一种基于均值聚类随机粒子群算法的RFID定位方法与流程
本发明涉及基于无线射频的室内定位方法,更具体地说是一种基于均值聚类随机粒子群算法的rfid定位方法,尤其应用于大型仓储货运的定位,属于监控定位技术领域。
背景技术:
随着无线局域网技术的发展,特别是物联网技术的兴起,人们对基于位置的服务要求越来越高,比如,购物时要确定商品在商场中的位置、儿童的安全定位、机场对行李箱进行位置追踪等。现有技术中,针对室外定位应用最多的是全球卫星定位系统;但是,室内环境往往错综复杂、障碍物较多、信号的阻挡作用极其明显,且建筑物往往为多层,显然,gps定位技术并不能满足室内定位的要求。
现有技术中常用的室内定位方法包括wi-fi定位、红外线定位、超宽带定位和led可见光定位、蓝牙定位等,对于定位方法的选择一方面要考虑定位精度的要求,另一方面要考虑系统的复杂程度和所用的开支。无线射频识别技术称为rfid,即:radiofrequeneyidentification,其具有非视距传播、抗干扰能力强、识别速度快、存储数据量大等优点,已在室内定位中得到广泛的应用。
目前,基于rfid技术的室内定位系统主要是使用信号强度测量的系统定位,主要包括基于距离和损耗模型的定位算法、landmarc算法、vire算法。其中,vire算法中的信号采集由于容易含有噪声,对噪声的处理不够完备,造成定位误差较大,同时存在多径问题以及虚拟参考标签定位的算法复杂性导致的冗余计算问题,都影响着定位的效率和精度。
技术实现要素:
本发明为避免上述现有技术所存在的问题,提供一种基于均值聚类随机粒子群算法的rfid定位方法,以满足监控定位系统的实时和准确定位的要求,提高定位精度,降低复杂度;针对vire算法进行改进,避免参考标签和虚拟参考标签的误差对定位精度产生的直接影响,利用改进的均值聚类粒子群算法寻找待定位标签的最优点,提高收敛速度,使定位性能更加稳定、精度更高。
本发明为解决技术问题采用如下技术方案:
本发明基于均值聚类随机粒子群算法的rfid定位方法的特点是包括以下步骤:
步骤1:在指定的室内区域中任意摆放m个参考标签、k个阅读器和一个待定位标签tag,已知各个参考标签的坐标,由阅读器获得待定位标签tag和各参考标签的rssi信号强度,将阅读器k在t时刻获取的参考标签ref的rssi信号强度记为参考标签信号强度rssirefk(t),将阅读器k在t时刻获取的待定位标签tag的rssi信号强度记为待定位标签信号强度rssitagk(t),其中,1≤ref≤m,1≤k≤k;
步骤2:采用阀值小波算法对所述参考标签信号强度rssirefk(t)和待定位标签信号强度rssitagk(t)进行信号处理,消除噪声;
步骤3:将指定的室内区域初始化为l个粒子,将每个粒子当成虚拟参考标签,通过sdqri算法中的二次回归曲线插值法计算获得每个粒子的rssi信号强度;
步骤4:将l个粒子进行随机聚类划分,建立均值聚类随机粒子群模型;通过均值聚类随机粒子群算法获得最优虚拟参考标签位置,依据所述最优虚拟参考标签位置估算出待定位标签的位置。
本发明基于改进均值聚类随机粒子群算法的rfid定位方法的特点也在于:在所述步骤2中,所述的信号处理是按如下过程进行;
步骤2.1:设s(t)为原始信号,n(t)为服从n(0,σ2)的高斯白噪声,则加入高斯白噪声的观测信号f(t)由式(1)所表征:
f(t)=s(t)+n(t)(1)
