一种基于紫外可见光谱的二元掺伪当归快速准确的定量分析方法与流程
本发明属于中药检测技术领域,具体涉及一种基于紫外可见光谱的二元掺伪当归快速准确的定量分析方法。
背景技术:
作为一种名贵的中药材,当归因其具有补血和血,调经止痛,润燥滑肠、抗癌、抗老防老、免疫等功效而市场需求量巨大。由于目前当归资源紧缺,价格不断飙升,因此市场上常有与当归外形相近、但价格低廉的伪品出现,如独活、川芎和白术等。当归一般是磨粉之后使用,由于颜色接近,粉末状的当归与其伪品的鉴别更加困难。在市场中掺伪药品常以药品粉末的形式掺杂在真品中以达到以假乱真的效果,掺伪药品的所占比例严重影响了药物的治疗效果。
近年来,对掺伪当归的鉴定研究方法大都集中在色谱分析上,但是色谱分析操作复杂,分析时间长,且价格昂贵。所以,目前鉴别主要依赖检验员的主观判断。而光谱分析技术因其快速、无污染、可在线分析等优势已经成为研究的热点。与近红外光谱相比,紫外可见光谱仪器更为便宜及普遍,物质吸收峰也较为明显。但是中药材本身为复杂体系,其紫外可见光谱是多组分吸收的叠加,谱带复杂、重叠严重,除了目标组分信息外,往往含有大量噪音和背景信息,所以中药材的紫外可见光谱必须借助化学计量学才能实现准确地定性及定量分析。
技术实现要素:
本发明的目的是针对传统鉴别技术的缺陷,采用紫外可见分光光度计扫描样品的光谱,对光谱进行预处理,建立多元校正模型,从而实现二元掺伪当归快速准确的定量分析。
为实现本发明所提供的技术方案包括以下步骤:
1)配制当归二元掺伪样品
购买不同药店的当归及相似品若干份。首先对样品进行统一干燥,烘箱温度设定为60℃,每一种药材干燥至恒温后取出。对干燥后的药材进行磨粉,过120目筛,储存在干燥器内备用。后将纯当归样品与相似品进行二元掺伪,每种组分的含量范围都为0-100%,每个样品配制10g置于50ml塑料瓶中。
2)设置紫外可见光谱仪器的测试参数,采集样品的紫外可见光谱。
紫外可见光谱仪器的波长范围设置为200-800nm,扫描速度为高速,采样间隔为0.5nm,扫描模式为单个,测定方式为反射率,狭缝宽为5.0nm,积分时间为0.1秒,光源转换波长为323.0nm,检测器单元为外置单检测器,s/r转换为标准。采用积分球漫反射附件采集样品的紫外可见光谱。为了减少测量及操作误差,每个样品重新取样并扫描3次,3次测量的平均值作为该样品的最终光谱。
3)对数据进行分组
将数据集按照ks分组方法划分为训练集和预测集,其中训练集样品数占总样品数的2/3,预测集样品数占总样品数的1/3。
4)采用snv方法消除光的散射
采用snv方法从原始光谱中减去该条光谱的平均值后,再除以训练集光谱的标准偏差,以消除由于颗粒分布不均匀及颗粒大小不同产生的散射对光谱的影响。
5)采用一阶导数(1stder)扣除光谱背景
采用最佳窗口数对光谱进行一阶导数处理,扣除光谱中背景信息的影响,并提高信号的分辨率。其中最佳窗口数的确定方法为:将窗口数从3-59,间隔为2进行改变,计算不用窗口下1stder预处理后pls建模的rmsep,其中rmsep最小值对应的窗口数为最佳窗口数。
6)采用mcuve消除无信息变量
采用蒙特卡罗-无信息变量消除法(mcuve)选择与预测组分相关的变量。
7)建立plsr模型,对未知样品进行预测
对经过snv-1stder-mcuve处理后的光谱采用最佳因子数建立plsr模型。其中最佳因子数根据交叉验证均方根误差(rmsecv)随因子数(lv)的变化确定,其中rmsecv最小时值对应的因子数为最佳因子数。将预测集的光谱进行同样的处理后代入到模型中,进行预测。
附图说明
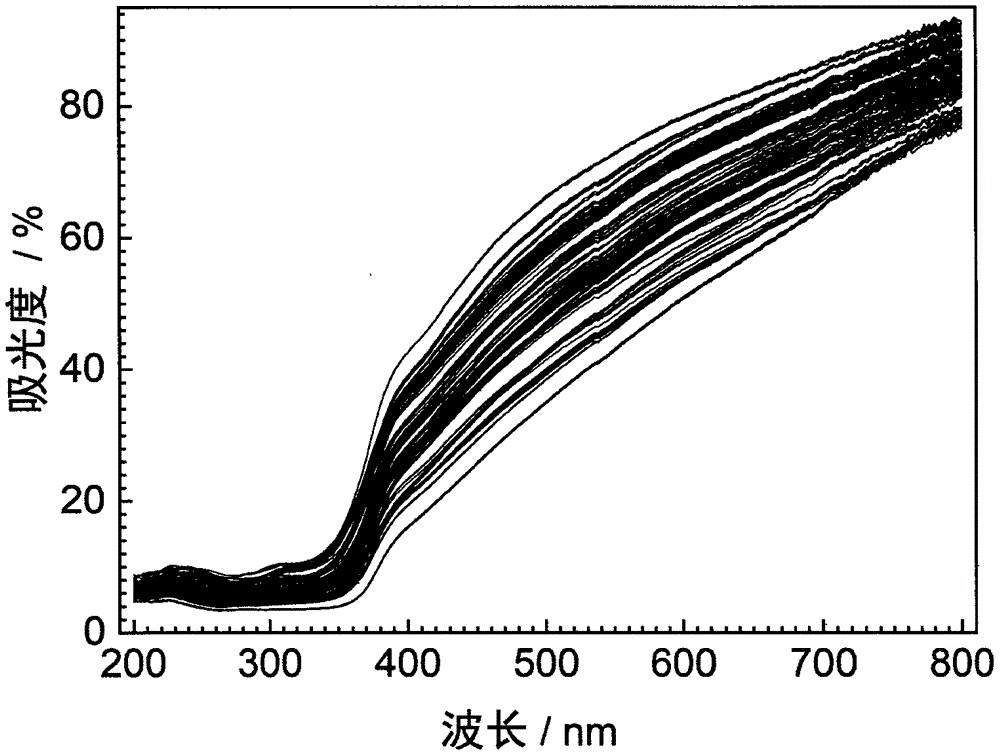
图1是81个当归独活二元掺伪样品的紫外可见光谱图
图2是当归组分数据集的rmsep随着一阶导数窗口尺度的变化图
图3是采用mcuve进行变量选择时对当归组分预测的rmsep随着保留变量数的变化图
图4是当归二元掺伪数据集plsr建模的rmsecv随因子数的变化图
