一种基于强化学习算法的分布式余压发电系统及其控制方法与流程
本发明涉及余压发电技术领域,具体地讲,涉及一种基于强化学习算法的分布式余压发电系统及其控制方法。
背景技术:
能源作为人类社会发展的原动力和物质基础的保障,是社会发展和技术进步不可或缺的基本条件,是人类生存和发展的重要物质基础。我国能源生产量和消费两均已居世界前列,但在能源利用方式上尚存一系列突出问题:能源结构不合理、能源利用率不高、可再生能源开发利用比例低。这就要求我们着力提高能源开发、转化和利用的效率,推动能源生产和利用方式的变革,加速我国低碳环保,资源节约型社会的建立。近年来,积极循环再利用二次能源已经成为降低能耗、节约能源、降低成本的有效措施。对余压余热的回收利用,则是其中行之有效的重要手段之一。
余压发电技术主要利用天然气或水蒸气在降压降温过程中的压差能量及热能驱动透平膨胀机做功,将其转化为机械能,并由其驱动发电机发电从而实现能量的转换并输出电能。该技术不仅能够做到节能、提高资源利用率,而且对环境不造成任何形式的污染,但是现有余压发电系统中存在供需双方能量不匹配问题。
另外,强化学习是一种重要的机器学习方法。强化学习通过感知环境状态信息来学习动态系统的最优策略,通过试错法不断与环境交互来改善自己的行为,并具有对环境的先验知识要求低的优点,是一种可以应用到实时环境中的在线学习方式,因此在智能控制、机器学习等领域得到了广泛研究,但其在分布式余压发电领域尚未应用。
技术实现要素:
本发明的目的在于克服现有技术中存在的上述不足,而提供一种结构设计合理、供需双方能量匹配的分布式余压发电系统,并提出一种基于强化学习算法的分布式余压发电控制方法。
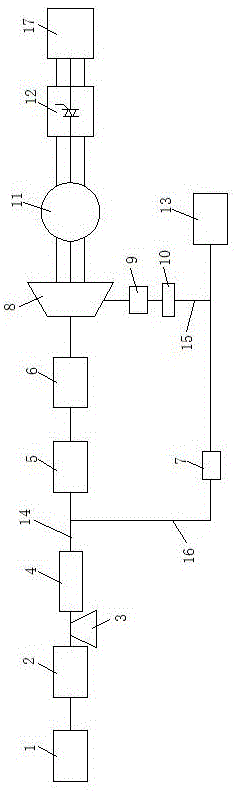
本发明解决上述问题所采用的技术方案是:一种基于强化学习算法的分布式余压发电系统,其特征在于:包括蒸汽管道、透平膨胀机、发电机、变频器和透平出口管路;所述蒸汽管道的输汽末端连接透平膨胀机,所述透平膨胀机与发电机连接,所述发电机与变频器连接,所述变频器与用户或电网连接;所述透平出口管路的一端与透平膨胀机的出口连接,透平出口管路的另一端通往低蒸汽压力用户;所述蒸汽管道上按照输汽方向依次安装有一号电动压力调节阀、流量计、一号电动截止阀和电动流量调节阀;所述透平出口管路上按照输汽方向依次安装有二号电动压力调节阀和背压阀。
优选的,所述蒸汽管道上还安装有疏水阀,所述疏水阀位于一号电动压力调节阀和流量计之间。
优选的,该系统还包括急停旁路,所述急停旁路上安装有二号电动截止阀,所述急停旁路的一端连接在流量计和一号电动截止阀之间的那一段蒸汽管道上,急停旁路的另一端连接在透平出口管路上。
一种基于强化学习算法的分布式余压发电系统的控制方法,其步骤如下:
步骤一:agent控制器读取分布式余压发电系统中一号电动压力调节阀、电动流量调节阀和二号电动压力调节阀的开度ov,读取一号电动截止阀、二号电动截止阀和背压阀的状态;
步骤二:agent控制器读取流量计检测到的流量值q、透平膨胀机前后的蒸汽压力p、蒸汽管道内蒸汽温度t以及发电机的角速度ω;
步骤三:agent控制器利用强化学习算法中的q学习算法控制调节一号电动压力调节阀、电动流量调节阀和二号电动压力调节阀的开度ov,并控制发电机的转速和变频器的输出;
q学习算法中对决策过程的行为值函数估计的迭代计算公式为:
其中,(st,at)为决策过程在t时刻的状态-行为对;st+1为t+1时刻的状态;γ为折扣因子,αt为学习因子;
步骤四:初始化值函数估计中的参数,包括折扣因子γ,学习因子αt,以及决策过程的状态集q(st,at),并设置奖赏值r;
步骤五:观察当前状态st,根据当前状态,按策略选择动作at,并观察下一状态st+1;其中st的状态参数包括蒸汽参数(p、q、t)和用户或电网的电能参数;at包括一号电动压力调节阀、电动流量调节阀和二号电动压力调节阀的阀门开度(ov)以及发电机的角速度ω;
步骤六:根据迭代公式更新当前的状态-行为对的值函数估计q(st,at);
步骤七:判断是否满足学习终止的条件,若满足则结束学习,不满足则令t=t+1,返回步骤五。
