一种基于分层滚动优化的自动驾驶多任务协调决策方法
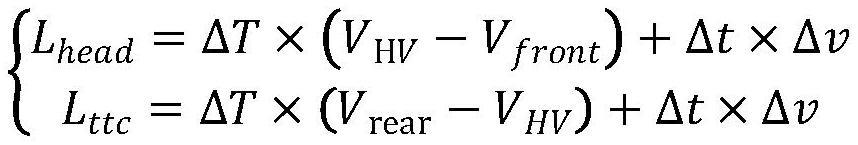
本发明涉及自动驾驶,具体涉及一种基于分层滚动优化的自动驾驶多任务协调决策方法。
背景技术:
1、智能驾驶正处于飞速发展的时期,各种控制决策方法层出不穷。经典控制方法由于其稳定性和成熟的实践经验得到了广泛的应用,并不断改善自身适应日益增长的技术需求。然而当经典方法覆盖了大部分的控制场景时,剩下的极端场景却是经典方法无法解决的领域。此时强化学习展现出强大的生命力,并不断在各个场景和功能中取代原有的经典控制方法。
2、在强化学习蓬勃发展的同时,也面临着难以投入实际使用的现实问题。强化学习或者深度学习难以迁移到训练场景或者数据意外的情形,这限制了其广泛的应用。同时对于训练场景的设置和训练数据的需求比较严格,依赖于人对于数据的筛选和标注。
3、专利cn114170488a公开了一种基于条件模仿学习和强化学习的自动驾驶方法,解决了随机初始化导致的强化学习探索效率低下的问题,但是模仿学习的应用没有解决算法对于标签数据的依赖性。专利cn115629608a公开了一种基于深度预测网络和深度强化学习的自动驾驶车辆控制方法,进一步考虑了车辆之间的交互对车辆轨迹预测的影响。然而更加复杂的驾驶场景中需要长期决策,并且端到端的控制损失了可解释性。专利cn114013443b公开了一种基于分层强化学习的自动驾驶车辆换道决策控制方法,将整个自动驾驶任务划分为决策和控制两层。分阶段的驾驶任务规划使得自动驾驶控制具有可解释性,然而该方案的可迁移性有待讨论验证。
技术实现思路
1、本发明的目的在于提供一种基于分层滚动优化的自动驾驶多任务协调决策方法,该方法能够进行多驾驶任务协调,适用于复杂驾驶场景中的自动驾驶长期决策。
2、为了实现上述目的,本发明采用的技术方案是:一种基于分层滚动优化的自动驾驶多任务协调决策方法,利用自动驾驶车辆环境状态信息作为强化学习决策框架的输入,将驾驶目标规划为多个驾驶任务的衔接,以实现多任务间的协调;将各个驾驶任务分别具体化为控制动作,但仅执行第一个驾驶任务的控制动作;然后滚动向前进入下一时间步,基于更新的自动驾驶车辆环境状态信息再次进行规划和控制动作的执行;如此反复进行规划,实现滚动优化决策。
3、进一步地,该方法包括以下步骤:
4、步骤s1、利用视觉传感器获得自动驾驶车辆周围的原始图像,对图像进行处理并获取其中的周围车辆和障碍物信息;将周围车辆和障碍物信息与本车信息、地图信息构成自动驾驶车辆环境状态信息并表示成高维环境状态鸟瞰图;将高维环境状态鸟瞰图输入神经网络框架,提取环境状态信息的低维表示,得到低维环境状态信息,以简化强化学习决策框架的输入信息;
5、步骤s2、将低维环境状态信息输入强化学习决策框架,通过强化学习决策框架进行多任务决策,得到决策动作,即多个驾驶任务的组合串行;在此基础上,决策各个驾驶任务的控制动作序列,即控制动作的组合串行;控制动作由动作单元库中的动作单元组成;
6、步骤s3、当决策动作和控制动作序列被规划之后,仅执行第一个驾驶任务对应的动作单元序列;
7、步骤s4、滚动向前进入下一时间步,重复步骤s1-s3,更新自动驾驶车辆环境状态信息,并基于此再次进行决策和决策更新后第一个驾驶任务的动作单元序列的执行;如此反复进行规划,实现滚动优化决策。
8、进一步地,所述本车信息包括本车位置和状态信息;所述地图信息来源于已有高精地图或者识别模块获得的语义地图,包含道路路径信息;所述道路路径信息为全局的路径信息,包含从起点到终点的系列路径点,在鸟瞰图中以折线表示;所述高维环境状态鸟瞰图为256*256像素,被处理调整为64*64像素,并且视角始终与本车视图对齐,本车位于视图的固定位置。
9、进一步地,为了将车辆的行为建模并作为强化学习决策框架的输入,把本车和周围车辆的尺寸建模为具有碰撞风险的可变单元,根据车辆的驾驶行为动态改变。
10、进一步地,将车辆尺寸建模为可变单元,具体如下:
11、对于恒速行驶车辆,其前后尺寸分别定义为:
12、
13、其中,lhead为可变单元基于车辆原始尺寸前方延长的尺寸,lttc为可变单元基于车辆原始尺寸后方延长的尺寸,δt为与前车保持最小间距所需的时间常数,vhv为本车车速,vfront为前车车速,vrear为后车车速;
14、对于正在加速车辆和减速车辆,分别将该车辆前方、后方尺寸增加;定义如下:
15、