所述参考标签信号强度rssirefk(t)和待定位标签信号rssitagk(t)同样地由式(1)所表征,分别是由原始参考标签信号强度rssicrefk(t)和原始待定位标签信号强度rssictagk(t)与高斯白噪声信号n(t)组成,如式(2)所示:
将参考标签信号强度rssirefk(t)和待定位标签信号强度rssitagk(t)记为标签信号a;
步骤2.2:根据离散小波函数分别对t时刻获取到的各标签信号a进行小波变换处理,分别获得所述各标签信号a的观测信号、原始信号和高斯白噪声的小波系数;
以aj,g表征标签信号a在第j分解层的观测信号的小波系数,
以bj,g表征标签信号a在第j分解层的原始信号的小波系数,
以cj,g表征标签信号a在第j分解层的高斯白噪声的小波系数,
则有:
aj,g=bj,g+cj,g(3)
j表示分解的层数,j=0,1,2..j;g=0,1,2..n,j为小波变换最大分解层,n为信号长度;
针对aj,g、bj,g和cj,g设置阈值函数η(x,th)和阈值th进行去噪,减少噪声对信号的影响;
所述阈值函数η(x,th)由式(4)所表征:
以x表示小波分解后的信号小波系数,x=aj,g,bj,g,cj,g;
阈值th由式(5)计算获得:
μ为噪声的方差,μ=median(|x|)/0.6745;
由式(4)和式(5)获得去噪后的小波信号系数η(aj,g,th),η(bj,g,th)和η(cj,g,th),利用所述去噪后的小波信号系数η(aj,g,th),η(bj,g,th)和η(cj,g,th)进行小波重构,得到原始参考标签信号强度rssicrefk(t)和原始待定位标签信号强度rssictagk(t)。
本发明基于均值聚类随机粒子群算法的rfid定位方法的特点也在于:在所述步骤3中,按如下方式计算获得每个粒子的rssi信号强度:
针对l个虚拟参考标签,通过sdqri算法中的二次回归曲线插值法计算获得t时刻第k个阅读器到第l个虚拟参考标签的信号强度rssikl(t)作为均值聚类随机粒子群算法的初代粒子,所述sdqri算法中的二次回归曲线插值法由式(6)所表征:
其中,
dkl表示第k个阅读器与第l个虚拟参考标签的距离,0≤l≤l;
dkm表示第k个阅读器与第m个参考标签的距离;
dkr表示第k个阅读器与第r个参考标签距离,0≤m≤m,0≤r≤m且m≠r;
e是m个参考标签中距离待定位标签不大于
本发明基于均值聚类随机粒子群算法的rfid定位方法的特点也在于:在所述步骤4中,按如下步骤确定最优虚拟参考标签位置,并利用最优虚拟参考标签位置估算出待定位标签的位置;
步骤4.1:初始化初代粒子,设定第i个初代粒子xi(1)为:xi(1)=rssikl(t),其中i=1,2,3...l,第i个t代粒子为xi(t),设定学习因子c1,c2,c3、最大速度vmax,在搜索范围内随机产生u个聚类中心,每个聚类中心记为:ow(t),其中w=1,2,...u;
定义适应度函数值最小的粒子为最优粒子,适应度函数f[xi(t)]由式(7)计算获得:
d[xi(t),ow(t)]=||xi(t)-ow(t)||;
t为均值聚类随机粒子群算法的迭代次数,t=1,2,...q,q为最大迭代次数;
k为阅读器的个数;
步骤4.2:根据min{d[xi(t),ow(t)]}将xi(t)划分到第w个聚类cw中。
步骤4.3:根据式(8)重新计算聚类中心位置o'w(t),
o'w(t)=(1/ni)×∑xs(t)(8)
其中s=1,2,...,ni,xs∈cw;ni表示聚类cw中的粒子个数;
xs(t)表示为t代属于聚类cw的粒子;
若o'w(t)=ow(t),则输出k个聚类子种群,否则返回4.2;
