基于麦克风十字环阵列的声源定位跟踪装置及方法与流程
本发明涉及麦克风声源定位技术领域,尤其涉及一种基于麦克风十字环阵列的声源定位跟踪装置及方法。
背景技术:
麦克风阵列由多个麦克风排列组成,各麦克风同时采集并联合处理声音信号,在得到信号时域与频域信息的同时,还能够获得声音的空域(空间方位)信息。用麦克风阵列和目标的声音信息来获取目标位置是一种有效的定位方法。由于麦克风拾取声音属于被动探测方式,基于麦克风阵列的声源定位技术在军事探测、安全监控、音/视频会议系统、人机交互等领域应用广泛。
近年来,随着网络通信与移动计算技术的发展,麦克风阵列由规则几何拓扑结构发展为无特定几何形状和尺寸信息的分布式结构,这使得阵列的搭建、更改与应用更加灵活,但也带来了许多新的问题,导致已有的规则麦克风阵列定位理论和方法无法直接应用于分布式麦克风阵列中。
现有的声源定位和跟踪技术在定位精度和计算量之间不能较好的均衡,往往定位精度较高的方法,跟踪反应快,计算量也很大,实现的成本较高;计算量简单的方法,其定位的精度差以及噪声环境下,鲁棒性较弱。
中国专利申请号为:201710163580.x,申请日是:2017年03月17日,公开日是:2017年06月13日,专利名称为:麦克风阵列声源定位方法及装置,该发明提供一种麦克风阵列声源定位方法及装置,方法包括:根据四个麦克风接收到的语音信号判断四个麦克风是否正常;若是,则从四个麦克风中选择任意一组三麦克风阵列,并根据该组三麦克风阵列中每个麦克风的位置和接收到语音信号的时间差确定声源角度;利用该声源角度对视频设备的镜头执行声源跟踪控制。本申请通过麦克风的冗余设计,可以从四个麦克风中任意选择一组三麦克风阵列确定出声源角度,即使四个麦克风中有一个麦克风不正常,利用剩余三个麦克风仍然可以确定出声源角度,仍能够保证声源定位系统的正常运行,从而增加了声源定位系统的寿命。
上述专利文献公开了一种麦克风阵列声源定位方法及装置,但是该装置及方法对定位精度不高,跟踪反应慢,实现成本高,可靠性不强。
技术实现要素:
有鉴于此,本发明在于提供一种定位精度高,跟踪反应快,实现成本低、可靠性强的一种基于麦克风十字环阵列的声源定位跟踪装置及方法。
为了实现本发明第一个目的,可以采取以下技术方案:
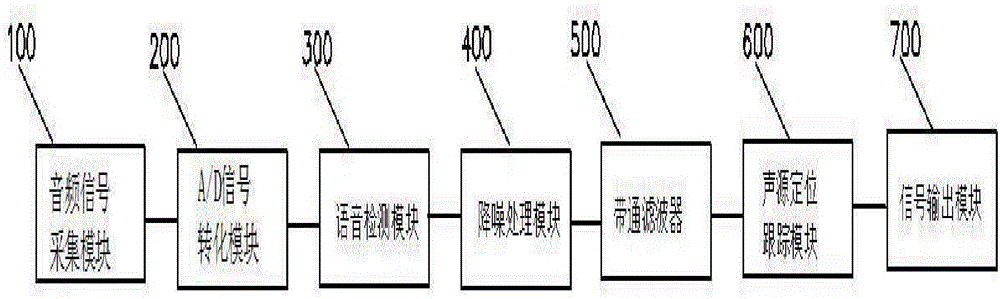
一种基于麦克风十字环阵列的声源定位跟踪装置,包括音频信号采集模块,用于采集声音信号;a/d信号转化模块,用于将模拟信号转化为数字信号;语音检测模块,用于检测语音信号;降噪处理模块,用于对语音信号进行降噪处理;带通滤波器,用于对语音信号滤波处理;声源定位跟踪模块,用于实现对声源方位跟踪;信号输出模块,用于信号输出;
所述音频信号采集模块通过a/d信号转化模块将语音信号传输至该语音检测模块;该语音检测模块通过降噪处理模块、带通滤波器将语音信号传输至该声源定位跟踪模块,该声源定位跟踪模块通过信号输出模块将语音信号输出。
所述音频信号采集模块通过麦克风十字环阵列采集语音信号。
为了实现本发明第二个目的,可以采取以下技术方案:
一种基于麦克风十字环阵列的声源定位跟踪方法,包括如下步骤:
步骤1):通过麦克风十字阵列拾取模拟声音信号,并输出四路数字信号;
步骤2):对四路数字信号,进行语音端点检测;
步骤3):对语音信号进行降噪处理;
步骤4):对语音信号通过带通滤波器进行滤波处理;
步骤5):对语音信号进行时延差计算;
步骤6):获取声源位置;
步骤7):语音信号输出及跟踪。
所述步骤2)包括若当前语音信号为非语音帧时,则利用当前语音帧数据进行噪声估计更新;若当前帧判决为语音帧时,则进入下一步。
所述噪声估计更新方法根据如下公式计算得出:
d(k,w)=d(k-1,w)*coef+(1-coef)*|x(k,w)|2
式中x(k,w)为当前帧信号进行短时傅立叶变化的频域表示;k表示为帧序号,w表示为频率分量;d(k,w)为当前帧估计得到的噪声功率;coef为平滑系数。
所述步骤3)降噪处理是通过如下公式计算得出:
|x(k,w)|2=|y(k,w)|2-α*d(k,w)if|y(k,w)|2>(α+β)*d(k,w)|x(k,w)|2=β*d(k,w)
式中x(k,w)为当前帧信号进行短时傅立叶变化的频域表示;k表示为帧序号,w表示为频率分量;d(k,w)为当前帧估计得到的噪声功率;coef、α、β为平滑系数。
所述步骤4)滤波处理是将100hz-4000hz的语音信号范围外的频率分量滤除。
所述步骤5)时延差包括整数延时估计和分数延时估计。
所述整数延时估计基于广义互相关函数的估计算法,其计算公式为:
其中,φ(w)为加权因子;x2*(w)为x2(w)的共轭。
所述分数延时估计基于抛物线差值的方法,其计算公式如下:
其中,del_tao为分数延时;α为两路信号互相关的峰值;1为与峰值相邻的左右两个点的数值。
所述步骤6)获取声源位置基于以下方程式计算得出:
13.
解方程得出:
所述步骤7)还包括定位的角度信息平滑处理,该平滑处理基于以下公式计算得出:
式中,k是帧序号,ci是加权系数,φ(k)是经过平滑处理过后的结果
本发明提供的技术方案的有益效果是:
1)本发明通过麦克风十字环阵列的声源定位跟踪定位精度高,跟踪反映块,实现成本低,计算量之间权衡关系比较好,性价比高;
2)本发明安全性高,稳定性强,准确率高,符合麦克风十字环阵列的声源定位跟踪发展要求;
3)本发明定位精度在噪声环境下鲁棒性强,适于普遍推广。
附图说明
图1为本发明实施例基于麦克风十字环阵列的声源定位跟踪装置系统方框图;
图2为本发明实施例基于麦克风十字环阵列的声源定位跟踪方法步骤流程图;
图3为本发明实施例基于麦克风十字环阵列的声源定位跟踪方法的整数时延迟估计算法框图;
图4为本发明实施例基于麦克风十字环阵列的声源定位跟踪方法的声源方位几何关系示意图。
具体实施方式
下面结合附图及本发明的实施例对发明作进一步详细的说明。
实施例1
参看图1,该基于麦克风十字环阵列的声源定位跟踪装置,包括音频信号采集模块100,用于采集声音信号;a/d信号转化模块200,用于将模拟信号转化为数字信号;语音检测模块300,用于检测语音信号;降噪处理模块400,用于对语音信号进行降噪处理;带通滤波器500,用于对语音信号滤波处理;声源定位跟踪模块600,用于实现对声源方位跟踪;信号输出模块700,用于信号输出;
所述音频信号采集模块100通过a/d信号转化模块200将语音信号传输至该语音检测模块300;该语音检测模块300通过降噪处理模块400、带通滤波器500将语音信号传输至该声源定位跟踪模块600,该声源定位跟踪模块600通过信号输出模块700将语音信号输出。
所述音频信号采集模块100通过麦克风十字环阵列采集语音信号。
本实施例中,首先通过麦克风十字阵列采集语音信号、该a/d信号转化模块200将模拟的声音信号转换成四路数字声音信号;该数字声音信号通过语音检测模块,将检测到的有人声说话的部分送入降噪处理模块;
语音信号经过降噪处理后,通过一个带通滤波器500(通带频率范围100-4000hz,人声的主要频率集中在300-3400hz)。在处理后的四路数据中任意选取三路数据,两两配对,构成三对信号对,然后分别计算三对信号的互相关信息得到三个的延时差值;
最后利用麦克风阵列的尺寸与前面计算得到的延时差计算出声源的位置信息,将计算得到的声源方位信息经过卡尔曼平滑和滤波处理,得到最终的定位信息,实现对声源方位的跟踪。
实施例2
