基于门控循环神经网络模型的孔隙度预测方法与流程
本发明属于储层参数预测领域,具体涉及一种基于门控循环神经网络模型的孔隙度预测方法。
背景技术:
孔隙度指的是储层岩石中所含的孔隙体积,反映了岩石储存流体的能力。它是评价储层性质、计算油气储量必不可少的岩石物性参数。因此,提高储层孔隙度预测精度是很有必要的。
孔隙度的测定是在实验室中进行的,用的是小块的岩芯或岩屑,测定时间比较长。除了费时之外,取心的成本也比较大。在很多情况下,取心仅限于某些层段,物性分析资料不足,不能全面地对储层进行评价。与昂贵的岩心资料相比,使用测井数据来估算孔隙度是比较廉价的方法。常用的测井方法有自然伽马、中子测井、声波测井、密度测井等,不同的测井方法都能一定程度上反映储层孔隙度的变化。根据测井数据与孔隙度的相关性,一些回归方程被提出,但是这种方法预测精度并不高,因为测井数据与储层孔隙度之间并不是绝对线性相关的。
技术实现要素:
针对上述问题,本发明提供一种基于门控循环神经网络模型的孔隙度预测方法。
为实现上述目的,本发明采用的技术方案为:
一种基于门控循环神经网络模型的孔隙度预测方法,包括以下步骤:
s1:构建用于孔隙度预测的基于门控循环神经网络模型;
基于门控循环神经网络模型包括gru层、全连接层;
所述gru层结构包括更新门,重置门,候选状态,隐藏状态;
gru隐藏层内部表达式如下:
zt=σ(wz[ht-1,xt]+bz)(1)
rt=σ(wr[ht-1,xt]+br)(2)
其中,xt为当前时刻的输入向量,ht-1为上一时刻的隐藏状态向量,wz与bz分别为更新门的权重矩阵与偏置向量,σ为sigmoid函数,zt为更新门的激活向量,rt为重置门的激活向量,wr与br分别为重置门的权重矩阵与偏置向量,
s2:选取多组能表征已知井孔隙度的测井参数作为输入数据,按比例随机分为训练集和验证集,对输入数据作归一化处理后输入到所述基于门控循环神经网络模型中,训练所述基于门控循环神经网络模型;
s3:输入未测井段的深度数据进行测试,利用上述步骤s2中训练完成的基于门控循环神经网络模型预测孔隙度。
进一步的,步骤s2中的测井参数优选为伽马、声波、密度、泥岩测井数据。
进一步的,步骤s2中将输入数据归一化到[0,1]的范围,采用的方法为:
其中:y为归一化后的值;x为原始数据;xmax为原始数据中的最大值;xmin为原始数据中的最小值。
进一步的,对上述步骤s2中训练完成的基于门控循环神经网络模型,采用如下方法评价模型预测性能:
其中,yi、
本发明的有益效果为:
gru具有记忆的特性,擅长处理序列问题,引入了门控单元控制信息传递可以更好的提取数据特征,用于孔隙度预测,预测精度更高。
附图说明
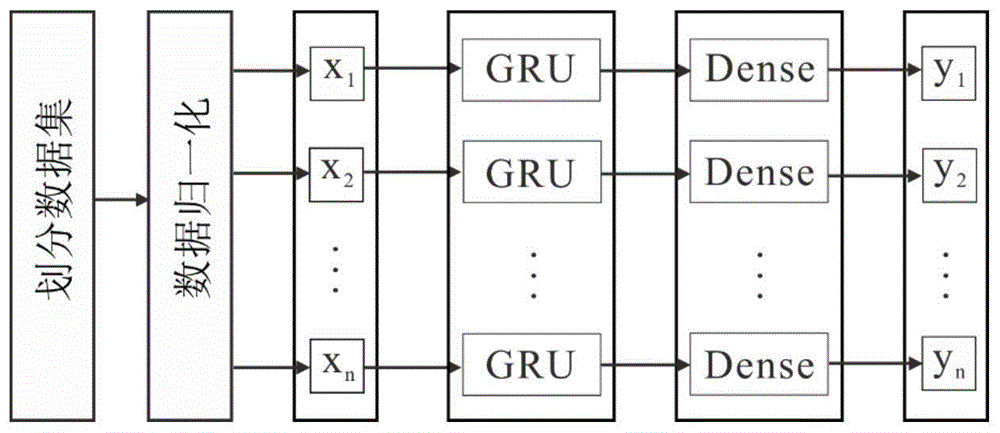
图1是本发明的实施流程示意图。
图2是本发明的gru结构示意图。
图3是本发明的实施例中gru模型w3井的孔隙度预测结果。
图4是本发明的实施例中gru模型在w3井的孔隙度预测结果交汇图。
图5a是本发明的实施例中三种深度学习模型在不同盲测试井中的预测结果mae评价指标对比图。
图5b是本发明的实施例中三种深度学习模型在不同盲测试井中的预测结果r2指标对比图。
具体实施方式
下面结合附图和具体实施例对本发明进行详细说明。本实施例以本发明技术方案为前提进行实施,给出了详细的实施方式和具体的操作过程,但本发明的保护范围不限于下述的实施例。
一种基于门控循环神经网络模型的孔隙度预测方法,包括以下步骤:
