用于通过使用谐振器来识别说话者的方法及设备与流程
本公开涉及用于通过使用谐振器来识别说话者的方法及设备。
背景技术:
可以在各种设备中使用分析声音或振动的频谱的频谱分析仪。例如,频谱分析仪可以被应用在用于执行涉及声音或振动的语音设别、说话者识别以及情景识别的计算机、汽车、移动电话、或家用电器中振动。另外,也可以在建筑物、各种家用电器等上安装频谱分析仪,以分析振动信息。
如同频谱分析仪,诸如机械谐振器之类的传感器和电子模拟或数字滤波器可以被用来对具有特定范围的频带的信号进行滤波。可以通过使用从这些传感器获得的信号来执行傅立叶变换等,以分析频谱。
技术实现要素:
技术问题
提供了通过使用谐振器来识别说话者的方法。
提供了包括谐振器在内的用于识别说话者的设备。
问题的解决方案
根据本公开的一方面,识别说话者的方法包括:从具有不同谐振带的多个谐振器中的至少一些谐振器接收与说话者的语音相对应的电信号;使用所述电信号来计算谐振带的幅度差;以及使用所述谐振带的幅度差来识别说话者。
谐振带的幅度差可以是基于频率的从具有相邻谐振频率的两个谐振器输出的电信号的幅度差。
对说话者的识别可以包括:通过对谐振带的幅度差进行编码来生成带梯度(bandgradient)的位图;以及使用所述带梯度的位图来识别所述说话者。
编码可以包括:将谐振带的幅度差转换成三个值或大于三的奇数个值中的任一值。
基于三个值或大于三的奇数个值中的一个值,剩余值中的对应值可以具有相同的绝对值和相反的符号。
三个值或大于三的奇数个值可以包括a、0和-a(其中a为常数)。
当说话者的语音是注册处理语音时,对说话者的识别可以包括:使用带梯度的位图来生成说话者模型;以及将所述说话者模型注册为认证模板。
当说话者的语音不是注册处理语音时,对说话者的识别可以包括:使用带梯度的位图来生成说话者特征值;以及通过将所述说话者特征值与已注册的认证模板进行比较,来确定说话者是否是已注册的说话者。
对说话者的识别可以包括:使用谐振带的幅度差来确定说话者的语音之中的元音。
对元音的确定可以包括:使用谐振带的幅度差来估计共振峰的相对位置;以及根据所述共振峰的相对位置来确定元音。
共振峰的数目可以是三个。
可以根据从谐振式传感器的四个谐振器接收到的电信号的幅度来确定谐振带的幅度差。
对说话者的识别可以包括:为所确定的元音分配权重;使用与用于确定元音的谐振带的幅度差不同的谐振带的幅度差来生成带梯度的位图;使用带梯度的位图来生成说话者特征值;以及通过使用所述权重将所述说话者特征值与认证模板进行比较,来识别说话者是否是已注册的说话者。
对权重的分配可以包括:为所确定的元音分配的权重要高于另一元音的权重。
可以为所确定的元音分配权重1,且可以为另一元音分配权重0。
用于生成带梯度的位图的谐振带的幅度差的数目可以大于用于确定元音的谐振带的幅度差的数目。
根据本公开的另一方面,用于识别说话者的设备包括:谐振式传感器,包括具有不同谐振带的多个谐振器,并且谐振式传感器被配置为:从所述多个谐振器中的至少一些谐振器输出与说话者的语音相对应的电信号;以及处理器,被配置为:使用所述电信号来计算谐振带的幅度差并使用所述谐振带的幅度差来识别说话者。
谐振带的幅度差可以是基于频率的从具有相邻谐振频率的两个谐振器输出的电信号的幅度差。
处理器可以被配置为:通过对谐振带的幅度差进行编码来生成带梯度的位图,以及使用带梯度的位图来识别说话者。
处理器可以被配置为:通过将谐振带的幅度差转换成三个值或大于三的奇数个值中的任一值,来对谐振带的幅度差进行编码。
处理器可以被配置为:通过将使用带梯度的位图所确定的说话者特征值与已注册的认证模板进行比较,来确定说话者是否是已注册的说话者。
处理器可以被配置为:使用谐振带的幅度差来确定说话者的语音之中的元音。
处理器可以被配置为:使用谐振带的幅度差来估计共振峰的相对位置,以及根据共振峰的相对位置来确定元音。
可以根据从谐振式传感器的四个谐振器接收到的电信号的幅度来确定谐振带的幅度差。
处理器可以被配置为:为所确定的元音分配权重,使用与用于确定元音的谐振带的幅度差不同的谐振带的幅度差,来生成说话者特征值,以及通过使用权重将说话者特征值与认证模板进行比较,来识别说话者。
对权重的分配可以包括:为所确定的元音分配的权重要高于另一元音的权重。
根据本公开的另一方面,识别说话者的方法包括:接收与说话者的语音相对应的频带的信号;计算所述信号的幅度差;使用幅度差来确定说话者的语音中的元音;以及使用所确定的元音来确定所述说话者是否是已注册的说话者。
对元音的确定可以包括:使用幅度差来估计共振峰的相对位置;以及根据所述共振峰的相对位置来确定元音。
频带的信号可以是从具有不同谐振带的多个谐振器接收的。
对说话者是否是已注册的说话者的确定可以包括:为所确定的元音分配权重;生成与说话者的语音相对应的说话者的特征值;以及通过使用所述权重将所述说话者的特征值与认证模板进行比较,来确定说话者是否是已注册的说话者。
