一种基于深度强化学习的伦理驱动多模态决策方法
本发明属于车联网和自动驾驶领域,特别是涉及一种基于深度强化学习的伦理驱动多模态决策方法。
背景技术:
1、伦理自动驾驶决策是当前自动驾驶技术面临的重要伦理问题之一。随着自动驾驶系统的普及和应用,其所涉及的道德和伦理问题已经成为公众关注的焦点。在这个背景下,伦理自动驾驶决策的重要性不言而喻。首先,伦理自动驾驶决策涉及到人类价值观和道德准则的问题,需要考虑到人类的安全、尊严、自由等基本权利。其次,伦理自动驾驶决策还必须遵守国家法律和道路交通规则,以确保道路交通的安全和有序。最后,伦理自动驾驶决策还需要考虑到社会公平和责任分配等问题,以避免可能给社会带来不必要的损失和负担。因此,伦理自动驾驶决策的研究和实践具有重要的意义,不仅能够促进自动驾驶技术的发展与应用,还能够为人类未来社会的可持续发展做出积极的贡献。
2、现有的深度强化学习方法在伦理交通场景进行伦理决策时,存在以下问题:获取的伦理交互信息不足、获取环境信息来源单一、对于状态信息处理效率低等问题,这导致无法满足伦理决策系统实际应用的需求。
技术实现思路
1、本发明的目的是提供一种基于深度强化学习的伦理驱动多模态决策方法,以解决上述现有技术存在的问题。
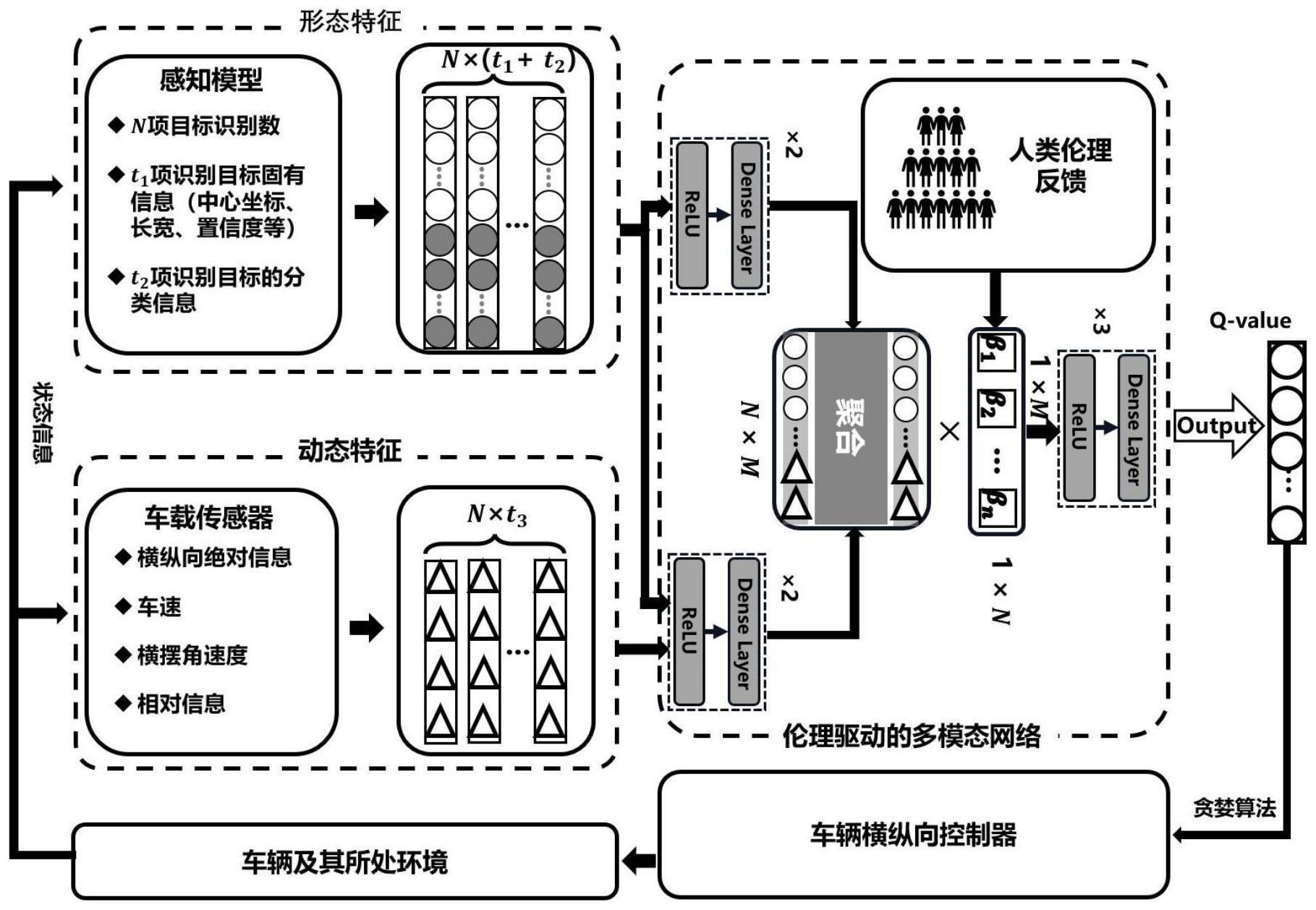
2、为实现上述目的,本发明提供了一种基于深度强化学习的伦理驱动多模态决策方法,包括:
3、获取车辆拍摄图像,基于所述车辆拍摄图像和感知模型获取周围环境形态特征和动态特征;
4、构建多模态神经网络,将人类伦理反馈的伦理系数引入至所述多模态神经网络中进行训练后对所述周围环境形态特征和动态特征进行计算,获得相应动作的q值;
5、基于强化学习算法将所述相应动作的q值进行计算,获得对应动作,基于所述对应动作对车辆进行决策。
6、优选地,所述基于所述车辆拍摄图像获取周围环境形态特征和动态特征的过程包括:
7、通过车载设备向汽车周围进行目标识别,获得所述周围环境形态特征的矩阵;
8、基于车载设备获取所述动态特征的矩阵和道路测量信息矩阵。
9、优选地,对所述周围环境形态特征和动态特征进行计算的过程包括
10、通过所述感知模型中的两个密集网络层单独提取所述周围环境形态特征的矩阵;
11、通过所述感知模型中的其余两个密集网络层提取所述动态特征的矩阵的同时提取道路测量矩阵;
12、将所述所述周围环境形态特征的矩阵、所述动态特征的矩阵和所述道路测量矩阵进行合并,获得所述特征矩阵。
13、优选地,所述获得相应动作的q值的过程包括:
14、基于训练后的多模态神经网络中的人类伦理反馈生成n维向量,通过所述n维向量将所述特征矩阵转化为m维向量,基于所述m维向量输出相应动作的q值。
15、优选地,所述基于人类伦理反馈生成n维向量的过程包括:
16、基于人类对不同目标识别碰撞的选择构建人类伦理反馈的伦理系数;
17、通过人类伦理反馈的伦理系数构建所述n维向量。
18、优选地,基于所述m维向量输出相应动作的q值的过程包括:
19、所述n维向量对所述特征矩阵进行伦理归一化,获得m维向量;
20、对所述m维向量进行密集网络层提取,最后输出为所述相应动作的q值。
21、优选地,所述人类伦理反馈的伦理系数包括损坏程度奖励子函数、经济价值子奖励函数、法律法规子奖励函数。
22、优选地,基于所述对应动作对车辆进行决策的过程包括:
