含分布式电源配电网的故障定位方法与流程
本发明含分布式电源配电网的故障定位方法属于电力系统故障检测技术领域,特别是一种适用于含分布式电源配电网的故障定位新方法。
背景技术:
随着分布式电源的不断接入,传统配电网拓扑结构从单电源辐射状网络变成复杂的多电源网络,目前,基于FTU(Feeder Terminal Unit,馈线终端设备)采集的故障电流信息进行配电网故障定位,主要的方法是矩阵算法、遗传算法。矩阵算法要求故障信息的准确性很高,容错性较差,使其难以得到广泛应用。而遗传算法虽有充分的研究,在许多优化问题中都有成功的应用,但其本身也存在一些不足,例如局部搜索能力差、存在未成熟收敛和随机漫游等现象,从而导致算法的收敛性能差,需要很长时间才能找到最优解。
技术实现要素:
本发明的目的在于针对上述不足之处提供一种含分布式电源配电网的故障定位方法,克服了传统矩阵算法和遗传算法的缺点,能够对含分布式电源的配网进行快速、有效的故障定位。
本发明是采取以下技术方案实现的:
含分布式电源配电网的故障定位方法,包括以下步骤:
(1)对故障电流进行编码;
(2)仿照生物免疫系统,针对电网拓扑结构进行初始抗体编码;
(3)构造开关函数,计算抗原;
(4)计算抗体与抗原之间的匹配度;
(5)计算抗体与抗体之间的亲和度以及抗体浓度;
(6)根据抗体之间的亲和度和抗体浓度计算抗体的期望繁殖概率;
(7)根据抗体的期望繁殖概率进化产生新的抗体,循环步骤(3)-(7);
(8)根据收敛判据,输出最优抗体,译码确定故障线路。
进一步地,步骤(1)的具体过程如下:
对每一个开关,设定距离该开关最近的电源为其上游电源,而其他电源为其下游电源,设定从该开关的上游电源到下游电源为该开关的正方向,当馈线终端设备检测到的故障过流方向与开关的正方向相同,则开关的状态值置1,如果故障过流方向与开关正方向相反,则开关的状态值置-1,如果馈线终端设备未检测到故障过流,则开关的状态值置0,从而完成状态编码。
进一步地,步骤(2)的具体过程如下:
利用免疫算法进行故障定位时,抗体为配电网中所有馈线区段的状态形成的向量,抗体由基因构成,每位基因对应某一馈线区段的状态,基因置1 表示对应的馈线区段发生故障,基因置0表示对应的馈线区段故障未发生故障。
进一步地,步骤(3)的具体过程如下:
对于每一个开关,定义开关与其上游电源之间的线路为该开关的上游线、开关与其下游电源之间的线路为该开关的下游线,然后构造开关函数:
上式中,是第 j个分段开关的开关函数 ,为单个抗体;是第j个分段开关上游线中第u个馈线区段的状态,故障状态置1,正常状态置0;是第j个分段开关下游线中第u个馈线区段的状态,故障状态置1,正常状态置0;表示第j个分段开关上游线各个馈线区段的状态逻辑或运算,M1是第j个分段开关上游线馈线区段的数目;表示第j个分段开关下游线各个馈线区段的状态逻辑或运算;是第j个分段开关下游线馈线区段的数目;表示第i个分布式电源是否并网运行,并网运行时,置1,未并网运行时,置0,N为分布式电源的数目。
进一步地,步骤(4)的具体过程如下:
首先构造评价函数:
上式中,为抗体群中每个抗体所对应的评价函数;表示抗体的每一位基因;N1为配电网中开关的总数;N2为配电网中馈线区段的总数;Ij为步骤(1)得到的各开关的状态编码;
然后计算抗体和抗原之间的匹配度:
上式中,表示抗体和抗原之间的匹配度。
进一步地,步骤(5)的具体过程如下:
计算抗体与抗体间的亲和度:
上式中,是抗体v和抗体s中处在相同基因位置且基因相同的位数;L为抗体的长度;
计算抗体浓度,即抗体群中相似抗体所占的比例:
上式中,Cv是抗体浓度,,e为抗体亲和度评价参数,M为抗体总数。
进一步地,步骤(6)的具体过程如下:
计算抗体的期望繁殖概率:
上式中,Pv为抗体的期望繁殖概率,表示所有抗体的亲和度总和,表示所有抗体的抗体浓度总和,为权重,。
进一步地,在步骤(8)中,所述收敛判据为期望繁殖概率最大的抗体在进化过程中保持代数超过所设置的值以及免疫算法不再进化。
进一步地,设定抗体的保留阈值,设置记忆库,采用优秀个体保留策略,在进化过程中,将期望繁殖概率大于保留阈值的抗体保留到记忆库中。
采用上述技术方案带来的有益效果:
本发明设计的故障定位方法基于免疫算法,利用免疫系统的多样性产生和维持机制来保持群体的多样性,克服了一般寻优过程的早熟问题,最终求得全局最优解,克服了传统基于矩阵算法或遗传算法的故障定位方法的各种缺点,实现对配电网的精确快速故障定位。
附图说明
图1是本发明的流程图。
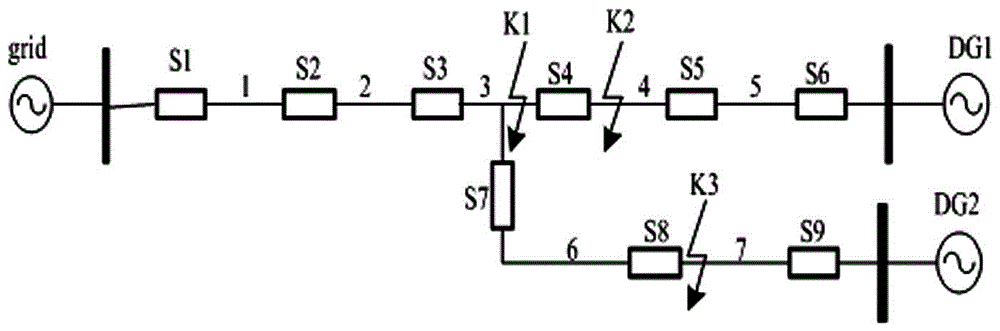
图2是实施例的含DG的配电网的简化图。
具体实施方式
以下将结合附图,对本发明的技术方案进行详细说明。
含分布式电源配电网的故障定位方法,如图1所示,包括以下步骤:
步骤1:对故障电流进行编码。
对每一个柱上开关,首先规定距离开关最近的电源为其上游电源,而其他电源为其下游电源。且规定从其上游电源到下游电源为开关的正方向。当FTU检测到的故障过流方向与假定的正方向开关一致,开关状态值Ij=1。如果过电流方向与假定的正方向相反,则Ij=-1。如果FTU没有监测到过电流,则Ij=0。
如图2所示配电网结构图,对于开关S1、S2和S3,其上游电源为电网电源,其下游电源为DG1和DG2。同样,对于开关S4、S5和S6,其上游电源为DG1,下游电源为电网电源和DG2。对于开关S7、S8和S9,其上游电源为DG2,下游电源为电网电源和DG1。
以S4为例,对于S4其正方向是从其上游电源DG1到下游电源电网电源和DG2。当K1处发生短路故障,流过S4的故障电流由分布式电源DG1提供并且故障电流的方向与假定的正方向一致,故S4的故障状态之为‘1’。当K2处发生故障,流过S4的故障电流由电网电源和分布式电源DG2提供并且故障电流的方向与假定的正方向相反,故此时S4的故障状态之为‘-1’。其它开关的状态值确定方法与S4类似。
步骤2:仿照生物免疫系统,针对电网拓扑结构进行初始抗体编码。
配电网故障定位中,馈线区段状态为待求量,利用免疫算法进行故障定位时,基因对应单一馈线区段的状态,抗体由基因构成,即配电网中所有馈线区段的状态形成的向量。本文采用二进制编码形式,抗体的长度由馈线区段数决定,抗体的每一位基因对应馈线区段的状态,1表示该馈线区段故障,0表示没有故障。例如,在图2中当K1发生故障,此时的抗体编码为 [0 0 1 0 0 0 0]。
步骤3:构造开关函数,计算抗原。
对于某一个开关来说,定义开关和上游电源之间的线路为该开关的上游线。同理,其下游线路为该开关与其下游电源之间的馈线。不同于传统的单电源辐射性供电系统,在分布式发电系统中,通过开关的电流与每一个供电电源都有关系。因此,本文定义了一个新的开关功能,如式(1)所示:
(1)
上式中,是第 j 个分段开关的开关函数 。是j号开关上游馈线的状态Sjd是j号开关下游馈线的状态。当线路发生故障值为1,正常运行值为0。是开关j的上游线路故障状态逻辑或运算。是开关j的下游线路故障状态逻辑或运算。表示着分布式电源(DG)是否并网运行。当DG并网运行,其状态代码为‘1’,如果没有,代码为‘0’。当没有DG 并入配电网系统中,此时和传统单电源辐射性配电网系统的开关函数一样。因此,新的开关函数能够适应网络拓扑结构的改变。