对权重的分配可以包括:为所确定的元音分配的权重要高于另一元音的权重。
可以为所确定的元音分配权重1,且可以为另一元音分配权重0。
本公开的有益效果
根据本公开,在进行说话者识别时无需长语音,即使在输入信号相对较短时也能够准确进行说话者识别。在进行说话者识别时,通过确定输入信号中的元音和使用有限的比较组(group),能够提高说话者识别的效率。
根据本公开,谐振式传感器可以不需要傅立叶变换,可以保持频带信息,并且可以改善时间分辨率。因为仅仅使用了相邻谐振器的电信号之间的差别,所以可以去除共有噪声的影响。
附图说明
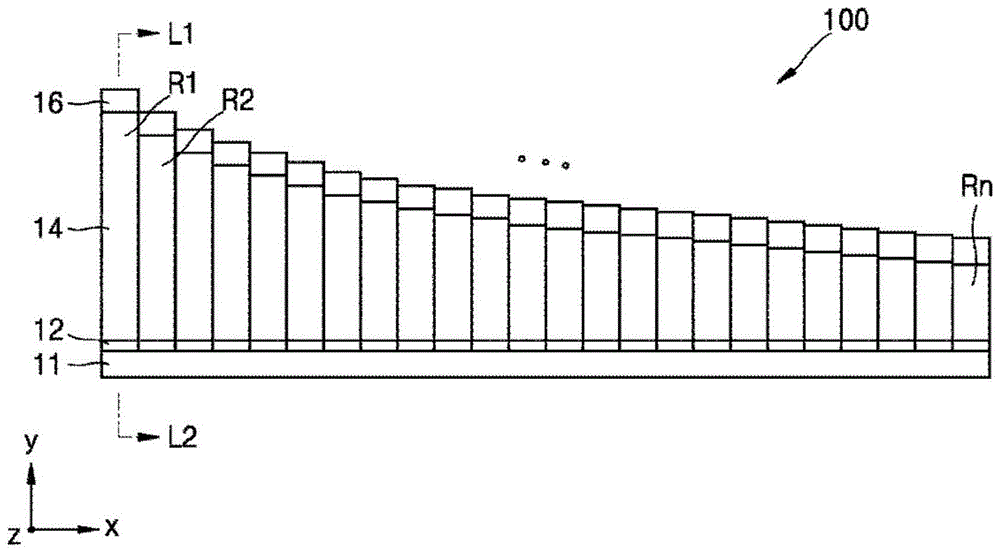
图1是示出了根据示例实施例的包括多个谐振器在内的谐振式传感器的示意结构的平面图。
图2是根据图1所示的示例实施例的谐振器沿着线l1-l2所取的截面图。
图3是示意性地示出了根据示例性实施例的包括谐振器在内的说话者识别设备的框图。
图4是示出了根据示例性实施例的使用谐振器的说话者识别方法的图。
图5是示出了具有不同谐振带的语音的图的示例。
图6是示出了使用谐振带的幅度差来生成带梯度的位图的示例的图。
图7是根据实施例的用于对谐振带的幅度差进行编码的公式的图。
图8是根据示例实施例的随时间变化的二维带梯度的位图的图。
图9是示出了元音[ah]发音的谐振带的频谱图。
图10是示出了元音[ee]发音的谐振带的频谱图。
图11和图12是示出了根据示例实施例的使用彼此间隔的谐振器结合元音确定来估计共振峰的位置的图。
图13是示出了根据示例实施例的元音的共振峰的位置的参考图。
图14是示出了使用元音和带梯度的位图来识别说话者的方法的流程图。
图15是用于说明在短语音中说话者特征值和认证模板之间的比较的参考图。
图16和图17是示出了根据示例实施例的将谐振式传感器的多个谐振器的中心频率设置为等间隔的示例的图。
图18和图19是示出了根据示例实施例的将谐振式传感器的多个谐振器的中心频率设置为恒定间隔的示例的图。
图20和图21是根据示例实施例的将谐振式传感器的多个谐振器的中心频率设置为任意间隔的示例的图。
图22是示出了根据示例实施例的包括多个谐振器在内的谐振式传感器的示意结构的平面图。
图23至图25是示出了根据示例实施例的谐振式传感器的多个谐振器的各种带宽变化的示例的图。
图26是示出了根据示例实施例的谐振式传感器的多个谐振器中的特定谐振器的带宽被设置得较宽的图。
具体实施方式
下文中,将参考附图来详细描述实施例。在附图中,类似的附图标记表示类似的元素,并且为了清楚和易于说明,可能夸张附图中每个元素的尺寸。同时,下文所描述的实施例仅仅是示例,且各种修改是可能的。在下文中,当构成元件被布置在另一构成元件的“上方”或“之上”时,该构成元件可以直接位于该另一构成元件上,或者以非接触方式位于该另一构成元件上方。此外,在本文中使用的术语“包括”和/或“包含”表明存在所提及的特征或组件,但是不排除存在或添加一个或多个其它特征或组件,但是另做具体说明的除外。
图1是示出了根据示例实施例的包括多个谐振器在内的谐振式传感器的示意结构的平面图。
图1中的谐振式传感器100可被作为分析声音或振动的频谱的频谱分析仪。谐振式传感器100可以包括:具有不同谐振带的多个谐振器,例如,第一谐振器r1、第二谐振器r2、...、第n谐振器rn。谐振式传感器100中所包括的单元谐振器的数目可以是两个或多于两个,并且可以根据用户的选择来确定但不限于此。谐振器r1、r2、...、rn可以被形成为具有大约若干mm或更短的长度,并且可以使用微机电系统(mems)过程等来制造。每个谐振器仅针对特定频带来谐振,且将谐振频带称作谐振带。
图2是根据图1所示的示例实施例的谐振器沿着线l1-l2所取的截面图。
参考图2,第一谐振器r1可以包括:固定单元11以及从固定单元11沿一个方向(例如,y方向)突出并延伸的支撑单元14。传感器单元12和质量单元16可以形成在支撑单元14上。传感器单元12可以形成在支撑单元14的一端,例如,在靠近固定单元11的区域中。质量单元16可以形成在支撑单元14的一端的相对侧,例如,在相对远离固定单元11的区域中。
固定单元11是被形成为使得谐振器r1、r2、...rn的支撑单元14突出的区域,并且可由通常用作电子设备的衬底的材料来形成。支撑单元14可以由si等形成并且可以在一个方向上具有横梁或长薄片的形状并且可以被称作悬臂。支撑单元14的一端可以由固定单元11固定,而另一端则可以沿上下方向自由振动,例如,如图2所示的z方向,而没有被其它对象固定。与图2所示不同,谐振器的支撑单元可以具有以下形状:支撑单元的两侧都被固定至固定单元,而支撑单元的中央部分振动。