23、强化学习算法使用贪婪策略生成所述对应动作,通过车辆横纵向控制器控制车辆,状态更新后,状态信息与奖励值对应更新,获得决策结果。
24、本发明的技术效果为:
25、1.本发明采用在环境中观测到的物体形态特征与通过车载传感器获取车辆相对状态的动态特征作为模型输入,并基于此提出了伦理驱动的多模态神经网络统一提取两种形态特征,可以提升整体状态信息的准确性和鲁棒性,并且将人类反馈的伦理信息用于特征矩阵的转换,可实现对不同伦理侧重的识别目标进行决策。
26、2.以上两种模态特征信息在模型中进行端到端处理,输入为识别的图片信息以及车载传感器的信号信息,输出为可选择动作的q值。这种处理方式奖励了实际应用的条件,可实现在现实场景中进行伦理决策,
27、3.为了建立更加符合人类意愿的伦理决策系统模型,损坏程度奖励子函数、经济价值子奖励函数、法律法规子奖励函数,所训练的决策模型可因此获得更准确的伦理交互信息。
技术特征:
1.一种基于深度强化学习的伦理驱动多模态决策方法,其特征在于,包括以下步骤:
2.根据权利要求1所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,所述基于所述车辆拍摄图像获取周围环境形态特征和动态特征的过程包括:
3.根据权利要求2所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,对所述周围环境形态特征和动态特征进行计算的过程包括
4.根据权利要求1所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,所述获得相应动作的q值的过程包括:
5.根据权利要求4所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,所述基于人类伦理反馈生成n维向量的过程包括:
6.根据权利要求4所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,基于所述m维向量输出相应动作的q值的过程包括:
7.根据权利要求1所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,所述人类伦理反馈的伦理系数包括损坏程度奖励子函数、经济价值子奖励函数、法律法规子奖励函数。
8.根据权利要求1所述的基于深度强化学习的伦理驱动多模态决策方法,其特征在于,基于所述对应动作对车辆进行决策的过程包括:
技术总结
本发明公开了一种基于深度强化学习的伦理驱动多模态决策方法,包括:获取车辆拍摄图像,基于所述车辆拍摄图像和感知模型获取周围环境形态特征和动态特征;构建多模态神经网络,将人类伦理反馈的伦理系数引入至所述多模态神经网络中进行训练后对所述周围环境形态特征和动态特征进行计算,获得相应动作的Q值;基于强化学习算法将所述相应动作的Q值进行计算,获得对应动作,基于所述对应动作对车辆进行决策。本发明采用在环境中观测到的物体形态特征与通过车载传感器获取车辆相对状态的动态特征作为模型输入,并基于此提出了伦理驱动的多模态神经网络统一提取两种形态特征,可以提升整体状态信息的准确性和鲁棒性。
技术研发人员:李雪原,高鑫,栾天,孟小强,刘琦
受保护的技术使用者:北京理工大学
技术研发日:
技术公布日:2024/1/15
- 还没有人留言评论。精彩留言会获得点赞!