一种基于二维近红外相关谱应用特征切谱判别牛奶中掺杂尿素的判别方法与流程
本发明属于检测方法领域,涉及掺伪牛奶的检测,尤其是一种基于二维近红外相关谱应用特征切谱判别牛奶中掺杂尿素的判别方法。
背景技术:
奶是人们生命的最初阶段的唯一食物。随着社会的快速发展和人民生活水平的提高,牛奶日益成为了大家平时生活中的日常饮品。牛奶,微量元素十分丰富,牛奶具有润肠、润燥的功能,也有延缓面部衰老,减缓人们大脑衰老的功能,因此受到广大消费者欢迎。但是,有很多不法商贩,为了获取暴利,往往会在牛奶中添加一些不同于牛奶固有组分的掺杂物,这些掺杂牛奶直接危害人体健康,存在很大的安全隐患,甚至导致部分饮用者中毒。因此,就需要发展一种快速便捷的掺杂牛奶的检测方法,以为消费者喝放心奶保驾护航。
常规的一维光谱已被广泛应用于判别掺假食品中。然而,牛奶是一种复杂的生物体系,既包含溶解物,还包括悬浮的胶体;再加上牛奶中掺杂物的多样化和微量化,以致纯牛奶的固有组分和掺杂物特征峰相互相叠。因此,通过常规的一维光谱无法有效地提取牛奶中微量的掺杂物特征信息。
相对于传统的一维光谱,二维相关谱技术可以更有效地提取复杂体系中待分析组分微弱的、变化的特征信息,已被用于掺伪食品的检测中。中国发明专利申请公开号cn104316491a公开了一种牛奶中掺尿素的同步-异步二维近红外相关谱检测方法;中国发明专利申请公开号cn103792198a公开了一种牛奶中掺三聚氰胺的中红外-近红外相关谱判别方法。上述所公开的两种方法虽然取得较好的分析结果,但建模所基于的是二维相关谱矩阵中所包含的全部信息,数据量巨大,计算时间长、效率低。
技术实现要素:
针对现有技术中存在的不足,本发明提供一种基于二维近红外相关谱应用特征切谱判别牛奶中掺杂尿素的判别方法,利用掺杂物特征切谱进行建模分析掺杂牛奶,该检测方法不仅有效提取了牛奶中微量掺杂物的特征信息,而且压缩了数据,克服了直接基于二维关谱建模效率低的问题,该方法简易、科学、分析效率和预测精度高。
本发明是通过以下技术方案实现的:
一种基于二维近红外相关谱应用特征切谱判别牛奶中掺杂尿素的判别方法,其特征在于:包括如下步骤:
步骤1:准备实验用纯尿素粉末、纯牛奶以及不同浓度的掺杂尿素牛奶;
步骤2:分别扫描实验用纯尿素粉末、纯牛奶以及不同浓度的掺杂尿素牛奶的近红外漫反射光谱,分别得到实验用纯尿素粉末、纯牛奶以及不同浓度掺杂尿素的牛奶一维近红外光谱数据;
步骤3:确定步骤2中纯尿素粉末的特征近红外波带:a1、a2、a3、a4、a5和a6;
步骤4:将实验用纯牛奶一维近红外平均谱数据与实验用纯牛奶一维近红外光谱数据进行二维相关计算得到实验用纯牛奶二维近红外相关谱;将实验用纯牛奶一维近红外平均谱数据与掺杂尿素牛奶一维近红外光谱数据进行二维相关计算得到实验用掺杂尿素牛奶二维近红外相关谱;
步骤5:对步骤5中得到的纯牛奶和掺杂尿素牛奶的二维近红外相关谱在步骤3确定的尿素特征波带:a1、a2、a3、a4、a5、a6处进行切谱,得到所有样品的特征切谱b1、b2、b3、b4、b5和b6;
步骤6:将步骤5中得到的样品特征切谱按行排列,得到所有样品的特征切谱矩阵x;
步骤7:将步骤6得到的所有样品的特征光谱矩阵x与类别变量矩阵y采用多维偏最小二乘判别法建立判别模型;
步骤8:将未知样品奶进行近红外漫反射光谱扫描得到未知样品奶一维近红外光谱数据,将实验用纯牛奶一维近红外平均谱数据与未知样品奶一维近红外光谱数据进行二维相关谱计算,得未知样品奶二维近红外相关谱,根据步骤6,在a1、a2、a3、a4、a5和a6处对未知样品奶二维近红外相关谱进行相切,得到未知样品的特征切谱,并根据步骤6对其按行排列,得到未知样品的特征切谱矩阵r,并将其代入步骤7中的判别模型,得到未知样品奶是否掺杂尿素。
