一种基于雷达与视觉多模态融合的具身语言导航方法
本发明涉及机器人导航、自然语言处理和计算机视觉领域,是一种基于雷达与视觉多模态融合的具身语言导航方法。
背景技术:
人们长期以来一直追求使用自然语言与计算机进行人机交互,因为它既有重要的理论意义,同时也有也有明显的实际意义。人类可以用自己习惯的自然语言使用计算机,而无需再花费大量的时间去学习各种复杂的计算机语言。当前,使用自然语言控制机器人进行自主导航正逐渐成为研究热点。研究者们希望未来可以通过自然语言控制机器人完成导航任务,而导航任务也是机器人其他复杂任务的基础,对发展人工智能有着重要的意义。
视觉语言导航是让机器人跟着自然语言指令进行导航,这个任务需要机器人同时理解自然语言指令与视角中可以看见的图像信息,然后在环境中对自身所处状态做出对应的动作,最终达到目标位置。当前的研究者们大多在仿真环境中提高机器人视觉语言导航的正确率,但是在现实场景中,由于环境的复杂,机器人在导航的过程中往往遇到障碍物的阻挡,仅仅依靠视觉和深度信息,机器人往往无法避开障碍物。况且由于双目相机通常安装在机器人的上方,因此机器人无法观测到脚下的障碍物。
技术实现要素:
本发明的目的是为克服已有技术的不足之处,提出一种基于雷达与视觉多模态融合的具身语言导航方法。本发明可使机器人对真实环境具有良好的感知能力,提高其避障导航的效率。
本发明提出一种基于雷达与视觉多模态融合的具身语言导航方法,其特征在于,该方法首先在带有双目相机的机器人的上安装激光雷达,并构建一个多模态融合神经网络模型;利用该机器人对该多模态融合神经网络模型进行训练,得到训练完毕的多模态融合神经网络模型;选取任一真实场景,对机器人下达自然语言导航指令并利用该神经网络模型转化为对应的语义向量;利用机器人在每个时刻分别获取的rgb图、深度图以及雷达信息,利用神经网络模型分别转化为对应的特征;对语义向量、rgb图特征和深度图特征进行特征融合,通过解码得到当前时刻的动作特征;利用雷达特征对该动作特征进行修正后,神经网络模型最终输出机器人在当前时刻的动作,直至机器人完成导航任务。该方法包括以下步骤:
1)在带有双目相机的机器人的上安装激光雷达,激光雷达安装在机器人的前方,安装完毕后,将该机器人作为执行导航任务的机器人;
2)构建多模态融合神经网络模型;该神经网络模型包括五个子网络,分别是:语言编码子网络,rgb图编码子网络,深度图编码子网络,雷达信息编码子网络以及包含两个全连接层和门控逻辑单元gru的解码子网络;利用步骤1)的执行导航任务的机器人在训练场景中对该多模态融合神经网络模型进行训练,训练完毕后,得到训练完毕的多模态融合神经网络模型;
3)选取任一真实场景,将执行导航任务的机器人放置在该场景中任意的初始位置并作为当前位置,记当前时刻t=1,给机器人下达自然语言导航指令,将该导航指令输入语言编码子网络,语言编码子网络对该导航指令的语言序列进行编码,得到语义向量s;该自然语言导航指令的内容包含导航任务的目的地;
4)机器人在当前位置利用双目相机获取到当前时刻t对应的rgb图和深度图,利用rgb图编码子网络对rgb图进行特征提取得到当前时刻的rgb图视觉特征vt,利用深度图编码子网络对深度图进行特征提取得到当前时刻的深度图视觉特征dt;机器人利用激光雷达从右向左进行扫描,对机器人到前方物体的距离进行采样,将采样得到的雷达数据输入雷达信息编码子网络,得到当前时刻的雷达特征lt;