传感器单元12是感测由于外部声音或振动通过谐振器r1、r2、...rn的支撑单元的流动所导致的信号的区域,例如,压力传感器。传感器单元12可以包括:下电极12a、压电材料层12b、以及上电极12c,依次形成在支撑单元14的一个表面上。传感器单元12的下电极12a和上电极12c可以由导电材料形成,例如,钼(mo)等。可选地,还可以在下电极12a和支撑单元14之间形成绝缘层。只要是压力传感器可以使用的压电材料,可以不受限制的使用压电材料层12b。压电材料层12b可以由例如aln、zno、sno、pzt、znsno3、聚偏二氟乙烯(pvdf)、聚(偏二氟乙烯-三氟乙烯)(p(vdf-trfe))或pmn-pt等形成。然而,谐振器r1、r2、...rn不限于包括压力传感器在内的压电类型,还可以使用静电传感器。
对形成质量单元16的材料不做限制并且其可以使用au等金属来形成。
在图2中,例如,配置也可以应用于图1中的第二谐振器r2至第n谐振器rn:第一谐振器r1包括固定单元11、支撑单元14、传感器单元12、以及质量单元16。
当声音、振动或力从外部作用在图1和图2所示的谐振器r1、r2、...rn时,根据质量单元16的行为可以生成惯性力。当支撑单元14的谐振频率与外部振动、声音或力的频率彼此相同时,就会生成谐振现象且惯性力可增大。这种惯性力可以在传感器单元12中生成弯矩。弯矩可以在传感器单元12的每层中生成应力。在这种情况下,在压电材料层12b中可出现具有与所施加的应力成正比的幅度的电荷,并且生成与电极12a和电极12c之间的电容成反比的电压。总之,当检测并分析来自谐振器r1、r2、...rn外部的诸如语音、振动或力之类的输入信号在传感器单元12中生成的电压时,就可以获得与诸如语音、振动或力之类的输入信号相关的信息。
由谐振器r1、r2、...rn所感测到的输入信号的频带可以是范围在接近20hz至20khz范围中的可听频带,但是不限于此。20khz的超声波频带的或者更高频带的语音或者20hz的甚低声音频带或更低频带的语音也能被接收到。
本公开提供了用于使用由谐振式传感器100所检测到的输出值(即,电信号)来识别说话者的设备和方法。
图3是示意性地示出了根据示例性实施例的包括谐振器在内的说话者识别设备的框图。
参考图3,说话者识别设备200包括:谐振式传感器100,其响应于如图1和图2所示的外部输入信号来输出具有特定值的电信号;以及处理器210,其根据从谐振式传感器100所接收到的电信号来计算谐振带的幅度差,并且使用谐振带的幅度差来识别说话者。
谐振式传感器100可以包括具有不同谐振频率(即,谐振带)的多个谐振器,如图1和图2所示。谐振式传感器100中的每个谐振器都可以输出与输入信号相对应的电信号。在谐振式传感器100中,具有输入信号的频率所包括的谐振带的谐振器可以输出幅度很大的电信号(例如,电压),而具有输入信号的频率所不包括的谐振带的谐振器可以输出幅度很小的电信号。因此,谐振式传感器100中的每个谐振器可以输出与输入信号相对应的电信号,且谐振式传感器100因而可以输出针对频率来细分的电信号。
谐振式传感器100可以被配置为:包括下文所述的处理器210的至少一部分。例如,除了检测语音的操作之外,谐振式传感器100还可以包括以下操作:针对说话者的语音来校正电信号,计算电信号的特征等。在这种情况下,谐振式传感器100可以是具有硬件模块和软件模块的功能模块。
处理器210可以驱动操作系统和应用程序以控制连接到处理器210的多个组件。处理器210可以使用从谐振式传感器100获得的电信号来执行说话者识别。
例如,处理器210可以使用从谐振式传感器100接收的电信号来计算谐振带的幅度差,并且对谐振带的幅度差进行编码以生成带梯度的位图。谐振带的幅度差可以意味着从具有不同谐振带的谐振器输出的电信号的幅度差。带梯度的位图将在下文中进行描述,在该图中对谐振带的幅度差进行了简化。
处理器210可以根据特定说话者的注册处理语音来生成带梯度的位图,并且可以使用带梯度的位图来生成个性化的说话者模型。例如,处理器210可以针对带梯度的位图,使用快速傅立叶变换(fft)、2d离散余弦变换(dct)、动态时间扭曲(dtw)、人工神经网络、矢量量化(vq)、高斯混合模型(gmm)等,来生成说话者的注册处理语音的特征值,并且根据注册处理语音的特征值来生成个性化的说话者模型。处理器210可以通过将注册处理语音的特征值应用于通用背景模型(ubm),来生成个性化的说话者模型。所生成的个性化的说话者模型可以被存储在存储器220的安全区域中作为认证模板,用于与后续输入的特定说话者的语音进行比较。
