一种基于博弈马尔可夫过程安全检测的无人车辆导航控制系统及方法
本发明涉及无人车辆导航控制,具体而言,涉及一种基于博弈马尔可夫过程安全检测的无人车辆导航控制系统及方法。
背景技术:
1、直随着计算机技术和5g技术的发展,无人驾驶技术迅速发展。对于不同大小和速度的行人、车辆、动物等障碍物的复杂场景,更快、更安全的导航控制方式是确保无人驾驶车辆安全的关键。在拓扑地图环境下,常规的导航算法如rrt*,a*,蚁群算法等不能很好地处理循迹与避障控制的关系,且缺少对无人驾驶车辆动作的安全性检测。
2、传统的安全检测方法大多采用智能体(车辆与障碍物)之间的最近距离模型来描述安全问题,该方法可以很容易地描述静态智能体的安全检测,但它没有考虑智能体动作(速度和加速度)对安全性的影响,也没有考虑智能体之间动作交互的影响。
技术实现思路
1、本发明要解决的技术问题是:
2、为了解决现有导航算法难以处理循迹与避障控制的关系,且传统安全检测方法没有考虑智能体动作对安全性的影响以及智能体间动作交互影响的问题。
3、本发明为解决上述技术问题所采用的技术方案:
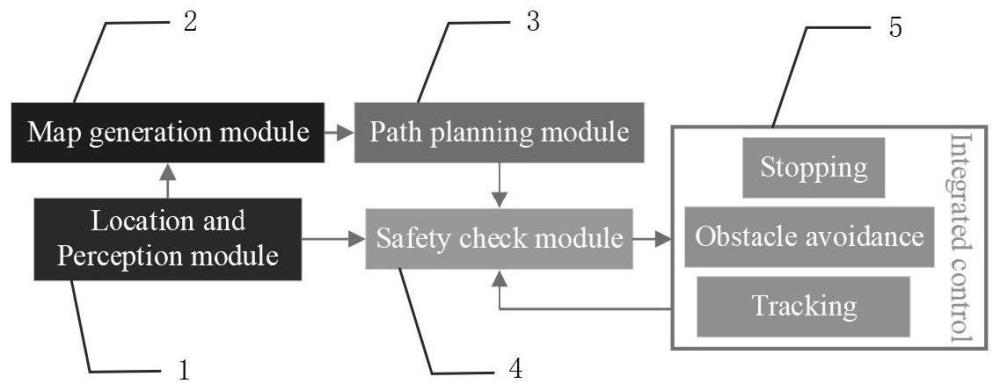
4、本发明提供了一种基于博弈马尔可夫过程安全检测的无人车导航控制系统,包括,
5、定位感知模块,用于获取环境数据信息和车辆信息;
6、地图生成模块,用于根据定位感知模块获取的环境数据信息生成拓扑路网地图;
7、全局路径规划模块,用于将地图生成模块生成的拓扑路网地图中搜索最短路径作为全局路径,并将全局路径发送给安全评估模块;
8、安全评估模块,用于将全局规划模块生成的全局路径和定位感知模块获取的环境数据信息进行实时分析,判断车辆是否安全;
9、集成控制模块,用于根据安全评估模块的反馈执行相应的操作。
10、进一步地,所述集成控制模块包括停车控制子模块、循迹控制子模块和避障控制子模块,所述避障控制子模块需要生成避障控制子模块。
11、一种基于博弈马尔可夫过程安全检测的无人车导航控制方法,包括以下步骤:
12、步骤一、地图生成模块基于定位感知模块获取的环境数据信息生成拓扑路网地图;
13、步骤二、全局路径规划模块从步骤一中获取的拓扑路网地图中搜索最短路径作为全局路径,并将全局路径发送给安全评估模块;
14、步骤三、安全评估模块接收定位感知模块的环境数据信息,结合步骤二中的全局路径,实时分析车辆是否安全,然后集成控制模块根据安全评估模块的反馈执行相应的停车控制、循迹控制或避障控制。
15、进一步地,在步骤一中,包括以下步骤:
16、通过定位感知模块和状态解析器获取车辆的当前位置信息,并采集车辆轨迹信息,得到一系列轨迹点信息;再对一系列的轨迹点信息进行平滑滤波处理后,得到新的道路信息;更新道路信息,建立与原道路的连接关系;根据新的道路信息与原地图中道路信息的关系,更新整体拓扑路网地图,并发送到后台系统进行地图存储。
17、进一步地,在步骤二中,全局路径规划模块采用基于权值的dijkstra算法搜索步骤一构建的拓扑路网地图,设计并使用道路代价值函数来搜索全局最短路径,具体包括,
18、根据位于不同道路区域的车辆起点和规划终点,在以下情况下设置道路的权重成本:道路为车辆点所在位置;道路为通行区;道路为规划终点所在位置;当车辆点与规划终点位于同一路线区域时,权值为车辆点与当前道路规划终点之间的长度;
19、设(xij,yij),(j=0,1,2,……,mi)为路网地图中的道路点,其中,i和j分别表示道路和点的序号,车辆最近点(xks,yks)表示道路点s在道路k上的位置,规划终点(xqe,yqe)最近点表示道路点e在道路q上的位置;其中,dir={0,1}表示车辆行驶方向与道路方向是否一致,当dir=1时代表车辆行驶方向与道路方向一致,当dir=0时代表车辆行驶方向与道路方向不一致;然后可以得到道路代价成本cr(k≠q),
20、
21、其中,mk和mp分别为道路k和道路p上路径点的数量,
22、当车辆起点与终点处于同一道路时,则,
23、
24、进一步地,在步骤三中,在对全局路径进行安全评估中,安全检测判断标准为,根据车辆和障碍物的状态信息进行动作安全检测;如果车辆安全,则循迹;相反,根据道路边界判断是否有足够的避让空间,若有足够的避让空间,则进行避让控制;相反,则停下来等待。