5)将语义向量s、视觉特征vt和dt进行特征融合组成当前初始状态特征,对当前初始状态特征使用dropout机制进行随机失活,得到最终的当前状态特征;将该当前状态特征与前一时刻的动作at-1进行拼接,然后输入解码子网络的第一全连接层,该第一全连接层输出对应的状态特征;
将状态特征与上一时刻的隐状态ht-1一起输入到解码子网络里的门控逻辑单元gru中,gru输出当前时刻的动作特征at与隐藏状态ht;
其中,h0和a0均为特征值全为1的向量;
6)利用雷达特征lt对动作特征at进行修正,将修正后的特征输入解码子网络的第二全连接层,该第二全连接层输出机器人执行各动作的概率分布,然后选取概率最大值对应的动作作为机器人在当前时刻t的执行动作at;
7)机器人执行动作at,当下一个时刻到来时,令t=t+1,然后重新返回步骤4);直到机器人在当前时刻t的执行动作at为停止时,机器人完成导航指令到达目的地相应的位置,导航结束。
本发明的特点及有益效果在于:
1)针对当前视觉语言导航任务应用于现实环境中,由于环境的复杂,机器人在导航的过程中往往遇到障碍物的阻挡,仅仅依靠视觉和深度信息,机器人无法避开障碍物。况且由于双目相机安装在机器人的上方,机器人观测不到脚下的障碍物。本发明使用雷达数据和视觉输入作为机器人观测到的信息,来提高机器人在现实场景中的避障能力。
2)本发明采用一种压缩扩展的机制来对雷达数据进行特征提取;雷达特征对当前动作特征进行修正方法采用直接相加的方式。通过雷达特征的修正,机器人避障的成功率显著增加。
3)本发明提出的基于雷达与视觉多模态融合的具身语言导航方法,可以广泛应用于家居服务机器人、安全救援机器人上,可有效提高机器人在实际工作环境中的避障能力。
附图说明
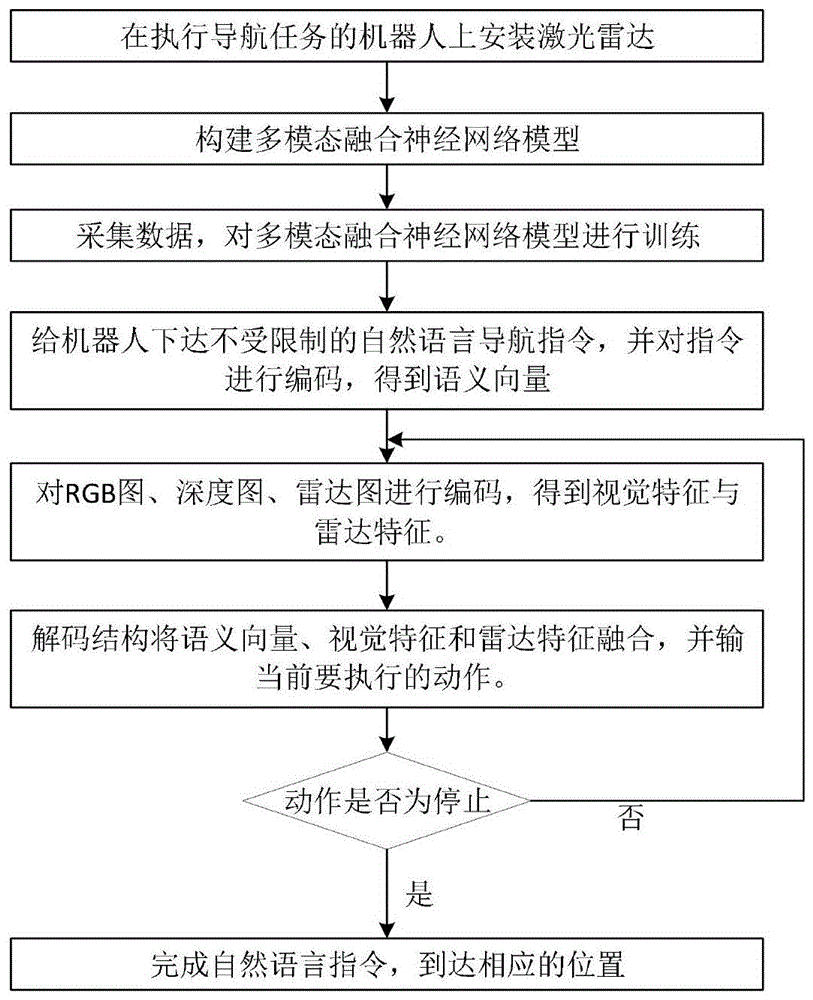
图1是本发明方法的整体流程图。
图2是本发明多模态融合神经网络模型中语言编码子网络、rgb图编码子网络、深度图编码子网络和雷达信息编码子网络的示意图。
图3是本发明多模态融合神经网络模型中的解码子网络工作原理图。
具体实施方式
本发明提出一种基于雷达与视觉多模态融合的具身语言导航方法,下面结合附图和具体实施方式对本发明作进一步详细的说明。
本发明提出一种基于雷达与视觉多模态融合的具身语言导航方法,整体流程如图1所示,包括以下步骤:
1)在带有双目相机的机器人的上安装激光雷达(本实施例采用hokuyo公司ust-10lx2d激光雷达),激光雷达安装在机器人的前方,安装完毕后,将该机器人作为执行导航任务的机器人;
2)构建多模态融合神经网络模型;该神经网络模型包括五个子网络,分别是:语言编码子网络,rgb图编码子网络,深度图编码子网络,雷达信息编码子网络以及包含两个全连接层和门控逻辑单元gru的解码子网络。
利用步骤1)的执行导航任务的机器人在训练场景中对该多模态融合神经网络模型进行训练,训练完毕后,得到训练完毕的多模态融合神经网络模型。
3)选取任一真实场景(该场景可与机器人训练时的训练场景不同),将执行导航任务的机器人放置在该场景中的任意初始位置并作为当前位置,记当前时刻t=1,给机器人下达不受限制的自然语言导航指令,将该导航指令输入语言编码子网络,语言编码子网络对该导航指令的语言序列进行编码,得到固定长度的语义向量s;其中,该自然语言导航指令的内容包含导航任务的目的地。
