具有施加的责任约束的导航系统的制作方法
本申请要求2016年12月23日提交的美国临时专利申请第62/438,563号、2017年8月16日提交的美国临时专利申请第62/546,343号、2017年9月29日提交的美国临时专利申请第62/565,244号、以及2017年11月7日提交的美国临时专利申请第62/582,687号的优先权权益。所有前述申请通过引用整体并入本文。
本公开总体涉及自主车辆导航。此外,本公开涉及根据潜在事故责任约束进行导航的系统和方法。
背景技术:
随着技术的不断进步,能够在车行道上导航的完全自主车辆的目标即将出现。自主车辆可能需要考虑各种各样的因素,并且基于那些因素做出适当的决定,以安全和准确地到达期望的目的地。例如,自主车辆可能需要处理和解释可视信息(例如,从相机捕捉的信息)、来自雷达或激光雷达的信息,并且也可能使用从其它源(例如,从gps设备、速度传感器、加速度计、悬架传感器等)获得的信息。同时,为了导航到目的地,自主车辆还可能需要标识其在特定车行道内(例如,在多车道道路内的特定车道)的地点、沿着其它车辆旁边导航、避开障碍和行人、观察交通信号和标志、在适当的交叉路口或交汇处从一条道路行进到另一条道路,并对车辆运行期间发生或进展的任何其他情况作出响应。此外,导航系统可能需要遵守某些施加的约束。在一些情况下,这些约束可以涉及主车辆和一个或多个其他对象(诸如其他车辆、行人等)之间的交互。在其他情况下,约束可能涉及在为主车辆实施一个或多个导航动作时要遵循的责任规则。
在自主驾驶领域,可行的自主车辆系统有两个重要的考虑。第一是安全保证(assurance)的标准化,包括每辆自驾驶汽车必须满足以保证安全的要求,以及如何验证这些要求。第二是可扩展性,因为导致释放成本的工程解决方案不会扩展到数百万辆汽车,并且可能会阻止自主汽车的广泛采用或甚至不那么广泛的采用。因此,需要一种用于安全保证的可解释的数学模型、以及一种遵守安全保证要求同时可扩展到数百万辆汽车的系统设计。
技术实现要素:
与本公开一致的实施例提供了用于自主车辆导航的系统和方法。所公开的实施例可以使用相机来提供自主车辆导航特征。例如,与所公开的实施例一致,所公开的系统可以包括一个、两个或更多个监控车辆环境的相机。所公开的系统可以基于例如对由一个或多个相机捕捉的图像的分析来提供导航响应。导航响应还可以考虑其他数据,包括例如全球定位系统(globalpositioningsystem,gps)数据、传感器数据(例如,来自加速度计、速度传感器、悬架传感器等)、和/或其他地图数据。
提供了用于导航主车辆的系统和方法。在一些实施例中,系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定用于实现主车辆的导航目标的规划导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;针对至少一个事故责任规则对规划导航动作测试,以确定主车辆相对于所识别的目标车辆的潜在事故责任;如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取规划导航动作,存在主车辆的潜在事故责任,则使得主车辆不实施规划导航动作;并且如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取规划导航动作,不会产生主车辆的事故责任,则使得主车辆实施规划导航动作。
在一些实施例中,用于主车辆的导航系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定主车辆的多个潜在导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;针对至少一个事故责任规则对多个潜在导航动作测试,以确定主车辆相对于所识别的目标车辆的潜在事故责任;选择潜在导航动作中的、对其的测试指示如果采取所选择的潜在导航动作不会产生主车辆的事故责任的一个潜在导航动作;以及使得主车辆实施所选择的潜在导航动作。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定用于实现主车辆的导航目标的两个或更多个规划导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;针对至少一个事故责任规则对两个或更多个规划导航动作中的每一个测试,以确定潜在事故责任;对于两个或更多个规划导航动作中的每一个,如果测试指示如果采取两个或更多个规划导航动作中的特定一个,存在主车辆的潜在事故责任,则使得主车辆不实施规划导航动作中的该特定一个;并且对于两个或更多个规划导航动作中的每一个,如果测试指示如果采取两个或更多个规划导航动作中的特定一个,不会产生主车辆的事故责任,则将两个或更多个规划导航动作中的该特定一个识别为供实施的可行候选;基于至少一个成本函数,从供实施的可行候选当中选择要采取的导航动作;以及使得主车辆实施所选择的导航动作。
在一些实施例中,用于主车辆的事故责任跟踪系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;分析至少一个图像以识别主车辆的环境中的目标车辆;基于对至少一个图像的分析,确定所识别的目标车辆的导航状态的一个或多个特性;将所识别的目标车辆的导航状态的所确定的一个或多个特性与至少一个事故责任规则进行比较;基于所识别的目标车辆的导航状态的所确定的一个或多个特性与至少一个事故责任规则的比较,存储指示所识别的目标车辆方的潜在事故责任的至少一个值;以及在主车辆和至少一个目标车辆之间发生事故之后,输出存储的至少一个值,用于确定事故的责任。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定用于实现主车辆的导航目标的规划导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;针对至少一个事故责任规则对规划导航动作测试,以确定潜在事故责任;如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取规划导航动作,存在主车辆的潜在事故责任,则使得主车辆不实施规划导航动作;并且如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取规划导航动作,不会产生主车辆的事故责任,则使得主车辆实施规划导航动作;并且其中该至少一个处理设备还被编程为:基于对至少一个图像的分析,确定所识别的目标车辆的导航状态的一个或多个特性;将所识别的目标车辆的导航状态的所确定的一个或多个特性与至少一个事故责任规则进行比较;以及基于所识别的目标车辆的导航状态的所确定的一个或多个特性与至少一个事故责任规则的比较,存储指示所识别的目标车辆方的潜在事故责任的至少一个值。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定用于实现主车辆的导航目标的规划导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;确定如果采取了规划导航动作将会产生的主车辆和目标车辆之间的下一状态距离;确定主车辆的当前最大制动能力和主车辆的当前速度;基于目标车辆的至少一个识别的特性,确定目标车辆的当前速度并假设目标车辆的最大制动能力;并且如果给定主车辆的最大制动能力和主车辆的当前速度,主车辆可以在小于所确定的下一状态距离与基于目标车辆的当前速度和所假设的目标车辆的最大制动能力而确定的目标车辆行驶距离之和的停止距离内停止,则实施规划导航动作。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定用于实现主车辆的导航目标的规划导航动作;分析至少一个图像,以识别主车辆前方的第一目标车辆和第一目标车辆前方的第二目标车辆;确定如果采取了规划导航动作将会产生的主车辆和第二目标车辆之间的下一状态距离;确定主车辆的当前最大制动能力和主车辆的当前速度;并且如果给定主车辆的最大制动能力和主车辆的当前速度,主车辆可以在小于所确定的主车辆和第二目标车辆之间的下一状态距离的停止距离内停止,则实施规划导航动作。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;分析至少一个图像以识别主车辆的环境中的目标车辆;确定用于实现主车辆的导航目标的两个或更多个潜在导航动作;针对至少一个事故责任规则对两个或更多个潜在导航动作中的每一个测试,以对于两个或更多个潜在导航动作中的每一个,确定主车辆和所识别的目标车辆之间的潜在事故责任的指示符;并且仅当与所选择的动作相关联的潜在事故责任的指示符指示没有潜在事故责任将由于实施所选择的动作而归给主车辆时,才选择两个或更多个潜在导航动作中的一个来实施。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该至少一个处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;从至少一个传感器接收主车辆的当前导航状态的指示符;基于对至少一个图像的分析并基于主车辆的当前导航状态的指示符,确定主车辆和一个或多个对象之间的碰撞是不可避免的;基于至少一个驾驶策略,确定涉及与第一对象的预期碰撞的、主车辆的第一规划导航动作和涉及与第二对象的预期碰撞的、主车辆的第二规划导航动作;针对至少一个事故责任规则测试第一和第二规划导航动作,以确定潜在事故责任;如果针对至少一个事故责任规则对第一规划导航动作的测试指示:如果采取第一规划导航动作,存在主车辆的潜在事故责任,则使得主车辆不实施所述第一规划导航动作;并且如果针对至少一个事故责任规则对第二规划导航动作的测试指示:如果采取第二规划导航动作,不会产生主车辆的事故责任,则使得主车辆实施第二规划导航动作。
与其他公开的实施例一致,非暂时性计算机可读存储介质可以存储程序指令,这些程序指令可由至少一个处理设备执行,并执行本文描述的任何步骤和/或方法。
前面的一般描述和下面的详细描述仅仅是示例性和解释性的,而不是对权利要求的限制。
附图说明
并入本公开中并构成本公开的一部分的附图示出所公开的各种实施例。在附图中:
图1是与所公开的实施例一致的示例系统的图示性表示。
图2a是包括与所公开的实施例一致的系统的示例车辆的图示性侧视图表示。
图2b是与所公开的实施例一致的图2a中所示的车辆和系统的图示性顶视图表示。
图2c是包括与所公开的实施例一致的系统的车辆的另一实施例的图示性顶视图表示。
图2d是包括与所公开的实施例一致的系统的车辆的又一实施例的图示性顶视图表示。
图2e是包括与所公开的实施例一致的系统的车辆的又一实施例的图示性顶视图表示。
图2f是与所公开的实施例一致的示例车辆控制系统的图示性表示。
图3a是与所公开的实施例一致的、包括后视镜和用于车辆成像系统的用户界面的车辆的内部的图示性表示。
图3b是与所公开的实施例一致的、配置为位置在后视镜之后并抵靠车辆挡风玻璃的相机安装的示例的图示。
图3c是与所公开的实施例一致的图3b中所示的相机安装从不同的视角的图示。
图3d是与所公开的实施例一致的、配置为位于后视镜之后并抵靠车辆挡风玻璃的相机安装的示例的图示。
图4是与所公开的实施例一致的、配置为存储用于执行一个或多个操作的指令的存储器的示例框图。
图5a是示出与所公开的实施例一致的、用于基于单目图像分析引起一个或多个导航响应的示例处理的流程图。
图5b是示出与所公开的实施例一致的、用于在一组图像中检测一个或多个车辆和/或行人的示例处理的流程图。
图5c是示出与所公开的实施例一致的、用于在一组图像中检测道路标记和/或车道几何信息的示例处理的流程图。
图5d是示出与所公开的实施例一致的、用于在一组图像中检测交通灯的示例处理的流程图。
图5e是示出与所公开的实施例一致的、用于基于车辆路径引起一个或多个导航响应的示例处理的流程图。
图5f是示出与所公开的实施例一致的、用于确定前方车辆是否正在改变车道的示例处理的流程图。
图6是示出与所公开的实施例一致的、用于基于立体图像分析引起一个或多个导航响应的示例处理的流程图。
图7是示出与所公开的实施例一致的、用于基于三组图像的分析引起一个或多个导航响应的示例处理的流程图。
图8是与所公开的实施例一致的、可由自主车辆的导航系统的一个或多个专门编程的处理设备来实现的模块的框图表示。
图9是与所公开的实施例一致的导航选项图。
图10是与所公开的实施例一致的导航选项图。
图11a、图11b和图11c提供了与所公开的实施例一致的并道区(mergezone)中的主车辆的导航选项的示意表示。
图11d提供了与所公开的实施例一致的双并道场景的图示性描述。
图11e提供了与所公开的实施例一致的、在双并道场景中潜在有用的选项图。
图12提供了与所公开的实施例一致的、捕捉了主车辆的环境的表示性图像以及潜在导航约束的图。
图13提供了与所公开的实施例一致的、用于导航车辆的算法流程图。
图14提供了与所公开的实施例一致的、用于导航车辆的算法流程图。
图15提供了与所公开的实施例一致的、用于导航车辆的算法流程图。
图16提供了与所公开的实施例一致的、用于导航车辆的算法流程图。
图17a和17b提供了与所公开的实施例一致的、导航进入环形道的主车辆的图示性图示。
图18提供了与所公开的实施例一致的、用于导航车辆的算法流程图。
图19示出了与所公开的实施例一致的、在多车道高速公路上行驶的主车辆的示例。
图20a和20b示出了与所公开的实施例一致的、正在另一车辆前方切入的车辆的示例。
图21示出了与所公开的实施例一致的、正在跟随另一车辆的车辆的示例。
图22示出了与所公开的实施例一致的、正在离开停车场并且并入可能繁忙的道路的车辆的示例。
图23示出了与所公开的实施例一致的、正在在道路上行驶的车辆。
图24a-24d示出了与所公开的实施例一致的四个示例场景。
图25示出了与所公开的实施例一致的示例场景。
图26示出了与所公开的实施例一致的示例场景。
图27示出了与所公开的实施例一致的示例场景。
图28a和28b示出了与所公开的实施例一致的、车辆正在跟随另一车辆的场景的示例。
图29a和29b示出了与所公开的实施例一致的切入场景中的示例归责(blame)。
图30a和30b示出了与所公开的实施例一致的切入场景中的示例归责。
图31a-31d示出了与所公开的实施例一致的漂移场景中的示例归责。
图32a和32b示出了与所公开的实施例一致的双向交通场景中的示例归责。
图34a和34b示出了与所公开的实施例一致的路线优先级场景中的示例归责。
图35a和35b示出了与所公开的实施例一致的路线优先级场景中的示例归责。
图36a和36b示出了与所公开的实施例一致的路线优先级场景中的示例归责。
图37a和37b示出了与所公开的实施例一致的路线优先级场景中的示例归责。
图38a和38b示出了与所公开的实施例一致的路线优先级场景中的示例归责。
图39a和39b示出了与所公开的实施例一致的路线优先级场景中的示例归责。
图40a和40b示出了与所公开的实施例一致的交通灯场景中的示例归责。
图41a和41b示出了与所公开的实施例一致的交通灯场景中的示例归责。
图42a和42b示出了与所公开的实施例一致的交通灯场景中的示例归责。
图43a-43c示出了与所公开的实施例一致的示例弱势道路使用者(vulnerableroaduser,vru)场景。
图44a-44c示出了与所公开的实施例一致的示例弱势道路使用者(vru)场景。
图45a-45c示出了与所公开的实施例一致的示例弱势道路使用者(vru)场景。
图46a-46d示出了与所公开的实施例一致的示例弱势道路使用者(vru)场景。
具体实施方式
接下来的详细描述参考附图。只要可能,在附图和接下来的描述中使用相同的附图标记来指代相同或相似的部分。尽管本文描述了若干示例性实施例,但是修改、调整和其它实施方式是可能的。例如,可以对附图中示出的组件做出替换、添加或修改,并且可以通过对所公开的方法进行步骤的替换、重新排序、移除或添加,来对本文描述的示例性方法进行修改。因此,接下来的详细描述并不限于所公开的实施例和示例。相反,适当的范围由所附权利要求限定。
自主车辆概览
如贯穿本公开所使用的,术语“自主车辆”是指在没有驾驶员输入的情况下能够实现至少一个导航改变的车辆。“导航改变”是指车辆的转向、制动、或加速/减速中的一个或多个。所谓自主,是指车辆不需要是完全自动的(例如,在没有驾驶员或没有驾驶员输入的情况下完全可操作的)。相反,自主车辆包括能够在某些时间段期间在驾驶员的控制下操作,且能够在其他时间段期间无需驾驶员控制而操作的那些车辆。自主车辆还可以包括仅控制车辆导航的某些方面(诸如转向(例如,在车辆车道约束之间维持车辆路线)或在某些情况下(但并非在所有情况下)的某些转向操作),但可以将其它方面交给驾驶员(例如,制动或在某些情况下的制动)的车辆。在一些情况下,自主车辆可以处理车辆的制动、速率控制和/或转向的某些或全部方面。
由于人类驾驶员通常依赖于可视线索和观察以便控制车辆,因此而建造了交通基础设施,其带有被设计为向驾驶员提供可视信息的车道标记、交通标志和交通灯。鉴于交通基础设施的这些设计特性,自主车辆可以包括相机以及分析从车辆的环境捕捉的可视信息的处理单元。可视信息可以包括,例如表示可由驾驶员观察到的交通基础设施的组件(例如,车道标记、交通标志、交通灯等)以及其它障碍物(例如,其它车辆、行人、碎片等)的图像。此外,自主车辆还可以使用存储的信息,诸如在导航时提供车辆环境的模型的信息。例如,车辆可以使用gps数据、传感器数据(例如,来自加速计、速度传感器、悬架传感器等)和/或其它地图数据,以在车辆正在行驶的同时提供与其环境有关的信息,并且该车辆(以及其它车辆)可以使用该信息在模型上对其自身定位。一些车辆也能够在车辆之间进行通信、共享信息、改变同伴车辆的危险或车辆周围的变化等。
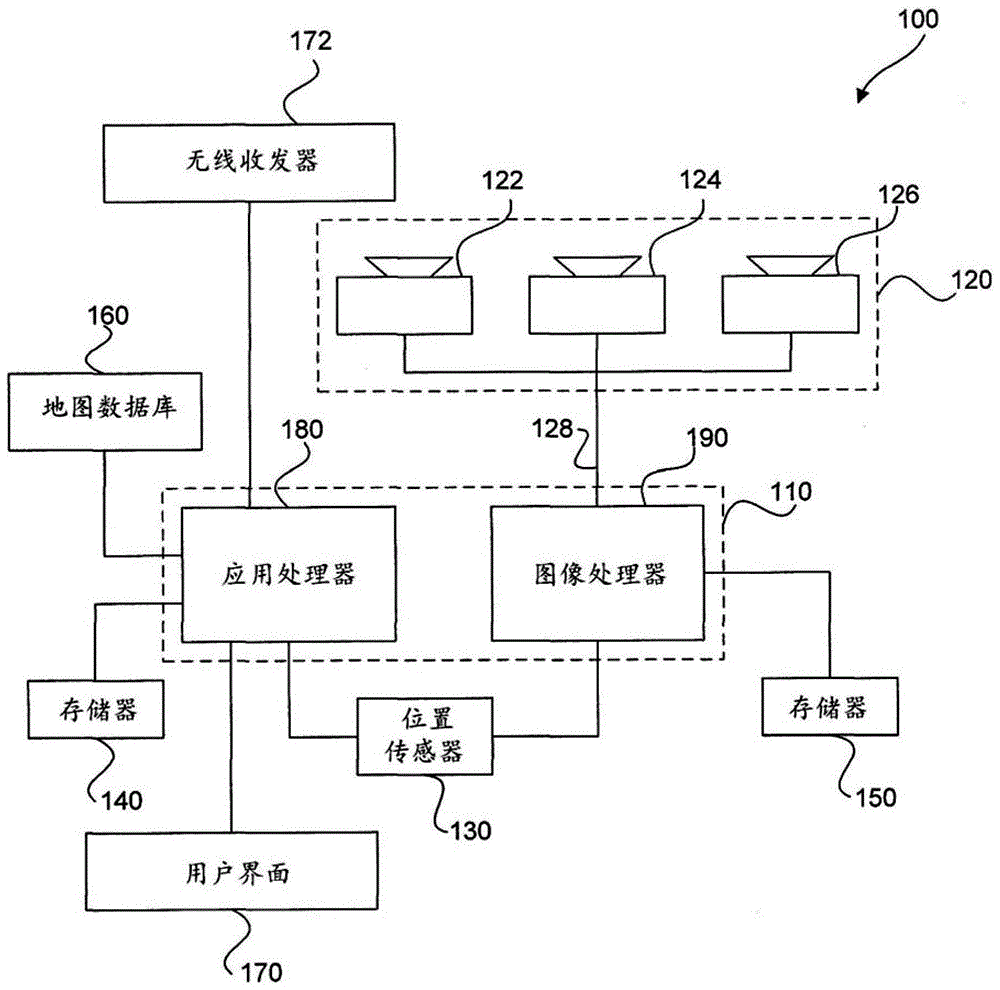
系统概览
图1是与所公开的示例实施例一致的系统100的框图表示。取决于特定实施方式的要求,系统100可以包括各种组件。在一些实施例中,系统100可以包括处理单元110、图像获取单元120、位置传感器130、一个或多个存储器单元140、150、地图数据库160、用户界面170和无线收发器172。处理单元110可以包括一个或多个处理设备。在一些实施例中,处理单元110可以包括应用处理器180、图像处理器190或任何其它合适的处理设备。类似地,取决于特定应用的要求,图像获取单元120可以包括任意数量的图像获取设备和组件。在一些实施例中,图像获取单元120可以包括一个或多个图像捕捉设备(例如,相机、电荷耦合器件(ccd)或任意其他类型的图像传感器),诸如图像捕捉设备122、图像捕捉设备124和图像捕捉设备126。系统100还可以包括将处理单元110通信地连接到图像获取单元120的数据接口128。例如,数据接口128可以包括用于将由图像获取单元120获取的图像数据传输到处理单元110的任何有线和/或无线的一个或多个链路。
无线收发器172可以包括被配置为通过使用射频、红外频率、磁场、或电场来交换通过空中接口到一个或多个网络(例如,蜂窝、因特网等)的传输的一个或多个设备。无线收发器172可以使用任何熟知的标准来发送和/或接收数据(例如,wi-fi、
应用处理器180和图像处理器190两者都可以包括各种类型的基于硬件的处理设备。例如,应用处理器180和图像处理器190中的任一者或两者可以包括微处理器、预处理器(诸如图像预处理器)、图形处理器、中央处理单元(cpu)、辅助电路、数字信号处理器、集成电路、存储器或适用于运行应用和适用于图像处理和分析的任何其它类型的设备。在一些实施例中,应用处理器180和/或图像处理器190可以包括任何类型的单核或多核处理器、移动设备微控制器、中央处理单元等。可以使用各种处理设备,包括例如可从诸如
在一些实施例中,应用处理器180和/或图像处理器190可以包括可从
任何本文所公开的处理设备可以被配置为执行某些功能。配置处理设备(诸如任何所描述的eyeq处理器或其它控制器或微处理器)以执行某些功能可以包括对计算机可执行指令的编程,并使处理设备在其操作期间可获得这些指令以用于执行。在一些实施例中,配置处理设备可以包括直接利用架构指令对处理设备编程。在其它实施例中,配置处理设备可以包括将可执行指令存储在操作期间处理设备可访问的存储器上。例如,处理设备在操作期间可以访问该存储器以获得并执行所存储的指令。在任一情况下,被配置为执行本文公开的感测、图像分析和/或导航功能的处理设备表示控制主车辆的多个基于硬件的组件的专用的基于硬件的系统。
尽管图1描绘了包含在处理单元110中的两个单独的处理设备,但是可以使用更多或更少的处理设备。例如,在一些实施例中,可以使用单个处理设备完成应用处理器180和图像处理器190的任务。在其它实施例中,这些任务可以由两个以上的处理设备执行。另外,在一些实施例中,系统100可以包括一个或多个处理单元110,而不包括诸如图像获取单元120之类的其它组件。
处理单元110可以包括各种类型的设备。例如,处理单元110可以包括各种设备,诸如控制器、图像预处理器、中央处理单元(cpu)、辅助电路、数字信号处理器、集成电路、存储器或任何其它类型的用于图像处理和分析的设备。图像预处理器可以包括用于捕捉、数字化和处理来自图像传感器的影像的视频处理器。cpu可以包括任何数量的微控制器或微处理器。辅助电路可以是任何数量的本领域公知的电路,包括高速缓存、电力供给、时钟和输入输出电路。存储器可以存储软件,该软件在由处理器执行时控制系统的操作。存储器可以包括数据库和图像处理软件。存储器可以包括任何数量的随机存取存储器、只读存储器、闪速存储器、磁盘驱动器、光存储、磁带存储、可移动存储和其它类型的存储。在一个实例中,存储器可以与处理单元110分离。在另一实例中,存储器可以被集成到处理单元110中。
每个存储器140、150可以包括软件指令,该软件指令在由处理器(例如,应用处理器180和/或图像处理器190)执行时可以控制系统100的各个方面的操作。例如,这些存储器单元可以包括各种数据库和图像处理软件,以及经训练的系统,诸如神经网络和深度神经网络。存储器单元可以包括随机存取存储器、只读存储器、闪速存储器、磁盘驱动器、光存储、磁带存储、可移动存储和/或任何其它类型的存储。在一些实施例中,存储器单元140、150可以与应用处理器180和/或图像处理器190分离。在其它实施例中,这些存储器单元可以被集成到应用处理器180和/或图像处理器190中。
位置传感器130可以包括适用于确定与系统100的至少一个组件相关联的位置的任何类型的设备。在一些实施例中,位置传感器130可以包括gps接收器。这种接收器可以通过处理由全球定位系统卫星广播的信号来确定用户位置和速度。可以使得来自位置传感器130的位置信息对于应用处理器180和/或图像处理器190可用。
在一些实施例中,系统100可以包括诸如用于测量车辆200的速率的速度传感器(例如,速度计)之类的组件。系统100还可以包括用于测量车辆200沿一个或多个轴的加速度的一个或多个加速度计(单轴或多轴的)。
存储器单元140、150可以包括数据库,或以任何其他形式组织的、指示已知地标的位置的数据。环境的传感信息(诸如来自激光雷达或两个或更多个图像的立体处理的图像、雷达信号、深度信息)可以与位置信息(诸如gps坐标、车辆的自我运动等)一起处理,以确定车辆相对于已知地标的当前位置,并且改进车辆位置。这项技术的某些方面包含于被称为remtm的定位技术中,该技术由本申请的受让人销售。
用户界面170可以包括适用于向系统100的一个或多个用户提供信息或从系统100的一个或多个用户接收输入的任何设备。在一些实施例中,用户界面170可以包括用户输入设备,包括例如触摸屏、麦克风、键盘、指针设备、跟踪转轮、相机、旋钮、按钮等。利用这样的输入设备,用户能够通过键入指令或信息、提供语音命令、使用按钮、指针或眼睛跟踪能力在屏幕上选择菜单选项、或通过任何其它适用于向系统100传送信息的技术来向系统100提供信息输入或命令。
用户界面170可以配备有一个或多个处理设备,其配置为向用户提供和从用户接收信息,并处理该信息以由例如应用处理器180使用。在一些实施例中,这样的处理设备可以执行指令以辨识和跟踪眼睛运动、接收和解释语音命令、辨识和解释在触摸屏上做出的触摸和/或手势、响应键盘输入或菜单选择等。在一些实施例中,用户界面170可以包括显示器、扬声器、触觉设备和/或任何其它用于向用户提供输出信息的设备。
地图数据库160可以包括任何类型的用于存储对系统100有用的地图数据的数据库。在一些实施例中,地图数据库160可以包括与各种项目在参考坐标系统中的位置有关的数据,各种项目包括道路、水特征、地理特征、商业区、感兴趣的点、餐馆、加油站等。地图数据库160不仅可以存储这些项目的位置,而且可以存储与这些项目有关的描述符,包括例如与任何所存储的特征相关联的名称。在一些实施例中,地图数据库160可以与系统100的其它部件在物理上位于一起。替代或附加地,地图数据库160或其一部分可以相对于系统100的其它组件(例如,处理单元110)位于远处。在这种实施例中,来自地图数据库160的信息可以通过与网络的有线或无线数据连接(例如,通过蜂窝网络和/或因特网等)而下载。在一些情况下,地图数据库160可以存储稀疏数据模型,该稀疏数据模型包括某些道路特征(例如,车道标记)或主车辆的目标轨迹的多项式表示。地图数据库160还可以包括已存储的各种辨识出的地标的表示,该地标的表示可用于确定或更新主车辆相对于目标轨迹的已知位置。地标表示可以包括数据字段,诸如地标类型、地标位置以及其他潜在标识符。
图像捕捉设备122、124和126均可以包括任何类型的适用于从环境捕捉至少一个图像的设备。此外,可以使用任何数量的图像捕捉设备来获取用于输入到图像处理器的图像。一些实施例可以仅包括单个图像捕捉设备,而其它实施例可以包括两个、三个、或甚至四个、或更多个图像捕捉设备。以下将参考图2b至图2e进一步描述图像捕捉设备122、124和126。
一个或多个相机(例如,图像捕捉设备122、124和126)可以是包括在车辆上的感测块的一部分。感测块中可以包括各种其他传感器,并且可以依靠这些传感器中的任何或全部,以形成车辆的感测的导航状态。除了相机(前方、侧方、后方等)之外,其他传感器(诸如雷达、激光雷达和声学传感器)可被包含在感测块中。另外,感测块可以包括一个或多个组件,该组件被配置为传送和发送/接收与车辆的环境有关的信息。例如,这种组件可以包括无线收发器(rf等),其可以从相对于主车辆位于远处的源接收基于传感器的信息或与主车辆的环境有关的任何其他类型的信息。这些信息可以包括从主车辆以外的车辆系统接收的传感器输出信息或相关信息。在一些实施例中,这些信息可以包括从远程计算设备、中央服务器等接收的信息。此外,相机可以采用许多不同的配置:单个相机单元、多个相机、相机群、长fov、短fov、广角、鱼眼等。
系统100或其各种组件可以合并到各种不同的平台中。在一些实施例中,系统100可以被包括在车辆200上,如图2a所示。例如,车辆200可以配备有如上关于图1描述的系统100的处理单元110和任何其它组件。在一些实施例中,车辆200可以仅配备有单个图像捕捉设备(例如,相机),而在其它实施例中,诸如结合图2b至图2e所讨论的那些实施例,可以使用多个图像捕捉设备。例如,图2a中所示的车辆200的图像捕捉设备122和124中的任一个可以是adas(advanceddriverassistancesystem,高级驾驶员辅助系统)成像集的一部分。
作为图像获取单元120的一部分的、被包括在车辆200上的图像捕捉设备,可以被置于任何合适的位置。在一些实施例中,如图2a至图2e,以及图3a至图3c中所示,图像捕捉设备122可以位于后视镜的附近。此位置可以提供与车辆200的驾驶员的视线相似的视线,这可以辅助确定对驾驶员而言什么是可视和不可视的。图像捕捉设备122可以被置于靠近后视镜的任何位置,而将图像捕捉设备122放置在镜子的驾驶员侧还可以辅助获得表示驾驶员的视场和/或视线的图像。
还可以使用图像获取单元120的图像捕捉设备的其它位置。例如,图像捕捉设备124可以位于车辆200的保险杠上或保险杠中。这种位置尤其可以适用于具有宽视场的图像捕捉设备。位于保险杠的图像捕捉设备的视线可以与驾驶员的视线不同,并且因此,保险杠图像捕捉设备和驾驶员可能不总是看到相同的对象。图像捕捉设备(例如,图像捕捉设备122、124和126)还可以位于其它位置中。例如,图像捕捉设备可以位于车辆200的侧视镜中的一者或两者之上或之中、车辆200的车顶上、车辆200的引擎盖上、车辆200的后备箱上、车辆200的侧面上、安装在车辆200的任何车窗上、置于车辆200的任何车窗的后面、或置于任何车窗的前面、以及安装在车辆200的前部和/或后部上的照明设备中或附近。
除了图像捕捉设备,车辆200还可以包括系统100的各种其它组件。例如,处理单元110可以被包括在车辆200上,与车辆的引擎控制单元(enginecontrolunit,ecu)集成或分离。车辆200还可以配备有诸如gps接收器之类的位置传感器130,并且还可以包括地图数据库160以及存储器单元140和150。
如早先讨论的,无线收发器172可以通过一个或多个网络(例如,蜂窝网络、因特网等)和/或接收数据。例如,无线收发器172可以将系统100收集的数据上传到一个或多个服务器,并且从一个或多个服务器下载数据。经由无线收发器172,系统100可以接收,例如对存储在地图数据库160、存储器140和/或存储器150中存储的数据的周期性更新或按需求更新。类似地,无线收发器172可以将来自系统100的任何数据(例如,由图像获取单元120捕捉的图像、由位置传感器130或其它传感器、车辆控制系统接收的数据等)和/或由处理单元110处理的任何数据上传到一个或多个服务器。
系统100可以基于隐私等级设置将数据上传到服务器(例如,上传到云)。例如,系统100可以实施隐私等级设置,以规定或限制发送到服务器的、可以唯一地标识车辆和/或车辆的驾驶员/所有者的数据(包括元数据)的类型。这些设置可以由用户经由例如无线收发器172来设置、可以由出厂默认设置、或由无线收发器172接收的数据来初始化。
在一些实施例中,系统100可以根据“高”隐私等级上传数据,并且在设定了设置的情况下,系统100可以传输数据(例如,与路途有关的位置信息、捕捉的图像等),而不带有任何关于特定车辆和/或驾驶员/所有者的细节。例如,当根据“高”隐私设置来上传数据时,系统100可以不包括车辆标识编号(vehicleidentificationnumber,vin)或车辆的驾驶员或所有者的名字,并且可以代替地传输数据(诸如,捕捉的图像和/或与路途有关的受限的位置信息)。
也可以考虑其它隐私等级。例如,系统100可以根据“中间”隐私等级向服务器传输数据,并且可以包括在“高”隐私等级下不包括的额外信息,诸如车辆的型号和/或模型和/或车辆类型(例如载客车辆、运动型多用途车辆、卡车等)。在一些实施例中,系统100可以根据“低”隐私等级上传数据。在“低”隐私等级设置下,系统100可以上传数据,并且包括足以唯一地标识特定车辆、所有者/驾驶员和/或车辆行驶过的部分路途或整个路途的信息。例如,这些“低”隐私等级数据可以包括以下中的一个或多个:vin、驾驶员/所有者姓名、出发之前车辆的源点、车辆的期望目的地、车辆的型号和/或模型、车辆类型等。
图2a是与所公开的实施例一致的、示例车辆成像系统的图示性侧视图表示。图2b是图2a中所示的实施例的图示性顶视图例示。如图2b所示,所公开的实施例可以包括车辆200,该车辆200在其车体中包括系统100,该系统100带有位于车辆200的后视镜附近和/或靠近驾驶员的第一图像捕捉设备122、位于车辆200的保险杠区域(例如,保险杠区域210中的一个)之上或之中的第二图像捕捉设备124、以及处理单元110。
如图2c所示,图像捕捉设备122和124两者可以都位于车辆200的后视镜附近和/或靠近驾驶员。此外,尽管图2b和图2c示出了两个图像捕捉设备122和124,应理解的是,其它实施例可以包括两个以上的图像捕捉设备。例如,在图2d和图2e中所示的实施例中,第一图像捕捉设备122、第二图像捕捉设备124和第三图像捕捉设备126被包括在车辆200的系统100中。
如图2d所示,图像捕捉设备122可以位于车辆200的后视镜附近和/或靠近驾驶员,并且图像捕捉设备124和126可以位于车辆200的保险杠区域(例如,保险杠区域210中的一个)之上或之中。并且如图2e所示,图像捕捉设备122、124和126可以位于车辆200的后视镜附近和/或靠近驾驶席。所公开的实施例不限于图像捕捉设备的任何特定数量和配置,并且图像捕捉设备可以位于车辆200内或车辆200上的任何合适的位置中。
应理解的是,所公开的实施例不限于车辆,并且可以被应用在其它情景中。还应理解,所公开的实施例不限于车辆200的特定类型,并且可以适用于所有类型的车辆,包括汽车、卡车、拖车和其它类型的车辆。
第一图像捕捉设备122可以包括任何合适类型的图像捕捉设备。图像捕捉设备122可以包括光轴。在一个实例中,图像捕捉设备122可以包括带有全局快门的aptinam9v024wvga传感器。在其它实施例中,图像捕捉设备122可以提供1280×960像素的分辨率,并且可以包括滚动快门。图像捕捉设备122可以包括各种光学元件。在一些实施例中,可以包括一个或多个镜头,例如用于为图像捕捉设备提供期望的焦距和视场。在一些实施例中,图像捕捉设备122可以与6毫米镜头或12毫米镜头相关联。在一些实施例中,如图2d所示,图像捕捉设备122可以配置为捕捉具有期望的视场(fov)202的图像。例如,图像捕捉设备122可以配置为具有常规fov,诸如在40度到56度的范围内,包括46度fov、50度fov、52度fov,或更大的fov。可替代地,图像捕捉设备122可以配置为具有在23至40度的范围内的窄fov,诸如28度fov或36度fov。此外,图像捕捉设备122可以配置为具有在100至180度的范围内的宽fov。在一些实施例中,图像捕捉设备122可以包括广角保险杠相机或者带有高达180度的fov的相机。在一些实施例中,图像捕捉设备122可以是带有大约2:1的高宽比(例如,h×v=3800×1900像素)、带有大约100度水平fov的7.2m(百万)像素图像捕捉设备。这种图像捕捉设备可以被用来替代三个图像捕捉设备配置。由于显著的镜头失真,在图像捕捉设备使用径向对称镜头的实施方式中,这种图像捕捉设备的垂直fov可以显著地小于50度。例如,这种镜头可以不是径向对称的,这将允许在100度水平fov情况下垂直fov大于50度。