步骤4.4:将划分完毕的种群根据式(9)进行粒子进化
c1~c3和r1~r3均为0到1之间的随机数;
pi(t)为粒子xi(t)所经历的最好位置;
pg(t)为各个聚类中的所有t代粒子所经历的最好位置;
zg(t)为所有聚类中的t代粒子所经历的最好位置;
vi(t)为所有t代粒子的当前速度;
若在t代某个聚类出现最优解,即xi(t)=pi(t)=pg(t),根据式(10)对粒子进化加入最优点保留随机粒补充机制:
pg(t)=argmin{f[p′g(t)],f[pg(t)]}(11)
其中,p′g(t)=argmin{f[pi(t)]},将由式(10)和式(11)得到的新的pi(t)和pg(t)重新代入式(9)进行计算;f[pi(t)]为关于pi(t)的适应度函数,f[p′g(t)]和f[pg(t)]分别为关于p′g(t)和pg(t)的适应度函数;
步骤4.5、计算每一个粒子的适应度函数值,当最优粒子的适应度函数值小于0.001时,表明均值聚类随机粒子群算法收敛;
若是:均值聚类随机粒子群算法满足最大迭代次数或算法收敛,则输出粒子xi(t)所经历的最好位置pi(t);
若否:则返回步骤4.4;
步骤4.6、由步骤4.5所获得的所述粒子xi(t)所经历的最好位置pi(t)为最优虚拟参考标签位置,将所述最优虚拟参考标签位置确定为待定位标签位置。
与已有技术相比,本发明有益效果体现在:
1、本发明能够从整体上提高定位精度,解决了很多算法中边缘节点定位误差较大的问题,所采用算法只是通过在仓储或空间定位中对rssi进行对比,尽可能地避免了多径问题,其整体定位策略尤其适合各种仓储货运、室内空间定位,其精度高、速率快、稳定性强和成本低。
2、本发明中采用小波阈值去噪算法,直接避免了参考标签和虚拟参考标签的误差对定位精度产生的直接影响;
3、本发明利用均值聚类粒子群算法寻找待定位标签的最优点,避免了标准粒子群算法存在不一定收敛到全局最优解的缺陷,且具有良好的收敛性,不会发散到无穷远处,精度更高,提高了收敛速度;
4、本发明使用sdqri算法中的二次回归曲线插值法避免了因为阅读器到不同参考标签的距离相同而导致的分母为0无法计算的缺点,从而提高了系统的定位稳定性;
5、本发明所需的rfid材料价格相对低廉,在相对复杂的工况中,可以节省大量的成本,大大避免了人力物力资源浪费。
附图说明
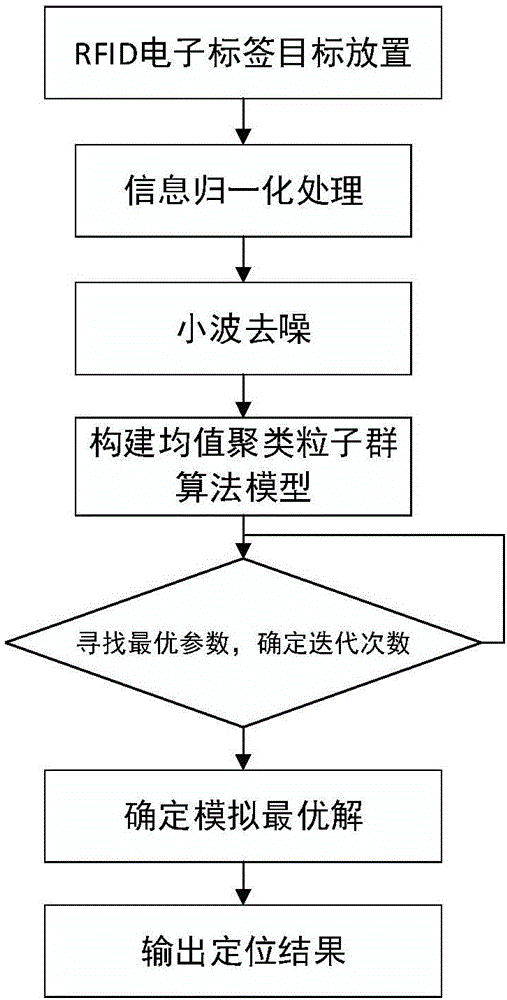
图1为本发明方法流程图;
图2为本发明中基于rfid的室内定位系统布局图;
图3为本发明中小波阈值去噪流程图;
图4为本发明中均值聚类随机粒子群算法流程图;
具体实施方式
参见图1,本实施例中基于均值聚类随机粒子群算法的rfid定位方法包括以下步骤:
步骤1:如图2所示,在指定的室内区域中任意摆放m个参考标签、k个阅读器和一个待定位标签tag,已知各个参考标签的坐标,由阅读器获得待定位标签tag和各参考标签的rssi信号强度,因为在不同时刻不同阅读器获得的信号强度都是不一样的,所以把它取成一个非线性变化的函数:阅读器k在t时刻获取的参考标签ref的rssi信号强度记为参考标签信号强度rssirefk(t),将阅读器k在t时刻获取的待定位标签tag的rssi信号强度记为待定位标签信号强度rssitagk(t),其中,1≤ref≤m,1≤k≤k。
步骤2:采用阀值小波算法对参考标签信号强度rssirefk(t)和待定位标签信号强度rssitagk(t)进行信号处理,消除噪声,其目的在于让采集到的信号更加贴近于真实信号,从而达到高精度的效果。
