适用于相干和非相干声源的反卷积声源成像算法的制作方法
本发明涉及噪声源的识别和定位领域,更具体地说是一种适用于相干和非相干声源的反卷积声源成像算法。
背景技术:
反卷积声源成像(damas)是一种基于声阵列的高分辨率噪声源识别与定位方法,该方法基于空间声源的非相干假设,建立互谱成像波束形成输出结果与真实声源分布以及阵列点扩展函数(psf)矩阵三者间的卷积关系,通过反卷积计算求解真实声源分布,从而消除非理想psf对波束形成输出结果的影响,达到有效降低主瓣宽度和旁瓣水平,显著提高声源识别空间分辨率的目的。由于其空间分辨率可达常规波束形成技术的10倍以上,且通过算法中的互谱操作可以有效抑制传感器在流体中的自噪声,因此damas在气动噪声领域获得了较为广泛的应用。目前已有的反卷积声源成像算法主要可以分为三类:第一类为brooks等提出的传统damas算法(brookstf,humphreyswm2006j.sound.vib.294856),其利用互谱波束形成输出结果,声源分布以及psf三者之间的卷积关系建立线性方程组,通过gauss-seidel迭代解卷积,求解真实声源分布,从而获得具有高分辨率的噪声源识别结果。但由于该算法在构建线性方程组时需要计算聚焦面上所有网格点处的psf,所需计算量很大,计算效率较低。第二类为基于快速fourier变换(fft)的damas算法,包括dougherty等提出的damas2算法(doughertyr.extensionsofdamasandbenefitsandlimitationsofdeconvolutioninbeamforming[j].aiaapaper05-2960,2005)与ehrenfried等提出的fft-nnls算法(ehrenfriedk,koopl.comparisonofiterativedeconvolutionalgorithmsforthemappingofacousticsources[j].aiaajournal,2012,45(7):1-19.)以及lylloff等提出了fista-damas算法(lylloffo,fernández-grandee,agerkvistf,etal.improvingtheefficiencyofdeconvolutionalgorithmsforsoundsourcelocalization[j].thejournaloftheacousticalsocietyofamerica,2015,138(1):172-180.)。这些算法的基本思想为:当测量阵列到声源的距离相比于测量阵列自身的孔径较大时或者聚焦面相对较小时,psf具有近似平移不变性,因此可以利用fft将声源分布与psf矩阵的空域卷积转化为阵列中心点处psf与声源分布在波数域的乘积,从而实现快速计算。这些算法由于仅需计算阵列中心点处的psf,求解过程也可运用fft实现,因此相对于传统damas算法具有明显的效率优势。第三类为基于稀疏重构方法的反卷积声源成像算法,其基本原理是利用声源分布在空间中的稀疏性,采用压缩感知理论中的稀疏重构算法解卷积,从而获得声源分布的精确解。由于稀疏约束的引入限制了方程解空间的大小,确保了声源分布的空间稀疏性,因此此类算法可以获得更高的精度和分辨率。