4)机器人在当前位置利用双目相机获取到当前时刻t对应的rgb图和深度图,利用rgb图编码子网络对rgb图进行特征提取得到当前时刻的rgb图视觉特征vt,利用深度图编码子网络对深度图进行特征提取得到当前时刻的深度图视觉特征dt;机器人利用激光雷达从右向左进行扫描,对机器人到前方物体的距离进行采样,将采样得到的雷达数据通过雷达信息编码子网络进行编码,得到当前时刻的雷达特征lt;
5)将语义向量s、视觉特征vt和dt进行特征融合组成当前初始状态特征,对当前初始状态特征使用dropout机制进行随机失活,得到最终的当前状态特征;将该当前状态特征与前一时刻的动作at-1进行拼接,然后输入解码子网络的全连接层fc(640,128),该全连接层输出对应的状态特征;
将状态特征与上一时刻的隐状态ht-1一起输入到解码子网络里的门控逻辑单元gru中,gru输出当前时刻的动作特征at与隐藏状态ht;
6)利用雷达特征lt对动作特征at进行修正,将修正后的特征输入解码子网络的全连接层(此全连接层为解码子网络中的全连接层fc(128,4)),该全连接层输出机器人执行各动作的概率分布,然后选取概率最大值对应的动作作为机器人在当前时刻t的执行动作at;
7)机器人执行动作at,当下一个时刻到来时,令t=t+1,然后重新返回步骤4);直到机器人在当前时刻t的执行动作at为停止时,机器人完成导航指令到达目的地相应的位置,导航结束。
所述步骤2)中,多模态融合神经网络模型的训练方法如下:
利用步骤1)执行导航任务的机器人从现实场景中采集训练数据;采集训练数据过程中,对于每条自然语言指令,将该语言指令输入当前语言编码子网络,语言编码子网络对该导航指令的语言序列进行编码,得到固定长度的语义向量s;
每条自然语言指令对应一个或者多条路径,每条路径包含多个机器人运动节点(训练时每条路径对应的动作序列由人工进行标注,得到该序列中每个节点对应正确动作的标签;测试的时候是随机将机器人放到某个初始位置,直接由神经网络输出机器人在每个节点对应的动作预测结果)。训练时,在每个节点机器人获取rgb图、深度图和雷达信息,作为当前节点的观测信息。在每个节点,机器人在当前位置利用双目相机获取到当前时刻t对应的rgb图和深度图,利用当前rgb图编码子网络对rgb图进行特征提取得到当前时刻的rgb图视觉特征vt,利用深度图编码子网络对深度图进行特征提取得到当前时刻的深度图视觉特征dt;机器人利用激光雷达从右向左进行扫描,对机器人到前方物体的距离进行采样,将采样得到的雷达数据通过当前雷达信息编码子网络进行编码,得到当前时刻的雷达特征lt;
然后将语义向量s、视觉特征vt和dt进行特征融合组成当前初始状态特征,对当前初始状态特征使用dropout机制进行随机失活,得到最终的当前状态特征;将该当前状态特征与前一时刻的动作at-1进行拼接,然后输入当前解码子网络的全连接层fc(640,128),该全连接层输出对应的状态特征;将状态特征与上一时刻的隐状态ht-1一起输入到当前解码子网络里的门控逻辑单元gru中,gru输出当前时刻的动作特征at与隐藏状态ht;
雷达特征lt对动作特征at进行修正,将修正后的特征输入当前解码子网络的全连接层,全连接层输出机器人执行各动作的概率分布,然后选取概率最大值对应的动作作为机器人在当前时刻t的预测执行动作at;
