一种非结构场景的强化学习泊车路径规划方法及系统
本发明涉及自动驾驶路径规划领域,具体涉及一种非结构场景的强化学习泊车路径规划方法及系统。
背景技术:
1、自动泊车是实现自动驾驶汽车的关键一环。由于交通环境拥挤,停车位资源紧张,这种环境下泊车容易引起局部交通堵塞、剐蹭事故的发生;另一方面由于车辆和人均受自身条件影响而存在视觉盲区,泊车往往耗费大量的时间和精力。自动泊车的出现和发展为解决泊车问题提供新思路,实现高效稳定的自动泊车能够极大节省驾驶员的时间,充分利用停车位资源。自动泊车在模块化自动驾驶汽车中属于路径规划模块。自动泊车是低速场景的路径规划,虽然不像高速场景对实时性要求较高,但泊车场景一般较为狭窄,在自身车辆运动学约束和障碍物限制的情况下更难以规划出一条安全、最优的无碰撞路径。且目前大多数研究针对结构化停车场,非结构化场景由于缺乏导航信息和停车位的不规范,在规划路径时更加困难。
2、经典泊车算法采用搜索和采样的规划,如rrt、a*搜索,并使用了考虑运动学约束的混合a*算法。经典算法能够处理典型的场景,但它们的计算复杂度与环境复杂度成正比,算法的响应时间可能会受到阻碍。在基于学习的路径规划模型中,强化学习通过与环境交互,并能记忆场景中的信息,而结合深度学习技术,通过拟合非线性神经网络,极大提高了可泛化性;深度强化学习已经在机器人导航控制取得了成功,但由于自动驾驶汽车自身运动学的约束,直接使用效果不佳;模仿学习根据专家数据集训练网络模型,但受到训练数据的限制,无法进行泛化;此外,深度强化学习训练时使用高维数据作为输入来检测和观察障碍物,这大大增加了整体训练时间,并使策略更难推广到不同的环境。
技术实现思路
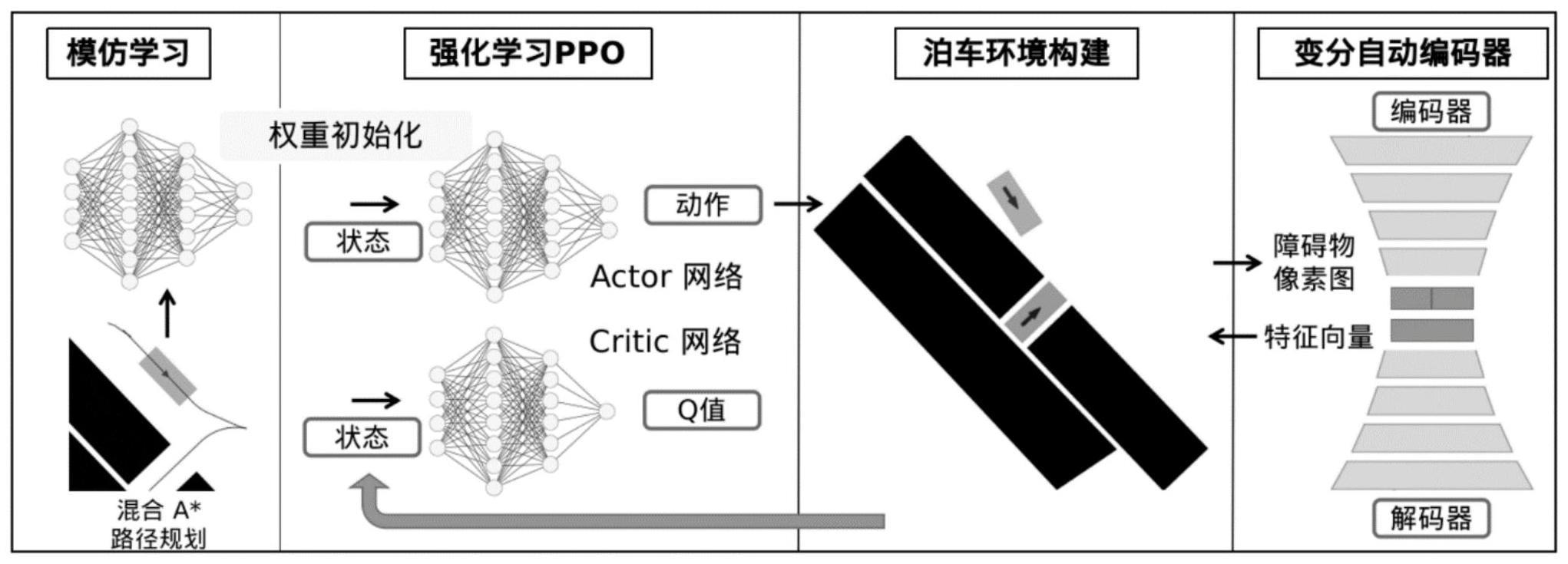
1、为了解决现有技术中存在的问题,本发明提供基于一种非结构泊车场景的模仿学习初始化的强化学习泊车路径规划方法及系统。首先使用混合a*算法生成专家策略,使用模仿学习从专家的演示快速训练网络模型,改善了强化学习训练缓慢且效率低下的问题,快速学习到专家策略;而强化学习的使用,则弥补了模仿学习专家数据集有限的问题,提升了模型应对未知和极端情况的能力;采用变分自动编码器获取障碍物图像特征向量,将训练数据转换为低维度数据,减少了模型训练时间,并提升了模型在不同环境的泛化能力。
2、为了实现上述目的,本发明采用的技术方案:一种非结构场景的强化学习泊车路径规划方法,包括以下步骤:
3、构建非结构泊车场景,根据障碍物信息、车辆位置和目标停车位置构建非结构化泊车场景;将障碍物信息用像素图表示,将车辆位置和目标停车位置分别用向量表示;
4、使用混合a*算法生成对应场景下的专家泊车策略,将专家策略和泊车场景信息转换为模仿学习数据集,输入到模仿学习网络训练,得到车辆的泊车策略;