目前此类算法主要有yardibi等提出的稀疏约束反卷积声源成像算法(sc-damas)(yardibit,lij,stoicap,etal.sparsityconstraineddeconvolutionapproachesforacousticsourcemapping[j].journaloftheacousticalsocietyofamerica,2008,123(5):2631-2642)和padois等提出的基于正交匹配追踪的反卷积声源成像算法(omp-damas)(padoist,berrya.orthogonalmatchingpursuitappliedtothedeconvolutionapproachforthemappingofacousticsourcesinverseproblem[j].journaloftheacousticalsocietyofamerica,2015,138(6):3678-3685.)。其中sc-damas算法通过一个l1范数正则化过程解卷积,其结果具有很高的精度和空间分辨率,但由于l1范数正则化过程需要求解一个凸优化问题,其计算复杂度较高,因此该算法计算效率较低。omp-damas算法理论上仅需要进行声源个数次迭代就能获得精确解,因此计算效率相对较高,但由于计算过程中没有控制噪声误差的正则化处理过程,因此其结果精度受测量误差影响更大,精度和分辨率不及sc-damas算法。
上述damas算法虽然在精度、空间分辨率或计算效率方面上各有优势,但由于这些算法在理论推导过程中均基于非相干声源假设,忽略了声源信号互谱矩阵中的交叉项(声源信号互谱矩阵中的非主对角线元素),从而导致上述算法仅对非相干声源有较好的识别效果,对于相干声源特别是交叉项能量较大的情况,算法的声源识别效果较差,出现伪峰和虚影,甚至完全失效。为此,brooks等提出一种可适用于识别相干声源的反卷积声源成像算法(damas-c)。该算法将声源信号互谱矩阵中的所有元素(包括交叉项)都作为待求未知数予以求解,这样无需忽略声源信号互谱矩阵中的交叉项也可求解出精确声源分布,从而避免了声源的非相干假设。然而交叉项的纳入大大增加了方程的未知数个数,因此导致矩阵方程的规模变得非常大,psf矩阵的构建以及矩阵方程的求解过程使得该算法计算量很大,因此该算法的计算效率非常低。brooks等也明确指出damas-c计算非常耗时,实际中应预先用其他方法估计出相干声源所在的区域,然后在较小的聚焦区域中应用该方法。由此可见,由于damas-c算法计算效率太低,在实际中并不实用。此外,yardibi等提出了一种可以进行相干声源识别的稀疏约束协方差矩阵拟合算法(cmf-c),该算法与damas-c算法的思想相同,都是将声源信号互谱矩阵中的所有元素(包括交叉项)都作为待求未知数予以求解,只是反卷积计算过程是通过极小化协方差矩阵的拟合误差来实现的,因此虽然cmf-c算法在识别精度上略高于damas-c算法,但在计算效率上与damas-c算法相当,同样不太实用。
技术实现要素:
本发明是为避免上述现有技术所存在的问题,提供一种适用于相干和非相干声源的反卷积声源成像算法,取消现有damas算法中的互谱去噪过程,使本发明方法能够同时适用于相干和非相干声源的识别,同时简化声源源强分布的求解过程,提高计算效率。
本发明为解决技术问题采用如下技术方案:
本发明适用于相干和非相干声源的反卷积声源成像算法的特点是按如下步骤进行:
步骤a、在k个声源辐射形成的声场中呈阵列布置m个传感器,形成测量面w,采集获得各传感器检测得到的测量声压p;
