基于自加权变量组合集群分析的近红外光谱变量选择方法与流程
本方法发明属于分析化学领域的无损分析技术领域,具体涉及基于自加权变量组合集群分析的近红外光谱变量选择方法。
背景技术:
随着近红外光谱技术和化学计量学的发展,变量选择技术已经成为了近红外光谱分析高维度数据领域的关键环节,对光谱变量进行变量选择可以提高预测模型的预测能力。降低光谱数据维度和增强预测模型的可解释性。同时,变量选择也是一个非常具有挑战性的问题,随着变量空间的增大找到一组最佳的变量组合是一个非常困难的问题。
国内外常见的变量选择方法有无信息变量消除法(uninformativevariableseliminationuve,参见张巧杰熊鸣祁鲲无信息变量消除法在糙米直链淀粉波长选择中的应用光谱仪器与分析2005-10-15)、蒙特卡洛无信息变量消除法(montecarlobaseduve,mc-uve,参见w-scai,y–kli,x-gshao,avariableselectionmethodbasedonuninformativevariableeliminationformultivariatecalibrationofnear-infraredspectra[j],chemometr,intell.lab.syst.2008,90,188-194)、遗传学算法(geneticalgorithm,ga,参见leardir,gonzalezal,geneticalgorithmsappliedtofeatureselectioninplsregression:howandwhentousethem,chemomintelllabsyst,1998,41,195-207)等。随着mpa思想的发展,一些新的变量选择方法如:随机蛙跳法(randomfrog,rf,参见朱逢乐何勇邵咏妮应用近红外高光谱成像预测三文鱼肉的水分含量光谱学与光谱分析2015-1,113-117)、迭代保留有信息变量法(iterativelyretainsinformativevariablesiriv,参见yong-huanyun,wei-tingwang,min-litan,yi-zengliang,hong-dongli,dong-shengcao,hong-meilu,qing-songxu,astrategythatiterativelyretainsinformativevariablesforselectingoptimalvariablesubsetinmultivariatecalibration,anal.chim.acta,2014,807,36-45)、竞争自适应重采样法(cars,参见h-dli,y-zliang,q-sxu,d-scao,keywavelengthsscreeningusingcompetitiveadaptivereweightedsamplingmethodformultivariatecalibration,anal.chim.acta,2009,648,77-84)和变量组合集群分析法(variablecombinationpopulationanalysisvcpa,参见yong-huanyun,wei-tingwang,bai-chuandeng,guang-bilai,xin-boliu,da-bingren,yi-zengliang,weifan,qing-songxu,usingvariablecombinationpopulationanalysisforvariableselectioninmultivariatecalibration,anal.chimacta,2015,862,14-23)等被提出。然而对于变量的重要性通常采用信息向量(ivs)来判定,常见的信息向量有偏最小二乘回归系数(reg)、相关系数向量(cor)、残差向量(res)、投影变量重要性向量(vip)、净信号向量(nas)、信噪比向量(stn)、协方差向量(cov)、选择比向量(sr)、预测残差向量(ssr)、变量出现频率(fre)和协方差向量(covsel)等。