5、初始化ppo算法网络结构中的actor网络,通过构建的非结构泊车场景训练网络模型,在多目标奖励函数作用下,基于ppo算法优化所述网络模型和泊车策略,得出泊车一系列路径点;
6、根据ppo算法网络输出的一系列路径点的距离变化和角度变化信息,在速度和曲率变化约束条件下进一步优化后得出车辆完整的泊车路径。
7、进一步的,构建的非结构化泊车场景具体如下:
8、障碍物位置信息:将多个障碍物被表示为凹或者凸的多边形,并记录其坐标点信息{(x1,y1),...,(xn,yn)},每个障碍物多边形的顶点信息按逆时针方向记录;
9、车辆位置和目标停车位姿信息:给出车辆起始位置和目标停车位置的3个维度的信息,横纵坐标和朝向角:{x,y,θ},其中横纵坐标表示自动驾驶车辆后轴中心的位置。
10、进一步的,使用混合a*算法生成对应场景下的专家泊车策略,将专家策略和泊车场景信息转换为模仿学习数据集,输入到模仿学习网络训练,得到车辆的泊车策略包括:首先根据所构建的泊车场景,使用混合a*算法生成一条从车辆起始位置到目标停车位置的一条符合车辆运动学的无碰撞路径,所述无碰撞路径的信息为包含一系列路径点的数组。
11、进一步的,构建非结构泊车场景时,用变分自动编码器将高度复杂的泊车场景编码成一维特征向量,变分自动编码器包括编码器和解码器,编码器接收来自非结构化泊车场景中的障碍物像素图,通过4层卷积层和2层全连接层生成隐藏层的分布模型,经过采样输出障碍物特征向量,障碍物特征向量通过由2层全连接层和4层逆卷积层构成的解码器恢复原来的图像数据。
12、进一步的,将泊车场景信息和专家策略转换为状态-动作对数据集时,状态是在某时刻t的障碍物特征向量,车辆位置和目标停车位姿信息向量,动作则是自动驾驶车辆在当前状态下需要执行的操作,在模仿学习网络训练过程中,输入一系列状态,输出对应状态的泊车策略;所述泊车策略包括前进直行、前进右转、前进左转、后退直行、后退右转、后退左转。
13、进一步的,ppo算法网络结构包括actor网络和critic网络,actor网络和critic网络的输出不同,其余结构相同;输入为障碍物特征向量、车辆位置和目标停车位姿信息向量;车辆位置和目标停车位姿信息向量分别通过一个全连接网络扩充到大小与障碍物特征向量相同,然后障碍物特征向量、车辆位置和目标停车位姿信息向量拼接起来,得到拼接后的状态表示;actor网络和critic网络连接并经过3个全连接层输出,同时经过tanh()函数激活,actor网络最后经过softmax函数归一化输出泊车策略行为,critic网络最后一层直接输出一个value值。