25、进一步地,安全评估模块(4)采用基于博弈马尔可夫过程对评估动作和预测动作的选择,将动作安全检测分为横向安全检测、纵向安全检测和速度安全检测三个层次,即如果车辆横向不安全,则需要考虑车辆纵向是否安全;如果车辆纵向不安全,就要考虑车速对安全的影响;如果车速是安全的,那么车辆就是安全的,
26、其中,根据实际速度、加速度、制动能力和制动响应时间计算估计的横向安全距离,将纵向安全距离和纵向安全速度的上下限与实际横向和纵向距离进行比较,并以此判断车辆是否安全,
27、并在安全检测策略中引入pomdp,基于转移动作预测智能体在未来时间的状态,对于预测时间内的每个状态,智能体需根据策略选择极端动作,并移动到新的状态,评估新状态的安全性,利用对未来时间内所有传递动作的安全性评价作为最终的安全检测,在此过程中利用即时奖励函数和累积奖励函数;
28、ta(st-1,at,st)=pa(st|st-1,at).
29、上式为状态转移概率模型,表示智能体采取转移动作后,该时刻状态转移到下一时刻状态的概率;
30、oa(st,zt)=pa(zt|st).
31、上式为观测模型,表示智能体在状态下对观测状态的置信度;
32、上述两个函数反映了智能体不确定性感知的随机特性和运动模型;
33、ssafe=k·tc·toi·oc·||s'ct,s'oit||
34、
35、rt=r1+γrt+1+γ2rt+2+…+γh-1rt+h-1
36、其中,rt(st-1,at)为即时奖励函数,表示在状态下所采取的转移动作所获得的即时奖励;rt为累积折扣奖励,表示在该状态下采取行动所获得的累积折扣奖励,其中,h为预测周期;
37、当智能体采取动作时,将通过上式所示的动作安全检测算法对其进行检查;如果他们是安全的,则rt=1;否则,rt=0;
38、设置安全阈值系数safe,若rt大于设置的安全阈值系数,则车辆相对于障碍物是安全的;否则,车辆相对于障碍物是不安全的;当车辆相对于所有障碍物安全时,则车辆是安全的;否则,车辆是不安全的,需要避让控制或停车;
39、通过对未来转移动作的反复迭代,获得包含未来预测周期内每个状态节点上评估最佳安全动作的完整动作安全检测周期。
40、进一步地,在安全评估模块(4)反馈操控过程中,首先需要获取车辆总势场函数;
41、将道路重力势场gpf、障碍物势场opf以及道路边界势场相结合得到车辆总势场函数tpf;
42、设道路重力势场gpf为:
43、
44、其中,κat和nat均为引力势场增益系数,pego和ptar分别为车辆和目标点在道路坐标系s-l下的位置;
45、基于全局路径建立飞网坐标系s-l,全局路径的长度为s轴的长度,左右道路宽度为l轴的正负方向,为满足障碍物斥力势场值在速度方向上最大,且从速度方向向两侧递减的要求,障碍物势场opf为:
46、
47、其中,κo和no均为障碍物势场的增益系数,θl为经过车辆和障碍物的直线与坐标轴s的夹角,θobs为障碍物前进方向与坐标轴s的夹角;
48、车辆上多个障碍物的总势场tpf可表示为,将道路重力势场gpf、障碍物势场opf以及道路边界势场相结合得到车辆总势场函数tpf,
49、
50、其中,κl、nl和κr、nr分别为左右道路边界势场的增益系数;pl_road和pr_road为道路边界的左右道路点;ρroad为道路边界点的影响范围。
51、进一步地,考虑不同避障子目标点会产生不同的避障效果,基于车辆的模型预测,提出避障控制伪代码,
52、为了计算车辆控制变量,通过计算tpf函数沿和方向的偏导数,得到了tpf在沿和方向上对车辆产生的虚力,并通过对求得的车轮转角进行车辆模型的运动学约束,
53、
54、
55、
56、
57、其中,kδ为避障控制器前轮转角增益系数;l为车辆前后车轮轴距;vt和分别为车辆t时刻的速度和航向角;
58、车辆在避障过程中的运动速度控制包括以下三种情况,
59、(1)当车辆横向和纵向相对于障碍物安全时,,pego(s)和pobs(s)表示车辆或障碍物的纵向距离,则无人驾驶汽车的加速度为,
60、a=kv(vtarget-vego),safe∩(pego(s)≤pobs(s)).