虽然大量的变量选择方法被提出,但是每一种变量选择方法都只采用这些信息向量中的一种作为变量重要性判断依据,进而忽略了其他信息向量对预测模型的影响,因此很容易产生预测模型的过拟合现象,此外现有算法模型的预测精度较低,切不稳定因素较多,会造成模型预测精度的不稳定。
技术实现要素:
针对现有技术的不足及缺陷,本发明提出了一种新的变量选择方法称为自加权变量组合集群分析法,该方法基于mpa思想采用rmsecv最小原则的情况下,对fre和reg两种信息向量的结果进行归一化加权处理,计算出每个光谱变量的贡献值,进而考虑了两种信息向量对每个光谱变量的影响,提高了预测模型的精度及稳定性。
具体步骤如下:
a应用近红外光纤光谱仪测试所收集样本的近红外光谱,运用kennard-stone算法分为校正集和预测集;
b通过二进制矩阵采样法从变量空间中采样k次,得到k个变量子集,每一个变量子集都含有一组随机的变量组合,其中k值为1000;
c利用偏最小二乘法计算出每个变量组合的交互检验均方根误差,并选取其交互检验均方根误差最小的前σ×k个变量子集作为变量集,其中σ值取10%,σ×k的值为100;
d统计变量集中每个变量出现的频率并进行归一化处理,进而得到了一个变量重要性判断依据称为第一类信息向量;
e计算出变量集中每个变量在不同变量集中的偏最小二乘回归系数的绝对值,并进行归一化处理,最后对变量集中每个变量在不同变量集中的归一化回归系数绝对值进行求和,变量归一化回归系数绝对值之和的大小与变量的重要性成正比,进而得到又一个变量重要性判据称为第二类信息向量;
f根据每种信息向量的交互检验均方根误差设置第一类信息向量和第二类信息向量的权重;
g根据第一类信息向量和第二类信息向量的权重,计算出变量集中每个变量的贡献值;
h运用指数衰减函数删除那些贡献值较小的变量,保留其贡献值较大的变量,得到一个新的变量空间r;
i变量空间r中的变量继续通过步骤b~步骤h进行变量筛选,此过程迭代n次,n值为50,最终剩下l个变量,l值为14,计算出这l个变量之间所有变量组合的交互检验均方根误差,其值最小的变量组合为最终特征波长选取结果。
根据上述的基于自加权变量组合集群分析的近红外光谱变量选择方法,通过每个变量在变量集中变量出现频率和偏最小二乘回归系数的绝对值之和两种信息向量加权思想与模型集群分析思想相结合计算出每个光谱变量的贡献值,具体计算过程如下,信息向量的权重计算公式:
w1:第一类信息向量的权重;w2:第二类信息向量的权重;rmsecv1:第一类信息向量的交互检验均方根误差;rmsecv2:第二类信息向量的交互检验均方根误差;
每个光谱变量的贡献值计算公式如下:
yi:第i个变量贡献值,其值越大则该变量越重要;
变量保留率的计算公式如下:
rn=e-θ×nⅳ
rn:指数衰减函数运行n次时变量保留率;θ:曲线控制参数,它与指数衰减函数的执行次数有关,指数衰减函数执行的次数越多,其θ值越小,n:指数衰减函数的执行次数,
曲线控制参数的计算公式为:
公式ⅴ中p为指数衰减函数执行n-1次后所保留的变量数目,l为指数衰减函数运行结束之后剩余变量数目。
与现有算法模型相比,本发明提出的基于自加权变量组合集群分析法的近红外光谱变量选择方法,采用的两种信息向量加权的方式判断变量的重要性,考虑了两种信息向量对预测模型的影响,弥补了只采用一种信息变量作为变量重要性判断依据的缺陷,避免了模型过拟合,提升了预测模型的稳定性和可靠性;同时由于采用了fre和reg两种信息向量加权思想与模型集群思想相结合,减少了光谱变量,简化了预测模型,大大的提升了其模型的预测精度。
附图说明
下面结合附图及实施方式对本发明作进一步说明:
图1为本发明awvcpa算法流程图
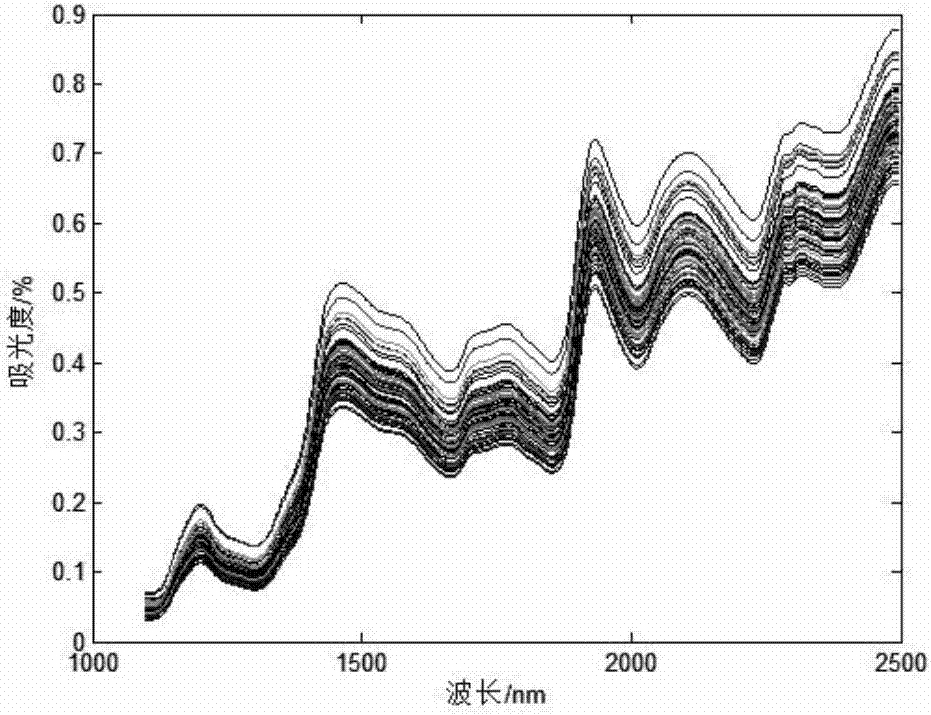
图2为玉米样本的近红外光谱图
图3为每个光谱变量基于awvcpa运行50次被选取为特征变量的频率分布图
图4为预测集真实值与预测值之间的散点图分布
图5为平均光谱与每种变量选择方法最终所选取的特征变量分布图
具体实施方式
实施方案一:为了证明本发明的适用性,结合实例进行详细的说明。但是本发明也可以应用于本次所采用的实例之外的光谱数据。
图1是本发明提供的一种基于自加权变量组合集群分析法(awvcpa)算法的流程图,可见,本发明具体包括以下步骤:
(1)所收集的玉米近红外光谱数据包含了80个玉米样本,每个样本的近红外光谱波长分布在1100-2498nm,运用光谱仪测试每个玉米样本的近红外光谱,并用化学方法测试每个样本含油量的化学值。运用kennard-stone(k-s)方法选取其中60个样本光谱数据和化学值数据作为校正集建立预测模型,将剩余的20个样本的光谱数据和化学值数据作为预测集样本检验模型的可行性,玉米近红外光谱图如图2所示。
(2)运用二进制矩阵采样法(bms)从玉米近红外光谱变量空间中采样1000次得到1000组不同的变量子集,之后运用偏最小二乘法(pls)计算出这1000组不同变量子集的交互检验均方根误差(rmsecv),选取其rmsecv值最小的前10%组变量子集作为变量集,进而得到了100组变量集。
(3)记录这100组变量集中每个光谱变量的出现次数并进行归一化处理得到每个光谱变量的fre。
(4)记录每个光谱变量在这100组不同的变量集中的偏最小二乘回归系数并进行归一化处理,最后对变量集中相同变量的归一化偏最小二乘回归系数的绝对值进行求和得到每个光谱变量的reg。
(5)通过公式(ⅰ)(ⅱ)分别计算这两类ivs的权重,并根据公式(ⅲ)计算出变量集中每个光谱变量的贡献值。
信息向量的权重计算公式
w1:第一类信息向量的权重;w2:第二类信息向量的权重;rmsecv1:第一类信息向量的交互检验均方根误差;rmsecv2:第二类信息向量的交互检验均方根误差;
每个光谱变量的贡献值计算公式如下:
(6)运用指数衰减函数删除那些贡献值较小的光谱变量,保留其贡献值较大的光谱变量,得到一个新的变量空间r。
rn=e-θ×n(ⅳ)
rn:指数衰减函数运行n次时变量保留率;θ:曲线控制参数,它与指数衰减函数的执行次数有关,指数衰减函数执行的次数越多,其θ值越小。n:指数衰减函数的执行次数。曲线控制参数的计算公式为
(7)对r中的变量重复(2)~(6)过程,此过程迭代50次,最终只剩下14个光谱变量,计算出这14个光谱变量之间所有变量组合的rmsecv,其值最小的变量组合为最终选取的特征变量。
为了避免算法运行过程中算法随机性对变量选择结果的影响,将awvcpa运行50次,每个光谱变量基于awvcpa运行50次选取为特征变量的频率如图3所示,选取awvcpa预测精度最高的一组特征变量作为最终特征变量选取的结果,最终通过awvcpa-pls建立玉米中含油量的预测模型的预测结果如图4所示。
为了说明awvcpa变量选择方法的优越性,将玉米近红外光谱数据在相同的条件下分别采用了ga、mc-uve、cars、vcpa和awvcpa五种变量选择方法进行特征变量提取,由于每种变量选择方法在运行过程中都带有一定的随机性,进而影响模型的可靠性,所以我们将以上每种变量选择方法运行50次,计算出每种变量选择方法在建模过程中的rmsep平均值,并选其每种算法预测精度最高的一组特征变量作为最终的特征变量选取结果,利用pls建立预测模型,每种变量选择方法所选取的特征变量结果如图5所示,每种建模方法的结果见表1。
表1不同建模方法的玉米中含油量的预测精度对比
本发明实施方式说明到此结束。
- 还没有人留言评论。精彩留言会获得点赞!