第一图像捕捉设备122可以获取关于与车辆200相关联的场景的多个第一图像。多个第一图像中的每一个可以作为一系列的图像扫描线而被获取,其可使用滚动快门来捕捉。每个扫描线可以包括多个像素。
第一图像捕捉设备122可以具有与第一系列图像扫描线中的每一个的获取相关联的扫描速率。扫描速率可以指,图像传感器可以以该扫描速率获取与包含在特定扫描线中的每个像素相关联的图像数据。
图像捕捉设备122、124和126可以包含任何合适的类型和数量的图像传感器,例如,包括ccd传感器或cmos传感器等。在一个实施例中,可以采用cmos图像传感器以及滚动快门,以使得一行中的每个像素一次被读取一个,并且各行的扫描在逐行的基础上继续进行,直到已经捕捉了整个图像帧。在一些实施例中,可以相对于帧从顶部到底部顺序地捕捉各行。
在一些实施例中,本文公开的图像捕捉设备(例如,图像捕捉设备122、124和126)中的一个或多个可以构成高分辨率成像器,并且可以具有大于5m像素、7m像素、10m像素或更大像素的分辨率。
滚动快门的使用可能导致不同行中的像素在不同的时间被曝光和捕捉,这可能引起所捕捉的图像帧中的扭曲和其它图像伪像。另一方面,当图像捕捉设备122配置为利用全局或同步快门操作时,所有像素可以以相同的时间量并且在共同的曝光时段期间被曝光。其结果是,在从采用全局快门的系统收集的帧中的图像数据表示在一特定时间的整个fov(诸如fov202)的快照。与之相比,在滚动快门应用中,在不同的时间,帧中的每行被曝光并且数据被捕捉。因此,在具有滚动快门的图像捕捉设备中,移动对象可能出现失真。将在下面更详细地描述这种现象。
第二图像捕捉设备124和第三图像捕捉设备126可以是任何类型的图像捕捉设备。类似于第一图像捕捉设备122,图像捕捉设备124和126中的每一个可以包括光轴。在一个实施例中,图像捕捉设备124和126中的每一个可以包括带有全局快门的aptinam9v024wvga传感器。可替代地,图像捕捉设备124和126中的每一个可以包括滚动快门。类似于图像捕捉设备122,图像捕捉设备124和126可以配置为包括各种镜头和光学元件。在一些实施例中,与图像捕捉设备124和126相关联的镜头可以提供fov(诸如fov204和206),其等于或窄于与图像捕捉设备122相关联的fov(诸如fov202)。例如,图像捕捉设备124和126可以具有40度、30度、26度、23度、20度或更小的fov。
图像捕捉设备124和126可以获取关于与车辆200相关联的场景的多个第二图像和第三图像。该多个第二图像和第三图像中的每一个可以作为第二系列图像扫描线和第三系列图像扫描线而被获取,这可以使用滚动快门进行捕捉。每个扫描线或行可以具有多个像素。图像捕捉设备124和126可以具有与被包含在第二系列和第三系列中的每个图像扫描线的获取相关联的第二扫描速率和第三扫描速率。
每个图像捕捉设备122、124和126可以放置在相对于车辆200的任何合适的位置和方向处。可以选择图像捕捉设备122、124和126的相对位置以帮助将从图像捕捉设备获取的信息融合在一起。例如,在一些实施例中,与图像捕捉设备124相关联的fov(诸如fov204)可能部分地或完全地和与图像捕捉设备122相关联的fov(诸如fov202)以及与图像捕捉设备126相关联的fov(诸如fov206)重叠。
图像捕捉设备122、124和126可以位于车辆200上的任何合适的相对高度处。在一个实例中,在图像捕捉设备122、124和126之间可以存在高度差,其可以提供足够的视差信息以使能立体分析。例如,如图2a所示,两个图像捕捉设备122和124在不同的高度处。例如,在图像捕捉设备122、124和126之间还可以存在横向位移差,为处理单元110的立体分析给出了额外的视差信息。如图2c和图2d所示,横向位移的差异可以通过dx表示。在一些实施例中,图像捕捉设备122、124和126之间可能存在前向或后向位移(例如,范围位移)。例如,图像捕捉设备122可以位于图像捕捉设备124和/或图像捕捉设备126之后0.5到2米或以上。这种类型的位移可以使得图像捕捉设备之一能够覆盖其它(一个或多个)图像捕捉设备的潜在盲点。
图像捕捉设备122可以具有任何合适的分辨率能力(例如,与图像传感器相关联的像素的数量),并且与图像捕捉设备122相关联的(一个或多个)图像传感器的分辨率可以比与图像捕捉设备124和126相关联的(一个或多个)图像传感器的分辨率更高、更低、或者与之相同。在一些实施例中,与图像捕捉设备122和/或图像捕捉设备124和126相关联的(一个或多个)图像传感器可以具有640×480、1024×768、1280×960的分辨率,或任何其它合适的分辨率。
帧速率(例如,在该速率下,图像捕捉设备获取一个图像帧的一组像素数据,然后继续捕捉与下一个图像帧相关联的像素数据)可以是可控的。与图像捕捉设备122相关联的帧速率可以比与图像捕捉设备124和126相关联的帧速率更高、更低或与之相同。与图像捕捉设备122、124和126相关联的帧速率可以取决于可能影响帧速率的定时的各种因素。例如,图像捕捉设备122、124和126中的一个或多个可以包括可选择的像素延迟时段,其在获取与图像捕捉设备122、124和/或126中的图像传感器的一个或多个像素相关联的图像数据之前或之后施加。通常,可以根据用于该设备的时钟速率来获取对应于每个像素的图像数据(例如,每个时钟周期一个像素)。另外,在包括滚动快门的实施例中,图像捕捉设备122、124和126中的一个或多个可以包括可选择的水平消隐时段,其在获取与图像捕捉设备122、124和/或126中的图像传感器的一行像素相关联的图像数据之前或之后施加。此外,图像捕捉设备122、124和126中的一个或多个可以包括可选择的垂直消隐时段,其在获取与图像捕捉设备122、124和126的图像帧相关联的图像数据之前或之后施加。
这些定时控制可以使能与图像捕捉设备122、124和126相关联的帧速率的同步,即便每个的线扫描速率不同。此外,如将在下面更详细地讨论的,这些可选择的定时控制以及其它因素(例如,图像传感器分辨率、最大线扫描速率等)可以使能从图像捕捉设备122的fov与图像捕捉设备124和126的一个或多个fov重叠的区域的图像捕捉的同步,即便图像捕捉设备122的视场不同于图像捕捉设备124和126的fov。
图像捕捉设备122、124和126中的帧速率定时可以取决于相关联的图像传感器的分辨率。例如,假定对于两个设备,线扫描速率类似,如果一个设备包括具有640×480的分辨率的图像传感器,并且另一设备包括带有1280×960的分辨率的图像传感器,则需要更多的时间来从具有更高分辨率的传感器获取一帧图像数据。
可能影响图像捕捉设备122、124和126中的图像数据获取的定时的另一个因素是最大线扫描速率。例如,从被包含在图像捕捉设备122、124和126中的图像传感器获取一行图像数据将需要某个最低时间量。假定没有添加像素延迟时段,则用于获取一行图像数据的此最低时间量将与用于特定设备的最大线扫描速率有关。提供较高的最大线扫描速率的设备具有提供比带有较低的最大线扫描速率的设备更高的帧速率的潜力。在一些实施例中,图像捕捉设备124和126中的一个或多个可以具有高于与图像捕捉设备122相关联的最大线扫描速率的最大线扫描速率。在一些实施例中,图像捕捉设备124和/或126的最大线扫描速率可以是图像捕捉设备122的最大线扫描速率的1.25、1.5、1.75或2倍或更多倍。
在另一实施例中,图像捕捉设备122、124和126可以具有相同的最大线扫描速率,但图像捕捉设备122可以以小于或等于其最大扫描速率的扫描速率而操作。该系统可以配置为使得图像捕捉设备124和126中的一个或多个以等于图像捕捉设备122的线扫描速率的线扫描速率而操作。在其它实例中,该系统可以配置为使得图像捕捉设备124和/或图像捕捉设备126的线扫描速率可以是图像捕捉设备122的线扫描速率的1.25、1.5、1.75、或2倍或更多倍。
在一些实施例中,图像捕捉设备122、124和126可以是不对称的。也就是说,它们可包括具有不同视场(fov)和焦距的相机。例如,图像捕捉设备122、124和126的视场可以包括关于车辆200的环境的任何期望的区域。在一些实施例中,图像捕捉设备122、124和126中的一个或多个可以配置为从在车辆200前面、车辆200后面、车辆200的侧面、或其组合的环境获取图像数据。
此外,与每个图像捕捉设备122、124和/或126相关联的焦距可以是可选择的(例如,通过包括适当的镜头等),使得每个设备在相对于车辆200的期望的距离范围处获取对象的图像。例如,在一些实施例中,图像捕捉设备122、124和126可以获取离车辆几米之内的接近对象的图像。图像捕捉设备122、124和126还可以配置为获取离车辆更远的范围处(例如,25米、50米、100米、150米或更远)的对象的图像。此外,图像捕捉设备122、124和126的焦距可以被选择以使得一个图像捕捉设备(例如,图像捕捉设备122)可以获取相对靠近车辆的(例如,在10米内或20米内的)对象的图像,而其它图像捕捉设备(例如,图像捕捉设备124和126)可以获取离车辆200较远的(例如,大于20米、50米、100米、150米等的)对象的图像。
根据一些实施例,一个或多个图像捕捉设备122、124和126的fov可以具有广角。例如,具有140度的fov可能是有利的,尤其是对于可以被用于捕捉车辆200附近的区域的图像的图像捕捉设备122、124和126。例如,图像捕捉设备122可以被用来捕捉车辆200的右侧或左侧的区域的图像,并且在这些实施例中,可能期望图像捕捉设备122具有宽fov(例如,至少140度)。
与图像捕捉设备122、124和126中的每一个相关联的视场可以取决于各自的焦距。例如,随着焦距增加,对应的视场减小。
图像捕捉设备122、124和126可以配置为具有任何合适的视场。在一个特定示例中,图像捕捉设备122可以具有46度的水平fov,图像捕捉设备124可以具有23度的水平fov,并且图像捕捉设备126可以具有在23度和46度之间的水平fov。在另一实例中,图像捕捉设备122可以具有52度的水平fov,图像捕捉设备124可以具有26度的水平fov,并且图像捕捉设备126可以具有在26度和52度之间的水平fov。在一些实施例中,图像捕捉设备122的fov与图像捕捉设备124和/或图像捕捉设备126的fov的比率可以从1.5到2.0变化。在其它实施例中,该比率可以在1.25与2.25之间变化。
系统100可以配置为使得图像捕捉设备122的视场至少部分地或完全地与图像捕捉设备124和/或图像捕捉设备126的视场重叠。在一些实施例中,系统100可以配置为使得图像捕捉设备124和126的视场例如落入(例如,窄于)图像捕捉设备122的视场并且与图像捕捉设备122的视场共享共同的中心。在其它实施例中,图像捕捉设备122、124和126可以捕捉相邻的fov,或者可以在它们的fov中具有部分重叠。在一些实施例中,图像捕捉设备122、124和126的视场可以对齐,以使得较窄fov图像捕捉设备124和/或126的中心可以位于较宽fov设备122的视场的下半部分中。
图2f是与所公开的实施例一致的示例车辆控制系统的图示性表示。如图2f所指示的,车辆200可以包括油门调节系统220、制动系统230和转向系统240。系统100可以通过一个或多个数据链路(例如,任何用于传输数据的有线和/或无线链路)向油门调节系统220、制动系统230和转向系统240中的一个或多个提供输入(例如,控制信号)。例如,基于对由图像捕捉设备122、124和/或126获取的图像的分析,系统100可以向油门调节系统220、制动系统230和转向系统240中的一个或多个提供控制信号以导航车辆200(例如,通过引起加速、转向、车道变换等)。此外,系统100可以从油门调节系统220、制动系统230和转向系统240中的一个或多个接收指示车辆200的运行条件(例如,速率、车辆200是否正在制动和/或转向等)的输入。以下结合图4至图7提供进一步的细节。
如图3a所示,车辆200还可以包括用于与车辆200的驾驶员或乘客进行交互的用户界面170。例如,车辆应用中的用户界面170可以包括触摸屏320、旋钮330、按钮340和麦克风350。车辆200的驾驶员或乘客还可以使用手柄(例如,位于车辆200的转向杆上或附近,包括例如转向信号手柄)、按钮(例如,位于车辆200的方向盘上)等与系统100交互。在一些实施例中,麦克风350可以位于与后视镜310相邻。类似地,在一些实施例中,图像捕捉设备122可以位于靠近后视镜310。在一些实施例中,用户界面170还可以包括一个或多个扬声器360(例如,车辆音频系统的扬声器)。例如,系统100可以经由扬声器360提供各种通知(例如,警报)。
图3b至图3d是与所公开的实施例一致的配置为位于后视镜(例如,后视镜310)后面并与车辆挡风玻璃相对的示例相机安装370的例示。如图3b所示,相机安装370可以包括图像捕捉设备122、124和126。图像捕捉设备124和126可以位于遮光板380的后面,其中遮光板380可以相对于车辆挡风玻璃齐平(flush)并且包括薄膜和/或防反射材料的合成物。例如,遮光板380可被放置为使得它相对于具有匹配斜面的车辆的挡风玻璃对齐。在一些实施例中,图像捕捉设备122、124和126中的每个可以位于遮光板380的后面,例如在图3d中所描绘的。所公开的实施例不限于图像捕捉设备122、124和126、相机安装370和遮光板380的任何特定配置。图3c是图3b所示的相机安装370从前面视角的例示。
如受益于本公开的本领域技术人员将理解的,可以对前述所公开的实施例做出许多变型和/或修改。例如,并非所有组件对于系统100的操作是必要的。此外,任何组件可以位于系统100的任何适当的部件中并且组件可以被重新布置成各种配置同时提供所公开的实施例的功能。因此,前述配置是示例性的,并且不管上述讨论的配置如何,系统100都可以提供广阔范围的功能以分析车辆200的周围并响应于该分析而导航车辆200。
如在下面更详细讨论的并且根据各种所公开的实施例,系统100可以提供各种关于自主驾驶和/或驾驶员辅助技术的特征。例如,系统100可以分析图像数据、位置数据(例如,gps位置信息)、地图数据、速率数据和/或来自包含在车辆200中的传感器的数据。系统100可以从例如图像获取单元120、位置传感器130以及其它传感器收集数据用于分析。此外,系统100可以分析所收集的数据以确定车辆200是否应该采取某个动作,然后无需人工干预而自动采取所确定的动作。例如,当车辆200无需人工干预而导航时,系统100可以自动地控制车辆200的制动、加速、和/或转向(例如,通过向油门调节系统220、制动系统230和转向系统240中的一个或多个发送控制信号)。此外,系统100可以分析所收集的数据,并基于对所收集的数据的分析向车辆乘员发出警告和/或警报。下面提供关于系统100提供的各种实施例的额外的细节。
前向多成像系统
如上所讨论的,系统100可以提供使用多相机系统的驾驶辅助功能。多相机系统可以使用面向车辆的前方的一个或多个相机。在其它实施例中,多相机系统可以包括面向车辆的侧方或面向车辆的后方的一个或多个相机。在一个实施例中,例如系统100可以使用双相机成像系统,其中,第一相机和第二相机(例如,图像捕捉设备122和124)可以位于车辆(例如,车辆200)的前面和/或侧面处。其他相机配置与所公开的实施例一致,并且本文公开的配置是示例性的。例如,系统100可以包括任何数量的相机的配置(例如,一个、两个、三个、四个、五个、六个、七个、八个等)。此外,系统100可以包括相机“群集”。例如,相机群集(包括任何适当数量的相机,例如一个、四个、八个等)可以相对于车辆是前向的,或者可以面向任何其他方向(例如,后向、侧向、成角度的等)。因此,系统100可以包括多个相机群集,其中每个群集以特定方向定向,以从车辆环境的特定区域捕捉图像。
第一相机可以具有大于、小于、或部分重叠于第二相机的视场的视场。此外,第一相机可以连接到第一图像处理器以执行对由第一相机提供的图像的单目图像分析,并且第二相机可以连接到第二图像处理器以执行对由第二相机提供的图像的单目图像分析。第一和第二图像处理器的输出(例如,处理后的信息)可以被组合。在一些实施例中,第二图像处理器可以从第一相机和第二相机两者接收图像以执行立体分析。在另一实施例中,系统100可以使用三相机成像系统,其中每个相机具有不同的视场。因此,这种系统可以基于从位于车辆的前方和侧方的变化距离处的对象得到的信息做出决定。对单目图像分析的参考可以参考基于从单个视点(例如,从单个相机)捕捉的图像执行图像分析的实例。立体图像分析可以参考基于利用图像捕捉参数的一个或多个变化而捕捉的两个或更多个图像执行图像分析的实例。例如,捕捉到的适用于执行立体图像分析的图像可以包括以下捕捉的图像:从两个或更多个不同的位置、从不同的视场、使用不同的焦距、与视差信息一起等捕捉的图像。
例如,在一个实施例中,系统100可以使用图像捕捉设备122至126实现三相机配置。在这种配置中,图像捕捉设备122可以提供窄视场(例如,34度或从大约20度至45度的范围选择的其它值等),图像捕捉设备124可以提供宽视场(例如,150度或从大约100度至大约180度的范围选择的其它值),并且图像捕捉设备126可以提供中间视场(例如,46度或从大约35度至大约60度的范围选择的其它值)。在一些实施例中,图像捕捉设备126可以作为主相机或基本相机。图像捕捉设备122至126可以位于后视镜310的后面并且基本上并排(例如,相距6厘米)。此外,在一些实施例中,如以上所讨论的,图像捕捉设备122至126中的一个或多个可以被安装在与车辆200的挡风玻璃齐平的遮光板380的后面。这种遮挡可以作用以减少任何来自车内的反射对图像捕捉设备122至126的影响。
在另一实施例中,如以上结合图3b和3c所讨论的,宽视场相机(例如,上述示例中的图像捕捉设备124)可以被安装得低于窄视场相机和主视场相机(例如,上述的示例中的图像捕捉设备122和126)。这种配置可以提供来自宽视场相机的自由视线。为减少反射,相机可以被安装得靠近车辆200的挡风玻璃,并且在相机上可以包括偏振器以衰减(damp)反射光。
三相机系统可以提供某些性能特性。例如,一些实施例可以包括通过一个相机基于来自另一相机的检测结果来验证对象的检测的能力。在上面讨论的三相机配置中,处理单元110可以包括例如三个处理设备(例如,三个如以上所讨论的eyeq系列处理器芯片),其中每个处理设备专用于处理由图像捕捉设备122至126中的一个或多个捕捉的图像。
在三相机系统中,第一处理设备可以从主相机和窄视场相机两者接收图像,并且执行对窄fov相机的视觉处理,以例如检测其它车辆、行人、车道标记、交通标志、交通灯以及其它道路对象。另外,第一处理设备可以计算来自主相机和窄相机的图像之间的像素的视差,并且创建车辆200的环境的3d重建。然后第一处理设备可以组合3d重建与3d地图数据、或组合3d重建与基于来自另一相机的信息计算出的3d信息。
第二处理设备可以从主相机接收图像,并执行视觉处理以检测其它车辆、行人、车道标记、交通标志、交通灯和其它道路对象。另外,第二处理设备可以计算相机位移,并且基于该位移计算连续图像之间的像素的视差,并创建场景的3d重建(例如,运动恢复结构(structurefrommotion))。第二处理设备可以将基于3d重建的运动恢复结构发送到第一处理设备以与立体3d图像进行组合。
第三处理设备可以从宽fov相机接收图像,并处理该图像以检测车辆、行人、车道标记、交通标志、交通灯和其它道路对象。第三处理设备还可以执行额外的处理指令来分析图像,以识别图像中移动的对象,诸如正改变车道的车辆、行人等。
在一些实施例中,使得基于图像的信息的流被独立地捕捉和处理可以提供用于在系统中提供冗余的机会。这种冗余可以包括例如使用第一图像捕捉设备和从该设备处理的图像来验证和/或补充通过从至少第二图像捕捉设备捕捉和处理图像信息而获得的信息。
在一些实施例中,系统100将两个图像捕捉设备(例如,图像捕捉设备122和124)用在为车辆200提供导航辅助中,并使用第三图像捕捉设备(例如,图像捕捉设备126)来提供冗余并验证对从其它两个图像捕捉设备接收到的数据的分析。例如,在这种配置中,图像捕捉设备122和124可以提供用于通过系统100进行立体分析的图像以导航车辆200,而图像捕捉设备126可以提供用于通过系统100进行单目分析的图像以提供对基于从图像捕捉设备122和/或图像捕捉设备124捕捉的图像而获得的信息的冗余和验证。即,图像捕捉设备126(和对应的处理设备)可以被视为提供用于提供对从图像捕捉设备122和124得到的分析的检查的冗余子系统(例如,以提供自动紧急制动(aeb)系统)。此外,在一些实施例中,可基于从一个或多个传感器接收的信息(例如,雷达、激光雷达、声学传感器,从车辆外部的一个或多个收发器接收的信息等)来补充接收到的数据的冗余和验证。
本领域的技术人员将认识到,上述相机配置、相机放置、相机数量、相机位置等仅为示例。在不脱离所公开的实施例的范围下,这些组件和关于整个系统描述的其它组件可以被组装并且在各种不同的配置中使用。关于使用多相机系统以提供驾驶员辅助和/或自主车辆功能的进一步的细节如下。
图4是可以存储/编程有用于执行与本公开实施例一致的一个或多个操作的指令的存储器140和/或存储器150的示范性功能性框图。虽然下面指代存储器140,但是本领域技术人员将认识到指令可以被存储在存储器140和/或存储器150中。
如图4所示,存储器140可以存储单目图像分析模块402、立体图像分析模块404、速度和加速度模块406以及导航响应模块408。所公开的实施例不限于存储器140的任何特定配置。此外,应用处理器180和/或图像处理器190可以执行在被包含在存储器140中的任何模块402至408中所存储的指令。本领域技术人员将理解,在下面的讨论中,对处理单元110的参考可以单独地或统一地指代应用处理器180和图像处理器190。因此,任何以下处理的步骤可以由一个或多个处理设备来执行。
在一个实施例中,单目图像分析模块402可以存储指令(诸如计算机视觉软件),该指令在由处理单元110执行时,执行对由图像捕捉设备122、124和126中的一个获取的一组图像的单目图像分析。在一些实施例中,处理单元110可以将来自一组图像的信息与额外的传感信息(例如,来自雷达的信息)组合以执行单目图像分析。如以下结合图5a至图5d所描述的,单目图像分析模块402可以包括用于在该组图像内检测一组特征的指令,该特征诸如车道标记、车辆、行人、道路标志、高速公路出口坡道、交通灯、危险对象以及任何其它与车辆的环境相关联的特征。基于该分析,系统100(例如,经由处理单元110)可以引起车辆200中的一个或多个导航响应,诸如转向、车道变换、加速度的改变等,如以下结合导航响应模块408所讨论的。
在一个实施例中,单目图像分析模块402可以存储指令(诸如计算机视觉软件),该指令在由处理单元110执行时,执行对由图像捕捉设备122、124和126中的一个获取的一组图像的单目图像分析。在一些实施例中,处理单元110可以将来自一组图像的信息与额外的传感信息(例如,来自雷达、激光雷达等的信息)组合以执行单目图像分析。如以下结合图5a至图5d所描述的,单目图像分析模块402可以包括用于在该组图像内检测一组特征的指令,该特征诸如车道标记、车辆、行人、道路标志、高速公路出口坡道、交通灯、危险对象以及任何其它与车辆的环境相关联的特征。基于该分析,系统100(例如,经由处理单元110)可以引起车辆200中的一个或多个导航响应,诸如转向、车道变换、加速度的改变等,如以下结合确定导航响应所讨论的。
在一个实施例中,立体图像分析模块404可以存储指令(诸如,计算机视觉软件),该指令在由处理单元110执行时,执行对由从任意图像捕捉设备122、124和126中选择的图像捕捉设备的组合而获取的第一组和第二组图像的立体图像分析。在一些实施例中,处理单元110可以将来自第一组和第二组图像的信息与额外的传感信息(例如,来自雷达的信息)组合以执行立体图像分析。例如,立体图像分析模块404可以包括用于基于由图像捕捉设备124获取的第一组图像和由图像捕捉设备126获取的第二组图像执行立体图像分析的指令。如下面结合图6所描述的,立体图像分析模块404可以包括用于检测第一组和第二组图像内的一组特征的指令,该特征诸如车道标记、车辆、行人、道路标志、高速公路出口坡道、交通灯、危险对象等。基于该分析,处理单元110可以引起车辆200中的一个或多个导航响应,诸如转向、车道变换、加速度的改变等,如以下结合导航响应模块408所讨论的。此外,在一些实施例中,立体图像分析模块404可实施与经训练的系统(诸如神经网络或深度神经网络)或未经训练的系统相关联的技术。
在一个实施例中,速度和加速度模块406可以存储被配置为对从车辆200中配置为引起车辆200的速度和/或加速度的改变的一个或多个计算和机电设备接收到的数据进行分析的软件。例如,处理单元110可以执行与速度和加速度模块406相关联的指令,以基于从单目图像分析模块402和/或立体图像分析模块404的执行而得到的数据来计算车辆200的目标速率。这种数据可以包括例如目标位置、速度和/或加速度、车辆200相对于附近车辆、行人或道路对象的位置和/或速率、车辆200相对于道路的车道标记等的位置信息等。此外,处理单元110可以基于传感输入(例如,来自雷达的信息)和来自车辆200的其它系统(诸如油门调节系统220、制动系统230和/或转向系统240)的输入来计算车辆200的目标速率。基于计算的目标速率,处理单元110可以向车辆200的油门调节系统220、制动系统230和/或转向系统的240传输电子信号,例如通过物理地压下制动器或松开车辆200的加速器,来触发速度和/或加速度的变化。
在一个实施例中,导航响应模块408可以存储软件,该软件可由处理单元110执行以基于从单目图像分析模块402和/或立体图像分析模块404的执行而得到的数据来确定期望的导航响应。这种数据可以包括与附近的车辆、行人和道路对象相关联的位置和速率信息、车辆200的目标位置信息等。另外,在一些实施例中,导航响应可以(部分地或完全地)基于地图数据、车辆200的预定位置、和/或车辆200与从单目图像分析模块402和/或立体图像分析模块404的执行检测到的一个或多个对象之间的相对速度或相对加速度。导航响应模块408还可以基于传感输入(例如,来自雷达的信息)和来自车辆200的其它系统(诸如车辆200的油门调节系统220、制动系统230和转向系统240)的输入确定期望的导航响应。基于期望的导航响应,处理单元110可以向车辆200的油门调节系统220、制动系统230和转向系统240传输电子信号以触发期望的导航响应,例如通过转动车辆200的方向盘以实现预定角度的旋转。在一些实施例中,处理单元110可以使用导航响应模块408的输出(例如,期望的导航响应)作为对速度和加速度模块406的执行的输入,以用于计算车辆200的速率的改变。
此外,本文公开的任何模块(例如,模块402、404和406)可以实现与经训练的系统(诸如神经网络或深度神经网络)或未经训练的系统相关联的技术。
图5a是示出与所公开的实施例一致的、用于基于单目图像分析引起一个或多个导航响应的示例处理500a的流程图。在步骤510,处理单元110可以经由在处理单元110和图像获取单元120之间的数据接口128接收多个图像。例如,包含在图像获取单元120中的相机(诸如具有视场202的图像捕捉设备122)可以捕捉车辆200的前方(例如,或者车辆的侧方或后方)区域的多个图像并经过数据连接(例如,数字、有线、usb、无线、蓝牙等)将它们传输到处理单元110。在步骤520,处理单元110可以执行单目图像分析模块402来分析该多个图像,如以下结合图5b至5d进一步详细描述的。通过执行该分析,处理单元110可以在该组图像内检测一组特征,诸如车道标记、车辆、行人、道路标志、高速公路出口坡道、交通灯等。
在步骤520,处理单元110还可以执行单目图像分析模块402来检测各种道路危险,诸如例如卡车轮胎的部件、倒下的道路标志、松散货物、小动物等。道路危险可能在结构、形状、大小和颜色上变化,这可能使这些危险的检测更加困难。在一些实施例中,处理单元110可以执行单目图像分析模块402来对该多个图像执行多帧分析以检测道路危险。例如,处理单元110可以估计连续图像帧之间的相机运动,并计算帧之间的像素中的视差来构建道路的3d地图。然后,处理单元110可以使用该3d地图来检测路面、以及存在于路面上的危险。
在步骤530,处理单元110可以执行导航响应模块408以基于在步骤520中执行的分析和如以上结合图4描述的技术引起一个或多个导航响应。导航响应可以包括例如转向、车道变换、加速度变化等。在一些实施例中,处理单元110可以使用从速度和加速度模块406的执行得到的数据来引起一个或多个导航响应。此外,多个导航响应可能同时地、按照顺序地或以其任意组合而发生。例如,处理单元110可以通过例如按照顺序地向车辆200的转向系统240和油门调节系统220传输控制信号,使得车辆200变换一个车道然后加速。可替代地,处理单元110可以通过例如同时向车辆200的制动系统230和转向系统240传输控制信号,使得车辆200制动同时变换车道。
图5b是示出与所公开的实施例一致的用于在一组图像中检测一个或多个的车辆和/或行人的示例处理500b的流程图。处理单元110可以执行单目图像分析模块402来实现处理500b。在步骤540,处理单元110可以确定表示可能的车辆和/或行人的一组候选对象。例如,处理单元110可以扫描一个或多个图像,将该图像与一个或多个预定模式比较,并且在每个图像内识别可能包含感兴趣的对象(例如,车辆、行人或其部分)的可能的位置。预定模式可以以实现高“伪命中”率和低“漏掉”率的这种方式来设计。例如,处理单元110可以将低的相似性的阈值用在预定模式以将候选对象识别为可能的车辆或行人。这样做可以允许处理单元110减少漏掉(例如,未识别出)表示车辆或行人的候选对象的可能性。
在步骤542,处理单元110可以基于分类标准过滤该组候选对象以排除某些候选(例如,不相关或较不相关的对象)。这种标准可以从与存储在数据库(例如,存储在存储器140中的数据库)中的对象类型相关联的各种属性得到。属性可以包括对象形状、尺寸、纹理、位置(例如,相对于车辆200)等。因此,处理单元110可以使用一组或多组标准来从该组候选对象中拒绝伪候选。
在步骤544,处理单元110可以分析多帧图像,以确定在该组候选对象中的对象是否表示车辆和/或行人。例如,处理单元110可以跨连续帧来跟踪检测到的候选对象并累积与检测到的对象相关联的逐帧数据(例如,大小、相对于车辆200的位置等)。此外,处理单元110可以估计检测到的对象的参数并将该对象的逐帧位置数据与预测的位置比较。
在步骤546,处理单元110可以对于检测到的对象构建一组测量。这种测量可以包括例如与检测到的对象相关联的(相对于车辆200的)位置、速度和加速度值。在一些实施例中,处理单元110可以基于使用一系列基于时间的观察的、诸如卡尔曼滤波器或线性二次估计(lqe)的估计技术和/或基于对于不同对象类型(例如,汽车、卡车、行人、自行车、道路标志等)可用的建模数据,来构建该测量。卡尔曼滤波器可以基于对象的比例的测量,其中该比例测量与要碰撞的时间(例如,车辆200到达对象的时间量)成比例。因此,通过执行步骤540至546,处理单元110可以识别在该组捕捉图像内出现的车辆和行人,并得到与该车辆和行人相关联的信息(例如,位置、速率、大小)。基于该识别和所得到的信息,处理单元110可以引起车辆200中的一个或多个导航响应,如以上结合图5a所描述的。
在步骤548,处理单元110可以执行对一个或多个图像的光流分析,以减少检测到“伪命中”和漏掉表示车辆或行人的候选对象的可能性。光流分析可以指,例如在一个或多个图像中分析相对于车辆200的、与其它车辆和行人相关联的并且区别于路面运动的运动模式。处理单元110可以通过跨越在不同时间捕捉到的多个图像帧观察对象的不同位置,来计算候选对象的运动。处理单元110可以使用该位置和时间值作为对用于计算候选对象的运动的数学模型的输入。因此,光流分析可以提供检测车辆200附近的车辆和行人的另一种方法。处理单元110可以结合步骤540至546执行光流分析,以提供检测车辆和行人的冗余,并提高系统100的可靠性。
图5c是示出与所公开的实施例一致的用于在一组图像中检测道路标记和/或车道几何信息的示例处理500c的流程图。处理单元110可以执行单目图像分析模块402来实现处理500c。在步骤550,处理单元110可以通过扫描一个或多个图像来检测一组对象。为了检测车道标记、车道几何信息以及其它相关的道路标记的分段(segment),处理单元110可以过滤该组对象以排除那些被确定为不相关的(例如,小坑洼、小石块等)。在步骤552,处理单元110可以将在步骤550中检测到的属于相同的道路标记或车道标记的分段分组在一起。基于该分组,处理单元110可以产生表示所检测到的分段的模型,诸如数学模型。