在语音认证时,处理器210可以根据未指定的说话者输入的语音来生成带梯度的位图,可以使用带梯度的位图来生成特征值,以及随后与已注册的认证模板进行比较,以对说话者进行认证。此时,处理器210可以对未指定的说话者的特征值的类型进行转换,以与已注册的认证模板进行比较,并且可以通过将经转换的特征值与已注册的认证模板进行比较来确定相似度。可以将最大似然估计方法等应用于相似度。处理器210可以在相似度大于第一参考值时确定认证成功,并且可以在相似度小于或等于第一参考值时,确定认证失败。第一参考值可以是预定义的作为参考值的值,通过该参考值能够将未指定的说话者的特征值等同于认证模板。
另外,处理器210可以使用从谐振式传感器100接收到的电信号来计算谐振带的幅度差,并且可以使用所计算出的谐振带的幅度差来确定元音。元音可以包括多个共振峰,共振峰是声能集中的频带。尽管特定共振峰对于每个说话者可能是不同的,但是该特定共振峰并不具有导致无法将该元音与其它元音相区分的变化。因此,通常都可以区分出要发出的元音,而不用考虑说话者是谁,而且可以将认证模板中与所确定的元音相对应的模型用于说话者识别。将在下文中描述元音确定方法。
说话者识别设备200可以包括存储认证模板的存储器220。存储器220可以暂时性地存储与未指定的说话者的语音相关的信息。
此外,说话者识别设备200还可以包括显示信息等的显示器230。显示器230可以显示与识别有关的各种信息,例如,用于识别的用户接口、指示识别结果的指示器等。
图4是示出了根据示例性实施例的使用谐振器的说话者识别方法的图。
参考图4,在根据本公开的说话者识别方法中,处理器210可以从谐振式传感器100接收与说话者的语音相对应的电信号(s310)。谐振式传感器100中的每个谐振器可以输出与语音相对应的电信号。处理器210可以接收该电信号。
处理器210可以使用从谐振式传感器100接收到的电信号来计算谐振带的幅度差(s320)。谐振带的幅度差可以是从具有相邻谐振频率的两个谐振器输出的电信号的幅度差,例如,相邻谐振频率是从不同谐振器接收到的电信号的频率。
处理器210可以使用谐振式传感器100中包括的所有谐振器来计算谐振带的幅度差。在图1中,当第一谐振器至第n谐振器具有顺序变化的谐振带时,处理器210可以计算从第一谐振器和第二谐振器接收到的电信号之间的幅度差,作为第一谐振带的幅度差;可以计算从第二谐振器和第三谐振器接收到的电信号之间的幅度差,作为第二谐振带的幅度差;以及可以计算从第n-1谐振器和第n谐振器接收到的电信号之间的幅度差,作为第n-1谐振带的幅度差。
处理器210可以仅仅使用谐振式传感器100中包括的某些谐振器来计算谐振带的幅度差。例如,处理器210可以使用从第一谐振器、第四谐振器、第k谐振器、以及第n谐振器接收到的电信号来计算谐振带的幅度差。当第一谐振器和第四谐振器的谐振带彼此相邻、第四谐振器和第k谐振器的谐振带彼此相邻、以及第k谐振器和第n谐振器的谐振带彼此相邻时,处理器210可以计算由第一谐振器和第四谐振器接收到的电信号之间的差,作为第一谐振带的幅度差;计算由第四谐振器和第k谐振器接收到的电信号之间的差,作为第二谐振带的幅度差;以及计算由第k谐振器和第n谐振器接收到的电信号之间的差,作为第三谐振带的幅度差。
处理器210可以使用所计算出的谐振带的幅度差来识别说话者(s330)。例如,处理器210可以通过对谐振带的幅度差进行编码来生成带梯度的位图,使用带梯度的位图来生成说话者的语音的特征值,以及通过将所生成的特征值与已存储的认证模板进行比较来识别说话者。带梯度的位图将在下文中进行描述,在该图中对谐振带的幅度差进行了简化。
附加地,处理器210可以使用谐振带的幅度差来确定元音。所确定的元音可以被用于确定发声的说话者是否是已注册的说话者。例如,认证模板中包括的个性化的说话者模型中与所确定的元音相对应的模型可以被加权,或者可以只将对应模型用于说话者识别。说话者识别设备200可以使用谐振带的幅度差来识别说话者。使用谐振带的幅度差的方法可以有效地去除谐振频率之间共有的噪声。
图5是示出了具有不同谐振带的语音的图的示例。通过使用谐振带的幅度差来识别谐振带的中心频率,可以去除图5中阴影所示的区域。阴影区域是与谐振带的中心频率相关性较弱的频率区域且可能对应于噪声。因此,与中心频率相关性较弱的共有噪声可以通过使用谐振带的幅度差而被有效地去除。去除共有噪声可以不需要使用各种噪声去除算法或者可以简化对各种噪声去除算法的使用,从而能够更高效地执行语音识别。换言之,谐振带的幅度差可以用于省略或简化用于噪声去除的预处理过程。
图6是示出了使用谐振带的幅度差来生成带梯度的位图的示例的图。参考图1和图6,谐振式传感器100中的谐振器r1、r2、...、rn中的每个谐振器可以响应于说话者的话音而输出电信号。谐振器r1、r2、...、rn中的每个谐振器可以具有如图6的(a)所示的谐振频率。在说话者的语音中可以混合了多个谐振频率。每个谐振器可以输出与说话者的语音中包括的频率相对应的电信号。例如,当说话者的语音包括第一频率h1时,第一谐振器r1可以谐振并输出幅度很大的电信号。