步骤b、运用主成分分析方法对所述测量声压p进行去噪处理,获得去噪声压
步骤c、将声源计算平面离散成网格面,所述网格面为聚焦面t,在所述聚焦面t中包含有n个网格点,每个网格点为聚焦点,利用延时求和算法由式(1)计算获得各聚焦点处波束形成的输出量y(rn),n=1,2,3…n,rn表示第n个聚焦点的坐标向量:
其中,v(rn)=[v1(rn)v2(rn)…vm(rn)]为导向矢量,v(rn)h为导向矢量v(rn)的共轭转置,
j为虚数单位,k为声波波数,k=2πf/c,π为圆周率,f为声源频率,c为声速,rm表示第m个传感器的坐标向量;
步骤d、由式(2)计算获得聚焦面t上所有聚焦点的声源源强与延时求和波束形成的输出量y(rn)之间的传递函数组成的n维行向量w(rn):
式(2)中,w(rn)=[w(rn/r1)w(rn/r2)…w(rn/rn)],w(rn/rn′)为延时求和波束形成的点扩展函数,n,n′=1,2,3…n,n为聚焦网格点数,g为声压green函数矩阵:
因w(rn)为n维行向量,聚焦面上共有n个聚焦点,则由n个n维行向量w(rn)构成的n×n的矩阵w表达如式(3),定义矩阵w为新型点扩展函数矩阵:
步骤e、建立如式(4)所示的矩阵方程:y=wq(4),
式(4)中,y为所有聚焦点处波束形成的输出量组成的n维已知列向量,q为n维的声源源强分布列向量;针对式(4)按如下反卷积过程求解获得n维的声源源强分布列向量q;
采用迭代收缩阈值算法,根据式(4)建立如式(5)所表达的目标方程:
式(5)中,||·||2表示l2范数,||·||1表示l1范数;λ为正则化参数;
依据求解获得的n维的声源源强分布列向量q的模进行声源的识别与定位。
本发明适用于相干和非相干声源的反卷积声源成像算法的特点也在于:所述步骤b中,对于测量声压p是按如下方式进行去噪处理获得去噪声压
步骤2.1、对所述测量声压p进行互谱获得互谱矩阵u:u=pph,ph为p的共轭转置;
步骤2.2、针对所述互谱矩阵u按式(6)进行特征值分解:
u=sdsh(6),
s为特征向量组成的矩阵,sh为s的共轭转置,d是由特征值组成的对角矩阵:
其中,d1,d2,d3…dn为互谱矩阵u的特征值,且d1≥d2≥…≥dn;
步骤2.3、根据主成分分析原理,d中大特征值对应的是声压中的主要成分,小特征值所对应的是声压中的噪声;依此,选择所有n个特征值中前l个较大的特征值,l<n;利用l个特征值以及l个特征值相对应的特征向量构造去噪声压
式(7)中,d为由所选择的l个特征值组成的列向量,s′为所选择的l个特征值所对应的特征向量组成的矩阵。
本发明适用于相干和非相干声源的反卷积声源成像算法的特点也在于:所述正则化参数λ的取值为:
本发明适用于相干和非相干声源的反卷积声源成像算法的特点也在于:步骤2.3中,对于所述l个特征值按如下方式进行选取:将所有特征值从大到小排列,计算排列后的相邻特征值间的变化率,取变化率最大位置处之前的l个特征值。
与已有技术相比,本发明有益效果体现在:
1、本发明方法直接建立点扩展函数矩阵、延时求和输出量及声源源强分布之间的矩阵方程,解得声源源强分布,实现声源的识别与定位。由于取消了反卷积声源成像(damas)算法中的互谱过程,避免了非相干声源的假设,能够同时适用相干声源和非相干声源的识别,应用范围更广。
