一种无监督深度学习网络的机械故障诊断方法与流程
本发明涉及工业生产中的故障诊断技术领域,特别是一种无监督深度学习网络的机械故障诊断方法。
背景技术:
目前,工业设备正向着大型化、高速化、自动化的方向发展。机械设备作为工业设备领域中最为常见的组成部分,被广泛应用于航空、航天、交通运输、智能制造等重要领域。现阶段,轴承等部件仍是机械最主要的动力传递和支撑部件,据统计30%的机械故障的产生是由轴承等部件出现局部损伤或缺陷造成,因此有必要对机械设备及其关键部位进行有效的状态监测与故障诊断。
机械设备如起重机、旋转机械等时刻产生着大量反映其运行状况的实时信息,这些信息包括振动、声音、温度等多方面的物理量。机械设备一旦出现异常,必将带来相应的物理信息的变化。为了从不同的角度描述机械设备的运行状况,需采集更多的机械信息,通过基于数据或信息的分析,对机械设备进行有效的智能监测与诊断。因此,故障诊断的目的就是通过获取的机械信息对设备实现有效的诊断与分析,以降低或减少机械设备故障所带来的损失或危害。
由于机械设备监测与诊断的装备集群规模大且测点多、采样频率高、工作寿命历时长,因此监测与诊断系统获取的是海量的数据,致使机械健康监测与管理领域进入了“大数据”时代。然而,在实际的工业现场中,“机械大数据”现象同样带来了机械设备标签信息获取比较困难的问题。这是因为机械设备的运行时间远远大于故障发生的时间,机械数据的稀疏性是不可避免的,且人工标记信息比较困难。为此,机械数据的标签信息缺乏与数据信息的稀疏性给故障诊断带来了一系列的挑战。因而,在有限的或缺乏训练样本标签信息的情况下,对机械设备进行有效的状态监测与故障识别是故障诊断领域一直以来悬而未决的关键问题。
技术实现要素:
本发明所要解决的技术问题是克服现有技术的不足而提供一种无监督深度学习网络的机械故障诊断方法,旨在实现机械设备的从特征提取到模式识别阶段的全程无监督故障诊断,该方法可为类别标签缺失情况下的机械故障诊断提供一种可解决的有效方案。
本发明为解决上述技术问题采用以下技术方案:
根据本发明提出的一种无监督深度学习网络的机械故障诊断方法,包括以下步骤:
步骤1、预先选定机械设备上的被测部件,采集机械设备上被测部件的振动信号;
步骤2、将采集的振动信号转化为混合域故障特征数据集,并将其分为测试样本特征子集与训练样本特征子集,测试样本特征子集即作为测试样本,训练样本特征子集即作为训练样本;
步骤3、初始化无监督深度学习网络udln模型的参数,将训练样本输入到udln模型中进行预训练,得到udln模型的参数;
预训练具体如下:
udln模型由两阶段学习构成:首先,将训练样本输入到l12范数稀疏滤波l12sf特征提取层,l12范数是融合1范数与2范数的范数表达,利用该l12sf产生特征竞争特效,从而提取到特征值;然后,该提取的特征值被送入到加权欧式距离相似仿射we-ap聚类层,得到训练后的udln模型的参数;
步骤4、再将测试样本输入到训练完成的udln模型,得到故障聚类与识别结果;
步骤5、根据故障聚类的隶属度情况及聚类中心,计算各类故障识别率,实现机械设备的故障诊断。
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,步骤1中的被测部件包括起重机、旋转机械的轴承、齿轮。
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,步骤2中混合域故障特征数据集的特征包括时域、频域和时频域特征。
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,将训练样本输入到udln模型中进行预训练的过程如下:
步骤3.1、初始化udln模型的参数;
步骤3.2、将训练样本特征子集作为两层l12sf的原始输入,逐层提取混合域故障特征数据集的低维无监督特征;其中,l12sf的目标函数如下:
其中,||*||1表示1范数,||*||2表示2范数,对m个训练样本来说
其中,
fli=g(wltxi)
其中,g(*)为激活函数;
将fli=g(wltxi)采用l-bfgs算法来优化l12sf的目标函数直至收敛;