在步骤554,处理单元110可以构建与所检测的分段相关联的一组测量。在一些实施例中,处理单元110可以创建所检测的分段从图像平面到现实世界平面上的投影。该投影可以使用具有与诸如所检测的道路的位置、斜率、曲率和曲率导数之类的物理属性对应的系数的三次多项式来表征。在产生该投影中,处理单元110可以考虑路面的变化、以及与车辆200相关联的俯仰(pitch)率和滚转(roll)率。此外,处理单元110可以通过分析出现在路面上的位置和运动线索来对道路标高进行建模。此外,处理单元110可以通过跟踪一个或多个图像中的一组特征点来估计与车辆200相关联的俯仰率和滚转率。
在步骤556,处理单元110可以通过例如跨连续图像帧跟踪所检测到的分段并累积与检测到的分段相关联的逐帧数据来执行多帧分析。由于处理单元110执行多帧分析,在步骤554中构建的该组测量可以变得更可靠并且与越来越高的置信度水平相关联。因此,通过执行步骤550至556,处理单元110可以识别在该组捕捉图像中出现的道路标记并得到车道几何信息。基于该识别和所得到的信息,处理单元110可以引起车辆200中的一个或多个导航响应,如以上结合图5a所描述的。
在步骤558,处理单元110可以考虑额外的信息源,以进一步产生车辆200在其周围的环境中的安全模型。处理单元110可以使用该安全模型来定义系统100可以在其中以安全的方式执行车辆200的自主控制的环境。为产生该安全模型,在一些实施例中,处理单元110可以考虑其它车辆的位置和运动、所检测的路缘和护栏、和/或从地图数据(诸如来自地图数据库160的数据)提取的一般道路形状描述。通过考虑额外的信息源,处理单元110可以提供用于检测道路标记和车道几何结构的冗余,并增加系统100的可靠性。
图5d是示出了与所公开的实施例一致的用于在一组图像中检测交通灯的示例处理500d的流程图。处理单元110可以执行单目图像分析模块402来实现处理500d。在步骤560,处理单元110可以扫描该组图像,并识别出现在图像中的可能包含交通灯的位置处的对象。例如,处理单元110可以过滤所识别的对象来构造一组候选对象,排除不可能对应于交通灯的那些对象。过滤可以基于与交通灯相关联的诸如形状、尺寸、纹理、位置(例如,相对于车辆200)等之类的各种属性来进行。这种属性可以基于交通灯和交通控制信号的多个示例并存储在数据库中。在一些实施例中,处理单元110可以对反映可能的交通灯的该组候选对象执行多帧分析。例如,处理单元110可以跨连续图像帧跟踪候选对象,估计候选对象的现实世界位置,并过滤掉那些移动的对象(其不可能是交通灯)。在一些实施例中,处理单元110可以对候选对象执行颜色分析,并识别出现在可能的交通灯内的所检测到的颜色的相对位置。
在步骤562,处理单元110可以分析交叉口的几何形状。该分析可以基于以下的任意组合:(i)在车辆200的任一侧检测到的车道的数量、(ii)在道路上检测到的标记(如箭头标记)、和(iii)从地图数据(例如,来自地图数据库160的数据)提取的交叉口的描述。处理单元110可以使用从单目分析模块402的执行得到的信息来进行分析。此外,处理单元110可以确定在步骤560中检测到的交通灯和在车辆200附近出现的车道之间的对应性。
在步骤564,随着车辆200接近交叉口,处理单元110可以更新与所分析的交叉口几何形状和所检测到的交通灯相关联的置信度水平。例如,被估计为出现在交叉口处的交通灯的数量与实际出现在交叉口处的交通灯的数量比较可能影响置信度水平。因此,基于该置信度水平,处理单元110可以将控制委托给车辆200的驾驶员以便改进安全条件。通过执行步骤560至564,处理单元110可以识别出现在该组捕捉图像内的交通灯,并分析交叉口几何形状信息。基于该识别和分析,处理单元110可以引起车辆200中一个或多个导航响应,如以上结合图5a所描述的。
图5e是示出了与所公开的实施例一致的、用于基于车辆路径引起车辆中的一个或多个导航响应的示例处理500e的流程图。在步骤570,处理单元110可以构建与车辆200相关联的初始车辆路径。车辆路径可以使用以坐标(x,z)表达的一组点来表示,并且该组点中两个点之间的距离di可以落入1至5米的范围中。在一个实施例中,处理单元110可以使用诸如左道路多项式和右道路多项式的两个多项式来构建初始车辆路径。处理单元110可以计算该两个多项式之间的几何中点,并且将被包含在得到的车辆路径中的每个点偏移预定的偏移(例如,智能车道偏移),如果有的话(零偏移可以对应于在车道的中间行驶)。该偏移可以在垂直于在车辆路径中的任何两点之间的线段的方向上。在另一个实施例中,处理单元110可以使用一个多项式和估计的车道宽度,来将车辆路径的每个点偏移估计的车道宽度的一半加上预定偏移(例如,智能车道偏移)。
在步骤572,处理单元110可以更新在步骤570构建的车辆路径。处理单元110可以使用更高的分辨率来重建在步骤570构建的车辆路径,以使得表示车辆路径的该组点中两个点之间的距离dk小于上述距离di。例如,该距离dk可以落入0.1至0.3米的范围中。处理单元110可以使用抛物线样条算法(parabolicsplinealgorithm)重建车辆路径,这可以产生对应于车辆路径的总长度的累积距离向量s(即,基于表示车辆路径的该组点)。
在步骤574,处理单元110可以基于在步骤572构建的更新的车辆路径来确定前视点(look-aheadpoint)(以坐标表达为(xl,zl))。处理单元110可以从累积距离向量s提取前视点,并且该前视点可以与前视距离和前视时间相关联。前视距离可以具有范围为从10米至20米的下限,可以被计算为车辆200的速率和前视时间的乘积。例如,随着车辆200的速率下降,前视距离也可以减小(例如,直到它到达下限)。前视时间的范围可以从0.5到1.5秒,可以与关联于引起车辆200中的导航响应的诸如航向误差(headingerror)跟踪控制环路的一个或多个控制环路的增益成反比。例如,该航向误差跟踪控制环路的增益可以取决于横摆角速率环路、转向致动器环路、汽车横向动力学等的带宽。因此,航向误差跟踪控制环路的增益越高,前视时间越短。
在步骤576,处理单元110可以基于在步骤574中确定的前视点来确定航向误差和横摆角速率命令。处理单元110可以通过计算前视点的反正切,例如arctan(xl,zl)来确定航向误差。处理单元110可以将横摆角速率命令确定为航向误差和高水平控制增益的乘积。如果前视距离不在下限处,则高水平控制增益可以等于:(2/前视时间)。否则,高水平控制增益可以等于:(2×车辆200的速率/前视距离)。
图5f是示出了与所公开的实施例一致的用于确定前方车辆是否正在改变车道的示例处理500f的流程图。在步骤580,处理单元110可以确定与前方车辆(例如,在车辆200前方行驶的车辆)相关联的导航信息。例如,处理单元110可以使用以上结合图5a和图5b所描述的技术来确定前方车辆的位置、速度(例如,方向和速率)和/或加速度。处理单元110还可以使用以上结合图5e所描述的技术来确定一个或多个道路多项式、前视点(与车辆200相关联)和/或追踪轨迹(snailtrail)(例如,描述前方车辆所采取的路径的一组点)。
在步骤582,处理单元110可以分析在步骤580中确定的导航信息。在一个实施例中,处理单元110可以计算追踪轨迹和道路多项式之间的距离(例如,沿着该轨迹)。如果沿着该轨迹的这个距离的变化(variance)超过预定的阈值(例如,在直路上0.1至0.2米,在适度弯曲道路上0.3至0.4米,以及在急转弯道路上0.5至0.6米),则处理单元110可以确定前方车辆很可能正在改变车道。在检测到多个车辆在车辆200前方行驶的情形中,处理单元110可以比较与每个车辆相关联的追踪轨迹。基于该比较,处理单元110可以确定追踪轨迹与其它车辆的追踪轨迹不匹配的车辆很可能正在改变车道。处理单元110可以额外地将(与前方车辆相关联的)追踪轨迹的曲率与前方车辆正在其中行驶的道路段的期望曲率相比较。该期望曲率可以从地图数据(例如,来自地图数据库160的数据)、从道路多项式、从其它车辆的追踪轨迹、从关于道路现有知识等提取。如果追踪轨迹的曲率和道路段的期望曲率的差异超过预定的阈值,则处理单元110可以确定前方车辆很可能正在改变车道。
在另一个实施例中,处理单元110可以在特定时间段(例如,0.5至1.5秒)将前方车辆的瞬时位置与(与车辆200相关联的)前视点相比较。如果前方车辆的瞬时位置与前视点之间的距离在该特定时间段期间变化,并且变化的累积总和超过预定阈值(例如,直路上0.3至0.4米,适度弯曲道路上0.7至0.8米,以及急转弯道路上1.3至1.7米),则处理单元110可以确定前方车辆很可能正在改变车道。在另一实施例中,处理单元110可以通过将沿着追踪轨迹行驶的横向距离与该追踪轨迹的期望曲率相比较,来分析该追踪轨迹的几何形状。期望曲率半径可以根据公式确定:(δz2+δx2)/2/(δx),其中δx表示行驶的横向距离以及δz表示的行驶的纵向距离。如果行驶的横向距离和期望曲率之间的差异超过预定阈值(例如,500至700米),则处理单元110可以确定前方车辆很可能正在改变车道。在另一个实施例中,处理单元110可以分析前方车辆的位置。如果前方车辆的位置遮挡了道路多项式(例如,前车覆盖在道路多项式的上方),则处理单元110可以确定前方车辆很可能正在改变车道。在前方车辆的位置是使得在前方车辆的前方检测到另一车辆并且这两个车辆的追踪轨迹不平行的情况下,处理单元110可以确定(较近的)前方车辆很可能正在改变车道。
在步骤584,处理单元110可以基于在步骤582进行的分析确定前方车辆200是否正在改变车道。例如,处理单元110可以基于在步骤582执行的各个分析的加权平均来做出该确定。在这种方案下,例如,由处理单元110基于特定类型的分析做出的前方车辆很可能正在改变通道的决定可以被分配值“1”(以及“0”用来表示前方车辆不太可能正在改变车道的确定)。在步骤582中执行的不同分析可以被分配不同的权重,并且所公开的实施例不限于分析和权重的任何特定组合。此外,在一些实施例中,所述分析可以利用经训练的系统(例如,机器学习或深度学习系统),其可以例如基于在当前位置处捕捉的图像来估计在车辆当前位置前方的未来路径。
图6是示出了与所公开的实施例一致的用于基于立体图像分析引起一个或多个导航响应的示例处理600的流程图。在步骤610,处理单元110可以经由数据接口128接收第一和第二多个图像。例如,被包含在图像获取单元120的相机(诸如具有视场202和204的图像捕捉设备122和124)可以捕捉在车辆200前方的区域的第一和第二多个图像,并经过数字连接(例如,usb、无线、蓝牙等)将它们传输到处理单元110。在一些实施例中,处理单元110可以经由两个或更多个数据接口接收该第一和第二多个图像。所公开的实施例不限于任何特定的数据接口配置或协议。
在步骤620,处理单元110可以执行立体图像分析模块404来执行对第一和第二多个图像的立体图像分析,以创建在车辆前方的道路的3d地图并检测图像内的特征,诸如车道标记、车辆、行人、道路标志、高速公路出口坡道、交通灯、道路危险等。立体图像分析可以以类似于以上结合图5a-图5d描述的步骤的方式来执行。例如,处理单元110可以执行立体图像分析模块404以在第一和第二多个图像内检测候选对象(例如,车辆、行人、道路标记、交通灯、道路危险等),基于各种标准过滤掉候选对象的子集,并对剩余的候选对象执行多帧分析、构建测量、并确定置信度水平。在执行上述步骤中,处理单元110可以考虑来自第一和第二多个图像二者的信息,而不是来自单独一组图像的信息。例如,处理单元110可以分析出现在第一和第二多个图像二者中的候选对象的像素级数据(或来自捕捉图像的两个流中的其它数据子集)的差异。作为另一示例,处理单元110可以通过观察候选对象在多个图像的一个中出现而未在另一个中出现,或相对于可能相对于出现在两个图像流中的对象而存在的其它差异,来估计候选对象(例如,相对于车辆200)的位置和/或速度。例如,可以基于与出现在图像流中的一个或两者中的对象相关联的轨迹、位置、移动特性等特征,来确定相对于车辆200的位置、速度和/或加速度。
在步骤630中,处理单元110可以执行导航响应模块408,以基于在步骤620中执行的分析和如以上结合图4所描述的技术而引起车辆200中的一个或多个导航响应。导航响应可以包括例如转向、车道变换、加速度的改变、速度的改变、制动等。在一些实施例中,处理单元110可以使用从速度和加速度模块406的执行得到的数据来引起该一个或多个导航响应。此外,多个导航响应可以同时地、按照顺序地、或以其任意组合而发生。
图7是示出了与所公开的实施例一致的用于基于对三组图像的分析来引起一个或多个导航响应的示例处理700的流程图。在步骤710中,处理单元110可以经由数据接口128接收第一、第二和第三多个图像。例如,被包含在图像获取单元120的相机(诸如具有视场202、204和206的图像捕捉设备122、124和126)可以捕捉在车辆200前方和/或侧方的区域的第一、第二和第三多个图像,并且经过数字连接(例如,usb、无线、蓝牙等)将它们传输到处理单元110。在一些实施例中,处理单元110可以经由三个或更多个数据接口接收第一、第二和第三多个图像。例如,图像捕捉设备122、124、126的每个可以具有用于向处理单元110传送数据的相关联的数据接口。所公开的实施例不限于任何特定的数据接口配置或协议。
在步骤720,处理单元110可以分析该第一、第二和第三多个图像以检测图像内的特征,诸如车道标记、车辆、行人、道路标志、高速公路出口坡道、交通灯、道路危险等。该分析可以以类似于以上结合图5a-图5d和图6所描述的步骤的方式来执行。例如,处理单元110可以对第一、第二和第三多个图像的每个执行单目图像分析(例如,经由单目图像分析模块402的执行以及基于以上结合图5a-图5d所描述的步骤)。可替代地,处理单元110可对第一和第二多个图像、第二和第三多个图像、和/或第一和第三多个图像执行立体图像分析(例如,经由立体图像分析模块404的执行以及基于以上结合图6所描述的步骤)。与对第一、第二和/或第三多个图像的分析相对应的处理后的信息可以进行组合。在一些实施例中,处理单元110可以执行单目和立体图像分析的组合。例如,处理单元110可以对第一多个图像执行单目图像分析(例如,经由单目图像分析模块402的执行)并且对第二和第三多个图像执行立体图像分析(例如,经由立体图像分析模块404的执行)。图像捕捉设备122、124和126的配置—包括它们各自的位置和视场202、204和206—可以影响对第一、第二和第三多个图像进行的分析的类型。所公开的实施例不限于图像捕捉设备122、124和126的特定配置或对第一、第二和第三多个图像进行的分析的类型。
在一些实施例中,处理单元110可以基于在步骤710和720所获取和分析的图像对系统100执行测试。这种测试可以提供对于图像获取设备122、124和126的某些配置的系统100的整体性能的指示符。例如,处理单元110可以确定“伪命中”(例如,系统100不正确地确定车辆或行人的存在的情况)和“漏掉”的比例。
在步骤730,处理单元110可以基于从第一、第二和第三多个图像中的两个得到的信息引起车辆200中的一个或多个导航响应。对第一、第二和第三多个图像中的两个的选择可以取决于各种因素,诸如例如在多个图像的每个中检测到的对象的数量、类型和大小。处理单元110还可以基于图像质量和分辨率、图像中反映的有效视场、捕捉的帧的数量、一个或多个感兴趣的对象实际出现在帧中的程度(例如,其中出现有对象的帧的百分比、出现在每个这种帧中的对象的比例)等进行选择。
在一些实施例中,处理单元110可以通过确定从一个图像源得到的信息与从其它图像源得到的信息的相一致的程度,对从第一、第二和第三多个图像中的两个得到的信息进行选择。例如,处理单元110可以将从图像捕捉设备122、124和126的每个得到的处理后的信息组合(无论通过单目分析、立体分析、还是两者的任意组合),并确定在从图像捕捉设备122、124和126的每个捕捉到的图像之间相一致的视觉指示符(例如,车道标记、检测到的车辆及其位置和/或路径、检测到的交通灯等)。处理单元110还可以排除在捕捉到的图像之间不一致的信息(例如,正改变车道的车辆、指示车辆太靠近车辆200的车道模型等)。因此,处理单元110可以基于对相一致和不一致的信息的确定,来选择从第一、第二和第三多个图像的两个得到的信息。
导航响应可以包括例如转向、车道变换、加速度的改变等。处理单元110可以基于在步骤720所执行的分析和如以上结合图4所描述的技术引起一个或多个导航响应。处理单元110还可以使用从速度和加速度模块406的执行得到的数据引起一个或多个导航响应。在一些实施例中,处理单元110可以基于在车辆200与在第一、第二和第三多个图像的任一者内检测到的对象之间的相对位置、相对速度和/或相对加速度来引起一个或多个导航响应。多个导航响应可以同时地、按顺序地或以其任意组合而发生。
强化学习和经训练的导航系统
下面的部分讨论自主驾驶以及用于完成车辆的自主控制的系统和方法,无论该控制是完全自主的(自驾驶车辆)还是部分自主的(例如,一个或多个驾驶员辅助系统或功能)。如图8所示,自主驾驶任务可以被划分为三个主要模块,包括感测模块801、驾驶策略模块803和控制模块805。在一些实施例中,模块801、803和805可以被存储在系统100的存储器单元140和/或存储器单元150中,或者模块801、803和805(或其中的部分)可以远离系统100而被存储(例如,存储在系统100经由例如无线收发器172可访问的服务器中)。此外,本文公开的任何模块(例如,模块801、803和805)可以实施与经训练的系统(诸如神经网络或深度神经网络)或未经训练的系统相关联的技术。
可以使用处理单元110实施的感测模块801可以处理与感测主车辆的环境中的导航状态有关的各种任务。这些任务可以依赖于来自与主车辆相关联的各种传感器和感测系统的输入。这些输入可以包括来自一个或多个车载相机的图像或图像流、gps位置信息、加速度计输出、用户反馈或对一个或多个用户接口设备的用户输入、雷达、激光雷达等。可以包括来自相机和/或任何其他可用的传感器的数据以及地图信息的感测可以被收集、分析并且制定成“感测到的状态”,该感测到的状态描述从主车辆的环境中的场景提取的信息。该感测到的状态可以包括与目标车辆、车道标记、行人、交通灯、道路几何形状、车道形状、障碍物、到其他对象/车辆的距离、相对速度、相对加速度有关的感测到的信息,以及任何其他潜在的感测到的信息。可以实施监督式机器学习,以便基于提供给感测模块801的感测到的数据产生感测状态输出。感测模块的输出可以表示主车辆的感测到的导航“状态”,其可以被传递至驾驶策略模块803。
尽管可以基于从与主车辆相关联的一个或多个相机或图像传感器接收的图像数据产生感测到的状态,但是还可以使用任何合适的传感器或传感器组合来产生在导航中使用的感测到的状态。在一些实施例中,可以在不依赖捕捉的图像数据的情况下产生感测到的状态。实际上,本文描述的任何导航原理可应用于基于捕捉的图像数据产生的感测到的状态以及使用其他基于非图像的传感器产生的感测到的状态。感测到的状态还可以经由主车辆外部的源来确定。例如,可以全部或部分地基于从远离主车辆的源接收的信息(例如,基于从其他车辆共享的、从中央服务器共享的、或来自与主车辆的导航状态有关的任何其他信息源的传感器信息、经处理的状态信息等),来产生感测到的状态。
驾驶策略模块803(在下文作更详细地讨论并且可以使用处理单元110来实施)可以实施期望的驾驶策略,以便响应于感测到的导航状态决定主车辆要采取的一个或多个导航动作。如果在主车辆的环境中不存在其他作用者(agent)(例如,目标车辆或行人),则可以以相对直接的方式处理输入到驾驶策略模块803的感测到的状态。当感测到的状态需要与一个或多个其他作用者进行协商时,任务变得更加复杂。用于生成驾驶策略模块803的输出的技术可以包括强化学习(下文更详细地讨论)。驾驶策略模块803的输出可以包括主车辆的至少一个导航动作,并且可以包括期望的加速度(其可以转化为主车辆的更新的速度)、主车辆的期望横摆率、期望的轨迹、以及其他潜在的期望导航动作。
基于来自驾驶策略模块803的输出,同样可以使用处理单元110实施的控制模块805可以产生用于与主车辆相关联的一个或多个致动器或受控设备的控制指令。这种致动器和设备可以包括加速器、一个或多个转向控制器、制动器、信号传输器、显示器或可以作为与主车辆相关联的导航操作的一部分而被控制的任何其它致动器或设备。控制理论的方面可以被用来生成控制模块805的输出。控制模块805可以负责产生并且输出指令至主车辆的可控组件,以便实施驾驶策略模块803的期望的导航目标或要求。
回到驾驶策略模块803,在一些实施例中,可以使用通过强化学习训练的经训练的系统来实施驾驶策略模块803。在其他实施例中,驾驶策略模块803可以在不用机器学习方法的情况下、通过使用指定的算法来“手动”解决自主导航期间可能出现的各种情景来实施。然而,这种方法虽然可行,但可能导致驾驶策略过于简单化,并且可能缺乏基于机器学习的经训练的系统的灵活性。例如,经训练的系统可能会更好地配备来处理复杂的导航状态,并且可以更好地确定出租车是在停车还是停下车来接/送乘客;确定行人是否意图穿过主车辆前的街道;防御性地平衡其他驾驶员的意外行为;在牵涉目标车辆和/或行人的密集交通中协商;决定何时暂停(suspend)某些导航规则或增强(augment)其他规则;预期未感测到但预期到的状况(例如,行人是否会从汽车或障碍物后面冒出);等等。基于强化学习的经训练的系统还可以更好地配备来解决连续且高维度的状态空间以及连续的动作空间。
使用强化学习对系统进行训练可以涉及学习驾驶策略,以便从感测到的状态映射到导航动作。驾驶策略是函数π:s→a,其中s是一组状态,而
可以通过暴露于各种导航状态,使该系统应用该策略,提供奖励(基于被设计为奖励期望导航行为的奖励函数),来训练该系统。基于奖励反馈,该系统可以“学习”该策略,并且变得在产生期望导航动作方面是经训练的。例如,学习系统可以观察当前状态st∈s,并基于策略
强化学习(rl)的目标是找到策略π。通常假设:在时间t处,存在奖励函数rt,其测量处于状态st并采取动作at的瞬时质量。然而,在时间t处采取动作at影响了环境,并因此影响未来状态的值。因此,当决定采取何种动作时,不仅应考虑当前的奖励,还应考虑未来的奖励。在某些情况下,当系统确定如果现在采用较低奖励选项则在将来可能实现更高的奖励时,则即使某一动作与低于另一个可用选项的奖励相关联,该系统也应采取该动作。为了对此形式化,观察到策略π以及初始状态s归纳出在
代替将时间范围限定为t,可以对未来奖励打折扣(discount),以对于一些固定的γ∈(0,1),定义:
在任何情况下,最佳策略是下式的解:
其中,期望(expectation)在初始状态s之上。
有若干种可能用于训练驾驶策略系统的方法。例如,可以使用模仿(imitation)方法(例如,行为克隆),在该方法中,系统从状态/动作对中学习,其中动作是好的作用者(例如,人类)响应于特定的观察到的状态而会选择的那些动作。假设观察人类驾驶员。通过这个观察,许多形式为(st,at)的示例(其中st是状态,而at是人类驾驶员的动作)可以被获得、观察并且用作训练驾驶策略系统的基础。例如,监督式学习可以用来学习策略π,使得π(st)≈at。这种方法有许多潜在的优点。首先,不要求定义奖励函数。其次,该学习是受监督的并且是离线发生的(不需要在学习过程中应用作用者)。这种方法的缺点在于:不同的人类驾驶员、甚至是相同的人类驾驶员在其策略选择中并不是确定性的。因此,对于||π(st)-at||非常小的函数的学习通常是不可行的。而且,随着时间的推移,即使是小的误差也可能会累积而产生较大的误差。
可以采用的另一种技术是基于策略的学习。此处,可以以参数形式来表达策略,并且使用合适的优化技术(例如,随机梯度下降)直接对策略进行优化。该方法是直接对以
系统还可以通过基于值的学习(学习q或v函数)来训练。假设,良好近似能够学习到最佳值函数v*。可以构建最佳策略(例如,依靠贝尔曼方程(bellmanequation))。有些版本的基于值的学习可以离线实施(称为“离线策略”训练)。基于值的方法的一些缺点可能是由于其强烈依赖于马尔可夫假设(markovianassumptions)以及需要对复杂函数的近似(相比直接对策略近似,对值函数的近似可能更难)。
另一种技术可以包括基于模型的学习和规划(学习状态转换的概率并对寻找最优v的优化问题求解)。这些技术的组合也可以用来训练学习系统。在这种方法中,可以学习过程的动态性,即,采取(st,at)并在下一个状态st+1上产生分布的函数。一旦学习了这个函数,可以求解最佳问题,以找到其值为最佳的策略π。这就是所谓的“规划”。这种方法的一个优点可能在于:学习部分受到监督,并且可以通过观察三元组(st,at,st+1)而被离线应用。类似于“模仿”方法,这种方法的一个缺点可能在于:学习过程中小的误差可能积累并产生未充分执行的策略。
用于训练驾驶策略模块803的另一种方法可以包括将驾驶策略函数分解为语义上有意义的分量。这允许手动实施该策略的某些部分,这可以确保策略的安全性;并且可以使用强化学习技术来实施策略的其他部分,这可以适应性地实现于许多情景、防御性/侵略性行为之间的类似于人的平衡、以及与其他驾驶员的类似于人的协商。从技术角度而言,强化学习方法可以结合几种方法,并提供易于操作的训练程序,其中大部分训练可以使用记录的数据或自行构建的模拟器来执行。
在一些实施例中,驾驶策略模块803的训练可以依赖于“选项”机制。为了说明,考虑双车道高速公路的驾驶策略的简单情景。在直接rl方法中,策略π将状态映射到
自动巡航控制(acc)策略,oacc:s→a:该策略总是输出为0的横摆率,并且仅改变速率以实现平稳且无事故的驾驶。
acc+左策略,ol:s→a:该策略的纵向命令与acc命令相同。横摆率是将车辆朝左车道的中间居中同时确保安全的横向移动(例如,如果在左侧有车,则不向左移动)的直接实施方式。
acc+右策略,or:s→a:与ol相同,但是车辆可以朝右车道的中间居中。
这些策略可以被称为“选项”。依靠这些“选项”,可以学习选择了选项的策略πo:s→o,其中o是一组可用选项。在一个情况下,o={oacc,ol,or}。选项选择器策略πo通过对每个s设置
实践中,策略函数可以被分解为选项图901,如图9所示。图10中示出了另一个示例选项图1000。选项图可以表示被组织为有向非循环图(dag)的分层决策集。存在一个称为图的根(root)节点903的特殊节点。该节点不具有进入(incoming)节点。决策过程从根节点开始遍历整个图,直到其到达“叶”节点,该叶节点是指没有外出(outgoing)决策线的节点。如图9所示,叶节点可以包括例如节点905、907和909。在遇到叶节点时,驾驶策略模块803可以输出与期望导航动作相关联的加速和转向命令,该期望导航动作与叶节点相关联。
内部节点(诸如节点911、913和915)例如可引起一策略的实施,该策略在其可用选项中选择子代(child)。内部节点的可用子代的集合包括经由决策线与特定内部节点相关联的所有节点。例如,图9中被指定为“并道(merge)”的内部节点913包括各自通过决策线与节点913相连的三个子代节点909、915和917(分别为“保持”、“右超车”和“左超车”)。
可以通过使节点能够调节其在选项图的层级中的位置而获得决策制定系统的灵活性。例如,可以允许任何节点声明自己为“关键(critical)”。每个节点可以实施“是关键的(iscritical)”的函数,如果节点处于其策略实施的关键部分,则该函数输出“真”。例如,负责超车的节点可以在操纵中途声明自己为关键。这可对节点u的可用子代的集合施加约束,该节点u的可用子代可以包括作为节点u的子代的所有节点v,并且存在从v到叶节点的经过所有被指定为关键的节点的路径。一方面,这种方法可以允许在每个时间步在图上声明期望路径,同时另一方面,可以保留策略的稳定性,特别是在策略的关键部分正在被实施之时。
通过定义选项图,学习驾驶策略π:s→a的问题可以被分解成为图中的每个节点定义策略的问题,其中内部节点处的策略应当从可用的子代节点之中进行选择。对于一些节点,相应的策略可以手动实现(例如,通过如果-则(if-then)类型算法来指定响应于观察到的状态的一组动作),而对于其他策略可以使用通过强化学习构建的经训练的系统来实施。手动或经训练/学习的方法之间的选择可以取决于与任务相关联的安全方面以及取决于其相对简单性。可以以使得一些节点直接实施、而其他节点可以依赖于经训练的模型的方式,来构建选项图。这种方法可以确保系统的安全运行。
以下讨论提供了关于在驾驶策略模块803内的如图9中的选项图的作用的进一步细节。如上所述,对驾驶策略模块的输入是“感测到的状态”,其概括了环境图,例如,从可用的传感器获得的。驾驶策略模块803的输出是一组期望(可选地连同一组硬性约束),该组期望将轨迹定义为对优化问题的解。
如上所述,选项图表示被组织为dag的分层决策集。存在称为图的“根”的特殊节点。根节点是没有进入边(例如,决策线)的唯一节点。决策过程从根节点开始遍历该图,直到其到达“叶”节点,所述叶节点即没有外出边的节点。每个内部节点应当实施在其可用的子代之中挑选一个子代的策略。每个叶节点应实施基于从根到叶的整个路径定义了一组期望(例如,主车辆的一组导航目标)的策略。基于感测到的状态而被直接定义的该组期望连同一组硬性约束一起建立了优化问题,该优化问题的解是车辆的轨迹。可以采用硬性约束来进一步提高系统的安全性,并且该期望可以用于提供系统的驾驶舒适性和类似于人的驾驶行为。作为优化问题的解而提供的轨迹进而定义了应该提供给转向、制动和/或引擎致动器的命令,以便完成该轨迹。
返回图9,选项图901表示双车道高速公路的选项图,包括并入车道(意味着在某些点,第三车道并入到高速公路的右侧车道或左侧车道中)。根节点903首先决定主车辆是处于普通道路情景还是接近并道情景。这是可以基于感测状态而实施的决策的示例。普通道路节点911包括三个子节点:保持节点909、左超车节点917和右超车节点915。保持是指主车辆想要继续在相同车道中行驶的情况。保持节点是叶节点(没有外出边/线)。因此,保持节点定义了一组期望。其定义的第一个期望可以包括期望的横向位置——例如,尽可能靠近当前行驶车道的中心。还可以期望平稳地导航(例如,在预定的或允许的加速度最大值内)。保持节点还可以定义主车辆如何对其他车辆作出反应。例如,保持节点可以查看感测到的目标车辆并且为每个车辆分配语义含义,该语义含义可以被转换成轨迹的分量。
各种语义含义可以被分配给主车辆的环境中的目标车辆。例如,在一些实施例中,语义含义可以包括以下指定中的任何指定:1)不相关:指示场景中感测到的车辆当前不相关;2)下一车道:指示感测到的车辆在相邻车道中并且相对于该车辆应当保持适当的偏移(精确的偏移可以在优化问题中计算,该优化问题在给定期望和硬性约束下构建轨迹,并且该精确的偏移可以潜在地是取决于车辆的——选项图的保持叶设定目标车辆的语义类型,其定义相对于目标车辆的期望);3)让路:主车辆将尝试通过例如降低速度(特别是在主车辆确定目标车辆可能切入主车辆的车道的情况下)让路给感测到的目标车辆;4)占道(takeway):主车辆将尝试通过例如增加速度占用路权;5)跟随:主车辆期望跟随在该目标车辆后保持平稳驾驶;6)左/右超车:这意味着主车辆想要发起到左或右车道的变道。左超车节点917和左超车节点915是尚未定义期望的内部节点。
选项图901中的下一个节点是选择间隙节点919。该节点可以负责选择主车辆期望进入的特定目标车道中的两个目标车辆之间的间隙。通过选择形式idj的节点,对于j的某个值,主车辆到达为轨迹优化问题指定了期望的叶——例如,主车辆希望进行操纵以便到达所选择的间隙。这种操纵可能涉及首先在当前车道加速/制动,然后在适当的时间前往目标车道以进入所选择的间隙。如果选择间隙节点919不能找到适当的间隙,则其移动到中止节点921,所述中止节点921定义了回到当前车道的中心并取消超车的期望。
返回到并道节点913,当主车辆接近并道时,其具有可取决于特定情况的若干选项。例如,如图11a所示,主车辆1105沿着双车道道路行驶,其中在双车道道路的主车道或并入车道1111中没有检测到其他目标车辆。在这种情况下,驾驶策略模块803在到达并道节点913时可以选择保持节点909。也就是说,在没有目标车辆被感测为并道到道路上的情况下,可以期望保持在其当前车道内。
在图11b中,情况稍有不同。此处,主车辆1105感测从并入车道1111进入主要道路1112的一个或多个目标车辆1107。在这种情况下,一旦驾驶策略模块803遇到并道节点913,它可以选择发起左超车操纵,以避免并道情况。
在图11c中,主车辆1105遇到从并入车道1111进入主要道路1112的一个或多个目标车辆1107。主车辆1105还检测在与主车辆的车道相邻的车道中行驶的目标车辆1109。主车辆还检测到在与主车辆1105相同的车道上行驶的一个或多个目标车辆1110。在这种情况下,驾驶策略模块803可以决定调节主车辆1105的速率,以为目标车辆1107让路并且行进在目标车辆1115前面。这可以例如通过以下方式来实现:进行到选择间隙节点919,该间隙节点919进而将选择id0(车辆1107)和id1(车辆1115)之间的间隙作为适当的并道间隙。在这种情况下,并道情况的适当间隙定义了轨迹规划器优化问题的目标。
如上所述,选项图的节点可以将其自己声明为“关键”,这可以确保所选择的选项通过关键节点。形式上,每个节点可以实施iscritical函数。在选项图上从根到叶执行正向传递,并且对轨迹规划器的优化问题求解之后,可以从叶返回到根执行反向传递。沿着这个反向传递,可以调用传递中所有节点的iscritical函数,并且可以保存所有关键节点的列表。在对应于下一时间帧的正向路径中,可能需要驾驶策略模块803选择从根节点到叶的经过所有关键节点的路径。