16、其中,δt表示图像采集间隔,δv表示相对速度;
17、对于静止障碍物,将其尺寸向后延长至安全刹车距离;
18、对于变道车辆,将其变道方向的尺寸延长,延长尺寸以车道尺寸为准;
19、对于大型车辆,固定延长其前后尺寸,其中后方尺寸相对于前方尺寸延长更多;
20、所述可变单元用于判定事故发生,如果两车的可变单元重合,则判定两车事故。
21、进一步地,提取环境状态信息的低维表示,具体为:
22、所述环境状态信息的低维表示通过变分自动编码器获得,编码网络将原始的高维环境状态信息编码为低维状态表示;为了获得网络中的具体参数,目标函数设置为:
23、
24、其中,lvae表示损失,dkl表示kl散度,表示多元高斯分布的先验概率分布,其中μ(st),σ(st)分别表示低维状态表示的平均值和标准偏差,为重构损失,用于测量预测帧与原始帧的接近程度。
25、进一步地,所述变分自动编码器包含4个3×3内核大小的卷积层,分别有32、64、128和256个信道;每个卷积层之后都为relu激活函数;然后将尺寸为64的潜在空间层完全连接到最后一个卷积层,使用adam优化器训练;
26、所述变分自动编码器预先进行训练,得到的网络集成在强化学习决策框架中,作为视觉编码层;所述视觉编码层的参数不再随着强化学习决策框架的改变而改变;
27、所述变分自动编码器在prescan环境下训练,利用carsim搭建车辆模型,获取原始图像并处理为鸟瞰图格式,用于变分自动编码器的训练。
28、进一步地,所述强化学习决策框架基于分阶段设计,用于决定未来一段时间内的驾驶任务;所述强化学习决策框架输出驾驶任务的组合串行之后,进一步决策控制动作的组合串行;
29、所述控制动作的组合串行由动作单元库中的动作单元组成,所述动作单元包含车辆的速度和转角信息,所述动作单元由纯追踪算法和pid算法在虚拟环境中获得。
30、进一步地,所述动作单元的设计包含以下步骤;
31、步骤1:决定任意任务的起点和终点;根据车辆的可变单元,选择本车与前车可变单元的间距以决定任务起点的动作;终点定义为目标车道的中心线、目标车速或者两者同时满足;
32、步骤2:选择起点到终点之间的可行动作单元;利用路径规划器产生可行路径,所述可行路径由一系列包含车辆状态信息的点组成;利用纯追踪算法和pid算法获得横向和纵向的控制指令;基于此,获得强化学习可用的动作单元集合。
33、进一步地,所述强化学习决策框架的实现方法为:
34、所述强化学习决策框架采用sac网络,所述sac网络包括两个q网络,一个为价值网络,一个为策略网络;价值网络的视觉编码层之后是5个密集层,隐藏单元范围从256到32;策略网络的结构与价值网络相同,只是最后一层拆分为两个分支;第一个分支表示作用的均值,第二个分支表示其方差;所述sac网络均使用adam优化器进行训练;
35、决策的产生依赖于奖励函数中的权重取舍,使得驾驶员和乘客的舒适性与满意度均被考量;奖励函数设计为:
36、r=rv+rα+rc+ro+k
37、其中各项分别表示速度奖励项、转向平顺项、碰撞项、驶出车道项和车辆静止惩罚项;
38、所述强化学习决策框架输出驾驶任务的控制动作序列,对应于每一个驾驶任务,使用q学习算法从动作单元库中选择动作单元序列,并执行第一个驾驶任务所对应的动作单元序列,完成一次复杂场景下的多任务决策和控制;基于此,循环进行决策控制以驾驶车辆到达目标位置。
39、与现有技术相比,本发明具有以下有益效果:本发明提出了一种基于分层滚动优化的自动驾驶多任务协调决策方法,解决了现有强化学习应用于自动驾驶时的可迁移性问题、可解释性问题和复杂场景下决策和控制的问题。对于强化学习输入信息的预处理能够使得决策控制器在虚拟环境中训练并快速迁移运用到实际环境,缩小了和实际场景应用时的差距。多任务串行以及动作串行使得控制器能够进行长效规划,极大提高自动驾驶对于复杂场景下的驾驶决策能力。分层规划控制也能够克服端到端的弊端,类似于人类先有驾驶决策,后进行细致的控制的驾驶行为。更进一步的,类似于人类驾驶员进行未来一段时间内的驾驶规划,然而最终执行的只是下一步的操作,然后根据新的状态重新规划,本发明亦只将驾驶任务串行中的第一任务所对应的动作串行实际应用执行,完成一次决策控制,而后进行下一轮决策控制。基于此,本发明提出的基于强化学习的多任务协调决策方法能够获得更加安全、稳定、高效的决策,控制器能够不断学习适应新环境,而非限制于虚拟场景或者训练过的场景。
- 还没有人留言评论。精彩留言会获得点赞!