一种用于识别肺癌组织的数据处理装置及系统的制作方法
本发明涉及数据识别处理技术,尤其涉及一种基于随机森林模型来识别肺癌组织的数据处理装置及系统。
背景技术:
肺癌是当前对人类健康和生命造成最大威胁的恶性肿瘤。目前随着经济的快速增长,环境污染日益严重,使得肺癌的发病率和病死率也呈快速增长趋势。早期发现、早期诊断、早期治疗是有效降低肺癌病死率,提高患者生存期的关键途径。传统的肺癌识别方法有影像学检查方法、痰脱落细胞学检查和支气管镜检技术,这些方法存在容易造成漏诊与误诊,操作相对复杂,且仪器价格昂贵的问题,不适合作为肺癌早期信息识别筛查手段。
技术实现要素:
为了解决上述技术问题,本发明的目的是提供一种基于随机森林模型来识别肺癌组织的数据处理装置。
本发明的另一目的是提供一种基于随机森林模型来识别肺癌组织的数据处理系统。
本发明所采用的技术方案是:一种用于识别肺癌组织的数据处理装置,该装置包括处理器,适于实现各指令,所述指令由处理器加载并执行以下步骤:
获取待测肺部组织样本所对应的肺部组织样本质谱数据;
通过基于随机森林算法而建立得到的肺癌组织识别模型,对获取得到的肺部组织样本质谱数据进行分类处理,从而得到待测肺部组织样本的分类结果。
进一步,所述指令由处理器加载并还执行建立肺癌组织识别模型这一步骤,所述建立肺癌组织识别模型这一步骤,其包括以下步骤:
获取肺癌组织与正常肺部组织所对应的肺部组织样本质谱数据,将由获取得到的肺部组织样本质谱数据所构成的数据集作为肺部组织样本质谱数据集;
将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型;
利用验证集对随机森林模型进行验证。
进一步,所述将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型这一步骤,其包括有以下步骤:
通过建立多棵自助采样形成的决策树,从而建立得到随机森林模型。
进一步,所述建立自助采样形成的决策树这一步骤,其具体包括以下步骤:
通过自助采样法,从肺部组织样本质谱数据集所包含的n个肺部组织样本质谱数据中,以有放回随机选取方式选取k个肺部组织样本质谱数据,利用选取出的k个肺部组织样本质谱数据来训练生成一棵决策树;
当决策树的每个节点需要分裂时,随机从肺部组织样本质谱数据集所包含的m个变量中选取m个变量,其中,m<<m;然后,从选取出的m个变量中,采用信息增益或基尼指数来选取出一个变量作为对应节点的分裂变量。
进一步,所述通过基于随机森林算法而建立得到的肺癌组织识别模型,对获取得到的肺部组织样本质谱数据进行分类处理,从而得到待测肺部组织样本的分类结果这一步骤,其包括以下步骤:
将待测肺部组织样本所对应的肺部组织样本质谱数据输入至肺癌组织识别模型进行分类处理,从而导出肺部组织样本相似度矩阵;
采用多维标度分析法对所述肺部组织样本相似度矩阵进行降维,降维后得到的矩阵为待测肺部组织样本的分类结果。
本发明所采用的另一技术方案是:一种用于识别肺癌组织的数据处理系统,该系统包括:
采样模块,用于获取待测肺部组织样本所对应的肺部组织样本质谱数据;
分类模块,用于通过基于随机森林算法而建立得到的肺癌组织识别模型,对获取得到的肺部组织样本质谱数据进行分类处理,从而得到待测肺部组织样本的分类结果。
进一步,还包括用于建立肺癌组织识别模型的模型建立模块,所述模型建立模块具体包括:
建模数据获取子模块,用于获取肺癌组织与正常肺部组织所对应的肺部组织样本质谱数据,将由获取得到的肺部组织样本质谱数据所构成的数据集作为肺部组织样本质谱数据集;
建模处理子模块,用于将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型;
验证子模块,用于利用验证集对随机森林模型进行验证。