进一步的,步骤5中对所有样品二维近红外谱进行相切,得到切谱用于建模分析。
进一步的,步骤5中仅在尿素特征波带处进行相切。
进一步的,步骤7中建模所用的特征切谱矩阵仅包括在掺杂物特征波带处的切谱。
本发明的优点及有益效果是:
1、本发明中,利用近红外相关谱仅在掺杂物特征谱带处的切谱进行建模分析,相较于完整的同步二维相关谱矩阵可有效减少特征数据量,建模效率更高。
2、本发明中,以在4000-11000cm-1的扫描范围内为例,一维近红外光谱数据1750个,进行二维相关计算后的二维相关谱矩阵的数据量为1750*1750个;而应用特征切谱后所用的数据量为1750*6个,需处理的数据量仅为原数据量的0.34%。因此,可明显提升建模效率,大幅减少数据量。
3、本发明中,基于二维近红外相关谱技术,相对于常规一维近红外光谱,具有更高的分辨率,可有效区分一维光谱上被覆盖的小峰和弱峰。操作方法更为简便,分析效率大幅提高,判别正确率更为准确。
附图说明
图1纯尿素粉末的一维近红外漫反射光谱;
图2纯牛奶同步二维近红外相关特征切谱;
图3纯牛奶异步二维近红外相关特征切谱;
图4掺杂尿素牛奶同步二维近红外相关特征切谱;
图5掺杂尿素牛奶异步二维近红外相关特征切谱。
具体实施方式
下面结合实施例,对本发明进一步说明,下述实施例是说明性的,不是限定性的,不能以下述实施例来限定本发明的保护范围。下面以牛奶中掺杂尿素判别为实施例,结合附图对本发明的掺伪牛奶判别方法进行详细说明。
一种基于二维近红外相关谱应用特征切谱判别牛奶中掺杂尿素的判别方法,本发明的创新在于,包括如下步骤:
步骤1:准备实验用纯尿素粉末、纯牛奶以及不同浓度的掺杂尿素牛奶;
本实施例中,取一定量的尿素粉末加入到少量纯牛奶中,搅拌、摇匀,再倒入到500ml容量瓶内,重复多次,最后用纯牛奶定容,通过充分摇匀,并且用超声波震动使得尿素在牛奶中充分溶解,得到10mg/ml浓度的掺杂尿素牛奶。依据低浓度分布紧和高浓度分布松的原则每个品牌分别配置40个掺杂尿素牛奶样品(0.1-10mg/ml)。
步骤2:在4000-11000cm-1范围分别扫描实验用纯尿素粉末、纯牛奶以及不同浓度的掺杂尿素牛奶的近红外漫反射光谱,分别得到实验用纯尿素粉末、纯牛奶以及不同浓度掺杂尿素牛奶在4000-11000cm-1范围的一维近红外光谱数据;
本实施例中,采用美国珀金埃尔默公司生产的傅里叶变换近红外光谱仪,对制备的尿素粉末、纯牛奶以及不同浓度掺杂尿素牛奶进行漫反射光谱扫描,得到每一样品的近红外漫反射光谱。
仪器参数设置如下:仪器自带积分球附件,扫描范围4000-11000cm-1,分辨率为8cm-1,每个样品扫描32次,取平均光谱。
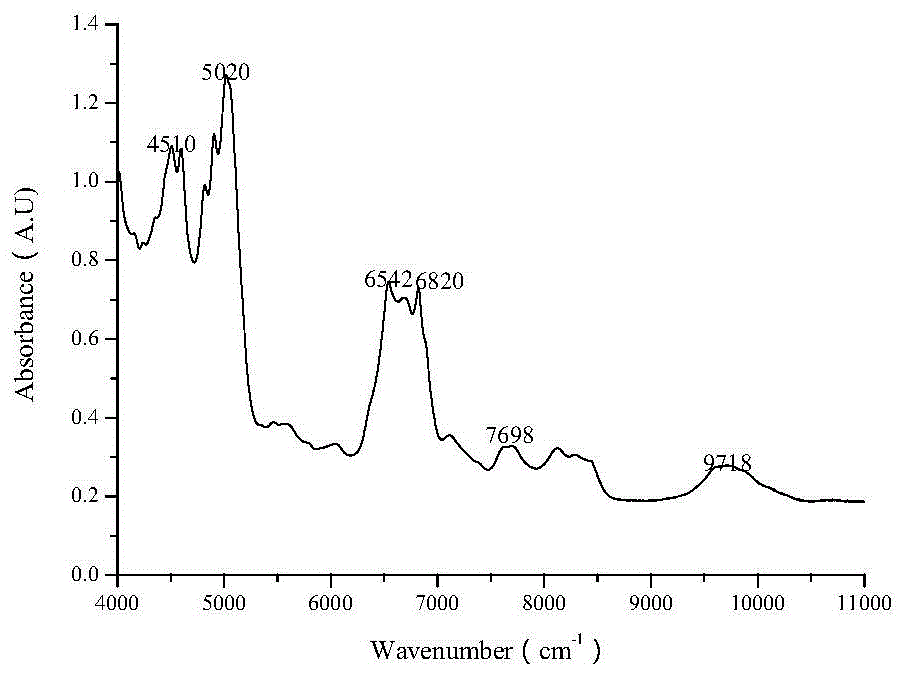
图1是纯尿素粉末在4000-11000cm-1范围的一维近红外漫反射光谱图。
步骤3:确定(2)中纯尿素粉末的特征近红外波带:4510cm-1、5020cm-1、6542cm-1、6820cm-1、7698cm-1、9718cm-1;
如图1所示,纯尿素粉末在4000-11000cm-1范围内存在六个明显的特征吸收波带,其位置分别在4510cm-1、5020cm-1、6542cm-1、6820cm-1、7698cm-1和9718cm-1处,选定这六个波带位置所对应的二维近红外相关谱的切谱来提取牛奶中掺杂尿素的相关特征信息。
