一种基于支持向量机模型的冷水机组高能效控制方法与流程
本发明属于中央空调的节能优化控制领域,特别涉及一种基于支持向量机模型的冷水机组高能效控制方法。
背景技术:
近年来随着建筑总量的增加和人们追求居住舒适度的提升,我国的建筑能耗目前每年已占社会总能耗的33%以上并仍在持续增加中。而在建筑能耗中,中央空调系统能耗约占50%;冷水机组作为中央空调制冷核心设备,能耗占据中央空调能耗的40%以上。因此,对冷水机组的节能潜力研究具有重要的意义。
冷水机组的能效比是指制冷机组单位功率下的制冷量,能效比的高低直接反映了能源转换的效率。影响能效比的因素有很多,一是机组本身,机组的结构、换热器热交换界面/介质等因素会直接影响能效比,这部分影响因素在运行中往往是不可改变的;二是机组的运行参数,这部分因素是可以进行人工设定的,如蒸发器的进/出口温度、冷凝器的进/出口温度、机组的负荷等。
如何在满足制冷负荷的前提下,合理设定运行参数,使冷水机组在较高的能效比下工作,是冷水机组节能的关键。冷水机组能效比与各运行参数之间是典型的非线性关系,常规的线性建模方法很难准确描述它们之间的关系。
技术实现要素:
本发明的目的,在于提供一种基于支持向量机模型的冷水机组高能效控制方法,能够挖掘能效比与关键运行参数之间的关系,利用关键运行参数和能效比的历史数据,建立冷水机组能效比模型。利用模型预测不同运行参数工况下的冷水机组能效比,从中选取满足冷负荷需求的、冷水机组效率最高的一组参数,指导冷水机组运行中参数的设定,为获得更好的运行效率提供依据,达到节能降耗的目的。
为了达成上述目的,本发明的解决方案是:
一种基于支持向量机模型的冷水机组高能效控制方法,包括如下步骤:
步骤1,从冷水机组的运行参数中选取对冷水机组能效比影响明显的多种运行参数,采集这些运行参数的历史数据;
步骤2,对冷水机组的各个运行参数、能效比的历史数据进行归一化处理,再通过聚类算法获取多组基于支持向量机能效比模型的训练数据;
步骤3,采用支持向量机方法建立冷水机组能效比模型,以历史运行参数作为模型的输入,以历史能效比数据作为模型的输出;
步骤4,利用能效比模型提前预测未来某工况下的冷水机组能耗。
上述步骤1中,选取对冷水机组能效比影响明显的多种运行参数包括机组负荷qload、蒸发器进口温度te_in、蒸发器出口温度te_out、冷凝器进口温度tc_in和冷凝器出口温度tc_out。
上述步骤1中,蒸发器和冷凝器的进/出口温度直接采集。
上述步骤1中,机组负荷qload利用如下公式计算:
qload=c·q·(te_in-te_out)/3.6/3.517
其中:qload——机组负荷,单位rt
c——水的比热容,值为4.2kj/(kg·℃)
q—冷冻水流量,单位t/h
te_in——蒸发器进口温度,单位℃
te_out——蒸发器出口温度,单位℃
3.6——kg/s与t/h换算系数
3.517——rt与kw换算系数。
上述步骤2中,对各组历史数据分别进行归一化处理,具体的方法是:
其中:x,y∈rn,xmin=min(x)为历史数据中的最小值,xmax=max(x)为历史数据中的最大值,原始数据x经归一化处理后得到y;每组运行参数历史数据分别经过归一化处理之后,所有的y均转化到[0,1]之间。
上述步骤2中,对数据进行归一化处理后,得到n组训练样本集a={a1,a2,···,an},其中ai为一组训练样本,i=1,2,··,n,通过聚类算法获得n组聚类中心,作为支持向量回归的训练样本:{ω1,ω2,···,ωn}。
上述步骤4的具体内容是,将一组冷水机组的运行参数(qload,te_in,te_out,tc_in,tc_out)使用原始训练数据的归一化处理,作为输入向量,利用建立的冷水机组能效比模型预测获得输出数据,经反归一化处理后得到在该运行参数下的冷水机组能效比预测值。
采用上述方案后,本发明可以利用聚类算法对历史运行数据处理,获得支持向量机训练样本;利用支持向量机强大的非线性拟合能力,建立冷水机组能效比模型,可由给定的运行参数提前预测该种工况下的能效比,为运行人员合理设定运行参数、冷水机组高效率运行以及后续协调控制打下基础。
附图说明