图11a至图11c可用于显示该方法的潜在益处。例如,在发起超车动作并且驾驶策略模块803到达对应于idk的叶的情况下,例如当主车辆处于超车操纵的中途时,选择保持节点909将会是不期望的。为了避免这种跳动,idj节点可以将其自己指定为关键。在操纵期间,可以监测轨迹规划器的成功,并且如果超车操纵按预期进行,则函数iscritical将返回“真”值。此方法可以确保在下一时间帧内,超车操纵将继续(而不是在完成最初选择的操纵之前跳到另一个潜在不一致的操纵)。另一方面,如果对操纵的监测指示所选择的操纵没有按预期进行,或者如果操纵变得不必要或不可能,则iscritical函数可以返回“假”值。这可以允许选择间隙节点在下一时间帧中选择不同的间隙,或完全中止超车操纵。此方法一方面可以允许在每个时间步在选项图上声明期望的路径,同时在另一方面,可以在执行的关键部分时帮助提高策略的稳定性。
硬性约束可以与导航期望不同,这将在下面更详细地讨论。例如,硬性约束可以通过对规划的导航动作应用附加的过滤层来确保安全驾驶。可以根据感测到的状态来确定所涉及的硬性约束,所述硬性约束可以被手动地编程和定义,而不是通过使用基于强化学习建立的经训练的系统。然而,在一些实施例中,经训练的系统可以学习要应用和遵循的可适用的硬性约束。这种方法可以促使驾驶策略模块803到达已经符合可适用的硬性约束的所选动作,这可以减少或消除可能需要之后修改以符合可适用的硬性约束的所选动作。尽管如此,作为冗余安全措施,即使在驾驶策略模块803已经被训练以应对预定硬性约束的情况下,也可以对驾驶策略模块803的输出应用硬性约束。
存在许多潜在的硬性约束的示例。例如,可以结合道路边缘上的护栏来定义硬性约束。在任何情况下,均不允许主车辆通过护栏。这种规则对主车辆的轨迹产生了硬性横向约束。硬性约束的另一个示例可以包括道路颠簸(例如,速率控制颠簸),其可以在颠簸之前以及正穿过颠簸时引起对驾驶速度的硬性约束。硬性约束可以被认为是安全关键的,因此可以手动定义,而不是仅仅依靠在训练期间学习约束的经训练的系统。
与硬性约束相比,期望的目标可以是实现或达到舒适的驾驶。如以上所讨论的,期望的示例可以包括将主车辆置于车道内的与主车辆车道的中心对应的横向位置处的目标。另一个期望可能包括适合进入的间隙的id。注意,主车辆不需要精确地处于车道中心,而是,尽可能靠近它的期望可以确保,即使在偏离车道中心的情况下,主车辆也倾向于迁移到车道的中心。期望可以不是安全关键的。在一些实施例中,期望可能需要与其他驾驶员和行人协商。构建期望的一种方法可以依赖于选项图,并且在图的至少一些节点中实现的策略可以基于强化学习。
对于实现为基于学习训练的节点的选项图901或1000的节点,训练过程可以包括将问题分解成监督式学习阶段和强化学习阶段。在监督式学习阶段,可以学习从(st,at)到
在某些情景下可以提供的重要元素是从未来损失/奖励回到对动作的决策的可微路径。通过选项图结构,涉及安全约束的选项的实现通常是不可微的。为了克服这个问题,对学习的策略节点中的子代的选择可以是随机的。也就是说,节点可以输出概率向量p,其分配用于选择特定节点的每个子代的概率。假设节点有k个子代,并令a(1),...,a(k)为从每个子代到叶的路径的动作。所得到的预测动作因此为
对于给定st,at下
此外,在一些实施例中,系统可以实施多作用者的方法。例如,该系统可以考虑来自各种源的数据和/或从多个角度捕捉的图像。此外,一些公开的实施例可以提供能量的经济性,因为可以考虑不直接涉及主车辆但对主车辆可能产生影响的事件的预期,或者甚至对可能导致涉及其他车辆的不可预测情况的事件的预期可以是考虑因素(例如,雷达可能会“看穿(seethrough)”前方车辆以及不可避免的预期、或者甚至将影响主车辆的事件的高可能性)。
带有施加的导航约束的经训练的系统
在自主驾驶的情况下,重要关注的是如何确保经训练的导航网络的经学习的策略是安全的。在一些实施例中,可以使用约束来训练驾驶策略系统,使得由经训练的系统选择的动作已经可以应对(accountfor)可适用的安全约束。另外,在一些实施例中,可以通过将经训练的系统的所选动作传递经过主车辆的环境中的特定的感测到的场景所涉及的一个或多个硬性约束,来提供额外的安全层。这种方法可以确保主车辆采取的动作仅限于被确认为满足可适用的安全约束的那些动作。
在其核心,导航系统可以包括基于将观察到的状态映射到一个或多个期望动作的策略函数的学习算法。在一些实施方式中,学习算法是深度学习算法。期望动作可以包括预期使车辆的预期奖励最大化的至少一个动作。虽然在一些情况下,车辆采取的实际动作可以对应于期望动作中的一个,但是在其他情况下,可以基于观察到的状态、一个或多个期望动作和对学习导航引擎施加的非学习的硬性约束(例如,安全约束)来确定采取的实际动作。这些约束可以包括围绕各种类型的检测到的对象(例如,目标车辆、行人、道路侧或道路上的静止对象、道路侧或道路上的移动对象、护栏等等)的禁止驾驶区。在一些情况下,该区的大小可以基于检测到的对象的检测到的运动(例如,速率和/或方向)而变化。其他约束可以包括在行人的影响区内穿行时的最大行驶速度、最大减速率(来应对主车辆后方的目标车辆间距)、在感测到的人行横道或铁路道口处的强制停止等。
与通过机器学习训练的系统结合使用的硬性约束可以在自主驾驶中提供一定程度的安全性,其可以超过仅基于经训练的系统的输出可达到的安全性程度。例如,可以使用期望的一组约束作为训练指导来训练机器学习系统,并且因此,经训练的系统可以响应于感测到的导航状态而选择动作,该动作应对并遵守可适用的导航约束的限制。然而,经训练的系统在选择导航动作方面仍具有一定的灵活性,并且因此,至少在某些情况下,由经训练的系统选择的动作可以不严格遵守相关的导航约束。因此,为了要求所选动作严格遵守相关的导航约束,可以使用在学习/经训练的框架之外的、保证严格适用相关的导航约束的非机器学习组件对经训练的系统的输出进行组合、比较、过滤、调节、修改等。
以下讨论提供了关于经训练的系统以及从将经训练的系统与经训练的/学习框架外的算法组件组合收集的潜在益处(特别是从安全角度而言)的附加细节。如前所述,可以通过随机梯度上升来优化策略的强化学习目标。目标(例如,预期奖励)可以被定义为
涉及期望的目标可以用于机器学习情景中。然而,这样的目标,在不受限于导航约束的情况下,可能不会返回严格受限于这些约束的动作。例如,考虑一奖励函数,其中,
观察到,事故对
引理:令πo为策略,并且令p和r是标量,使得在概率p下获得
其中,最终近似适用于r≥1/p的情况。
该讨论表明,形式为
如图11d所示,双并道导航情况提供了进一步示出这些概念的示例。在双并道中,车辆从左侧和右侧两侧接近并道区域1130。并且,来自各侧的车辆(诸如车辆1133或车辆1135)可以决定是否并道至并道区域1130的另一侧的车道中。在繁忙交通中成功执行双并道可能需要显著的协商技巧和经验,并且可能难以通过枚举场景中所有作用者可能采取的所有可能的轨迹而以启发式或蛮力方法来执行。在该双并道的示例中,可以定义适合于双并道操纵的一组期望
下面描述了一组期望
给定期望的速率v∈[0,vmax],与速率相关联的轨迹的代价为
给定期望的横向位置l∈l,与期望的横向位置相关联的代价为
其中dist(x,y,l)是从点(x,y)到车道位置l的距离。关于由于其他车辆导致的代价,对于任何其他车辆,(x′1,y′1),...,(x′k,y′k)可以表示以主车辆的以自我为中心的单位的其他车辆,并且i可以是最早的点,对于该点,存在j,使得(xi,yi)与(x’j,y’j)之间的距离很小。如果没有这样的点,则i可被设置为i=∞。如果另一车辆被分类为“让路”,则可以期望τi>τj+0.5,这意味着主车辆将在另一车辆到达同一点后至少0.5秒后到达轨迹相交点。用于将上述约束转换为代价的可以公式为[τ(j-i)+0.5]+。
同样,如果另一汽车被分类为“占道”,可以期望τj>τi+0.5,其可以转化为代价[τ(i-j)+0.5]+。如果另一汽车被分类为“偏移”,则可以期望i=∞,这意味着主车辆的轨迹和偏移汽车的轨迹不相交。可以通过相对于轨迹之间的距离进行惩罚,将这种情况转化为代价。
为这些代价中的每一个分配权重可以为轨迹规划器提供单个目标函数π(t)。鼓励平稳驾驶的代价可以被增加至该目标。而且,为了确保轨迹的功能性安全,可以将硬性约束增加至该目标。例如,可以禁止(xi,yi)离开道路,并且如果|i–j|小,则可以对于任何其他车辆的任何轨迹点(x’j,y’j),禁止(xi,yi)接近(x’j,y’j)。
总而言之,策略πθ可以被分解成从不可知状态到一组期望的映射以及从期望到实际轨迹的映射。后一种映射不是基于学习的,并且可以通过求解优化问题来实现,该优化问题的代价取决于期望,并且其硬性约束可以保证该策略的功能性安全。
以下讨论描述从不可知状态到该组期望的映射。如上所述,为了符合功能性安全,仅依靠强化学习的系统可能遭受关于奖励
出于各种原因,决策制定可以被进一步分解为语义上有意义的分量。例如,
回到选项图的概念,图11e中示出了可以表示图11d中描绘的双并道情景的选项图。如前所述,选项图可以表示组织为有向非循环图(dag)的分层决策集。在该图中可能存在被称为“根”节点1140的特殊节点,该节点可以是没有进入边(例如,决策线)的唯一节点。决策过程可以从根节点开始遍历该图,直到其到达“叶”节点,即,没有外出边的节点。每个内部节点可以实施从其可用子代中选择一子代的策略函数。可以存在从选项图上的一组遍历到一组期望
在图11e中的双并道选项图1139中,根节点1140可首先判定主车辆是否在并道区域内(例如,图11d中的区域1130),或者主车辆是否正在接近并道区域并且需要为可能的并道做准备。在这两种情况下,主车辆可能需要决定是否改变车道(例如,向左或向右)或是否保持在当前车道中。如果主车辆已决定改变车道,则主车辆可能需要决定条件是否适合继续并执行车道改变操纵(例如,在“继续”节点1142处)。如果不可能改变车道,则主车辆可以试图通过以处于车道标记上为目标,而朝着期望的车道“推进”(例如,在节点1144处,作为与期望车道中的车辆的协商的一部分)。替代地,主车辆可以选择“保持”在同一车道中(例如,在节点1146处)。这种过程可以以自然的方式确定主车辆的横向位置。例如,
这可以实现以自然的方式确定期望的横向位置。例如,如果主车辆将车道从车道2改变为车道3,则“继续”节点可以将期望的横向位置设置为3,“保持”节点可以将期望的横向位置设置为2,而“推进”节点可以将期望的横向位置设置为2.5。接下来,主车辆可以决定是维持“相同”速率(节点1148)、“加速”(节点1150)或是“减速”(节点1152)。接下来,主车辆可以进入超越其他车辆并且将它们的语义含义设置为集合{g,t,o}中的值的“链状”结构1154。这个过程可以设置相对于其他车辆的期望。该链中所有节点的参数可以共享(类似于循环神经网络)。
选项的潜在益处是结果的可解释性。另一个潜在益处在于可以依赖集合
如上所述,双并道场景中片段的长度可以大致为t=250个步长。这样的值(或取决于特定的导航情景的任何其他合适的值)可以提供足够的时间来看到主车辆动作的后果(例如,如果主车辆决定改变车道作为并道的准备,主车辆仅在成功完成并道后才能看到益处)。另一方面,由于驾驶的动态性,主车辆必须以足够快的频率(例如,在上述情况下为10hz)做出决策。
选项图可以以至少两种方式实现降低t的有效值。首先,给定更高等级的决策,可以为较低等级的决策定义奖励,同时考虑较短的片段。例如,当主车辆已经选择了“车道改变”和“继续”节点时,通过观看2至3秒的片段(意味着t变为20-30,而不是250),可以学习用于为车辆分配语义含义的策略。其次,对于高等级决策(诸如是否改变车道或保持在同一车道),主车辆可能不需要每0.1秒做出决策。替代地,主车辆能够以较低频率(例如,每秒)作出决策,或者实现“选项终止”功能,然后可以仅在每次选项终止之后计算梯度。在这两种情况下,t的有效值可能比其原始值小一个数量级。总而言之,每个节点的估计器可以取决于t的值,其比原来的250个步长小一个数量级,这可能会立即转到一个较小的方差。
如上所述,硬性约束可以促进更安全的驾驶,并且可以存在几种不同类型的约束。例如,可以直接根据感测状态定义静态硬性约束。这些硬性约束可包括在主车辆的环境内的减速带、速率限制、道路弯曲、交叉口等,其可能涉及对车辆速率、航向、加速、制动(减速)等的一个或多个约束。静态硬性约束可能还包括语义上的自由空间,其中,例如,主车辆被禁止驶出自由空间之外,以及被禁止太靠近物理障碍行驶。静态硬性约束还可以限制(例如,禁止)不符合车辆的运动学运动的各个方面的操纵,例如,可以使用静态硬性约束来禁止可能导致主车辆翻转、滑动或者其他失去控制的操纵。
硬性约束还可以与车辆相关联。例如,可以采用一约束,该约束要求车辆保持到其他车辆的至少一米的纵向距离和到其他车辆的至少0.5米的横向距离。还可以应用约束,使得主车辆将避免保持与一个或多个其他车辆的碰撞路线。例如,时间τ可以是基于特定场景的时间度量。可以从当前时间到时间τ考虑主车辆和一个或多个其他车辆的预测轨迹。在两条轨迹相交的情况下,
主车辆和一个或多个其他车辆的轨迹被追踪的时间量τ可以变化。然而,在交叉口情景中,速率可能更低,τ可能更长,并且τ可以被定义为使得主车辆将在小于τ秒内进入和离开交叉口。
当然,对车辆轨迹应用硬性约束要求预测那些车辆的轨迹。对于主车辆而言,轨迹预测可能相对直接,因为主车辆通常已经理解并且事实上正在在任何给定时间对预期轨迹进行规划。相对于其他车辆,预测它们的轨迹可能不那么直接。对于其他车辆而言,用于确定预测轨迹的基线计算可能依赖于其他车辆的当前速率和航向,例如,如基于对由主车辆上的一个或多个相机和/或其他传感器(雷达、激光雷达、声学等)捕捉的图像流的分析所确定的。
然而,可能存在一些例外,其可以简化问题或者至少提供在针对另一车辆预测的轨迹中的增加的置信度。例如,对于存在车道指示的结构化道路以及可能存在让路规则的情况,其他车辆的轨迹可以至少部分地基于其他车辆相对于车道的位置以及基于可适用的让路规则。因此,在一些情况下,当观察到车道结构时,可以假设下一车道的车辆将遵守车道边界。也就是说,主车辆可以假设下一车道的车辆将保持在其车道中,除非观察到指示下一车道的车辆将切入主车辆的车道中的证据(例如,信号灯、强的横向运动、跨车道边界的移动)。
其他情况也可以提供关于其他车辆的预期轨迹的线索。例如,在主车辆可以有路权的停车标志、交通灯、环形道等处,可以假设其他车辆将遵守该路权。因此,除非观察到违反规则的证据,否则可以假设其他车辆沿着遵守主车辆拥有的路权的轨迹继续前进。
还可以相对于主车辆环境中的行人应用硬性约束。例如,可以相对于行人建立缓冲距离,使得禁止主车辆相对于任何观察到的行人比规定的缓冲距离更近地行驶。行人缓冲距离可以是任何合适的距离。在一些实施例中,缓冲距离可以是相对于观察到的行人至少一米。
类似于带有车辆的情况,还可以相对于行人与主车辆之间的相对运动来应用硬性约束。例如,可以相对于主车辆的预计轨迹来监测行人的轨迹(基于航向和速率)。给定特定的行人轨迹,其中对于轨迹上的每个点p,t(p)可以表示行人到达点p所需的时间。为了保持距行人至少1米的所需的缓冲距离,t(p)必须大于主车辆将到达点p的时间(具有足够的时间差,使得主车辆在行人的前方以至少一米的距离通过),或者t(p)必须小于主车辆将到达点p的时间(例如,如果主车辆制动来为行人让路)。尽管如此,在后一示例中,硬性约束可能要求主车辆在晚于行人足够的时间到达点p,使得主车辆可以在行人后方通过,并且维持至少一米的所需的缓冲距离。当然,对行人的硬性约束可能有例外。例如,在主车辆具有路权或速度非常缓慢的情况下,并且没有观察到行人将拒绝为主车辆让路或将以其他方式导航向主车辆的证据,可以松弛(relax)行人硬性约束(例如,到至少0.75米或0.50米的较小缓冲)。
在一些示例中,在确定不是全部约束都可以被满足的情况下,可以松弛约束。例如,在道路太窄而不能留出两个路缘或路缘与停放车辆的所需间距(例如0.5米)的情况下,如果存在减轻情况,则可以松弛一个或多个约束。例如,如果人行道上没有行人(或其他对象),可以在离路缘0.1米处缓慢行驶。在一些实施例中,如果松弛约束会改善用户体验,则可以松弛约束。例如,为了避免坑洼,可以松弛约束以允许车辆比通常可能允许的更靠近车道边缘、路缘或行人。此外,在确定哪些约束要松弛时,在一些实施例中,选择要松弛的一个或多个约束是被认为对安全具有最小可用负面影响的那些约束。例如,在松弛涉及与其他车辆的接近度的一个约束之前,可以松弛关于车辆可以有多接近行驶到路缘或混凝土障碍的约束。在一些实施例中,行人约束可以是最后被松弛的,或者在某些情况下可能永远不被松弛。
图12示出可在主车辆的导航期间捕捉和分析的场景的示例。例如,主车辆可以包括如上所述的导航系统(例如,系统100),其可以从与主车辆相关联的相机(例如,图像捕捉设备122、图像捕捉设备124和图像捕捉设备126中的至少一个)接收表示主车辆的环境的多个图像。图12中所示的场景是可以在时间t从沿着预测轨迹1212在车道1210中行驶的主车辆的环境捕捉的图像之一的示例。导航系统可以包括至少一个处理设备(例如,包括上述的任何eyeq处理器或其他设备),所述处理设备被专门编程为接收多个图像并分析图像以确定响应于场景的动作。具体而言,如图8所示,至少一个处理设备可以实现感测模块801、驾驶策略模块803和控制模块805。感测模块801可以负责收集并输出从相机收集的图像信息,并且将该信息以所识别的导航状态的形式提供至驾驶策略模块803,其可以构成已经通过机器学习技术(诸如监督式学习、强化学习等)训练的经训练的导航系统。基于由感测模块801提供至驾驶策略模块803的导航状态信息,驾驶策略模块803(例如,通过实施上述的选项图方法)可以生成用于由主车辆响应于所识别的导航状态而执行的期望导航动作。
在一些实施例中,至少一个处理设备可以使用例如控制模块805,将期望导航动作直接转换成导航命令。然而,在其他实施例中,可以应用硬性约束,使得针对场景和所述期望导航动作可能涉及的各种预定导航约束,对由驾驶策略模块803提供的期望导航动作进行测试。例如,在驾驶策略模块803输出将引起主车辆跟随轨迹1212的期望导航动作的情况下,可以相对于与主车辆的环境的各个方面相关联的一个或多个硬性约束来测试该导航动作。例如,捕捉图像1201可以显示路缘1213、行人1215、目标车辆1217以及存在于场景中的静止对象(例如,翻倒的箱子)。这些中的每个都可以与一个或多个硬性约束相关联。例如,路缘1213可以与禁止主车辆导航进路缘或经过路缘并且到人行道1214上的静态约束相关联。路缘1213还可以与路障包络(envelope)相关联,该路障包络限定了远离路缘(例如,0.1米、0.25米、0.5米、1米等)并且沿着路缘延伸的距离(例如,缓冲区),该距离限定了主车辆的禁止导航区。当然,静态约束还可以与其他类型的路侧边界(例如,护栏、混凝土柱、交通锥标、桥塔或任何其他类型的路侧障碍)相关联。
应注意,距离和范围可以通过任何合适的方法来确定。例如,在一些实施例中,距离信息可以由车载雷达和/或激光雷达系统提供。替代地或另外地,距离信息可以从对从主车辆的环境捕捉的一个或多个图像的分析中导出。例如,可以确定图像中表示的已辨识的对象的多个像素,并将其与图像捕捉设备的已知视场和焦距几何形状进行比较,以确定比例和距离。例如,可以通过观察在已知时间间隔内从图像到图像的对象之间的比例变化,来确定速度和加速度。该分析可以指示对象朝着主车辆或者远离主车辆的运动方向、以及对象正在以多快速度远离主车辆或朝主车辆过来。可以通过分析在已知时间段内从一个图像到另一个图像的对象x坐标位置的变化,来确定穿越速度。
行人1215可以与限定了缓冲区1216的行人包络相关联。在一些情况下,施加的硬性约束可以禁止主车辆在离行人1215一米的距离内(在相对于行人1215的任何方向)导航。行人1215还可以限定行人影响区1220的位置。这种影响区可以与限制主车辆在影响区内的速度的约束相关联。影响区可以从行人1215延伸5米、10米、20米等。影响区的每个分级(graduation)可以与不同的速率限制相关联。例如,在离行人1215一米至五米的区域内,主车辆可以被限制为第一速率(例如,10mph(每小时英里数),20mph等),所述第一速率可以小于从5米延伸至10米的行人影响区中的速率限制。可以对于影响区的各级使用任何分级。在一些实施例中,第一级可以比从一米到五米更窄,并且可以仅从一米延伸到两米。在其他实施例中,影响区的第一级可从一米(围绕行人的禁止导航区的边界)延伸至至少10米的距离。第二级又可以从十米延伸到至少约二十米。第二级可以与主车辆的最大行驶速度相关联,其大于与行人影响区的第一级相关联的最大行驶速度。
一个或多个静止对象约束也可以与主车辆的环境中检测到的场景有关。例如,在图像1201中,至少一个处理设备可以检测静止对象,诸如存在于道路中的箱子1219。检测到的静止对象可以包括各种对象,诸如树、杆、道路标志或道路中的对象中的至少一个。一个或多个预定导航约束可以与检测到的静止对象相关联。例如,这种约束可以包括静止对象包络,其中所述静止对象包络限定了关于对象的缓冲区,可以禁止主车辆导航到该缓冲区内。缓冲区的至少一部分可以从检测到的静止对象的边缘延伸预定距离。例如,在由图像1201表示的场景中,至少0.1米、0.25米、0.5米或更多的缓冲区可以与箱子1219相关联,使得主车辆将以至少一段距离(例如,缓冲区距离)通过箱子的右侧或左侧,以避免与检测到的静止对象发生碰撞。
预定的硬性约束还可以包括一个或多个目标车辆约束。例如,可以在图像1201中检测到目标车辆1217。为了确保主车辆不与目标车辆1217碰撞,可以采用一个或多个硬性约束。在一些情况下,目标车辆包络可以与单个缓冲区距离相关联。例如,可以通过在所有方向上围绕目标车辆1米的距离来限定缓冲区。缓冲区可以限定从目标车辆延伸至少一米的区域,禁止主车辆导航到该区域中。
然而,围绕目标车辆1217的包络不需要由固定的缓冲距离限定。在一些情况下,与目标车辆(或在主车辆的环境中检测到的任何其他可移动对象)相关联的预定硬性约束可取决于主车辆相对于检测到的目标车辆的定向。例如,在一些情况下,纵向缓冲区距离(例如,从目标车辆向主车辆的前方或后方延伸的距离——诸如在主车辆正朝着目标车辆行驶的情况下)可以为至少一米。横向缓冲区距离(例如,从目标车辆向主车辆的任一侧延伸的距离——诸如当主车辆以与目标车辆相同或相反的方向行驶时,使得主车辆的一侧将邻近目标车辆的一侧通过)可以为至少0.5米。
如上所述,通过对主车辆的环境中的目标车辆或行人的检测,还可能涉及其他约束。例如,可以考虑主车辆和目标车辆1217的预测轨迹,并且在两个轨迹相交(例如,在相交点1230处)的情况下,硬性约束可以需要
还可以采用其他硬性约束。例如,至少在一些情况下,可以采用主车辆的最大减速率。这种最大减速率可以基于检测到的距跟随主车辆的目标车辆的距离(例如,使用从后向相机收集的图像)而被确定。硬性约束可以包括在感测到的人行横道或铁路道口处的强制停止、或其他可适用的约束。
在对主车辆的环境中的场景的分析指示可能涉及一个或多个预定导航约束的情况下,可以相对于主车辆的一个或多个规划的导航动作来施加这些约束。例如,在对场景的分析导致驾驶策略模块803返回期望导航动作的情况下,可以针对一个或多个涉及的约束来测试该期望导航动作。如果期望导航动作被确定为违反所涉及的约束的任何方面(例如,如果期望导航动作将驱使主车辆在行人1215的0.7米的距离内,其中预定硬性约束要求主车辆保持距离行人1215至少1.0米),则可以基于一个或多个预定导航约束对期望导航动作做出至少一个修改。以这种方式调节期望导航动作可以遵循在主车辆的环境中检测到的特定场景所涉及的约束,为主车辆提供实际导航动作。
在确定主车辆的实际导航动作之后,可以通过响应于所确定的主车辆的实际导航动作而引起对主车辆的导航致动器的至少一个调节,来实现该导航动作。这种导航致动器可以包括主车辆的转向机构、制动器或加速器中的至少一个。
优先约束
如上所述,导航系统可采用各种硬性约束来确保主车辆的安全操作。约束可以包括相对于行人、目标车辆、路障或检测到的对象的最小安全驾驶距离、当在检测到的行人的影响区内通过时的最大行驶速率、或者主车辆的最大减速率等等。这些约束可以对基于机器学习(监督式、强化或组合)训练的经训练的系统来施加,但是它们也可以对非经训练的系统(例如,采用算法来直接处理在来自主车辆环境的场景中发生的预期情况的那些系统)有用。
在任何一种情况下,都可能存在约束的层级。换言之,一些导航约束优先于其他约束。因此,如果出现了不可获得会导致所有相关约束均被满足的导航动作的情况,则导航系统可首先确定实现最高优先级约束的可用导航动作。例如,系统也可以使车辆首先避开该行人,即使避开该行人的导航会导致与道路中检测到的另一车辆或对象碰撞。在另一个示例中,系统可以使车辆骑上路缘来避开行人。
图13提供了示出用于实现基于对主车辆的环境中场景的分析而确定的相关约束的层级的算法的流程图。例如,在步骤1301,与导航系统相关联的至少一个处理设备(例如,eyeq处理器等)可以从安装在主车辆上的相机接收表示主车辆的环境的多个图像。通过在步骤1303对表示主车辆环境的场景的图像的分析,可以识别与主车辆相关联的导航状态。例如,导航状态可以指示主车辆正沿着双车道道路1210行驶,如图12所示,其中目标车辆1217正在移动通过主车辆前方的交叉口,行人1215正在等待穿过主车辆行驶的道路,对象1219存在于主车辆车道的前方,以及场景的各种其他属性。
在步骤1305,可以确定主车辆的导航状态涉及的一个或多个导航约束。例如,在分析由一个或多个捕捉图像表示的主车辆的环境中的场景之后,至少一个处理设备可以确定通过对捕捉图像的图像分析所辨识的对象、车辆、行人等涉及的一个或多个导航约束。在一些实施例中,至少一个处理设备可以确定导航状态涉及的至少第一预定导航约束和第二预定导航约束,并且第一预定导航约束可以不同于第二预定导航约束。例如,第一导航约束可以涉及在主车辆的环境中检测到的一个或多个目标车辆,而第二导航约束可以涉及在主车辆的环境中检测到的行人。
在步骤1307,至少一个处理设备可以确定与在步骤1305中识别的约束相关联的优先级。在所描述的示例中,涉及行人的第二预定导航约束可以具有比涉及目标车辆的第一预定导航约束更高的优先级。虽然可以基于各种因素来确定或分配与导航约束相关联的优先级,但是在一些实施例中,导航约束的优先级可能与其从安全角度而言的相对重要性有关。例如,虽然在尽可能多的情况下遵守或满足所有实施的导航约束可能是重要的,但是一些约束可能与其他约束相比与具有更高的安全风险相关联,因此,这些约束可被分配更高的优先级。例如,要求主车辆保持与行人间距至少1米的导航约束可具有比要求主车辆保持与目标车辆间距至少1米的约束更高的优先级。这可能是因为与行人相撞会比与另一车辆相撞造成更严重的后果。类似地,保持主车辆与目标车辆之间的间距可以具有比以下约束更高的优先级:要求主车辆避开道路上的箱子、在减速带上低于特定速度驾驶、或者使主车辆占有者暴露于不超过最大加速度等级。
虽然驾驶策略模块803被设计为通过满足特定场景或导航状态涉及的导航约束以使安全性最大化,但是在一些情况下,实际上不可能满足每个所涉及的约束。在这种情况下,如步骤1309所示,可以使用每个涉及的约束的优先级来确定应该首先满足哪个涉及的约束。继续上面的示例,在不可能同时满足行人间隙约束和目标车辆间隙两者约束,而只能满足其中一个约束的情况下,则更高优先级的行人间隙约束可导致该约束在尝试保持到目标车辆的间隙之前被满足。因此,在正常情况下,如步骤1311所示,在第一预定导航约束和第二预定导航约束两者都可以被满足的情况下,至少一个处理设备可以基于所识别的主车辆的导航状态来确定满足第一预定导航约束和第二预定导航约束两者的主车辆的第一导航动作。然而,在其他情况下,在不是所有涉及的约束都可以被满足的情况下,如步骤1313所示,第一预定导航约束和第二预定导航约束不能同时被满足的情况下,至少一个处理设备可以基于所识别的导航状态,确定满足第二预定导航约束(即,较高优先级约束)但不满足第一预定导航约束(具有低于第二导航约束的优先级)的主车辆的第二导航动作。
接下来,在步骤1315,为了实施所确定的主车辆的导航动作,至少一个处理设备可以响应于所确定的主车辆的第一导航动作或所确定的主车辆的第二导航动作,引起对主车辆的导航致动器的至少一个调节。如在前面的示例中所述,导航致动器可以包括转向机构、制动器或加速器中的至少一个。
约束松弛
如上所述,出于安全目的可以施加导航约束。约束可以包括相对于行人、目标车辆、路障或检测到的对象的最小安全驾驶距离、当在检测到的行人的影响区内通过时的最大行驶速度、或者主车辆的最大减速率等等。这些约束可以被施加在学习或非学习的导航系统中。在某些情况下,这些约束可以被松弛。例如,在主车辆在行人附近减速或停靠,然后缓慢前进以传达要驶过行人的意图的情况下,可以从所获取的图像中检测行人的响应。如果行人的响应是保持静止或停止移动(和/或如果感测到与行人的眼神接触),则可以理解该行人认识到导航系统要驶过行人的意图。在这种情况下,系统可松弛一个或多个预定约束并实施较不那么严格的约束(例如,允许车辆在行人0.5米内导航,而不是在更严格的1米边界内)。
图14提供了用于基于一个或多个导航约束的松弛来实施主车辆的控制的流程图。在步骤1401,至少一个处理设备可以从与主车辆相关联的相机接收表示主车辆的环境的多个图像。在步骤1403对图像的分析可以使得能够识别与主车辆相关联的导航状态。在步骤1405,至少一个处理器可以确定与主车辆的导航状态相关联的导航约束。导航约束可以包括导航状态的至少一个方面所涉及的第一预定导航约束。在步骤1407,多个图像的分析可以揭示至少一个导航约束松弛因素(relaxationfactor)的存在。
导航约束松弛因素可以包括一个或多个导航约束在至少一个方面可以被暂停、改变或以其他方式松弛的任何合适的指示符。在一些实施例中,至少一个导航约束松弛因素可以包括(基于图像分析)行人的眼睛正看向主车辆的方向的确定。在这种情况下,可以更安全地假定行人意识到主车辆。因此,行人不会参与导致行人移动到主车辆路径中的意外动作的置信度可能更高。还可以使用其他约束松弛因素。例如,至少一个导航约束松弛因素可以包括:被确定为没有在移动的行人(例如,假定不太可能进入主车辆路径的行人);或者其运动被确定为正在减慢的行人。导航约束松弛因素还可以包括更复杂的动作,诸如被确定为在主车辆停住然后恢复移动后没有在移动的行人。在这种情况下,可以假设行人知道主车辆具有路权,并且行人停住可以表明行人让路给主车辆的意图。其他可能导致一个或多个约束被松弛的情况包括路缘石的类型(例如,低路缘石或具有渐变坡度的路缘石可能允许松弛的距离约束)、在人行道上缺少行人或其他对象、处于其引擎未运转的车辆可以具有松弛的距离、或者行人正背向和/或远离于主车辆驶向的区域移动的情况。
在识别存在导航约束松弛因素(例如,在步骤1407)的情况下,可以响应于约束松弛因素的检测来确定或产生第二导航约束。该第二导航约束可以不同于第一导航约束,并且所述第二导航约束可以包括相对于第一导航约束被松弛的至少一个特性。第二导航约束可以包括基于第一约束的新生成的约束,其中所述新生成的约束包括在至少一个方面松弛第一约束的至少一个修改。可替代地,第二约束可以构成在至少一个方面比第一导航约束不那么严格的预定约束。在一些实施例中,可以保留这种第二约束,以仅用于在主车辆的环境中识别约束松弛因素的情况。无论第二约束是新生成的还是从一组完全或部分可用的预定约束中选择的,应用第二导航约束代替更严格的第一导航约束(其可以应用在没有检测到相关导航约束松弛因素的情况)可以被称为约束松弛并且可以在步骤1409中完成。
在步骤1407检测到至少一个约束松弛因素,并且在步骤1409中已经松弛了至少一个约束的情况下,可以在步骤1411中确定主车辆的导航动作。主车辆的导航动作可以基于所识别的导航状态并且可以满足第二导航约束。可以在步骤1413通过响应于所确定的导航动作而引起对主车辆的导航致动器的至少一个调节来实施导航动作。
如上所述,导航约束和松弛导航约束的使用可以对经训练(例如,通过机器学习)或未经训练(例如,被编程为响应于特定导航状态以预定动作来响应的导航系统)的导航系统采用。在使用经训练的导航系统的情况下,用于某些导航情况的松弛导航约束的可用性可以表示从经训练的系统响应到未经训练的系统响应的模式切换。例如,经训练的导航网络可以基于第一导航约束来确定主车辆的原始导航动作。然而,车辆采取的动作可以是与满足第一导航约束的导航动作不同的动作。相反,所采取的动作可以满足更松弛的第二导航约束,并且可以是由未经训练的系统产生的动作(例如,作为在主车辆的环境中检测到特定状况的响应,诸如导航约束松弛因素的存在)。
有许多可以响应于在主车辆的环境中检测到约束松弛因素而被松弛的导航约束的示例。例如,在预定导航约束包括与检测到的行人相关联的缓冲区,并且缓冲区的至少一部分从检测到的行人延伸一定距离的情况下,被松弛的导航约束(新产生的、从预定集合中从存储器中调用的,或作为先前存在的约束的松弛版本生成的)可以包括不同的或修改的缓冲区。例如,不同的或修改的缓冲区可以具有比相对于检测到的行人的原始的或未修改的缓冲区更小的相对于行人的距离。因此,在主车辆的环境中检测到适当的约束松弛因素的情况下,鉴于经松弛的约束,可以允许主车辆更靠近检测到的行人而导航。
如上所述,导航约束的被松弛的特性可以包括与至少一个行人相关联的缓冲区的宽度减少。然而,被松弛的特性还可以包括对与目标车辆、检测到的对象、路侧障碍或在主车辆的环境中检测到的任何其他对象相关联的缓冲区的宽度减少。
至少一个被松弛的特性还可以包括导航约束特性的其他类型的修改。例如,被松弛的特性可以包括与至少一个预定导航约束相关联的速率的增加。被松弛的特性还可以包括与至少一个预定导航约束相关联的最大可允许减速度/加速度的增加。