如图6的(b)所示,处理器210可以通过使用从谐振式传感器100接收到的电信号,来计算谐振带的幅度差。处理器210可以基于谐振频率使用从相邻谐振器输出的电信号来计算谐振带的幅度差。图6的(b)示出了通过使用谐振式传感器100中包括的所有谐振器来计算谐振带的幅度差的结果。在图6的(a)中,从第一谐振器至第n谐振器具有顺序变化的谐振带,且处理器210因此可以计算第一谐振器至第n谐振器中的相邻谐振器的电信号的幅度差,作为谐振带的幅度差。例如,第一谐振带的幅度差g1是第一谐振器和第二谐振器接收到的电信号之间的幅度差,第二谐振带的幅度差g2是第二谐振器和第三谐振器接收到的电信号之间的幅度差,且第三谐振带的幅度差g3是第三谐振器和第四谐振器接收到的电信号的幅度差。第n-1谐振带的幅度差gn-1是第n-1谐振器和第n谐振器接收到的电信号之间的幅度差。
如图6的(c)所示,处理器210可以对谐振带的幅度差进行编码。例如,处理器210可以使用以下公式对语音的差异进行编码:
[公式1]
其中,hk表示第k谐振器的带特征(即,电信号),hk+1表示第k+1谐振器的带特征,且tk表示通过对第k带谐振器与第k+1谐振器之间的特征差异进行编码所得到的值。该编码值被称作谐振带的位(bit)值。α表示任意常数并且可以根据实施例来确定。
图7是示出了根据实施例的用于对谐振带的幅度差进行编码的公式的图。α和-α是阈值。说话者的语音的编码值可以根据阈值的量值而改变。参考公式1和图7,针对来自说话者的语音,处理器210可以通过以下方式将谐振带的幅度差编码为三个结果值-1、0、+1:通过在具有相邻谐振带的谐振器r1、r2、...、rn之间的输出值的差值大于或等于指定数值α时将该差值表示为1,在差值小于-α时将其表示为-1,以及在差值小于α或差值大于-α时将其表示为0。
在图6的(c)中,当使用公式1将由t1、t2、t3...tn-1表示的每个区域的两条边界线的值计算为谐振带的位值时,可以获得t1为0且t2为-1、t3为0以及tn为-1的结果。图6的(d)是示出了图6的(c)中所示出的位值的图。如图6的(d)所示,从谐振式传感器100输出的电信号的最大幅度和最小幅度大约相差100倍。然而,当从谐振式传感器100输出的信号被转换成带梯度的位值时,该位值可以被简化为如图6的(d)所示的8个级别。
在图6中,处理器210将谐振带的幅度差编码为了-1、0、+1,但是这仅仅是示例。处理器210可以采用各种形式来对谐振带的幅度差进行编码。例如,处理器210可以将谐振带的幅度差编码为三个值或大于三的奇数个值中的任一值。基于这三个值或大于三的奇数个值中的一个值的剩余值中的对应值可以具有相同的绝对值和相反的符号。例如,处理器210可以将谐振带的幅度差编码为-2、-1、0、1和2。备选地,处理器210可以将谐振带的幅度差编码为偶数个值中的任一值。偶数个值中的对应值可以具有相同的绝对值和相反的符号。例如,处理器210可以将谐振带的幅度差编码为-3、-1、1和3。
当将这种操作应用于从谐振式传感器100输出的整个电信号时,可以生成随时间变化的二维带梯度的位图。二维带梯度的位图根据说话者的不同而不同,并且可以是用于说话者识别的特征。
图8是示出了根据示例实施例的随时间变化的二维带梯度的位图的图。如图8所示,可以针对每个时间帧来生成带梯度的位图。处理器210可以根据具有预定时间单位的帧来生成带梯度的位图,但不限于此。当以预定时间单位来生成带梯度的位图并且连续生成的位图相同时,可以仅将一个位图用于说话者识别,此后可以不再将相同的位图用于说话者识别。例如,说话者可能会发出一秒或两秒的音节“u”。在这种情况下,处理器210可以使用在两秒的发音期间所生成的带梯度的位图,以进行说话者识别,但是可以从在两秒的发音期间所生成的带梯度的位图中去除相同位图,且可以仅使用一个不同的位图来进行说话者识别。生成二维带梯度的位图的方法可以根据识别的使用而改变。
处理器210可以通过使用带梯度的位图生成特定说话者的个性化的说话者模型,并且将个性化的说话者模型存储为认证模板,来注册说话者的语音。当稍后接收到未指定的说话者的语音时,可以将语音的相似度与以前存储的认证模板的相似度进行比较,以确定未指定的说话者与已注册的说话者是否相同。
例如,当“start”(开始)被注册为用于识别的语音时,特定说话者可以发出“start”。谐振式传感器100的每个谐振器或某些谐振器可以输出与“start”相对应的电信号。处理器210可以根据从谐振式传感器100接收到的电信号来计算并编码谐振带的幅度差,生成带梯度的位图,然后使用带梯度的位图来计算与“start”相对应的个性化的特征值,使用具有个性化的特征值来生成个性化的说话者模型,以及将个性化的说话者模型注册为认证模板。然后,当未指定的说话者发出“start”时,处理器210可以生成与之相对应的带梯度的位图,并且使用该位图来计算与未指定的说话者的“start”相对应的特征值。处理器210可以将特征值转换成可以与认证模板进行比较的形式,将具有经转换形式的个性化的说话者模型与认证模板进行比较,并且确定未指定的说话者是否是已注册的说话者以执行说话者识别。
