基于聚类思想的电站空预器积灰监测方法与流程
本发明属于空预器积灰监测技术领域,具体的说是基于聚类思想的电站空预器积灰监测方法。
背景技术:
空气预热器是利用锅炉排烟热量加热空气的热交换设备,能够有效降低锅炉排烟温度,提高锅炉效率。目前各电站广泛采用回转式空气预热器,该种空预器易发生堵灰情况,尤其近年来随着各厂脱硝系统改造完成,脱硝过程中产生的硫酸氢氨进一步加剧了这一问题,威胁到机组的安全经济运行。目前缺乏对于空预器积灰状态的直接监测手段,往往通过空预器进出口压差侧面反映,但压差受烟气流量影响很大,当机组处于变工况运行时,压差存在很大波动,无法表现出空预器积灰程度的变化。
技术实现要素:
本发明要解决的技术问题是提供基于聚类思想的电站空预器积灰监测方法,利用聚类算法对相同负荷下空预器压差数据进行聚类处理,通过类心数据变化反应空预器积灰状态变化,对空预器冲洗进行指导。
为解决上述技术问题,本发明采用的技术方案为:
基于聚类思想的电站空预器积灰监测方法,其特征是:包括以下步骤:
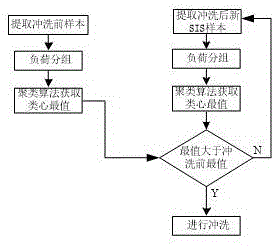
步骤1,获取原始数据;获取空预器冲洗前n个月的机组负荷数据、进出口烟气侧压差数据以及进出口空气侧压差数据,根据机组负荷程度将过程数据分组,并对原始数据进行预处理,获取有效数据;
步骤2,计算对比数据;通过聚类算法对步骤1中不同负荷程度下的空气侧进出口压差以及烟气侧进出口压差数据分别进行聚类,并记录下每组数据中类心的最小值和最大值,其中,每组数据中的类心最大值代表在该负荷程度下空预器运行的最差工况,即积灰最严重,每组数据中的类心最小值代表在该负荷程度下空预器运行的最在优工况,并以上述数据作为对比数据;
步骤3,空预器冲洗后,每隔一个月收集其过程数据,并按照步骤1中的机组负荷程度进行数据划分,进而对划分后的数据通过聚类算法获取其类心最值,将计算得到的类心最值与步骤2中的对比数据进行对比,当空预器冲洗后得到的任一负荷程度下该组数据的类心最大值大于对比数据中相同负荷程度下类心最大值时,空预器需要进行冲洗。
所述的步骤2和步骤3中,采用聚类算法对不同负荷程度下的空气侧进出口压差以及烟气侧进出口压差数据进行聚类的具体步骤为:
步骤s1:用值在0,1之间的随机数初始化隶属矩阵,使其满足式(1);
式中:uij为某一负荷程度下第j个样本,即压差数据对于第i个类的隶属度;c为类的数目;n为该负荷程度下用来聚类的样本总数,j为计数器;
步骤s2:用式(2)计算c个聚类中心;
式中:ci为第i个聚类中心;m为算法的模糊程度,一般取2;xj为某一负荷程度下第j个样本;i为计数器;
步骤s3:用式(3)计算目标函数,若目标函数值小于某个给定的阈值,或者本次计算结果与上一次结果相比变化量小于某个阈值,则算法停止;
式中:ji为第i个类的目标函数;dij为第i个聚类中心与第j个样本点间的欧式距离;
步骤s4:用式(4)计算隶属矩阵,返回步骤二;
式中:k为计数器。
所述的步骤1中,空预器冲洗前n个月的机组负荷数据从电厂的sis数据库中提取,所述的n的取值为2~6。
所述的步骤1中,获取的过程数据按照60%额定负荷、70%额定负荷、80%额定负荷、90%额定负荷、100%额定负荷进行分组,每组数据中的负荷差距不超过±2mw。
所述的步骤2中计算出的类心所属的类中数据量小于用来聚类的数据总数量的5%时,判定该类心为离群点。
该种基于聚类思想的电站空预器积灰监测方法能够产生的有益效果为:该方法利用聚类算法对相同负荷下空预器压差数据进行聚类处理,通过类心数据变化反应空预器积灰状态变化,对空预器冲洗进行指导。
附图说明
图1为本发明基于聚类思想的电站空预器积灰监测方法的工作流程图。
图2为本发明基于聚类思想的电站空预器积灰监测方法中冲洗前负荷与空气侧压差类心图。
图3为本发明基于聚类思想的电站空预器积灰监测方法中冲洗前负荷与烟气侧压差类心图。
图4为本发明基于聚类思想的电站空预器积灰监测方法中冲洗后负荷与空气侧压差类心图。