尽管如上所述在某些情况下约束可以被松弛,而在其他情况下,导航约束可以被增强(augment)。例如,在一些情况下,导航系统可以确定授权(warrant)对一组正常导航约束的增强的条件。这种增强可以包括将新的约束添加到一组预定的约束或者调节预定约束的一个或多个方面。添加或调节可导致相对于在正常驾驶条件下可适用的该组预定约束而言更为保守的导航。可以授权约束增强的条件可以包括传感器故障、不利的环境条件(雨、雪、雾或与可见性降低或车辆牵引力降低相关联的其他情形)等。
图15提供用于基于对一个或多个导航约束的增强来实施主车辆的控制的流程图。在步骤1501,至少一个处理设备可以从与主车辆相关联的相机接收表示主车辆的环境的多个图像。在步骤1503对图像的分析可以使得能够识别与主车辆相关联的导航状态。在步骤1505,至少一个处理器可以确定与主车辆的导航状态相关联的导航约束。导航约束可以包括导航状态的至少一个方面所涉及的第一预定导航约束。在步骤1507,对多个图像的分析可以揭示至少一个导航约束增强因素的存在。
涉及的导航约束可以包括上述的(例如,关于图12)任何导航约束或任何其他合适的导航约束。导航约束增强因素可以包括一个或多个导航约束可以在至少一个方面被补充/增强的任何指示符。可以在每个组的基础上(例如,通过将新的导航约束添加到一组预定的约束)或者可以在每个约束的基础上(例如,修改特定的约束,使得经修改约束比原始约束更具限制性,或者添加对应于预定约束的新约束,其中该新约束在至少一个方面比对应约束更具限制性),来执行导航约束的补充或增强。另外或可替代地,导航约束的补充或增强可以是指基于层级从一组预定约束中进行选择。例如,一组被增强的约束可用于基于是否在主车辆的环境中或相对于主车辆检测到导航增强因素来进行选择。在没有检测到增强因素的正常情况下,则可以从适用于正常情况的约束中抽取所涉及的导航约束。另一方面,在检测到一个或多个约束增强因素的情况下,所涉及的约束可以从被增强的约束中抽取,该被增强的约束是相对于一个或多个增强因素而生成或预定的。被增强的约束在至少一个方面与正常情况下适用的对应约束相比可能更具限制性。
在一些实施例中,至少一个导航约束增强因素可以包括在主车辆的环境中检测到(例如,基于图像分析)道路表面上存在冰、雪或水。例如,这种确定可以基于对以下的检测:反射率高于干燥道路所预期的区域(例如,指示道路上的冰或水);道路上的指示雪的存在的白色区域;道路上的与道路上存在纵向沟(例如,雪中的轮胎痕迹)一致的阴影;主车辆挡风玻璃上的水滴或冰/雪颗粒;或者道路表面上存在水或冰/雪的任何其他合适的指示符。
至少一个导航约束增强因素还可以包括在主车辆的挡风玻璃的外表面上检测到的颗粒。这种颗粒可能会损害与主车辆相关联的一个或多个图像捕捉设备的图像质量。虽然关于主车辆的挡风玻璃进行了描述,其与安装在主车辆的挡风玻璃后面的相机相关,但对在其他表面(例如,相机的镜头或镜头盖、前灯透镜、后挡风玻璃、尾灯透镜或对于与主车辆相关联的图像捕捉设备可见(或由传感器检测到)的主车辆的任何其他表面)上的颗粒的检测,也可指示导航约束增强因素的存在。
导航约束增强因素也可以被检测为一个或多个图像获取设备的属性。例如,检测到的由与主车辆相关联的图像捕捉设备(例如,相机)捕捉的一个或多个图像的图像质量方面的降低,也可以构成导航约束增强因素。图像质量的下降可能与硬件故障或部分硬件故障相关联,该故障与图像捕捉设备或与图像捕捉设备相关联的组件相关联。这种图像质量的下降也可能是由环境条件引起的。例如,在主车辆周围的空气中存在烟、雾、雨、雪等也可能导致降低相对于可能存在于主车辆的环境中的道路、行人、目标车辆等的图像质量。
导航约束增强因素还可以涉及主车辆的其它方面。例如,在一些情况下,导航约束增强因素可以包括检测到的与主车辆关联的系统或传感器的故障或部分故障。这种增强因素可以包括,例如检测到速度传感器、gps接收器、加速度计、相机、雷达、激光雷达、制动器、轮胎或与主车辆相关联的任何其他系统的故障或部分故障,该故障可影响主车辆相对于与主车辆的导航状态相关联的导航约束进行导航的能力。
在识别导航约束增强因素的存在(例如,在步骤1507)的情况下,可以响应于检测到约束增强因素来确定或产生第二导航约束。该第二导航约束可以不同于第一导航约束,并且所述第二导航约束可以包括相对于第一导航约束被增强的至少一个特性。第二导航约束可以比第一导航约束更具限制性,因为检测到在主车辆的环境中的或者与主车辆相关联的约束增强因素可以表明主车辆可以具有至少一个相对于正常操作条件降低的导航能力。这种降低的能力可以包括较低的道路牵引力(例如,道路上的冰、雪、或水;降低的轮胎压力等);受损的视觉(例如,降低捕捉图像质量的雨、雪、沙尘、烟、雾等);受损的检测能力(例如,传感器故障或部分故障、传感器性能降低等),或主车辆响应于检测到的导航状态而导航的能力方面的任何其他降低。
在步骤1507中检测到至少一个约束增强因素,并且在步骤1509中增强了至少一个约束的情况下,可以在步骤1511中确定主车辆的导航动作。主车辆的导航动作可以基于所识别的导航状态并且可以满足第二导航(即,被增强的)约束。可以在步骤1513通过响应于所确定的导航动作而引起对主车辆的导航致动器进行至少一个调节来实施导航动作。
如所讨论的,导航约束和被增强的导航约束的使用可以对经训练(例如,通过机器学习)或未经训练(例如,被编程为响应于特定导航状态以预定动作来响应的系统)的导航系统采用。在使用经训练的导航系统的情况下,针对某些导航情况的被增强的导航约束的可用性可表示从经训练的系统响应到未经训练的系统响应的模式切换。例如,经训练的导航网络可以基于第一导航约束来确定主车辆的原始导航动作。然而,车辆采取的动作可以是与满足第一导航约束的导航动作不同的动作。相反,所采取的动作可以满足被增强的第二导航约束,并且可以是由未经训练的系统产生的动作(例如,作为对在主车辆的环境中检测到特定条件的响应,诸如存在导航约束增强因素)。
有许多可以响应于在主车辆的环境中检测到约束增强因素而生成、补充或增强的导航约束的示例。例如,在预定导航约束包括与检测到的行人、对象、车辆等相关联的缓冲区,并且缓冲区的至少一部分从检测到的行人/对象/车辆延伸一定距离的情况下,被增强的导航约束(新产生的、从预定集合中从存储器调用的,或作为先前存在的约束的增强版本而生成的)可以包括不同的或修改的缓冲区。例如,不同的或修改的缓冲区可以具有比相对于检测到的行人/对象/车辆的原始的或未修改的缓冲区而言更大的相对于行人/对象/车辆的距离。因此,在主车辆的环境中或相对于主车辆检测到适当的约束增强因素的情况下,鉴于该被增强的约束,可以强制主车辆更远离检测到的行人/对象/车辆而导航。
至少一个被增强的特性还可以包括导航约束特性的其他类型的修改。例如,被增强的特性可以包括与至少一个预定导航约束相关联的速度的降低。被增强的特性还可以包括与至少一个预定导航约束相关联的最大可允许减速度/加速度的减小。
基于长远规划的导航
在一些实施例中,所公开的导航系统不仅可以对主车辆的环境中检测到的导航状态进行响应,而且还可以基于长远规划(longrangeplanning)来确定一个或多个导航动作。例如,系统可以考虑可用作相对于检测到的导航状态进行导航的选项的一个或多个的导航动作对未来导航状态的潜在影响。考虑可用的动作对未来状态的影响可以使得导航系统不仅基于当前检测到的导航状态、而且还基于长远规划来确定导航动作。在导航系统采用一种或多种奖励函数作为从可用选项中选择导航动作的技术的情况下,使用长远规划技术的导航可能尤其适用。可以相对于可以响应于检测到的主车辆的当前导航状态而采取的可用导航动作,来分析潜在奖励。然而,进一步地,还可以相对于可以响应于未来导航状态而采取的动作,来分析潜在奖励,所述未来导航状态预计是由于对当前导航状态的可用动作而造成的。因此,所公开的导航系统在某些情况下可以响应于检测到的导航状态而从可以响应于当前导航状态而采取的可用动作之中选择导航动作,即使在所选择的导航动作可能不会产生最高的奖励的情况之下。这在系统确定以下情况时尤其正确:所选择的动作可能导致未来导航状态,该未来导航状态引起一个或多个潜在的导航动作,其中该潜在的导航动作提供比所选择的动作或者在某些情况下比相对于当前导航状态可用的任何动作更高的奖励。该原理可以更简单地表达为:为了在未来产生更高的奖励选项,而在现在采取不那么有利的动作。因此,所公开的能够进行长远规划的导航系统可以选择短期非最理想的动作,其中长期预测指示奖励的短期损失会导致长期奖励增加。
通常,自主驾驶应用可涉及一系列规划问题,其中导航系统可以决定即时动作以便优化更长期目标。例如,当车辆在环形道处遇到并道情况时,导航系统可以决定即时加速或制动命令,以便发起到环形道的导航。虽然在环形道处对检测到的导航状态的即时动作可能涉及响应于所检测到的状态的加速或制动命令,但长期目标是成功并道,并且所选命令的长期影响是并道的成功/失败。可以通过将问题分解为两个阶段来解决规划问题。首先,监督式学习可以应用于基于现在来预测近未来(假设预测符(predictor)相对于现在的表示将是可微的)。其次,可以使用循环神经网络对作用者的完整轨迹进行建模,其中未解释的因素被建模为(加性)输入节点。这可以允许使用监督式学习技术和对循环神经网络直接优化来确定长期规划问题的解。这种方法还可以使得能够通过将对抗性要素纳入环境来学习鲁棒的策略。
自主驾驶系统的两个最基本的要素是感测和规划。感测处理的是寻找环境的现在状态的紧凑表示,而规划处理的是决定采取何种动作以优化未来目标。监督式机器学习技术对求解感测问题是有用的。机器学习算法框架也可以用于规划部分,尤其是强化学习(rl)框架,诸如上述那些。
rl可以按照连续几轮(round)的顺序而执行。在第t轮,规划器(亦称作用者或驾驶策略模块803)可以观察状态st∈s,其表示作用者和环境。然后其应该决定动作at∈a。在执行该动作后,该作用者接收即时奖励
监督式学习(sl)可以被看作是rl的特例,其中st是从s上的一些分布中采样的,并且奖励函数可以具有
在一些sl情况下,学习器采取的动作(或预测)可能对环境没有影响。换言之,st+1和at是独立的。这会有两个重要的含义。首先,在sl中,样本(s1,y1),...,(sm,ym)可以提前被收集,然后才能开始搜索相对于样本具有良好准确度的策略(或预测符)。相反,在rl中,状态st+1通常取决于所采取的动作(以及之前的状态),而这又取决于用于生成该动作的策略。这将使数据生成过程束缚于策略学习过程。其次,因为在sl中动作不影响环境,所以选择at对π的表现的贡献是局部的。具体而言,at只影响即时奖励的值。相反,在rl中,第t轮采取的动作可能会对未来轮中的奖励值产生长期影响。
在sl中,“正确”答案的知识yt、连同奖励
许多rl算法至少部分地依赖于马尔可夫决策过程(mdp,markovdecisionprocess)的数学优化模型。马尔可夫假设是:给定st和at,st+1的分布被完全确定。依据mdp状态上的稳定分布,其给出了给定策略的累积奖励的闭合解表达式。策略的稳定分布可以表示为线性规划问题的解。这产生了两类算法:1)相对于原始问题的优化,其被称为策略搜索;2)相对于双重问题的优化,其变量被称为值函数vπ。如果mdp从初始状态s开始,并且从那里根据π来选择动作,则值函数确定预期累积奖励。相关量是状态-动作值函数qπ(s,a),假设从状态s开始,即时选择的动作a,以及从那里根据π选择的动作,则状态-动作值函数确定累积奖励。q函数可能会引起最优策略的表征(使用贝尔曼方程)。特别是,q函数可能表明最优策略是从s到a的确定性函数(实际上,它可能被表征为相对于最优q函数的“贪婪”策略)。
mdp模型的一个潜在优点在于其允许使用q函数将未来耦合到现在。例如,假设主车辆现在处于状态s,qπ(s,a)的值可以指示执行动作a对未来的影响。因此,q函数可以提供动作a的质量的局部测量,从而使rl问题更类似于sl场景。
许多rl算法以某种方式近似v函数或q函数。值迭代算法(例如q学习算法)可以依赖于以下事实:最优策略的v和q函数可以是从贝尔曼方程导出的一些运算符的固定点。行动者-评价器(actor-critic)策略迭代算法旨在以迭代的方式学习策略,其中在迭代t处,“评价器”估计
尽管mdp的数学优势和切换到q函数表示的方便性,但该方法可能具有若干限制。例如,马尔可夫行为状态的近似概念可能是在某些情况下所能找到的全部。此外,状态的转变不仅取决于作用者的行为,还取决于环境中其他参与者的行为。例如,在上面提到的acc示例中,尽管自主车辆的动态可以是马尔可夫的,但下一个状态可取决于另一车辆的驾驶员的行为,而该行为不一定是马尔可夫的。对这个问题的一个可能的解决方案是使用部分观察到的mdp,其中假设:存在马尔可夫状态,但是可以看到的是根据隐藏状态而分布的观察。
更直接的方法可以考虑mdp的博弈理论概括(例如,随机博弈框架)。事实上,用于mdp的算法可以被推广到多作用者博弈(例如,最小最大-q学习或纳什-q学习)。其他方法可包括其他参与者的显式建模以及消除遗憾(vanishingregret)学习算法。在多作用者场景中的学习可能比在单作用者场景中更复杂。
q函数表示的第二限制可以通过偏离表格场景(tabularsetting)而产生。表格场景就是当状态和动作的数量很小之时,因此q可以表示为|s|个行和|a|个列的表格。然而,如果s和a的自然表示包含欧几里得空间,并且状态和动作空间是离散的,则状态/动作的数量可能在维度上是指数的。在这种情况下,采用表格场景可能并不实际。相反,q函数可以由来自参数假设类别(例如,某个架构的神经网络)的某个函数来近似。例如,可以使用深q网络(dqn,deep-q-network)学习算法。在dqn中,状态空间可以是连续的,而动作空间可以仍然是小的离散集合。可以存在处理连续动作空间的方法,但它们可能依赖于对q函数近似。在任何情况下,q函数都可能是复杂的且对噪声敏感,因此可能会对学习带来挑战。
不同的方法可以是使用循环神经网络(rnn,recurrentneuralnetwork)来解决rl问题。在某些情况下,rnn可以与多作用者博弈的概念和来自博弈论的对抗环境的稳健性相结合。此外,这种方法可以并不明确依赖任何马尔可夫假设。
以下更详细地描述通过基于预测进行规划来导航的方法。在这种方法中,可以假定状态空间s是
作为该方法的第一步,可以观察到存在有趣的问题,其中奖励的强盗本质并不是问题。例如,acc应用的奖励值(如下面将更详细讨论的)可能相对于当前状态和动作是可微的。事实上,即使奖励是以“强盗”方式给出的,学习可微函数
为了解决过去与未来之间的联系,可以使用类似的想法。例如,假设可以学习一个可微函数
如上所述,学习系统可受益于相对于对抗环境(诸如主车辆的环境)的鲁棒性,所述环境可包括可能以预料外的方式动作的多个其他驾驶员。在不对vt施加概率性假设的模型中,可以考虑其中是以对抗方式来选择vt的环境。在某些情况下,可以对μt施加限制,否则对抗方可能会使规划问题变得困难甚至不可能。一种自然约束可能是要求由常数来限制||μt||。
针对对抗环境的鲁棒性可能在自主驾驶应用中有用。以对抗的方式选择μt甚至可加快学习过程,因为它可以将学习系统专注于稳健的最佳策略。可以用简单的博弈来说明这个概念。状态为
这种方法可以应用于实际上可能出现的任何导航情况。以下描述适用于一个示例的方法:自适应巡航控制(acc)。在acc问题中,主车辆可能试图与前方的目标车辆保持适当的距离(例如,到目标车辆1.5秒)。另一个目标可能是尽可能平稳地驾驶,同时保持期望的间隙。代表这种情况的模型可以如下定义。状态空间为
系统的完整动态可以通过以下描述来描述:
这可以被描述为两个向量的总和:
第一向量是可预测的部分,而第二向量是不可预测的部分。第t轮的奖励定义如下:
第一项可导致对非零加速度的惩罚,因此鼓励平稳驾驶。第二项取决于到目标汽车的距离xt和期望的距离
实施以上概述的方法,主车辆的导航系统(例如,通过在导航系统的处理单元110内的驾驶策略模块803的操作)可以响应于观察到的状态来选择动作。所选动作可以基于不仅对与相对于感测到的导航状态可用的响应动作相关联的奖励的分析,而且还可以基于对未来状态、响应于未来状态的潜在动作和与潜在的动作相关联的奖励的考虑和分析。
图16示出了基于检测和长远规划的导航的算法方法。例如,在步骤1601,主车辆的导航系统的至少一个处理设备110可以接收多个图像。这些图像可以捕捉表示主车辆的环境的场景,并且可以由上述任何图像捕捉设备(例如,相机、传感器等)提供。在步骤1603分析这些图像中的一个或多个可以使至少一个处理设备110能够识别与主车辆相关联的当前导航状态(如上所述)。
在步骤1605、1607和1609,可以确定响应于感测到的导航状态的各种潜在的导航动作。这些潜在的导航动作(例如,第一导航动作至第n可用导航动作)可以基于感测到的状态和导航系统的长远目标(例如,完成合并、平稳地跟随前车、超过目标车辆、避开道路中的对象、针对检测到的停车标志而减速、避开切入的目标车辆、或可以推进系统的导航目标的任何其他导航动作)来确定。
对于所确定的潜在导航动作中的每个,系统可以确定预期奖励。预期奖励可以根据上述技术中的任一种来确定,并且可以包括关于一个或多个奖励函数对特定潜在动作的分析。对于在步骤1605、1607和1609中确定的每个潜在导航动作(例如,第一,第二和第n),可以分别确定预期奖励1606、1608和1610。
在一些情况下,主车辆的导航系统可基于与预期奖励1606、1608和1610(或预期奖励的任何其他类型的指示符)相关联的值,从可用潜在动作中选择。例如,在某些情况下,可以选择产生最高预期奖励的动作。
在其他情况下,尤其是在导航系统进行长远规划以确定主车辆的导航动作的情况下,系统可以不选择产生最高预期奖励的潜在动作。相反,系统可以展望未来以分析,如果响应于当前导航状态选择了较低的奖励动作,是否有机会在之后实现较高奖励。例如,对于在步骤1605、1607和1609处确定的任何或全部潜在动作,可以确定未来状态。在步骤1613、1615和1617确定的每个未来状态可以表示预期基于当前导航状态、由相应潜在动作(例如,在步骤1605、1607和1609确定的潜在动作)修改而得到的未来导航状态。
对于在步骤1613、1615和1617预测的未来状态中的每个,可以确定和评估一个或多个未来动作(作为响应于确定的未来状态而可用的导航选项)。在步骤1619、1621和1623处,例如,可以(例如,基于一个或多个奖励函数)产生与一个或多个未来动作相关联的预期奖励的值或任何其他类型的指示符。可以通过比较与每个未来动作相关联的奖励函数的值或通过比较与预期奖励相关联的任何其他指示符,来评估与一个或多个未来动作相关的预期奖励。
在步骤1625,主车辆的导航系统可基于预期奖励的比较,不仅基于相对于当前导航状态识别的潜在动作(例如,步骤1605、1607和1609中的),并且还基于作为响应于预测的未来状态可用的潜在未来动作的结果而确定的预期奖励(例如,在步骤1613、1615和1617处确定的),来选择主车辆的导航动作。在步骤1625处的选择可以基于在步骤1619、1621和1623处执行的选项和奖励分析。
在步骤1625处对导航动作的选择可以仅基于与未来动作选项相关联的预期奖励的比较。在这种情况下,导航系统可以仅基于对从对潜在的未来导航状态的动作得到的预期奖励的比较,来选择对当前状态的动作。例如,系统可以选择在步骤1650、1610和1609处识别的、与通过在步骤1619、1621和1623处的分析确定的最高未来奖励值相关联的潜在动作。
在步骤1625对导航动作的选择还可以仅基于当前动作选项的比较(如上所述)。在这种情况下,导航系统可以选择在步骤1605、1607或1609识别的、与最高预期奖励1606、1608或1610相关联的潜在动作。这种选择可以在很少或不考虑未来导航状态或对响应于预期未来导航状态的可用导航动作的未来预期奖励的情况下执行。
另一方面,在一些情况下,在步骤1625对导航动作的选择可以基于与未来动作选项和当前动作选项两者相关联的预期奖励的比较。事实上,这可能是基于长远规划的导航原理之一。例如,可以分析对未来动作的预期奖励,以确定是否有任何预期奖励可以授权响应于当前导航状态对较低的奖励动作进行的选择,以便响应于后续导航动作实现潜在的较高奖励,该后续导航动作是预期响应于未来导航状态而可用的。作为示例,预期奖励1606的值或其他指示符可以指示在奖励1606、1608和1610当中的最高预期奖励。另一方面,预期奖励1608可以指示在奖励1606、1608和1610当中的最低预期奖励。并非简单地选择在步骤1605确定的潜在动作(即,引起最高预期奖励1606的动作),可以将未来状态、潜在的未来动作、以及未来奖励的分析用于在步骤1625进行导航动作选择。在一个示例中,可以确定在步骤1621识别的奖励(响应于对步骤1615确定的未来状态的至少一个未来动作,而步骤1615确定的未来状态是基于步骤1607中确定的第二潜在动作的)可以高于预期奖励1606。基于该比较,可以选择在步骤1607确定的第二潜在动作,而不是在步骤1605确定的第一潜在动作,尽管预期奖励1606高于预期奖励1608。在一个示例中,在步骤1605确定的潜在导航动作可以包括在检测到的目标车辆前面的并道,而在步骤1607确定的潜在导航动作可以包括在目标车辆后面的并道。尽管在目标车辆前面并道的预期奖励1606可能高于与在目标车辆后面并道相关联的预期奖励1608,但可以确定在目标车辆后面并道可能导致一未来状态,对于该未来状态可能存在产生比预期奖励1606、1608或基于响应于当前的、感测到的导航状态的可用动作的其他奖励甚至更高的潜在奖励的动作选项。
在步骤1625处从潜在动作之中进行选择可以基于预期奖励的任何合适的比较(或将与一个潜在动作相关联的益处的任何其他度量或指示符彼此比较)。在一些情况下,如上所述,如果预计第二潜在动作要提供与高于与第一潜在动作相关联的奖励的预期奖励相关联的至少一个未来动作,则可以越过第一潜在动作而选择第二潜在动作。在其他情况下,可以采用更复杂的比较。例如,与响应于预计的未来状态的动作选项相关联的奖励可以与与确定的潜在动作相关联的多于一个预期奖励相比较。
在一些情况下,如果至少一个未来动作被预期产生高于预期作为对当前状态的潜在动作的结果的任何奖励(例如,预期奖励1606、1608、1610等)的奖励时,则基于预计的未来状态的动作和预期奖励可以影响对当前状态的潜在动作的选择。在某些情况下,产生最高的预期奖励(例如,从与对感测到的当前状态的潜在动作相关联的预期奖励、以及从与相对于潜在未来导航状态的潜在未来动作选项相关联的预期奖励当中)的未来动作选项可以用作选择对当前导航状态的潜在动作的指导。也就是说,在识别产生最高预期奖励(或者高于预定阈值的奖励等)的未来动作选项之后,在步骤1625可以选择将导致与识别的、产生最高的预期奖励的未来动作相关联的未来状态的潜在动作。
在其他情况下,可以基于预期奖励之间确定的差,来进行可用动作的选择。例如,如果与在步骤1621确定的未来动作相关联的预期奖励与预期奖励1606之间的差大于预期奖励1608与预期奖励1606之间的差(假设正符号的差),则可以选择在步骤1607确定的第二潜在动作。在另一个示例中,如果与在步骤1621确定的未来动作相关联的预期奖励和与在步骤1619确定的未来动作相关联的预期奖励之间的差大于预期奖励1608与预期奖励1606之间的差,则可以选择在步骤1607确定的第二潜在动作。
已经描述了用于从对当前导航状态的潜在动作当中进行选择的若干示例。然而,可以使用任何其他合适的比较技术或标准,用于通过基于延伸到预计的未来状态的动作和奖励分析的长远规划来选择可用动作。此外,虽然图16表示长远规划分析中的两个层(例如,第一层考虑对当前状态的潜在动作产生的奖励,而第二层考虑响应于预计的未来状态的未来动作选项产生的奖励),然而,基于更多层的分析可以是能够的。例如,不是将长远规划分析基于一个或两个层,而是可以使用三层、四层或更多层分析来从响应于当前的导航状态的可用潜在动作当中选择。
在从响应于感测到的导航状态的潜在动作当中进行选择之后,在步骤1627,至少一个处理器可以响应于所选择的潜在导航而引起对主车辆的导航致动器的至少一个调节动作。导航致动器可以包括用于控制主车辆的至少一个方面的任何合适的装置。例如,导航致动器可以包括转向机构、制动器或加速器中的至少一个。
基于推断的其他方侵略的导航
可以通过分析获取的图像流来监测目标车辆,以确定驾驶侵略的指示符。本文将侵略描述为定性或定量参数,但可以使用其他特性:注意力的感知等级(驾驶员的潜在损伤、手机造成分心、睡着等)。在一些情况下,目标车辆可以被认为具有防御性姿势,并且在一些情况下,可以确定目标车辆具有更具侵略性姿势。基于侵略指示符可以选择或产生导航动作。例如,在一些情况下,可以跟踪相对于主车辆的相对速度、相对加速度、相对加速度的增加、跟随距离等,以确定目标车辆是侵略性的还是防御性的。例如,如果目标车辆被确定为具有超过阈值的侵略等级,则主车辆可能倾向于让路给目标车辆。还可以基于确定的目标车辆相对于目标车辆的路径中或其附近的一个或多个障碍物(例如,前方车辆、道路上的障碍物、交通灯等)的行为,来辨别目标车辆的侵略等级。
作为对这个概念的介绍,将相对于主车辆并道至环形道来描述示例性实验,其中导航目标是穿过环形道并从环形道出去。该情况可以以主车辆接近环形道的入口开始,并且可以以主车辆到达环形道的出口(例如,第二出口)结束。可以基于主车辆是否始终与所有其他车辆保持安全距离、主车辆是否尽快完成路线、以及主车辆是否遵循平稳的加速策略来衡量成功。在这个示例中,nt个目标车辆可以随机置于环形道上。为了对对抗和典型行为的混合进行建模,在概率p下,目标车辆可以通过“侵略性”驾驶策略来建模,使得侵略性的目标车辆在主车辆试图在目标车辆前方并道时加速。在概率1-p下,目标车辆可以通过“防御性”驾驶策略来建模,使得目标车辆减速并让主车辆并道。在该实验中,p=0.5,并且可以不为主车辆的导航系统提供关于其他驾驶员的类型的信息。可以在片段开始时随机选择其他驾驶员的类型。
导航状态可以表示为主车辆(作用者)的速度和位置、以及目标车辆的位置、速度和加速度。保持目标加速度观察可能很重要,以便基于当前状态区分侵略性和防御性的驾驶员。所有目标车辆都可能沿着环形路径为轮廓的一维曲线移动。主车辆可以在其自身的一维曲线移动,该曲线在并道点处与目标车辆的曲线相交,并且该点是两条曲线的起点。为了对合理驾驶进行建模,所有车辆的加速度的绝对值可以以常数为界限。因为不允许倒退驾驶,速度也可以通过relu传递。注意,通过不允许倒退驾驶,因此长远规划可以成为必要的,因为作用者不会对其过去的行为后悔。
如上所述,下一状态st+1可被分解为可预测部分
图18提供了表示用于基于预测的其他车辆的侵略来导航主车辆的示例性算法的流程图。在图18的示例中,可以基于相对于目标车辆的环境中的对象所观察到目标车辆的行为,来推断与至少一个目标车辆相关联的侵略等级。例如,在步骤1801,主车辆导航系统的至少一个处理设备(例如,处理设备110)可以从与主车辆相关联的相机接收表示主车辆的环境的多个图像。在步骤1803,对一个或多个所接收的图像的分析可以使至少一个处理器能够识别主车辆1701的环境中的目标车辆(例如,车辆1703)。在步骤1805,对一个或多个所接收的图像的分析可以使至少一个处理设备能够在主车辆的环境中识别目标车辆的至少一个障碍物。所述对象可以包括道路中的碎片、停车灯/交通灯、行人、另一车辆(例如,在目标车辆前方行驶的车辆、停放的车辆等)、道路中的箱子、路障、路缘或可能在主车辆的环境中遇到的任何其他类型的对象。在步骤1807,对一个或多个接收的图像的分析可以使至少一个处理设备能够确定目标车辆相对于目标车辆的至少一个识别的障碍物的至少一个导航特性。
可以使用各种导航特性来推断检测到的目标车辆的侵略等级,以便产生对目标车辆的适当的导航响应。例如,这种导航特性可以包括目标车辆与至少一个识别的障碍物之间的相对加速度、目标车辆距障碍物的距离(例如,目标车辆在另一车辆后面的跟随距离)、和/或目标车辆与障碍物之间的相对速度等。
在一些实施例中,可以基于来自与主车辆相关联的传感器(例如雷达、速度传感器、gps等)的输出来确定目标车辆的导航特性。然而,在一些情况下,可以部分地或完全地基于对主车辆的环境的图像的分析来确定目标车辆的导航特性。例如,上文所述和在例如通过引用合并如此处的美国专利号9,168,868中描述的图像分析技术可以用于识别主车辆的环境内的目标车辆。并且,随着时间的推移监测目标车辆在捕捉图像中的位置和/或监测与目标车辆相关联的一个或多个特征(例如,尾灯、头灯、保险杠、车轮等)在捕捉图像中的位置,可以使得能够确定目标车辆与主车辆之间或者目标车辆与主车辆的环境中的一个或多个其它对象之间的相对距离、速度和/或加速度。
可以从目标车辆的任何合适的观察到的导航特性或观察到的导航特性的任何组合中推断所识别的目标车辆的侵略等级。例如,可以基于任何观察到的特性和一个或多个预定阈值等级或任何其他合适的定性或定量分析,作出对侵略性的确定。在一些实施例中,如果目标车辆被观察到以小于预定侵略性距离阈值的距离跟随主车辆或另一车辆,则目标车辆可被认为是侵略性的。另一方面,被观察到以大于预定防御性距离阈值的距离跟随主车辆或另一车辆的目标车辆可被认为是防御性的。预定侵略性距离阈值不需要与预定防御性距离阈值相同。另外,预定侵略性距离阈值和预定防御性距离阈值中的任一个或两者可以包括值的范围,而不是分界值(brightlinevalue)。此外,预定侵略性距离阈值和预定防御性距离阈值都不必被固定。相反,这些值或值的范围可以随时间而改变,并且可以基于观察到的目标车辆的特性来应用不同的阈值/阈值的范围。例如,所应用的阈值可以取决于目标车辆的一个或多个其他特性。较高的所观察到的相对速度和/或加速度可以授权应用较大的阈值/范围。相反,较低的相对速度和/或加速度(包括零相对速度和/或加速度)可以授权在进行侵略性/防御性推断时应用较小的距离阈值/范围。
侵略性/防御性推断也可以基于相对速度和/或相对加速度阈值。如果观察到的目标车辆相对于另一车辆的相对速度和/或相对加速度超过预定等级或范围,则该目标车辆可被认为是侵略性的。如果观察到的目标车辆相对于另一车辆的相对速度和/或相对加速度低于预定水平或范围,则该目标车辆可被认为是防御性的。
尽管可以仅基于任何观察到的导航特性来进行侵略性/防御性确定,但该确定还可以取决于观察到的特性的任何组合。例如,如上所述,在一些情况下,目标车辆可以仅基于观察到其正在以某个阈值或范围以下的距离跟随另一车辆而被认为是侵略性的。然而,在其他情况下,如果目标车辆以小于预定量(其可以与仅基于距离进行确定时应用的阈值相同或不同)并且具有大于预定量或范围的相对速度和/或相对加速度跟随另一车辆,则该目标车辆可以被认为是侵略性的。类似地,目标车辆可以仅基于观察到其正在以大于某个阈值或范围的距离跟随另一车辆而被认为是防御性的。然而,在其他情况下,如果目标车辆以大于预定量(其可以与仅基于距离进行确定时应用的阈值相同或不同)并且具有小于预定量或范围的相对速度和/或相对加速度跟随另一车辆,则该目标车辆可以被认为是防御性的。如果例如车辆超过0.5g加速度或减速度(例如,5m/s3觉克(jerk))、车辆在车道变换或曲线上具有0.5g的横向加速度、一车辆导致另一车辆进行上述任何一项、车辆改变车道并导致另一车辆以0.3g减速度或3米/秒觉克以上进行让路、和/或车辆在不停的情况下改变两条车道,则系统100可以得出侵略性/防御性。
应该理解的是,对超过一范围的量的引用可以指示该量超过与该范围相关联的所有值或落入该范围内。类似地,对低于一范围的量的引用可以指示该量低于与该范围相关的所有值或落入该范围内。另外,尽管相对于距离、相对加速度和相对速度描述了用于进行侵略性/防御性推断的示例,但是可以使用任何其他合适的量。例如,可以使用对要发生碰撞的时间的计算、或者目标车辆的距离、加速度和/或速度的任何间接指示符。还应该注意的是,尽管上述示例关注于相对于其他车辆的目标车辆,但是可以通过观察目标车辆相对于任何其他类型的障碍物(例如,行人、路障、交通灯、碎片等)的导航特性来进行侵略性/防御性推断。
回到图17a和17b所示的示例,当主车辆1701接近环形道时,导航系统(包括它的至少一个处理设备)可以接收来自与主车辆相关联的相机的图像流。基于对一个或多个接收的图像的分析,可以识别目标车辆1703、1705、1706、1708和1710中的任何一个。此外,导航系统可以分析一个或多个识别的目标车辆的导航特性。导航系统可以辨识到目标车辆1703与1705之间的间隙表示潜在并道至环形道的第一机会。导航系统可以分析目标车辆1703以确定与目标车辆1703相关联的侵略指示符。如果目标车辆1703被认为是侵略性的,则主车辆导航系统可以选择为车辆1703让路而不是在车辆1703前方并道。另一方面,如果目标车辆1703被认为是防御性的,则主车辆导航系统可以尝试在车辆1703前完成并道动作。
当主车辆1701接近环形道时,导航系统的至少一个处理设备可以分析所捕捉的图像以确定与目标车辆1703相关联的导航特性。例如,基于图像,其可以确定车辆1703以一距离跟随车辆1705,该距离为主车辆1701安全进入提供足够的间隙。事实上,可以确定车辆1703以超过侵略性距离阈值的距离跟随车辆1705,并且因此基于该信息,主车辆导航系统可以倾向于将目标车辆1703识别为防御性的。然而,在一些情况下,如上所述,可以在进行侵略性/防御性确定时,分析目标车辆的多于一个的导航特性。进一步分析,主车辆导航系统可以确定,当目标车辆1703以非侵略距离在目标车辆1705后面跟随时,车辆1703相对于车辆1705具有超过与侵略性行为相关联的一个或多个阈值的相对速度和/或相对加速度。实际上,主车辆1701可以确定目标车辆1703相对于车辆1705正在加速,并且靠近存在于车辆1703与1705之间的间隙。基于对相对速度、加速度和距离(以及甚至是车辆1703与1705之间的间隙正在靠近的速率)的进一步分析,主车辆1701可以确定目标车辆1703正在侵略性地表现行为。因此,虽然可能存在主车辆可以安全地导航进入的足够间隙,但主车辆1701可以预期在目标车辆1703前方的并道将导致在主车辆紧后面的侵略性地导航的车辆。此外,基于通过图像分析或其他传感器输出观察到的行为,目标车辆1703可以被预期为:如果主车辆1701要在车辆1703的前方并道,则目标车辆1703将继续加速朝向主车辆1701或者以非零相对速度继续朝向主车辆1701行驶。从安全角度来看,这种情况可能是不希望的,并且也可能导致主车辆的乘客不适。出于这种原因,如图17b所示,主车辆1701可以选择为车辆1703让路,并且在车辆1703后面并且在车辆1710的前方并道至环形路,该车辆1710基于对其一个或多个导航特性的分析而被视为是防御性的。