s1:构建用于孔隙度预测的基于门控循环神经网络模型,如图1所示;
基于门控循环神经网络模型包括gru层、全连接层(dense层);
所述gru层结构包括更新门,重置门,候选状态,隐藏状态;
gru结构如图2所示,gru隐藏层内部表达式如下:
zt=σ(wz[ht-1,xt]+bz)(1)
rt=σ(wr[ht-1,xt]+br)(2)
其中,xt为当前时刻的输入向量,ht-1为上一时刻的隐藏状态向量,wz与bz分别为更新门的权重矩阵与偏置向量,σ为sigmoid函数,zt为更新门的激活向量,rt为重置门的激活向量,wr与br分别为重置门的权重矩阵与偏置向量,
s2:选取多组能表征已知井孔隙度的测井参数作为输入数据,所述测井参数优选为伽马、声波、密度、泥岩测井数据,输入数据按比例随机分为训练集和验证集,对输入数据作归一化处理后输入到所述基于门控循环神经网络模型中,训练所述基于门控循环神经网络模型。
s3:输入未测井段的深度数据进行测试,利用上述步骤s2中训练完成的基于门控循环神经网络模型预测孔隙度。
本发明实施例结合多口井资料建立孔隙度预测模型,来预测未知井的孔隙度。本文设计的模型由单层gru层与单层全连接层组成,神经单元数分别设置为20、1。
本实施例实验井数据来源于中国中部地区。储集层属盐湖相沉积环境。岩性以粉细砂岩为主,分选中等,砂岩成分以石英为主,长石次之,为长石石英砂岩。储集类型为孔隙型,胶结物含量较少,胶结类型以孔隙式为主。从6口井选择5920个样本作为模型的数据集,并将6口井命名为w1—w6。
在有监督的深度学习中,为了防止过度拟合,一般需要将数据集分成独立的三部分:训练集,验证集和测试集。其中训练集用来确定模型普通参数,例如权重和偏置,被梯度下降所更新的,验证集用来确定模型超参数,例如网络层数,网络节点数,学习率等等,是通过人工设置的,而测试集不参与模型调参,纯粹是为了测试模型的泛化能力。在我们的研究中,测试集由w3井中的所有数据组成。从剩下的数据随机选择20%作为验证集,其余的数据作为训练集,用于训练模型。
输入数据特征量纲相差比较大,这会导致学习过程中,收敛过慢甚至是不收敛的情况。因此,我们需要用下面的公式将数据进行归一化处理,使我们的数据尽量处在相同的量纲。
该公式运用线性化方法将原始数据等比例缩放到[0,1]的范围;其中,y为归一化后的值;x为原始数据;xmax为原始数据中的最大值;xmin为原始数据中的最小值。
在这里评价模型预测性能的方法是mae与拟合优度r2。
其中,yi、
gru神经单元数设置为20,时间步长设置为6。图3展示了gru模型的预测结果,从图中可以看到孔隙度变化的整个趋势基本都预测对了。为了测试模型的泛化能力,我们用其他井轮流作为盲井测试并且与将测试结果cnn、rnn进行比较。cnn使用两层卷积层,每层包含20个1×3的卷积核,不使用池化层与卷积层。rnn的网络结构与gru相同。图4展示了gru模型在w3井的孔隙度预测结果,可以看出gru模型预测的孔隙度与实际孔隙度具有很高的相关性,说明gru模型取得了不错的预测结果。图5a~5b展示了三个模型在其他盲井测试的性能。图5a展示了,在mae指标上,gru性能都比rnn好,然而在w2与w6井上比cnn差;图5b展示了,在r2指标上,gru在所有盲井测试的表演是最好的。整体来看,gru在所有盲井测试上有更好的预测结果。
本说明书未作详细描述的内容属于本领域专业技术人员公知的现有技术。
- 还没有人留言评论。精彩留言会获得点赞!