进一步,所述建模处理子模块包括用于通过建立多棵自助采样形成的决策树,从而建立得到随机森林模型的建模单元。
进一步,所述自助采样形成的决策树,其建立步骤包括有:
通过自助采样法,从肺部组织样本质谱数据集所包含的n个肺部组织样本质谱数据中,以有放回随机选取方式选取k个肺部组织样本质谱数据,利用选取出的k个肺部组织样本质谱数据来训练生成一棵决策树;
当决策树的每个节点需要分裂时,随机从肺部组织样本质谱数据集所包含的m个变量中选取m个变量,其中,m<<m;然后,从选取出的m个变量中,采用信息增益或基尼指数来选取出一个变量作为对应节点的分裂变量。
进一步,所述分类模块具体包括:
分类处理子模块,用于将待测肺部组织样本所对应的肺部组织样本质谱数据输入至肺癌组织识别模型进行分类处理,从而导出肺部组织样本相似度矩阵;
降维处理子模块,用于采用多维标度分析法对所述肺部组织样本相似度矩阵进行降维,降维后得到的矩阵为待测肺部组织样本的分类结果。
本发明的有益效果是:通过本发明装置,能在无需样品预处理的条件下快速实现对肺癌质谱数据与健康肺部组织样本质谱数据进行类型识别,具有操作简单、分析速度快、精确度高等优点,解决了传统肺癌信息识别技术操作复杂、分析速度慢且价格昂贵等局限性,将在重大疾病、临床医学、生命安全等相关技术领域具有巨大的潜在应用前景。
本发明的另一有益效果是:通过本发明系统,能在无需样品预处理的条件下快速实现对肺癌质谱数据与健康肺部组织样本质谱数据进行类型识别,具有操作简单、分析速度快、精确度高等优点,解决了传统肺癌信息识别技术操作复杂、分析速度慢且价格昂贵等局限性,将在重大疾病、临床医学、生命安全等相关技术领域具有巨大的潜在应用前景。
附图说明
图1是本发明一种用于识别肺癌组织的数据处理装置中处理器所执行的步骤流程示意图;
图2是本发明一种用于识别肺癌组织的数据处理装置中处理器所执行的一具体实施例步骤流程示意图;
图3是本发明一种用于识别肺癌组织的数据处理系统的结构框图;
图4是本发明的随机森林模型的参数优化示意图;
图5是肺癌组织与健康肺部组织的分类结果示意图。
具体实施方式
如图1所示,一种用于识别肺癌组织的数据处理装置,该装置包括处理器,适于实现各指令,所述指令由处理器加载并执行以下步骤:
获取待测肺部组织样本所对应的肺部组织样本质谱数据;
通过基于随机森林算法而建立得到的肺癌组织识别模型,对获取得到的肺部组织样本质谱数据进行分类处理,从而得到待测肺部组织样本的分类结果。
进一步作为本发明方法的优选实施方式,所述指令由处理器加载并还执行建立肺癌组织识别模型这一步骤,所述建立肺癌组织识别模型这一步骤,其包括以下步骤:
获取肺癌组织与正常肺部组织所对应的肺部组织样本质谱数据,将由获取得到的肺部组织样本质谱数据所构成的数据集作为肺部组织样本质谱数据集;
将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型;
利用验证集对随机森林模型进行验证。
进一步作为本发明方法的优选实施方式,所述将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型这一步骤,其包括有以下步骤:
通过建立多棵自助采样形成的决策树,从而建立得到随机森林模型。
进一步作为本发明方法的优选实施方式,所述建立自助采样形成的决策树这一步骤,其具体包括以下步骤:
通过自助采样法,从肺部组织样本质谱数据集所包含的n个肺部组织样本质谱数据中,以有放回随机选取方式选取k个肺部组织样本质谱数据,利用选取出的k个肺部组织样本质谱数据来训练生成一棵决策树;
当决策树的每个节点需要分裂时,随机从肺部组织样本质谱数据集所包含的m个变量中选取m个变量,其中,m<<m;然后,从选取出的m个变量中,采用信息增益或基尼指数来选取出一个变量作为对应节点的分裂变量。
