一种基于在线字典更新的地震信号编码方法与流程
本发明属于地震信号数据传输方法,具体涉及一种地震信号有损编码方法。
背景技术:
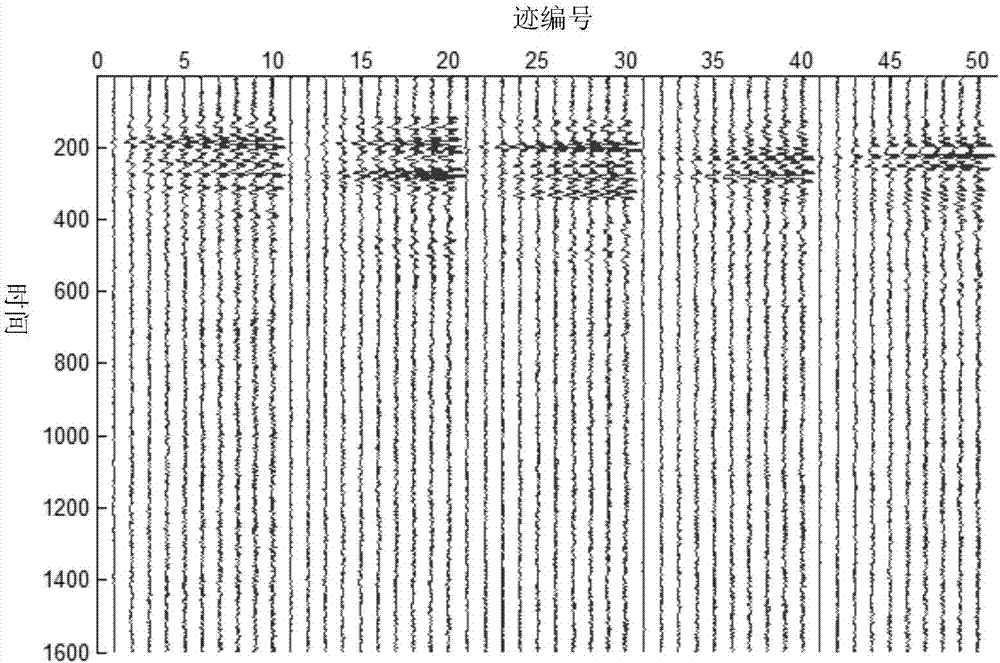
:基于地震信号测量的测绘技术是目前地底结构和矿产资源测量的有效方法之一。在每次测绘时,对地底进行地震信号测量将会产生超过100t以上的数据,而目前信号传输的带宽极为有限,因此有必要在传输前通过地震信号编码技术减少地震信号的数据量。现有技术中,提出了一种基于离散余弦变换的地震信号编码方法,它能够获得接近于3倍的压缩倍数。也有采用二维基于局部地震信号自适应的离散余弦变换技术,使得重建后的地震信号重要特征能够得以保存。更进一步地,采用自适应小波包的地震信号编码技术可以获得更高的压缩倍数和更好的重建质量由于其较好的方向保持特性,目前被广泛应用于地震信号的特征提取中。上述方法的主要思想是采用一种合适的基或者冗余的字典来表征地震信号,使得信号的表征是稀疏的。近年来,通过字典学习进行稀疏表示获得了广泛地关注,尤其是在图像编码中得到了广泛的应用在遥感图像中通过双稀疏模型去学习字典,从而获得了较好的编码效果。这些研究成果均表明了在地震信号编码中应用字典学习和稀疏表示的可行性。传统基于字典学习和稀疏表示的编码方法往往包含如下两种主要方法:(1)通过离线学习的字典对实时获取的在线数据进行稀疏表示。对于该方法而言,预先需要存在一个离线训练集,并通过该离线训练集去获得所需的字典信息。因此,在线数据的稀疏表示是否有效极度依赖于离线数据和在线数据的相关性。对于实际地震信号测量而言,很难获得适用于不同情况的通用离线训练集。(2)使用实时在线数据训练字典,通过该字典对实时在线数据进行稀疏表示。在该方法中,有必要对字典进行传输,从而使得编解码端的稀疏表示过程能够同步。因此,字典信息的传输将会增加编码码流的大小,从而降低编码性能。技术实现要素::本发明提出一种基于在线字典更新的地震信号编码方法,属于地震信号数据编码传输方法,解决地震信号编码中采用字典学习和稀疏表示带来的如何传输字典的问题,可以应用于各种基于地震信号测量的地底测绘中。本发明的一种基于在线字典更新的地震信号编码方法,包括编码步骤和解码步骤;其中,所述编码步骤包括:步骤1、将输入地震信号按照时间顺序分成多个组,对每组数据采用缓存中的字典进行稀疏编码,具体是:步骤11、将近临t个迹的地震信号数据分为一组,对每组数据单独进行处理;假设当前组数据为z组数据,其表示为yz;将每个迹的数据等分为若干个单元,每个单元yi的长度为m×1,将yi按照列方式进行排序;因此,yz=[y1,...yi,...yn];这里假设每个迹上记录的数据长度为u,那么有如下关系式:t×u=m×n;步骤12、读取缓存中的字典dz-1,给定稀疏系数矩阵wz的稀疏性为l,对下式进行优化求解:步骤2、对步骤s1中的稀疏系数进行量化及熵编码,具体包括:步骤21、采用均匀量化方法对稀疏系数矩阵进行量化,具体如下:wz(i,j)代表稀疏系数矩阵wz中坐标为(i,j)的系数数值,δ代表量化步长,代表(i,j)的系数数值的量化结果,round(·)代表取整运算;步骤22、创建由数值0和数值1组成的非零系数位置矩阵pt,创建方法如下:其中,abs(·)代表绝对值运算;步骤23、对非零系数位置矩阵pt采用算术编码;步骤24、对非零系数(对应于pt(i,j)=1位置的采用huffman编码;步骤3、从缓存中读取前面p个已传输组的重建数据,结合当前组传输的稀疏系数进行字典学习,从而更新下一组数据稀疏表示所需的字典,具体包括:步骤31、计算p+1组重建数据p∈[z-p,z](当前组数据是z