步骤4:计算抗体与抗原之间的匹配度。
抗体与抗原亲和度计算的关键在于评价函数的构造,评价函数是基于通过馈线区段状态确定的馈线开关的状态与 FTU 实际上传的电流越限信息的差别最小来构造的。本发明采用的评价函数如式(2)所示:
(2)
上式中,Fit(SB)为抗体群中每个抗体所对应的适应度函数,即评价函数对可行解的评价值;SB为单个抗体,即所有馈线区段状态组成的解向量,SB(i)表示抗体的每一位基因,对应着配电网中各馈线的状态,取值为1表示故障状态,取值为0表示正常状态;N1为配电网中开关的总数;N2为配电网中馈线区段的总数;Ij为配电网中馈线的故障状态编码;则开关函数,由式(1)确定。比如开关S1下游有馈线区段 a和馈线区段 b,则,只要馈线区段a、b的状态有一个为1,则为1。
抗体和抗原之间的匹配度如式(3)所示:
(3)
上式中,表示最小优化问题的评价函数;Av用来表示抗体与抗原之间的匹配程度,反映了初始解或者迭代过程中产生的可行解的优良,Av越大,该可行解越好,Av越小,该可行解越差。
步骤5:计算抗体与抗体之间的亲和度以及抗体浓度。
抗体与抗体之间的亲和度反映了可行解与可行解之间的相似程度。此处采用R位连续计算抗体与抗体之间的亲和度。两种抗体有超过R位或者连续R位编码相同,则表示两种抗体近似“相同” ,否则表示两种抗体不同,即:
(4)
上式中,kv,s是抗体v和抗体s中处在相同基因位置且基因相同的位数;L为抗体的长度。越大,则两个抗体越相似;反之,越不相似。
抗体浓度 Cv即抗体群中相似抗体所占的比例,反应了抗体群的多样性,计算公式:
(5)
(6)
上式中,e为抗体相似度评价参数;Hv,s表示两个抗体是否相似,是,取1,否,取 0;M为抗体总数。
步骤6:根据抗体之间的亲和度和抗体浓度计算抗体的期望繁殖概率。
在抗体群中,每个抗体的期望繁殖概率由抗体与抗原之间的亲和度和抗体浓度两部分共同决定,这是与遗传算法的主要区别,即:
(7)
上式中,表示所有抗体的亲和度总和,表示所有抗体的抗体浓度总和,为权重,优选值为0.95。
步骤7:根据抗体的期望繁殖概率进化产生新的抗体,循环步骤3-7。
由式(7)可见,抗体与抗原亲和度Av越大, 则期望繁殖率Pv越大,被选择作为交叉、变异个体的可能性越大;抗体浓度Cv越大,则期望繁殖率Pv越小,被选择作为交叉、变异个体的可能性越小。这样既促进了与抗原亲和度高的抗体,同时也抑制了浓度高的抗体,从而确保了抗体的多样性。
免疫算法在抑制高浓度抗体时,与抗原亲和度较高的抗体可能会因为其浓度高而受到抑制,从而导致已求得的最优解丢失,因此采用优秀个体保留策略,增加记忆库,在每次更新记忆库时,将期望繁殖概率值较高的若干个体存入记忆库。同时记忆库的创建也避免了交叉、变异过程使群体退化的发生。
步骤8:根据收敛判据,输出最优抗体,译码确定故障线路。
算法终止的判据是抗体群中最优个体的最少保持代数,即在进化过程中对应期望繁殖度最大的个体在进化过程中保持代数超过所设置的值及免疫算法不再进化时,判定算法收敛。根据步骤2的抗体编码原则,在最优抗体中,对应线路编码为1的即为故障线路。例如,算法最后确定的最优抗体为[0 0 0 0 1 0 0...],则可以判定5号线路发生故障。这种判据充分利用了免疫算法在进化过程中的知识积累,可适应复杂程度不同的配电网,提高收敛效率。
实施例仅为说明本发明的技术思想,不能以此限定本发明的保护范围,凡是按照本发明提出的技术思想,在技术方案基础上所做的任何改动,均落入本发明保护范围之内。
- 还没有人留言评论。精彩留言会获得点赞!