道;换道车辆进行换道,目标车道车辆拒绝换道;换道车辆不换道,目标车道车辆允许换道;换道车辆不换道,目标车道车辆拒绝换道。只有换道车辆选择“换道”策略,且目标车道前车和跟随车都做出“允许换道”的策略时,才能成功执行换道。
[0104]
计算出每种策略下换道车和目标车道车辆考虑安全性和时效性的收益值,得到博弈收益矩阵,如果博弈矩阵中存在某一纯策略(d
in
,mn),i={fd,ld},n=1,2使得下式(13)成
立,则称(d
in
,mn)为当前博弈的纯策略纳什均衡。即为当前环境下车辆做出的最优换道决策,根据此决策确定所需求解的换道轨迹规划子问题,如左换道、右换道、车道保持(不换道)。
[0105][0106]
步骤4具体包括如下步骤:
[0107]
步骤4.1,根据步骤3得到的换道决策,确定换道车辆的初始状态和结束状态,包括车辆的速度、横纵位置坐标。
[0108]
步骤4.2,建立基于深度强化学习的智能网联车辆换道轨迹规划模型,包括状态空间,动作空间以及奖励函数的设计。
[0109]
a.状态空间中包含自动驾驶车辆换道所需要的全部信息,每个时刻都需要获取当前换道车辆的纵坐标x
t
,横坐标y
t
,纵向速度v
xt
,横向速度v
yt
。每一时刻的状态用一个四元组表示,s
t
=[x
t
,v
xt
;y
t
,v
yt
]。
[0110]
b.动作空间主要定义自动驾驶车辆所采取的动作,结合车辆运动学纵横向解耦状态方程(1-4),用纵横向加速度作为自动驾驶车辆的动作,考虑驾驶的舒适性,纵向加速度a
xt
的取值范围设定为[-2m/s2,2m/s2];考虑变道车的横向安全约束和横向舒适性,横向加速度a
yt
的取值范围为[-0.2m/s2,0.2m/s2]。每一时刻的动作用一个二元组表示,a
t
=[a
xt
;a
yt
]。
[0111]
c.奖励函数设计,期望换道车在换道过程中尽量沿车道中心线行驶,最终能够与目标车道前车以相同速度保持安全车距;且考虑换道过程中的瞬时油耗,达到节能驾驶的目的。奖励r
t
由沿目标车道中心线奖励ry,目标速度奖励rv,油耗奖励re,和结束任务奖励rd四部分组成。
[0112]rt
=w
yry
+w
vrv
+were+wdrd.
ꢀꢀꢀ
(14)
[0113]ry
=-|y
t-y
target
|
ꢀꢀꢀ
(15)
[0114]rv
=-a
xt
(v
xt-v
target
)
ꢀꢀꢀ
(16)
[0115]
re=ln(moe)
ꢀꢀꢀ
(17)
[0116][0117][0118]
其中,moe为瞬时燃油消耗,包括线性、二次和三次速度和加速度项的组合,l
k,q
和m
k,q
表示在速度的k次幂和加速度的q次幂下moe的模型系数,此项用瞬时燃油消耗作为惩罚项,使车辆学习到节能的换道方式;wy、wv、we和wd分别为不同收益的权重系数,表示其重要程度,c1和c2为常数,y
target
表示目标车道中心线的横向坐标,v
target
表示车辆到达换道终点时的目标速度,e为自然对数的底数。
[0119]
步骤4.3,将变道车辆初始状态作为双延迟深度确定性策略梯度学习算法(td3算
法,如图2所示)的输入,换道目标对应状态作为变道车辆的结束状态,进行td3算法训练,训练过程中先收集部分添加随机噪声的决策行为以及对应收益,并存放到经验回放池中,达到一定数量后进行批量选取进行训练,直到收益逐步稳定,即车辆能够学到对应的换道序列决策。训练过程中td3算法的评价网络和策略网络的损失计算如下:
[0120][0121][0122]
步骤4.4,根据步骤4.3得到的收敛后td3算法,对td3算法输入当前车辆的初始状态和换道目标状态,求解步骤4.2建立的换道轨迹规划模型,得到整个换道过程最优的序贯加速度决策信息;
