一种基于GPU的各向异性叠前逆时偏移优化方法与流程
本发明是关于一种应用于地震勘探领域的基于gpu的各向异性叠前逆时偏移优化方法。
背景技术:
逆时偏移作为目前理论上最精确的成像技术,通过求解双程波动方程进行波场延拓,它在对陡倾角界面及强横向变速的复杂构造成像中体现出了明显优势,近年来,该技术受到广泛关注,在gpu的支持下得到了迅速发展,其理论已经成熟,并正逐步应用于生产实践之中。它本身没有偏移孔径和偏移倾角的限制,而在对陡构造成像时往往需要较大的偏移孔径,当选择的偏移孔径较大时,各向异性效应对成像的影响则会变得更不容忽视。这时,必须考虑各向异性才能充分发挥rtm的成像技术优势,从而实现高精度波场归位。经过近几十年的不断发展,各向同性逆时偏移理论已经日趋成熟,并且逐步广泛地应用于实际生产中,取得了较好的成像效果,而gpu技术的引入使计算效率得到了大幅提高。然而,地球各向异性在地下介质中普遍存在,各向同性的偏移方法不能够有效地解决各向异性介质中地震波的偏移成像问题,成像精度受到限制,因此,人们开始关注和探索各向异性逆时偏移技术。另一方面,gpu的发展加快了地震成像技术在实际生产中的应用步伐,已形成了一系列基于gpu平台的偏移技术,如:基于gpu平台的kirchhoff叠前时间偏移,gpu单程波动方程叠前深度偏移,各向同性gpu逆时偏移等。因此,开展基于gpu平台的tti-rtm研究,利用gpu的高度并行计算能力进一步加快各向异性逆时偏移的计算效率,满足实际生产需求。
相对于各向同性逆时偏移,各向异性逆时偏移算法更加复杂,数据量更大.在算法上,各向异性逆时偏移增加了交叉导数项,增加了计算量;在数据上,各向异性逆时偏移需要5个参数,是各向同性逆时偏移参数的五倍.我们知道,gpu的显存空间是有限的,各向异性逆时偏移需要更多的存储空间,这对gpu来说是一个挑战.因此,针对各向异性逆时偏移的特点,如何进行gpu并行优化是一项重要的研究内容。
技术实现要素:
本发明提供一种高效的基于gpu的各向异性叠前逆时偏移(rtm)实现方法。运用本发明方法在gpu上进行各向异性逆时偏移计算可以提高计算效率。
一种基于gpu的各向异性叠前逆时偏移优化方法,包括算法优化和性能优化,所述性能优化包括内存密集型优化、指令密集型优化和延迟密集型优化。
所述算法优化方法包括以下步骤:
(1)、设定两个共享存储器s_pp和s_px以及三个本地寄存器local_px、local_py和local_pxy,
(2)、每个线程分别从共享存储器s_pp中读取数据并计算x-导数,
(3)、每个线程分别从共享存储器s_pp中读取数据并计算y-导数,
(4)、共享存储器s_px存放由共享存储器s_pp中数据计算得出的x-导数,然后再计算y-导数,即得xy-导数。
步骤(2)还包括将所述x-导数存放在局部存储器local_px中;
步骤(3)还包括将y-导数存放在局部存储器local_py中;
步骤(4)还包括将xy-导数存放在局部存储器local_pxy中。
指令密集型优化是通过减少warp或cuda计算单元的计算分支实现的。
所述指令密集型优化是还可以通过采用cuda自带的快速计算函数实现。
延迟密集型计算优化的方法是通过以下步骤实现:
1)循环展开:提高gpu上sm的并行性,有效隐藏数据读取时间;
2)异步流技术实现计算和传输的异步执行。
延迟密集型计算优化的方法还通过全局读优化和全局写优化实现。
全局读优化通过将输入数据和系数合并读入共享存储器再合并输出,设定临时变量,将部分和保存到寄存器中,直到全部写完实现
本发明的优点在于充分利用gpu的高效存储器共享存储器,采用two-pass计算模式,大幅度提高了计算效率。
附图说明
在下文中将基于实施例并参考附图来对本发明进行更详细的描述。其中:
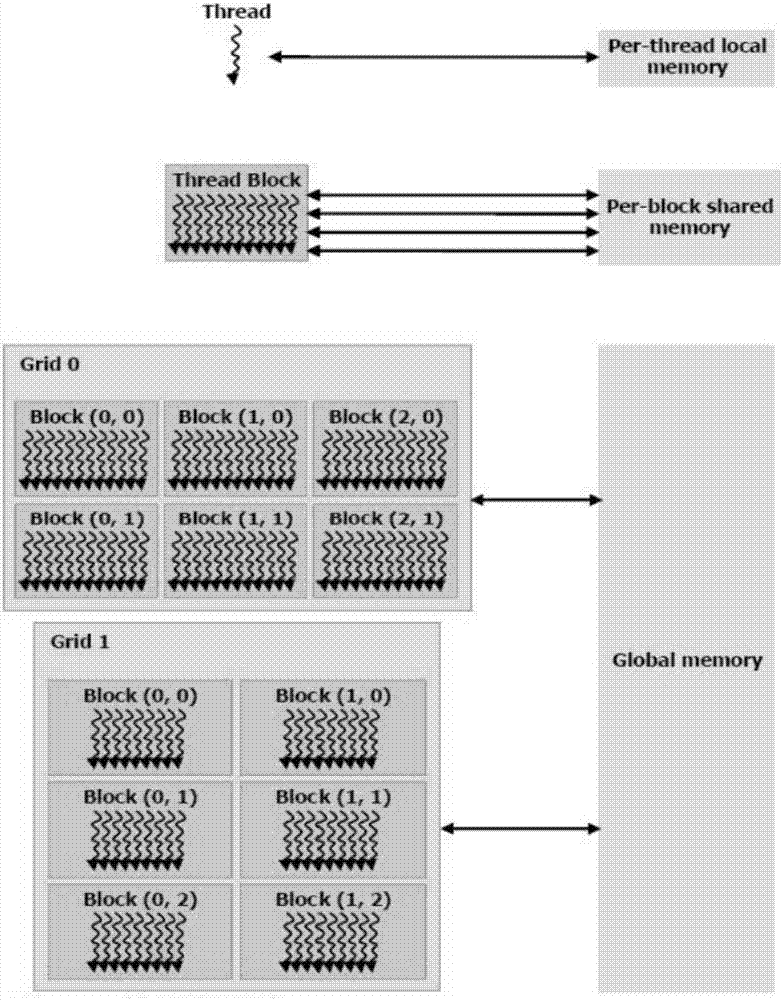
图1是gpu存储器层次示意图;
图2是共享存储器数组分配模式图;
图3是本地存储器数组分配模式图;
图4是模型数据tti介质速度模型图;
图5是各向同性与各向异性偏移结果对比图;
图6是实际资料各向异性参数模型图;