本发明中,网络模型的初始参数可以分为三个部分:(1)对rgb图和深度图编码的卷积部分,分别加载了imagenet和gibson的预训练权重,(2)对于语言编码子网络的h0、解码子网络中的h0以及a0映射成的128维的初始特征全为1,(3)其它部分的网络参数按照高斯分布进行初始化。
本发明通过交叉熵损失函数来测量预测动作与正确动作的差距:
公式中的i表示根据自然语言导航指令所做的动作序列中动作的索引(其中,一条路径的所有动作构成一个序列),ai和
对整个多模态融合神经网络模型训练的过程包括前向传播和反向传播两个方面:前向传播主要是评估当前参数的损失,后向传播主要是根据损失函数的梯度更新参数。本发明中,机器人每完成一条训练路径,多模态融合神经网络模型完成一次训练,计算一次损失,然后根据损失值完成一次梯度更新。
在网络模型训练的过程中本发明采用teacherforcing的机制,teacherforcing是一种快速有效地训练循环神经网络模型的方法,该模型使用来自先验时间步长的输出作为输入,即在训练的过程中,它不是每次都使用上一个状态的动作输出作为下一个状态的动作输入,而是基于0.5的概率直接使用训练数据的正确动作(groundtruth)作为下一个状态的动作输入。
本发明使用adam优化器优化模型的参数,并将学习率设为0.001。每次从训练数据集中随机选择一条路径进行一次训练,完成一次后向传播,更新一次参数。一共训练2000次完成整个训练过程。得到训练完毕的多模态融合神经网络模型。
如图2(a)所示,在语言编码子网络中,对语言序列进行编码采用循环神经网络的方法,将不同长度的自然语言指令编码成固定维度的语义向量s,向量维度为128;所述自然语言指令为单词序列,该序列中可包含若干不同的动作;
首先将指令中的每个单词(本实施例采用英文单词序列作为自然语言指令)进行embedding(词嵌入)操作,转换成词向量,我们用xi来表示第i个词向量;从i=1开始,将xi作为当前词向量与前一词向量的隐状态hi-1(i=1时,对应hi-1的128维的特征值全为1)按照时间顺序输入到语言编码子网络中,每一个时刻输出当前词向量xi对应的隐状态hi,我们用函数f来表示循环神经网络隐藏层的变换:hi=f(xi,hi-1);
假设自然语言指令有m个单词,将语言编码子网络输出的最后一个词向量对应隐状态hm作为整条指令的语义向量s。
作为一种可能实现的方式,所述机器人对rgb图和深度图进行特征提取过程中,首先通过卷积神经网络对图像进行特征提取,然后通过全连接神经网络将其映射到固定维度的视觉特征;rgb图和深度图分别进入各自的编码子网络,所用的网络权重也不相同;
如图2(b)所示,rgb图编码子网络采用了resnet50神经网络的卷积部分,然后在最后一层卷积层后再增加一层全连接层;为了增强加快梯度下降的收敛速度,增强模型的泛化表达能力,用来对rgb图编码的resnet50神经网络的卷积部分加载了在imagenet上训练的预训练权重,用来收集rgb图的视觉语义特征;用来对rgb图编码的全连接层用于输入卷积部分输出的视觉语义特征,并将其映射到256维的特征并输出rgb图视觉特征vt。如图2(c)所示,深度图编码子网络包括修改后的resnet50神经网络的卷积部分,然后在最后一层卷积层后再增加一层全连接层,其中卷积部分的卷积核个数相比于修改前减少一半;同样为了加快与训练权重,我们将深度图表示的绝对距离转换为相对距离(即将该深度图上绝对距离先归一化,其中以图中最近的绝对距离为0,最远的绝对距离1);用来对深度图编码的resnet50神经网络的卷积部分加载了在gibson虚拟环境中上训练的预训练权重,用来收集深度图的视觉语义特征;用来对深度图编码的全连接层用于输入卷积部分输出的视觉语义特征,并将其映射到128维的特征并输出视觉特征dt。