组),计算方法如下:其中,中的单元步骤32、按照如下优化过程求解所需字典dz:其中,ai代表描述组间相关性的常数,式(2)通过如下步骤迭代运算求解:步骤321、固定dz,w'可以通过前面所述的ps方法进行计算;步骤322、固定w',dz可以按照mod方法进行更新:步骤323、重复上述步骤321和步骤322至指定迭代次数,更新所需的字典dz;所述解码步骤包括:步骤4、对接收到的稀疏系数进行反量化及熵解码,生成非零系数矩阵w'z,具体如下:步骤41、对非零系数编码码流进行huffman解码,获得非零系数wc;步骤42、对非零系数wc进行反量化,获得反量化系数w'c,具体如下:w'c=wc×δ步骤43、对非零系数位置矩阵pt编码码流进行算术解码,获得非零系数位置矩阵pt,结合步骤42中生成的反量化系数w'c,生成非零系数矩阵w'z;步骤5、进行地震信号重建,具体如下:步骤51、读取缓存中的字典dz-1,生成重建信号y'z,具体如下:y'z=dz-1×w'z步骤52、对重建信号y'z=[y'1...y'i...y'n](每个单元y'i的长度为m×1)进行重排列,将临近若干个单元按照列的方式首尾连在一起拼成一迹,因此,每迹的长度为总共有t迹;步骤6、生成缓存中的字典dz,用于下一组数据的重建,即:从缓存中读取前面p个已传输组的重建数据,结合当前组传输的稀疏系数进行字典学习,从而更新下一组数据稀疏表示所需的字典,具体包括:步骤61、计算p+1组重建数据p∈[z-p,z](当前组数据是z组),计算方法如下:其中,中的单元步骤62、按照如下优化过程求解所需字典dz:其中,ai代表描述组间相关性的常数,式(2)通过如下步骤迭代运算求解:步骤621、固定dz,w'可以通过前面所述的ps方法进行计算;步骤622、固定w',dz可以按照mod方法进行更新:步骤623、重复上述步骤321和步骤322至指定迭代次数,更新所需的字典dz。本发明通过在线字典更新的方式,在保证信号有效稀疏表示的前提条件下,并不需要实时传输字典信息,从而有效减少数据传输数据量,可以适用于各种地震信号高速采集应用场合。附图说明图1是本发明的流程图;图2是测试地震信号数据中的部分信号;图3是学习的字典;图4是不同方法性能对比的结果。具体实施方式实施例:本发明主要包括:s1:将输入地震信号按照时间顺序分成多个组,对每组数据采用缓存中的字典进行稀疏编码;s2:对步骤s1中的稀疏系数进行量化及熵编码;s3:从缓存中读取前面p个已传输组的重建数据,结合当前组传输的稀疏系数进行字典学习,从而更新下一组数据稀疏表示所需的字典。更进一步地,步骤s1具体为:s11:将近临t个迹的地震信号数据分为一组,对每组数据单独进行处理;假设当前组数据为z组数据,其表示为yz。将每个迹的数据等分为若干个单元,每个单元yi的长度为m×1,将yi按照列方式进行排序。因此,yz=[y1,...yi,...yn]。这里假设每个迹上记录的数据长度为u,那么有如下关系式:t×u=m×n。s12:读取缓存中的字典dz-1,给定稀疏系数矩阵wz的稀疏性为l,对下式进行优化求解:对于式(1)的求解,我们拟采用ps方法(“partialsearchvectorselectionforsparsesignalrepresentation,”innorsig-03)。ps方法是基于omp算法(正交匹配追踪,“comparisonofbasisselectionmethods,”insignals,systemsandcomputers,1996.conferencerecordofthethirtiethasilomarconferenceon),因此,首先给出omp算法的流程:ps方法将上述步骤(1)仅仅对最大相关性字典单元的搜索过程修改为对若干个极大相关性字典单元的搜索,从而提供更多的搜索判决获得较佳的稀疏向量。