进一步作为本发明方法的优选实施方式,所述通过基于随机森林算法而建立得到的肺癌组织识别模型,对获取得到的肺部组织样本质谱数据进行分类处理,从而得到待测肺部组织样本的分类结果这一步骤,其包括以下步骤:
将待测肺部组织样本所对应的肺部组织样本质谱数据输入至肺癌组织识别模型进行分类处理,从而导出肺部组织样本相似度矩阵;
采用多维标度分析法对所述肺部组织样本相似度矩阵进行降维,降维后得到的矩阵为待测肺部组织样本的分类结果。
本发明装置一具体实施例
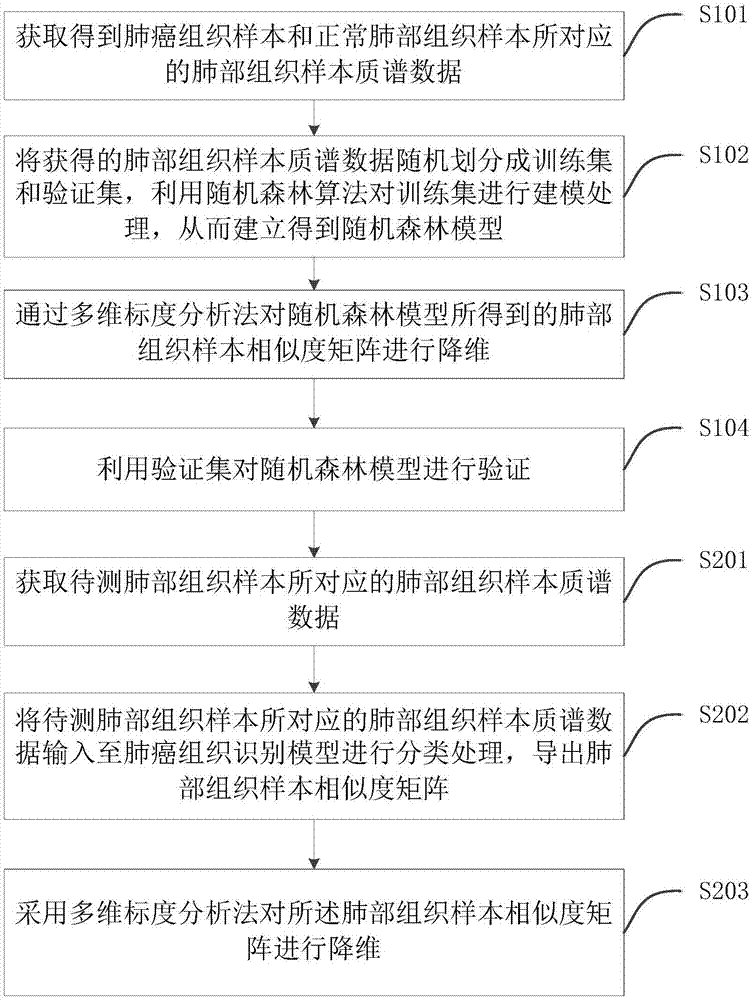
如图2所示,一种用于识别肺癌组织的数据处理装置,该装置包括处理器,适于实现各指令,所述指令由处理器加载并执行以下具体步骤:
第一步骤:建立肺癌组织识别模型
s101、获取得到肺癌组织样本和正常肺部组织样本所对应的肺部组织样本质谱数据,这些数据为用于建立肺癌组织识别模型的数据;所述肺癌组织样本和正常肺部组织样本所对应的肺部组织样本质谱数据,其是通过采用表面解吸常压化学电离质谱技术(dapca-ms),对肺癌组织样本和正常肺部组织样本(即健康肺部组织样本)进行质谱分析后而得到的;
其中,将由步骤s101获取得到的肺部组织样本质谱数据所构成的数据集作为肺部组织样本质谱数据集;
s102、将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型;
其中,对于所述随机森林模型,其是由多棵自助采样形成的决策树组合而成,而所述自助采样形成的决策树,其建立生成步骤包括:
s1021、通过自助采样法,从肺部组织样本质谱数据集所包含的n个肺部组织样本质谱数据中,以有放回随机选取方式选取k个肺部组织样本质谱数据,利用选取出的k个肺部组织样本质谱数据来训练生成一棵决策树;
s1022、当决策树的每个节点需要分裂时,随机从肺部组织样本质谱数据集所包含的m个变量中选取m个变量,其中,m<<m;然后,从选取出的m个变量中,采用信息增益或基尼指数来选取出一个变量作为对应节点的分裂变量;
可见,通过重复执行上述步骤s1021~s1022,便可建立n棵决策树,构成随机森林模型;具体地,在肺部组织样本质谱数据集中用于训练建立随机森林模型的数据构成训练集,而其它剩余的数据则构成验证集;
在本实施例随机森林自助采样过程中,每棵树建立时仅使用了肺部组织样本质谱初始训练集63.2%的样本,而剩余的36.8%的样本则作为验证集来对泛化性能进行“包外估计”,这36.8%的数据称为袋外数据,可以用于取代测试集进行误差估计和作为评价指标来优化参数,本实施例中得到的随机森林算法模型的参数优化如图4所示;其中,在随机森林算法的建模过程当中主要需要优化两个参数:决策树的数量及每棵树生长时的变量数;其中,决策树个数的多少直接影响随机森林分类算法的运算速度和分类效果,因此决策树的个数对建模至关重要,例如,若决策树的棵数太多,则会导致随机森林算法的速度下降,反之,若决策树的棵数太少,则会导致模型的分类准确率下降;
s103、通过多维标度分析法(mds)对随机森林模型所得到的肺部组织样本相似度矩阵进行降维;
s104、利用验证集对随机森林模型进行验证;
通过上述步骤建立得到的随机森林模型则为所需的肺癌组织识别模型。
第二步骤:
s201、获取待测肺部组织样本所对应的肺部组织样本质谱数据;其中,所述待测肺部组织样本所对应的肺部组织样本质谱数据,其是通过采用表面解吸常压化学电离质谱技术(dapca-ms),对待测肺部组织样本进行质谱分析后而得到的;
s202、将待测肺部组织样本所对应的肺部组织样本质谱数据输入至肺癌组织识别模型进行分类处理,从而导出肺部组织样本相似度矩阵;