2、本发明方法取消了互谱过程,但另一方面由于互谱过程是一个去噪过程,因此取消互谱过程将影响算法对噪声干扰的鲁棒性。为提高对噪声干扰的鲁棒性,本发明引入主成分分析方法进行去噪处理,从而使本算法具有较好的噪声鲁棒性。
3、本发明方法取消了互谱过程,直接求解声源复数源强分布,从而避免了互谱操作导致的待求未知数个数的剧增。使得本发明方法的计算效率远远高于可以用于相干声源识别的damas-c算法。
附图说明
图1为波束形成技术声源识别示意图;
图2a是声源频率为2000hz,本发明方法针对相干声源的定位效果示意图;
图2b是声源频率为2000hz,sc-damas方法针对相干声源的定位效果示意图;
图3a是声源频率为2500hz,本发明方法针对相干声源的定位效果示意图;
图3b是声源频率为2500hz,sc-damas方法针对相干声源的定位效果示意图;
图4a是声源频率为3000hz,本发明方法针对相干声源的定位效果示意图;
图4b是声源频率为3000hz,sc-damas方法针对相干声源的定位效果示意图;
图5a是声源频率为2000hz,本发明方法针对非相干声源的定位效果示意图;
图5b是声源频率为2000hz,sc-damas方法针对非相干声源的定位效果示意图;
图6a是本发明方法在低信噪比条件下的相干声源识别实验。
图6b是sc-damas算法在低信噪比条件下的相干声源识别实验。
表1为本发明方法与已有技术中damas-c算法在同一环境下运行所需的时间;
具体实施方式
本实施例中适用于相干和非相干声源的反卷积声源成像算法是按如下步骤进行:
步骤a、根据图1所示模型,在k个声源辐射形成的声场中呈阵列布置m个传感器,形成测量面w,采集获得各传感器检测信号得到测量声压p,声源的个数k小于传感器的数量m,传感器为传声器。
步骤b、为了抑制传感器的自噪声对声源识别结果的影响,提高声源空间分辨率。运用主成分分析方法对所述测量声压p进行去噪处理,获得去噪声压
步骤c、根据图1所示模型,将声源计算平面离散成一网格面,网格面为聚焦面t,在聚焦面t中包含有n个网格点,每个网格点为聚焦点,利用延时求和算法由式(1)计算获得各聚焦点处波束形成的输出量y(rn),n=1,2,3…n,rn表示第n个聚焦点的坐标向量:
其中,v(rn)=[v1(rn)v2(rn)…vm(rn)]为导向矢量,v(rn)h为导向矢量v(rn)的共轭转置,
j为虚数单位,k为声波波数,k=2πf/c,π为圆周率,f为声源频率,c为声速,rm表示第m个传感器的坐标向量。
步骤d、由式(2)计算获得聚焦面t上所有聚焦点的声源源强与延时求和波束形成的输出量y(rn)之间的传递函数组成的n维行向量w(rn):
式(2)中,w(rn)=[w(rn/r1)w(rn/r2)…w(rn/rn)],w(rn/rn′)为延时求和波束形成的点扩展函数,n,n′=1,2,3…n,n为聚焦网格点数;将w(rn/rn′)看作为延时求和波束形成的点扩展函数,其物理意义是单位强度点声源的延时求和波束形成阵列响应输出,g为声压green函数矩阵:
因w(rn)为n维行向量,聚焦面上共有n个聚焦点,则由n个n维行向量w(rn)构成的n×n的矩阵w表达如式(3),定义矩阵w为新型点扩展函数矩阵:
步骤e、建立如式(4)所示的矩阵方程:y=wq(4),
式(4)中,y为所有聚焦点处波束形成的输出量组成的n维已知列向量,q为n维的声源源强分布列向量;针对式(4)按如下反卷积过程求解获得n维的声源源强分布列向量q;