步骤3.3、将步骤3.2提取的特征值输入we-ap的聚类层进行故障聚类学习与故障划分,这里we-ap聚类首先初始化具有n个训练样本的加权相似度矩阵sw
其中,x1k与x2k表示两个不同训练样本的第k个特征,sk表示两个训练样本的方差,n为特征值数目,n=m;
同时,计算第i个训练样本的可信度和可用度,其具体的计算方式为
r(i,k)=s(i,k)-max{a(i,j)+s(i,j)}
st.j=1,2,...,nandj≠i,k
st.j=1,2,...,nandj≠i,k
r(k,k)=b(k)-max{a(k,j)+s(k,j)}
st.j=1,2,...,nandj≠k
其中,b(k)为先验数值,代表每一个训练样本被选为聚类中心点的倾向性;s(i,k)表示第i个训练样本与第k个训练样本的加权相似度矩阵,a(i,j)表示了第i个训练样本选择第j个训练样本作为其聚类中心的可用度,s(i,j)表示第i个训练样本与第j个训练样本的加权相似度矩阵,a(i,k)表示了第i个训练样本选择第k个训练样本为其聚类中心的可用度,a(i,j)表示了第i个训练样本选择第j个训练样本作为其聚类中心的可用度,r(k,k)表示了第k个训练样本选择第k个训练样本作为其聚类中心的可信度,r(i,k)表示了第i个训练样本选择第k个训练样本作为其聚类中心的可信度,r(k,k)表示了第k个训练样本选择第k个训练样本作为其聚类中心的可信度,a(k,j)表示了第k个训练样本选择第j个训练样本作为其聚类中心的可用度,s(k,j)表示第k个训练样本与第j个训练样本的加权相似度矩阵。
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,步骤3.2中,g(*)为采用软绝对值的激活函数:
其中,σ为激活阈值,然后将
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,σ=10-8。
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,步骤5中根据udln模型计算如下公式来决定第k个训练样本作为聚类中心的条件以及隶属度情况
r(k,k)+a(k,k)>0
其中,r(k,k)表示第k个训练样本选择第k个训练样本作为其聚类中心的可信度,a(k,k)表示第k个训练样本选择第k个训练样本作为其聚类中心的可用度;
根据预设的最大迭代次数tmax,更新每个训练样本的可信度和可用度tmax次,更新方式为
r(i,k)=(1-lam)*r(i,k)+lam*r(i-1,k)
a(i,k)=(1-lam)*a(i,k)+lam*a(i-1,k)
其中,lam为阻尼因子,其中,r(i-1,k)表示第(i-1)个训练样本选择第k个训练样本作为其聚类中心的可信度,a(i-1,k)表示第(i-1)个训练样本选择第k个训练样本作为其聚类中心的可用度;
最后,根据故障聚类的隶属度情况及聚类中心,计算各类故障识别率,实现机械设备的故障诊断。
作为本发明所述的一种无监督深度学习网络的机械故障诊断方法进一步优化方案,步骤3的udln的模型参数包括第i个训练样本的权值参数wi及正则化范数调节系数
本发明采用以上技术方案与现有技术相比,具有以下技术效果:
(1)所改进的l12范数稀疏滤波(l12sf)无监督特征提取网络,可层层提取故障数据的无监督特诊信息,新定义的l12范数增强了提取的低维特征的泛化能力;
(2)所改进的加权欧式相似仿射(we-ap)聚类可以更精确地实现故障类别的自适应无监督聚类,克服了传统聚类方法需要预先设定聚类数及聚类中心,同时突出不同样本特征对聚类的贡献程度;
(3)在l12sf以及we-ap聚类基础上,构建了一种全新的无监督深度学习网络-udln,该神经网络可以实现从特征提取到模式识别的全程无监督学习;
(4)发明一种新的基于udln模型的机械故障诊断方法,实现在无类别标签信息下的无监督的智能机械故障诊断,并通过机械设备的振动信号验证了所提发明方法的可行性。此外,本发明简单易行,适用于类别标签缺少的情况下的机械设备在线或现场故障诊断。
附图说明
图1是本发明技术的流程图。
图2是多层l12sf网络的结构示意图。
图3是udln模型结构示意图。
图4是轴承各类故障信号的时域与频域波形包络。
图5是基于udln故障诊断的机械故障识别的混淆矩阵。