本发明与现有技术相比,具有以下优点和效果:分布式余压发电系统解决了供需双方能量不匹配的问题,提高了能源利用率;针对供需双方输出参数不稳定问题,采用强化学习算法,在线动态控制分布式余压发电系统的各个设备,从而达到保证分布式余压发电系统高效稳定运行的目的;此外,本发明的应用,还有利于电厂开拓更广阔的用户市场,使得能源站的负荷增加,燃机系统得以在高效率点运行,从而提高了燃机发电效率,进一步提高系统运行的综合经济性。
附图说明
图1是本发明实施例中分布式余压发电系统图。
图2是标准的agent强化学习模型示意图。
图3是本发明实施例中基于强化学习算法的分布式余压发电控制策略图。
附图标记说明:高蒸汽压力用户1、一号电动压力调节阀2、疏水阀3、流量计4、一号电动截止阀5、电动流量调节阀6、二号电动截止阀7、透平膨胀机8、二号电动压力调节阀9、背压阀10、发电机11、变频器12、低蒸汽压力用户13、蒸汽管道14、透平出口管路15、急停旁路16、用户或电网17。
具体实施方式
下面结合附图并通过实施例对本发明作进一步的详细说明,以下实施例是对本发明的解释而本发明并不局限于以下实施例。
实施例。
参见图1至图3。
本发明实施例为一种基于强化学习算法的分布式余压发电系统,该系统包括蒸汽管道14、透平膨胀机8、发电机11、变频器12、透平出口管路15和急停旁路16。
本实施例中,蒸汽管道14的输汽末端连接透平膨胀机8,透平膨胀机8与发电机11连接,发电机11与变频器12连接,变频器12与用户或电网17连接。透平出口管路15的一端与透平膨胀机8的出口连接,透平出口管路15的另一端通往低蒸汽压力用户13。
本实施例中,蒸汽管道14上按照输汽方向依次安装有一号电动压力调节阀2、流量计4、一号电动截止阀5和电动流量调节阀6。在透平膨胀机8正常工作时,一号电动截止阀5处于打开状态,当透平膨胀机8发生故障时,一号电动截止阀5迅速关闭,以保护透平膨胀机8;电动流量调节阀6通过调节器阀门开度来控制进入透平膨胀机8的蒸汽流量,从而达到调节透平膨胀机8输出功率的目的。蒸汽管道14上还安装有疏水阀3,疏水阀3位于一号电动压力调节阀2和流量计4之间。
本实施例中,透平出口管路15上按照输汽方向依次安装有二号电动压力调节阀9和背压阀10。背压阀10主要用来稳定透平膨胀机8出口压力,从而保证透平膨胀机8出入口具有稳定的压力差;
本实施例中,急停旁路16上安装有二号电动截止阀7,急停旁路16的一端连接在流量计4和一号电动截止阀5之间的那一段蒸汽管道14上,急停旁路16的另一端连接在透平出口管路15上。正常运行时,二号电动截止阀7处于关闭状态,而透平膨胀机8发生故障时,二号电动截止阀7打开,用以泄压泄流,从而达到保护整个余压发电系统内各设备的目的。
本实施例中,变频器12分为电机侧整流器和电网侧逆变器,采用高性能的矢量控制技术,低速高转矩输出,具有良好的动态特性、超强的过载能力。
本实施例中,蒸汽管道14由高蒸汽压力用户1供汽,高蒸汽压力用户1为供方,透平出口管路15的另一端通往的用户为低蒸汽压力用户13,低蒸汽压力用户13为需方,供需两方存在蒸汽压力需求不匹配和供气参数、用户电力需求具有波动性问题,为解决该问题,采用了一种基于强化学习算法的分布式余压发电系统的控制方法。
强化学习就是一个与环境反复交互、反复学习来增强某些决策的过程,这一序贯决策的优化依赖于评价性的反馈信号。其基本原理是:若智能体执行某个行为策略所得到的奖惩是正奖惩,那么智能体在以后的行动中采取这个策略的趋势会加强。
强化学习具有下面三种特征:1、智能体需要主动的对环境做出测试而非静止或被动的;2、环境对于这些试探动作做出的反馈是评价性的;3、智能体在主动试探和获得环境评价这一过程中获得知识,不断的改进和完善行动方案,最终适应环境完成学习任务。
强化学习把学习看成是一种不断试探的过程,标准的agent强化学习模型如附图2所示。智能体不断从环境中接受输入状态s,然后根据内部的一些推理机制,选择一个动作a继续执行。环境状态在动作a的作用下,变更到了一个新的状态s,并给予当前智能体所选择的动作一个评价信号立即回报r奖励或惩罚反馈给智能体,智能体根据评价信号和当前环境状态继续选择下一个动作,每次动作的选择标准是使自身收到的好的回报的概率增加。智能体每一次选择的动作不仅影响到当前获得回报值,而且会对下一时刻的状态甚至于最终的奖赏值有影响。