采用迭代收缩阈值算法(lasso)根据式(4)建立如式(5)所表达的目标方程:
式(5)中,||·||2表示l2范数,||·||1表示l1范数;λ为正则化参数;
依据求解获得的n维的声源源强分布列向量q的模进行声源的识别与定位。
本实施例中,对于步骤b中的测量声压p是按如下方式进行去噪处理获得去噪声压p~:
步骤2.1、对测量声压p进行互谱获得互谱矩阵u:u=pph,ph为p的共轭转置;
步骤2.2、针对互谱矩阵u按式(6)进行特征值分解:
u=sdsh(6),
s为特征向量组成的矩阵,sh为s的共轭转置,d是由特征值组成的对角矩阵:
其中,d1,d2,d3…dn为互谱矩阵u的特征值,且d1≥d2≥…≥dn;
正则化参数λ的取值为:
步骤2.3、根据主成分分析原理(principalcomponentanalysis,pca),d中大特征值对应的是声压中的主要成分,小特征值所对应的是声压中的噪声;依此,选择所有n个特征值中前l个较大的特征值,l<n;利用l个特征值以及l个特征值相对应的特征向量构造去噪声压
式(7)中,d是由所选择的特征值所组成的列向量,s′为所选择的特征值所对应的特征向量组成的矩阵;对于l个特征值按如下方式进行选取:将所有特征值从大到小排列,计算排列后的相邻特征值间的变化率,取变化率最大位置处之前的l个特征值。
去噪声压
仿真1,用于验证本发明方法相比sc-damas算法能够更好地识别相干声源:
数值仿真中,测量面、聚焦面的分布如图1所示。假设空间中有两个等强度的相干点声源分别位于聚焦面上,声源坐标分别为:(-0.15,0)m、(0.1,0)m。
测量面w位于z=0m平面,w的平面尺寸为1mx1m,其上沿x轴、y轴均匀划分11x11个测量点,测量点间距为0.1m。
聚焦面t位于z=1m平面,t的平面尺寸也为1mx1m,并划分21x21个聚焦网格点,聚焦点间距为0.05m。
为使仿真与实际实施中存在测量噪声的情况更加一致,在输入测量声压中添加高斯白噪声,信噪比为20db。
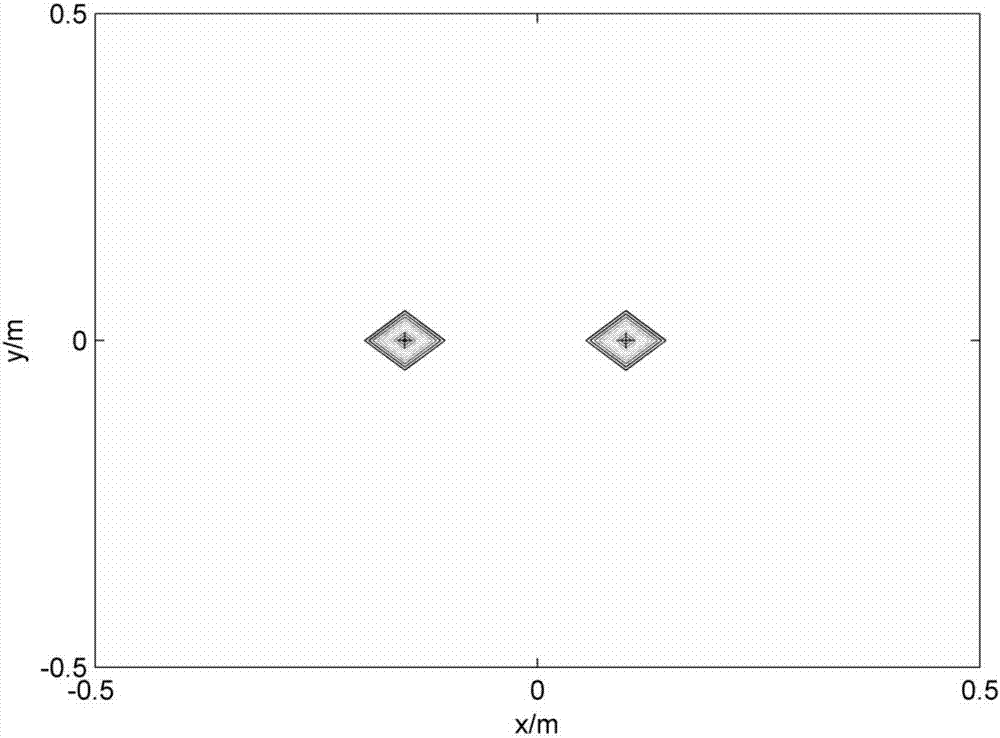
图2a、图3a、图4a展示了频率为2000hz、2500hz和3000hz时本发明算法的声源识别的效果,图2b、图3b、图4b展示了频率为2000hz、2500hz和3000hz时sc-damas算法的声源识别的效果。声源识别结果的图像中‘+’表示真实声源点所在位置。
当频率为2000hz时,如图2a所示,本发明算法识别出的峰值点与真实的相干声源所在位置精确重合,定位结果非常干净,没有伪峰和虚影,图2b中sc-damas算法的声源识别图上尽管定位出来了两个相干声源,但在两个声源之间会出现一个峰值稍低的伪声源。这显然是由于仿真中的采用相干声源,不符合sc-damas算法的非相干声源的假设,导致的问题。
当频率为2500hz时,图3a所示本发明算法的声源识别图中峰值点与真实的相干声源所在位置精确重合,并且不存在其他的虚源,说明其精确定位出了相干声源的位置。图3b所示sc-damas算法识别出的峰值点与真实的相干声源所在位置则没有重合,向左偏移了一个网格点,同时声源峰值势线也不如图3a集中,说明其空间分辨率也没有本发明算法高。
