一种提高小麦水分预测精度的近红外光谱变量选择方法与流程
本方法发明属于农业分析领域,具体涉及一种提高小麦水分预测精度的近红外光谱变量选择方法。
背景技术:
小麦是我国主要的粮食作物之一,小麦作为一种广泛种植的谷类作物,富含淀粉、水分、蛋白质、脂肪、矿物质以及一些人体所需的微量元素,磨成粉后可以制作饼干、糕点、面条、馒头、面包,发酵后可以制成啤酒、酒精等,具有很好的营养价值,小麦水分含量是评估小麦品质的重要指标,快速无损检测小麦品质的方法和技术,对于粮食检验和食品加工等方面有重要意义。
近红外光谱技术可以同时、快速、无损的对小麦多个指标进行检测分析,由于近红外光谱主要是物质的倍频与合频吸收,信号相对较弱,并且谱带较宽、重叠严重,因此需要结合基于变量选择算法的化学计量方法来对近红外光谱数据进行处理,提取样品的特征信息,从而实现对未知样品化学值的预测。
国内外常见的变量选择方法有变量组合集群分析法(variablecombinationpopulationanalysis,vcpa,参见yonghuanyun,weitingwang,baichuandeng.usingvariablecombinationpopulationanalysisforvariableselectioninmultivariatecalibration.[j].analyticachimicaacta.2015.862:14-23)、迭代保留信息变量法(iterativelyretainsinformativevariables,iriv,参见yonghuanyun,weitingwang,yizengliang.astrategythatiterativelyretainsinformativevariablesforselectingoptimalvariablesubsetinmultivariatecalibration.[j].analyticachimicaacta.2014,807:36-43)、遗传学算法(geneticalgorithm,ga,参见leardir,gonzalezal,geneticalgorithmsappliedtofeatureselectioninplsregression:howandwhentousethem,chemomintelllabsyst,1998,41,195-207)、竞争性自适应重加权采样分析法(competitiveadaptivereweightedsamplingcars,参见hongdongli,yizengliang.keywavelengthsscreeninguingcompetitiveadaptivereweightedsamplingmethodformultivariatecalibration.[j].analyticachimicaacta.2009,648(1):77-84)、自加权变量组合集群分析法(automaticweightingvariablecombinationpopulationanalysis,awvcpa,参见赵环,宦克为,石晓光.基于自加权变量组合集群分析法的近红外光谱变量选择方法研究.[j].分析化学,2018,46(1):136-142)和变量组合集群分析迭代保留信息变量法(variablecombinationpopulationanalysis-iterativelyretainsinformativevariables,vcpa-iriv)等。
在小麦水分含量预测中,现有的变量选择方法都强制删除了次要变量与贡献较少的变量,忽视了变量组合对预测性能的影响,当这些变量组合在一起时会存在重要的特征信息,当变量数目很大时,一些变量选择方法会导致非常高的过拟合风险,产生很高的预测误差,使得预测结果不准确,此外现有算法模型复杂,预测精度低,模型不稳定。
技术实现要素:
针对现有技术的不足及缺陷,本发明提出了一种用于提高小麦水分预测精度的近红外光谱变量选择方法,该方法基于较小的交叉验证均方根误差值,对偏最小二乘回归系数和变量出现频率两种信息向量的结果进行归一化加权处理,计算出每个光谱变量的贡献值,根据贡献值的大小,建立回归模型,基于模型的回归系数绝对值,得到变量权重,逐步校正优化变量权重,得到最优的变量集,以此建立预测模型,可以很好的提高预测模型的精度及稳定性。