回到图18,在步骤1809,主车辆的导航系统的至少一个处理设备可以基于识别的目标车辆相对于识别的障碍物的至少一个导航特性,来确定主车辆的导航动作(例如,在车辆1710的前方和车辆1703的后方并道)。为了实施该导航动作(在步骤1811),至少一个处理设备可以响应于所确定的导航动作引起对主车辆的导航致动器的至少一个调节。例如,可以应用制动器以便让路给图17a中的车辆1703,并且加速器可以与主车辆的车轮的转向一起应用以便使主车辆在车辆1703后面进入环形交叉口,如图17b所示。
如以上示例中所述,主车辆的导航可以基于目标车辆相对于另一车辆或对象的导航特性。另外,主车辆的导航可以仅基于目标车辆的导航特性而不特别参考另一车辆或对象。例如,在图18的步骤1807处,对从主车辆的环境捕捉的多个图像的分析可以使得能够确定识别的目标车辆的至少一个导航特性,该导航特性指示与目标车辆相关联的侵略等级。导航特性可以包括速度、加速度等,其不需要相对于另一对象或目标车辆进行参考,以便进行侵略性/防御性的确定。例如,观察到的与目标车辆相关联的超过预定阈值或落入或超过数值范围的加速度和/或速度可以指示侵略性行为。相反,观察到的与目标车辆相关联的低于预定阈值或落入或超过数值范围的加速度和/或速度可以指示防御性行为。
当然,在一些情况下,为了进行侵略性/防御性的确定,可以相对于主车辆来参考所观察到的导航特性(例如,位置、距离、加速度等)。例如,观察到的目标车辆的指示与目标车辆相关联的侵略等级的导航特性可以包括目标车辆与主车辆之间的相对加速度的增加、主车辆后方目标车辆的跟随距离、目标车辆与主车辆之间的相对速度等。
基于事故责任(liability)约束的导航
如以上各节所述,可以针对预定的约束测试规划导航动作,以确保符合某些规则。在一些实施例中,这个概念可以扩展到潜在事故责任的考虑。如下所述,自主导航的主要目标是安全。由于绝对安全可能是不可能的(例如,至少因为处于自主控制下的特定主车辆不能控制其周围的其他车辆——它只能控制其自身的动作),在自主导航中使用潜在事故责任作为考虑因素,并且实际上作为对规划动作的约束,可有助于确保特定的自主车辆不采取任何被认为不安全的动作——例如,潜在事故责任可能附给主车辆上的那些动作。如果主车辆仅采取安全的并且被确定不会导致主车辆自身过错(fault)或责任的事故的动作,那么可以实现期望的事故避免等级(例如,每小时驾驶少于10-9)。
大多数当前的自主驾驶方法带来的挑战包括缺乏安全保证(或至少无法提供期望的安全等级),以及也缺乏可扩展性。考虑保证多作用者安全驾驶的问题。由于社会不太可能容忍机器造成的道路事故死亡,因此可接受的安全等级对于接受自动驾驶车辆至关重要。虽然目标可能是提供零事故,但这可能是不可能的,因为事故中通常涉及多个作用者,并且可以设想事故完全是由于其他作用者的责任而发生的情况。例如,如图19所示,主车辆1901在多车道高速公路上驾驶,虽然主车辆1901可以控制其自身相对于目标车辆1903、1905、1907和1909的动作,但是它不能控制其周围的目标车辆的动作。结果,如果车辆1905例如在与主车辆的碰撞路线上突然切入主车辆的车道,主车辆1901可能无法避免与至少一个目标车辆发生事故。为了解决这一难题,自主车辆从业者的典型响应是采用统计数据驱动的方法,在这种方法中,随着更多里程上的数据被收集,安全验证变得更加严格。
然而,为理解针对安全的数据驱动方法的问题本质,首先要考虑的是,已知每小时(人类)驾驶事故引起的死亡的概率为10-6。合理的假设是,为了使社会接受机器在驾驶任务中代替人类,死亡率应该降低三个数量级,即降低到每小时10-9的概率。这一估计与假设的气囊死亡率相似并且来自航空标准。例如,10-9是机翼在半空中自发脱离飞机的概率。然而,试图使用通过累积驾驶里程来提供额外的置信度的数据驱动的统计方法来保证安全是不实际的。保证每小时驾驶10-9的死亡概率所需的数据量与其倒数(即109小时的数据)成比例,其大约为300亿英里的量级。此外,多作用者系统与其环境交互,并且可能无法离线验证(除非有逼真模拟器是可用的,该逼真模拟器以其全部的丰富性和复杂性来模拟真实人类驾驶(诸如鲁莽的驾驶)——但是验证该模拟器的问题甚至比创建安全的自主车辆作用者还要困难)。对规划和控制软件的任何改变都将需要同样量级的新数据收集,这显然是不实用和不切实际的。此外,通过数据开发系统总是遭受缺乏对被采取动作的可解译性(interpretability)和可解释性(explainability)——如果自主车辆(autonomousvehicle,av)发生事故导致死亡,我们需要知道原因。因此,需要一种针对安全的基于模型的方法,但是汽车工业中现有的“功能安全”和asil要求并不是为了应对多作用者环境而设计的。
为自主车辆开发安全驾驶模型的第二主要挑战是对可扩展性的需求。av的前提不仅仅是“建设更美好的世界”,而是基于这样一个前提,即没有驾驶员的移动性可以以比有驾驶员的移动性更低的成本得以维持。这一前提总是与可扩展性的概念相结合——即,支持av的大规模生产(以百万计),并且更重要的是支持可以忽略不计的增量成本,以便能够在新的城市驾驶。因此,计算和感测的成本确实很重要,如果要大规模制造av,验证的成本和在“每个地方”驾驶而不是在选择的少数几个城市的能力也是维持业务的必要要求。
大多数当前方法的问题在于沿着三个轴的“蛮力”心态:(i)所需的“计算密度”,(ii)高清地图被定义和创建的方式,以及(iii)传感器的所需规格。蛮力方法与可扩展性背道而驰,并将重心转移到不受限的车载计算无处不在的未来,在未来,构建和维护hd地图的成本变得可忽略不计且可扩展,奇异的超高级传感器将被开发、生产到汽车级并且成本可以忽略不计。实现上述任何一种情况的未来确实是可能的,但使上述所有情况成立很可能是低概率事件。因此,有必要提供一种形式(formal)模型,将安全和可扩展性结合成社会可以接受的、并且在支持数百万辆汽车在发达国家的任何地方驾驶的意义上是可扩展的av程序。
所公开的实施例表示了一种解决方案,该解决方案可以提供目标安全等级(或者甚至可以超过安全目标),并且还可以扩展到包括数百万辆(或更多)自主车辆的系统。在安全方面,引入被称为“责任敏感安全(responsibilitysensitivesafety,rss)”的模型,该模型将“事故归责”的概念形式化,是可解译和可解释的,并将“责任”观念合并到机器人作用者的动作中。rss的定义对实施它的方式是不可知的——这是促进创建令人信服的全局安全模型的目标的关键特征。rss的动机是,观察到(如图19所示)作用者在通常只有其中一个作用者对事故负责并且因此要对该事故负责的事故中起着不对称的作用。rss模型还包括在有限的感测条件下对“谨慎驾驶”的形式处理,在这种条件下,并非所有的作用者都总是可见的(例如,由于遮挡)。rss模型的一个主要目标是保证作用者永远不会发生“归责”给它或它要负责的事故。只有当模型带有符合rss的有效策略(例如,将“感测状态”映射到动作的功能)时,它才可能有用。例如,当前时刻看似无辜的动作可能会在遥远的将来导致灾难性事件(“蝴蝶效应”)。rss可有助于在短期的将来构建一组局部约束,这些约束可以保证(或至少实际上保证)未来不会因主车辆的动作而发生事故。
另一贡献围绕“语义(semantic)”语言的引入而进展,该“语义”语言包括单位、测量和动作空间,以及如何将它们合并到av的规划、感测和致动中的规范。为了获得语义观念,在此上下文中,考虑参加驾驶课程的人是如何被指导去思考“驾驶策略”的。这些指令不是几何的——它们不用“以当前速度行驶13.7米,然后以0.8m/s2的速率加速”的形式。相反,这些指令是语义性质的——“跟随你前面的车”或“在你左侧超过那辆车”。人类驾驶策略的典型语言是关于纵向和横向目标,而不是通过加速度矢量的几何单位。形式语义语言在多个方面可能是有用的,这些方面涉及不随时间和作用者数量成指数级比例增加的规划的计算复杂性、安全和舒适交互的方式、对感测的计算进行定义的方式、传感器模态的规格以及它们在融合方法中如何交互。融合方法(基于语义语言)可以确保rss模型实现所需的每一小时驾驶10-9的死亡概率,同时只对量级为105小时的驾驶数据的数据集执行离线验证。
例如,在强化学习设置中,q函数(例如,对当作用者处于状态s∈s时,执行动作a∈a的长期质量进行评估的函数;给定这样的q函数,动作的自然选择可以是挑选具有最高质量的动作π(s)=argmaxaq(s,a))可以在语义空间上定义,在该语义空间中,在任何给定时间要检查的轨迹的数量以104界定,而不管用于规划的时间范围。这个空间中的信噪比可能是高的,允许有效的机器学习方法成功地对q函数建模。在对感测进行计算的情况下,语义可以允许区分影响安全的错误和影响驾驶舒适性的错误。我们定义用于感测的pac模型(可能近似正确(probablyapproximatecorrect,pac),借用了valiant的pac学习术语),将该模型与q函数相配合,并展示了测量错误是如何以符合rss的方式合并到规划、同时又能允许优化驾驶舒适性的。语义语言对于该模型的某些方面的成功可能很重要,因为误差(诸如相对于全局坐标系统的误差)的其他标准测量可能不符合pac感测模型。此外,语义语言可能是定义hd地图的重要促成因素,hd地图可以使用低带宽感测数据构建,从而通过众包(crowdsourcing)和支持可扩展性来构建。
总而言之,所公开的实施例可以包括涵盖av的重要成分的形式模型:感测、规划和行动。该模型可能有助于确保从规划的角度来看,不会发生av自身责任的事故。并且通过pac感测模型,即使存在感测误差,所描述的融合方法也可能只需要非常合理量级的离线数据收集来符合所描述的安全模型。此外,该模型可以通过语义语言将安全和可扩展性配合在一起,从而为安全和可扩展的av提供完整的方法。最后,值得注意的是,制定将会被业界和监管机构采用的被接受的安全模型可能是av成功的必要条件。
rss模型通常遵循经典的感测-规划-行动机器人控制方法。感测系统可以负责理解主车辆环境的当前状态。规划部分可以被称为“驾驶策略”,并且可以由一组硬编码指令、通过经训练的系统(例如,神经网络)或组合来实施,该规划部分可以负责根据用于实现驾驶目标(例如,如何从左车道移动到右车道以便离开高速公路)的可用选项来确定最佳的下一步移动。行动部分负责实施规划(例如,致动器和用于对车辆进行转向、加速和/或制动等以便实施所选择的导航动作的一个或多个控制器的系统)。下面描述的实施例主要集中在感测和规划部分。
事故可能源于感测误差或规划误差。规划是多作用者的努力,因为还有其他道路使用者(人和机器)对av的动作做出反应。所描述的rss模型被设计为解决规划部分的安全等问题。这可以被称为多作用者安全。在统计方法中,规划误差的概率的估计可以“在线”完成。也就是说,软件每次更新后,必须用新版本驾驶数十亿英里,以提供规划误差的频率的估计的可接受等级。这显然是不可行的。作为一种替代,rss模型可以对规划模块不会犯归责给av的错误(形式上定义了“归责”的概念)提供100%的保证(或几乎100%的保证)。rss模型还可以提供一种不依赖于在线测试的用于其验证的有效方法。
感测系统中的误差可能更容易验证,因为感测可以独立于车辆动作,因此我们可以使用“离线”数据验证严重感测误差的概率。但是,即使收集超过109小时驾驶的离线数据,也很有挑战性。作为所公开的感测系统的描述的一部分,描述了一种融合方法,其可以使用显著更少量的数据来验证。
所描述的rss系统也可以扩展到数百万辆汽车。例如,所描述的语义驾驶策略和所应用的安全约束可以与即使在当今的技术中也能扩展到数百万辆汽车的感测和映射(mapping)要求相一致。
对于这样的系统的基础构造块来说,是彻底的安全定义,即av系统可能需要遵守的最低标准。在下面的技术引理中,用来验证av系统的统计方法被证明是不可行的,即使是用于验证简单的声明,诸如“系统每小时发生n起事故”。这意味着,基于模型的安全定义是用于验证av系统的唯一可行工具。
引理1令x为概率空间,并且a为pr(a)=p1<0.1的事件。假设我们从x采样
pr(z=0)≥e-2。
证明我们使用不等式1-x≥e-2x(在附录a.1中证明了完整性),得到
推论1假设av系统av1以很小但不足(smallyetinsufficient)的概率p1发生事故。被给予1/p1个样本的任何确定性验证程序都将以恒定的概率无法区分av1和从不发生事故的不同av系统av0。
为了获得对这些概率的典型值的透视,假设我们希望事故概率为每小时10-9,而某个av系统提供仅10-8的概率。即使该系统获得了108小时的驾驶,仍有恒定的概率该验证过程将无法指示该系统是危险的。
最后,请注意,该困难在于使单一、特定、危险的av系统无效。完整的解决方案(solution)不能被看作是单一的系统,因为需要新的版本、错误修正和更新。从验证器的角度来看,每一次改变,甚至是单行代码的改变,都会生成新的系统。因此,一个经过统计验证的解决方案,必须在每次小的修正或改变后通过新的样本在线验证,以应对新系统观察到和得出的状态分布的偏移。重复且系统地获得如此大量的样本(并且即使如此,也以恒定的概率无法验证系统)是不可行的。
此外,任何统计性的声明都必须被形式化来进行衡量。声明一系统发生的事故的数量的统计属性比声明“它以安全的方式驾驶”要弱得多。为了说明这一点,必须形式上定义什么是安全。
绝对安全是不可能的
如果在未来某个时间没有事故跟随动作a发生,则汽车c采取的动作a可以被认为是绝对安全的。通过观察例如如图19所描绘的简单的驾驶场景,可以看出,是不可能实现绝对安全的。从车辆1901的角度来看,没有任何动作可以确保周围的车辆不会撞上它。通过禁止自主汽车处于这种情况来解决这个问题也是不可能的。由于每条有两条以上车道的高速公路都会在某一点导致这种场景,禁止这种场景相当于要求留在车库里。乍一看,这种暗示可能看起来令人失望。没有什么是绝对安全的。然而,如上所述,对绝对安全的这种要求可能过于苛刻,事实证明人类驾驶员并不遵守绝对安全的要求。相反,人类根据依赖于责任的安全理念行事。
责任敏感安全
绝对安全概念中缺少的重要方面是大多数事故的不对称——通常是其中一个驾驶员对撞车负责,并且要被归责。在图19的示例中,如果例如左侧汽车1909突然驶入中央汽车1901,则中央汽车1901不应被归责。为了将考虑到其缺乏责任的事实形式化,av1901待在自己车道上的行为可以被认为是安全的。为此,描述了“事故归责(accidentblame)”或事故责任的形式概念,可以作为安全驾驶方法的前提。
作为示例,考虑两辆汽车cf、cr以相同的速度、一辆在另一辆后面、沿着直道行驶的简单情况。假设处于前面的汽车cf因为路上出现障碍物而突然制动并设法避开它。不幸的是,cr没有与cf保持足够的距离,不能及时作出响应,并撞上cf的后侧。很明显,责任在于cr;后车有责任与前车保持安全距离,并为意外但合理的制动做好准备。
接下来,考虑一系列更广泛的场景:行驶在多车道道路上,其中汽车可以自由改变车道、切入其他汽车的路径、以不同的速度行驶,等等。为了简化以下讨论,假设在平面上有一条直道,其中横向轴和纵向轴分别是x轴和y轴。在温和条件下,这可以通过定义实际弯道和直道之间的同态(homomorphism)来实现。另外,考虑离散的时间空间。定义可能有助于区分两组直观上不同的情况:不执行显著的横向操纵(lateralmaneuver)的简单的情况、和涉及横向运动的更复杂的情况。
定义1(汽车廊道(corridor))汽车c的廊道是一个范围[cx,left,cx,right]×[±∞],其中cx,left,cx,right是c的最左、最右角的位置。
定义2(切入)若汽车c1(图20a和20b中的汽车2003)在时间t-1不与汽车c0(图20a和20b中的汽车2001)的廊道相交,并且在时间t与c0的廊道相交,则汽车c1在时间t切入汽车c0的廊道。
可以在廊道的前/后部分之间作进一步区分。术语“切入方向”可以描述在相关廊道边界方向上的运动。这些定义可以定义有横向运动的情况。对于不存在这种发生的简单情况,诸如汽车跟随另一辆汽车的简单情况,定义了安全纵向距离:
定义3(安全纵向距离)若对于由cf执行的任何制动命令a,|a|<amax,brake,如果cr从响应时间p应用其最大制动直到完全停止,然后其不会与cf相撞,那么汽车cr(汽车2103)和位于cr的前方廊道的另一辆汽车cf(汽车2105)之间的纵向距离2101(图21)关于响应时间p是安全的。
下面的引理2计算d作为cr、cf的速度、响应时间ρ和最大加速度amax,brake的函数。ρ和amax,brake都是常数,都应通过规定被确定为一些合理的值。
引理2令cr为纵轴上在cf后面的车辆。令amax,brake、amax,accel为最大制动和最大加速度命令,并且令ρ为cr的响应时间。令υr、υf为汽车的纵向速度,并且令lf、lr为它们的长度。定义υp,max=υr+ρ·amax,accel,并定义
证明令dt为时间t时的距离。为了防止事故,对于每一个t,我们必须让dt>l。为了构造dmin,我们需要找到对d0的最紧需的下限。显然,d0必须至少为l。只要两辆汽车在t≥ρ秒后没有停止,前一辆车的速度将为υf–tamax,brake,而cr的速度的上限将为υρ,max–(t–ρ)amax,accel。因此,在t秒后,汽车之间的距离的下限将为:
注意,tr是cr达到完全停止(速度为0)的时间,并且tf是另一车辆达到完全停止的时间。注意,amax,brake(tr–tf)=υρ,max–υf+ρamax,brake,所以如果tr≤tf,要求d0>l就足够了。如果tr>tf,则
要求dtr>l并重新排列项就可以得出证明的结论。
最后,定义了一个比较运算符,它允许带有一些“余量”的概念进行比较:当比较长度、速度等时,有必要接受非常相似的量为“相等”。
定义4(μ-比较)两个数字a、b的μ-比较为:若a>b+μ则a>μb;若a<b–μ则a<μb;若|a–b|≤μ则a=μb。
下面的比较(argmin、argmax等)是针对一些合适的μ的μ-比较。假设汽车c1、c2之间发生了事故。为了考虑谁应对事故负责,定义了需要检查的相关时刻。这是事故发生前的某个时间点,并且直观地是“不可返回的点”;在那之后,没有什么能阻止事故的发生。
定义5(归责时间(blametime))事故的归责时间是事故发生前满足如下条件的最早时间:
·其中一辆汽车和另一辆汽车的廊道之间有相交(intersection),并且
·纵向距离不安全。
显然存在这样一个时间,因为在事故发生的时刻,两个条件都成立。归责时间可以分为两个不同的类别:
·一类是其中也发生了切入,即,它们是一辆汽车和另一辆汽车的廊道相交的第一时刻,并且在不安全的距离内。
·一类是其中不发生切入,即,已经与廊道相交了,处于安全的纵向距离,并且该距离在归责时间时已变为不安全。
定义6(μ-横向速度失败)假设汽车c1、c2之间发生切入。假如c1相对于切入的方向的横向速度比c2的横向速度大μ,则我们将c1称为μ-横向速度失败。
应当注意的是速度的方向很重要:例如,速度-1、1(两辆车撞向彼此)是平局(tie),然而如果速度是1、1+μ/2,则正向朝着另一辆汽车的那辆汽车应该被归责。直觉上,这个定义允许我们归责给一辆横向向另一辆汽车开得很快的汽车。
定义7((μ1,μ2)-横向位置获胜)假设汽车c1、c2之间发生切入。假如c1相对于切入车道的中心(最靠近切入相关廊道的中心)的横向位置比μ1小(以绝对值),并且比c2的横向位置小μ2,则我们将c1称为(μ1,μ2)-横向位置获胜。
直觉上,如果一辆汽车非常靠近车道中心(μ1),并且比另一辆汽车更靠近(更靠近μ2),将不会归责给它。
定义8(归责)汽车c1、c2之间事故的归责或责任是归责时间时的状态的函数,并且定义如下:
·如果归责时间不是切入时间,则归责给后面的汽车。
·如果归责时间也是切入时间,则归责给两辆汽车,除非对于其中一辆汽车c1(不失一般性),对于某些预定义的μ,以下两个条件成立:
·它没有横向速度失败,
·它横向位置获胜。
在这种情况下,c1是幸免的。换句话说,如果发生不安全的切入,两辆汽车都要被归责,除非其中一辆汽车(明显)没有更快的横向速度,并且(明显)更靠近车道中心。这样,就可以捕捉到想要的行为:如果正在跟随一辆汽车,保持安全的距离,并且如果切入一辆只在自己车道上行驶的汽车的廊道,仅在安全的距离处切入。如下文进一步讨论的,用于遵循上述安全指南的基于自动控制器的系统不应导致过度防御性驾驶。
处理有限感测
在考虑了高速公路的示例之后,接下来的第二示例解决了有限感测的问题。当被归责了事故时,非常常见的人类响应落入“但我没能看到他”类别。很多时候,这是真的。人类的感测能力是有限的,有时是因为把注意力集中在道路的不同部分的无意识的决定,有时是因为粗心大意,有时是因为物理限制——不可能看到藏在停着的汽车后面的行人。在这些人类限制中,先进的自动感测系统可能只受后者的制约:360°的道路视野以及计算机从不粗心大意的事实,使它们凌驾于人类的感测能力之上。回到“但我没能看到他”的示例,恰当的回答是“好吧,你应该更小心一点的”。为了使关于有限感测要小心的事物形式化,考虑如图22所示的场景。汽车2201(c0)正试图离开停车场,并入一条(可能)繁忙的道路,但看不到街上是否有汽车,因为它的视野被建筑2203遮挡住了。假设这是一条城市的狭窄街道,速度限制为30公里/小时。人类驾驶员的行为是慢慢并入道路,获得越来越多的视场,直到感测限制消除。应该定义一个重要的时刻——被遮挡对象暴露给我们的第一时间;在其暴露后,人们就像能感测到的任何其他对象一样来处理它。
定义9(暴露时间(exposuretime))对象的暴露时间是我们看到它的第一时间。
定义10(由于不合理的速度的归责)假设在暴露时间或暴露时间之后,汽车c1(汽车2205)以速度υ>υlimit行驶,并且c0没有这样做。那么,只归责给c1上。我们说c1由于不合理的速度而被归责。
这个扩展允许c0安全地离开停车场。使用我们先前的责任敏感安全定义以及动态υlimit定义(其使用道路条件和速度限制,加上合理的余量),仅仅需要做的是检查在最坏的情况下,如图所示,切入是否在安全的纵向距离内,同时假设c1不会超过υlimit。直觉上,这鼓励c0开得更慢且距障碍物更远,从而慢慢增加其视场,之后允许安全地并入街道。
将事故责任定义扩展到有限感测这一基本情况后,一系列扩展可以解决类似的情况。关于什么可以被遮挡(一辆潜在的快速汽车不能在两辆停得很近的汽车之间被遮挡,但是行人能被遮挡)、以及它能执行的最坏情况操纵(行人的υlimit比汽车的υlimit小得多)的简单假设,意味着对驾驶的限制——必须做好最坏的准备,并且有能力在暴露时间突然到来时做出响应。在城市场景中,可以从可能被停放的汽车遮挡的行人的场景中举出更详细的示例。与行人发生的事故的事故归责可定义为:
定义11(行人事故归责(accident-with-pedestrianblame))行人事故归责总是在汽车上,除非以下三种情况之一成立:
·汽车以汽车的侧面撞击行人,汽车关于撞击方向的横向速度小于μ。
·行人在暴露时间或之后的速度大于υlimit。
·汽车处于完全停止。
非形式上地,只有当行人撞向汽车的侧面,而汽车没有以比μ快的速度驶向行人,或者如果汽车是处于停止的,或者如果行人在某个方向(不一定是撞击方向)超出常人地快速跑,汽车才不被归责。
尽管所描述的系统可能无法确保绝对安全,但它可能会导致在自主车辆当中很少(如果有的话)事故发生的情况。例如,在所有的汽车(和其他道路使用者)能够成功地验证他们不会因为所采取的动作导致的事故而被归责的情况下,事故就可以被消除。根据定义,每起事故至少有一辆负责任的汽车。因此,如果没有汽车采取可能为导致的事故负责的动作(根据上述rss模型),就决不应该有任何事故,从而产生不实用和不切实际的统计方法所寻求的绝对安全或接近绝对安全的类型。
不是所有的路都是简单的结构。有些,像交叉口和环形道,包含更复杂的情况以及各种路权规则。并非所有被遮挡对象都是汽车或行人,自行车和摩托车都是要被考虑的合法的道路使用者。本部分介绍的原理可以扩展到这些额外的情况。
责任敏感安全的有效验证条件
本部分讨论rss的实施方面。首先,应该注意的是,现在执行的动作可能具有蝴蝶效应,其例如在驾驶10分钟后会导致一连串有事故的事件。检查未来所有可能结果的“蛮力”方法不仅不切实际,而且很可能是不可能的。为了克服这一挑战,上面描述的责任敏感安全定义现在与计算上有效的方法一起被描述来验证它们。
计算上可行的安全验证。
计算上可行的验证的主要数学工具是“归纳法”。要通过归纳法来证明一个声明,首先要证明简单情况的声明,然后,每个归纳法步骤都将证明扩展到越来越多的相关情况。为了说明这种归纳工具如何有助于安全验证,请再次考虑汽车cr跟随另一汽车cf的简单示例(参见图21)。以下约束可以应用于cr的策略上。在每个时间步t,策略可以挑选任何加速度命令,使得即使cf将应用-amax的减速度,下一时间步之时cr和cf之间产生的距离将至少是安全纵向距离(定义3和引理2中定义)。如果不存在这样的动作,cr必须应用减速-amax。下面的引理使用归纳法来证明任何遵守上述约束的策略都决不会与cf发生事故。
引理3在定义3中给出的假设下,如果cr的策略遵守上面给出的约束,它将决不会与cf发生事故。
证明通过归纳法来证明。基于归纳法,从两辆汽车之间的距离是安全的(根据引理2)的初始状态开始。归纳步骤如下。考虑在某个时间t,cr和cf之间的距离。如果有一个动作导致安全距离(即使cf作出最大减速的情况),我们也很乐意。如果所有动作都不能保证安全距离,令t′<t为我们采取非最大减速的动作的最大时间。根据归纳法假设,在时间t'+1处,我们在一个安全的距离,从那开始,我们执行最大减速。因此,根据安全距离的定义,从时间t'到现在没有碰撞,这就得出了证明的结论。
上面的示例证实了更一般的想法:在极端情况下,cr可以执行一些紧急操纵,并将其引导回“安全状态”。应该注意的是,我们上面描述的对策略的约束只取决于一个未来的时间步,因此它可以以计算上有效的方式来验证。
为了概括这些对rss足够的局部属性的想法,我们首先定义了默认紧急策略(defaultemergencypolicy,dep),并将其用作定义我们称之为“谨慎(cautious)”的动作采取的局部属性的构造块。结果表明,对于rss来说,只采用谨慎的命令就足够了。
定义12(默认紧急策略)默认紧急策略(dep)是应用最大制动力、以及朝着相对于车道的0航向的最大航向改变。最大制动力和航向改变从汽车的物理参数(也可能从天气和路况)导出。定义13(安全状态)如果从某个状态s开始执行dep不会导致归责给我们的事故,则这个状态s是安全的。就像在一辆汽车跟随另一辆汽车的简单情况中一样,如果某个命令导致安全状态,则我们将其定义为是谨慎的。定义14(谨慎命令(cautiouscommand))假设我们当前处于状态s0。如果相对于其他车辆现在可能执行的可能命令的集合a,下一状态s1是安全的,则命令a是谨慎的。上述定义取决于集合a中的其他车辆可能会执行的最坏情况下的命令。我们将基于最大制动/加速度和横向运动的合理上限来构建集合a。
下面的定理再次通过归纳法证明,如果我们只发出谨慎命令,那么就不会有归责给我们的事故。定理1假设在时间0,c处于安全状态,并且对于每个时间步,c只发出谨慎命令,如果在某个时间步处不存在谨慎命令,c应用dep。那么,c决不会发生归责给它的事故。证明通过归纳法。归纳法的基础来自安全状态的定义,并且基于谨慎命令的定义。
这种方法的一个好处是,可能没有必要检查无限的未来,因为我们可以迅速回到安全状态,并从那里安全地继续。此外,考虑到我们将在t+1时再次规划,因此如果必要的话能够在那时执行dep,我们应该只检查我们在时间t给出的命令,而不是我们可能想到的更长的规划——我们可以在t+1时改变这个规划。现在,当在运行时用这个透明模型来验证学习组件时,将学习组件合并到系统中成为可能。最后,这种局部验证意味着完整的未来rss,这是我们期望的目标。一个实现障碍是谨慎性(cautiousness)定义涉及到另一作用者直到tbrake可以执行的所有轨迹,即使对于中等的tbrake,这也是一个巨大的空间。为了解决这个问题,我们接下来转到开发一种有效的可计算方法,以可扩展的方式验证谨慎性,从而验证rss。
有效谨慎性验证
第一个观察(observation)是,当且仅当存在特定的车辆
当考虑单个目标汽车时,当且仅当存在一系列对
引理4假设在时间t=0,
证明假设a不是谨慎的,即,存在导致归责给c的事故的
最后,如果t<0,根据引理的假设,在切入的时刻,
根据引理4,检查是否可以存在归责给c的不安全切入的问题仍然存在。下面给出了一种有效的算法,用于检查在时间t不安全切入的可能性。为了验证整个轨迹,我们将时间间隔[0,tbrake]离散化,并将该算法应用于所有时间间隔(在安全距离定义中使用稍大的p值,以确保离散化不会造成损伤)。令
以下定理证明了上述算法的正确性。
定理2如果算法1返回“不可行”,那么在时间t,不会有归责给自我(ego)车辆的不安全切入。为了证明这个定理,我们依赖下面的关键引理,它证明了算法1的两个构造块的正确性。从纵向可行性开始:
引理5在算法1的注释下,如果检查纵向可行性程序是通过返回“不可行”来结束的,则在时间t不会有归责给自我车辆的非安全切入。
证明忽略切入操纵的横向方面,我们仅仅检验c和
接下来,横向可行性。
引理6在算法1的注释下,如果检查横向可行性程序是通过返回“不可行”来结束的,则在时间t不会有归责给自我车辆的不安全切入。
证明首先,很明显,通过坐标的简单改变和相对速度的考虑,x[t]=0,
请注意,在我们的示例中,切入中所涉及的汽车的位置是(x[t],x[t]–w),这意味着一些(μ1,μ2)-横向位置获胜属性影响了归责。通过我们对υx[t]的假设,我们得到,
从算法中回想
考虑ttop>0的情况。那么,由于xmax<–w,程序返回“不可行”。考虑时间范围[0,t]内的
第一,可以看出ua满足约束
观察到,由于算法中定义的xmax是<x[t]–w的,因此我们有acut>ax,max。这不足以证明没有有效的操纵可以导致位置≥x[t]–w;这仅适用于u族成员。我们现在证明,即使在u之外,所有达到最终位置x[t]–w的速度分布在途中必须使用至少为acut的加速度值,使其无效,从而完成证明。
假设某个速度分布u满足边界约束
假设对所有τ满足
这意味着u的不可行性,因为它使用的加速度(即u',速度的导数)超过ax,max。
现在,假设
安全验证-遮挡
以与处理观察到的对象相似的方式,我们可以用与定理1相似的定理来定义关于被遮挡对象的谨慎性的扩展,证明谨慎性意味着决没有归责给我们的事故。
定义15(关于被遮挡对象的谨慎性)如果在对象的暴露时间为t+1并且我们在t+1发出默认紧急策略(dep)命令的情况下,将不会发生归责给我们的事故,则在时间t给出的命令关于被遮挡对象是谨慎的。
引理7如果我们只给出关于被遮挡对象和未被遮挡对象的谨慎命令,就决不会有归责给我们的事故。
证明假设归责给我们的事故发生在时间t,暴露时间t'≤t。通过谨慎性假设,在t'–1给出的命令允许我们在t'发出dep命令,而不会因为事故被归责。由于发生了归责给我们的事故,我们显然没有在时间t'发出dep命令。但从t'起,我们关于未被遮挡对象是安全的,因此我们给出的命令是安全的,并且没有归责给我们的事故。
在这里,我们也提供了有效的方法来检查关于被遮挡对象的最坏情况假设的谨慎性,允许可行的、可扩展的rss。
驾驶策略
驾驶策略是从感测状态(对我们周围世界的描述)到驾驶命令(例如,该命令是下一秒的横向和纵向加速度,其决定了从现在起的下一秒汽车应该在哪里以及以什么速度行驶)的映射。驾驶命令被传递给控制器,其目标是将汽车实际移动到期望的位置/速度。
在前面的部分中,描述了形式安全模型以及所提出的对由驾驶策略所发布的命令的、保证安全的约束。对安全的约束是针对极端情况设计的。通常,我们甚至不希望需要这些约束,而是希望构建能够带来舒适驾驶的驾驶策略。本部分的重点是如何建立一个有效的驾驶策略,特别是需要可扩展到数百万辆汽车的计算资源的策略。目前,这种讨论没有解决如何获得感测状态以及假设忠实地表示我们周围的世界而没有任何限制的乌托邦(utopic)感测状态的问题。后面的部分将讨论感测状态的不准确对驾驶策略的影响。
如上面部分所讨论的,定义驾驶策略的问题是用强化学习(reinforcementlearning,rl)的语言来表达的。在rl的每次迭代中,作用者观察描述世界的状态,表示为st,并且应当基于将状态映射到动作的策略函数π来挑选一个动作,表示为at。由于它的动作和超出它控制的其他因素(诸如其他作用者的动作),世界的状态被改变为st+1。我们用
为了用上面的rl语言来表达驾驶策略问题,令st为自我车辆以及其他道路使用者的道路、位置、速度和加速度的某一表示。令at为横向和纵向加速度命令。下一状态st+1取决于at以及其他作用者的行为。瞬时奖励ρ(st,at)可能取决于与其他汽车的相对位置/速度/加速度、我们的速度和期望速度之间的差异、我们是否遵循期望的路线、我们的加速度是否舒适等。