图7实际资料各向同性与各向异性偏移结果对比图;
图8是gpu优化前后时间对比图。
在附图中,相同的部件使用相同的附图标记。附图并未按照实际的比例。
具体实施方式
下面将结合附图对本发明作进一步说明。
1)算法优化
算法优化是对实现方式的优化,为了适应gpu计算做了相应的改进和调整。
gpu具有三个层次的存储器,在执行期间,cuda线程可能访问来自多个存储器空间的数据,如图1所示。每个线程有私有的本地存储器。每个块有对块内所有线程可见的共享存储器,共享存储器的生命期和块相同。所有的线程可访问同一全局存储器。其中,全局存储器的访存速度是最慢的,共享存储器和本地存储器具有快速的数据读写速度。因此本项目着重利用共享存储器和本地存储器对算法进行优化改进。
在算法实现上,tti-rtm算法比iso-rtm算法更加复杂,它增加了交叉导数项。
在gpu的计算中,这部分计算是既复杂又耗时的,为了优化这部分计算,首
先设定两个共享存储器s_pp和s_px和三个本地寄存器local_px、local_py、local_pxy,如图2和图3所示:
计算过程如下:
1)每个线程分别从共享存储器s_pp中读取数据并计算x-导数,放在局部存储器local_px中;
2)每个线程分别从共享存储器s_pp中读取数据并计算y-导数,放在局部存储器local_py中;
3)图中的共享存储器s_px存放由s_pp中数据计算得出的x-导数,然后再计算y-导数,即得xy-导数,放在局部存储器local_pxy中.
通过上述计算可分别得到x-导数、y-导数和xy-导数,并且整体计算效率得到了有效提升。
2)性能优化
在gpu的性能优化中可分为三种类型:内存密集型优化、指令密集型优化和延迟密集型优化。之前的gpu算法优化主要就是针对内存密集进行的性能优化,下面主要从指令密集型和延迟密集型两个方面进行性能优化。
1、针对指令密集型,我们采取的措施减少warp(cuda计算单元)内的计算分支。warp0中所有的线程都执行同样的命令,那么一次就可以完成计算;warp1中有两个指令,那么就要分两次执行才能完成所有线程的计算,显然这种计算是事倍功半的。所以在线程的分配和处理中尽量避免warp1这种类型。
另外,采用一些cuda自带的快速计算函数也可提高计算速度。
2、针对延迟密集型计算的优化主要从两方面开展:
1)循环展开:提高gpu上sm的并行性,有效隐藏数据读取时间;
2)采用异步流技术实现计算和传输的异步执行。gpu计算中可以创建多个流,每个流是按顺序执行的一系列操作,而不同的流与其他的流之间可以是乱序执行的,也可以是并行执行的。这样,可以使一个流的计算与另一个流的数据传输同时进行,从而提高gpu中资源的利用率。
3)全局读优化:将输入数据和系数合并读入共享存储器;
4)全局写优化:合并输出,通过设定临时变量,将部分和保存到寄存器中,直到全部写完。
通过上述两方面优化,将gpu-tti-rtm计算效率提高了三倍以上。
测试模型数据:tti模型采用15m×15m×10m的成像网格,偏移孔径为14000米,总炮数3333炮,每炮道数为81101。速度模型如图4所示,偏移结果如图5所示。可以看出,各向异性tti逆时偏移成像明显优于各向同性iso逆时偏移成像,尤其在盐丘下方弱反射能量区域优势非常明显。表明tti-rtm聚焦更好,波场描述更准确,成像结果更真实。
实际资料选用某三维陆上起伏地表采集的实际数据。该工区成像面积为292km2,总炮数10192炮,每炮道数为2160,记录时间5s,采样2ms,偏移孔径7500米。速度模型如图6所示,偏移结果如图7所示。
gpu优化前后时间对比如图8所示,可以看出采用本方法进行优化使得各向异性叠前逆时偏移计算效率得到了显著提升。
虽然已经参考优选实施例对本发明进行了描述,但在不脱离本发明的范围的情况下,可以对其进行各种改进并且可以用等效物替换其中的部件。尤其是,只要不存在结构冲突,各个实施例中所提到的各项技术特征均可以任意方式组合起来。本发明并不局限于文中公开的特定实施例,而是包括落入权利要求的范围内的所有技术方案。
- 还没有人留言评论。精彩留言会获得点赞!