具体步骤如下:
a测量小麦样本的近红外光谱数据x和小麦水分含量化学值数据y,运用kennard-stone算法分为校正集和预测集;
b通过二进制矩阵采样法从变量空间中采样k次,得到k个变量子集,每一个变量子集都含有一组随机的变量组合,其中k值为1500;
c利用偏最小二乘法计算出每个变量组合的交互检验均方根误差,并选取其交互检验均方根误差最小的前σ×k个变量子集作为变量集,其中σ值取15%;
d统计变量集中每个变量出现的频率并进行归一化处理,进而得到了一个变量重要性判断依据称为第一类信息向量,归一化处理后的变量出现频率值为在以第一类信息向量为判定标准下的变量贡献值;
e计算出步骤c中所述变量集中每个变量在不同的变量子集中的偏最小二乘回归系数的绝对值,并进行归一化处理,最后对变量集中每个变量在不同变量子集中的归一化回归系数绝对值进行求和,变量归一化回归系数绝对值之和的大小与变量的重要性成正比,进而得到第二个变量重要性判据称为第二类信息向量,每个变量在不同变量子集中的归一化回归系数绝对值和为该变量在以第二类信息向量为判定标准下的变量贡献值;
f根据每种信息向量的交互检验均方根误差设置第一类信息向量和第二类信息向量的权重;
g根据第一类信息向量和第二类信息向量的权重,计算出变量集中每个变量的贡献值;
h运用指数衰减函数删除利用步骤g计算出的贡献值小的变量,保留利用步骤g计算出的贡献值大的变量,得到一个新的变量空间r;
i将变量空间r中的变量重复执行步骤b~步骤h进行变量筛选,此过程迭代n次,n值为50,在迭代过程中保留交互检验均方根误差值小的集合,最终剩下l个变量,l值为100;
j对剩余的l个变量采用自助随机采样方法进行采样,生成相互不完全相同的z个子集,z值为500,z个子集中的所有变量具有相同的选取概率权重;
k用步骤j中获得的z个子集建立子模型,计算子模型的交叉验证均方根误差,提取出交叉验证均方根误差最小的15%的最佳模型;
l计算步骤k中提取的每个最佳模型的回归系数,得到每个最佳模型的回归矢量,将上述回归矢量中所有回归系数转换为绝对值的形式,得到二次回归矢量,把所有二次回归矢量进行归一化得到最终回归矢量,并对最终回归矢量进行求和,根据最终回归矢量求和的结果,赋予每个变量新的权重;
m基于每个变量的新权重,应用加权采样去生成相互不完全相同的新的子集,并构建新的子集的子模型,在新的子集的子模型中,令回归系数绝对值越大的变量的选择概率值越大;
n将j~m步骤迭代运行n次,n值为50,在迭代过程中将交叉验证均方根误差值最小的子集作为最优变量集,以最优变量集建立小麦水分预测模型。
根据上述的变量选择方法,所述步骤f中的第一信息向量权重和第二信息向量权重的计算公式:
w1:第一类信息向量的权重;w2:第二类信息向量的权重;rmsecv1:第一类信息向量的交互检验均方根误差;rmsecv2:第二类信息向量的交互检验均方根误差;
所述步骤g中所述变量集中每个变量的贡献值的计算公式:
yi:第i个变量的贡献值,其值越大则该变量越重要;
与现有小麦水分分析技术相比,本发明提出的一种提高小麦水分预测精度的近红外光谱变量选择方法,采用了两种信息向量加权的方式判断变量的重要性,考虑了两种信息向量对预测模型的影响,弥补了只采用一种信息变量作为变量重要性判断依据的缺陷,同时基于模型回归系数对变量进行加权处理,考虑变量组合对预测结果的影响,减少了光谱变量,简化了预测模型,大大的提升了模型的预测精度。
附图说明
下面结合附图及实施方式对本发明作进一步说明:
图1为本发明一种提高小麦水分预测精度的近红外光谱变量选择方法流程图
图2为小麦样本的近红外光谱图
图3为预测集真实值与预测值之间的散点图分布
图4为平均光谱与每种变量选择方法最终所选取的特征变量分布图
具体实施方式
实施方案一:为了证明本发明的适用性,结合实例进行详细的说明。但是本发明也可以应用于本次所采用的实例之外的光谱数据。
