机器人声源定位学习中视觉示教声源角度的方法与流程
本发明涉及人机交互技术,特别涉及一种机器人声源定位学习中的视觉示教声源角度的方法,即利用视觉方式提供机器人声源定位学习中所需的声源角度的方法。
背景技术:
声源定位对于提高机器人的环境感知和理解以及友好的人机交互能力具有重要意义。现有的机器人声源定位方法主要有基于双耳的方法和基于阵列的方法两大类。这些声源定位方法大多是依据麦克风的几何位置关系以及对声学环境的各种假设,人工构造声源定位函数。为了使得构造出的声源定位方法可解或者减少计算量,必须进行多种假设,例如近场模型、远场模型、窄带信号等。由于这些假设与实际应用环境不相符,且无法综合考虑机器人声源定位中的多种约束,导致机器人声源定位的性能无法满足实用要求。
如果能够利用机器学习的方法以在线学习方式得到声源定位函数,将能够解决声源定位过程中由于定位函数所引入各种假设造成的定位性能下降问题。但是,以学习方式得到某种函数的前提是具有示教条件。针对机器人声源定位学习问题中的声源角度示教问题,本发明利用视频示教的方式来提供声源角度。
技术实现要素:
本发明的目的在于提供一种声源定位学习中的视觉示教声源角度的方法。
本发明的目的是这样实现的:
一种机器人声源定位学习中视觉示教声源角度的方法,其特征在于,包括如下步骤:
(1)将具有云台的摄像机安装在机器人平台上,使得云台的方位角为0°时,摄像机的视线方向与机器人正前方重合,云台的俯仰角为0°时,摄像机的视线方向与水平面间的角度为0°;
(2)在机器人平台上安装M个麦克风,构成麦克风阵列以拾取声音信号,至少存在一个麦克风与其它麦克风中的至少一个位于不同平面,其中M>3;
(3)构造视觉示教板,该视觉示教板上具有易于识别的规则平面几何图形,在所述规则平面图形的几何中心安装一个点声源;
(4)构造一个能够学习非线性函数的学习机,该学习机具有I个输入,I是从M个不同的麦克风中取出2个麦克风的组合数,该学习机具有2个输出,分别对应点声源的方位角和俯仰角;
(5)选定一个需要示教的空间位置,令视觉示教板具有规则平面几何图形的一面朝向摄像机,控制摄像头的云台运动,令视觉示教板的规则平面几何图形的几何中心位于摄像头感知区域的中心,此时云台的方位角β和俯仰角γ看作是声源相对于机器人的方位角和俯仰角;
(6)令位于规则几何图形中心的点声源持续发声,利用数据采集卡对各麦克风感知到的信号进行采样,令采样点数为N点,记第i个麦克风所采集到的声音信号序列为si[n],0≤i≤M-1,0≤n≤N-1;
(7)从M个不同的声音信号序列中取出2个不同的序列Si[n]和Sj[n],计算它们之间的时延τij,τij的数目与I相同;
(8)将I个时延τij作为学习机的输入,方位角β和俯仰角γ作为目标值,构成训练样本对学习机进行训练;
(9)重复步骤(5)-(8),直至任务结束。
由于采用上述技术方案,本发明提供的一种声源定位学习中的视觉示教声源角度的方法,与现有技术相比具有这样的有益效果:
机器人具有声源定位能力对于提高机器人的环境感知能力和人机交互能力具有重要意义。现有的声源定位方法,大多数需要对声学环境做出某些假设,另外,从计算的可行性方面考虑,对麦克风的拓扑结构有较为严格的限制。利用视觉示教声源位置的方法,可以忽略上述约束,而是通过机器学习的方式来获得声源定位函数,可以提高机器人对声源的定位精度。
附图说明
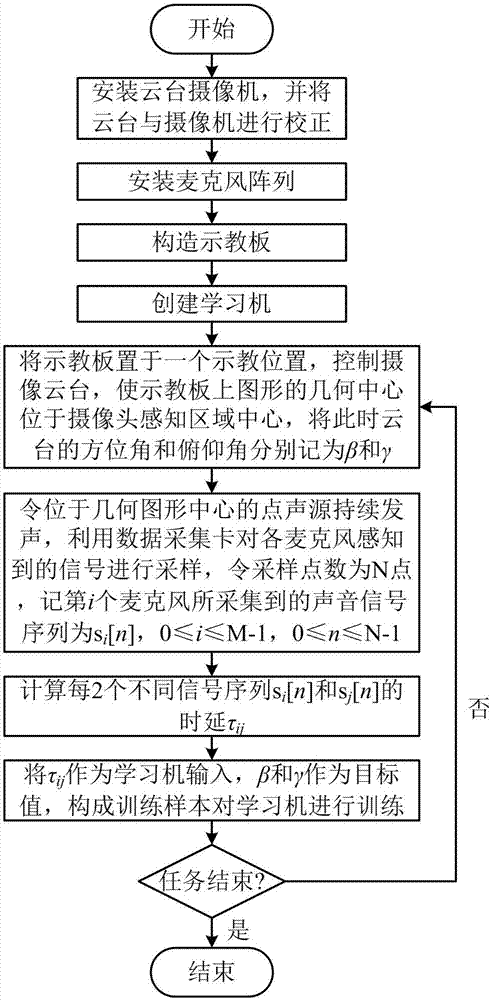
图1是机器人声源定位学习中视觉示教声源角度方法流程图。
图2是示教板示意图。
图3是学习机示意图。
具体实施方式
下面结合附图举例对本发明做详细的描述:
一种机器人声源定位学习中视觉示教声源角度的方法,其实施例流程图如图1所示,现根据图1对本发明方法做详细说明如下:
(1)将具有云台的摄像机安装在机器人平台上,使得云台的方位角为0°时,摄像机的视线方向与机器人正前方重合,云台的俯仰角为0°时,摄像机的视线方向与水平面间的角度为0°;
(2)在机器人平台的合适位置上安装M个麦克风,不能所有的麦克风都位于同一平面中,构成麦克风阵列以拾取声音信号,其中M≥3;
(3)构造视觉示教板,该示教板上具有易于识别的规则平面几何图形,在平面图形的几何中心安装一个点声源,示教板示意图如图2所示;
(4)构造一个能够学习非线性函数的学习机,该学习机具有I个输入,I是从M个不同的麦克风中取出2个麦克风的组合数,即I=C(M,2),该学习机具有2个输出,分别对应声源的方位角和俯仰角,学习机示意图如图3所示;
(5)选定一个需要示教的空间位置,令示教板具有几何图形的一面朝向摄像机,控制摄像头的云台运动,令示教板的几何图形的几何中心位于摄像头感知区域的中心,此时云台的方位角β和俯仰角γ可以看作是声源相对于机器人的方位角和俯仰角;
(6)令位于几何图形中心的点声源持续发声,利用数据采集卡对各麦克风感知到的信号进行采样,令采样点数为N点,记第i个麦克风所采集到的声音信号序列为si[n],0≤i≤M-1,0≤n≤N-1;
(7)从M个不同的声音信号序列中取出2个不同的序列Si[n]和Sj[n],计算它们之间的时延τij,τij的数目与I相同;
(8)将I个时延τij作为学习机的输入,方位角β和俯仰角γ作为目标值,构成训练样本对学习机进行训练;
(9)重复步骤(5)-(8),直至任务结束。
以上所述,仅为本发明创造较佳的具体实施方式,但本发明创造的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明创造披露的技术范围内,根据本发明创造的技术方案及其发明构思加以等同替换或改变,都应涵盖在本发明创造的保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!