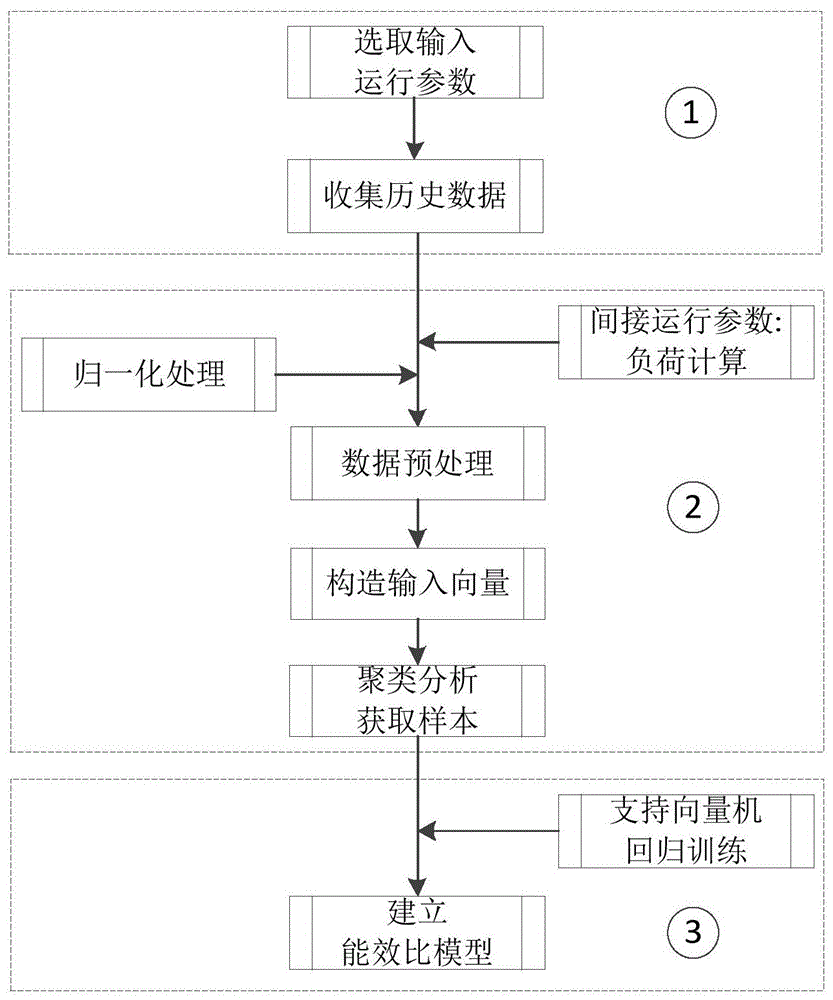
图1是本发明中基于支持向量机的冷水机组模型建模方法示意图;
图2是本发明中利用冷水机组模型预测及控制示意图。
具体实施方式
以下将结合附图,对本发明的技术方案及有益效果进行详细说明。
如图1所示,本发明提供一种基于支持向量机模型的冷水机组高能效控制方法,包括如下步骤:
步骤1,从冷水机组的运行参数中选取对冷水机组能效比影响明显的多种运行参数,例如:蒸发器的进/出口温度、冷凝器的进/出口温度、机组负荷,将这些运行参数作为预测冷水机组能效比的输入参数,采集这些运行参数的历史运行数据,具体来说,蒸发器和冷凝器的进/出口温度均可直接采集,机组负荷可通过将蒸发器侧进/出口温度和冷冻水流量计算来获取,具体如下:
qload=c·q·(te_in-te_out)/3.6/3.517
其中:qload——机组负荷,单位rt
c——水的比热容,值为4.2kj/(kg·℃)
q—冷冻水流量,单位t/h
te_in——蒸发器进口温度,单位℃
te_out——蒸发器出口温度,单位℃
3.6——kg/s与t/h换算系数
3.517——rt与kw换算系数
步骤2,对冷水机组的各个运行参数、能效比的历史数据进行归一化处理,再通过聚类算法获取多组基于支持向量机能效比模型的训练数据;
步骤3,采用支持向量机方法建立冷水机组能效比模型,支持向量机思想是基于学习理论中结构风险最小化准则的一种算法思想,有出色的泛化能力,应用于非线性、多维度的辨识及函数拟合。
在本实施例中,运行参数作为模型的输入,能效比作为模型的输出:
能效比模型的输入参数为:机组负荷qload、蒸发器进口温度te_in、蒸发器出口温度te_out、冷凝器进口温度tc_in、冷凝器出口温度tc_out
能效比模型的目标输出为:冷水机组的能效比eer
能效比eer的计算公式是:
其中:w——机组消耗功率,单位kw
基于支持向量机的冷水机组能效比预测模型可表示为:
eer=f(qload,te_in,te_out,tc_in,tc_out)
本发明的目标是根据多组历史数据的eer和(qload,te_in,te_out,tc_in,tc_out),利用支持向量机方法拟合出上述负荷预测模型。
剔除明显异常的数据后,将所有上述的历史数据进行归一化处理:
其中:x,y∈rn,xmin=min(x),xmax=max(x),经过归一化处理之后,得到n组训练样本集a={a1,a2,···,an},其中ai为一组训练样本,i=1,2,··,n,历史数据的样本数量往往很大,通过聚类算法获得n组聚类中心,作为支持向量回归的训练样本:{ω1,ω2,···,ωn},每组训练样本中同时包含模型输入向量(qload,te_in,te_out,tc_in,tc_out)和目标输出eer。
冷水机组能效比eer与输入向量(qload,te_in,te_out,tc_in,tc_out)之间并不是简单线性关系,需要引入核函数处理该非线性问题。本发明中的支持向量机算法核函数选用径向基核函数(rbf):
其中,σ为核函数宽度系数,σ值越小,径向基核函数的拟合性能越高,泛化能力越差。
支持向量机训练建模是一个函数拟合的过程,引入惩罚因子c表示对拟合误差的宽容度。因此建模过程有径向基核函数的宽度系数σ和训练误差的惩罚因子c两个参数需要通过寻优法确定,最终得到冷水机组能效比的模型:
其中:
步骤4,利用能效比模型提前预测未来某工况下的冷水机组能耗。如图2所示,将一组冷水机组的运行参数(qload,te_in,te_out,tc_in,tc_out)使用原始训练数据的归一化规则处理,作为输入向量
上述基于支持向量机模型的冷水机组高能效控制方法,将历史数据进行归一化及聚类分析等预处理,获得建模样本;合理确定训练参数,利用支持向量机强大的非线性拟合能力,建立冷水机组的能效比预测模型;基于该模型改变运行参数,可以获得在不同设定工况下冷水机组的能效比预测值,以此作为依据合理设定运行参数,使冷水机组始终处于高能效比工况运行,并为后续协调控制打下基础。
以上实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!