具体实施方式
为了使本发明的目的、技术方案和优点更加清楚,下面将结合附图及具体实施例对本发明进行详细描述。
在实际的工业现场诊断中,多层无监督学习可以为训练样本及其类别标签缺失情况下提供可解决的方案之一,为此本发明拟通过所提出的l12范数稀疏滤波(l12sf)与加权欧式距离相似仿射(we-ap)联合构建一种新的无监督深度学习网络(udln)模型,并在此基础上发明了基于udln模型的机械故障诊断方法。
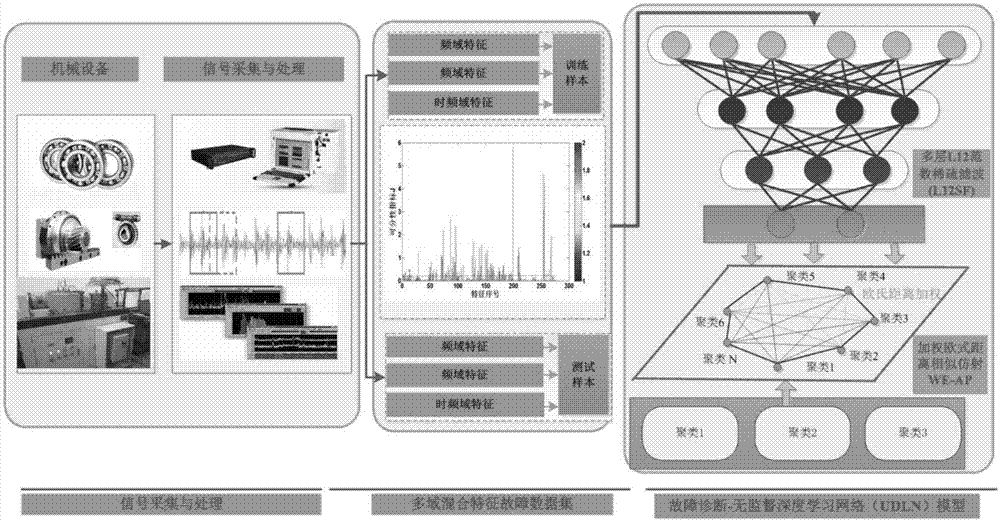
一种无监督深度学习网络的机械故障诊断方法流程如图1所示,步骤可总结如下:
(1).首先,在机械设备(如起重机等)的关键位置布置相应的传感器对机械设备的振动信号进行拾取;
(2).将振动信号转化为多域混合故障特征数据集,并将其分为测试样本特征子集与训练样本特征子集;
目前,最常用的特征包括时域、频域、时频域特征等,这些特征很好地刻画了机械故障数据集的健康状况。通过轴承振动信号样本构建如表1所示混合多域特征集,记作特征数据集h。
表1时域、频谱、时频域统计特征参数
(3)初始化网络参数,将训练样本特征子集输入到udln模型中进行训练学习;
具体方法说明如下:
(3.1)对l12sf方法的说明
稀疏滤波被视为一个无监督的双层神经网络,相比较其他特征学习方法,稀疏过滤不需要试图去对数据分布构建一个模型,它只需要优化一个简单的损失函数2范数标准化特征的稀疏性。给定具有m个训练样本的样本集如下所示
fli=wltxi
其中,fli表示第i个样本(列)的第l个特征值,wlt表示第l特征值的权值矩阵的转置。
稀疏过滤使用2范数归一化数据的稀疏性。这些特征组成一个特征矩阵。我们首先将所有样本中的特征矩阵的每一行用2范数标准化。
其中,
其中,
其中,m表示训练样本数目,||*||1表示1范数,||*||2表示2范数。同时,我们知道l1范数可以使得数据的更加稀疏,2范数可以防止数据的过拟合,提升模型的泛化能力。因此,如果融合1范数与2范数的优点,可以充分调节数据的稀疏特性以及神经网络的泛化性能。所以本发明重新定义一种范数r(w):
其中,
其中,||*||l12表示l12范数,通过优化式中的目标函数,学习特征能够从输入样本中发现更多的非线性信息,具有较好的泛化能力。
fli=g(wltxi)
其中,g(*)表示软绝对值的激活函数。所以l12sf结构示意图如图2所示。
(3.2)对we-ap聚类方法的说明
we-ap聚类的具体计算步骤如下所示
(1):计算加权的相似度矩阵sw,定义最大迭代tmax=1000.
(2):计算每个样本点的可信度r和可用度a,其具体的计算方式为
r(i,k)=s(i,k)-max{a(i,j)+s(i,j)}
st.j=1,2,...,nandj≠i,k
st.j=1,2,...,nandj≠i,k
r(k,k)=b(k)-max{a(k,j)+s(k,j)}
st.j=1,2,...,nandj≠k
其中,b(k)为先验数值,代表每一个训练样本被选为聚类中心点的倾向性;s(k,j)表示训练样本的加权相似度矩阵,r(i,k)表示训练样本i适合作为训练样本k的聚类中心的程度,a(k,j)表示了训练样本k选择训练样本j作为其聚类中心的适合程度。
(3):根据计算可信度来决定第k个训练样本能否作为聚类中心点的条件,对于训练样本本身,其相似度数值设置为b(k):
r(k,k)+a(k,k)>0
其中,r(k,k)表示训练样本k适合作为训练样本k的聚类中心的程度,a(k,k)表示了训练样本k选择训练样本k作为其聚类中心的适合程度。
(4):更新可信度r和可用度a。更新方式为
r(i,k)=(1-lam)*r(i,k)+lam*r(i-1,k)
a(i,k)=(1-lam)*a(i,k)+lam*a(i-1,k)
其中,lam为阻尼因子,r(i-1,k)表示训练样本i-1适合作为训练样本k的聚类中心的程度,a(i-1,k)表示了训练样本i-1选择训练样本k作为其聚类中心的适合程度。其作用是为了避免发生震荡,平衡前后两次迭代中的可信度r和可用度a。
(5):检查是否满足终止条件即迭代次数达到最大迭代tmax,若不满足则跳转到3.2中的步骤(2)。