步骤3:将指定的室内区域初始化为l个粒子,将每个粒子当成虚拟参考标签,通过sdqri算法中的二次回归曲线插值法计算获得每个粒子的rssi信号强度。
步骤4:将l个粒子进行随机聚类划分,建立均值聚类随机粒子群模型;通过均值聚类随机粒子群算法获得最优虚拟参考标签位置,依据最优虚拟参考标签位置估算出待定位标签的位置。
具体实施中,如图3所示,步骤2中的信号处理是按如下过程进行;
步骤2.1:设s(t)为原始信号,n(t)为服从n(0,σ2)的高斯白噪声,则加入高斯白噪声的观测信号f(t)由式(1)所表征:
f(t)=s(t)+n(t)(1)
参考标签信号强度rssirefk(t)和待定位标签信号rssitagk(t)同样地由式(1)所表征,分别是由原始参考标签信号强度rssicrefk(t)和原始待定位标签信号强度rssictagk(t)与高斯白噪声信号n(t)组成,如式(2)所示:
将参考标签信号强度rssirefk(t)和待定位标签信号强度rssitagk(t)记为标签信号a。
步骤2.2:根据离散小波函数分别对t时刻获取到的各标签信号a进行小波变换处理,分别获得各标签信号a的观测信号、原始信号和高斯白噪声的小波系数;
以aj,g表征标签信号a在第j分解层的观测信号的小波系数,
以bj,g表征标签信号a在第j分解层的原始信号的小波系数,
以cj,g表征标签信号a在第j分解层的高斯白噪声的小波系数,
则有:
aj,g=bj,g+cj,g(3)
j表示分解的层数,j=0,1,2..j;g=0,1,2..n,j为小波变换最大分解层,n为信号长度;
针对aj,g、bj,g和cj,g设置阈值函数η(x,th)和阈值th进行去噪,减少噪声对信号的影响;
阈值函数η(x,th)由式(4)所表征:
以x表示小波分解后的信号小波系数,x=aj,g,bj,g,cj,g;
阈值th由式(5)计算获得:
μ为噪声的方差,μ=median(|x|)/0.6745;
由式(4)和式(5)获得去噪后的小波信号系数η(aj,g,th),η(bj,g,th)和η(cj,g,th),利用去噪后的小波信号系数η(aj,g,th),η(bj,g,th)和η(cj,g,th)进行小波重构,得到原始参考标签信号强度rssicrefk(t)和原始待定位标签信号强度rssictagk(t)。
具体实施中,在步骤3中是按如下方式计算获得每个粒子的rssi信号强度:
将指定的室内区域初始化为l个粒子,将每个粒子当成虚拟参考标签,通过sdqri算法中的二次回归曲线插值法计算获得每个粒子的rssi信号强度;其原因是在于相比于其它文献中记载的应用拉格朗日插值法虽然能较好地模拟复杂的非线性曲线,但非线性插值计算量庞大;通过sdqri算法中的二次回归曲线插值法计算获得每个粒子的rssi信号强度,其在相当程度上减少了计算量。
针对l个虚拟参考标签,通过sdqri算法中的二次回归曲线插值法计算获得t时刻第k个阅读器到第l个虚拟参考标签的信号强度rssikl(t)作为均值聚类随机粒子群算法的初代粒子,sdqri算法中的二次回归曲线插值法由式(6)所表征:
其中,
dkl表示第k个阅读器与第l个虚拟参考标签的距离,0≤l≤l;
dkm表示第k个阅读器与第m个参考标签的距离;
dkr表示第k个阅读器与第r个参考标签距离,0≤m≤m,0≤r≤m且m≠r;
e是m个参考标签中距离待定位标签不大于