步骤4:将实验用纯牛奶一维近红外平均谱数据与实验用纯牛奶一维近红外光谱数据进行同步和异步二维相关计算得到实验用纯牛奶同步和异步二维近红外相关谱;将实验用纯牛奶一维近红外平均谱数据与掺杂尿素牛奶一维近红外光谱数据进行二维相关计算得到实验用掺杂尿素牛奶同步和异步二维近红外相关谱;
本实施例中,对于一维动态光谱矩阵s(m×n),根据noda理论,同步二维近红外相关谱φ(ν1,ν2)可表示为:
异步二维近红外相关谱ψ(v1,v2)可表示为:
式中:m是光谱数,n为m阶方阵,称为hilbert-noda矩阵,t表示转置,n表示在近红外波段分别采集的波长数。
本实施例中,s中都包括两个光谱(m=2),s的第一行为纯牛奶的一维近红外平均谱,当s的第二行为第i个纯牛奶或掺杂尿素牛奶的一维近红外谱时,根据上式就可分别得到第i个纯牛奶或掺杂尿素牛奶所对应的同步和异步二维近红外相关谱。
步骤5:对(4)中得到的纯牛奶和掺杂尿素牛奶的同步和异步二维近红外相关谱在(3)确定的尿素特征波带:4510cm-1、5020cm-1、6542cm-1、6820cm-1、7698cm-1和9718cm-1处进行切谱,得到所有样品同步和异步二维近红外相关谱在上述6个尿素特征波带处的切谱;
如图2和图3所示,分别为纯牛奶的同步和异步二维近红外相关谱在上述6个尿素特征波带处对应的切谱。图4和图5分别是掺杂尿素牛奶的同步和异步二维近红外相关谱在上述6个尿素特征波带处对应的切谱。
步骤6:将(5)中得到的样品同步特征切谱按行排列,得到所有样品的同步特征切谱矩阵x1(80×6×1750);同样将(5)中得到的样品异步特征切谱按行排列,得到所有样品的异步特征切谱矩阵x2(80×6×1750);
步骤7:利用特征切谱矩阵与类别变量矩阵建立纯牛奶和掺杂尿素牛奶的多维偏最小二乘判别模型;
采用浓度梯度法从40个纯牛奶和40个掺杂尿素样品中选出54个作为校正集,余下26个样品作为独立的预测集。在校正集和预测集中,纯牛奶和掺杂尿素牛奶分别用“0”、“1”来表示其类别属性。将特征切谱矩阵作为自变量,类别属性变量矩阵作为因变量,建立纯牛奶和掺杂牛奶的多维偏最小二乘判别模型。对于同步特征切谱矩阵(54×6×1750)与类别变量(54×1)所建立的判别模型,该模型对校正集样品进行内部预测,其判别正确率为100%。对于异步特征切谱矩阵(54×6×1750)与类别变量(54×1)所建立的判别模型,该模型对校正集样品进行内部预测,其判别正确率为100%。
步骤8:利用步骤7所建立的模型,对未知奶样品进行判别。
在本实例中,通过测定未知奶样品的一维近红外漫反射光谱,采用校正模型中所用纯牛奶样品的一维近红外平均谱,依据式(1)计算其同步和异步二维近红外相关谱,并在4510cm-1、5020cm-1、6542cm-1、6820cm-1、7698cm-1和9718cm-1处对未知样品奶同步和异步二维近红外相关谱进行相切,得到未知样品的同步和异步特征切谱,并按行进行排列,得到未知奶同步和异步特征切谱矩阵。在此基础上,利用上述建立的多维偏最小二乘判别模型对预测集样品进行外部预测。对于同步特征切谱矩阵模型对未知样品的判别正确率为100%;对于异步特征切谱矩阵模型对未知样品的判别正确率也为100%。
上述参照实施例对一种基于二维近红外相关谱应用特征切谱判别牛奶中掺杂尿素的判别方法的详细描述,是说明性的而不是限定性的,应该说明的是,在不脱离本发明的核心的情况下,任何简单的变形、修改或者其他本领域技术人员能够不花费创造性劳动的等同替换均落入本发明的保护范围。
- 还没有人留言评论。精彩留言会获得点赞!