61、其中,kv为避障控制器速度增益系数;vtarget为车辆的目标车速,vego为车辆当前车速;
62、(2)当车辆横向和纵向不安全时,假设无人车在避障过程中以恒减速运动,则无人车在方向上的加速度为,
63、
64、a=-max{ai},unsafe.
65、其中,vrt为t时刻车辆相对于障碍物的速度;为车辆相对于障碍物的速度方向与经过车辆和障碍物的直线所形成的夹角,ρ为障碍物的影响范围,s0为最小安全距离,kv'为加速度增益系数。
66、(3)当车辆避开障碍物并远离障碍物时,则车辆加速到目标速度,
67、a=kv(vtarget-vego),safe∩(pego(s)≥pobs(s)+sback).
68、
69、进一步地,对于循迹控制,车轮角度的控制量为,
70、
71、其中,k'δ为循迹控制器前轮转角增益系数,ld为车辆前视距离;
72、对于速度控制,速度控制量为,
73、v=vego+kp(vtarget-vego).
74、其中,kp为循迹控制器速度增益系数;
75、采用优化算法进行处理,构造速度和转角的记忆空间和设置优化后的平滑控制变量μi',i=1,2,……,nφ,μ'0=μ0,定义优化目标函数j(μ)为,
76、
77、j*(μ)=arg min(j(μ)).
78、
79、其中,第一项用于衡量优化后与原控制量的偏差程度;第二项用于测量优化后控制量之间的距离;优化的过程就是最小化;最后选择优化后的第一个预测控制量μi'作为当前车辆的控制量;再最终计算出的控制量转换到笛卡尔坐标系中。
80、相较于现有技术,本发明的有益效果是:
81、本发明一种基于博弈马尔可夫过程安全检测的无人车导航控制系统及方法,提出了一种基于安全检测、循迹控制与避障控制融合逻辑和目标点确定的导航综合控制系统,能够很好的处理循迹与避障控制之间的关系,补入了对无人驾驶车辆动作的安全性检测,且考虑到了智能体动作对安全性的影响和智能体之间动作交互的影响;
82、本发明一种基于博弈马尔可夫过程安全检测的无人车导航控制系统及方法,为了解决无人驾驶地面车辆在拓扑道路网络地图上的避障问题,保证车辆的安全,提出了一种基于安全检测的集成避障控制方法。为了减轻智能体动作交互对安全检测的影响,设计了基于评估动作的动作安全检测。为了对未来一段时间内车辆持续行动的安全性进行评估,基于pomdp预测了智能体之间的博弈对抗行为和评价行为,设计了评价奖励函数和安全阈值系数,生成了车辆安全检测策略。另外,采用基于改进apf的实时避障控制策略与跟踪控制进行交互。考虑障碍物速度和道路边界的影响,设计了矢量障碍物势场和道路势场。结合车辆运动模型,提出了预测控制策略。最后,设计了横向和纵向控制算法,并引入控制变量存储空间对控制算法进行优化;
83、本发明一种基于博弈马尔可夫过程安全检测的无人车导航控制系统及方法,考虑无人车与障碍物之间的动作交互,提出了一种基于博弈论和部分可观察马尔可夫决策过程pomdp的动作安全评估策略,且系统结构层次简单,反应速率快,安全性高。
- 还没有人留言评论。精彩留言会获得点赞!