如上文所述,当使用带梯度(即,谐振带的幅度差)来执行说话者识别时,与使用stft(短时傅立叶变换)和mfcc(梅尔频率倒谱系数)进行语音处理相比,可以简化处理过程。
根据本公开的说话者识别方法可以附加地使用元音。元音可以包括作为构成音素的共振峰。此处,共振峰意味着由人的发声器官的通道的形状、尺寸等引起的腔体谐振现象所生成的声能的频率强度的分布,即,声能集中的频带。图9和图10是语音模型中的特定元音的能量分布的图。图9是示出了元音[ah]发音的谐振带的频谱图。图10是示出了元音[ee]发音的谐振带的频谱图。参考图9和图10的元音频谱,可以看出存在不止一个谐振带,而是存在多个谐振带。根据说话者,元音[ah]发音和元音[ee]发音的频谱可能不同。然而,根据说话者的这种频谱变化不足以将元音[ah]与元音[ee]相区分。这种现象同样适用于其它元音。换言之,一般可以区分元音,而不管说话者个人的语音特征如何。
从低频侧开始,元音中的谐振带可以被称为第一共振峰f1、第二共振峰f2、以及第三共振峰f3。第一共振峰f1的中心频率最小。第三共振峰f3的中心频率最大。第二共振峰f2的中心频率可以具有在第一共振峰f1和第三共振峰f3之间的幅度。在比较说话者的语音和图1所示的谐振式传感器100的谐振器r1、r2、...、rn中的每个谐振器的输出后,就可以确定语音的中心频率,并且可以获得第一共振峰f1、第二共振峰f2、以及第三共振峰f3的位置。在获得了第一共振峰f1、第二共振峰f2、以及第三共振峰f3的位置时,可以获得来自说话者的语音中的元音。
图11和图12是示出了根据示例实施例的使用彼此间隔的谐振器结合元音确定来估计共振峰的位置的图。
图1所示的谐振式传感器100中的谐振器r1、r2、...、rn中的两个不同的谐振器可以输出与来自说话者的输入信号相对应的电信号。这两个间隔的谐振器可以是相邻的或不相邻的谐振器。参考图11,具有谐振频率ωa的第一谐振器和具有谐振频率ωe的第二谐振器可以输出与说话者的输入信号相对应的不同幅度的电信号。例如,当语音的中心频率是ωa时,第一谐振器的输出值h1(ω)可以非常大,而第二谐振器的输出值h2(ω)可以没有或者非常小。当语音的中心频率是ωc时,第一谐振器的输出值h1(ω)和第二谐振器的输出值h2(ω)都可以非常小。当语音的中心频率是ωe时,第一谐振器的输出值h1(ω)可以没有或者非常小,且第二谐振器的输出值h2(ω)可以非常大。
换言之,当语音的中心频率具有诸如ωa、ωb、ωc、ωd或ωe等的值时,第一谐振器的输出值与第二谐振器的输出值彼此不同。因此,可以看出,第一谐振器的输出值与第二谐振器的输出值之间的差值h2(ω)-h1(ω)也随着图12中所示的语音的中心频率改变。因此,也可以根据两个谐振器的输出值之间的差值来反向确定语音的中心频率。即,可以使用谐振器之间的谐振带的幅度差来确定作为语音的中心频率的共振峰,并且可以根据中心频率的位置来确定元音。
元音通常包括三个共振峰。处理器210可以选择谐振式传感器100的四个谐振器,并且使用从选定谐振器输出的电信号来确定共振峰。
图13是示出了根据示例实施例的元音的共振峰的位置的参考图。
参考图13,水平轴表示元音的类型且垂直轴表示根据元音的第一共振峰f1、第二共振峰f2、以及第三共振峰f3的中心频率。图13中所示的根据元音的第一共振峰f1、第二共振峰f2、以及第三共振峰f3的位置可以使用众所周知的元音的共振峰的位置数据。例如,可以使用可以被称作通用背景模型(ubm)的针对各种说话者的元音信息数据库来获得元音的共振峰的位置。
如图13所示,可以看出每个元音通常包括三个共振峰。可以看出:根据元音,共振峰的位置不同。三个共振峰中具有最低中心频率的共振峰可以被称作第一共振峰,具有最高中心频率的共振峰可以被称作第三共振峰,且具有中间中心频率的共振峰可以被称作第二共振峰。
为了确定这三个共振峰,处理器210可以从图1所示的谐振式传感器100中选择具有不同谐振频率的四个谐振器。在选择这四个谐振器时,处理器210可以选择谐振频率低于第一共振峰的中心频率的任一谐振器作为第一谐振器,可以选择谐振频率在第一共振峰的中心频率与第二共振峰的中心频率之间的任一谐振器作为第二谐振器,可以选择谐振频率在第二共振峰的中心频率与第三共振峰的中心频率之间的任一谐振器作为第三谐振器,以及可以选择谐振频率高于第三共振峰的中心频率的任一谐振器作为第四谐振器。例如,处理器210可以选择分别具有大约300hz、大约810hz、大约2290hz、以及大约3000hz的谐振频率的四个谐振器。