在决定策略在时间t应该采取什么动作时,一个挑战来自这样一个事实,即人们需要估计这一动作对奖励的长期影响。例如,在驾驶策略的上下文中,在时间t采取的动作可能看起来是目前的好动作(即,奖励值ρ(st,at)是好的),但可能在5秒后导致事故(即,5秒内的奖励值将是灾难性的)。因此,当作用者处于状态s时,我们需要估计执行动作a的长期质量。这通常被称为q函数,即q(s,a)应该反映在时间s执行动作a的长期质量。给定这样的q函数,动作的自然选择是挑选具有最高质量π(s)=argmaxaq(s,a)的那个。
即刻的问题是如何定义q和如何有效地评估q。让我们首先做出(完全不现实的)简化假设,即st+1是(st,at)的某种确定性函数,也就是说,st+1=f(st,at)。熟悉马尔可夫决策过程(markovdecisionprocess,mdp)的人会注意到,这个假设甚至比mdp的马尔可夫假设(即,st+1条件地独立于过去给定的(st,at))更强。正如[5]中指出的,即使马尔可夫假设也不适用于多作用者场景,诸如驾驶,因此我们稍后将放松该假设。
在这个简化假设下,给定st,对于t个步骤的每个决策序列(at,…,at+t),我们可以精确地计算未来状态(st+1,...,st+t+1)以及时间t,...,t的奖励值。将所有这些奖励值汇总成一个数字,例如,通过取它们的和
也就是说,如果我们现在处于状态s并且立即执行动作a,那么q(s,a)是我们所能期待的最好的未来。
让我们讨论一下如何计算q。第一个想法是将一组可能的动作的集合a离散化为一个有限集合
参数t通常被称为“规划的时间范围”,并且它控制着计算时间和评估质量之间的自然权衡——t越大,我们对当前动作的评估就越好(因为我们显式地更深地检查其对未来的影响),但另一方面,更大的t会指数地增加计算时间。为了理解为什么我们可能需要大的t值,考虑一个场景:我们在高速公路出口前200米并且我们应走这个出口。当时间范围足够长时,累积奖励将指示在t和t+t之间的某个时间τ我们是否已经到达出口车道。另一方面,对于短的时间范围,即使我们执行了正确的即刻动作,我们也不知道它是否会最终把我们引向出口车道。
另一种不同的方法试图执行离线计算,以构造q的近似,表示为
处理这种维数灾难的一种方法是将q限制为来自受限的函数类(通常称为假设类(hypothesisclass)),诸如手动确定特征的线性函数或深度神经网络。例如,考虑深度神经网络,在玩atari游戏的上下文中,它对q进行近似。这导致了资源有效的解决方案,前提是可以有效地评估对q进行近似的函数类。然而,这种方法有几个缺点。首先,不知道所选的函数类是否包含对期望的q函数的良好近似。其次,即使存在这样的函数,也不知道现有算法是否能设法有效地学习它。到目前为止,学习复杂的多作用者问题(诸如我们在驾驶中遇到的问题)的q函数的成功案例还不多。这项任务之所以困难,有几个理论上的原因。正如关于马尔可夫假设所提到的,根本的现有方法是有问题的。但是,更严重的问题是由于作出决策的时间分辨率而导致的信噪比非常小,如下所述。
考虑一个简单的场景,在这个场景中,车辆需要改变车道以便从200米内的高速公路出口出去,并且道路当前是空旷的。最好的决策是开始进行车道改变。可以每0.1秒做出一次决策,因此在当前时间t,q(st,a)的最佳值应该是对于对应于向右侧的小的横向加速度的动作a的。考虑对应于零横向加速度的动作a'。因为现在开始改变车道或者在0.1秒内改变车道之间的差异很小,所以q(st,a)和q(st,a')的值几乎相同。换句话说,选择a比a'只有非常小的益处。另一方面,由于我们使用的是对q的函数近似,并且由于在测量状态st时有噪声,所以我们对q值的近似很可能是有噪声的。这产生非常小的信噪比,这导致非常慢的学习,尤其是对于大量用于神经网络近似类的随机学习算法。然而,正如本文,这个问题不是任何特定函数近似类的属性,而是q函数的定义中所固有的。
总之,可用的方法大致可以分为两个阵营。第一种是蛮力方法,包括搜索许多动作序列或将感测状态域离散化、并在存储器中维护一个巨大的表。这种方法可以得到对q的非常准确的近似,但是无论是在计算时间还是在存储器方面都需要无限的资源。第二种是资源有效的方法,在这种方法中,我们要么搜索短的动作序列,要么对q应用函数近似。在这两种情况下,我们的代价都是对q不太准确的近似,这可能会导致糟糕的决策。
本文描述的方法包括构造一个既资源有效又准确的q函数,以偏离几何动作并适应语义动作空间,如下一部分所述。
语义方法
作为所公开的语义方法的基础,考虑一个刚刚拿到驾照的青少年。他的父亲坐在他旁边,并给他“驾驶策略”指示。这些指令不是几何的——它们不采用“以当前速度行驶13.7米,然后以0.8m/s2的速度加速”的形式。相反,指令是语义性质的——“跟随你前面的车”或“快速在你左侧超过那辆车”。我们为这些指令形式化(formalize)了一种语义语言,并将它们用作语义动作空间。然后我们在语义动作空间上定义q函数。我们揭示了语义动作可以有很长的时间范围,这允许我们在不规划许多未来的语义动作的情况下估计q(s,a)。是的,语义动作的总数尚小。这允许我们在保持资源有效的同时得到对q函数的准确估计。此外,正如我们后面所揭示的,我们结合学习技术来进一步改进质量函数,同时因为不同语义动作之间的显著差异而不会遭受小的信噪比的困扰。
现在定义语义动作空间。主要思想是定义横向和纵向目标,以及实现这些目标的侵略性(aggressiveness)等级。横向目标是车道坐标系统中期望的位置(例如,“我的目标是在2号车道的中心”)。纵向目标有三种类型。第一类型是相对于其他车辆的相对位置和速度(例如,“我的目标是以与3号汽车相同的速度落后于3号汽车,处于距它2秒钟的距离”)。第二类型是速度目标(例如,“以该道路的允许速度的110%行驶”)。第三类型是某个位置的速度约束(例如,当接近交叉口时,“在停车线处速度为0”,或者当通过急转弯时,“在弯道上某个位置处速度最多为60kmh”)。对于第三个选项,我们可以改为应用“速度分布”(路线上的几个离散点以及每个点处的期望速度)。横向目标的合理数量以16=4x4(最多4个相关车道上的4个位置)为界。第一类型的纵向目标的合理数量以8×2×3=48为界(8辆相关汽车,无论是在他们前面还是后面,以及3个相关距离)。绝对速度目标的合理数量是10,速度约束数量的合理上限是2。为了实施给定的横向或纵向目标,我们需要应用加速,然后减速(或者反过来)。实现目标的侵略性是最大(绝对值)加速度/减速度以实现该目标。随着定义了目标和侵略性,我们有封闭形式的公式来使用运动学计算来实施该目标。唯一剩下的部分是确定横向目标和纵向目标之间的组合(例如,“从横向目标开始,并且正好在横向目标的中间,也开始应用纵向目标”)。一组5次混合和3个侵略性等级似乎就足够了。总之,我们得到了大小为≈104的语义动作空间。
值得一提的是,履行这些语义动作所需的可变时间不同于决策做出过程的频率。为了对动态世界做出反应,我们应该以高频率做出决策——在我们的实施方式中,每100毫秒做出决策。相反,每一次这样的决策都是基于构建履行某种语义动作的轨迹,该轨迹将具有更长的时间范围(比如,10秒)。我们使用更长的时间范围,因为它有助于我们更好地评估轨迹的短期前缀(prefix)。下一部分讨论了语义动作的评估,但在此之前,我们论证语义动作归纳了足够的搜索空间。
如上所述,语义动作空间归纳了所有可能的几何弯道(curve)的子集,其大小指数地(以t)小于枚举所有可能的几何弯道。第一个直接的问题是,这个更小的搜索空间的短期前缀的集合是否包含我们将想要使用的所有几何命令。从以下意义上说,这确实足够了。如果道路没有其他作用者,则除了在某些位置设置横向目标和/或绝对加速度命令和/或速度约束之外,没有理由进行改变。如果道路包含其他作用者,我们可能需要与其他作用者协商路权。在这种情况下,相对于其他作用者设置纵向目标就足够了。长期来看,这些目标的具体实施方式可能会有所不同,但短期前缀不会有太大改变。因此,我们可以很好地涵盖相关的短期几何命令。
构建语义动作的评价函数
我们已经定义了语义动作集合,用as表示。假定我们目前在状态s,我们需要一种方法来选择最好的as0as。为了解决这个问题,我们采取了类似于[6]的选项机制的方法。基本思想是把as看作元(meta)动作(或者选项)。对于元动作的每个选择,我们构建表示元动作as的实现的几何轨迹(s1,a1),...,(st,at)。要做到这一点,我们当然需要知道其他作用者将如何对我们的动作做出反应,但是目前我们仍然依赖于(不现实的)假设,即对于某些已知的确定性函数f,st+1=f(st,at)。我们现在可以使用
这种方法可以产生强大的驾驶策略。然而,在某些情况下,可能需要更复杂的质量函数。例如,假设我们在出口车道前跟着一辆慢的卡车,在那里我们需要走出口车道。一个语义选项是继续在卡车后面慢慢行驶。另一个语义选项是超越卡车,希望稍后我们能回到出口车道并且准时从出口出去。前面描述的质量测量没有考虑我们超越卡车后会发生什么,因此即使有足够的时间超车并返回出口车道,我们也不会选择第二个语义动作。机器学习可以帮助我们构造对语义动作更好的评估,它将考虑的不仅仅是即刻的语义动作。如前所述,由于信噪比低(缺乏优势),在即刻几何动作上学习q函数是有问题的。当考虑语义动作时,这是没有问题的,都是因为执行不同的语义动作之间有很大的差异,并且因为语义时间范围(我们考虑了多少语义动作)非常小(在大多数情况下可能少于三个)。
应用机器学习的另一个潜在优势是为了一般化:我们可以通过手动检查道路的属性,为每条道路设置适当的评估函数,这可能涉及一些尝试和误差。但是,我们能自动一般化到任何道路吗?这里,如上所述,机器学习方法可以在多种道路类型上进行训练,以便也一般化到未见的道路。根据所公开的实施例的语义动作空间可以考虑潜在的好处:语义动作包含长时间范围内的信息,因此我们可以在资源有效的同时获得对它们质量的非常准确的评估。
其他作用者的动态
迄今为止,我们一直依赖于st+1是st和at的确定性函数的假设。如前所述,这一假设并不完全现实,因为我们的动作会影响其他道路使用者的行为。虽然我们确实考虑了其他作用者对我们的动作的一些反应(例如,我们假设如果我们执行安全切入,那么我们后面的汽车会调整其速度以免从后面撞上我们),但是假设我们对其他作用者的所有动态进行建模是不现实的。这个问题的解决方案是以高频率重新应用决策做出,并通过这样做,不断地使我们的策略适应超出我们建模范围的环境部分。从某种意义上说,可以把这看作是在每一步对世界的马尔可夫过程。
感测
本部分描述感测状态,即场景相关信息的描述,并形成对驾驶策略模块的输入。总的来说,感测状态包含静态和动态对象。静态对象是车道、物理道路定界符、速度约束、路权约束以及关于遮挡物(例如,遮挡了并入道路的相关部分的围栏)的信息。动态对象是车辆(例如,边界框、速度、加速度)、行人(边界框、速度、加速度)、交通灯、动态道路定界符(例如,建筑区域的锥形物)、临时交通标志和警察活动以及道路上的其他障碍物(例如,动物、从卡车上掉下来的床垫等)。
在任何合理的传感器设置中,我们都不能期望获得精确的感测状态s。相反,我们查看原始传感器和地图数据,我们用x0x表示,并且存在取得x并产生近似感测状态的感测系统。
定义16(感测系统)令s表示感测状态的域,并且令x为原始传感器和地图数据的域。感测系统为函数
理解何时我们应该接受
·漏警(falsenegative):感测系统漏掉了一个对象
·虚警(falsepositive):感测系统指示一个“幻影(ghost)”对象
·不准确测量:感测系统正确检测到对象,但不正确地估计其位置或速度
·不准确语义:感测系统正确地检测到对象,但误解了它的语义含义,例如交通灯的颜色
舒适
回想一下,对于语义动作a,给定当前感测状态为s,我们使用q(s,a)来表示我们对a的评估。我们的策略挑选动作π(s)=argmaxaq(s,a)。如果我们注入
我们可以使用几个(∈,δ)对来评估系统的不同方面。例如,我们可以选择三个阈值∈1<∈2<∈3来表示轻度、中度和严重错误,并且为它们中的每一个设置不同的δ值。这导致以下定义。
定义17(pac感测系统)令((∈1,δ1),...,(∈k,δk))为(准确度,置信度)对的集合,令s为感测状态域,令x为原始传感器和地图数据域,并且令d为x×s上的分布。令a为动作空间,q:s×a→/为质量函数,以及π:s→a使得π(s)∈argmaxaq(s,a)。如果对于每一个i∈{1,...,k}我们有
这里,定义取决于x×s上的分布。重要的是要强调,我们通过记录许多人类驾驶员的数据而不是遵循我们的自主车辆的特定策略来构造这种分布。虽然后者似乎更合适,但它需要在线验证,这使得感测系统的开发不切实际。由于任何合理的策略对d的影响都很小,通过应用简单的数据增强技术,我们可以构造适当的分布,然后在感测系统的每次重大更新后执行离线验证。该定义为使用
接下来,我们推导出遵循以上pac定义的设计原则。回想一下,我们已经描述了几种类型的感测错误。对于漏警、虚警和不准确语义类型的错误,错误要么出现在不相关的对象上(例如,当我们直行时左转的交通灯),要么被该定义的δ部分捕捉。因此,我们关注经常发生的“不准确测量”类型的误差。
有些令人惊讶的是,我们将论证,经由自我准确度(即通过测量每个对象相对于主车辆的位置的准确度)来测量感测系统准确度的流行方法不足以确保pac感测系统。然后,我们将提出一种不同的方法来确保pac感测系统,并将论证如何有效地获得它。我们从一些附加的定义开始。
对于场景中的每个对象o,令p(o)、
要求远处对象的加性误差很小是不现实的。事实上,假设o是一辆距离主车辆150米的车辆,并且令∈为适中大小,比如∈=0.1。对于加性准确度,这意味着我们应该知道车辆的位置高达10厘米的准确度。这对于价格合理的传感器来说是不现实的。另一方面,对于相对准确度,我们需要估计高达10%的位置,这相当于15米的准确度。这是可行的(如下所述)。
如果对于每一个o∈o,p(o)和
也就是说,对于相当小的∈值(小于3.5%的误差),感测系统可以是∈-自我准确度的,然而,对于任何合理的q函数,q的值是完全不同的,因为我们混淆了需要强烈制动的情况和不需要强烈制动的情况。
上面的示例论证了,∈-自我准确度不能保证我们的感测系统是pac的。是否存在另一个属性足以满足pac感测系统取决于q。我们将描述一系列的q函数,其中存在一个简单的定位属性来保证pac感测系统。∈-自我准确度的问题是它可能会导致语义错误——在前面提到的示例中,即使
定义18(语义单位)车道中心是一条简单的自然曲线,也就是说,它是一条可微分的内射映射
类似于几何单位,对于语义纵向距离,我们使用相对误差:如果
定义19(语义单位的误差)令
横向和纵向速度的距离定义类似。有了上面的定义,我们就可以定义q的属性以及相应的pac感测系统的充分条件。
定义20(语义-李普希茨q)如果对于每一个
作为一个直接的推论,我们得到:
引理8如果q是l-语义-李普希茨的,并且感测系统
安全
本部分讨论了导致不想要的行为的感测误差的潜在性。如前所述,策略是可证明安全的,因为它不会导致归责给主av的事故。这种事故仍可能由于硬件故障(例如,所有传感器故障或高速公路上的轮胎爆炸)、软件故障(某些模块中的重大缺陷)或感测错误而发生。我们的最终目标是这种事件的概率非常小——每小时发生这种事故的概率为10-9。为了理解这个数字,在美国驾驶员在道路上花费的平均小时数(截至2016年)不到300小时。因此,按预期,一个人需要活330万年才能发生由这些类型的事件中的一种引起的事故。
我们首先定义什么是安全相关的感测误差。回想一下,在每一步,我们的策略都会挑选使q(s,a)最大化的a的值,即π(s)=argmaxaq(s,a)。对于每一个不谨慎(见定义14)的动作a,我们通过令q(s,a)=∞来确保安全。因此,第一种类型的安全评价器(safety-critic)感测错误是:如果我们的感测系统导致了挑选一个不安全的动作。形式地,令
通常,安全评价器遗漏是由漏警引起的,而安全评价器幻影是由虚警引起的。这种错误也可能是由明显不正确的测量引起的,但是在大多数情况下,我们的舒适目标确保我们远离安全定义的边界,因此合理的测量误差不太可能导致安全评价器错误。我们如何才能确保安全评价器错误的概率非常小,比如说,小于每小时10-9次?如引理1所述,在不做进一步假设的情况下,我们需要在超过109小时的驾驶上检查我们的系统。这是不现实的(或者至少是极具挑战性的)——这相当于记录了一年内330万辆汽车的驾驶。此外,构建达到如此高准确度的系统是巨大的挑战。系统设计和验证挑战两者的解决方案是依赖于几个子系统,每个子系统都是独立设计的,并依赖于不同的技术,这些系统以确保提高他们各自的准确度的方式融合在一起。
假设我们构建了三个子系统,表示为s1、s2、s3(扩展到3个以上是很简单的)。每个子系统接收a并且应该输出安全/非安全。大多数子系统(在我们的示例中是2个)接受为安全的动作被认为是安全的。如果没有动作被至少2个子系统认为是安全的,则应用默认紧急策略。基于以下定义,该融合方案的性能分析如下:
定义21(单侧c-近似独立)两个伯努利随机变量r1、r2若满足:
则被称为单侧c-近似独立。
对于i0{1,2,3},由
因此,如果所有子系统都有
推论2假设对于任意一对i≠j,随机变量
这个推论允许我们使用小得多的数据集来验证感测系统。例如,如果我们想要获得10-9的安全评价器错误概率,取105数量级的示例并分别测试每个系统就足够了,而不用取109数量级的示例。
可能存在产生不相关误差的传感器对。例如,雷达在恶劣天气条件下工作良好,但可能会因不相关的金属对象而失效,这与受恶劣天气影响但不太可能受金属对象影响的相机相反。看起来,相机和激光雷达有共同的误差来源——例如,两者都受雾天、大雨或雪的影响。然而,相机和激光雷达的误差类型会有所不同——相机可能会由于恶劣天气而遗漏对象,而激光雷达可能会由于来自空气中粒子的反射而检测到幻影。由于我们已经区分了这两种类型的误差,近似独立性仍然可能成立。
我们对安全重要的(safety-important)幻影的定义要求:根据至少两个传感器,所有的动作是不安全的。即使在困难的条件下(例如,大雾),这也不太可能发生。原因是,在这种情况下,受困难条件影响的系统(例如,激光雷达)将决定非常防御性的驾驶,因为它们可以宣称高速和横向操纵是不安全的动作。因此,主av将缓慢驾驶,并且然后即使需要紧急停车,因为行驶速度低,也不会有危险。因此,我们的定义使驾驶风格适应道路条件。
构建可扩展的感测系统
已经在舒适性和安全两方面描述了来自感测系统的要求。接下来,描述了一种用于构建满足这些要求同时是可扩展的的感测系统的方法。感测系统有三个主要组件。第一个是基于相机的场景的远距离、360度覆盖。相机的三个主要优点是:(1)高分辨率,(2)纹理,(3)价格。低价格支持可扩展系统。纹理能够理解场景的语义,包括车道标记、交通灯、行人的意图等等。高分辨率支持远距离检测。此外,在同一域中检测车道标记和对象能够实现出色的语义横向准确度。相机的两个主要缺点是:(1)信息是2d的并且估计纵向距离很困难,(2)对光照条件(低日照、恶劣天气)敏感。我们使用我们系统的接下来两个组件来克服这些困难。
我们系统的第二组件是语义高清晰度制图(mapping)技术,称为道路体验管理(roadexperiencemanagement,rem)(它涉及基于为路段预先确定和存储的目标轨迹进行的导航、以及基于在主车辆环境中识别的已识别地标的位置(例如,在图像中)确定沿目标轨迹的精确位置的能力)。地图创建的常见几何方法是在地图创建过程中记录3d点云(由激光雷达获得),然后通过将现有激光雷达点与地图中的点进行匹配来获得地图上的定位。这种方法有几个缺点。首先,每公里的地图数据需要很大的存储器,因为我们需要保存很多点。这需要昂贵的通信基础设施。其次,并不是所有的汽车都装备有激光雷达传感器,因此地图更新非常不频繁。这是有问题的,因为道路中可能发生改变(施工区域、危险),基于激光雷达的制图解决方案的“反射现实时间(time-to-reflect-reality)”很大。与此相反,rem遵循基于语义的方法。这个想法是利用大量的装备有相机和检测场景中的语义上有意义的对象(车道标记、路缘、电线杆、交通灯等)的软件的车辆。如今,许多新车都装备了可用于众包(crowd-sourced)地图创建的adas系统。由于该处理是在车辆端完成的,因此只有少量语义数据应当被传输到云。这允许以可扩展的方式非常频繁地更新地图。此外,自主车辆可以通过现有的通信平台(蜂窝网络)接收小尺寸化的地图数据。最后,可以基于相机获得地图上的高精度定位,而不需要昂贵的激光雷达。
rem可用于多种目的。第一,它让我们对道路的静态结构有所预见(我们可以提前对高速公路出口路进行规划)。第二,它为我们提供了所有静态信息的准确信息的另一来源,它与相机检测一起产生了对世界的静态部分的鲁棒视图(robustview)。第三,它解决了将2d信息从图像平面提升到3d世界的问题,如下所示。该地图将所有车道描述为3d世界中的曲线。自我车辆在地图上的定位能够将道路上的每个对象从图像平面轻松提升到其3d位置。这就产生了遵守语义单位的准确度的定位系统。该系统的第三组件可以是互补的雷达(radar)和激光雷达(lidar)系统。这些系统可以有两个目的。首先,它们可以提供极高的准确度等级来增强安全。其次,他们可以给出对速度和距离的直接测量,这进一步提高了乘坐的舒适性。
以下部分包括rss系统的技术引理和几个实际考虑。
引理9对于所有x0[0,0.1],满足1–x>e-2x。
证明令f(x)=1–x–e-2x。我们的目标是论证,对于x0[0,0.1],f(x)≥0。注意,f(0)=0,因此只要在上述范围内有f(x)≥0就足够了。显式地,f'(x)=–1+2e-2x。显然,f′(0)=1,并且它是单调递减的,因此验证f'(0.1)>0就足够了,这在数值上很容易做到,f'(0.1)≈0.637。
有效谨慎性验证——被遮挡对象
与未被遮挡对象一样,我们可以检查给出当前命令然后dep是否为rss。为此,当假设暴露时间为1并在那时我们发出dep命令(根据定义,这足以满足谨慎性)时,我们展开(unroll)我们的未来直到tbrake。对于所有t'0[0,tbrake],我们检查是否会发生可归责的事故——当假设被遮挡对象出现最坏情况时。我们使用一些我们的最坏情况下的操纵和安全距离规则。我们采用基于遮挡物的方法来寻找兴趣点——也就是说,对于每个遮挡对象,我们计算最坏情况。这是一种至关重要的效率驱动的方法——例如,行人可以藏在汽车后面的许多位置,并且可以执行许多操纵,但是只有单个它可以执行的最坏情况的位置和操纵。
接下来,考虑更复杂的情况,即被遮挡行人。考虑停着的汽车后面的被遮挡区域。被遮挡区域和我们的汽车c的前面/侧面的最近点可以例如通过它们的几何属性(三角形、矩形)来找到。形式上,我们可以把被遮挡区域看作是少数简单形状的凸区域的结合,并分别处理它们中的每一个。此外,可以看到行人可以从被遮挡区域跑到汽车(在vlimit约束下)的前面,当且仅当他可以使用可能的最短路径来这样做。利用行人可以行驶的最大距离是vlimit·t'的事实,我们可以简单地检查正面碰撞的可能性。至于侧面碰撞,我们注意到,如果路径短于vlimit·t',当且仅当在碰撞方向上我们的横向速度大于μ时,我们有责任。公开了一种关于被遮挡行人的谨慎性验证的算法,其在此以自由伪码描述。关键部分,即检查与被车辆遮挡的行人发生可归责的事故的可能性的存在的部分,是以上述简单方式完成的。
关于验证模拟器的问题
如前所述,多作用者安全可能难以统计地验证,因为它应该以“在线”方式进行。有人可能会主张,通过建立驾驶环境模拟器,我们可以在“实验室”验证驾驶策略。然而,验证模拟器忠实地表示现实和验证策略本身一样困难。要了解为什么这是真的,假设模拟器在以下意义上已经过验证:在模拟器中应用驾驶策略π会导致发生事故的概率为
基于车道的坐标系统
rss定义中可以做的一个简化假设是道路由相邻的、恒定宽度的直车道组成。横轴和纵轴之间的区别、以及纵向位置的排序可能在rss中起着重要作用。此外,这些方向的定义显然是基于车道形状。从平面上的(全局)位置到基于车道的坐标系统的变换将问题简化为原始的“恒定宽度的直车道”情况。
假设车道的中心是平面上的平滑有向曲线r,其中其所有片段(表示为r(1),...,r(k))或者是线性的、或者是弧形的(arc)。请注意,曲线的平滑度意味着没有一对连续的片段可以是线性的。形式上,曲线将“纵向”参数y0[ymin,ymax]
r={r(y)+αw(y)r┴(y)|y0[ymin,ymax],α0[±1/2]}
非形式地,我们的目标是构造r的变换φ,使得对于车道上的两辆汽车,它们的“逻辑排序”将被保留:如果在曲线上cr在cf的“后面”,则φ(cr)y<φ(cf)y。如果在曲线上cl在cr的“左侧”,则φ(cl)x<φ(cr)x。在这里,和rss一样,我们将把y轴与“纵向”轴相关联,x轴与“横向”相关联。
为了定义φ,我们依赖于这样的假设:对于所有i,如果r(i)是半径为ρ的弧形,则整个r(i)的车道宽度≤ρ/2。请注意,这一假设适用于任何实际道路。这个假设简单地暗含了,对于所有(x',y')0r,存在唯一的一对y'0[ymin,ymax],α'0[±1/2],使得满足(x',y')=r(y')+α'w(y')r┴(y')。我们现在可以定义φ:r→|2为φ(x',y')=(y',α'),其中(y',α')是满足(x',y')=r(y')+α'w(y')r┴(y')的唯一值。
这个定义抓住了车道的坐标系统中“横向操纵”的概念。例如,考虑一条加宽的车道,汽车恰好在该车道的边界中的一个边界上行驶(见图23)。车道2301的加宽意味着汽车2303正在远离车道的中心移动,因此具有相对于车道横向速度。然而,这并不意味着它执行横向操纵。φ(x',y')x=α'的定义,即以w(y')为单位到车道中心的横向距离,意味着车道边界具有±1/2的固定横向位置。因此,坚持在车道边界中的一个边界上的汽车不被视为执行任何横向运动。最后,可以看出φ是同态(homomorphism)。当讨论φ(r)=[ymin,ymax]×[±1/2]时,使用基于车道的坐标系统这一术语。因此,我们得到了从一般的车道几何形状到直的、纵向/横向坐标系统的简化。
将rss扩展到一般道路结构
本部分描述了适用于所有道路结构的rss的完整定义。本部分涉及rss的定义,而不是如何有效地确保策略遵守rss。接下来引入路线优先级(routepriority)的概念,以捕捉不止单车道几何形状存在的任何情况,例如交叉口。
第二个一般化涉及双向道路,其中可能有两辆汽车朝相反的方向驾驶。在这种情况下,已经建立的rss定义仍然有效,只是对到迎面而来的交通的“安全距离”进行了微小的一般化。受控交叉口(使用交通灯控制交通流量)可以完全由路线优先级和双向道路的概念来处理。没有明确路线定义的非结构化道路(例如停车场)也可以使用rss进行处理。rss在这种情况下仍然有效,在这种情况下,唯一需要的修改是采用定义虚拟路线并将每辆汽车分配到(可能是几条)路线的方式。
路线优先级
现在引入路线优先级的概念来处理在一个场景中有多个不同的道路几何形状在特定区域重叠的场景。如图24a-d所示,示例包括环形道、交叉口和并入高速公路。已经描述了一种将一般车道几何形状变换成对于纵轴和横轴具有一致的含义的、基于车道的几何形状的方法。现在解决存在不同道路几何形状的多条路线的场景。可见,当两辆车接近重叠区域时,两者都会执行到另一辆车的前方廊道的切入。当两条路线具有相同的几何形状时(如两条相邻高速公路车道的情况),这种现象不会发生。大致来说,路线优先级原则规定,如果路线r1、r2重叠,并且r1优先于r2,则来自r1的车辆进入来自r2的车辆的前方廊道不被视为执行切入。
要形式地解释这个概念,回想一下,事故的归责取决于从车道坐标系统中导出的几何特性并且取决于也依赖于它的最坏情况假设。令r1,...,rk为定义道路结构的路线。作为一个简单的示例,考虑并道场景,如图24a所示。假设两辆汽车,2401(c1)和2402(c2)分别行驶在路线r1、r2上,并且r1是优先路线。例如,假设r1是高速公路车道,并且r2是并入车道。为每条路线定义了基于路线的坐标系统后,第一个观察是,我们可以在任何路线的坐标系统中考虑任何操纵。例如,如果我们使用r2的坐标系统,在r1上直行看起来像是并入r2的左侧。rss的定义的一种方法可以是,当且仅当
定义22(具有路线优先级的事故责任)假设r1、r2是重叠的两条具有不同几何形状的路线。我们使用r1>[b,e]r2来表示r1在r1坐标系统的纵向区间[b,e](图25)中优先于r2。假设在路线r1、r2上行驶的汽车c1、c2之间发生事故。对于i0{1,2},如果我们考虑ri的坐标系统,令
·若r1>[b,e]r2,并且在关于r1的归责时间上,其中一辆汽车在r1-系统纵轴的[b,e]区间内,则归责根据b1。
·否则,归责根据b1∪b2。
为了说明该定义,请再次考虑并入高速公路的示例。图25中表示为“b”和“e”的线表示r1>[b,e]r2的b、e的值。因此,我们允许汽车在高速公路上自然行驶,同时暗示并入汽车关于那些汽车必须是安全的。特别地,观察到在汽车2401c1在优先车道的中心行驶、没有横向速度的情况下,汽车2401c1不会为与在非优先车道上行驶的汽车2402c2的事故负责,除非2402c2已经在安全距离处切入了2401c1的廊道。请注意,最终结果与常规rss非常相似——这与汽车在直路上试图执行车道改变的情况完全相同。请注意,可能存在另一作用者使用的路线是未知的的情况。例如,在图26中,汽车2601可能无法确定汽车2602将走路径“a”还是路径“b”。在这种情况下,可以通过迭代地检查所有可能性来获得rss。
双向交通
为了处理双向交通,对归责定义的修改是通过锐化(sharpening)依赖于后方/前方关系的部分来实现的,因为在这种情况下,这些部分具有略有不同的含义。考虑两辆汽车c1、c2在某条直的双车道道路上行驶,纵向方向相反,即v1,long·v2,long<0。在合理的城市场景中,相对于车道的驾驶方向可能是负的,诸如汽车偏离到对面车道(oppositelane)以超过停放的卡车,或者汽车正在倒车进入停车点。因此,需要扩展我们为负的纵向速度被假设为不现实的情况所引入的安全纵向距离的定义。回想一下,如果cf的最大制动允许cr有足够的响应时间在碰撞cf之前制动,那么cr和cf之间的距离是安全的。在我们的情况中,我们再次以稍微不同的方式考虑对面汽车的“最坏情况”:当然,我们并不假设“最坏情况”是它朝向我们加速,而它确实会制动以避免碰撞——但只是使用一些合理的制动力。为了捕捉汽车之间的责任的差异,当他们中的一辆明显以相反的方向行驶时,我们从定义“正确的”行驶方向开始。
在平行车道的rss定义中,相关车道被定义为其中心最靠近切入位置的车道。我们现在可以简化到只考虑这条车道(或者,在对称的情况下,分开处理两条车道,如定义22所示)。在下面的定义中,术语“航向(heading)”表示横向速度除以纵向速度的反正切(弧度)。
定义23((μ1,μ2,μ3)-正确驾驶方向获胜)假设c1、c2以相反的方向行驶,即v1,long·v2,long<0。令xi、hi为他们相对于车道的横向位置和航向。如果所有以下条件成立,我们称c1为(μ1,μ2,μ3)-正确驾驶方向获胜:
·|h1|<μ1,
·|h2-π|<μ2,
·|x1|<μ3。
该事件的指示符由wcdd(i)表示。
换句话说,如果c1靠近车道中心在正确的方向上行驶,而c2采取相反的方向,则c1获胜。最多有一辆车能获胜,或者也可能没有一辆车能获胜。直觉上,假设在讨论的情况发生了碰撞。把更多的责任归给正确驾驶方向失败的汽车c1是合理的。这是通过针对汽车正确驾驶方向获胜的情况重新定义amax,brake来实现的。
定义24(合理制动力(reasonablebrakingpower))令αmax,brake,wcdd>0为小于amax,brake的常数。假设c1、c2以相反的方向行驶。若c1为(μ1,μ2,μ3)-正确驾驶方向获胜,则每辆汽车ci的合理制动力(表示为rbpi)为amax,brake,wcdd,否则为amax,brake。
对于通过正确驾驶方向获胜/未获胜的情况,amax,brake,wcdd,amax,brake的精确值是应该被定义的常数,并且可以取决于每辆汽车所驾驶的道路和车道类型。例如,在一条狭窄的城市街道上,正确驾驶方向获胜可能并不意味着小得多的制动值:在繁忙的交通中,我们确实期望汽车以相似的力制动,无论是否有人明显偏离到它的车道。然而,考虑允许高速的农村双向道路的示例。当偏离到对面车道时,不能期望在正确方向上行驶的汽车应用非常强的制动力来避免撞到主车辆——主车辆将比它们有更多的责任。当两辆车在同一车道上,其中一辆正在倒车进入停车点时,可以对这种情况定义不同的常数。
接下来定义以相反的方向行驶的汽车之间的安全距离,并立即导出其精确值。
定义25(安全纵向距离-双向交通)以相反的方向行驶并且都处于彼此的前方廊道的一辆汽车c1和另一辆汽车c2,若对于由c1、c2执行到响应时间ρ的任何加速命令a,|a|<amax,accel,如果c1和c2从时间ρ应用它们的合理制动力直到完全停止,然后它们不会碰撞,则c1、c2之间的纵向距离关于响应时间ρ是安全的。
引理10令c1、c2如定义25所示。令rbpi、amax,accel为合理制动(对于每个i)和加速度命令,并且令ρ为汽车的响应时间。令v1、v2为汽车的纵向速度,并且令l1、l2为它们的长度。定义vi,ρ,max=|vi|+ρ·amax,accel。令l=(lr+lf)/2。则,最小安全纵向距离为:
总和(sum)中的项是每辆车在执行定义25中的操纵时直到达到完全停止之前行驶的最大距离。因此,为了使完全停止处于大于l的距离,初始距离必须大于这个总和与附加项l。
将具有如定义25中定义的非安全纵向距离的rss的相同归责时间定义用于定义双向交通场景的归责/事故责任。