具体实施中,如图4所示,在步骤4中按如下步骤确定最优虚拟参考标签位置,并利用最优虚拟参考标签位置估算出待定位标签的位置,建立均值聚类随机粒子群算法的目的是为解决基本粒子群算法“早熟”问题,基于对基本粒子群进化原理的分析,提出应用聚类思想对粒子群算法进行改进,聚类思想结合最优点保留随机粒子补充机制构造改进算法,而均值聚类随机粒子群算法的基本思想是利用粒子初始位置差异,对初始种群进行聚类划分,将不同的类认为是种群中的各个子种群,结合最优点保留随机粒子补充机制对种群进行更新;
步骤4.1:初始化初代粒子,设定第i个初代粒子xi(1)为:xi(1)=rssikl(t),其中i=1,2,3...l,第i个t代粒子为xi(t),设定学习因子c1,c2,c3、最大速度vmax,在搜索范围内随机产生u个聚类中心,每个聚类中心记为:ow(t),其中w=1,2,...u;
定义适应度函数值最小的粒子为最优粒子,适应度函数f[xi(t)]由式(7)计算获得:
d[xi(t),ow(t)]=||xi(t)-ow(t)||;
t为均值聚类随机粒子群算法的迭代次数,t=1,2,...q,q为最大迭代次数;
k为阅读器的个数;
步骤4.2:根据min{d[xi(t),ow(t)]}将xi(t)划分到第w个聚类cw中。
步骤4.3:根据式(8)重新计算聚类中心位置o'w(t),
o'w(t)=(1/ni)×∑xs(t)(8)
其中s=1,2,...,ni,xs∈cw;ni表示聚类cw中的粒子个数;
xs(t)表示为t代属于聚类cw的粒子;
若o'w(t)=ow(t),则输出k个聚类子种群,否则返回4.2;
步骤4.4:将划分完毕的种群根据式(9)进行粒子进化
c1~c3和r1~r3均为0到1之间的随机数;
pi(t)为粒子xi(t)所经历的最好位置;
pg(t)为各个聚类中的所有t代粒子所经历的最好位置;
zg(t)为所有聚类中的t代粒子所经历的最好位置;
vi(t)为所有t代粒子的当前速度;
由粒子进化方程可知,由于惯性权值和学习因子的改变使得粒子的全局搜索能力减弱,局部搜索能力加强,且当xi(t)=pi(t)=pg(t)时,粒子将停止进化。为增强全局搜索能力,对粒子进化加入最优点保留随机粒子补充机制,其具体方法为:若在t代某个聚类出现最优解,即xi(t)=pi(t)=pg(t),根据式(10)对粒子进化加入最优点保留随机粒补充机制:
pg(t)=argmin{f[p′g(t)],f[pg(t)]}(11)
其中,p′g(t)=argmin{f[pi(t)]},将由式(10)和式(11)得到的新的pi(t)和pg(t)重新代入式(9)进行计算;f[pi(t)]为关于pi(t)的适应度函数,f[p′g(t)]和f[pg(t)]分别为关于p′g(t)和pg(t)的适应度函数;
步骤4.5、计算每一个粒子的适应度函数值,当最优粒子的适应度函数值小于0.001时,表明均值聚类随机粒子群算法收敛;
若是:均值聚类随机粒子群算法满足最大迭代次数或算法收敛,则输出粒子xi(t)所经历的最好位置pi(t);
若否:则返回步骤4.4;
步骤4.6、由步骤4.5所获得的粒子xi(t)所经历的最好位置pi(t)为最优虚拟参考标签位置,将最优虚拟参考标签位置确定为待定位标签位置。
本发明方法中采用阈值小波降噪、均值随机聚类的粒子群算法,并与由sdqri算法中的二次回归曲线插值法准确计算得到的粒子信号强度相结合,比经典的vire定位系统效果更佳,比普通的粒子群算法更加准确,并提高了收敛速度,避免了过早陷入局部最优;其精度、稳定性、速率和成本都有大幅度改善,能够更加科学准确地在不同的仓储货运,室内定位等场景进行应用。
- 还没有人留言评论。精彩留言会获得点赞!