处理器210可以使用四个谐振器中具有相邻谐振带的两个谐振器的输出值之间的差值来确定第一共振峰至第三共振峰。例如,处理器210可以通过第一谐振器和第二谐振器的输出值之间的差值h2(ω)-h1(ω)来确定第一共振峰,并且可以通过第二谐振器和第三谐振器的输出值之间的差值h3(ω)-h2(ω)来确定第二共振峰。处理器210可以通过第三谐振器和第四谐振器的输出值之间的差值h4(ω)-h3(ω)来确定第三共振峰。处理器210可以根据第一谐振器和第二谐振器的输出值之间的差值h2(ω)-h1(ω)、第二谐振器和第三谐振器的输出值之间的差值h3(ω)-h2(ω)、以及第三谐振器和第四谐振器的输出值之间的差值h4(ω)-h3(ω)来分别确定第一共振峰至第三共振峰,并且可以使用第一共振峰至第三共振峰来确定所发出的元音,而不管谁是说话者。所确定的元音可以被用于确定发声的说话者是否是已注册的说话者。具体地,仅认证模板中包括的个性化的说话者模型中的与所确定的元音相对应的模型可以被用于进行说话者识别。
图14是示出了使用元音和带梯度的位图来识别说话者的方法的流程图。参考图14,处理器210可以从谐振式传感器100接收与说话者的语音相对应的电信号(s1110)。例如,说话者可以发出“we”且谐振式传感器100可以输出与“we”相对应的电信号,使得处理器210可以接收与“we”相对应的电信号。
处理器210可以使用从某些谐振器接收到的电信号来计算谐振带的幅度差(s1120)。某些谐振器可以被预先定义,以确定元音的共振峰。例如,处理器210可以使用从四个预定谐振器接收到的电信号来计算谐振带的幅度差,以确定上述三个共振峰。
处理器210可以使用某些谐振器的谐振带的幅度差来确定元音(s1130)。例如,处理器210可以使用四个谐振带的幅度差来确定第一共振峰至第三共振峰,并且可以使用第一共振峰至第三共振峰的相对位置关系来确定元音。在确定了元音之后,可以使用图13所示的图。例如,处理器210可以使用第一共振峰至第三共振峰的相对位置关系按照时间顺序来确定元音“u”和“i”。
处理器210可以为所确定的元音分配权重(s1140)。例如,处理器210为所确定的元音分配的权重的值可以高于其它元音的权重。
同时,处理器210可以使用从谐振式传感器100包括的所有谐振器接收的电信号来生成带梯度的位图(s1150)。具体地,处理器210可以使用从谐振式传感器100包括的所有谐振器接收的电信号来计算并编码谐振带的幅度差,以生成带梯度的位图。在操作s1150中,处理器210使用从所有谐振器接收的电信号来生成带梯度的位图。然而,处理器210可以使用从某些谐振器接收到的电信号来生成带梯度的位图。与元音确定相比,该带梯度的位图需要包括与说话者的语音相关的更详细的信息,且因此该带梯度的位图的数量可以大于用于元音确定的谐振器的数量。
处理器210可以使用所生成的带梯度的位图来生成说话者特征值(s1160)。处理器210可以使用快速傅立叶变换(fft)、2d离散余弦变换(dct)、动态时间扭曲(dtw)、人工神经网络、矢量量化(vq)、高斯混合模型(gmm)等,根据带梯度的位图来生成说话者特征值。说话者特征值可以被转换成能够与认证模板进行比较的形式。在该转换处理中,处理器210可以使用通用背景模型(ubm)。
处理器210可以通过使用权重将已转换的说话者特征值与认证模板进行比较,来识别说话者(s1170)。处理器210可以对认证模板中与所确定的元音分量相对应的模型应用高的权重,且对其它元音分量应用低的权重。例如,当所确定的元音是[u]和[i]时,处理器210可以对认证模板中与分量[u]和[i]相对应的模型应用高的权重,并且对其它分量应用低的权重,以将经转换的说话者特征值与认证模板进行比较。当比较结果大于或等于参考值时,处理器210可以确定发声的说话者是已注册的说话者,且当比较结果小于参考值时,处理器210可以确定发声的说话者不是已注册的说话者。
所分配的权重可以是1或0。即,处理器210可以仅使用认证模板的与所确定的元音相对应的模型来进行比较。
图15是用于说明在短语音中说话者特征值和认证模板之间的比较的参考图。在图15中,阴影区域表示ubm模型,+图案区域表示个性化的说话者模型(即,已注册的认证模板),且▲表示说话者特征值。例如,当说话者简短地说出“we”时,处理器210可以获得[u]和[i]作为所说出的元音分量。当处理器210生成了说话者特征值1230时,元音分量[u]和[i]可以是指示说话者的特征。因此,当认证模板中的与元音分量[u]和[i]相对应的模型1210的权重高且与其他元音分量相对应的模型1220的权重低时,在确定针对说话者特征值1230的相似度时,所发出的元音分量1210的影响就高,且因此可以增加说话者识别的准确性。