图5是当归组分snv-1stder-mcuve-plsr建模对预测集预测的预测值与真实值的关系图
具体实施方式
为更好理解本发明,下面结合实施例对本发明做进一步地详细说明,但是本发明要求保护的范围并不局限于实施例所表示的范围。
实施例:
1)配制当归二元掺伪样品
从天津的40家药店中购买当归40份、独活39份,合计79份药品。对79份药品进行统一干燥。首先,烘箱温度设定为60℃,每一种药材干燥至恒温后取出。对干燥后的药材进行磨粉,过120目筛,储存在干燥器内备用。后将独活按照质量百分数0-3%范围内间隔1%、在3-5%范围内间隔2%、在5-95%范围内间隔2%、在95-97%范围内间隔2%、在97-100%范围内间隔1%对当归进行掺伪,每个样品配制10g置于50ml塑料瓶中共81个样品。
2)设置紫外可见光谱仪器的测试参数,采集样品的紫外可见光谱。
使用uv-2700紫外可见分光光度计(日本岛津公司)采集样品的紫外可见光谱。开机预热25分钟后打开电脑中的uv-probe2.34软件对测定所需要的仪器参数进行设置:采集样品所需要的波长范围为200-800nm,扫描速度为高速,采样间隔为0.5nm,扫描模式为单个,测定方式为反射率,狭缝宽为5.0nm,积分时间为0.1秒,光源转换波长为323.0nm,检测器单元为外置单检测器,s/r转换为标准,关闭阶梯校正。待仪器自检无误后,先将样品池放入紫外可见分光光度计中进行基线扫描,再用小药勺将待测样品取样放入样品池中,将样品涂抹覆盖均匀致使样品池的底部不留空隙,将样品池放入紫外分光光度计的卡槽之中进行样品扫描测定。测定一次后将样品池转一个角度接着放入卡槽中再次测定,每个样品均测量3次,取平均值作为该样品的最终光谱。81个当归独活二元掺伪样品的紫外可见光谱如图1所示。
3)对数据进行分组
将数据采用ks分组方法进行分组,取样品总数2/3的样品作为训练集,总样品数1/3的样品作为预测集。其中训练集有54个,预测集有27个。
4)采用snv方法消除光的散射
采用snv方法从原始光谱中减去该条光谱的平均值后,再除以训练集光谱的标准偏差,以消除由于颗粒分布不均匀及颗粒大小不同产生的散射对光谱的影响。
5)采用一阶导数(1stder)扣除光谱背景
采用最佳窗口数对光谱进行一阶导数处理,扣除光谱中背景信息的影响,并提高信号的分辨率。其中最佳窗口数的确定方法为:将窗口数从3-59,间隔为2进行改变,计算不用窗口下1stder预处理后pls建模的rmsep,其中rmsep最小值对应的窗口数为最佳窗口数。图2是当归组分数据集的rmsep随着一阶导数窗口尺度的变化图。从图2中可以看出,当归组分的rmsep均随着窗口数的增大先呈降低趋势到达最低点后开始缓慢上升。当归组分在窗口数为27时rmsep最小,所以得出当归的一阶求导最佳窗口数为27。
6)采用mcuve消除无信息变量
采用蒙特卡罗-无信息变量消除法(mcuve)选择与预测组分相关的变量。图3是采用mcuve进行变量选择时当归组分预测的rmsep随着保留变量数的变化图。当保留变量数为810时,rmsep达到最小值。
7)建立plsr模型,对未知样品进行预测
对经过snv-1stder-mcuve处理后的光谱采用最佳因子数建立plsr模型。其中最佳因子数根据交叉验证均方根误差(rmsecv)随因子数(lv)的变化确定,其中rmsecv最小时值对应的因子数为最佳因子数。将预测集的光谱代入到模型中,进行预测。图4是当归二元掺伪数据集plsr建模的rmsecv随因子数的变化图。rmescv最小值对应的因子数为11。采用因子数11对snv-1stder-mcuve处理后的光谱建立plsr模型。图5显示了当归组分snv-1stder-mcuve-plsr建模对预测集预测的预测值与真实值的关系,从图中可以看到,真实值与预测值具有很好的相关性,相关系数0.9871,达到很好的预测准确度。
- 还没有人留言评论。精彩留言会获得点赞!