(3.3)对udln方法的说明
udln由两阶段学习构成:首先,样本输入经过修正的l12稀疏滤波(l12sf),利用该算法提取深层特征表达;然后,该深层特征被送入基于we-ap神经网络,进一步通过非线性函数映射来建立输入数据的内部分布模型,得到学习后的整个udln模型的网络权值。在识别的时候同样先对测试样本进行稀疏滤波,再将提取的特征输入到训练好的基于we-ap之后就能得到直接具有分类效果的udln。相对于深度学习及其其他故障诊断方法,整个模型的无需借助类别标签,可实现全程无监督特征提取与故障模式识别。udln模型的训练过程如下:该算法预训练阶段由两层l12sf结构构成的特征提取层以及一层无监督的we-ap聚类组成。udln模型结构图如图3所示。
具体实施方式:
实施案例1:在本节中为了验证所提出的基于udln的机械故障诊断模型的性能,需要模拟各类滚动轴承故障。该实验是在加速轴承寿命测试仪(ablt-1a由杭州轴承试验研究中心提供),实验台的主要组成部分为:计算机控制系统、试验头座、实验头、润滑系统、传动系统、加载系统、测试及数据采集系统。设计的测试仪上有四个轴承安装在由交流电机驱动的轴上,其传动系统由橡胶带支撑用于使用两个皮带轮连接交流电机和轴。与此同时,实验模拟了6205单排深沟球轴承的各类故障。实验用线切割分别模拟了6205滚动轴承的故障有内圈故障,内外圈复合故障,内外圈复合微弱故障,滚动体外圈复合故障,滚动体外圈复合微弱故障等五类故障。通过ni9234数据采集卡与pcb加速度传感器每隔5分钟采集一组20480点的振动数据。采样频率为10240hz,转速为1050r/min。每个该数据采集系统包括四个加速度传感器和数据采集卡。6205轴承的测试条件与试验数据说明具体如表2所示。
表26205轴承测试实验情况
在轴承故障数据中,各类轴承状态中有微弱故障也有严重故障同时也有复合故障等不同状况下的各类故障情况,振动信号的时域与单边谱频域波形图如图4所示。可以看出,相对于严重故障,微弱故障振动信号相对微弱且受到噪声干扰的程度影响大,其冲击特性不明显,频谱中共振频带也不明显,早期微弱故障难以观测出来。传统的时频方法难以量化故障程度与类别,需要依赖大量的专家知识与现场经验,导致实际故障诊断困难。因此,需要一种智能的故障诊断方法,以量化故障诊断结果,基于机器学习的智能故障诊断方法被广泛应用。为了显示更多的诊断信息,图5给出了所提的故障诊断模型按照故障诊断流程图1对轴承故障数据特征集h的处理结果,故障诊断结果的测试样本混淆矩阵如图5所示。从图5可以看出,所提出的方法将几个第二类样本的测试样本错误分类为第四类,原因可能是两类复合故障之间区分度不明显,且都包含内圈故障容易产生混淆,其他各类都聚类较为成功。
为验证所提基于udln的特征提取与模式识别能力。本发明将l12sf+ap,l12sf+kmeans;l12sf+fcm作为udln诊断模型的对比试验,分别记{udln=fd1;l12sf+ap=fd2;l12sf+kmeans=fd3;l12sf+fcm=fd4}。按照如上的故障诊断流程图1所示,使用上述其他诊断模型作为对比试验,将时域、频域、混合域特征分别输入上述4类故障诊断模型,根据隶属度与划分归类得到相应的识别结果如表3所示:
表3基于不同特征数据集的各类聚类识别结果
综上,为了使得智能故障诊断不依赖于先验的知识和诊断专家经验。本发明提出了一种基于无监督学习神经网络(uldn)的机械故障诊断方法。该方法所提的uldn模型是由两层改进l12sf和一层改进ap聚类组成。在该方法中uldn中,改进稀疏滤波能自适应地以无监督的方式从振动信号捕获具有鉴别信息的特征;然后将这些特征输入到改进的ap聚类,并以无监督的方式对健康状况进行分类。通过轴承数据集的实例研究表明,该方法不仅能够学习到具有判别性的高层特征,且能有效的实现无监督的全程自动化故障诊断。在不利用标签信息的情况下,该方法能够充分利用无监督学习的优点,提高机械故障诊断的准确性与自动辨识故障健康状况的。
以上所述,仅为本发明的具体实施方式,但本发明的保护范围并不局限于此,任何熟悉本技术领域的技术人员在本发明揭露的技术范围内,可轻易想到的变化或替换,都应涵盖在本发明的保护范围内。
- 还没有人留言评论。精彩留言会获得点赞!