[0123]
步骤5具体包括如下步骤:
[0124]
利用车辆横纵向离散化运动学模型,通过所述最优的序贯加速度决策信息计算出得到最优的换道轨迹,包括换道过程中车辆的速度轨迹和车辆纵横向位置轨迹。
[0125]
自动驾驶车辆进行左换道生成的换道轨迹如图3(a)所示,训练前后油耗对比图以及换道过程中的速度变化如图3(b)和图3(c)所示。车辆进行右换道生成的换道轨迹如图4(a)所示,训练前后油耗对比图以及换道过程中的速度变化如图4(b)和图4(c)所示。
[0126]
从左换道、右换道的实验训练过程可以得出,车辆智能体在前150个回合中处于试错阶段,此时车辆不知道如何进行换道,总是由于异常结束而导致回合提前结束。大概从150回合后,收集到足够的历史数据后,开始逐步学习提升,每回合所得的累积收益开始增大,说明车辆智能体学习到的策略在不断变好,由刚开始的无法完成换道任务到能够逐步完成换道,并不断优化(为了便于看出智能体学习到的策略在优化,使用滑动平均曲线将收益进行平滑,收益曲线波动是由于不同初始速度完成换道所得到的收益不同。)最终逐渐稳定在一个范围内,表明车辆的策略的优化过程,此时车辆智能体能够到达设定的换道终点,且换道车辆的速度与环境车的速度相等,能够安全完成换道任务。
[0127]
在换道过程中考虑了油耗问题,以油耗的大小作为对智能体的惩罚,油耗越大,惩罚越大,希望车辆智能体能够以节能的方式完成换道任务。车辆在左、右换道任务中训练前后完成换道任务的平均油耗对比如图3(b),图4(b)所示:
[0128]
由图3(b),图4(b)可得,未经过td3算法学习前,左换道过程中每步的平均油耗为0.030l/s,右换道过程中每步的平均油耗为0.032l/s,经过算法提升后的左换道过程中的单步平均油耗为0.011l/s,右换道过程中的单步平均油耗为0.018l/s,左、右换道过程中的平均油耗分别减少了63%和44%,达到了节能驾驶的目的。
[0129]
本发明所用的td3算法与ddpg算法进行对比,在左换道和右换道实验中每回合所用的训练时间对比情况如图5(a)和图(b)所示:
[0130]
从图5(a)和图(b)可得,使用td3算法在左换道实验和右换道实验中所用的训练时间均少于ddpg,在左换道实验中,td3总的训练速度和每回合的平均训练速度较ddpg提升了12%左右。在右换道实验中,td3总的训练速度和每回合的平均训练速度较ddpg提升了约9%左右。综上,与ddpg算法相比,本文所用算法的平均训练速度提升了10.5%左右。且采用
训练好的模型完成左、右换道场景完整的轨迹规划所需时间均在1.3s内,单步规划所需时间在10ms内,可满足实时要求,且所需时间与处理器性能有关,采用高性能处理器所需时间会更短。
[0131]
本发明使用能够处理连续控制量的双延迟深度确定性策略梯度算法(twin delayed deep deterministic policy gradient,td3),能够实现对自动驾驶车辆速度,加速度的控制,解决了使用dqn算法将动作空间离散化造成的丢失精度控制问题,以及使用ddpg算法会出现的收益函数估值过高的问题,能够较为准确的对车辆控制行为进行评估。通过车辆与环境进行交互,存储得到的历史经验数据对网络进行训练,不需要像机器学习一样通过大量的真实换道数据来训练,节省了对数据进行清洗、筛选等预处理操作,提高了灵活性。在奖励函数中考虑了瞬时燃油消耗量和目标速度控制,最终得到安全,舒适,绿色的换道轨迹。
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1