14、基于上述方法的构思,提供一种非结构场景的强化学习泊车路径规划系统,包括场景构建模块、模仿学习预训练模块、强化学习优化模块以及路径生成模块;
15、场景构建模块用于构建非结构泊车场景,根据障碍物信息、车辆位置和目标停车位置构建非结构化泊车场景;将障碍物信息用像素图表示,将车辆位置和目标停车位置分别用向量表示;
16、模仿学习预训练模块使用混合a*算法生成对应场景下的专家泊车策略,将专家策略和泊车场景信息转换为模仿学习数据集,输入到模仿学习网络训练,得到车辆的泊车策略;
17、强化学习优化模块基于初始化ppo算法网络结构中的actor网络,通过构建的非结构泊车场景训练网络模型,在多目标奖励函数作用下,基于ppo算法优化所述网络模型和泊车策略,得出优化后的泊车一系列路径点;
18、路径生成模块用于根据ppo算法网络输出的一系列路径点的距离变化和角度变化信息,在速度和曲率变化约束条件下进一步优化后得出车辆完整的泊车路径。
19、还提供一种自动驾驶车辆,基于本发明所述基于模仿学习初始化的强化学习自动泊车路径规划方法进行泊车路径规划。
20、本发明还提供一种计算机设备,包括处理器以及存储器,存储器用于存储计算机可执行程序,处理器从存储器中读取所述计算机可执行程序并执行,处理器执行计算可执行程序时能实现本发明所述基于模仿学习初始化的强化学习自动泊车路径规划方法。
21、同时提供一种计算机可读存储介质,计算机可读存储介质中存储有计算机程序,所述计算机程序被处理器执行时,能实现本发明所述的基于模仿学习初始化的强化学习自动泊车路径规划方法。
22、与现有技术相比,本发明至少具有以下有益效果:
23、本发明结合模仿学习和强化学习优点的自动泊车路径规划算法,能在复杂的没有导航信息的非结构化场景下快速规划出一条安全无碰撞的泊车路径,模仿学习预训练actor网络,以混合a*算法生成一条从车辆起始位置到目标停车位置的一条符合车辆运动学的无碰撞路径为专家数据集,快速学会基本的泊车策略。再使用强化学习进行策略的优化,通过与泊车场景的交互,在多目标奖励函数的反馈下,有效评估不同状态-动作对的奖励,每一步都会给出反馈,在完成目标时还会有更大的正奖励,使泊车策略朝着多目标最优的方向更新;强化学习ppo网络利用多目标奖励函数优化训练模仿学习初始化后的泊车路径规划,并针对构建的场景设置了多种随机情景,使本发明对于未知和极端场景具有更好的泛化性。
24、进一步的,引入变分自动编码器技术,对障碍物像素图进行编码,能够通过特征向量捕获输入数据中一些隐藏特征,通过简单的特征向量映射复杂的障碍物像素图数据,并使得强化学习ppo网络从对图像的处理转换为对一维向量数据的处理,减少了整体的训练时间,并根据隐藏特征使得模型更容易推广到其他环境中去。
- 还没有人留言评论。精彩留言会获得点赞!