图5为本发明基于聚类思想的电站空预器积灰监测方法中冲洗后负荷与烟气侧压差类心图。
具体实施方式
以下结合说明书附图和具体优选的实施例对本发明作进一步描述。
基于聚类思想的电站空预器积灰监测方法,其特征是:包括以下步骤:
步骤1,获取原始数据;获取空预器冲洗前n个月的机组负荷数据、进出口烟气侧压差数据以及进出口空气侧压差数据,根据机组负荷程度将过程数据分组,并对原始数据进行预处理,获取有效数据;
本实施例中,从电厂sis数据库中提取出空预器冲洗前两个月的机组负荷,进出口烟气侧压差δpflue,进出口空气侧压差δpair数据,根据机组负荷将过程数据分组,主要分为400mw,450mw,500mw,550mw,600mw这几个区间,每个区间内负荷变化不超过±2mw。
步骤2,计算对比数据;通过聚类算法对步骤1中不同负荷程度下的空气侧进出口压差以及烟气侧进出口压差数据分别进行聚类,并记录下每组数据中类心的最小值和最大值,其中,每组数据中的类心最大值代表在该负荷程度下空预器运行的最差工况,即积灰最严重,每组数据中的类心最小值代表在该负荷程度下空预器运行的最在优工况,并以上述数据作为对比数据;
本实施例中,通过聚类算法,对400mw,450mw,500mw,550mw,600mw机组功率下的数据组进行聚类,得到类心数据如表1所示:
表1冲洗前聚类结果
上述计算结果中类心所属的类中数据量小于用来聚类的数据总数量的5%时,判定该类心为离群点,即假如用来聚类的总数据量为m个,聚出来n个类,其中第n个类包含的类中数据有m个,如果m<0.05*m,那么认为这个类所含数据量过少,这个类的类心属于离群点,不是正常运行范围的数据。
步骤3,空预器冲洗后,每隔一个月收集其过程数据,并按照步骤1中的机组负荷程度进行数据划分,进而对划分后的数据通过聚类算法获取其类心最值,将计算得到的类心最值与步骤2中的对比数据进行对比,当空预器冲洗后得到的任一负荷程度下该组数据的类心最大值大于对比数据中相同负荷程度下类心最大值时,空预器需要进行冲洗。
本实施例中,提取空预器冲洗后一个月的空预器数据进行分组并进一步通过聚类算法进行聚类,得到类心如表2所示:
表2冲洗后聚类结果
显而易见,表2中各负荷类心都小于表1中冲洗前得到的类心,表明此时还不需要进行冲洗。
进一步的,后续的每个月都可以得到相同规格的数据,并与表1中冲洗前的类心进行比较,当任一负荷程度下该组数据的类心最大值大于对比数据中相同负荷程度下类心最大值时,空预器需要进行冲洗。
进一步的,步骤2和步骤3中,采用聚类算法对不同负荷程度下的空气侧进出口压差以及烟气侧进出口压差数据进行聚类的具体步骤为:
步骤s1:用值在0,1之间的随机数初始化隶属矩阵,使其满足式(1);
式中:uij为某一负荷程度下第j个样本,即压差数据对于第i个类的隶属度;c为类的数目;n为该负荷程度下用来聚类的样本总数,j为计数器;
步骤s2:用式(2)计算c个聚类中心;
式中:ci为第i个聚类中心;m为算法的模糊程度,一般取2;xj为某一负荷程度下第j个样本;i为计数器;
步骤s3:用式(3)计算目标函数,若目标函数值小于某个给定的阈值,或者本次计算结果与上一次结果相比变化量小于某个阈值,则算法停止;
式中:ji为第i个类的目标函数;dij为第i个聚类中心与第j个样本点间的欧式距离;
步骤s4:用式(4)计算隶属矩阵,返回步骤二;
式中:k为计数器。
进一步的,步骤1中,获取的过程数据也可以按照60%额定负荷、70%额定负荷、80%额定负荷、90%额定负荷、100%额定负荷进行分组。
以上仅是本发明的优选实施方式,本发明的保护范围并不仅局限于上述实施例,凡属于本发明思路下的技术方案均属于本发明的保护范围;应当指出,对于本技术领域的普通技术人员来说,在不脱离本发明原理前提下的若干改进和润饰,应视为本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!