当频率为3000hz时,图4a所示发明算法和图4b所示sc-damas算法识别出的峰值点都与真实的相干声源所在位置精确重合,说明两种算法都准确定位出了相干声源的位置,这个结果符合所有damas算法的规律,就是频率越高,damas算法的定位精度越高,所以当频率为3000hz高频率的时候,sc-damas算法的定位精度高,相干声源对其定位精度的影响变小,因此频率为3000hz时,sc-damas算法也精确定位出了相干声源的位置。
本次仿真过程说明本发明算法比sc-damas算法能够更好的识别相干声源。
仿真2,比较sc-damas算法和本发明算法在非相干声源下的识别效果:
本发明算法是在sc-damas算法的基础上发展而来。因此,本发明算法对非相干声源的识别效果应该与sc-damas算法的识别效果相当,都对非相干声源有着较好的识别效果。本次仿真以数值说明这一情况:参数设定与仿真1类似,仅仅把声源换成了两个等强度的非相干声源。图5a和图5b是频率为2000hz时,本发明算法与sc-damas算法的声源识别的效果,当频率大于2000hz时,两种算法的定位效果与2000hz时类似,都能非常准确的定位出声源,因此本实施例中仅给出2000hz时两种算法的定位效果。
由图5a和图5b看出,在频率为2000hz时,两种算法都能非常准确的定位出非相干声源的位置,说明本发明算法对非相干声源的识别效果与sc-damas算法相当,能够很好地识别非相干声源。
仿真3,验证本发明算法的鲁棒性:
本发明算法是为避免非相干声源假设取消了抑制噪声的互谱过程,转而通过主成分分析去噪过程来抑制噪声的影响,提高算法的鲁棒性。本实施例利用低信噪比条件下的相干声源识别实验来检验本发明算法对噪声的鲁棒性。仿真参数与仿真1中的参数基本相同,仅将测量面声压的信噪比降为5db,图6a和图6b是频率为3000hz,信噪比为5db时,本发明算法与sc-damas算法的声源识别结果。
图6a中声源识别效果与图4a中的声源识别效果对比可以看出,信噪比从20db降到5db时,本发明算法依旧能够准确定位声源;图6b中声源识别效果与图4b中的声源识别效果对比可以看出,信噪比从20db降到5db时,sc-damas算法同样可以准确定位出声源;显然,本发明算法与sc-damas算法对噪声的鲁棒性相当,都有着比较好的鲁棒性。
仿真4,本发明方法较之damas-c算法是一种快速识别声源的反卷积声源成像算法:
利用数值仿真比较本发明算法与damas-c算法的计算效率,在仿真中,频率为3000hz,聚焦面分别划分为49、81、121、169、225个聚焦点,保持聚焦点间距为0.05m,其余仿真参数与仿真1中的仿真参数相同,并且damas-c算法中的迭代次数为200次。表1为本发明算法与damas-c算法在处理器cpu为intelcorei7-5960x3.00ghz、内存ram为32.0gb的同一服务器上运行时,所需时间随聚焦点个数增加的变化情况。仿真中聚焦点个数最多只有225个的原因在于当聚焦点较多时,damas-c算法的矩阵就非常大,需要很大的内存来存储,超出计算机的内存空间,使得算法无法运行,不能进行仿真研究。
表1
表1可见,damas-c算法所需要的计算时间远远大于本发明算法所需要的时间(时间单位为秒),例如:当聚焦点数为225时,damas-c算法所需要的时间是本发明算法所需要的时间的1600倍之多。显然,说明本发明算法是一种快速识别相干声源的反卷积声源成像算法,其比damas-c算法更有实际意义。
- 还没有人留言评论。精彩留言会获得点赞!