定义26(双向交通中的归责)以相反的方向行驶的汽车c1、c2之间发生事故的双向交通中的归责,是归责时间处的状态的函数,并定义如下:
·如果归责时间也是切入时间,则归责被定义为和常规rss定义中的一样。
·否则,对于每一个i,如果在归责时间之后发生的某个时刻t,ci没有以至少rbpi的力来制动,则归责给ci。
例如,假设在归责时间之前发生了安全切入。例如,c1偏离到了对面车道,以安全距离执行了到c2的廊道的切入。请注意,c2正确驾驶方向获胜,因此这个距离可能非常大——我们不期望c2执行强的制动力,而只是合理制动力。那么,两辆汽车都有责任不彼此相撞。然而,如果切入不在安全距离内,则我们使用常规定义,注意如果c2在其车道中心行驶而没有横向运动,则c2不会被归责。将完全归责给c1。这允许汽车在其车道中心自然行驶,而不用担心不安全地偏离到其车道的交通。另一方面,允许安全偏离到对面车道,这是密集城市交通中需要的常见操纵。考虑到汽车启动倒车停车操纵的示例,它应该在确保与其后面汽车的距离是安全的的同时开始倒车。
交通灯
在包括有交通灯的十字路口的场景中,人们可能会认为交通灯场景的简单规则是“如果一辆汽车的路线有绿灯,而另一辆汽车的路线有红灯,那么归责给路线有红灯的那一辆”。然而,这不是正确的规则,尤其是在所有情况下。考虑例如图27中描绘的场景。即使汽车2701在具有绿灯的路线上,我们也不期望它忽略已经在十字路口的汽车2703。正确的规则是具有绿灯的路线优先于具有红灯的路线。因此,我们获得了从交通灯到我们之前已经描述的路线优先级概念的清晰简化。
非结构化道路
转到无法定义清晰路线几何形状的道路,首先考虑根本没有车道结构的场景(例如停车场)。确保不会发生事故的一个方法是要求每辆汽车都直线行驶,而如果发生航向改变,必须在我周围没有附近汽车时进行。这背后的基本原理是,一辆汽车可以预测其他汽车将做什么,并相应地行动。如果其他汽车偏离了这一预测(通过改变航向),这是在足够长的距离内完成的,因此可能有足够的时间来修正预测。当有车道结构时,它可以更智能地预测其他汽车将做什么。如果根本没有车道结构,汽车将根据其当前航向继续行驶。从技术上来说,这相当于根据每辆汽车的航向将每辆汽车分配到一条虚拟的直的路线上。接下来,考虑一个大型非结构化环形道的场景(例如,巴黎凯旋门周围)。这里,合理的预测是假设汽车将根据环形道的几何形状继续行驶,同时保持其偏移。从技术上来说,这相当于根据每辆汽车与环形道中心的当前偏移,将每辆汽车分配到一条虚拟的弧形路线。
上述驾驶策略系统(例如,rl系统)可以与一个或多个所述的事故责任规则一起实施,以提供导航系统,该导航系统在决定要实施的特定导航指令时考虑潜在事故责任。这些规则可以在规划阶段期间应用;例如,在一组编程的指令内或在经训练的模型内应用,使得所建议的导航动作由已经符合规则的系统产生。例如,驾驶策略模块可以考虑例如rss所基于的一个或多个导航规则,或用rss所基于的一个或多个导航规则来训练。附加地或可替代地,rss安全约束可以被应用为过滤层,通过该过滤层,针对相关事故责任规则对由规划阶段提议的所有建议的导航动作进行测试,以确保所建议的导航动作是相符合的。如果特定动作符合rss安全约束,则可以实施该动作。否则,如果所建议的导航动作不符合rss安全约束(例如,如果基于一个或多个上述规则,所建议的动作可能导致主车辆的事故责任),则不采取该动作。
实际上,特定的实施方式可以包括用于主车辆的导航系统。主车辆可以配备有图像捕捉设备(例如,一个或多个相机,诸如上述那些中的任何一个),其在操作期间捕捉表示主车辆环境的图像。使用图像信息,驾驶策略可以接收多个输入并输出用于实现主车辆的导航目标的规划导航动作。驾驶策略可以包括一组编程的指令、经训练的网络等,其可以接收各种输入(例如,来自一个或多个相机的、示出了主车辆的周围环境的图像,主车辆的周围环境包括目标车辆、道路、对象、行人等;来自激光雷达或雷达系统的输出;来自速度传感器、悬架传感器等的输出;表示主车辆的一个或多个目标的信息--例如用于将乘客运送到特定位置的导航规划等)。基于该输入,处理器可以例如通过分析相机图像、激光雷达输出、雷达输出等,来识别主车辆环境中的目标车辆。在一些实施例中,处理器可以通过分析一个或多个输入,诸如一个或多个相机图像、激光雷达输出和/或雷达输出,来识别主车辆环境中的目标车辆。此外,在一些实施例中,处理器可以基于传感器输入的多数同意或组合(例如,通过分析一个或多个相机图像、激光雷达输出和/或雷达输出,并且基于输入的多数同意或组合来接收识别目标车辆的检测结果),来识别主车辆环境中的目标车辆。
基于驾驶策略模块可用的信息,可以以用于实现主车辆的导航目标的一个或多个规划导航动作的形式来提供输出。在一些实施例中,rss安全约束可以被应用为规划导航动作的过滤器。也就是说,规划导航动作一旦产生,就可以针对至少一个事故责任规则(例如,上面讨论的事故责任规则中的任何一个)对其进行测试,以确定主车辆相对于所识别的目标车辆的潜在事故责任。并且,如所指出的,如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取了规划导航动作,可能存在主车辆的潜在事故责任,则处理器可以使得主车辆不实施规划导航动作。另一方面,如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取了规划导航动作,不会产生主车辆的事故责任,则处理器可以使得主车辆实施规划导航动作。
在一些实施例中,系统可以针对至少一个事故责任规则来测试多个潜在导航动作。基于测试结果,系统可以将潜在导航动作过滤为多个潜在导航动作的子集。例如,在一些实施例中,子集可以仅包括以下的潜在导航动作:针对这些潜在导航动作,针对至少一个事故责任规则的测试指示,如果采取了潜在导航动作,则不会产生主车辆的事故责任。然后,系统可以对没有事故责任的潜在导航动作进行评分和/或优先级排序,并且基于例如最佳评分或最高优先级来选择导航动作之一来实施。评分和/或优先级可以基于例如一个或多个因素,诸如被视为最安全、最有效、乘客最舒适的潜在导航动作等。
在一些情况下,是否实施特定的规划导航动作的确定还可以取决于默认紧急程序在规划动作之后的下一状态下是否可用。如果dep可用,rss过滤器可以批准规划动作。另一方面,如果dep不可用,下一状态可以被视为不安全的状态,并且规划导航动作可以被拒绝。在一些实施例中,规划导航动作可以包括至少一个默认紧急程序。
所述系统的一个好处是,为了确保车辆的安全动作,只需要考虑主车辆相对于特定目标车辆的动作。因此,在存在一个以上目标车辆的情况下,可以关于主车辆附近的影响区中的目标车辆(例如,在25米、50米、100米、200米等内),针对事故责任规则来顺序地测试主车辆的规划动作。实际上,至少一个处理器可以进一步被编程为:基于对表示主车辆环境的至少一个图像的分析(或者基于激光雷达或雷达信息等)来识别主车辆环境中的多个其他目标车辆,并重复针对至少一个事故责任规则对规划导航动作的测试,以确定主车辆相对于多个其他目标车辆中的每一个的潜在事故责任。如果针对至少一个事故责任规则对规划导航动作的重复测试指示:如果采取了规划导航动作,可能存在主车辆的潜在事故责任,则处理器可以使得主车辆不实施规划导航动作。如果针对至少一个事故责任规则对规划导航动作的重复测试指示:如果采取了规划导航动作,不会产生主车辆的事故责任,则处理器可以使得主车辆实施规划导航动作。
如上所述,上述任何规则都可以用作rss安全测试的基础。在一些实施例中,至少一个事故责任规则包括跟随规则(followingrule),该规则定义了所识别的目标车辆后方的距离,主车辆不能在该距离内没有事故责任的可能性地行进。在其他情况下,至少一个事故责任规则包括前导规则(leadingrule),该规则定义了所识别的目标车辆前方的距离,主车辆不能在该距离内没有事故责任的可能性地行进。
虽然上述系统可以将rss安全测试应用于单个规划导航动作,以测试与主车辆不应该采取任何可能要对导致的事故负责的动作的规则的符合性,但是该测试可以应用于多于一个规划导航动作。例如,在一些实施例中,基于至少一个驾驶策略的应用,所述至少一个处理器可以确定用于实现主车辆的导航目标的两个或更多个规划导航动作。在这些情况下,处理器可以针对至少一个事故责任规则来测试两个或更多个规划导航动作中的每一个,以确定潜在事故责任。并且,对于两个或更多个规划导航动作中的每一个,如果测试指示:如果采取了两个或更多个规划导航动作中的特定一个,可能存在主车辆的潜在事故责任,则处理器可以使得主车辆不实施规划导航动作中的该特定一个。另一方面,对于两个或更多个规划导航动作中的每一个,如果测试指示:如果采取两个或更多个规划导航动作中的特定一个,不会产生主车辆的事故责任,则处理器可以将两个或更多个规划导航动作中的该特定一个识别为供实施的可行候选。接下来,处理器可以基于至少一个成本函数从供实施的可行候选当中选择要采取的导航动作,并使得主车辆实施所选择的导航动作。
因为rss的实现涉及确定主车辆和一个或多个目标车辆之间的事故的相对潜在责任、以及测试规划导航动作的安全符合性,所以系统可以跟踪遇到的车辆的事故责任潜在性。例如,不仅系统能够避免采取导致的事故将造成主车辆的责任的动作,而且主车辆系统还能够跟踪一个或多个目标车辆,并且识别和跟踪那些目标车辆已经违反了哪些事故责任规则。在一些实施例中,用于主车辆的事故责任跟踪系统可以包括至少一个处理设备,该处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像,并且分析至少一个图像以识别主车辆环境中的目标车辆。基于对至少一个图像的分析,处理器可以包括编程以确定所识别的目标车辆的导航状态的一个或多个特性。导航状态可以包括目标车辆的各种操作特性,诸如车辆速度、到车道中心的接近度、横向速度、行驶方向、距主车辆的距离、航向或者可以用于基于上述规则中的任何一个确定潜在事故责任的任何其他参数。处理器可以将所确定的所识别的目标车辆的导航状态的一个或多个特性与至少一个事故责任规则(例如,上述规则中的任何一个,诸如横向速度获胜、方向优先级、车道中心接近度获胜、跟随或前导距离和切入等)进行比较。基于状态与一个或多个规则的比较,处理器可以存储指示所识别的目标车辆方的潜在事故责任的至少一个值。并且在事故的情况下,处理器可以提供存储的至少一个值的输出(例如,经由有线或无线的任何合适的数据接口)。例如,可以在主车辆和至少一个目标车辆之间发生事故之后提供这样的输出,并且该输出可以用于或者可以以其他方式提供事故责任的指示。
可以在任何合适的时间和任何合适的条件下存储指示潜在事故责任的至少一个值。在一些实施例中,如果确定主车辆不能避免与所识别的目标车辆碰撞,则至少一个处理设备可以为所识别的目标车辆分配和存储碰撞责任值。
事故责任跟踪能力不限于单个目标车辆,而是可以用于跟踪多个遇到的目标车辆的潜在事故责任。例如,至少一个处理设备可以被编程为检测主车辆的环境中的多个目标车辆,确定多个目标车辆中的每一个的导航状态特性,并且基于目标车辆中的每一个的相应导航状态特性与至少一个事故责任规则的比较,确定和存储指示多个目标车辆中的相应目标车辆方的潜在事故责任的值。如上所述,用作责任跟踪的基础的事故责任规则可以包括上述规则中的任何一个或任何其他合适的规则。例如,至少一个事故责任规则可以包括横向速度规则、横向位置规则、驾驶方向优先级规则、基于交通灯的规则、基于交通标志的规则、路线优先级规则等。事故责任跟踪功能还可以与基于rss考虑的安全导航相结合(例如,主车辆的任何动作是否会造成对导致的事故的潜在责任)。
除了基于根据rss的事故责任考虑进行导航之外,还可以从车辆导航状态以及对特定的未来导航状态是否被认为是安全的确定(例如,如上文详细描述的,是否存在dep使得事故可以被避免或者任何导致的事故不会被认为是主车辆的过错)的方面来考虑导航。可以控制主车辆从安全状态导航到安全状态。例如,在任何特定状态下,驾驶策略可用于生成一个或多个规划导航动作,并且可通过确定对应于每个规划动作的所预测的未来状态是否将提供dep来测试这些动作。如果是这样,提供dep的一个或多个规划导航动作可以被视为安全的,并可以有资格实施。
在一些实施例中,用于主车辆的导航系统可以包括至少一个处理设备,该处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定用于实现主车辆的导航目标的规划导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;针对至少一个事故责任规则测试规划导航动作,以确定主车辆相对于所识别的目标车辆的潜在事故责任;如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取规划导航动作,可能存在主车辆的潜在事故责任,则使得主车辆不实施规划导航动作;并且如果针对至少一个事故责任规则对规划导航动作的测试指示:如果采取规划导航动作,不会产生主车辆的事故责任,则使得主车辆实施规划导航动作。
在一些实施例中,用于主车辆的导航系统可以包括至少一个处理设备,该处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像;基于至少一个驾驶策略,确定主车辆的多个潜在导航动作;分析至少一个图像以识别主车辆的环境中的目标车辆;针对至少一个事故责任规则测试多个潜在导航动作,以确定主车辆相对于所识别的目标车辆的潜在事故责任;选择潜在导航动作中的、对其的测试指示如果采取所选择的潜在导航动作不会产生主车辆的事故责任的一个潜在导航动作;并使得主车辆实施所选择的潜在导航动作。在一些情况下,所选择的潜在导航动作可以从多个潜在导航动作的子集中选择,对多个潜在导航动作的子集的测试指示:如果采取多个潜在导航动作的子集中的任何一个,不会产生主车辆的事故责任。此外,在一些情况下,可以根据评分参数来选择所选择的潜在导航动作。
在一些实施例中,用于导航主车辆的系统可以包括至少一个处理设备,该处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像,并且基于至少一个驾驶策略确定用于实现主车辆导航目标的规划导航动作。处理器还可以分析至少一个图像以识别主车辆的环境中的目标车辆;确定如果采取了规划导航动作将会产生的主车辆和目标车辆之间的下一状态距离;确定主车辆的当前最大制动能力和主车辆的当前速度;基于目标车辆的至少一个所识别的特性,确定目标车辆的当前速度并假设目标车辆的最大制动能力;并且,如果给定主车辆的最大制动能力和主车辆的当前速度,主车辆可以在停止距离内停止,则实施规划导航动作,该停止距离小于所确定的下一状态距离与基于目标车辆的当前速度和所假设的目标车辆的最大制动能力而确定的目标车辆行驶距离之和。停止距离还可以包括主车辆在没有制动的反应时间期间行驶的距离。
确定目标车辆的最大制动能力所基于的目标车辆的所识别的特性可以包括任何合适的特性。在一些实施例中,特性可以包括车辆类型(例如,摩托车、汽车、公共汽车、卡车,其中每一个都可以与不同的制动曲线(brakingprofile)相关联)、车辆尺寸、预测的或已知的车辆重量、车辆型号(vehiclemodel)(例如,可以用于查找已知的制动能力)等。
在一些情况下,可以相对于一个以上的目标车辆做出安全状态确定。例如,在一些情况下,安全状态确定(基于距离和制动能力)可以基于领先主车辆的两个或更多个所识别的目标车辆。这种确定可能是有用的,尤其是在关于最前面的目标车辆的前方的信息不可用的情况下。在这种情况下,为了确定安全状态、安全距离和/或可用的dep,可以假设最前面的可检测车辆将经历与不可移动或几乎不可移动的障碍物的即将发生的碰撞,使得跟随的目标车辆可以比其自身的制动曲线所允许的更快地达到停止(例如,第二目标车辆可能与最前面的第一车辆碰撞,因此比预期的最大制动条件更快地达到停止)。在这种情况下,基于所识别的最前面目标车辆相对于主车辆的位置来确定安全状态、安全跟随距离、dep可能是重要的。
在一些实施例中,这种安全状态到安全状态导航系统可以包括至少一个处理设备,该处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像。这里,与其他实施例一样,由图像捕捉设备(例如,相机)捕捉的图像信息可以用从一个或多个其他传感器(诸如,激光雷达或雷达系统)获得的信息来补充。在一些实施例中,用于导航的图像信息甚至可以源自激光雷达或雷达系统,而不是源自光学相机。至少一个处理器可以基于至少一个驾驶策略来确定用于实现主车辆导航目标的规划导航动作。处理器可以分析至少一个图像(例如,从相机、雷达、激光雷达或可以从中获得主车辆的环境的图像的任何其他设备中的任何一个获得的图像,无论是基于光学的、基于距离图的等等)以识别主车辆前方的第一目标车辆和第一目标车辆前方的第二目标车辆。处理器然后可以确定如果采取了规划导航动作将会产生的主车辆和第二目标车辆之间的下一状态距离。接下来,处理器可以确定主车辆的当前最大制动能力和主车辆的当前速度。如果给定主车辆的最大制动能力和主车辆的当前速度,主车辆可以在小于所确定的主车辆和第二目标车辆之间的下一状态距离的停止距离内停止,则处理器可以实施规划导航动作。
也就是说,如果主车辆处理器确定在前方可见目标车辆和主车辆之间的下一状态距离中有足够的距离来停止而不发生碰撞或不发生责任将归给主车辆的碰撞,并且假设前方可见目标车辆将在任何时刻突然完全停止,则主车辆的处理器可以采取规划导航动作。另一方面,如果没有足够的空间使主车辆停止而不发生碰撞,则可以不采取规划导航动作。
另外,虽然在一些实施例中下一状态距离可以用作基准,但是在其他情况下,可以使用不同的距离值来确定是否采取规划导航动作。在一些情况下,如在上述情况下,主车辆可能需要停止以避免碰撞的实际距离可能小于所预测的下一状态距离。例如,在前方可见目标车辆被一个或多个其他车辆(例如,上述示例中的第一目标车辆)跟随的情况下,实际预测的所需停止距离将是所预测的下一状态距离减去跟随前方可见目标车辆的(一个或多个)目标车辆的长度。如果前方可见目标车辆立即停止,可以假设正在跟随的目标车辆将与前方可见目标车辆碰撞,因此,它们也需要被主车辆避开以避免碰撞。因此,主车辆处理器可以评估下一状态距离减去主车辆和前方可见/检测到的目标车辆之间的任何中间目标车辆的总长度,以确定是否有足够的空间在最大制动条件下使主车辆停下来而没有碰撞。
在其他实施例中,用于评估主车辆和一个或多个前方目标车辆之间碰撞的基准距离可以大于所预测的下一状态距离。例如,在一些情况下,前方可见/检测到的目标车辆可能会快速但不是立即停止,使得前方可见/检测到的目标车辆在假设的碰撞之后行驶较短的距离。例如,如果该车辆撞到停放的汽车,碰撞的车辆在完全停止之前仍可能行驶一段距离。在假设的碰撞后行驶的距离可能小于相关目标车辆的假设的或确定的最小停止距离。因此,在一些情况下,主车辆的处理器可以在其对是否采取规划导航动作的评估中延长下一状态距离。例如,在该确定中,下一状态距离可以增加5%、10%、20%等,或者可以用预定的固定距离(10米、20米、50米等)来补充,以考虑在假设的即将发生的碰撞后前方/可见目标车辆可能行驶的合理距离。
除了通过假设的距离值在该评估中延长下一状态距离之外,可以通过考虑前方可见/检测到的目标车辆在碰撞后行驶的距离和跟随前方可见/检测到的目标车辆的任何目标车辆的长度(其可以假设在前方可见/检测到的车辆突然停止后与前方可见/检测到的车辆堆积在一起)两者,来修改下一状态距离。
除了基于主车辆和前方可见/检测到的目标车辆之间的下一状态距离(通过考虑前方可见/检测到的目标车辆的碰撞后运动和/或跟随前方可见/检测到的目标车辆的车辆长度对其修改)确定是否采取规划导航动作之外,主车辆可以在其确定中继续考虑一个或多个前方车辆的制动能力。例如,主车辆处理器可以继续确定如果采取了规划导航动作将会产生的主车辆和第一目标车辆(例如,跟随前方可见/检测到的目标车辆的目标车辆)之间的下一状态距离;基于第一目标车辆的至少一个所识别的特性,确定第一目标车辆的当前速度并假设第一目标车辆的最大制动能力;并且如果给定主车辆的最大制动能力和主车辆的当前速度,主车辆不能在停止距离内停止,则不实施规划导航动作,该停止距离小于所确定的主车辆和第一目标车辆之间的下一状态距离与基于第一目标车辆的当前速度和所假设的第一目标车辆的最大制动能力而确定的第一目标车辆行驶距离之和。这里,如在上述示例中,第一目标车辆的所识别的特性可以包括车辆类型、车辆尺寸、车辆型号等。
在一些情况下(例如,通过其他车辆的动作),主车辆可以确定碰撞即将发生并且不可避免。在这种情况下,主车辆的处理器可以被配置为选择导致的碰撞将不会产生主车辆的责任的导航动作(如果可用)。附加地或可替代地,主车辆的处理器可以被配置为选择将比当前轨迹或相对于一个或多个其他导航选项而言对主车辆提供更少的潜在损害或对目标对象提供更少的潜在损害的导航动作。此外,在一些情况下,主车辆处理器可以基于预期碰撞的一个或多个对象的类型的考虑来选择导航动作。例如,当面对由于第一导航动作而与停放的汽车发生碰撞或由于第二导航动作而与不可移动的对象发生碰撞时,可以选择对主车辆提供更低潜在损害的动作(例如,导致与停放的汽车发生碰撞的动作)。当面对由于第一导航动作而与以与主车辆相似的方向移动的车辆发生碰撞或由于第二导航动作而与停放的车辆发生碰撞时,可以选择对主车辆提供更低潜在损害的动作(例如,导致与移动的汽车发生碰撞的动作)。当面临由于第一导航动作而与行人发生碰撞或者由于第二导航动作而与任何其他对象发生碰撞时,可以选择提供对于行人碰撞的任何替代的动作。
实际上,用于导航主车辆的系统可以包括至少一个处理设备,该处理设备被编程为:从图像捕捉设备接收表示主车辆的环境的至少一个图像(例如,可见图像、激光雷达图像、雷达图像等);从至少一个传感器接收主车辆的当前导航状态的指示符;并且基于对至少一个图像的分析以及基于主车辆的当前导航状态的指示符,确定主车辆和一个或多个对象之间的碰撞是不可避免的。处理器可以评估可用的替代。例如,处理器可以基于至少一个驾驶策略来确定涉及与第一对象的预期碰撞的主车辆的第一规划导航动作以及涉及与第二对象的预期碰撞的主车辆的第二规划导航动作。可以针对至少一个事故责任规则来测试第一和第二规划导航动作,以确定潜在事故责任。如果针对至少一个事故责任规则对第一规划导航动作的测试指示:如果采取第一规划导航动作,可能存在主车辆的潜在事故责任,则处理器可以使得主车辆不实施第一规划导航动作。如果针对至少一个事故责任规则对第二规划导航动作的测试指示:如果采取第二规划导航动作,不会产生主车辆的事故责任,则处理器可以使得主车辆实施第二规划导航动作。对象可以包括其他车辆或非车辆对象(例如,道路碎片、树木、电线杆、标志、行人等)。
以下附图和讨论提供了在进行导航和实施所公开的系统和方法时可能发生的各种场景的示例。在这些示例中,主车辆可以避免采取一动作,如果采取了该动作,将会产生对于导致的事故归因于主车辆的责任。
图28a和28b示出了以下场景和规则的示例。如图28a所示,车辆2804(例如,目标车辆)周围的区域表示车辆2802(例如,主车辆)的最小安全距离廊道,车辆2802在车道上行驶在车辆2804后面一段距离。根据与所公开的实施例一致的一条规则,为了避免责任归属于车辆2802的事故,车辆2802必须通过留在车辆2802周围的区域来保持最小安全距离。相反,如图28b所示,如果车辆2804制动,那么如果发生事故,则车辆2802将有过错。
图29a和29b示出了切入场景中的示例归责。在这些场景下,车辆2902周围的安全廊道确定切入操纵中的过错。如图29a所示,车辆2902在车辆2902的前方切入,违反了安全距离(由车辆2902周围的区域描绘),并因此有过错。如图29b所示,车辆2902在车辆2902的前方切入,但是在车辆2904的前方保持了安全距离。
图30a和30b示出了切入场景中的示例归责。在这些场景中,车辆3004周围的安全廊道确定车辆3002是否有过错。在图30a中,车辆3002在车辆3006后面行驶,并且改变到目标车辆3004正在行驶的车道。在这种场景下,车辆3002违反了安全距离,并且因此如果发生事故,就有过错。在图30b中,车辆3002切入车辆3004后面并保持安全距离。
图31a-31d示出了漂移场景中的示例归责。在图31a中,该场景以车辆3104的轻微横向操纵、切入车辆3102的宽阔廊道开始。在图31b中,车辆3104继续切入车辆3102的正常廊道,违反了安全距离区域。如果发生事故,应归责给车辆3104。在图31c中,车辆3104保持其初始位置,而车辆3102横向移动,“迫使”违反ae正常安全距离廊道。如果发生事故,应归责给车辆3102。在图31b中,车辆3102和3104朝向彼此横向移动。如果发生事故,责任由两辆车分担。
图32a和32b示出了双向交通场景中的示例归责。在图32a中,车辆3202对车辆3206进行超车,并且车辆3202已经执行了切入操纵,保持着距车辆3204的安全距离。如果发生事故,车辆3204应该因没有以合理的力制动而被归责。在图32b中,车辆3202切入,而没有与车辆3204保持安全的纵向距离。如果发生事故,要归责给车辆3202。
图33a和33b示出了双向交通场景中的示例归责。在图33a中,车辆3302漂移到迎面而来的车辆3204的路径中,保持着安全距离。如果发生事故,车辆3204因没有以合理的力制动而被归责。在图33b中,车辆3202漂移到迎面而来的车辆3204的路径中,违反了安全的纵向距离。如果发生事故,要归责给车辆3204。
图34a和34b示出了路线优先级场景中的示例归责。在图34a中,车辆3202运行到停止标志。由于不尊重交通灯分配给车辆3204的优先权,责任归属于车辆3202。在图34b中,尽管车辆3202没有优先权,但是当车辆3204的灯变绿时,车辆3202已经在十字路口。如果车辆3204撞到3202,将归责给车辆3204。
图35a和35b示出了路线优先级场景中的示例归责。在图35a中,车辆3502倒车进入迎面而来的车辆3504的路径。车辆3502执行保持着安全距离的切入操纵。如果发生事故,车辆3504应该为没有以合理的力制动而被归责。在图35b中,车辆3502在没有保持安全纵向距离的情况下切入。如果发生事故,要归责给车辆3502。
图36a和36b示出了路线优先级场景中的示例归责。在图36a中,车辆3602和车辆3604在相同的方向上行驶,而车辆3602跨过车辆3604的路径左转。车辆3602执行保持着安全距离的切入操纵。如果发生事故,车辆3604应该为没有以合理的力制动而被归责。在图36b中,车辆3602在没有保持安全纵向距离的情况下切入。如果发生事故,要归责给车辆3602。
图37a和37b示出了路线优先级场景中的示例归责。在图37a中,车辆3702想要左转,但是必须给迎面而来的车辆3704让路。车辆3702左转,违反了相对于车辆3704的安全距离。责任在于车辆3702。在图37b中,车辆3702左转,相对于车辆3704保持着安全距离。如果发生事故,车辆3704应该为没有以合理的力制动而被归责。
图38a和38b示出了路线优先级场景中的示例归责。在图38a中,车辆3802和车辆3804直行,并且车辆3802具有停止标志。车辆3802进入十字路口,违反了相对于车辆3804的安全距离。责任在于车辆3802。在图38b中,车辆3802进入十字路口,同时相对于车辆3804保持着安全距离。如果发生事故,车辆3804应该为没有以合理的力制动而被归责。
图39a和39b示出了路线优先级场景中的示例归责。在图39a中,车辆3902想要左转,但是必须给来自其右侧的车辆3904让路。车辆3902进入十字路口,违反了路权和相对于车辆3904的安全距离。责任在于车辆3902。在图39b中,车辆3902进入十字路口,同时保持着路权和相对于车辆3904的安全距离。如果发生事故,车辆3904应该为没有以合理的力制动而被归责。
图40a和40b示出了交通灯场景中的示例责备。在图40a中,车辆4002正在闯红灯。由于不尊重交通灯分配给车辆4004的优先权,责任归属于车辆4002。在图40b中,尽管车辆4002没有优先权,但是当车辆4004的灯变绿时,车辆4002已经在十字路口。如果车辆4004撞到车辆4002,将归责给车辆4004。
图41a和41b示出了交通灯场景中的示例归责。车辆4102正在跨过迎面而来的车辆4104的路径左转。车辆4104具有优先权。在图41中,车辆4102左转,违反了相对于车辆4104的安全距离。责任归属于车辆4102。在图41b中,车辆4102左转,相对于车辆4104保持着安全距离。如果发生事故,车辆4104应该为没有以合理的力制动而被归责。
图42a和42b示出了交通灯场景中的示例归责。在图42a中,车辆4202正在右转,切入正在直行的车辆4204的路径。红灯时右转(right-on-red)被假设为合法的操纵,但是车辆4204具有路权,因为车辆4202违反了相对于车辆4204的安全距离。责任归属于车辆4202。在图42b中,车辆4202右转,相对于车辆4204保持着安全距离。如果发生事故,车辆4204应该为没有以合理的力制动而被归责。
图43a-43c示出了示例弱势道路使用者(vru)场景。车辆执行操纵时与动物或vru发生的事故被视为切入的变型,其中默认归责给汽车,但有一些例外。在图43a中,车辆4302切入动物(或vru)的路径,同时保持着安全距离并确保可以避免事故。在图43b中,车辆4302切入动物(或vru)的路径,违反了安全距离。责任归属于车辆4302。在图43c中,车辆4302注意到动物并停止,给动物足够的时间来停止。如果动物撞到了汽车,那要归责给动物。
图44a-44c示出了示例弱势道路使用者(vru)场景。在图44a中,车辆4402正在设置有信号灯的十字路口左转,并在人行横道上遇到行人。车辆4402有红灯,并且vru有绿灯。车辆4402有过错。在图44b中,车辆4402有绿灯,并且vru有红灯。如果vru进入人行横道,则vru有过错。在图44c中,车辆4402有绿灯,并且vru有红灯。如果vru已经在人行横道上,则车辆4402有过错。
图45a-45c示出了示例弱势道路使用者(vru)场景。在图45a中,车辆4402正在右转并遇到骑车人。骑车人有绿灯。车辆4502有过错。在图45b中,骑车人有红灯。如果骑车人进入十字路口,则骑车人有过错。在图45c中,骑车人有红灯,但已经在十字路口了。车辆4502有过错。
图46a-46d示出了示例弱势道路使用者(vru)场景。车辆不执行操纵时与vru发生的事故默认归责给车辆,但有一些例外。在图46a中,车辆4602必须始终确保保持安全距离,并确保能够避免与vru发生事故。在图46b中,如果车辆4602没有保持安全距离,则要归责给车辆4602。在图46c中,如果车辆4602没有保持足够低的速度以便避免与可能被车辆5604遮挡的vru相撞,或者驾驶超过法定限速,则要归责给车辆4602。在图46d中,在vru可能被车辆4604遮挡的另一场景下,如果车辆4602保持足够低的速度,但vru速度高于合理的阈值,则要归责给vru。
如本文所公开的,rss定义了多作用者场景的框架。带有静态对象、道路偏离、失控或车辆故障的事故都归责给主车辆(host)。rss定义了谨慎操纵,谨慎操纵不允许与其他对象发生事故,除非其他对象危险地操纵到主车辆的路径上(在这种情况下,要归责给它们)。在责任在于目标(target)的肯定碰撞的情况下,主车辆将应用它的制动。只有在操纵是“谨慎的”(感知到不会引起另一事故)的情况下,系统才可以考虑规避转向。
非碰撞事故包括由车辆火灾、坑洼、坠落对象等引发的事故。在这些情况下,可能默认归责给主车辆,但主车辆可以避免的场景除外,诸如可以被分类为“静态对象”场景的坑洼和坠落对象,假设它们在安全距离处可见或存在谨慎的规避操纵。在主车辆是静止的多作用者场景中,不应归责给主车辆。在这种情况下,目标实质上执行了不安全切入。例如,如果骑车人骑进一辆静止的汽车,则不应归责给主车辆。
rss还包括在道路结构不清晰的地方(诸如停车场或没有车道标记的宽阔环形道)分配责任的指南。在这些非结构化道路场景中,通过检查每辆车与其路径的偏离来确定它们是否允许了足够的距离以允许该区域中的其他对象进行调整,从而分配责任。
已经出于说明的目的呈现了前面的描述。其并非详尽无遗,并且不限于所公开的精确形式或实施例。考虑到所公开实施例的说明书和实践,修改和调整对于本领域技术人员而言将是显而易见的。另外,尽管所公开的实施例的各方面被描述为存储在存储器中,但是本领域技术人员将理解,这些方面也可以存储在其他类型的计算机可读介质上,诸如辅助存储设备,例如,硬盘或cdrom,或其他形式的ram或rom、usb介质、dvd、蓝光、4k超高清蓝光或其他光驱介质。
基于书面描述和公开的方法的计算机程序在有经验的开发者的技能范围内。可以使用本领域技术人员已知的任何技术来创建各种程序或程序模块,或者可以结合现有软件来设计各种程序或程序模块。例如,程序部分或程序模块可以在.netframework、.netcompactframework(以及相关语言,如visualbasic、c等)、java、c++、objective-c、html、html/ajax组合、xml或包含java小程序的html中设计或通过它们设计。
此外,虽然本文已经描述了说明性实施例,但是具有等效的元件、修改、省略、组合(例如,跨各种实施例的方面)、调整和/或改变的任何和所有实施例的范围,如本领域技术人员基于本公开的技术将理解的。权利要求中的限制将基于权利要求中采用的语言广泛地解释,并且不限于本说明书中或在申请的审查期间描述的示例。这些示例应被解释为非排他性的。此外,可以以任何方式修改所公开方法的步骤,包括通过重新排序步骤和/或插入或删除步骤。因此,其意图是说明书和示例仅被认为是说明性的,真正的范围和精神由所附权利要求及其等同物的全部范围表示。
- 还没有人留言评论。精彩留言会获得点赞!