生成说话者特征值的操作s1150和s1160以及分配权重的操作s1120至s1140不一定顺序执行,而是这两个处理可以同时执行,或者用于分配权重的处理的某些操作可以首先执行,随后可以执行生成说话者特征值的操作s1150和s1160。例如,图1所示的谐振式传感器100可以进行使用具有不同频带的四个谐振器根据说话者的语音来确定元音的操作s1130,且与此同时可以进行使用从所有谐振器r1、r2、...、rn输出的信号来生成带梯度的位图的操作s1150。
尽管上文已经描述了使用带梯度的位图和元音确定来识别说话者的方法,但是可以仅仅使用带梯度的位图来识别说话者。例如,在确保通过使用预定的特定单词(例如,“start”)来识别说话者的情况下,可以仅通过与特定说话者的“start”相对应的个性化的模型来识别认证模板。在这种情况下,可以仅使用带梯度的位图来识别说话者,且可以不需要使用元音确定。备选地,即使是在指定说话者随机说出单词、短语或者句子时,认证模板也可能需要大量的个性化模型以进行识别。在这种情况下,个性化的模型可以按元音分类,并且可以将与所确定的元音相对应的模型用于比较识别。此外,可以通过将按元音分配的权重应用于使用除了带梯度的位图之外的方法所生成的说话者的特征值,来识别说话者。如上文所述,在根据本公开的使用谐振器的说话者识别方法和设备中,谐振式传感器100可以包括具有各种类型的多个机械谐振器。谐振式传感器100可以具有各种形状,而且其所包括的谐振器的形状或布置可以根据需要进行选择。谐振式传感器100中所包括的谐振器的中心频率可以通过调整图2中所示的支撑单元14的长度l来改变。谐振式传感器100中的谐振器可以根据用户需要被形成具有各种的中心频率间隔。
图16和图17是示出了根据示例实施例的将谐振式传感器100a的多个谐振器的中心频率设置为等间隔的示例的图。
参考图16,谐振器rm的中心频率可以与谐振器长度(即,图2中所示的支撑单元14的长度l的平方)成反比。因此,如图17所示,当相邻谐振器rm之间的长度差恒定时,谐振式传感器100a中包括的谐振器rm可以使得具有相对低频率的中心频率的谐振器的比例要高于具有高频率区域的中心频率的谐振器的比例。
图18和图19是示出了根据示例实施例的将谐振式传感器100b的多个谐振器的中心频率设置为恒定间隔的示例的图。
参考图18和图19,谐振式传感器100b中包括的谐振器rn可以被形成为使得彼此相邻的谐振器rn之间的长度差异从长谐振器到短谐振器逐渐减小。在这种情况下,谐振器rn的中心频率的差异可以被设置成具有均匀恒定的间隔。
图20和图21是示出了根据示例实施例的将谐振式传感器100c的多个谐振器的中心频率设置为任意间隔的示例的图。
参考图20和图21,谐振式传感器100c可以被形成为使得谐振式传感器100c中包括的谐振器ro的长度的间隔不具有特定规律。例如,在图21中,为了增加具有在2000至3000hz范围内的中心频率的谐振器的比例,可以调整某些间隔中的谐振器的长度。
如上文所述,在根据本公开的使用谐振器的说话者识别方法和设备中,谐振式传感器100、100a、100b和100c可以包括具有相等间隔和恒定间隔的谐振频率的谐振器、或具有任意频带的谐振频率的谐振器。
图22是根据示例实施例的包括多个谐振器在内的谐振式传感器100d的示意结构的平面图。
参考图22,谐振式传感器100d可以包括:支撑单元30,其具有在其中心部分形成的腔体或通孔40;以及多个谐振器r,其从支撑单元30延伸并环绕腔体或通孔40。在图1中,谐振式传感器100的谐振器r1、r2、...、rn在一个方向上延伸,反之如图22所示,根据本公开的谐振式传感器100d可以被形成为具有各种结构。
图23至图25是示出了根据示例实施例的谐振式传感器的多个谐振器的各种带宽变化的示例的图。
根据本公开的谐振式传感器可以缩窄谐振器的频带,以根据需要或为了提高特定频带的分辨率而改变谐振器的频带的频率间隔。例如,图23中的谐振器频率带宽被称为参考带宽s11时,在图24的情况下,谐振器可以被形成为具有比参考带宽s11窄的带宽s12。此外,如图25所示,谐振器可以被形成为具有比图23的参考带宽s11宽的带宽s13。
图26是示出了根据示例实施例的谐振式传感器的多个谐振器中的特定谐振器的带宽被设置得较宽的图。
参考图26,用于确定图3中的输入信号的元音的谐振式传感器100的特定谐振器的带宽s22可以被形成为比谐振式传感器100中的其余谐振器的带宽s21相对大,使得可以更高效地执行确定输入信号的元音的处理。
如上文所述的说话者识别方法和设备可以被应用于各种领域。例如,该说话者识别方法和设备可以通过基于语音信号准确地识别说话者是否是已注册的说话者,来操作或解锁在移动设备、家庭或车辆中所采用或安装的特定设备。
已经描述并在附图中示出了示例性的实施例,以便于理解上述技术原理。然而,需要理解的是:这些实施例仅仅是说明性的且不限制所要求的权利的范围。
- 还没有人留言评论。精彩留言会获得点赞!