在机器人领域,激光雷达传感器可以帮助机器人在未知环境中获取机器人到前方物体的距离,为后续定位导航提供很好的环境认知能力。如图2(d)所示,雷达信息编码子网络包含三个全连接层,并采用了一种压缩扩展的机制,使机器人对前方的物体有着良好的感知能力。其中,第一全连接层用于输入64维的雷达数据,提取雷达特征并输出128维的雷达语义特征;第二全连接层用于输入第一全连接层输出的雷达语义特征,压缩雷达语义特征,将其映射到32维的特征并输出;所述的第三全连接层用于输入第二全连接层输出的雷达语义特征,扩展雷达语义特征,将其映射到128维并输出当前雷达特征lt。
如图3所示,在语义向量s、视觉特征vt和dt进行特征融合的过程中,首先将三种特征concat(拼接)连接到一起,组成512维的当前初始状态特征,对当前初始状态特征使用dropout机制进行随机失活;当前所用的dropout,是指在特征输入过程中,按照一定的概率将一些特征丢弃(本实施例取值0.2,即在拼接后的特征中随机选取20%的特征变成0),得到最终的当前状态特征,这样可以起到数据增强的效果,来避免过拟合。
在机器人做出的动作序列中,接下来要做的动作与上一时刻要做的动作有很大的相关性,因此我们将上一时刻动作at-1被映射成一个128维的特征(t=1时,at-1对应的128维的特征值全为1),并与经过dropout之后的状态特征concat连接到一起,组成640维度的特征,紧接着通过解码子网络的全连接层fc(640,128)将其映射到128维的状态特征并输出;状态特征与解码子网络上一时刻输出的隐状态ht-1(隐状态的初始值全为1,向量长度为128维)一起被送入到解码子网络的门控逻辑单元gru中,输出当前动作特征at与隐藏状态ht;输出的动作特征at可以被表示为:
at=gru([st,vt,dt,at-1],ht-1)
雷达特征lt对当前动作特征at进行修正方法采用直接相加的方式,增加机器人的避障能力;被修正后的特征经过解码子网络的全连接层fc(128,4),该全连接层用于生成动作at,wa和ba表示这一层的神经元所对应的权重和阈值,并输出相应的动作概率分布pat,选取概率最大值对应的动作作为机器人的将要执行动作at,这个过程可以被表示为:
at=argmax(softmax(wa(at+lt)+ba))
在本发明中,机器人接收的是自然语言指令序列,在每个状态都做出一个动作,是一种将指令序列转为动作序列的过程。随机初始化机器人的位置,并给予机器人不受限制的自然语言指令,机器人根据当前观测的视觉信息,并通过雷达信息来修正当前所要做的动作,在机器人认为未完成自然语言导航指令,即未到达目标位置时,机器人会继续观测当前状态,做出当前应该执行的动作,直到机器人认为到达了目标位置,机器人停止,等待下一条自然语言导航指令。
- 还没有人留言评论。精彩留言会获得点赞!