参看图2,图3,图4,与上述实施例的不同之处在于,本发明一种基于麦克风十字环阵列的声源定位跟踪方法,包括如下步骤:
步骤1):通过麦克风十字阵列拾取模拟声音信号,并输出四路数字信号;
步骤2):对四路数字信号,进行语音端点检测s1;
步骤3):对语音信号进行降噪处理s2;
步骤4):对语音信号通过带通滤波器进行滤波处理s3;
步骤5):对语音信号进行时延差计算s4;
步骤6):获取声源位置s5;
步骤7):语音信号输出及跟踪s6。
本实施例中,首先,通过麦克风十字阵列硬件拾取模拟声音信号,并输出四路数字信号。其次,对四路数字信号,进行语音端点检测。所述语音检测模块300具体检测方法是:首先对数字音频信号进行分帧处理,计算每一帧的短时能量和倒谱距离两个特征。根据这两个特征,利用双门限判决法估计得到语音检测结果。
所述步骤2)包括若当前语音信号为非语音帧时,则利用当前语音帧数据进行噪声估计更新,否则噪声分量值不变;若当前帧判决为语音帧时,则进入下一步,进行降噪处理。
所述噪声估计更新方法根据如下公式计算得出:
d(k,w)=d(k-1,w)*coef+(1-coef)*|x(k,w)|2
式中x(k,w)为当前帧信号进行短时傅立叶变化的频域表示;k表示为帧序号,w表示为频率分量;d(k,w)为当前帧估计得到的噪声功率;coef为平滑系数。
所述步骤3)降噪处理是通过如下公式计算得出:
|x(k,w)|2=|y(k,w)|2-α*d(k,w)if|y(k,w)|2>(α+β)*d(k,w)|x(k,w)|2=β*d(k,w)
式中x(k,w)为当前帧信号进行短时傅立叶变化的频域表示;k表示为帧序号,w表示为频率分量;d(k,w)为当前帧估计得到的噪声功率;coef、α、β为平滑系数。
所述步骤4)采用具有线性相位的fir带通滤波器对四路信号进行滤波处理,将100-4000hz范围外的频率分量滤除。
从以上四路数据中,任意选择三路进行两两配对,分别计算每一对信号的延时差。所述步骤5)时延差包括整数延时估计和分数延时估计。
所述整数延时估计基于广义互相关函数的估计算法,参看图3,,首先对输入的两路信号进行短时傅立叶变换,在频域计算两路信号的互相关值。为了抑制噪声和混响干扰,加入加权因子φ(w),其计算公式为:
其中,φ(w)为加权因子;x2*(w)为x2(w)的共轭。
所述分数延时估计基于抛物线差值的方法,其计算公式如下:
其中,del_tao为分数延时;α为两路信号互相关的峰值;l为与峰值相邻的左右两个点的数值。
最后的延时估计结果计算:
τij=tao+del_tao
上式中i,j表示通道编号。例如:τ12表示第1路数据与第2路数据之间的延时差。
所述步骤6)获取声源位置利用麦克风阵列的几何结构以及前面计算得到的三个延时值,进行计算得到声源的位置。如图3所示,s(x,y,z)表示声源,设ri表示声源到麦克风mi的距离,τij表示声源到麦克风mi与mj间的延时,r,θ[0°,90°],
17.
解方程得出:
所述步骤7)还包括定位的角度信息平滑处理,将计算得到的方位角
式中,k是帧序号,ci是加权系数,φ(k)是经过平滑处理过后的结果;该结果就是当前帧最终的定位结果。原则上,加权系数的总和等于1,且i值与k越接近,加权系数越大。
本实施中,通过重复以上步骤,对每一帧估计的结果进行简单的平滑处理,系统能够实现持续的声源定位,达到声源跟踪的效果。
本发明就是要解决定位精度、跟踪速度、稳定性、计算量之间的权衡关系;既要简化计算,同时还要保证定位与跟踪的准确性和稳定。
以上所述,仅为本发明的较佳实施例而已,并非用于限定本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!