步骤s2具体为:s21:采用均匀量化方法对稀疏系数矩阵进行量化,具体如下:wz(i,j)代表稀疏系数矩阵wz中坐标为(i,j)的系数数值,δ代表量化步长,代表(i,j)的系数数值的量化结果,round(·)代表取整运算。s22:创建由数值0和数值1组成的非零系数矩阵pt,创建方法如下:其中,abs(·)代表绝对值运算。s23:对非零系数矩阵pt采用算术编码。s24:对非零系数(对应于pt(i,j)=1位置的wri,j)采用huffman编码。步骤s3具体为:s31:计算p+1组重建数据p∈[z-p,z](当前组数据是z组),计算方法如下:其中,中的单元s32:按照如下优化过程求解所需字典dz:其中,ai代表描述组间相关性的常数。式(2)可以通过如下步骤迭代运算求解:1)固定dz,w'可以通过前面所述的ps方法进行计算;2)固定w',dz可以按照mod方法(“methodofoptimaldirectionsforframedesign,”in1999ieeeinternationalconferenceonacoustics,speechandsignalprocessing(icassp))进行更新:3)重复上述步骤1)和步骤2)至指定迭代次数,生成所需的更新字典dz。实施例1:1.测试地震信号数据来源于utam图像数据库(http://utam.gg.utah.edu/seismicdata/seismicdata.html),我们选用find-trapped-miners数据作为测试数据,它包含72个传感器,每个传感器包含135个迹;2.每个迹取1600个时间长度样本,每10个迹的数据为1组,部分测试数据如图1所示;1.假定当前组是第3组(前2组数据均已完成编码且相关数据已输出到解码端和缓存中),读取缓存中的字典d2进行稀疏编码,在该实施例中缓存中字典的大小均为16×64,稀疏性为1/16(非零系数占总体系数的比例),计算获得的w3中部分数据如下;0000000000000191086.6900000000069516.63000000000000000000263371.0300000-275961.58248225.2100000000000000000000002.对w3进行量化,量化步长选用1024;对量化后中的非零数据采用huffman编码,对非零元位置采用算术编码,我们通过snr来衡量原始信号和重建信号的差异,此时的snr是21.2db。3.通过读取前两组重建数据和w3,进行字典更新,所更新的字典d3如图3所示。实施例2:1.对第四组数据用第三组数据更新的字典d3进行稀疏表示,并更新字典d4;2.对第五组数据用第四组数据更新的字典d4进行稀疏表示,并更新字典d5;3.对上述每组数据进行量化及编码,计算码率并通过snr衡量失真;4.调整不同稀疏性,重复上述3个步骤,得到不同码率下的失真情况。5.为了证明算法的有效性,我们同时对基于dct,curvelet和离线字典学习方法(k-svd+ormp)的地震信号编码算法进行了实验,得到不同算法的率失真情况,相关对比实验结果如图4所示。本技术中所描述的具体实施例仅仅是对本发明精神作举例说明。本发明所属
技术领域:
的技术人员可以对所描述的具体实施例做各种各样的修改或补充或采用类似的方式替代,但并不会偏离本发明的精神或者超越所附权利要求书所定义的范围。当前第1页12
相关技术
网友询问留言
已有0条留言
- 还没有人留言评论。精彩留言会获得点赞!
1