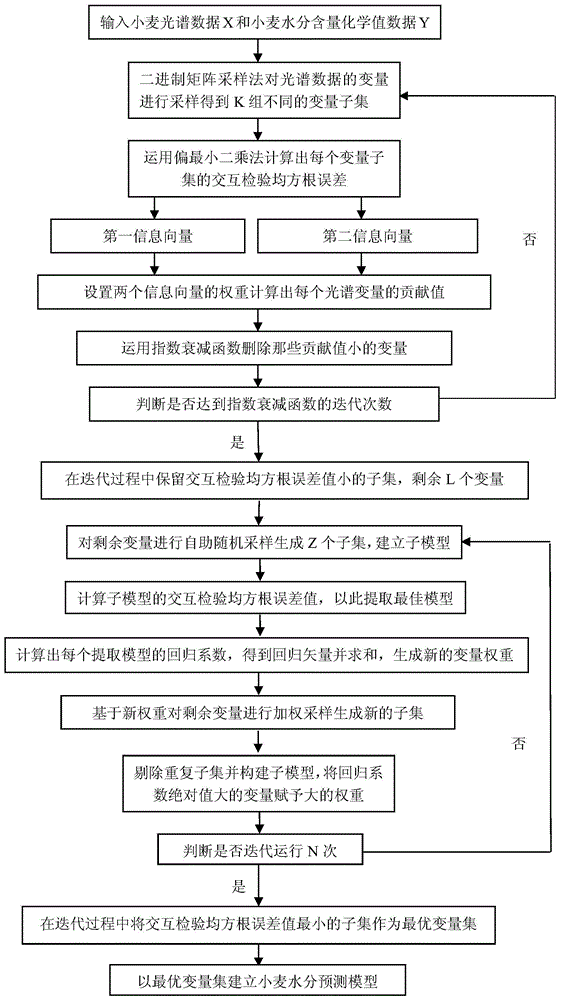
图1是本发明提供的一种提高小麦水分预测精度的近红外光谱变量选择方法的流程图,可见,本发明具体包括以下步骤:
(1)所收集的小麦近红外光谱数据包含了66个小麦样本,每个样本的近红外光谱波长分布在950-1700nm,运用光谱仪测试每个小麦样本的近红外光谱,并用化学方法测试每个样本含水分含量的化学值。运用kennard-stone(k-s)方法选取其中44个样本光谱数据和化学值数据作为校正集建立预测模型,将剩余的22个样本的光谱数据和化学值数据作为预测集样本检验模型的可行性,小麦近红外光谱图如图2所示。
(2)运用二进制矩阵采样法(bms)从小麦近红外光谱变量空间中采样1500次得到1500组不同的变量子集,之后运用偏最小二乘法(pls)计算出这1500组不同变量子集的交互检验均方根误差(rmsecv),选取其rmsecv值最小的前15%组变量子集作为变量集。
(3)记录变量集中每个光谱变量的出现次数并进行归一化处理得到第一类信息向量。
(4)记录每个光谱变量在变量集中的偏最小二乘回归系数并进行归一化处理,最后对变量集中相同变量的归一化偏最小二乘回归系数的绝对值进行求和得到第二类信息向量。
(5)通过公式(ⅰ)(ⅱ)分别计算这两类信息向量的权重,并根据公式(ⅲ)计算出变量集中每个光谱变量的贡献值。
信息向量的权重计算公式
w1:第一类信息向量的权重;w2:第二类信息向量的权重;rmsecv1:第一类信息向量的交互检验均方根误差;rmsecv2:第二类信息向量的交互检验均方根误差;
每个光谱变量的贡献值计算公式如下:
yi:第i个变量的贡献值,其值越大则该变量越重要;
(6)运用指数衰减函数删除那些贡献值小的光谱变量,保留其贡献值大的光谱变量,得到一个新的变量空间r。
rn=e-θ×n(ⅳ)
rn:指数衰减函数运行n次时变量保留率;θ:曲线控制参数,它与指数衰减函数的执行次数有关,指数衰减函数执行的次数越多,其θ值越小。n:指数衰减函数的执行次数。曲线控制参数的计算公式为
(7)对r中的变量重复(2)~(6)过程,此过程迭代50次,最终剩下100个光谱变量。
(8)对变量空间r中剩余的变量采用自助随机采样方法生成500个子集,在每个子集中提取所选择的变量,并剔除重复变量,将获得的变量子集建立子模型,计算子模型的rmsecv,并通过小的rmsecv提取最佳模型。
(9)计算每个提取模型的回归系数rc,将所有回归矢量归一化到(0,1)之间,并对回归矢量求和,使得变量获得新的权重wi。新的权重wi计算公式如下:
wi:新的权重,vi,z:z子集中第i个变量的归一化回归系数绝对值。
(10)基于变量的新权重,应用加权采样去生成新的子集,在每个新子集中提取所选择的变量,剔除重复变量并构建子模型,将回归系数绝对值大的变量赋予大的权重。
(11)将(8)~(10)步骤迭代运行50次,在迭代过程中将rmsecv值较小的子集作为最优变量集。
(12)以最优变量集建立小麦水分预测模型。
为了避免算法运行过程中算法随机性对变量选择结果的影响,将自加权变量组合集群分析结合权重采样算法(awvcpa-ws)运行50次,选取awvcpa-ws中预测精度最高的一组特征变量作为最终特征变量选取的结果,最终通过awvcpa-ws-pls建立小麦中水分含量的预测模型的预测结果如图3所示。
为了说明awvcpa-ws变量选择方法的优越性,将小麦近红外光谱数据在相同的条件下分别采用了ga、iriv、vcpa、cars、vcpa-iriv和awvcpa六种变量选择方法进行特征变量提取,由于每种变量选择方法在运行过程中都带有一定的随机性,进而影响模型的可靠性,所以我们将以上每种变量选择方法运行50次,计算出每种变量选择方法在建模过程中的预测均方根误差平均值,并选其每种算法预测精度最高的一组特征变量作为最终的特征变量选取结果,利用pls建立预测模型,每种变量选择方法所选取的特征变量结果如图4所示,每种建模方法的结果见表1。
表1不同建模方法对小麦水分含量的预测结果
本发明实施方式说明到此结束。
- 还没有人留言评论。精彩留言会获得点赞!