s203、采用多维标度分析法对所述肺部组织样本相似度矩阵进行降维,降维后得到的矩阵为待测肺部组织样本的分类结果,其为一可视化图。每棵树建成后,所有的肺部组织样本质谱数据都达到该树的某个叶节点上,若两个肺部组织落在每棵树的同一个叶子节点的频率越大,表明相似度越高,所以,从决策树导出的肺部组织样本相似度矩阵能收集待测肺部组织样本之间的相似性,从而将原始空间样本映射到相似性空间;而为了能直观方便地观测随机森林模型所导出的分类结果,本实施例还通过多维标度分析法(mds)对随机森林模型所得到的肺部组织样本相似度矩阵进行降维;由于采用mds来实现肺部组织样本相似度矩阵的降维,能尽可能地保留原始对象之间的相似性,也就是说,通过设有降维步骤,在达到直观方便观测分类结果这一效果的同时,还能保证这降维结果的精确性。本实施例中最终得到的肺癌组织与健康肺部组织的分类结果如图5所示,本实施例得到的随机森林算法模型对未知样本验证得到的混淆矩阵则如表1所示。所述表1如下所示:
表1
其中,ca表示为肺癌组织,cab表示为正常肺部组织。另外,对于上述第二步骤,其实现肺癌组织与健康肺部组织之间的类别识别过程约为1分钟,达到快速识别、处理效率高等效果。
如图3所示,一种用于识别肺癌组织的数据处理系统,其特征在于:该系统包括:
采样模块,用于获取待测肺部组织样本所对应的肺部组织样本质谱数据;
分类模块,用于通过基于随机森林算法而建立得到的肺癌组织识别模型,对获取得到的肺部组织样本质谱数据进行分类处理,从而得到待测肺部组织样本的分类结果。所述采样模块和分类模块,可为程序模块,也可为硬件设备模块。
进一步作为本发明系统的优选实施方式,还包括用于建立肺癌组织识别模型的模型建立模块,所述模型建立模块具体包括:
建模数据获取子模块,用于获取肺癌组织与正常肺部组织所对应的肺部组织样本质谱数据,将由获取得到的肺部组织样本质谱数据所构成的数据集作为肺部组织样本质谱数据集;
建模处理子模块,用于将获得的肺部组织样本质谱数据随机划分成训练集和验证集,利用随机森林算法对训练集进行建模处理,从而建立得到随机森林模型;
验证子模块,用于利用验证集对随机森林模型进行验证。
进一步作为本发明系统的优选实施方式,所述建模处理子模块包括用于通过建立多棵自助采样形成的决策树,从而建立得到随机森林模型的建模单元。
进一步作为本发明系统的优选实施方式,所述自助采样形成的决策树,其建立步骤包括有:
通过自助采样法,从肺部组织样本质谱数据集所包含的n个肺部组织样本质谱数据中,以有放回随机选取方式选取k个肺部组织样本质谱数据,利用选取出的k个肺部组织样本质谱数据来训练生成一棵决策树;
当决策树的每个节点需要分裂时,随机从肺部组织样本质谱数据集所包含的m个变量中选取m个变量,其中,m<<m;然后,从选取出的m个变量中,采用信息增益或基尼指数来选取出一个变量作为对应节点的分裂变量。
进一步作为本发明系统的优选实施方式,所述分类模块具体包括:
分类处理子模块,用于将待测肺部组织样本所对应的肺部组织样本质谱数据输入至肺癌组织识别模型进行分类处理,从而导出肺部组织样本相似度矩阵;
降维处理子模块,用于采用多维标度分析法对所述肺部组织样本相似度矩阵进行降维,降维后得到的矩阵为待测肺部组织样本的分类结果。
由上述可得,本发明装置及系统采用随机森林算法,并结合表面解吸常压化学电离质谱技术(dapca-ms),能在无需样品预处理和常温常压条件下,直接实现肺癌和健康肺癌组织样本的鉴别,具有操作简单、分析速度快、精确度高等优点,解决了传统肺癌组织识别技术操作复杂、分析速度慢且价格昂贵等局限性,将在重大疾病、临床医学、生命安全等相关技术领域具有巨大的潜在应用前景。
以上是对本发明的较佳实施进行了具体说明,但本发明创造并不限于所述实施例,熟悉本领域的技术人员在不违背本发明精神的前提下还可做作出种种的等同变形或替换,这些等同的变形或替换均包含在本申请权利要求所限定的范围内。
- 还没有人留言评论。精彩留言会获得点赞!