q学习算法是强化学习算法的一种,其学习的是每个状态—动作对的评价值,即q(st,at),q(st,at)的值是在状态st时根据策略选择动作at并执行,以此类推循环执行得到的累积回报。q学习算法适用于解决含不确定性的控制问题,且算法执行效率与模型的复杂程度相关性较小。
q学习的最优策略是使q(st,at)得累计回报值最大化,因此最优策略可以表示为:
π*(st)=argmaxatq(st,at)
因此智能体只需要考虑当前状态和当前可选的动作,然后按照策略选择使q(st,at)最大化的动作。这样一来智能体只需要对q(st,at)的局部值做出反应就可以找到全局最优的动作序列,也就是说智能体不需要前瞻性的搜索,也不需要考虑下一个可能的状态,就可以选出最优的动作来。
q学习算法所学习的是自己不断探索得来的学习经验,并不需要知道环境模型,所以也不需要知道状态转移函数。在做决策时只需要从q(st,at)表里选出最大值就可以了,从而大大简化了决策的过程。q(st,at)表里的值是一步一步迭代学习的结果。智能体需要不断的与环境交互来充实q(st,at)表,以使其能够覆盖所有可能的情境。当迭代了一段时间后,q(st,at)表里的值不在发生大的变化,则表明结果已收敛。
本发明采用q学习算法控制分布式余压发电系统的各个电动调节阀门、发电机及变频器等设备,使得变频器输出的电能满足分布式用户的电力品质需求。本发明中分布式余压发电系统的供方蒸汽参数、用户的电力需求都属于q学习算法的状态量st,各电动阀门根据智能体的决策进行开度调节属于q学习算法的动作at,q(st,at)学习的是每个状态—动作对的评价值,即在蒸汽参数波动情况下满足分布式用户电力品质需求的状态—动作评价值。经过一段时间的迭代学习,q(st,at)表里的值就会稳定下来,则表明学习结果以收敛,此时便可满足分布式余压发电系统高效稳定运行的目的。
本实施例中,高蒸汽压力用户1的蒸汽参数为2~3mpa压力,200~280℃,蒸汽量为1.5~2.2t/h,到达低蒸汽压力用户13入口处的蒸汽参数为1.8~2.6mpa压力,150~230℃;而低蒸汽压力用户13实际所需供热参数为0.8~1.2mpa压力,150~200℃,蒸汽量1.5~2.2t/h,用户或电网17所需电能为0.38kv,15kw~30kw,此时在低蒸汽压力用户13处安装本余压发电系统,并采用q强化学习算法实时在线控制系统各设备,使得系统输出的电能和热能满足分布式用户的用能需求。
基于强化学习算法的分布式余压发电系统的控制方法的具体步骤如下:
步骤一:agent控制器读取分布式余压发电系统中一号电动压力调节阀2、电动流量调节阀6和二号电动压力调节阀9的开度ov,读取一号电动截止阀5、二号电动截止阀7和背压阀10的状态;
步骤二:agent控制器读取流量计4检测到的流量值q、透平膨胀机8前后的蒸汽压力p、蒸汽管道14内蒸汽温度t以及发电机11的角速度ω;
步骤三:agent控制器利用强化学习算法中的q学习算法控制调节一号电动压力调节阀2、电动流量调节阀6和二号电动压力调节阀9的开度ov,以及控制发电机的转速和变频器的输出;
q学习算法中对决策过程的行为值函数估计的迭代计算公式为:
其中,(st,at)为决策过程在t时刻的状态-行为对;st+1为t1时刻的状态;γ为折扣因子,反映了下一个动作的奖励值对于此次动作的q值的重要性;αt为学习因子,决定了新信息覆盖老信息的程度;
步骤四:初始化值函数估计中的参数,包括折扣因子γ,学习因子αt,以及决策过程的状态集q(st,at),并设置奖赏值r;
步骤五:观察当前状态st,根据当前状态,按策略选择动作at各阀门开度和电机角速度,并观察下一状态st+1;其中st的状态参数包括蒸汽参数p、q、t和用户或电网的电能参数;at包括一号电动压力调节阀2、电动流量调节阀6和二号电动压力调节阀9的阀门开度ov以及发电机的角速度ω;
步骤六:根据迭代公式更新当前的状态-行为对的值函数估计q(st,at);
步骤七:判断是否满足学习终止的条件,若满足则结束学习,不满足则令t=t+1,返回步骤五。
虽然本发明已以实施例公开如上,但其并非用以限定本发明的保护范围,任何熟悉该项技术的技术人员,在不脱离本发明的构思和范围内所作的更动与润饰,均应属于本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!